基于机器学习的生物质热解三态产物产率提升研究
2024-01-03李明月陈虎生肖运昌
易 植, 季 玲, 李明月, 陈虎生, 肖运昌
(1.湖北孝感美珈职业学院 智能制造学院,湖北 孝感 432000; 2.湖南文理学院 计算机与电气工程学院,湖南 常德 415000; 3.新疆第二医学院 生物医学工程学院,新疆 克拉玛依 834000)
为了应对能源供应紧张和化石燃料引起的环境问题的双重压力,生物质作为最丰富和最有前途的可再生原料之一,已引起广泛关注,现有生物质资源总量相当于5.4亿t标准煤,其中2.8亿t可用作能源[1]。生物化学转化和热化学转化是生物质转化为能源、燃料和化学品的2种主要途径。热解是热化学转化技术的一种重要形式,也是各种热化学转化技术的起始阶段,可以在无氧或缺氧的环境下将固体生物质转化为生物炭、生物油和生物质热解气。生物油通过提质可以生产液态燃料和高附加值的化学品,热解气和生物炭可用于燃烧供热发电,其中生物炭也可以作为催化剂、吸附剂、有机肥料等用于化工、环境、农业等领域,以促进热解的经济性[2]。不同的生物质原料热解三态产物的产率有着较大差别,例如相同的热解条件下橡树的热解生物油产率为41%,而棕榈叶的生物油产率仅16.58%[3]。此外同种类型的生物质原料由于粒径不同热解产物的产率也会不同,例如相同条件下粒径为0.5和2.3 mm的茶叶废弃物生物炭的产率分别为13%和24%[4]。热解条件如热解温度、气体流量、进料速度等都会影响热解产物的分布。热解温度为影响热解产物分布的关键因素之一,例如保持其他热解条件不变,当热解温度由300 ℃上升到500 ℃时生物油产率由26.5%增加到36.6%[5]。除了实验手段外,有众多研究采用动力学模型对生物质原料特性和热解条件的影响进行描述[6],由于原料特性和热解条件的影响机制尚不清楚,建立生物质快速热解全反应输运模型困难且计算耗时长,通过有限数据拟合的全局或半全局动力学模型无法准确描述复杂的原料特性和热解条件影响。机器学习为应对这种复杂性提供了选择方案,可以在有限的认知下构建预测模型,并挖掘数据内在关联信息。Zhu等[7]通过机器学习构建模型预测了慢速热解生物炭的产量以及生物炭的碳含量。Chen等[8]构建了基于支持向量机(SVM)与人工神经网络(ANN)的三态产物分布和生物油热值预测模型,研究结果表明:SVM预测准确率高于ANN。Pathy等[9]以原料特性和热解条件作为输入构建了极端梯度提升算法(XGBoost)回归模型,成功地预测了藻类生物质热解生物炭的产量。刘立等[10]通过研究生物质特点及生物质转化工艺对产品中碳含量的影响,证明了随机森林算法(RF)模型的准确预测;通过预测不同生物质适用的转化类型及产生高附加值产品的产能以及品质,从而实现对生物质高效利用的合理预测。RF是基于决策树的机器学习算法,与其它机器学习算法相比,RF能够处理具有较高维度特征的输入样本、对数据量的要求较低,且有着极高的准确率[11]。本研究基于文献中生物质鼓泡流化床快速热解实验数据,采用RF对生物质快速热解三态产物产率进行了预测,验证了RF用于预测生物质流化床快速热解的生物炭、生物油、气体产率的可行性,并分析了原料特性和热解条件在生物质热解过程中的相对重要性。
1 材料与方法
1.1 样本数据收集
收集、采用了453条数据来构建模型,所有数据均来自于文献报道的鼓泡流化床生物质快速热解实验[12-57]。热解原料均为木质纤维素类生物质,包括小麦秸秆、松木等。数据直接从表格中获取,或使用Plot Digitizer 2.6.8从图片中提取。由于原料来源的广泛性、实验条件的差异性和重复性,305条数据存在相应的问题,故筛选出148条数据来构建与检验模型。筛选后每条数据的热解原料和热解条件均存在差异,且每条数据均包含所有变量的有效值。选取148条数据中的122条用于训练和测试模型,26条用于检验模型的泛化能力。快速热解实验大多采用预热到达预设热解温度,因此该环境下热解条件不包括加热速率。
影响生物质热解产物分布的关键因素可以分为5类:生物质的结构成分、生物质的三大主要化学组分、元素组成、原料外观和热解条件,具体见表1。将随机森林模型的输入变量Ash-V-FC-M记为输入Ⅰ,将变量Cel-Hem-Lig记为输入Ⅱ,变量C-H-O-N记为输入Ⅲ,变量PS记为输入Ⅳ,变量PT-GFR-FR记为输入Ⅴ。输入Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ共包含15个输入变量。输出变量为生物炭产率、生物油产率、生物质热解气产率,共计3个。

表1 输入生物质组成变量及热解产物产率的范围Table 1 Input biomass variables and range of pyrolysis products yield
1.2 随机森林算法
随机森林算法(RF)是一种基于决策树的数据分析方法。算法中将决策树作为弱分类器,用于处理变量之间的非线性关系。决策树由于具有成熟、可靠、能够对多类数据进行分类的特点,故能用来做分类也可以用于回归预测,为新兴的机器学习算法。RF通过Python机器学习库来训练样本和优化预测结果,其对生物炭、生物油、生物质热解气产率预测模型的算法原理如图1 所示。
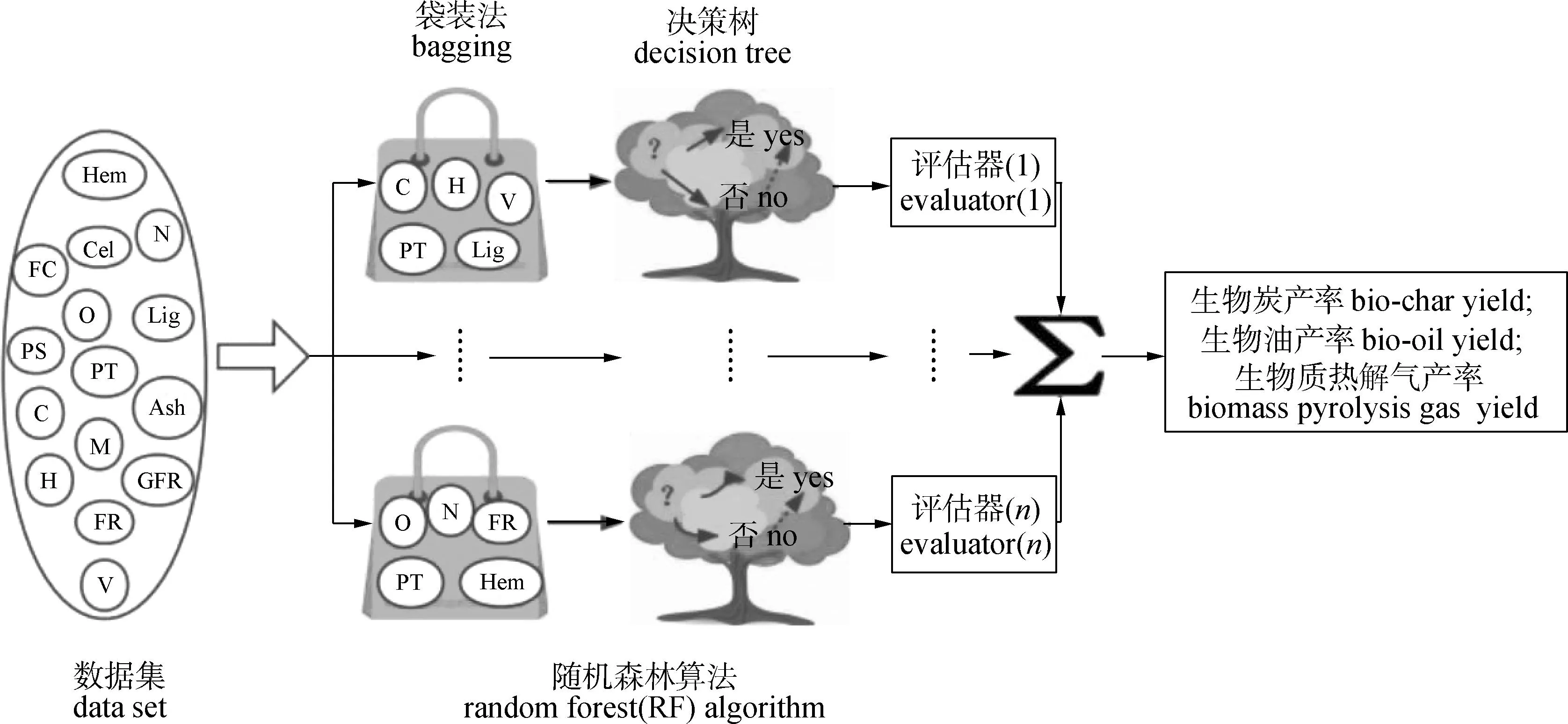
图1 随机森林模型对生物炭、生物油、生物质热解气产率预测模型的流程示意Fig.1 Process diagram of the RF model to generate the yield prediction model of bio-oil, bio-char and biomass pyrolysis gas
RF的实施分为5个步骤:1) 从原始训练集中使用袋装法随机采样选出m个样本,共进行n次采样,生成n个训练集;2) 利用生成的n个训练集,分别训练n棵决策树模型;3) 对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据基尼系数选择最好的特征进行分裂;4) 每棵决策树都这样分裂下去,直到该节点的所有训练样本都属于同一类;5) 将生成的多棵决策树组成随机森林,多棵树预测值的均值决定最终预测结果[13]。RF模型的关键参数为决策树棵数(n_estimators)、最大选择的特征数(max_features)、树的最大深度(max_depth)、分支节点的最少样本数(min_samples_split)、叶子的最少样本数(min_samples_leaf)。使用网格搜索与4折(4-fold)交叉验证的方法得到各个参数的最优值即最佳参数,然后使用最佳参数对模型进行重新训练与测试。将122条数据分为训练集和测试集,二者比例为4∶1。
随机森林回归公式为式(1),通过袋外数据(OOB)计算决策树的预测误差,每个决策树的平均泛化误差(EG)的标准化式子为式(2):
Y=Eθh(X,θ)
(1)
EG=EθEX,Y[Y-h(X,θ)]2
(2)
式中:θ—随机变量;Eθ—期望函数;X、Y—训练集进行随机抽取所取得的自变量、因变量;h—决策树预测函数;EX,Y—X、Y的联合期望函数。
所有用于构建模型的数据在进行训练测试前,都将使用Z-score进行标准化,见式(3):
(3)

根据测试数据的回归系数(R2)和均方根误差(RMSE)来评估模型的准确性,R2越大,表示模型拟合效果越好;R2越小,表示模型拟合效果越差。RMSE 越小,表示模拟值越接近观测值,误差越小;RMSE 越大,误差越大。
主要探究生物质原料特性输入(模型输入变量Ⅰ、Ⅱ、Ⅲ)对三态产物(生物炭、生物油和生物质热解气)产率的预测以及RF模型准确度。为防止模型出现过拟合现象、降低模型复杂度、寻找热解三态产物最优预测模型,对原料特性输入进行了7种组合。模型输入变量IV、V存在于全部7种组合中。
2 结果与讨论
2.1 RF产率预测性能评估
使用4-fold交叉验证与网格搜索结合的方法,以R2作为评价指标,得到不同输入所构建模型的最佳超参数,从而构建该输入条件下的最优模型,不同输入所构建模型在测试集上的准确度结果见表2。

表2 模型准确度信息Table 2 Model accuracy information
总体来说7个不同输入所构建的模型的准确度都比较高,都能很好地预测生物质热解三态产物的产率,生物质快速热解过程需尽可能提高生物油产率,模型6在生物油产率预测上表现突出,R2与RMSE分别为0.956 1、 2.939 5。
由于在所有模型中,模型6的输入变量最少,且准确度最高,因此选择该模型进行下一步讨论,其部分超参数见表3。

表3 模型6部分超参数Table 3 Part hyper-parameters of the model 6
模型6对于生物质热解三态产物产率预测在测试集上的表现,结果见图2。图中圆点表示测试样本,细线表示预测值与实验值相等(y=x),粗线表示用最小二乘法拟合的预测样本回归线。图2中部分测试样本点落在细线上,剩下样本点贴近细线且均匀分布在粗线两侧,且粗线与细线夹角较小,说明模型能很好地预测三态产物产率。图2(b)的粗线与细线夹角在图2(a)~(c)中最小,说明模型6对生物油产率的预测较生物炭、生物质热解气的更好。

a.生物炭bio-char; b.生物油bio-oil; c.生物质热解气biomass pyrolysis gas图2 RF模型6预测值与实验值对比Fig.2 Comparison of the predicted value of the RF model 6 with experimental values
2.2 模型可视化分析
2.2.1贡献度分析 基于模型6探讨了在预测生物质热解三态产物产率的过程中,原料特性与热解条件的相对重要性,总结如表4所示。由表可知,热解温度(PT)为影响热解产物产率的最重要因素,其对生物炭、生物油和气体产率预测的贡献度分别为0.332 7、 0.220 4和0.214 7。快速热解过程中生物炭产率主要由PT、Lig和PS决定,三者贡献总占比0.864 1。生物油产率由热解条件和原料特性共同决定,二者占比分别为0.474 4和0.525 6;各个输入变量对产率的贡献度分布比较均匀。热解条件对生物质热解气产率的贡献度占比0.519 7,略大于原料特性,PS和Lig对气体产率贡献较小。PT、FR、GFR、Cel和Hem为影响气体产率的关键因素。

表4 不同特征对三态产物产率预测的贡献度Table 4 Contribution degree of different characteristics for the prediction of three-state product yield
2.2.2部分依赖图分析 通过部分依赖图(PDP)可将输入变量对模型预测结果的影响可视化,即通过PDP分析输入原料特性与热解条件中的某一特征是如何影响三态产物产率预测的,排除了其它特征,显示了三态产物产率与某一输入特征之间的独立性。
可视化结果如图3~图5所示。图中x轴刻度线表示目标特征值,刻度线的疏密程度反映了数据的密度,当数据点过于稀疏时,趋势线可能不够准确,因此要结合各个特征的分布箱线图(图6)来分析,生物质热解三态产物产率的上下限也通过箱线图进行展示。

a.热解温度pyrolysis temperature; b.木质素质量分数lignin mass fraction; c.生物质粒径biomass particle size图3 生物炭产率部分依赖图Fig.3 Partial dependence diagram of yield of biochar

a.热解温度pyrolysis temperature; b.纤维素质量分数cellulose mass fraction; c.半纤维素质量分数hemicellulose mass fraction图4 生物油产率部分依赖图Fig.4 Partial dependency graph of yield of bio-oil

a.热解温度pyrolysis temperature; b.纤维素质量分数cellulose mass fraction; c.气体流量gas flow rate图5 生物质热解气体产率部分依赖图Fig.5 Partial dependence graph of yield of biomass pyrolysis gas

图6 各个特征箱线图Fig.6 Box plot of each feature
通过生物炭文献数据集的统计分析结果发现:热解温度与生物炭产率有显著的负相关性(p<0.05)。热解温度对生物炭产率的影响如图3(a)所示,当温度低于450 ℃时生物炭产量随着温度的升高大致呈线性下降且斜率较大,当温度超过450 ℃时,随着温度的继续升高产率变化较小。模型预测的生物质三组分的热解在450 ℃均趋于完成,同文献结论一致[51]。木质素质量分数对生物炭产率的影响如图3(b)所示。木质素质量分数的集中分布区间为25%~35%(图6(b)),此区间内生物炭产率随着木质素质量分数的增加先缓慢降低,超过30%之后再缓慢增加。通过木质素热解实验发现其固体产物含量较高,而液体和气体产物含量较低[55]。采用不同木质素质量分数的生物质原料进行热解实验,同样条件下木质素质量分数高的原料热解生物炭产率也高[56]。生物质粒径对生物炭产率的影响如图3(c)所示。生物质粒径的分布范围大致为200~4 000 μm(图6(c)),在200~1 000 μm范围内随着粒径的增加产率整体呈下降趋势且中间存在一小段下降后上升趋势(V形折线部分),粒径大于1 000 μm时随着粒径增大产率小幅度增加。通过农业残留物热解实验发现生物质粒径为500~2 300 μm时,粒径增大生物炭产率呈增加趋势。
图4(a)为生物油产率随热解温度的变化趋势。热解温度小于480 ℃时随着温度的升高生物油产率大致呈线性增加,而后随温度继续升高呈线性下降趋势,在450~500 ℃范围内生物油的产率较高。在制取生物油为主要目的的快速热解过程中,不同的生物质原料有着不同的最佳热解温度,例如松木屑在热解温度为462 ℃时生物油产率最大(68.4.%)[14],秃柏最佳热解温度为500 ℃(57.%)[44],棉秆的最佳热解温度为490 ℃(36%)[33]。纤维素质量分数对生物油产率的影响如图4(b)所示。纤维素质量分数分布区间为32%~48%(图6(b)),在此区间当纤维素质量分数低于37%时,随着其含量增加生物油产率变化较小,而后随着纤维素质量分数的增加,生物油产率呈线性增加且斜率较大,纤维素质量分数为40%~48%时,生物油产率较大。半纤维素质量分数对生物油产率的影响如图4(c)所示。半纤维素质量分数分布范围为16%~30%(图6(b)),在此范围内生物油产率随着其含量增加呈先不变后增加趋势。纤维素和半纤维素给热解多联产产物提供了较多的气体和液体产物,其中纤维素对气、液产物的贡献比半纤维素大,生物质三组分热解实验中影响生物油产率由高到低顺序依次是纤维素、半纤维素、木质素[57]。
图5(a)为生物质热解气产率随热解温度变化的变化规律。随着温度的升高,气体产量大致呈线性增加,420~540 ℃区间内气体产率随着温度的升高有较大幅度的增加,这与生物油和生物炭产率的规律不同,是因为热解挥发分和焦炭在反应温度升高时通过二次裂解转化为气体[16]。图5(b)表明当纤维素质量分数大于38%时随着纤维素含量增加气体产率基本维持不变。图5(c)为气体流量对气体产率的影响,随气体流量增加,气体产率呈较大幅度下降,而后大致保持不变。通过调节气体流量可控制热解气的停留时间,增大气体流量可缩短焦油在反应器中的停留时间,防止焦油进一步反应转化为气体,从而降低气体产率,提高生物油产率[29]。
分析PDP可知,热解温度是影响三态产物产率的关键因素,热解温度为450~500 ℃时木质素类生物质生物油产率最大。
2.3 模型泛化能力分析
2.3.1算法比较 在众多经典机器学习算法中,可用于多元非线性回归问题分析的有RF算法、极端梯度提升算法(XGBoost)、支持向量机(SVR)、神经网络(ANN),与模型6输入同样变量分别构建基于XGBoost、SVR、ANN的热解三态产物产率预测回归模型,并与模型6进行比较,结果表明:RF算法具有准确率高(R2大)、RMSE小的优点,在生物油产率的回归预测上较其他算法优势较大,4种算法所构建的模型在测试集上的分析结果如表5所示。
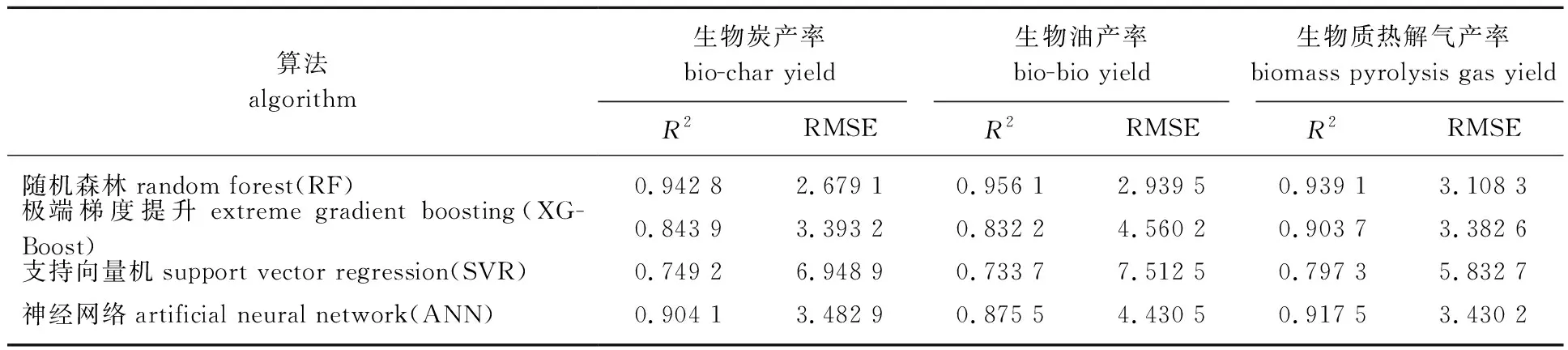
表5 不同算法预测准确度Table 5 Prediction accuracy of different algorithms
2.3.2模型泛化能力检验 为了检验模型的泛化能力和外延性,将所筛选的148条代表研究数据中未被用于模型训练与测试的26条数据用于检验模型的泛化能力。将全部26条数据输入已构建好的模型(模型6),模型对生物质热解三态产物固、液、气预测的R2分别为0.912 7、 0.921 8、 0.897 2,在应对未知数据集时模型的准确度有小幅度下降,但模型的准确度依旧保持较高水平,可见所构建的快速热解三态产物产率回归预测模型具有良好的内插和外延能力。
3 结 论
3.1以原料特性和热解条件为随机(RF)森林回归预测模型的输入变量,三态产物产率为模型输出,成功地预测了鼓泡流化床木质纤维素类生物质快速热解产生物炭、生物油、生物质热解气三态产物产率。通过对本文模型内部信息的研究,发现生物炭产率主要由热解温度、木质素含量、原料粒径决定,而木质素含量和原料粒径大小对生物油、气体产率的影响较小;生物油和气体产率由热解温度、进料速度、气体流量、纤维素和半纤维含量共同决定。
3.2通过部分依赖图(PDP)分析各个输入特征是如何影响产物产率的,模型结果显示热解温度450~500 ℃时生物油产率最大,选择纤维素和半纤维素含量较高的生物质原料以及适当增大气体流量都能够增加生物油产率。PDP分析有助于进一步了解快速热解反应机理,促进了对生物质热解过程的全面了解,并为快速热解三态产物产率调控提供了一定的理论指导。
3.3通过模型预测结果对比及模型泛化能力分析发现,随机森林算法较其它算法在快速热解产物产率预测上具有准确度高、泛化能力好的优势。研究结果促进了对生物质热解过程的全面了解,且为快速热解三态产物产率调控提供了理论指导。
