基于改进YOLOV5s的安全帽佩戴检测算法
2024-01-02王向前
王向前,史 策
(安徽理工大学,安徽 淮南 232001)
0 引言
安全帽是在物体打击发生时用来减轻或避免冲击对头部造成伤害的防护用具,是从事建筑、采矿等危险行业一线施工人员的重要安全保障。但是由于部分施工人员缺乏安全意识,因不佩戴安全帽而导致的安全事故时有发生。目前许多行业仍然采用人工监督检查的方式对施工人员佩戴安全帽的情况进行监管,耗费大量的人力成本与时间成本。因此基于深度学习的安全帽佩戴检测具有重要的现实需求。
1 YOLOV5算法原理
YOLOV5算法包括YOLOV5n、YOLOV5s、YOLOV5m、YOLOV5l、YOLOV5x五个网络模型,本文选用YOLOV5s网络模型进行安全帽佩戴检测。YOLOV5s由输入端、主干网络、颈部网络、检测端4个部分组成。输入端包括马赛克数据增强、自适应图片缩放和自适应锚框计算。主干网络用来提取图片的特征,采用CSPDarkNet35网络,主要由C3模块、CSP模块和SPPF模块构成。颈部网络由FPN和PAN的模块组合对骨干网络提取的特征进行融合。输出端利用颈部网络传来的3种尺度不同的特征图对不同大小的目标进行检测。
2 YOLOV5s算法改进
2.1 结合SimAM注意力
2021年中山大学提出一种无参数注意力SimAM[1]如图1所示。现有的通道注意力和空间注意力往往采用额外的子网络生成注意力权重,而SimAM注意力认为信息丰富的神经元与普通神经元具有不同的放电模式,并且重要的神经元会对周围普通的神经元产生空域抑制现象。SimAM注意力通过度量神经元之间的线性可分性寻找更重要的神经元并给予它额外的权重。
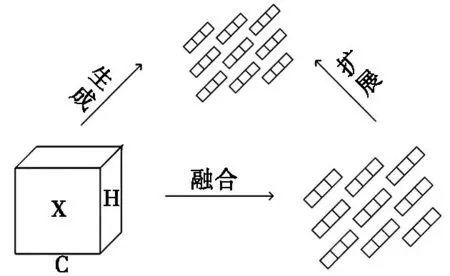
图1 SimAM注意力
SimAM注意力定义了一个能量函数,公式如下:
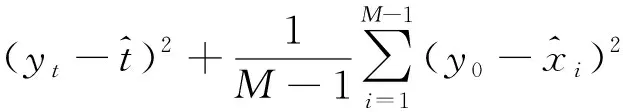
(1)
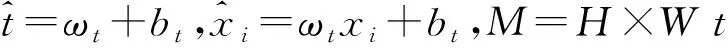
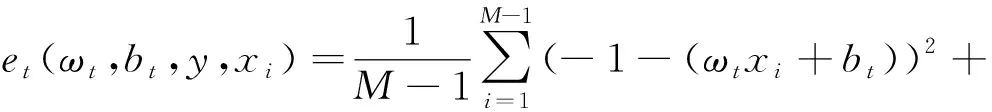
(2)
解析公式2得到:
(3)
(4)
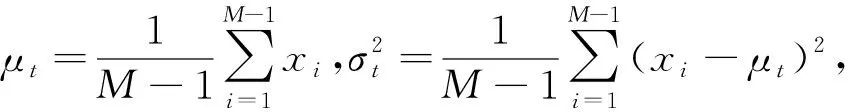
(5)
2.2 引入Bi-FPN网络
安全帽不仅有多种颜色,成像尺寸也有差异。为了更好的融合特征,引入双向特征金字塔网络(Bidirectional Feature Pyramid Network,Bi-FPN)[2]。Bi-FPN网络对YOLOV5s原有的FPN+PAN[3]网络进行简化,删去只有一个输入和一个输出的节点。同时对于处于同一层的输入和输出节点,在两个节点之间添加一条直接相连的通道,在不增加计算量的前提下可以融合更多的特征。Bi-FPN中一对自底向上和自顶向下的路径视为一个模块,可以重复叠加融合更高层次的特征,Bi-FPN网络结构如图2所示。
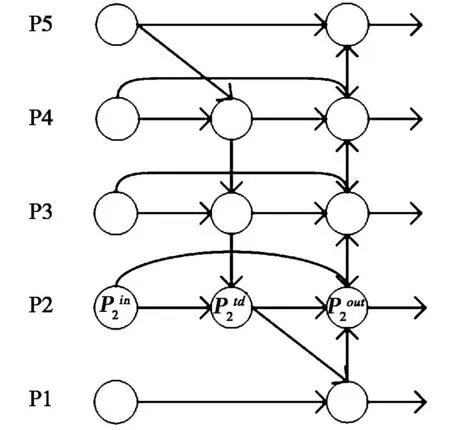
图2 Bi-FPN网络结构
2.3 增加小目标检测层
在安全帽检测场景中,摄像头往往距离安全帽比较远,导致安全帽目标的成像较小。为了提高YOLOV5s对小目标安全帽的检测能力,本文在YOLOV5s原有的3个检测层的基础上增加一个额外的小目标检测层。首先在21层之后,增加一个CBS模块提取特征,同时将通道数由512降为256。接着继续对特征图进行上采样处理,扩大特征图尺寸为160×160,在23层和主干网络传入的第2层的特征图进行拼接操作,最后经过24层的C3模块实现小目标检测层的搭建,整体改进后的YOLOV5s网络结构如图3所示。
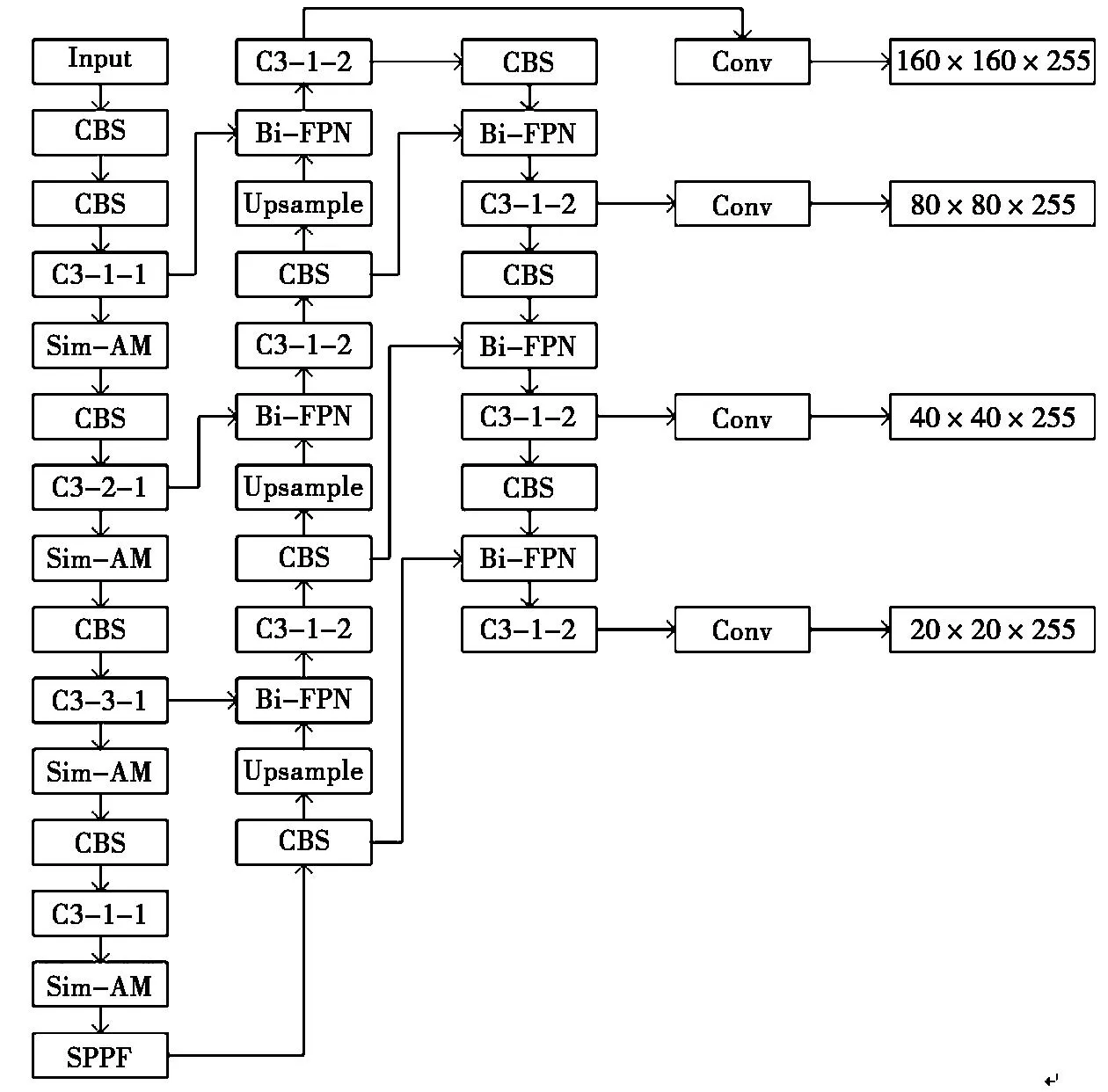
图3 改进后的YOLOV5s网络结构
2.4 采用DIOU-NMS
在检测安全帽任务时,经常出现由于工人密集导致安全帽目标存在遮挡的情况,为了解决这个问题,本文采用DIOU-NMS代替原有的NMS算法。DIOU-NMS借鉴了DIOU损失函数[4]的思想,具体公式为:
(6)
式中:M代表预测分数最高的预测框,Bi代表其他预测框,Si代表分类得分,ε代表NMS阈值大小,RDIOU代表两个框之间的距离,RDIOU公式如所示:
(7)
式中:ρ2(b,bgt)为预测框和检测框之间的中心点距离,b是预测框中心点,bgt为真实框中心点,c为两个框之间最小外接矩形对角线距离。
3 实验
3.1 数据集
本文选用开源的安全帽数据集GDUT-HWD,该数据集包括3174张不同场景、天气、光照、人物等变化的数据照片,包含五类样本,分别是None、Red、Blue、Yellow、White。本文将数据集按照9∶1的比例随机划分为训练集和测试集。
3.2 实验设置和评价指标
本文实验采用ubuntu20.04操作系统,内存30GB,GPU为RTXA4000,显存16GB;深度学习框架为PyTorch1.10.0;Cuda版本为11.3,Python版本为3.8。YOLOV5s训练学习率采用Warmup训练,通过余弦退火算法对学习率进行更新,epoch设置为200,batch size设置为16。
本实验采用精确率(Precision,P)、平均精度均值(mean average precision,mAP)来评价YOLOV5s对安全帽的检测性能,其中精确率P、平均精度均值mAP的公式分别为:
(8)
(9)
(10)
式中:TP是指正确检测到安全帽的检测框数量;FP是指误检为安全帽的检测框数量;NC为类别总数。
3.3 实验结果分析
3.3.1 消融实验
为了分析不同改进对整个YOLOV5s模型性能的影响,以YOLOV5s为基础模型对所提出的改进算法进行消融实验,实验结果如表1所示。字母A~D分别表示加入SimAM注意力、增加小目标检测层、引入Bi-FPN网络、引入DIOU-NMS。从表中可以看出,本文提出的4种改进相比较原始YOLOV5s算法都有不同程度的提升,4种改进共同加入YOLOV5s后,精确率P提升了4.1%、平均精度均值mAP提升了4.5%,说明本文提出的算法能够更好的检测现实场景下安全帽佩戴检测问题。
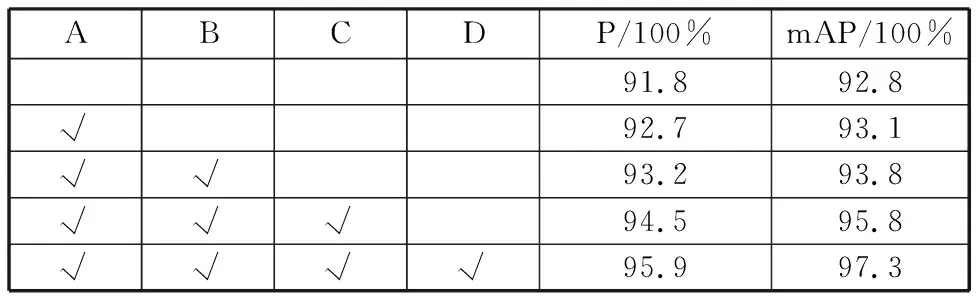
表1 YOLOV5s消融实验
为了能够更加直观地看出改进后的YOLOV5s带来的检测性能的提升,本文用改进前后的YOLOV5s算法对同样的测试集进行检测,部分测试结果如图4所示。图4(a)中,YOLOV5s没有检测出远处的安全帽,并将近处的钢管横截面误检为黄色头盔,而改进后的YOLOV5s准确地检测出了远处的安全帽,没有发生误检并且置信度也高于原始YOLOV5s算法。图4(b)是安全帽密集遮挡图像,YOLOV5s算法出现了漏检的情况,而改进后的YOLOV5s算法准确地检测到所有被遮挡的安全帽。综上所述,改进后的YOLOV5s在现实场景下表现出了更加优异的性能,在小目标和遮挡目标的检测中也优于原始YOLOV5s算法。

图4 不同场景下算法检测对比
4 结论
为了解决当前安全帽佩戴检测任务中存在检测精度低,对于小目标和遮挡目标的检测容易出现误检、漏检的问题,本文提出了一种基于改进YOLOV5s的安全帽佩戴检测算法。通过结合SimAM注意力、增加小目标检测层、引入Bi-FPN网络以及采用DIOU-NMS来改进YOLOV5s算法。由实验结果可知改进后的YOLOV5s算法对安全帽的检测取得了较高的检测精度,并且在小目标和遮挡目标的检测上也获得了明显的进步,满足现实施工场景下的安全帽检测需求。由于本实验都是在高算力的设备上进行,下一步研究的重点是将检测模型移植到嵌入式设备中实现工业应用。
