基于注意力机制上下文建模的弱监督动作定位
2024-01-02党伟超高改梅刘春霞
党伟超,王 飞,高改梅,刘春霞
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引言
视频时序动作定位是视频理解中的一个重要任务,动作定位相比动作识别难度更高[1-3],不仅需要检测出视频中动作片段的开始时间和结束时间,还需要对动作进行分类。随着计算机计算性能的提升和图形处理器的普及,深度学习技术开始运用于视频理解领域。基于深度学习的动作定位方法可分为强监督动作定位和弱监督动作定位两种。强监督动作定位需要人工标注出每一个动作实例的类别、开始时间以及结束时间,这些工作非常耗时且很容易出现错误[4-7];弱监督动作定位省去了一部分人力标注成本,但缺乏帧级别分类标签,很容易发生动作帧没有被识别或识别错误的情况。为提高动作定位的准确率,大多数弱监督动作定位模型都会结合注意力机制来生成帧级注意力值。基于注意力机制的弱监督动作定位可以分为两种方式:一种是自上而下的方式。该方式需先训练一个视频分类器,利用分类器产生的分类激活序列(Class Activation Sequence,CAS)获得帧级别的注意力分数。例如Paul 等[8]提出的W-TALC 是目前比较成熟的自上而下的模型;Islam 等[9]提出的HAM-Net 也是一种自上而下的弱监督动作定位方法,其利用混合注意力机制分离视频中的动作帧和背景帧,同时定位得到动作实例发生的完整时间边界。另一种是自下而上的方式。该方式直接从原始视频特征中提取前景和背景注意力,例如Nguyen 等[10]提出的STPN 模型利用视频特征提取注意力分数,并在此基础上加入注意力稀疏性损失加强视频中动作帧的稀疏性;Shi 等[11]提出的DGAM 动作定位模型将原始特征和从特征中提取到的注意力同时输入到一个条件变分自编码器模块中进行重构,利用重建损失降低重构特征与视频特征误差。
然而以上方法存在对特征不明显的动作帧难以识别,以及动作帧和上下文帧识别错误的问题。为此,本文提出一种基于注意力机制上下文建模的弱监督动作定位方法,利用注意力机制提取视频中的关键动作信息,用于分离动作—背景帧;在此基础上引入半软注意力,引导模型识别视频中特征不明显的动作帧;同时对视频中的上下文信息建模,使模型可以识别上下文帧,从而解决动作帧—上下文帧易混淆的问题。
1 相关研究
1.1 视频动作识别
视频动作识别任务主要是指对裁剪好的短视频进行动作分类。在该方面研究中,Simonyan 等[12]首先提出基于双流卷积神经网络的动作识别算法,使用空间流网络处理空间信息,时间流网络处理时间信息;Wang 等[13]采用稀疏采样方案,通过平均聚集的方式对长时视频信息进行建模;Donahue 等[14]应用长时递归卷积网络捕捉视频中的时序信息;Karpathy 等[15]采用卷积神经网络提取视频中每一帧的特征,然后完成动作分类;Tran 等[16]提出C3D 网络用于动作识别,采用3D 卷积核提取视频中的时间和空间信息。动作识别是视频内容理解中的一个基础任务,弱监督动作定位算法可以采用预训练好的动作识别模型提取视频特征。
1.2 弱监督动作定位
视频动作定位不仅需要识别动作类别,还需要定位每个动作的开始时间和结束时间。与强监督动作定位相比,弱监督动作定位无需帧级标签且减少了时间轴标注人力成本和时间成本。近年来,弱监督动作定位相关研究成果丰硕。针对动作—上下文易混淆的问题,Liu 等[17]提出ACSNet 模型,通过扩展上下文类别标签将动作帧与上下文帧解耦,从而实现动作—上下文帧的分离。针对动作完整性边界问题,Singh 等[18]提出Hide-Seek 模型,在训练样本过程中随机隐藏一些帧,使分类网络能够学习到区分度相对较低的视频帧;Zhong 等[19]提出的Step-by-step 方法利用迭代训练多个分类器来检测同一动作实例的互补片段;Liu 等[20]提出的弱监督动作定位模型采用多分支网络和多样性损失检测同一个动作实例的不同动作片段。
本文采用自上而下的方式进行动作定位。为验证模型有效性,在对比实验部分比较该模型与W-TALC 模型[8],HAM-Net 模型[9],DGAM 模型[11],ACSNet 模型[17]等弱监督定位模型在不同IoU 阈值下的平均检测精度均值(mAP)。
1.3 注意力机制
神经网络通过引入注意力机制对样本进行全局扫描,进而发现有用信息,并为样本分配一组权重来增强关键信息、抑制冗余。根据注意力是否可微,可将其分为硬注意力和软注意力两种[21],其中硬注意力不可微,某个区域的注意力值非0 即1;软注意力可微,每个区域的注意力值是介于0~1的数值。
本文利用注意力机制为每个样本学习得到特定的半软阈值,并利用半软阈值将软注意力得分中高于阈值的区域值置为0,余下区域的注意力值不变,得到半软注意力。引入半软注意力可以引导模型关注视频中运动特征不明显的动作帧,同时借助注意力机制权重分配方式聚焦于输入视频序列中的时间上下文信息,完成上下文建模,实现动作帧与上下文帧的分离。
2 动作定位模型
2.1 整体框架
动作定位模型整体框架如图1 所示,主要包括特征提取、视频分类模型和注意力模型3 个部分。特征提取部分采用预训练好的I3D 模型[22]分别获取视频RGB 和光流特征,然后对RGB 和光流特征进行拼接,得到双流视频特征。分类模型生成帧级别的分类激活序列。注意力模型分为动作—背景分支和上下文分支,其中动作—背景分支提取视频的动作注意力和背景注意力分数,并利用半软注意力引导模型识别特征不明显的动作帧;上下文分支利用视频上下文信息建模,提取上下文帧的注意力分数,使模型可以分离动作帧与上下文帧。视频类别标签可以表示为y∈{0,1}C+1,视频包含第j类动作,则y(j)=1,不包含则y(j)=0,第C+1 维表示背景类别。利用视频类别标签训练模型,并对帧级分类激活序列和动作注意力分数进行处理以完成动作定位。

Fig.1 Framework of action localization model图1 动作定位模型框架
2.2 视频分类模型
视频分类模型包含两个卷积层,模型输出结果为帧级动作分类激活序列CAS。表示为:
式中:X为提取到的双流视频特征;Wcls和bcls分别为分类网络卷积层的权重和偏差;* 为卷积操作;CAS∈RT×(C+1)表示帧级的动作类别分数;T为视频片段数;第C+1类为背景类别。
2.3 基于动作—背景注意力的弱监督动作定位
2.3.1 动作—背景注意力分支
动作—背景注意力分支提取视频的帧级动作注意力和背景注意力分数,该分支由注意力模型提取视频注意力值后进行softmax运算以区分动作注意力与背景注意力。计算公式为:
注意力模型由两层卷积组成,其中X为双流视频特征;Watt和batt分别表示注意力网络的权重参数和偏差;Ains - bak∈RT×2表示视频片段总数为T;每个片段包含动作注意力分数attins和背景注意力分数attbak,总和为1。
动作注意力抑制背景帧的类激活分数,因此动作分支视频标签为yins=[y(j)=1,y(C+1)=0];背景注意力抑制动作帧的类激活分数,因此背景分支视频标签为ybak=[y(j)=0,y(C+1)=1]。图2 为动作—背景注意力分支结构。

Fig.2 Action-background attention branch structure图2 动作—背景注意力分支结构
将动作和背景注意力分别与帧级分类序列CAS 相乘,得到两种注意力加权得到的帧级分类激活分数。采用TOP-K 方法[8]对帧级分类激活序列中每个动作类别沿着时间维度上聚合TOP-K 得分并求平均值,得到视频级分类得分。计算公式为:
2.3.2 半软注意力
为更加准确地优化动作注意力分布,使模型可以识别动作特征不明显的视频帧,采用半软阈值γ擦除动作注意力分数attins中高于阈值γ的片段,以提取半软注意力分数attsemi-soft。计算公式为:
式中:阈值γ并非人工经验设置的固定值,而是通过神经网络结合注意力机制为每一个视频样本设置的一个特定值。提取到半软注意力分数后,首先通过点积运算求得半软注意力加权的帧级分类序列;然后根据式(3)聚合平均得到视频分类得分,并在类别维度进行softmax运算得到semi-soft;最后结合视频标签ysemi-soft构建半软注意力分类损失函数训练模型。半软注意力分支的视频标签为ysemi - soft=yins=[y(j)=1,y(C+1)=0];半软分类损失函数表示为:
2.4 基于上下文注意力的弱监督动作定位
动作—背景注意力分支没有考虑上下文帧对动作定位的影响,导致模型难以区分动作帧和上下文帧,因此本文增加上下文注意力分支,利用注意力模型对动作、背景以及上下文进行分类。注意力模型提取帧级上下文注意力后,采用softmax区分上下文注意力和动作—背景注意力。计算公式为:
式中:X为双流视频特征;Watt和batt为注意力网络参数;上下文注意力Acon∈RT×1;T为视频片段数,每个视频片段上下文注意力与动作—背景注意力的和为1。
上下文帧与动作类别相关,常与动作帧一起发生,但其运动特征稀疏,这又与静态背景帧类似,因此设置上下文分支视频类别标签ycon=[y(j)=1,y(C+1)=1]。图3为上下文注意力分支结构。
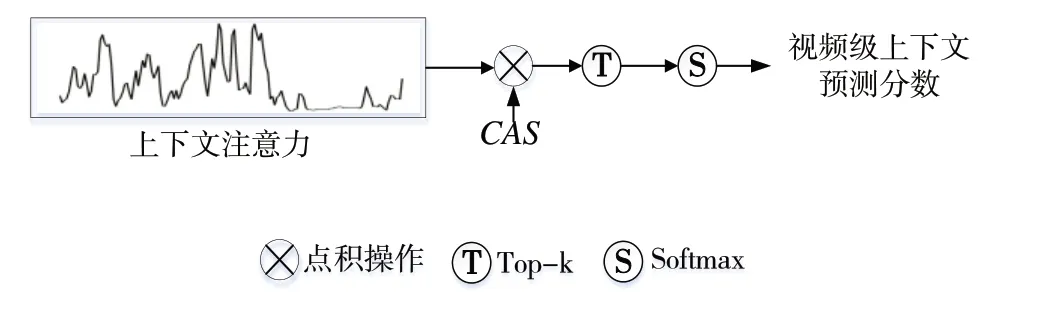
Fig.3 Context attention branch structure图3 上下文注意力分支结构
将上下文注意力分数与CAS相乘,得到上下文注意力加权后的帧级分类激活序列,然后采用式(3)聚合平均得到视频级别的分类得分,并且在类别维度进行softmax运算,得到预测的视频动作分类分数。利用视频级标签ycon和预测值计算上下文分类损失函数。计算公式为:
2.5 动作定位
获取到动作注意力分数attins和动作注意力加权后的帧级分类分数CASins后,首先过滤掉attins和CASins中低于预设阈值的部分,然后选择剩余连续片段产生动作提议(ts、te、c、φ),表示动作开始时间、结束时间、预测类别以及置信度分数。置信度分数的计算方式参照文献[20],利用每个动作提议的内部和外部区域得分比较产生置信度。实验过程中采用设置多个阈值的方式增加动作提议数量,并引入非极大值抑制重叠程度高的提议。
2.6 网络训练
模型采用视频级分类损失函数Lcls、注意力引导损失函数Lguide以及稀疏注意力损失函数Lsparse进行训练。最终损失函数表示为:
式中:α1、α2、α3、α4、β1、β2为平衡整体损失项的超参数;Lcls由视频级动作分类损失、背景分类损失、半软分类损失和上下文分类损失构成。
注意力引导损失利用动作注意力作为帧级监督优化视频分类模型,使分类激活序列与动作注意力趋于一致,有助于产生更加准确的动作分类结果。计算公式为:
稀疏注意力损失分别对动作注意力和上下文注意力进行L1 范式运算,并将二者的值相加取时域平均值。计算公式为:
式中:attins(t)、attcon(t)分别表示时间段t的动作注意力和上下文注意力分数;T为视频片段数。
3 实验方法与结果分析
3.1 实验环境
使用PyTorch 1.7 框架,实验设备为NVIDIA GeForce GTX 1660Ti GPU,使用Adam 优化器。
3.2 数据集
为验证所提方法对视频动作定位的有效性,本文在THUMOS14 数据集[23]和ActivityNet1.3 数据集[24]上进行消融实验和比较实验。THUMOS14数据集中训练集包含2 765个修剪视频,验证集包含200 个未修剪视频,测试集包含212个未修剪视频。选取验证集用于模型训练,测试集用于测试模型性能。视频一共包含20 种不同类别的动作,平均每个视频包含15.5 个动作实例,视频中超过70%的帧为上下文帧和背景帧。
ActivityNet1.3 数据集中包含10 024 个未剪辑视频用于模型训练,4 926 个未剪辑视频用于模型性能测试。视频一共包含200 种不同类别的动作,平均每个视频包含1.6个动作实例,其中约36%的视频帧属于上下文帧和背景帧。
3.3 评价指标
采用在不同 IoU 阈值下的平均检测精度(mAP)进行动作定位的准确性评估,其中THUMOS14 数据集的阈值IoU 范围为0.10~0.70,间隔为0.1;ActivityNet1.3 数据集的阈值 IoU 范围为 0.50~0.95,间隔为0.05。
3.4 消融实验
为验证在动作—背景注意力分支中加入半软注意力对于模型识别动作特征不明显视频帧的改善效果,在THUMOS14 数据集上进行第一组消融实验。在基线对照组的基础上加入半软分类损失,分别计算模型在IoU 阈值为0.5 时的mAP 和动作漏检率,其中漏检率为视频中未被成功检测为动作帧的个数与全部动作帧个数的比值。实验结果如表1 所示。可以看出,与基线实验1 和实验2 相比,加入半软注意力后(实验3)的mAP@0.5 分别提高了11.7%和4.3%,动作漏检率分别降低了7.1%和3.6%,说明半软注意力可以提高模型对特征不明显动作帧的识别效果。
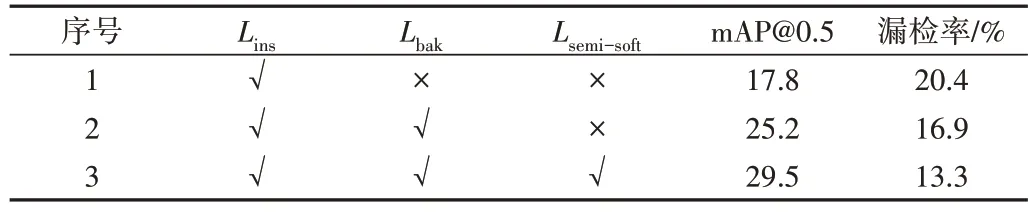
Table 1 Result of first ablation experiment表1 第一组消融实验结果
为验证加入上下文注意力对于模型识别动作帧和上下文帧的改善效果,在THUMOS14 数据集上进行第二组消融实验,计算模型在IoU 阈值为0.5 时的mAP,结果如表2所示。可以看出,与基线实验1 和实验2 相比,单独加入上下文注意力(实验4)后mAP@0.5 分别提高了12.0%和阈值为0.5 时,本文模型在THUMOS14 和ActivityNet1.3 数据集上的平均检测精度分别达到32.6%和38.6%,优于其他弱监督动作定位模型,验证了基于注意力机制上下文建模方法的有效性。4.6%;与实验3 相比,在半软注意力基础的上加入上下文注意力(实验5)后mAP@0.5 提高了0.8%。图4 为模型引入全部分类损失后CAS 和动作注意力加权后CAS 的分布情况,可以看出动作注意力抑制了原始CAS 数值。表2 和图4 数据证实了上下文建模可以区分视频动作帧与上下文帧。
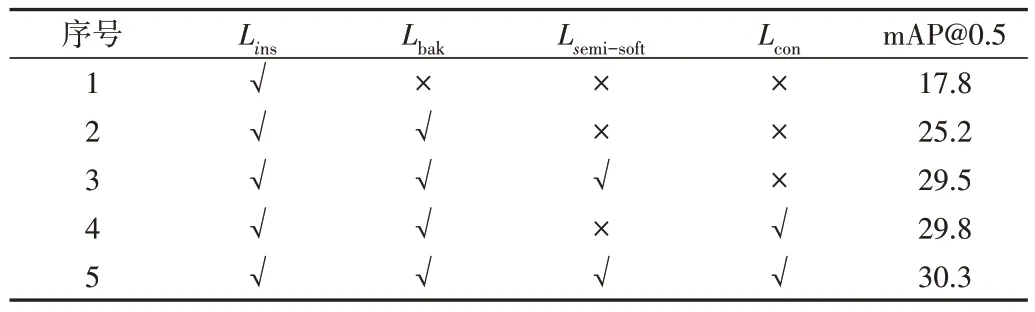
Table 2 Result of the second ablation experiment表2 第二组消融实验结果
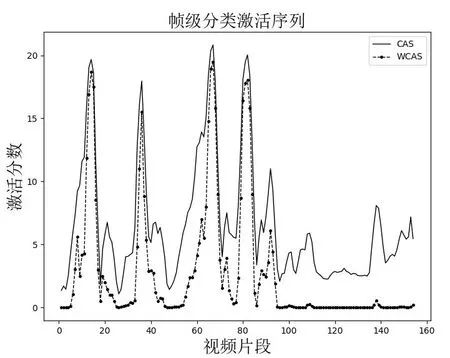
Fig.4 Distribution of CAS图4 CAS分布情况
为验证注意力引导损失Lguide和稀疏性损失Lsparse对模型注意力值分布的优化效果,在THUMOS14 数据集上进行第三组消融实验,结果见表3。可以看出,同时引入Lguide和Lsparse后,mAP@0.5 达到32.6%,证明了两种损失函数对动作定位的有效性。
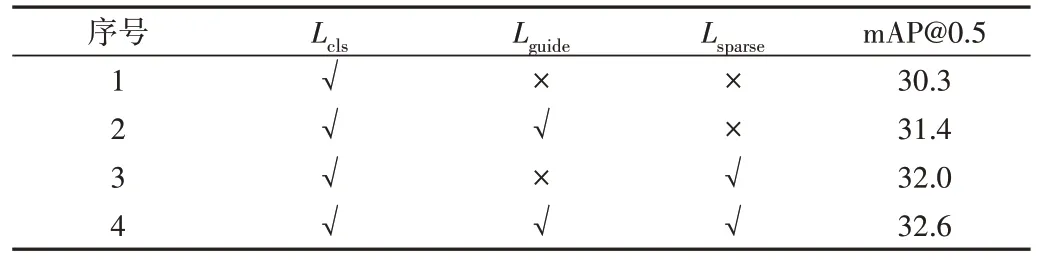
Table 3 Result of the third ablation experiment表3 第三组消融实验结果
3.5 与其他模型的比较实验
在THUMOS14 数据集上与W-TALC[8]、HAM-Net[9]、DGAM[11]、ACS-Net[18]、BasNet[25]、A2CL-PT[26]、CoLA[27]等弱监督动作动作定位模型的定位效果进行比较,在ActivityNet1.3 数据集上与STPN[10]、BasNet[25]、A2CL-PT[26]、MAAN[28]、TSM[29]、TSCN[30]、Huang et al[31]等弱监督动作定位模型的定位效果进行比较,结果见表4、表5,表中AVG 指间隔0.05 取得的mAP 平均值。可以看出,当 IoU
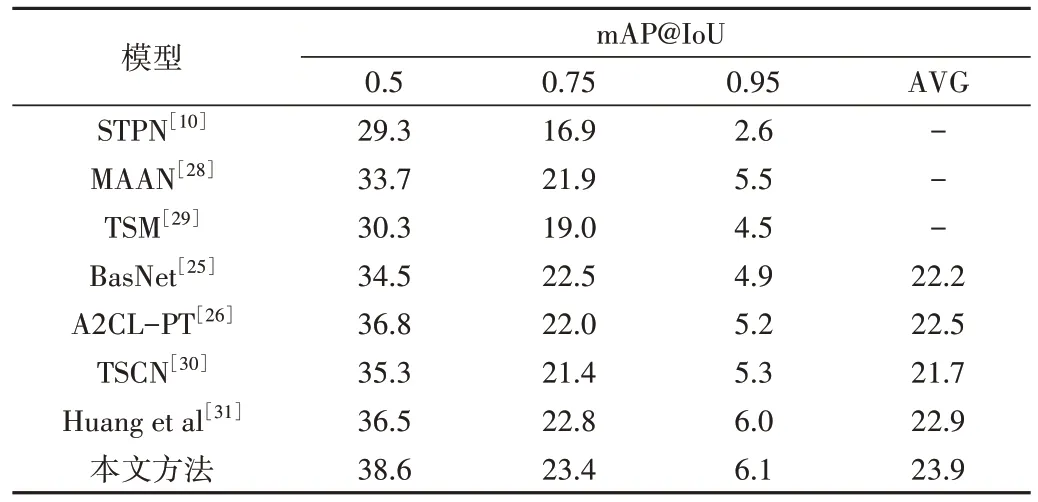
Table 5 Comparison mAP values of different models on ActivityNet1.3 dataset表5 不同模型在ActivityNet1.3数据集上的比较
4 结语
为解决弱监督动作定位方法对特征不明显的动作帧难以识别以及动作—上下文帧易混淆的问题,本文提出一种基于注意力机制上下文建模的动作定位模型,在公共数据集THUMOS14 和ActivityNet1.3 上与主流弱监督动作定位模型的定位效果进行了比较,发现在IoU 阈值为0.5 时,本文模型的mAP 值均高于其他比较模型,证实了引入半软注意力可以引导模型检测到特征不明显的动作帧,通过上下文注意力对上下文信息建模可以分离视频中的动作—上下文帧。未来考虑设计细粒度的上下文建模方法,以进一步提高模型的动作定位效果。
