基于弱信号的颠覆性技术早期识别研究
2024-01-03刘俊婉庞博徐硕
刘俊婉,庞博,徐硕
(北京工业大学经济与管理学院,北京 100124)
0 引 言
颠覆性技术是指改变原有技术轨迹的全新技术或跨学科、跨领域应用的现有技术,可对已有传统或主流技术产生整体或根本性的替代效果和相应的市场颠覆效应[1]。颠覆性技术具有跨界性、突变性、破坏性、替代性、前沿性等特征,属于一种对现有市场、技术体系等产生巨大影响的技术。因颠覆性技术对现有市场的颠覆性和破坏性,围绕该类技术的研究成为国家和企业掌握未来技术发展动向、进行市场变革以及提升自身竞争力的重要途径[2],因此,针对颠覆性技术的识别研究成为当前学界关注的热点领域。在以往研究中,常用的颠覆性技术识别方法包括以专家评议为主的定性研究方法和以文献或专利分析法、技术演化规律法、理论或数学模型法为主的定量方法,识别结果主要集中在技术的快速发展期或成熟期,针对颠覆性技术早期识别的研究较少。预先感知刚刚萌芽的颠覆性技术,可以掌握市场先机并进行针对性地研发,在技术竞争过程中占据先导地位。颠覆性技术发展初期,信号的信噪比较低,对于有征兆意义的弱信号,需要运用系统的方法在庞杂的信号中进行扫描、筛选、甄别,才能辅助科技决策[3]。如何建立颠覆性技术探测的弱信号扫描体系,以实现颠覆性技术的早期识别,是提高颠覆性技术战略政策感知预警能力的关键。
目前,关于颠覆性技术的早期识别通常依赖于专家进行人工判断,随着大数据规模呈指数级增长,专家们从各种信息来源中扫描预警信息变得越来越具有挑战性,而弱信号探测全自动化的研究处于起步阶段,本文基于专利的弱信号探测模型与技术颠覆性潜力测度体系相结合的方法,进行颠覆性技术早期识别。具体而言,基于目标领域的专利数据,利用LDA(latent Dirichlet allocation)主题模型抽取专利的研究主题,使用弱函数对研究主题进行过滤,得到包含弱信号的主题,进一步利用预兆函数对弱信号主题涉及的术语进行过滤,结合语义分析得到弱信号术语集合,利用技术颠覆性潜力测度指标体系对包含弱信号术语的专利进行颠覆性潜力测度,最终识别出具有颠覆性潜力特征的技术。本文使用的弱信号探测模型与技术颠覆性潜力测度体系相结合的方法,为颠覆性技术的早期识别提供了一种可供参考的思路和方法。
1 相关研究
1.1 弱信号及探测方法
与电子通信领域中“信号”的含义不同,情报学领域的“信号”侧重于信息的语用维度,注重解读信号的产生、信号包含的信息和趋势等[4-5]。弱信号通常是指强度较弱、不易被感知和接收、携带着预示未来发展可能性的有效信息,随着时间的推移可以演变为强信号,其表现出的变化和预兆既是一种机遇,也是一种威胁[4]。弱信号具有隐匿性和不确定性[6],针对弱信号的研究可获得有关未来趋势的关键信息,预防和控制可能发生的各类情形,抓住可能带来的增益机会,提前规避可能存在的风险,为此各领域学者开展了关于弱信号的研究[7]。颠覆性技术在萌芽初期往往以主题间的微弱连接关系存在,而弱信号是识别这种弱关系的切入点,通过弱信号分析可以使颠覆性技术的早期识别成为可能[6]。
与“弱信号”相关的研究涉及计算机科学、社会科学、商业和管理等学科领域[7],其中与技术弱信号相关的研究是目前的热点和难点,众多学者针对不同阶段的技术开展了弱信号的相关研究[8],相关分析方法包括定性和定量两种方法。弱信号的定性分析主要包括主观感知、德尔菲法、环境扫描法、情景分析法等。该类分析方法以专家为核心进行弱信号探测,常用于企业战略规划、行业或国家政策导向等实际应用[4]。弱信号的定量分析主要包括文献计量、专利计量、文本挖掘、模糊综合评价法、突变理论、监测模型、机器学习探测法等。利用机器学习方法进行弱信号探测是当前研究的热点之一,该方法通过建立全自动化的弱信号探测模型,较大程度排除了主观方面的影响。在诸多方法中,利用文本挖掘技术进行弱信号探测受到越来越多的学者关注。Yoon[9]基于Web新闻中的关键词,利用文本挖掘方法构建了关键词画像图谱,从中识别出弱信号主题。主题模型方法是一种无监督的机器学习技术,其能够不受人为干预独立确定文本的研究主题。已有研究中,有学者使用LDA主题模型进行弱信号检测。Pépin等[10]基于推特数据,利用LDA方法动态抽取其中的主题,并通过主题演化的桑基图对弱信号进行探测。Gutsche[11]使用LDA模型对弱信号的生命周期进行跟踪。
1.2 颠覆性技术及识别方法
颠覆性技术早期识别的主要目的是对处于潜伏期的技术进行有效预判,尽早发现可能存在的颠覆性技术,并针对该类技术进行相应的政策支持、风险防范和市场应对等措施[12]。与颠覆性技术识别相关的概念包括突破性创新、新兴主题等,相关概念如表1所示。

表1 颠覆性技术相似概念对比
在突破性创新识别的研究中,早期以专家评议等定性分析方法为主,后期随着大规模数据分析工具及算法的出现,定量分析方法逐渐成为突破性创新研究的主要方法[13],在实际研究过程中,围绕突破性创新的特征、技术演化规律、产品效益与市场表现等开展相关识别研究。新兴主题识别方法主要以文本挖掘和科学计量分析方法为主,前者借助自然语言处理方法挖掘科学文献和专利文献中的话题、关键词或受控词等,后者通常借助网络分析方法对科技文献元数据进行分析[14]。总体来看,突破性创新识别侧重技术创新中的突破性,新兴主题识别侧重研究的新颖性,而颠覆性技术早期识别通常关注未来技术对现有技术与市场的颠覆性。
常用的颠覆性技术识别方法大体可以分为4类:专家评议法、文献或专利分析法、技术演化规律法和理论或数学模型法。其中,第1种偏向于定性研究,后3种偏向于定量研究。在研究的过程中,通常会结合不同类型方法,围绕颠覆性技术的替代性、破坏性、突变性、跨界性、前沿性等特征[15]进行预判和识别。
第1类,专家评议法。该方法主要包括德尔菲法、问卷调查法、技术路线图、情景分析法、技术定义法,是国家层面进行颠覆性技术识别常用的方法。如美国、日本、英国等国家建立了单独的研究部门对颠覆性技术的识别进行研究,通常以需求为导向、以专家为核心进行主观预判和识别。此类方法在研究过程中需要大量的人力、物力,且很大程度上依赖于专家的个人经验和主观判断,具有一定的局限性。Weissenberger-Eibl等[16]根据颠覆性创新过程,将技术路线图和指标预测相结合,构建了一种颠覆性创新项目的综合预判方法。
第2类,文献或专利分析法。该方法主要包括文献计量、专利计量、文本挖掘等定量分析方法。该类方法主要以文献或专利数据作为数据分析源,通过建立相应的指标、评判标准,从客观角度挖掘潜在的颠覆性技术。刘忠宝等[17]使用LDA-LSTM(latent Dirichlet allocation - long short term memory)文本分类算法,从论文和专利数据中抽取技术主题,构建主题共现网络并进行主题突变探测,以达到颠覆性技术识别的目的。王康等[18]基于专利引用方向的变化,构建了颠覆性技术识别方法。马荣康等[19]比较专利之间的相似度,从专利的新颖性、独特性和影响力3个方面进行测度,构建突破性技术发明的综合识别方案。本文使用专利计量和文本挖掘相结合的方法,对专利信息进行主题抽取、弱信号探测和技术颠覆性潜力测度,构建一种基于弱信号的颠覆性技术早期识别方案。
第3类,技术演化规律法。该方法包括TRIZ理论、技术生命周期、技术轨道、S曲线等方法。该类方法主要利用进化法则、生命周期和S曲线等,通过识别当前技术所处的发展阶段预判未来可能的发展趋势,以实现对颠覆性技术的识别。刘玉梅等[20]基于技术轨道跃迁和技术融合理论,对技术轨道中不同技术交叉融合形成的复杂关系网络进行分析,利用技术新颖度、差异度和融合度等特征判断技术轨道的跃迁及跃迁程度,构建了预测突破性技术的方法体系。
第4类,理论或数学模型法。该方法主要包括层次分析法、突变理论、技术颠覆性风险预测模型等。此类方法主要用于识别处于成长期的颠覆性技术,通过理论或数学模型进行颠覆性技术的未来预判。相较于其他方法,理论或数学模型法更容易操作、预测周期短,但需要对模型使用的数据进行高效获取和处理。侯广辉等[21]构建了颠覆性技术突变级数模型,并根据评估指标体系搜集专家评估数据进行颠覆性技术的识别和评估工作。Chen等[22]提出了一个基于机器学习的判别模型用于识别潜在的颠覆性技术。
上述研究为本文颠覆性技术的弱信号识别提供了借鉴和参考,但前期的研究依赖于具有丰富经验的专家的直观判断,服务成本较高,不同专家可能提供不同的判断结果。同时,包括论文和专利在内的科技大数据呈现爆炸式增长,几乎不可能完全依赖专家对颠覆性技术进行扫描和判断。现有针对颠覆性技术的弱信号识别研究尚比较缺乏,特别是基于技术信息的内在主题特征进行弱信号识别的研究仍需进一步深入。本文采用LDA主题模型方法对目标领域的弱信号进行探测,有助于从技术本质特征出发对早期颠覆性技术进行识别。
2 研究方法
本文基于专利的弱信号探测模型与技术颠覆性潜力测度体系相结合的方法,进行颠覆性技术早期识别。首先,对目标领域的专利信息进行弱信号探测,具体过程如下:利用LDA主题模型对领域的专利数据进行主题抽取,再利用弱函数过滤抽取到的主题,得到包含弱信号的主题集合,进一步利用预兆函数过滤弱信号主题涉及的术语,得到弱信号术语集合。其次,基于技术颠覆性潜力测度体系,对包含弱信号术语的专利进行颠覆性潜力测度,得到具有颠覆性技术潜力的技术,为目标领域的颠覆性技术早期识别提供参考。颠覆性技术早期识别技术路线如图1所示。
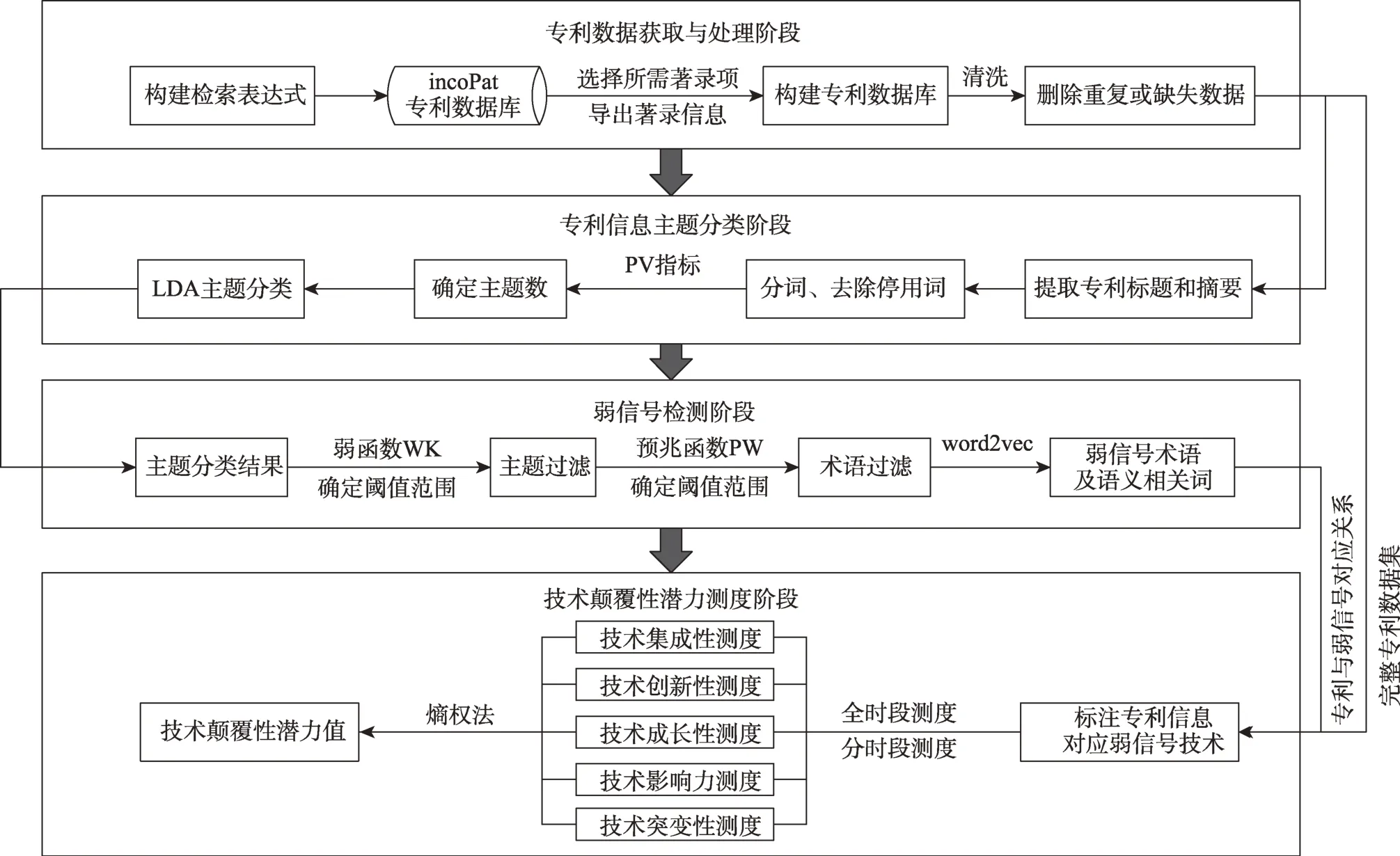
图1 颠覆性技术早期识别技术路线
2.1 LDA主题模型
LDA主题模型主要由数据预处理、模型训练和结果输出构成[23]。数据预处理部分主要通过去除噪声和无关数据、去除停用词等方式,对专利数据进行清洗和分词处理。LDA主题模型训练中的主要问题是主题数的确定,本文选用关鹏等[24]提出的PV(perplexity-var)指标,基于主题相似度和困惑度进行模型最优主题数的确定。模型的输入为经过预处理的专利文本数据,输出结果为专利信息的主题提取结果,如主题对应的词汇、专利与主题对应的概率等。下文将对模型训练中主题数确定PV指标进行详述。
(1)困惑度。困惑度是评估一个语言模型优劣的指标,困惑度越低,表示模型对文本的解释效果越好。通常随着主题数的增加,困惑度呈先递减后递增的趋势,常用于判断最优主题数的“手肘法”便是根据该趋势进行主题数的判断。在LDA主题模型中,困惑度的计算公式为
其中,D表示专利文献集,共计M篇专利文献;wd表示专利文献d中的词汇;p(wd)表示专利文献中wd产生的概率;Nd表示专利文献d中的单词数量。
(2)主题相似度。主题相似度是指模型得到的主题结果中,不同主题间的相似程度和辨识度。主题相似度越低,代表模型对主题的区分度越高。本文选取满足对称性和三角不等式的JS(Jensen-Shan‐non)散度作为主题相似度的度量方法[25]。为衡量主题空间的整体差异性,引入随机变量方差概念构建主题方差指标。主题方差越大,表示主题之间的差异性越大,区分度越高,主题的结构越稳定。主题方差以JS散度为基础,计算每个主题与其均值间距离平方和的平均数,计算公式为
其中,T表示LDA模型中的主题;K表示主题数量;DJS表示JS散度;表示主题-词概率分布ϕ的均值。
(3)PV指标。PV指标结合了困惑度和主题方差,当困惑度越小、主题方差越大时,PV值达到最小。此时,对应的主题数使LDA主题模型效果达到最优,计算公式为
其中,D表示专利文献集;Perplexity(D)表示数据集D的困惑度;Var(T)表示数据集的主题方差。
在进行LDA主题模型训练过程中,通过计算PV指标,选取该指标最小时对应的主题数作为最优主题数,以确保主题提取达到最优效果。
2.2 弱信号技术识别
弱信号通常是指强度较弱、不易被感知和接收、携带着预示未来发展可能性的有效信息,是一种未来趋势和系统不连续的迹象,未来可能产生较大变化和影响[9]。基于弱信号的概念与特征,本文考虑使用一种全自动弱信号探测方法进行弱信号识别[26]。一般来说,主题(topic)由不同的术语(term)概括而来。本文通过对包含弱信号的主题进行过滤,抽取出潜在的弱信号术语。弱信号探测过程如下:首先,通过弱函数过滤目标领域的专利信息主题集合,得到包含弱信号的主题集合;其次,利用预兆函数过滤弱信号主题下的术语,提取具有弱信号特征的术语集合;最后,利用word2vec模型分析弱信号术语的上下文,计算词向量间的余弦相似度并排序,得到与弱信号术语语义相关的单词列表。最终弱信号术语和语义相关词的集合为弱信号词汇集合,与弱信号词汇集合相关的专利为弱信号技术集合。
一方面,与依赖专家提取关键词进行的弱信号检测的研究[9]不同,本文采用的方法不需要人工专家干预即可自动探测全文文本中的微弱信号;另一方面,主题模型从文档中提取主题信息,考虑的不仅仅是单独的词汇或关键词,还有词汇与文档之间的语义信息。El Akrouchi等[26]认为,主题分类得到的结果中,每一主题下的术语强弱程度均取决于其所属主题的强弱,即弱信号主题中的术语词汇更可能成为弱信号。因此,在弱信号探测过程中,先进行弱信号主题过滤,再对过滤后主题下的术语词汇进行过滤,提取潜在的弱信号。
(1)主题过滤
本文使用由Logistic函数推导的一种弱函数(weakness,WK)进行主题过滤[26]。该函数由接近中心性、主题权重和自相关函数组成。S形曲线是识别技术生命周期阶段的一种经典模型,其中Lo‐gistic曲线可用于模拟语言的变化,如对边缘术语随时间变化的传播速度、范围增长或变化趋势进行模拟,经研究适用于快速、明显增长的技术生命周期预测[27]。Logistic函数中的较低值可代表主题以及术语的稀有性,通过研究这些较低值能够实现技术生命周期发展阶段前期的微弱信号检测,即对未来可能快速发展的技术实现早期信号检测。下文将对弱函数WK包含的3项度量指标进行详述。
第1个度量指标是接近中心性,指的是一个主题与其他主题之间的距离,通过两个主题间的距离描述主题之间的相似性。基于一个距离测量必须呈现一个基于S形的变化这一原理[10],使用海林格距离(Hellinger distance)进行主题距离的测量,该指标在概率和统计学中用于衡量两个概率分布之间的相似性,计算公式为
其中,d为海林格距离;t为主题。
第2个度量指标是主题权重,指基于连贯性表达的主题t在所有主题中的重要性程度,计算公式为
其中,Coh(t)为主题t的连贯性。
第3个度量指标是“自相关性”指标,指同一变量在不同时间段观测值之间的关系,是一种趋势分析。自相关指时间序列和自身滞后的版本线性相关,本文对主题相关的专利频率随时间的变化进行自相关分析,目的是评估一段时间后该主题在专利频率方面的变化情况。该指标用于过滤掉不包含弱信号的主题,计算公式为
其中,Cov(t)k为主题t在滞后时间k处的协方差。
综合以上3个指标,定义主题t的弱函数公式为
在弱信号的定义中,稀有性、隐匿性和不确定性等是弱信号的主要特征。因此,主题对应的弱函数WK数值越低,表现出的信号就越弱,此类具有低函数值的主题可以被认为是具有弱信号特征的主题。为减少噪声影响,过滤出信号强度较弱的主题,将WK函数计算数值在区间[1%,10%]的主题视为包含弱信号的主题[26]。
(2)术语过滤
通过主题过滤提取包含弱信号的主题,但每个主题内包含的术语较多且不一定全部具有弱信号特征。同时,主题中术语的概率和出现频率并不相同,不能保证与主题最相关的术语具有相应的弱信号。因此,在进行主题过滤后需再进行术语过滤,从中提取包含弱信号的术语集合。在术语过滤部分,仍以Logistic函数为理论基础,通过术语及其对应主题的概率和频率,建立与术语相关的预兆函数PW[26],计算公式为
其中,w为术语;NF(w)为对应主题中的术语w的归一化频率;ϕ(w)为从LDA模型获得相应主题中的术语w的概率。基于弱信号特征,在术语过滤部分,提取PW函数值处于区间[1%,10%]的术语作为具备弱信号特征的术语集合[26]。
(3)结果输出
在进行主题过滤和术语过滤后,得到弱信号术语集合,通过对弱信号术语进行上下文分析得到术语语义相关词集合。使用基于神经网络的word2vec[26]模型分析术语语义相关词,该模型通过将数据集中的单词表示为向量,捕捉单词的上下文并进行重构,使语料库中共享相同上下文的词汇在语义空间中更加接近,最终获取与弱信号术语语义相关的单词集合。
2.3 技术颠覆性潜力测度体系
以往研究中,李乾瑞等[28]基于专利视角,从技术的融合性、新颖性、扩张性和影响力4个维度,运用熵权法和模糊一致性矩阵方法,构建了一套系统的颠覆性技术识别模型,并通过在5个技术领域开展的实证研究,验证了模型的可行性以及各技术颠覆性潜力指数的有效性和适用性。本文参考李乾瑞等[28]提出的四维技术颠覆性潜力测度指标体系,增加技术突变性特征维度形成五维颠覆性潜力测度指标体系,对包含弱信号术语的专利集合进行颠覆性潜力测度,探测其中具有颠覆性潜力的技术,以实现颠覆性技术的早期识别。技术颠覆性潜力测度指标体系由5个维度构成,每一个维度代表一个颠覆性技术特征,分别为技术集成性、技术创新性、技术成长性、技术影响力和技术突变性。通过综合分析技术的颠覆性潜力测度值,评估某类技术所具有的颠覆性程度。颠覆性技术测度模型的指标计算公式具体阐述如下。
(1)技术集成性测度[28]。技术集成性是指数根据多样性、差异性和均匀度3个维度进行加权拟合,测度技术领域多样性和领域内知识信息交叉融合与集成程度。
不同技术类别的平均数目(average number,AN):通过专利中包含的技术类别数量,衡量技术多样性程度。多样性程度越高,表明技术涉及的理论基础与学科越丰富,集成性越高。
其中,n为专利中对应的技术类别平均数目;N为领域专利数量。
不同技术的平均距离(average distance,AD):通过测度不同技术类别性质的差异程度,衡量技术领域的差异程度。技术领域内不同技术的差异程度越高,表明该领域涉及的研究方向越丰富,集成性越高。
其中,n为技术类别的数目;Sij为类别i和j的相似度。
技术类别分布的均衡度:用“1-基尼系数(Gini coefficient,GC)”进行计算,对技术分布的均匀程度进行有效测度。基尼系数计算公式为
其中,xi为属于第i个技术类别的专利数量;技术类别的排序依据xi的数值从小到大排列;i为此序列的序列号。
(2)技术创新性测度[28]。技术创新性指数根据技术独创性、原创性和科学关联度3个维度进行综合加权拟合,测度技术的创新性。
技术独创性(distinctive level,DL):反映专利依赖本领域技术的程度。DL值越大,表示该技术依赖本领域技术进行创新的程度越高,越可能拥有相对独立的技术发展理论体系。
其中,N为该领域专利数量;CPi(cited patent col‐lection)为专利i后向引用文献集合;P(patent col‐lection)为该领域的专利集合。
技术原创性(originality level,OL):反映专利包含未出现的分类号数目。OL值越大,表示在一定时间内出现的该类技术包含之前未出现过的分类号数量越多,即该技术的原创程度越高,创新性越高。
其中,N为该领域的专利数量;IPCAi为专利i的分类号组合的集合;IPCBi为在专利i申请年份之前出现的分类号组合的集合。
科学关联度(scientific relevance,SR):反映领域内专利引用科技文献的数量。该指标用于衡量专利技术和基础科学研究的关系强弱和影响强度[29],有研究表明,基础知识对技术创新具有广泛影响且是颠覆性技术的重要来源[30]。SR值越大,表示该专利引用科技文献的数量越多,与基础知识和基础研究的关联性越强,越有可能成为颠覆性技术。
其中,N为该领域专利数量;Pi为专利i引用的科学文献的数量。
(3)技术成长性测度[28]。技术成长性指数根据技术生长率、技术扩张性和技术覆盖比率3个维度进行加权拟合。
技术生长率(growth rate,GR):反映技术随时间变化的专利申请数量的增长程度。GR值越大,表示技术成长性越强。
其中,Y为测度时间长度(单位:年);Ni和Nj分别为第i年和第j年的专利申请数量。
技术扩张性(expansionary rate,ER):反映技术随时间变化的专利申请对应分类号的数量。ER值越大,表示技术跨领域的扩张性越强,成长性越强。
其中,Y为测度时间长度(单位:年);IPCi和IPCi-1分别为第i年和第i-1年专利申请对应的分类号数量,i=(1,2,…,Y)。
技术覆盖比率(coverage ratio,CR):反映专利涉及的技术类别。CR值越大,表示该专利涉及技术的类别越多,适应性越强,成长性越强。
其中,N为该领域专利数量,IPCi为专利i对应的分类号数量。
(4)技术影响力测度[28]。技术影响力指数根据即时影响、平均后向引文率和前向引用分布类别3个维度进行加权拟合。
即时影响指数(current impact index,CII):反映近5年内专利对技术创新的影响程度。CII值越大,表示该专利对技术创新的影响程度越高,当前阶段的影响力越强,表明该专利具有一定的颠覆性。
其中,Y为测度时间段(单位:年);Ni和Nj分别为第i年和第j年专利的申请量;NCij为第j年专利引用第i年专利的数量;NCj为第j年以前的专利被本领域专利引用的数量;SNj为第j年以前专利的数量。
平均前向引文率(average citing rate,ACR):该指标表示在相应领域内专利被后续专利引用的程度。ACR值越大,表示专利对技术的影响力越大。
其中,N为该领域专利数量;NCi为专利i被后续专利引用的数量。
前向引用分布类别(citing distribution category,CDC):也称前向引用专利类别数,反映一类技术对于其他类别技术的影响程度。CDC值越大,表示该类技术对其他类别的技术影响程度越高,跨领域影响力越大。
其中,Num(citing)为前向引用专利的类别数量。
(5)技术突变性测度[29-31]。技术突变性指数根据技术突变可能性、新技术类别频次突变率、重复技术类别频次突变率3个维度进行加权拟合。技术突变性越大,成为颠覆性技术的潜力越大。
技术突变可能性(mutation possibility,MP)[31]:该指标结合词突发检测算法[32]和基于重复关键词的主题突变程度[30],测度弱信号术语对应技术类别的突变可能性。MP值越大,表示该类技术术语频次突变程度越大;技术突变性越高,越具有成为颠覆性技术的潜力。
其中,t为弱信号术语;TFt代表弱信号术语t在某一时段内出现的频次;代表弱信号术语t在研究区间内出现频次的平均值;TFSt代表弱信号术语t在研究区间内出现频次的标准差。
新技术类别频次突变率(new frequency muta‐tion rate,NM)[30]:反映测度时间段内,一类技术中新出现的技术类别突变程度。新技术类别频次突变率越高,表明技术涉及的新学科和新分类越多,技术突变性越高。
其中,Y为测度时间段(单位:年);IPCi和IPCi-1分别为第i年和第i-1年专利申请对应的分类号种类,i=(1,2,…,Y);IF代表相应分类号出现的频次。
重复技术类别频次突变率(repeat frequency mu‐tation Rate,RM)[30]:反映测度时间段内,一类技术中重复出现的技术类别突变程度。重复技术类别频次突变率越高,表明该类技术在相同学科与分类的研究中变化程度越大,技术突变性越高。
其中,Y为测度时间段(单位:年);IPCi和IPCi-1分别为第i年和第i-1年专利申请对应的分类号种类,i=(1,2,…,Y);IF代表相应分类号出现的频次。
3 实证研究
3.1 数据获取与清洗
本文以基因编辑领域的专利作为研究样本,专利检索数据库为incoPat专利数据库。基因编辑技术已成为生命科学领域重要的颠覆性技术之一,为生物学研究、医学治疗领域带来了革命性的变化。该技术通过定点修饰或修改基因组及其转录产物实现高效、精确的基因工程,在基因治疗、核酸诊断和建立细胞、动物疾病模型方面具有极其重要的价值。CRISPR/Cas9技术的出现更是引起了广泛关注,甚至曾两次荣登Science“年度十大科学突破”[33]。为了获得基因编辑领域技术的专利文献,通过查阅文献、阅读相关研究报告、时事新闻等对基因编辑领域进行技术分解,构建基因编辑领域的专利检索式。具体而言,根据基因编辑领域技术所涉及的代表性技术及其特征词汇,以及基因编辑领域技术所涉及的其他相关词汇,构建专利数据库检索表达式:
(TIABC=(“gene edit*” OR “genome edit*” OR“ZFN” OR “zinc finger nucleases” OR “TALEN” OR“transcription activator like effector nucleases” OR “CRIS‐PR” OR “clustered regularly interspaced short palindromic repeats” OR “Cas9”) OR DES=(“gene edit*” OR “ge‐nome edit*” OR “ZFN” OR “zinc finger nucleases” OR“TALEN” OR “transcription activator like effector nucleas‐es” OR “CRISPR” OR “clustered regularly interspaced short palindromic repeats” OR “Cas9”)OR TIABC=(“gene targeting” OR “gene knock in” OR “gene re‐pair” OR “targeted gene repair” OR“gene therapy” OR“Synthetic genomics” OR “human genome project”) OR(TIABC=(“gene” OR “genome”) AND TIABC=(“Syn‐thia” OR “CAGE” OR “CAR-T” OR “YOGE” OR“Yeast oligo-mediated genome engineering”OR “Chimeric Antigen Receptor T-Cell Immunotherapy” OR “CERES”OR “CROP-seq")))
在构建检索表达式的过程中,使用了专利TIA‐BC(标题title、摘要abstract、权利要求claims)及专利DES(说明书description)两种方式进行了检索。其中,对于“gene edit”“ZFN”“CRISPR”等基因编辑领域的核心词汇,为了提高专利查全率,同时采用TIABC及DES两种方式对专利进行了检索。此外,为了提高专利查准率,对于“gene tar‐geting”“CAGE”等频繁出现在其他领域的关键词或非基因编辑领域专有的词汇,仅通过TIABC对专利进行数据检索。检索时间为2020年1月23日,初步的数据检索结果为,1988—2019年共获得基因编辑领域专利78338件。检索到的专利数据内容包括标题、摘要、说明书、申请时间、专利引文和非专利引文等。为了使各年专利数据的数量满足主题抽取、主题过滤的效果以及技术颠覆性潜力指标计算的要求,本文选取2008—2019年的专利数据作为研究数据样本集合,专利的年代分布情况如图2所示。专利数据的预处理主要分为数据清洗和文本处理两个部分:删除重复、摘要缺失和非英文语言的专利信息后,获得共计35687件专利的信息;通过分词(tokenization)、大写字母转换为小写、去除停用词等处理,将上述专利信息中的题目和摘要处理为由单词组成的文本信息,便于后续研究使用。
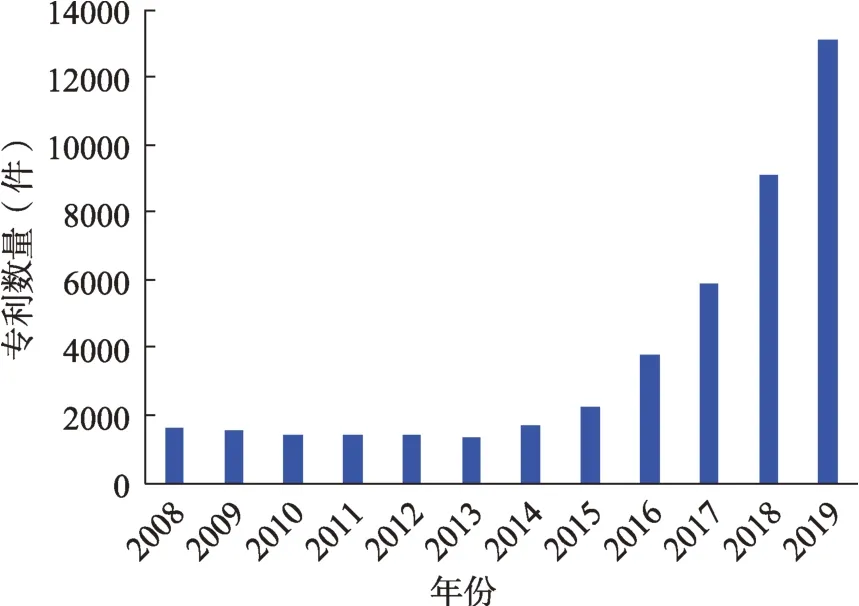
图2 专利数据的年份分布
3.2 专利数据的弱信号分析
3.2.1 LDA主题抽取
对LDA主题模型进行训练,寻找最优主题数用于专利数据的主题抽取。从经过预处理的专利数据中随机抽取25000条文本信息作为训练集,获取54385个单词建立词典并计算文本向量。主题数的取值范围设置为[1,50],以步长为1进行LDA主题抽取,分别计算不同主题数下的困惑度、主题方差和PV值。综合考虑3种指标结果以及后续的主题过滤,确定30作为LDA主题模型中的主题数量。在该数量的主题下,最重要的PV指标处于较低值,困惑度趋于最低,主题方差处于较大值。根据确定的主题数,对专利数据进行逐年主题抽取。以2019年专利数据主题抽取为例,选择该年份对应的专利数据作为模型的输入信息,2019年预处理后的专利信息共计11983条。基于该年的专利信息计算文本向量,再通过开源Python库gensim中的LDA模型方法进行主题建模。其中,主题数设置为30个,每个主题下获取100个术语(term)。
3.2.2 专利数据的主题过滤
通过专利所属主题的概率和主题词频率进行相关指标计算,以年为单位使用弱函数WK进行主题过滤。第1个指标贴近中心性CC主要通过海林格距离计算主题t与其他主题间的距离,基于LDA主题模型中获得的主题-词概率分布,分别计算一个主题和其他主题间的距离,得到每一个主题对应的接近中心性。第2个指标主题权重W基于LDA主题模型中得到主题所具有的连贯性进行计算,该指标使用gensim中计算连贯性的方法。根据得到的每个主题的连贯性和总体主题的连贯性确定所计算主题的权重,得到每个主题对应的主题权重。第3个指标是自相关函数AC,该函数描述了一个变量在不同时间段观测值的变化。在本文中,每个主题对应的文档频率,即主题对应的专利频率随着时间不断变化,选用每个主题在不同月份的专利频率进行自相关函数的计算。将每一年的专利数据按月进行自相关计算,滞后时间选择6个月。
在对以上3个指标进行计算后,结合3个指标的结果进行弱函数WK(t)的计算。在El Akrouchi等[26]提出的弱信号识别模型中,阈值为区间[1%,10%]的信号构成弱信号函数值范围。以1%作为下限的原因是在该函数值以下的信号未来可能成为弱信号,但是包含了较多噪声,出现有意义的词汇的概率较小。以10%作为上限的原因是该阈值内获得的函数值较低,且能够获取到有意义的弱信号集合。本文结合专利主题计算得到的弱函数结果以及对比不同阈值主题过滤结果,最后选择弱函数结果在阈值区间[5%,10%]的主题作为该年包含弱信号的主题。由于噪声通常在0%~5%变化[26],提高上限至5%是为了过滤掉更多噪声。
通过弱信号阈值对每年的主题函数值进行筛选,得到逐年的弱信号主题。以2008年专利数据的主题过滤结果为例,展示弱信号主题的筛选结果。由图3可以看出,在2008年的30个主题中,有1个主题在弱信号的阈值内,即T21,该主题的弱函数WK值高于5%且低于10%。

图3 2008年专利数据的主题过滤结果
通过弱信号探测模型对2008—2018年的专利信息进行弱信号探测,得到每一年的弱信号主题分别为T21(2008年)、T21(2009年)、T8(2010年)、T11(2011年)、T18(2012年)、T25(2013年)、T7(2014年)、T29(2015年)、T26(2016年)、T18(2017年)、T1(2018年),共计11个弱信号主题。
3.2.3 专利数据的术语过滤
针对从2008—2018年共计330个主题过滤得到的11个包含弱信号的主题,对每一个主题下的100个术语进行弱信号筛选,得到每年的弱信号术语。该部分的输入为术语、术语频率,分别对每一个主题下的每一个术语进行预兆函数PW的计算,根据LDA模型得到的术语概率,计算术语在对应主题中的归一化频率,得到该术语的预兆函数值。其中,对于术语在主题中的归一化频率的计算,需要统计该主题下的专利数据总量和主题中术语的文档频率。参考3.2.2节中的主题过滤方法,本节的术语过滤同样需要进行弱信号阈值调整。由于潜在警告函数PW值均较小,[1%,10%]这一阈值无法过滤出弱信号术语,直至将上限提升至30%时,2008—2018年每一年均可获得弱信号术语。
通过开源Python库gensim中的word2vec模型对术语过滤结果进行处理,针对弱信号术语对应的主题内相关专利进行语义分析,最后输出与该弱信号术语语义相关的30个单词形成语义相关词集。通过该词集对弱信号术语及弱信号主题进行解释,在后续研究中用于形成弱信号术语对应的专利集。实践证明,使用word2vec模型获取语义相关词可以丰富探测到的弱信号含义,并能探测到随时间变强的新的弱信号[26]。
3.3 基于弱信号的技术颠覆性潜力测度
3.3.1 专利数据弱信号选取
由于弱信号术语结果中存在干扰词汇,即术语对应的语义相关词集中存在无意义词汇或术语含义过于宽泛,无法对术语进行合理解释。因此,本文结合每一个弱信号术语对应的语义相关词集,人工剔除无意义或无关词汇,选择符合基因编辑领域技术特征的弱信号术语。最后,选择出2008—2018年的35个弱信号术语,如表2所示,测度结果中若出现相同术语,则优先考虑该术语最先出现的年份用以后续的相关测度。
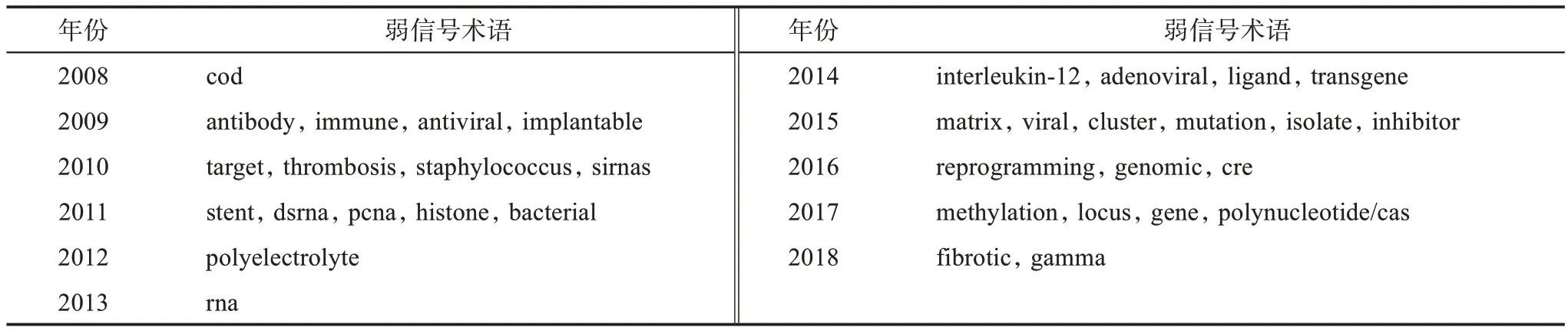
表2 2008—2018年术语过滤结果(5%~30%的百分位数)
3.3.2 技术颠覆性潜力测度
以筛选出的弱信号术语为基础,将每个术语及其对应的30个语义相关的词汇看作该弱信号术语集合,针对每一个术语及语义相关词建立起来的词汇集合,检索该词汇集合对应的专利,构建每个弱信号术语对应的专利集合。本节基于该专利数据集合,进行技术颠覆性潜力测度指标体系计算,评估包含弱信号的技术所具备的颠覆性潜力。
以2017年的4个弱信号术语及语义相关词所构成的词汇集为例,如表3所示。从专利数据库中检索所有包含这些词汇的专利信息,并根据4个弱信号术语分别建立4个技术类别专利集。基于专利信息,分别计算这4个弱信号技术类别在3年中的技术集成性、创新性、成长性、影响力和突变性指标数值,计算结果如表4所示。

表3 弱信号术语与语义相关词(2017年)
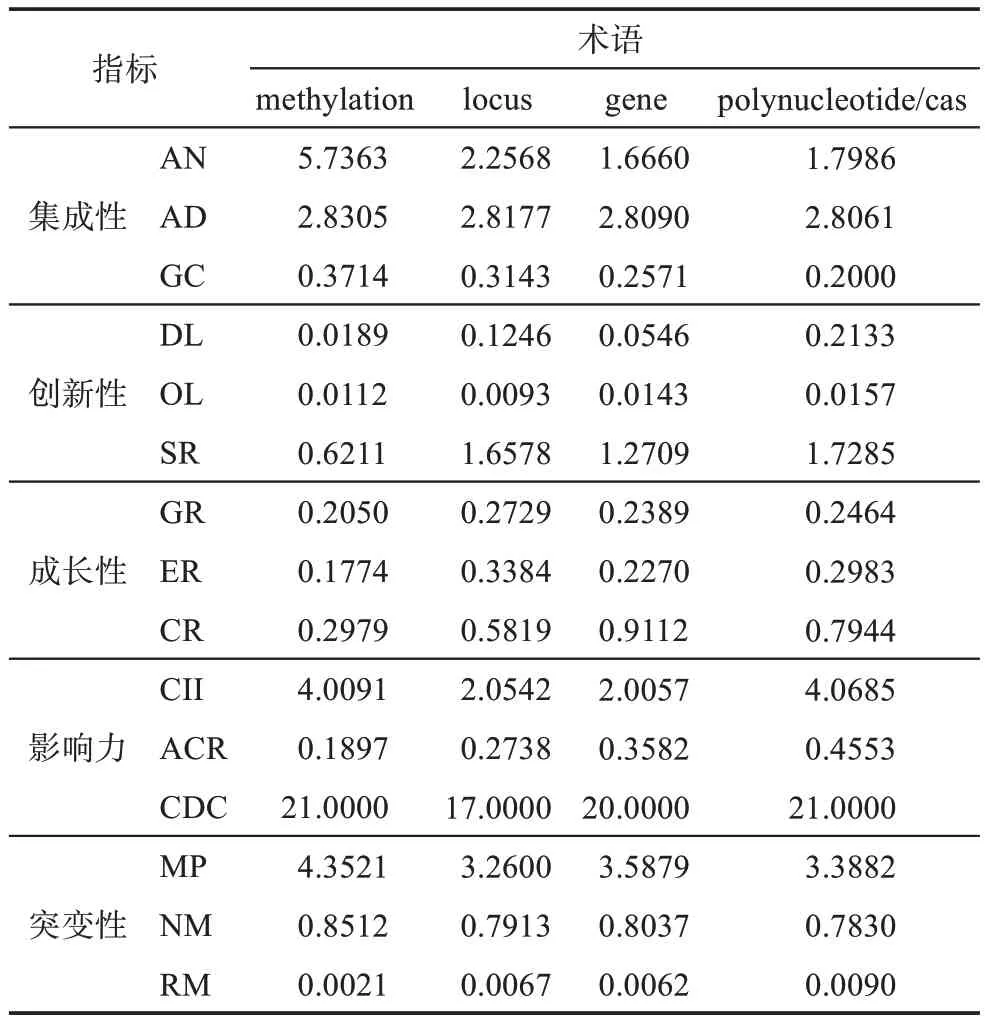
表4 4项弱信号技术颠覆性潜力指数(2017年)
基于以上指标结果,利用熵权法计算颠覆性潜力测度指标。首先,通过极差标准化方法对获得的指标结果进行标准化处理,消除变量量纲和变异范围影响。其次,计算每个维度每个指标的比重、信息熵和权重。最后,通过加权求和得到颠覆性潜力测度综合结果,即颠覆性潜力测度指标值,测度结果按照从高到低排序,如表5所示。
按照技术颠覆性潜力测度值对识别出的弱信号术语进行排序,为颠覆性技术的早期识别提供参考。2008—2018年的35个弱信号术语及对应的技术颠覆性潜力测度值如表6所示。
3.3.3 弱信号技术潜力测度结果
本文基于颠覆性潜力测度值对所识别的弱信号进行排序。对技术弱信号进行全时段的颠覆性潜力测度,得到每项技术弱信号在2008—2019年的不同时期、不同维度的颠覆性潜力测度值。为进一步获得有效的颠覆性测度指标数值和潜力测度值,保证每个时段每个指标均可得到有效且连续的结果,进一步采用3年为一个周期进行分时段的指标测度,分析弱信号颠覆性潜力数值在12年内4个阶段的变化。
以2017年测度结果为例,该年弱信号术语对应的颠覆性潜力测度结果如图4所示。其中展现了包含技术弱信号在5个维度的测度结果,以及加权后的整体颠覆性潜力测度值。从整体来看,methyla‐tion和polynucleotide/cas潜力测度值较高,methyla‐tion的5个维度的表现为集成性和突变性突出、创新性和成长性较差,polynucleotide/cas在5个维度特征上均表现较好;locus潜力测度值最低,但其成长性远远大于其他弱信号技术。从分析结果来看,各方面表现均衡的polynucleotide/cas具有较高的颠覆性潜力,locus的高成长性则表示该技术在专利申请数量、对应分类号数量和涉及技术类别3个方面均处于较高水平,未来具有一定颠覆性潜力。
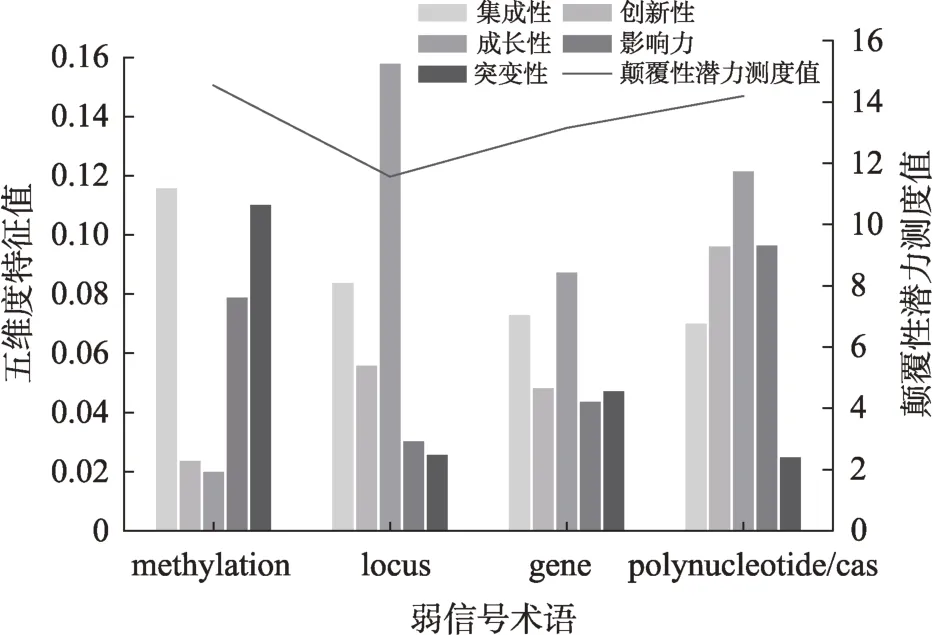
图4 2017年弱信号技术颠覆性潜力测度
3.4 弱信号结果对比
基于文本挖掘的弱信号识别方法还包括三维模型方法,该方法是Yoon[9]基于信号的三维模型理论[34]提出的一种弱信号主题扫描方法。该方法利用关键词的出现信息(occurrence information)与时间加权分析,生成关键字涌现图和关键字分配图两种关键词画像图谱,在此基础上识别和分析弱信号主题。该过程由4个步骤组成:①数据采集;②定义领域相关关键词;③利用关键词信息构建时间加权的关键词画像图谱;④通过统计分析以及相关信息搜索识别出弱信号主题。
为进一步验证本文弱信号识别方法的有效性,本文参照Yoon[9]的弱信号识别框架进行了基于专利挖掘的弱信号识别工作,并将识别结果与本文弱信号识别结果进行对比,用于验证弱信号探测结果的有效性。具体过程如下:
(1)获取关键词。基于3.2.1节中LDA主题抽取结果,将历年获取的主题词集合进行汇总和去重,将该主题词集合作为下一步分析的数据集。
(2)构建关键词涌现图。利用关键词的出现频率衡量弱信号主题的可见程度,关键词的出现频率越高,表示相关弱信号主题的可见度越高。关键词i在周期j中的可见程度(degree of visibility,DOV)计算公式为
其中,TFij是关键词i在周期j中出现的总频率;Nj是周期j中专利的总数量;n是周期数;tw是时间权重,设定为0.05[9]。
逐年计算关键词的DOV指标和时间加权增长率(几何平均值),部分计算结果如表7所示。
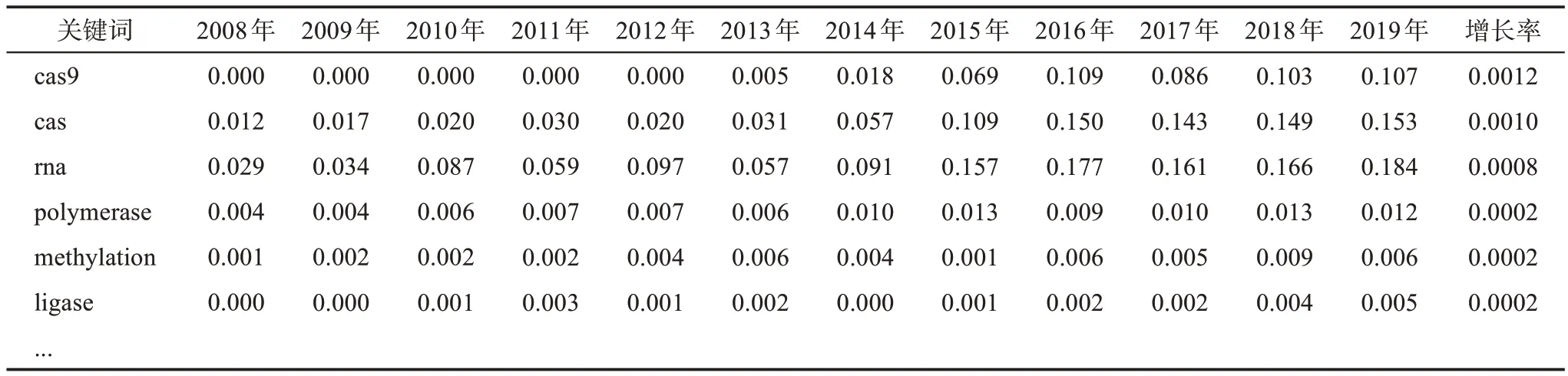
表7 关键词DOV指标及增长率
(3)构建关键词分配图。利用关键词的文档频率衡量弱信号主题的扩散程度,关键词的文档频率越高,表明该词在文本信息集合中的一般性程度越高,即相关弱信号主题扩散程度越高。关键词i在周期j中的扩散程度(degree of diffusion,DOD)计算公式为
其中,DFij是关键词i在周期j中的文档频率;Nj是周期j中专利总数量;n是周期数;tw是时间权重,设定为0.05。
逐年计算关键词的DOD指标和时间加权增长率(几何平均值),部分计算结果如表8所示。

表8 关键词DOD指标及增长率
(4)弱信号关键词识别。未来信号的主题通常扩散程度低且伴随异常模式[34]。从定量分析角度看,弱信号关键词具有出现频率较低但波动幅度较大的特点,因此,可通过相关关键词指标的时间加权增长率和关键词平均词条(文档)频率进行弱信号的识别[9]。对关键词涌现和分配的测度结果进行分析,分别取符合弱信号关键词特征的词汇集合,即DOV和DOD指标结果时间加权增长率的前30%且低于平均绝对词条(文档)频率的关键词为弱信号关键词[9],两个集合的交集词汇是最终的弱信号关键词识别结果,共计有1182个词汇。
(5)结果对比。将上述得到的弱信号关键词集合与本文弱信号术语及语义相关词集进行对比。去除噪声后对比发现,两个弱信号词汇集合的语义重复词汇为311个,本文弱信号术语集合包含545个词汇,与弱信号关键词集合重复率为57.06%。对比结果可分为形同词汇、意同形异词汇以及形异意异词汇3类,部分词汇如表9所示。
两种弱信号识别方法得到的词汇大致可分属“疾病类型”“应用领域”“技术要点”3个领域。共同弱信号词汇代表了现在具有一定发展潜力和发展前景的技术,其中包括已验证为颠覆性技术的CRISPR/Cas9。非重复词汇部分是两种方法得到的弱信号识别结果中具有差异的词汇,该部分分为两种情况:一是词形相近或语义相关词汇,如adeno‐virus(腺病毒)和adenosine(腺苷,腺甘酸),两个词汇具有相似的语义;二是词形和词意完全不相同的词汇。两种弱信号探测结果重复率达到了一半以上,证明本文的弱信号探测方法具有一定的合理性和有效性。探测结果的差异部分,是由于两种方法原理不同而造成的识别结果的差异。
3.5 识别结果验证
经过对基因编辑领域的科学文献、新闻报道等内容的研读,最终选择规律成簇间隔的短回文重复相关蛋白技术(CRISPR/Cas9)作为颠覆性技术,用于验证基于弱信号的颠覆性技术早期识别方法和结果的有效性。CRISPR/Cas9技术是一种基因编辑技术,源于细菌和古细菌的适应性免疫系统,2012年首次成功应用于大肠杆菌的基因组编辑,2017年左右已经出现了针对遗传病、感染病的临床试验[35]。该系统从被发现到发展成为目前精准、多功能的基因编辑工具仅10年左右时间,虽未完成临床应用,但该技术为新一代基因疗法奠定了基础[36]。结合搜集到的相关新闻报道以及CRISPR/Cas9技术相关研究文献,认为以CRISPR技术为代表的基因组编辑技术已经成为生命科学研究领域的颠覆性技术之一。
(1)弱信号探测模型结果
在弱信号探测模型的主题抽取结果中,存在与CRISPR/Cas9技术相关的单词crispr和cas,两个相关单词分别在2010年和2014年出现,而CRISPR/Cas9技术的全称则直至2016年才出现。在弱信号主题结果中还发现,2017年的弱信号主题T18中出现与CRISPR/Cas9技术相关的单词rna/cas,且该单词仅在这一个主题中出现,表明该年弱信号主题识别结果具有一定实际意义。2017年的主题抽取可视化结果如图5所示。
2016年和2017年,在弱信号术语的语义相关词集中出现了与CRISPR/Cas9技术相关的单词,具体的弱信号术语及语义相关词如表10所示。由表10可知,弱信号探测模型得到的弱信号术语结果和语义相关词集中,存在与CRISPR/Cas9技术相关的弱信号术语,弱信号识别结果具有一定实际意义。
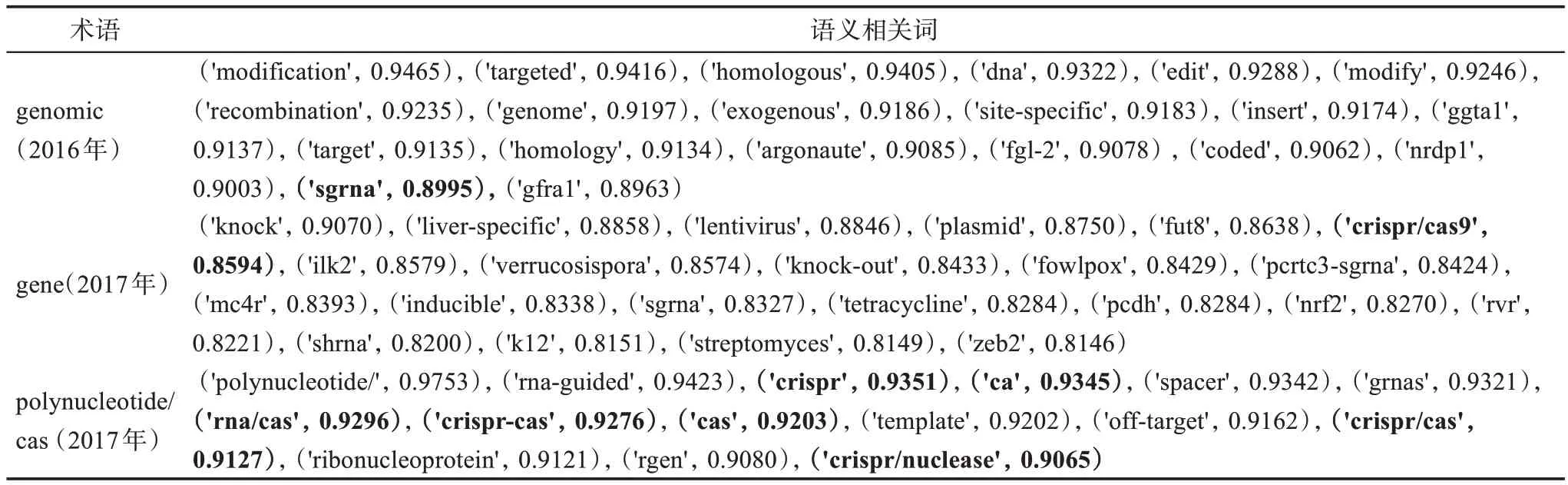
表10 弱信号术语与语义相关单词(含CRISPR/Cas9技术)
通过对比弱信号探测模型各阶段的筛选结果,发现与CRISPR/Cas9技术相关的术语在各个阶段均有不同程度的体现,弱信号术语及语义相关词集作为本文的一项重要研究结果包含了与该技术相关的明确信息。弱信号探测模型得到的弱信号术语中,在2010年、2014年和2016年探测到CRISPR/Cas9技术存在的弱信号,2017年探测到CRISPR/Cas9技术全称的出现。
(2)技术颠覆性潜力测度
根据弱信号探测模型的验证结果,本文选择2017年弱信号术语polynucleotide/cas和gene的技术颠覆性潜力测度结果进行颠覆性潜力验证。2017年弱信号的颠覆性潜力测度结果见图4,两个弱信号术语各时段测度结果分别如图6和图7所示。
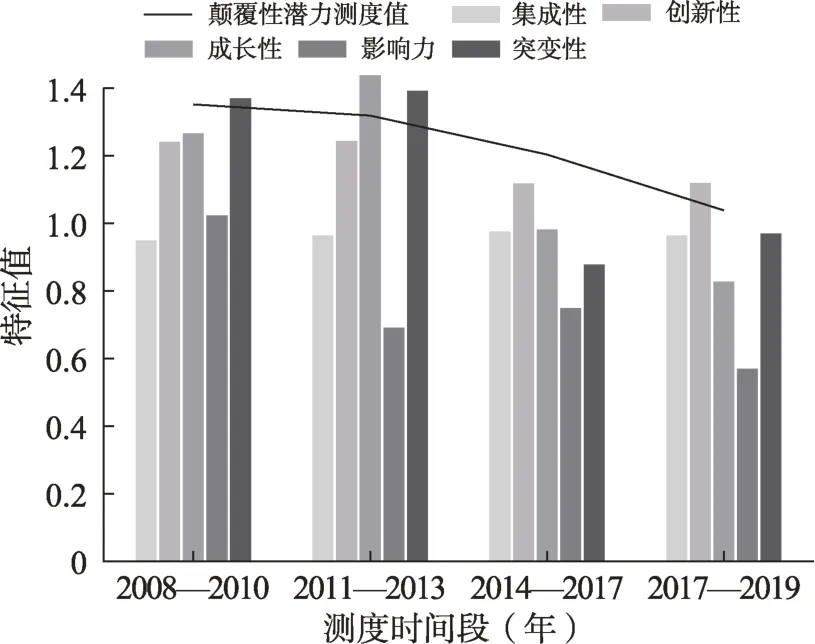
图6 gene各时段的颠覆性潜力测度
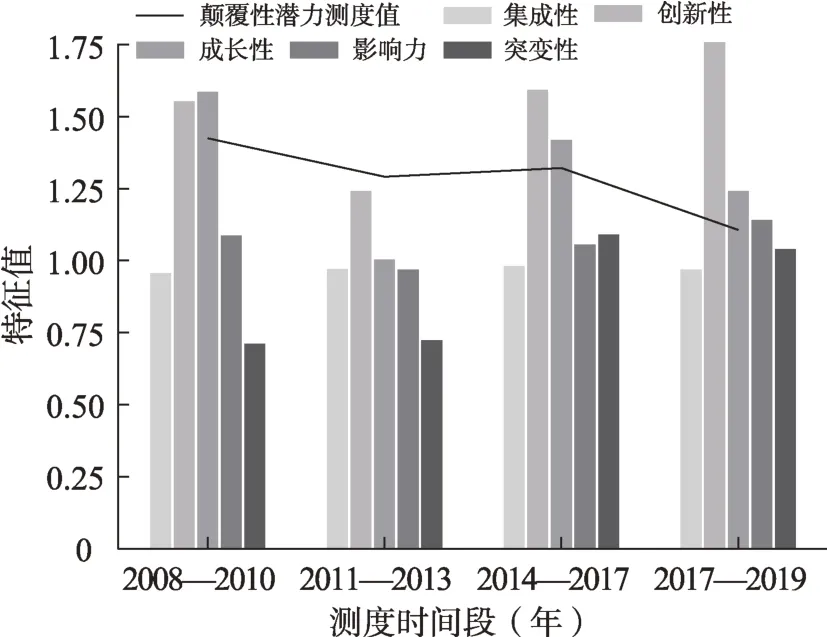
图7 polynucleotide/cas各时段的颠覆性潜力测度
从图4可以看出,2017年弱信号技术颠覆性潜力测度对比中,polynucleotide/cas相关技术在该年识别的弱信号术语中呈现了较高的颠覆性潜力值,在5个特征维度中均有较好表现。从图6和图7的分析结果可以看出,弱信号术语polynucleotide/cas和gene的颠覆性潜力测度值在2017年之前相对较高且均在2017达到最低值,因此,2017年识别得到的CRISPR/Cas9技术相关弱信号在该年之前体现出相对较高的颠覆性潜力,并于2017—2019年逐渐成为该领域中较为成熟的技术。
CRISPR/Cas9技术于2012年宣布正式成功实现,2017年基本进入临床试验阶段,主要被用于遗传病、传染性病毒等研究。案例分析证明,通过弱信号探测模型和颠覆性潜力测度体系相结合,可以实现对颠覆性技术CRISPR/Cas9的早期识别。因此,弱信号探测模型和颠覆性潜力测度体系相结合的颠覆性技术早期识别方法,通过弱信号探测模型筛选弱信号术语,为颠覆性技术的早期识别提供了丰富的信号基础。颠覆性潜力测度指标体系实现了对同一时期不同弱信号的颠覆性潜力测度对比,以及对同一技术不同时段的颠覆性潜力的对比,从多维视角对弱信号探测结果的颠覆性进行验证和修正。经实例验证,本文所使用的基于弱信号的颠覆性技术早期识别方法具有可行性和有效性。
4 总 结
本文基于领域专利信息,提出了一种基于弱信号探测模型和技术颠覆性潜力测度指标体系相结合的方法,用于实现对领域颠覆性技术进行早期识别。首先,使用弱信号探测模型对专利数据依次进行LDA主题建模、弱信号主题过滤以及弱信号术语过滤,得到弱信号术语及包含弱信号术语的专利集合。其次,根据技术颠覆性潜力测度指标体系,计算得到弱信号的颠覆性潜力测度值,并对5个维度和不同时段弱信号的颠覆性潜力进行相关测度和分析。最后,结合不同方法结果对比和文献调研进行实证研究,以验证该颠覆性技术早期识别方法的可行性和有效性,研究结果为颠覆性技术的早期识别提供了一种新的思路和方案。
本文针对颠覆性技术早期识别方法的研究存在一定不足。首先,该方法未涉及技术的应用情况,在后续研究中应考虑加入市场中的相关信息,为技术的应用测度提供支撑。其次,由于不同国家针对专利引用的要求不同,部分专利引用的参考专利或参考文献并未标明,因此,造成与引用相关的专利信息出现残缺、无法补全,会对相关指标的计算产生影响。最后,在研究结果验证部分,目前仅确认一个颠覆性技术,后续应扩大验证范围以提升方法的适用性和准确度。本文的颠覆性技术早期识别仅分析了基因编辑领域,未来还将继续对其他领域如工程技术领域等进行更广泛的研究和分析。
