基于动态时间权重的混合协同过滤推荐算法
2024-01-02李卓敏马圣雨宋逸杰
李卓敏,卢 敏,马圣雨,宋逸杰
(1.江西理工大学 理学院,江西 赣州 341000;2.河南理工大学 计算机科学与技术学院,河南 焦作 454003)
0 引言
信息技术的快速发展为用户在平台上提供了更多浏览选择,在众多信息中快速、准确寻找偏好信息是一个亟待解决的难题[1]。为了更好地过滤信息,提升用户服务质量,推荐技术由此诞生,并迅速引起了学术界的广泛关注。许多算法被提出来解决推荐技术的各种问题,其中协同过滤推荐算法是研究热门,在许多案例中取得了较好的推荐效果。
该算法通过收集与用户推荐偏好相似的相关用户信息,或收集用户感兴趣的领域信息,为其推荐相关产品[2],可分为基于用户和基于项目两方面[3]。其中,用户协同过滤算法(Collaborative Filtering,CF)挖掘与目标用户评价过相同项目的其他用户,通过判断共评信息,推荐相似用户评价高的项目,但只考虑了用户间的联系,未考虑热门项目对用户的影响,忽略了热门项目无法突显用户个性化的问题;项目协同过滤算法通过挖掘项目所有历史评分记录,根据评分高低计算各项目间的相似度,以推荐相似度高的项目集,致力于挖掘项目间的相关性,但忽略了时间因素对相关性的影响,导致评分可靠性较低。然而,上述两种算法仅考虑了单方面因素,忽略了时间因素对两者相关性的影响。
为此,本文提出一种HCFADT 算法解决传统算法中热门项目无法突显个性化、用户可靠度与时间相关性低的问题。首先提出一种引入动态时间权重因子的相似度计算方法,根据用户为项目评分的时间生成动态时间权重因子,将用户可靠性与时间形成关联,突显用户个性化;然后提出一种引入参数β的综合考虑用户和项目相似度的混合算法,根据两者不同的依赖程度调整参数,获取最佳参数β,以综合考虑用户和项目两个因素,解决传统算法存在的数据稀疏性问题。
1 相关工作
协同过滤算法的产生使互联网为用户提供了更精确的服务信息,但却出现了数据稀疏、冷启动等问题[4]。针对这些问题,国内外研究人员提出了许多改进的推荐算法,对今后发展具有启发式作用。
为了解决数据稀疏问题,吴宾等[5]根据不同结构的数据设计了不同建模方式,提出MSRA 算法分析异构数据间的相关性来解决问题。李改等[6]提出一种URA 算法兼顾评分预测和排序预测,使算法能更快适应在大数据环境中的预测。文诗琪等[7]对用户评分设定阈值,将项目属性分为用户偏好与不偏好,只有具备偏好属性的项目才能作为近邻,减少了计算近邻相似项目的个数,有效提升了推荐精度,但并未考虑筛选用户偏好的计算效率和时间对用户偏好的影响,使得算法的时间复杂度较大。
为了提升传统推荐方法在大量物品中为用户进行推荐的计算效率,张飞等[8]提出一种根据用户兴趣和物品特征进行聚类分组的方法,并构建图模型求解分组。王瑞琴等[9]根据项目评分数据,生成用户对项目的评论态度影响因子,通过影响因子进一步放大用户对项目的偏好,以更准确地预测目标用户偏好,提升推荐质量和计算效率。然而,上述文献均只考虑了用户偏好领域的信息,未考虑时间因素对用户偏好的影响和热门项目对用户个性化的影响。
针对用户推荐算法中用户可靠度问题,李伟霖等[10]考虑社会心理学中多个信任要素,深入提取用户间的信任信息并融入推荐算法,有效提升了推荐精确度,但未考虑时间对用户间信任关系的影响。潘一腾等[11]考虑用户作为信任者和被信任者时不同偏好的情况,得到社会关系的隐含间接影响,然后根据两种信任强度影响提出一种自适应相似度计算的模型,但忽略了信任关系的可靠度。综上,上述方法仅考虑了用户间信任关系,均未考虑用户之间信任关系的可靠性和时间变化与用户可靠度变化的相关性。
考虑到结合用户和项目算法,能有效解决单一依靠用户或项目导致推荐质量较低的问题。Rosa 等[12]提出一种局部相似性方法,利用用户间的多种相关结构,使用聚类方法查找对相似项目存在相似偏好的对象组,为每个集群创建一个基于用户的相似性模型,得到了较好的推荐效果。Ortega 等[13]提出一种基于多类分类算法合并不同CF方法提供的推荐结果,在MovieLens、Netflix 数据集上取得了较高的推荐质量。Zhang 等[14]提出一种TTHybridCF 算法,利用标签和评级信息计算用户或物品间的相似性,极大提升了模型预测精度。上述方法表明,混合算法能有效提升推荐精度,但并未考虑时间因素,仍然存在时间对用户关系与热门项目的影响。
对于时间改变用户偏好的问题,Liao 等[15]利用一群信息素捕捉用户兴趣实时变化,相较于传统算法提升了推荐准确性。Wangwatcharakul 等[16]利用联合分解方法提取用户潜在过渡模式,基于动态环境的主题建模结合潜在因素与评论文本的相关主题演,捕捉评分矩阵中的用户偏好动态。Joorabloo 等[17]考虑到未来的相似性趋势,重新排列用户或项目邻域集提出一种算法预测相似性趋势,根据趋势的增减来更新CF 公式的最终最近邻集,以提升算法的精确度。虽然,加入时间因子能提供未来趋势,有效提升算法精确度,但未考虑将混合算法与时间因素相结合,无法有效利用用户与项目的信息,存在数据稀疏性问题。
综上,考虑到用户和项目单一的缺点,结合混合算法与时间因素,本文提出一种基于动态时间权重的混和协同过滤推荐算法。首先,加入动态时间权重解决热门项目和用户可靠性问题;其次,融合两种算法计算相似度,以有效利用用户与项目信息解决数据稀疏性问题;再次,选取用户的最佳相似邻居集对目标用户进行推荐预测,提升模型推荐性能。
2 基于HCFADT的算法设计
2.1 皮尔逊相似度
本文采用皮尔逊相似度进行计算[18],该数是一个-1~1 的数,能衡量两个数据集合之的相似性。相似性强时相似度趋于1;相似性弱时相似度趋于0;在负相似性情况下,一个数据的值很高而另一个数据值很低时相似度趋于-1。
2.2 引入动态时间权重的用户相似度计算
用户CF 算法[19,20]假设用户间存在相似兴趣,很可能会购买相同物品,该方法通过挖掘目标用户的历史偏好信息来识别相似用户,利用相似用户历史评价信息判断相似用户偏好项目,对目标用户进行推荐,如图1所示。
2.2.1 用户间的相似度
根据用户共同评分的项目集合信息,计算用户间的相似度。计算用户u、v的相似度如式(1)所示。
式中:Iuv表示用户u、v历史共同评价过的项目集合;Ruj表示用户u对项目j的评分,Rvj表示用户v对项目j的评分;和分别表示用户u和用户v对项目的平均评分。
2.2.2 用户动态时间权重值
假设两个用户都购买了新华词典,但无法突显他们的个性化,因为大多数人都会购买这本书。然而,如果两个用户都买了机器学习这种少数人购买的书,将突显两人的个性化,表明他们存在相同的兴趣或需求。为了解决用户CF 算法存在热门项目无法突显个性化问题,本文引入用户权重wut(i)表示用户u对项目i评分的动态时间权重,如式(2)所示。
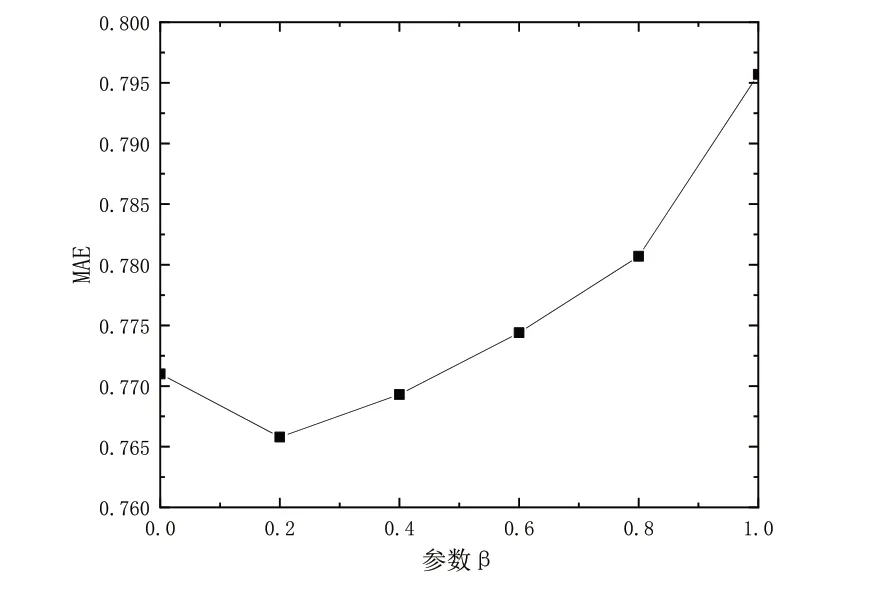
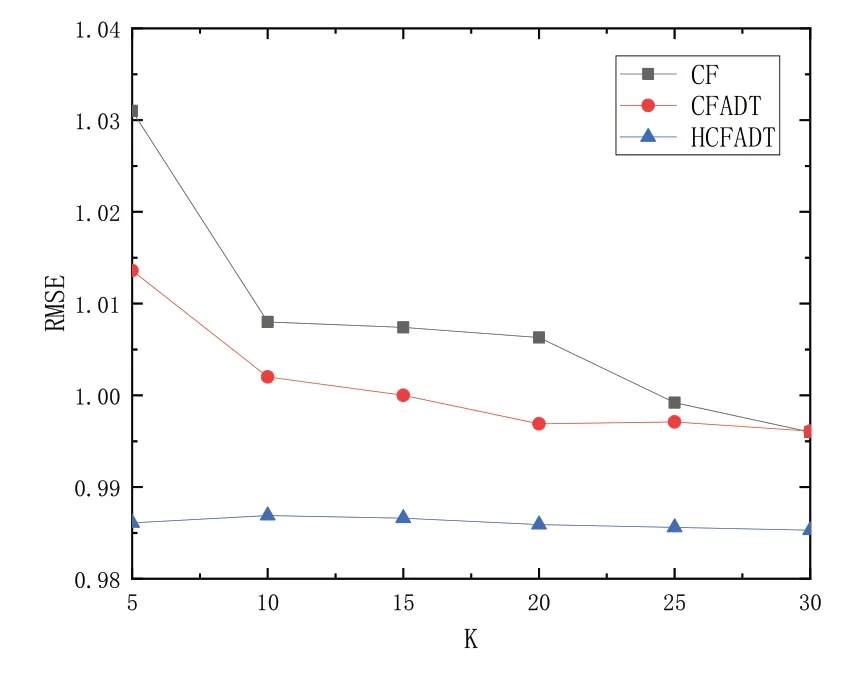
式中:i∈Iuv、tminu表示用户第一次对项目的评分时间;tmaxu表示用户最近一次对项目的评分时间;tu表示用户的评分时间段,即tminu 2.2.3 用户动态时间权重的相似度 引入用户动态时间权重的相似度计算,如式(3)所示。 用户间相似度的计算首先生成用户评分矩阵(见表1),根据评分信息计算相似度;然后计算每个项目被评分的频数时间权重;最后将时间权重加入相似度计算中。 Table 1 User rating matrix表1 用户评分矩阵 2.2.4 获取目标用户的邻居集 通过计算用户间的相似度得到相似度矩阵,对相似度进行降序排序,选取前k个用户作为相似邻居集,用集合N(u)表示。 2.2.5 根据用户相似度与相似邻居集计算预测评分 利用选取的邻居集中各相似用户对目标项目的评分,预测目标用户u对目标项目i的评分PUADT(Rui),如式(4)所示。 传统项目CF 计算项目相似度的原理是用户可能会对与历史偏好项目相似的项目感兴趣,通过挖掘用户的历史评价数据识别相似项目,根据这些项目的相似度进行推荐,如图2所示。 Fig.2 Project similarity diagram process图2 项目相似图流程 2.3.1 项目间的相似度 根据对项目i、j共同评分过的用户集计算项目i和j之间相似度,如式(5)所示。 式中:Uij表示对项目i、j共同评价过的用户集合;Rui、Ruj分别表示用户u对项目i和j的评分分别表示项目i、j的平均评分。 2.3.2 项目动态时间权重值 项目CF 算法未考虑用户打分可靠度,假设某用户在某时间内由于环境影响或时间因素随意评价项目,此时分数并不可靠,对相似度计算会造成影响。为此,本文引入wit(u)表示项目i的动态时间权重,以降低该情况造成的影响,如式(6)所示。 式中:u∈Uij、tmini表示项目第一次被用户评分时间;tmaxi表示项目最近一次被的评分时间;ti表示项目被评分的时间段,即tminu 2.3.3 引入项目动态时间权重项目相似度 引入项目动态时间权重的项目相似度计算,如式(7)所示。 项目间相似度计算首先生成项目评分矩阵(见表2),根据用户评分信息计算相似度;然后通过计算每个用户评分的频数得出时间权重;最后将时间权重加入相似度计算。 Table 2 Item rating matrix表2 项目评分矩阵 2.3.4 选取目标项目相似项目集 通过计算项目相似度得到相似度矩阵,对相似度进行降序排序,选取前k个相似项目作为相似项目集,通过集合N(i)进行表示。 2.3.5 预测评分 根据项目相似度选取项目集,计算目标用户u对目标项目i的预测评分PIADT(Rui),如式(8)所示。 由于在评分预测时,依靠项目预测或用户预测得到的推荐质量较低。为此,本文提出基于动态时间权重的混合协同过滤推荐算法(HCFADT),如式9所示。 式中:等式第一部分包括基于UADT、IADT 的预测结果;β∈(0,1) 为调节因子,代表对UADT、IADT 的依赖程度,当β=0 时表示算法只考虑了用户信息,当β=1 时表示算法只考虑了项目信息,取中间值时表示综合考虑了两者信息。 为了验证HCFADT 算法的推荐效果,获取最佳参数β,实验在Intel(R)Core(TM)i5-7200U CPU 环境下进行训练,使用Tensorflow 为后端,Python 3.8 进行编译。以平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)作为评价指标[21],采用的ML-100k 数据集包含10 万条对电影的评分记录,电影评分范围为[1,5]的整数,用户对电影的评分越高代表兴趣程度越高。数据预处理环节,将80%的用户评分数据作为实验训练集,20%的用户评分数据作为实验测试集,实验参数如表3所示。 Table 3 Detailed parameters of ML-100k dataset表3 ML-100k数据集详细参数 MAE 计算真实值与预测值间的平均差值,能表明预测与真实值的接近程度,如式(10)所示;RMSE 由计算预测值与真实值偏差的平方与总数之比的平方根所获得,如式(11)所示,由于RMSE 对预测结果的波动非常敏感,因此可有效验证实验方法的稳定性。 式中:MAE 越小表明预测更接近真实值,预测精度越高。 式中:rui、分别表示用户u对项目i的预测评分和实际评分;N表示测试集的评分数量;RMSE 值越低表明预测结果与真实结果越接近,算法精确度越高。 由于近邻数量对预测得分的准确性具有很大影响,实验比较了参数β在(0,1)内间隔为0.2 取值下的最佳值,如图3 所示。为了评价推荐算法的预测精度,在相同的实验环境下,将本文算法、传统CF 算法、引入动态时间权重的CFADT 算法,在[5,30]间隔为5 的预测精度下进行实验比较,实验结果如图4、图5所示。 Fig.3 MAE values of different β图3 不同β时的MAE值 Fig.4 Comparison of MAE values图4 MAE值比较 Fig.5 Comparison of RMSE values图5 RMSE值比较 3.2.1 参数β 在混合协同过滤算法中引入参数β,以确定算法对加入动态时间权重的项目和用户依赖程度。实验中,对所有近邻的选择进行实验以确定β的灵敏度,其中β的值从0变化到1,间隔为0.2,结果如图3所示。 由图3 可见,当β=0 时MAE 值为项目算法的相似度;当β处于0~1 时,预测融合了用户和项目算法的优点,有效提升了预测精度;随着参数β增大,预测向基于用户的方面靠近,MAE 值逐渐增大,即预测误差逐渐增大;当β=1时,MAE值为用户算法的相似度。 综上,在两端单一依赖用户或项目算法的推荐精确度较低,取中间值能融合各算法的优点,提升预测精度,在0.2时预测精度最佳。 3.2.2 MAE值 为了验证所提算法的优越性和有效性,将HCFADT 算法、传统CF 算法和基于动态时间权重的CFADT 算法进行比较,K 表示所选近邻数量,如图4所示。 随着近邻数量增加,MAE 值逐渐降低,HCFADT 算法的MAE 值远低于CF、CFADT,表明预测值更接近真实值。引入动态时间权重的算法预测精度优于传统协同过滤算法,因此动态时间权重对模型预测精度具有积极作用。此外,结合二者算法的混合算法预测精度优于单一引入动态时间权重的算法。 由图5 可见,随着近邻数量增加,CF、CFADT 算法的RMSE 值下降并逐渐趋于稳定,但HCFADT 的RMSE 值波动较小,总体低于CF、CFADT 算法。原因为CF、CFADT 仅考虑了项目或用户单方面的影响,导致预测精确度不高,并且CF 算法未考虑时间变化,因此算法RMSE值存在明显波动。然而,本文算法综合考虑了项目、用户及时间因素,因此具有更好的稳定性和精确性。 本文为了有效提升推荐算法的推荐质量,解决传统协同过滤算法存在热门项目影响和无法识别一段时间内用户项目偏爱度的问题,提出一种基于动态时间权重的混合协同过滤推荐算法。首先计算目标用户的评论频数和目标项目的被评频数,通过用户评论量和项目用户评论数分别为基于项目、用户的算法添加动态时间权重;然后在获得较好效果的情况下,将两个算法相结合。 实验表明,在用户评分数据稀疏的情况下,混合相似度计算显著提升了模型的推荐预测精确性,证明了本文算法在整体上相较于传统方法更优。下一步,考虑到用户兴趣爱好与用户之间信任关系的动态变化性,将通过强化学习方法接收环境对动作的奖励(反馈),获得学习信息并更新模型参数,以快速对用户进行推荐,进一步提升模型推荐预测的准确性。
2.3 引入动态时间权重的项目相似度计算


2.4 基于动态时间权重的混合协同过滤推荐算法
3 实验结果与分析
3.1 实验设置

3.2 算法比较

4 结语
