面向多源异构数据库的SQL解析与转换方法研究
2024-01-02练金栋岳文静吕伟初
练金栋,陈 志,岳文静,赵 培,3,吕伟初,3
(1.南京邮电大学 计算机学院;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003;3.金篆信科有限责任公司,江苏 南京 210012)
0 引言
随着数据量的爆发式增长,传统的单一数据库模式愈发难以满足存储和查询的实时性要求。数据结构呈现多样化趋势,多种存储类型的数据库并行交互[1-2],各行业内部出现不同部门存在数据壁垒、数据共享消耗大量资源、数据流转和融合处理成本上升、数据一致性难以保证等问题[3]。为了满足各行各业对数据应用的需求,企业开始根据自身业务特点,采用多种数据库产品管理业务数据,形成了不同技术解决不同场景应用问题的局面[4]:企业会以Oracle、MySQL、PostgreSQL 等多个主流数据库管理数据;各部门的数据会以CSV、XML、JSON 等不同文件类型分别进行存储;各类实时业务会采用HBase、MongoDB、Neo4J 等数据库进行数据处理与分析。研究表明[5],每个企业应用程序至少都涉及两到三种不同类型的查询系统,许多现实的分析业务也提出了便捷、高效地执行跨平台查询的需求。针对这一情形,研究人员开展了大量针对多源异构数据库的跨平台、统一操作技术的研究[6-7]。
然而,与数据库系统的快速发展相对的,已有的异构数据库集成操作在易用性、统一性与高效性方面都存在一定的不足[8-10]。首先,现有工作尚未提供一个适用于跨平台查询的统一的SQL 查询语言,易用性不高;其次,由于异构数据库不同的特性和各异的语法规则,数据库之间的相互访问需要通过编写数据转换接口来实现,学习成本高且工作量大,扩展性不足。此外,现有工作大多只能针对单一的跨平台SQL 査询进行优化,可能严重影响跨平台查询性能。
为了解决以上问题,本文开发了一套高效、灵活且具有跨平台特性的多源SQL 解析转换方案。该方案设计了一种能描述异构数据库执行逻辑的中间表示模型,通过该模型来隐藏底层库的差异性,从而实现对异构数据库的统一解析建模和映射转换,满足多种数据集中存储、查询和修改的业务需求,提高数据处理效率和灵活性。
1 相关工作
SQL 和NoSQL 数据库都有着各自的适用场景,并能满足特定的数据需求与应用目标,因此将多种SQL 与NoSQL数据库进行集成,实现异构数据库的统一管理和互操作,可以让不同数据库系统在功能方面进行有机结合,发挥各自的优势,从而利于提升数据处理效率,灵活应对各种类型数据的查询需求[11]。
目前的研究成果主要集中在SQL 与NoSQL 的集成融合系统以及支持数据相互访问的标准化API 上。文献[12]通过将key-value 数据转换合并到关系模型,实现利用PostgreSQL 对MongoDB 进行操作,证明了在关系型和NoSQL 数据存储上集成统一操作的可能性;文献[13]提出基于SQL 模型的映射算法,通过SQL 查询扩充来实现每个SPARQL 代数运算符,并生成高效的SQL 查询;文献[14-16]通过设计模式映射和查询映射方法,实现了关系型数据库与RDF 平台的互操作。但此类研究只简单堆积了少数SQL 和NoSQL 数据库,仅适用于涉及两三类不同数据库的小型业务,不具备通用性。另一些研究进一步尝试设计统一适配器的方式,通过向统一数据中间模型动态提供适配数据,实现异构数据库的SQL 统一查询。文献[17]提出一种为每种SQL 语句定制正则表达式的方法解析SQL,并通过扩展XQuery 实现对MongoDB 数据库的操作;文献[18-20]通过将关系表、键值对、CSV 文件、JSON 文件等结构化与半结构化数据转换为临时关系表结构,以单一数据库语法操作实现多数据源的统一查询。此类方法的局限性在于要求在异构数据库之间设计数据转换接口,以实现相互访问,工作量大,扩展性很差。
本文对上述方案的设计思想和方法进行参考与总结,设计了一套通用的异构数据库解析转换方案,通过设计统一中间表示模型来隐藏异构数据库在查询语言和数据格式上的差异,实现多种关系型和NoSQL 数据库的统一解析与转换,生成统一的逻辑查询计划实现底层库的操作请求,同时保证了较好的可扩展性。
2 基于SQL语法的中间表示模型
由于Oracle、MySQL、DB2 等基于ANSI-SQL 标准开发的关系型数据库仍被广泛应用。本文采用以SQL 语法为基础、引入多种NoSQL 语法模型的模式设计异构数据库的中间表示模型。该模式降低了数据模型之间的开发和维护成本,并为满足特定业务需求提供了更强的灵活性。
2.1 异构语法转换模式
由于不同数据库系统的数据存储模型不同,在数据命名、数据类型、数据结构方面存在差异[21-22],需要设计不同语法模型之间的转换策略。如图1(a)所示的传统多对多转换模式,两个异构数据库之间直接进行数据转换,转换效率高,但n 个异构数据库节点的双向操作必须编写n*(n-1)个数据转换器。如果新增一个异构数据库类型,则需要开发2n 个转换器,导致开发维护成本高、可扩展性差。
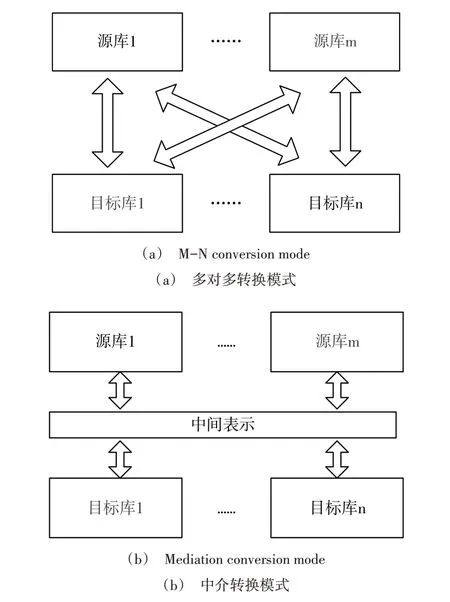
Fig.1 Grammar conversion mode图1 语法转换模式
本文采取图1(b)所示的中介转换模式,即通过设计一种中间模型,为所有的数据库指令提供统一的元数据描述格式,并通过转换器实现从源库数据转换为中间模型、再由中间模型转换为目标库数据的间接转换模式。该方案仅需编写2n 种转换器,当增加、修改一个数据库存储模型时,只需编写新数据库模型与通用模型的语法转换器,其它同步节点的数据转换模块保持不变。该模式屏蔽了底层数据库之间的差异,极大地降低了开发难度,并考虑了一定的扩展性。
2.2 中间表示模型设计
中间表示模型在解析SQL 语句对数据集合的计算操作后,以结构化形式描述SQL 各个子句语法块。模型参考文献[23-25]的设计框架,以实体(Entity)作为对所有SQL语法块的统一描述,并将部分实体进一步划分为语句(Stmt)和表达式(Expr)。即:
Stmt 实体存储SQL 语句执行计划的基本步骤,Expr 实体存储执行计划的具体数据,其他实体负责对Stmt 和Expr作进一步描述。统一的中间表示模型的形式化表示如下:
其中,Type 表示实体类型,Stmt 实体类型包括INSERT、SELECT、CREATE_TABLE,Expr 实体类型包括Numeric、Literal、Logical 等;Field 表示一系列实体集合,即当前实体的所有子句类;Attribute 表示实体内部属性,即SQL请求的元数据信息;实体关系Relation∈(Entity×Entity)用于描述实体间的语义关联,包括字符常量与数据表(Table)、数值与数据结构(Datatype);Map 表示此实体的映射转换方法。
以查询语句的From 子句为例,在标准 SQL 语句中,From 子句既可以由单个引用表实体组成,又可以由多个引用表实体通过各种形式的连接(Join)构成:
其中,tableSource 实体用于描述引用表,即参与数据查询的关系表结构,按连接关系分为tableSourceL和tableSourceR。joinType 是一个枚举(Enum)属性,代表Join连接操作类型,包括INNER_JOIN、LEFT_JOIN、RIGHT_JOIN 等。condition 是Expr 实体的子类,用于描述SQL 语句的可嵌套逻辑关系式,在fromClause 实体中用于指定tableSourceL和tableSourceR的连接条件。其形式化表示为:
其中,logicalExpr 和comparisonExpr 分别表示可嵌套的逻辑表达式与关系表达式,在SELECT、UPDATE、DELETE等操作中指定数据筛选条件,通过运算符优先级进行划分。一个logicalExpr 可以由一个comparisonExpr 组成,也可以由若干可嵌套逻辑表达式(nestedLogicalExpr)和逻辑运算符号(AND、OR 和NOT)组合构成,以筛选出符合指定逻辑规则的数据行。logicalExpr 的形式化表示如下:
其中,comparisonExpr 用于根据特定条件比较两个值或列之间的大小关系以筛选数据。形式表达式如下:
其中,compOp 是关系运算符(如=、<、>、<=、!=等)的集合,表示值或列的比较方式;unaryExpr 实体用于表示计算表达式以及对象名、变量、常量等,是SQL 标准语句中的基本参数。其形式化表示如下:
以上实体构成了Expr 的形式化表示,其中一元表达式的value 代表整数、浮点数、字符串、标识符等,用Java 包装类型进行存储;unaryOp 是正负号、引号等常规符号的集合;dataType 表示literal存储数据的数据类型。
3 面向多源异构语法的统一SQL解析转换器
面向多源异构语法的统一SQL 解析转换器参照传统数据库的编译流程,将解析与转换功能划分为语法解析器、语义分析器、语法重构器、查询优化器等组件,执行流程如图2所示。首先根据语法文件生成SQL 语法的词法和语法分析器,组成语法解析器;然后将SQL 语句输入对应的语法解析器,生成抽象语法树(Abstract Syntax Tree,AST);接下来使用语义分析器遍历访问抽象语法树,提取特征信息,封装为中间表示模型并进行语义分析;语法重写器根据前台指定的目标库类型,选取相应转化策略对中间模型进行映射,使其转换为能在目标平台执行的逻辑执行计划;最后,执行优化器可以对逻辑执行计划作进一步优化处理,以提高可执行性。

Fig.2 SQL parsing and conversion process图2 SQL解析转换流程
3.1 语法解析器
语法解析器(Syntax Parser)由ANTLR 工具生成的词法分析器(Lexer)和语法分析器(Parser)组成,负责在语法规则的支持下,经过词法解析和语法解析将查询语句编译成AST 结构。以SQL 语法为例[26]:词法分析器负责分析词法结果,即通过拆解SQL 语句将输入的字符序列分解成词法符号(token)序列。其中,token 是语法的基本词汇符号,可分为5 种类型:①保留字(keyword)。由固定字符序列组成,如select、table、case 等;②标识符(identifier)。如常量名、表名、属性名;③文字常量(literal)。包括25、4.14、4e3等数字常量,以及“abc”“cid”字符串;④运算符(operator)。常用的包括算术运算符(+-*/)、关系运算符(<,>,<=,!=)和逻辑运算符(NOT、AND、OR);⑤分隔符(separator)。如小括号、中括号、逗号等,负责对标识符进行规范。语法分析器则通过检查token 的序列结构是否符合语法规则,判断语句是否合法,并把token 按照语法规则进行模式匹配,组装成AST 结构。
3.2 语义分析器
语义分析是编译过程中的一个逻辑阶段,负责收集抽象语法树标识符的属性信息并与节点绑定,审查SQL 查询请求有无语义错误,例如库表、列名是否存在,列的数据类型是否正确,为逻辑计划树生成收集类型信息。
语义分析器(Semantic Analyzer)通过ANTLR 提供Visitor访问模式按深度优先顺序遍历语法分析树,通过显式的方法调用来获取子节点信息,生成逻辑执行树结构。具体算法如下:
算法1语义分析算法
算法1以深度优先、自底向上的顺序对AST 进行遍历,将语法树节点与元数据绑定,引入2.2 节建立的中间表示模型,同时结合上下文进行语义分析。对于整数、字符串及复合表达式等Expr 实体,算法按类型判断参数类型是否匹配、逻辑是否有歧义、是否超出变量范围等,接着按照具体值域类型生成继承表达式类;对于增删改查等Stmt 实体及其内部元素,算法先判断是否存在重复声明属性、形参与实参不匹配、属性不存在等语义错误,再根据具体SQL语句类型和子句类型封装语法块的语义。最终逻辑执行树能完整描述SQL 的逻辑执行步骤。
以查询请求“SELECT * FROM people WHERE status="A" ORDER BY user_id DESC”为例,划分SQL 各语法块并通过分析可知:查询实体为people 表,以status="A"为筛选条件获取实体所有属性,并将结果集根据user_id 列递减排序。算法1 生成的中间表示对应的JSON 格式化描述如下:
在语义分析与实体封装过程中,模块判断people 表是否存在,以及是否存在status、user_id 等表属性、status 属性是否为varchar 类型数据等。此外还会检查user_id 是否为people 表索引,若是,则在Query 语义树中标记其索引名为“user_id”以及对应的索引类型。
3.3 语法重写器
语法重写器(Syntax Rewriter)负责接收语义分析器生成的逻辑执行树,若目标数据库为关系型数据库,则可通过transform 转换策略将中间表示内部属性、变量进行修改,实现源实体entitysrc到目标实体entitytarget的转换。以Oracle 到MySQL 的转换为例,部分转换策略如表1所示。
若目标数据库是NoSQL 类型,则将中间表示转换为对应的NoSQL 语法。SQL 与NoSQL 的部分对象映射关系如表2 所示。关系型数据库的表、列、属性和数据对象分别与NoSQL 数据库MongoDB 的集合、文档、字段、值等数据结构对应。
在分析器生成SQL 的逻辑查询树后,通过此映射关系将SQL 数据一一转换为NoSQL 形式,以实现SQL 逻辑执行树的重构。以MongoDB 为目标对象,其转换算法如下:
算法2模型转换算法
3.4 查询优化器
若目标数据库是关系型,则调用查询优化器(Query Optimizer)对目标SQL 请求进行优化。查询优化器采用基于规则的优化(RBO)方式定义一系列优化规则,包括列剪裁、最大最小消除、投影消除、谓词下推、Join 消除等,优化规则与表1 原理一致。优化器搜索过程可视为根据指定的优先顺序循环判断SQL 各语块是否匹配优化格式(Pattern),若符合则按照优化规则(Rule)对SQL 语句进行优化,并重新进入循环,直到没有可以匹配的语块,从而完成优化。
以“获得满分成绩的学生查询”为例,常用的SQL 写法为:SELECT * FROM Student t,Grade g WHERE t.S_id=g.S_id AND g.score=100。该Select语句对应的关系代数为:
根据代数式可知,语句在执行时数据库会先全表扫描全部的Student 学生信息表和Grade 学生成绩表,然后才根据where 条件进行筛选,因而提高了查询计算量。这种情况可以通过谓词下推,将过滤条件表达式(如=、!=、like、in、between 等)尽量靠近待过滤的数据源(Student 表和Grade 表),即先将通过过滤条件“grade=100”筛选Grade 表中的数据,再进行连接操作,以达到优先过滤无用数据、提升SQL 执行效率的目的。对应关系代数为:
转换成对应语句为:SELECT * FROM Student t1 RIGHT JOIN(SELECT * FROM Grade WHERE grade=100 )t2 ON t1.S_id=t2.S_id。转换前和转换后的关系表达树如图3所示。
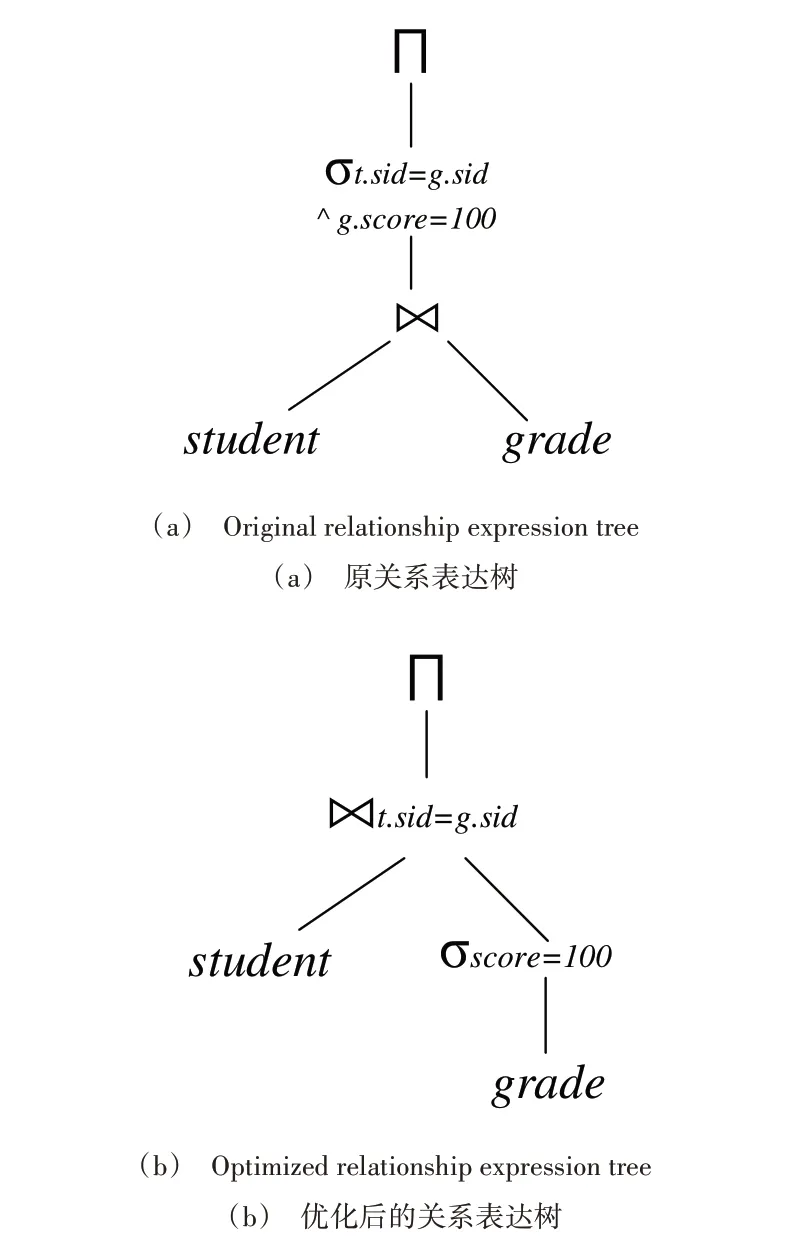
Fig.3 Query optimization -predicate pushdown图3 查询优化—谓词下推
如图3 所示,在数据库执行查询操作时,逻辑执行计划根据关系表达树中的操作符逐步向上计算,直到根节点(整个表达式)的计算完成。因此,通过谓词下推,数据库在内查询时就先过滤了Grade 表中的大部分无用数据,极大地减少了临时表的空间开销,提高了查询效率。
4 实验与结果分析
为验证面向多源异构数据库的SQL 解析转换器在实际开发环境中的应用,本文基于方案实现了一个多源异构数据库的统一操作系统,旨在检验解析转换器在异构数据库间跨平台访问的可靠性、正确性和高效性。功能测试主要验证查询系统在多源异构、跨平台环境下数据库对基本操作的支持度,以及核心查询业务的可靠性,性能测试主要验证解析转换器基本增删改查操作的性能。
4.1 环境配置
操作系统以Java 编程平台作为运行平台,分别使用Oracle、MySQL 和MongoDB 存储关系型和非关系型数据,并基于TPC-H 基准测试数据集进行功能测试和性能测试,实验中针对不同测试单元对数据集进行相应处理。具体实验环境参数如表3所示。
Table 3 Environmental configuration table表3 环境配置表
4.2 功能测试
4.2.1 数据类型支持度
为测试本系统对各结构化、半结构化数据的支持度,先导入完整的包含各种类型的测试数据集(所有数据均不包含NULL 和NAN 值)。为维护执行效率,各底层库随机导入数据集数据1万条,再使用简单的query操作语句对数值型、字符型和时间日期型数据进行查询与解析,检验最终的返回结果是否与映射表相符,以及是否存在非法值或缺失。其中,数据类型映射基于SQLines 技术文档(Oracle映射至MySQL 类型映射表:http://www.sqlines.com/oracleto-mysql)进行整合,部分映射如表4所示。

Table 4 Data types mapping表4 数据类型映射
经自定义函数对查询结果进行数据统计和异常值检验,最终的实验结果表明,系统支持对所有已集成数据库的数据类型进行解析、存储和映射转换。
4.2.2 操作类型支持度
本系统已集成的数据库有Oracle、MySQL 和MongoDB,本节测试其对于SQL 各种操作类型的支持度。实验涉及的SQL 语句主要面向与具体数据操作相关的环境,所以在实验论证中只对关系型数据库的部分DDL 语句和DML 语句,以及NoSQL 的标准CURD 语句进行实验验证。实验分别在Oracle、MySQL 及MongoDB 数据库创建相应的数据集,并对多源异构数据执行增删改查操作。实验结果如表5所示。
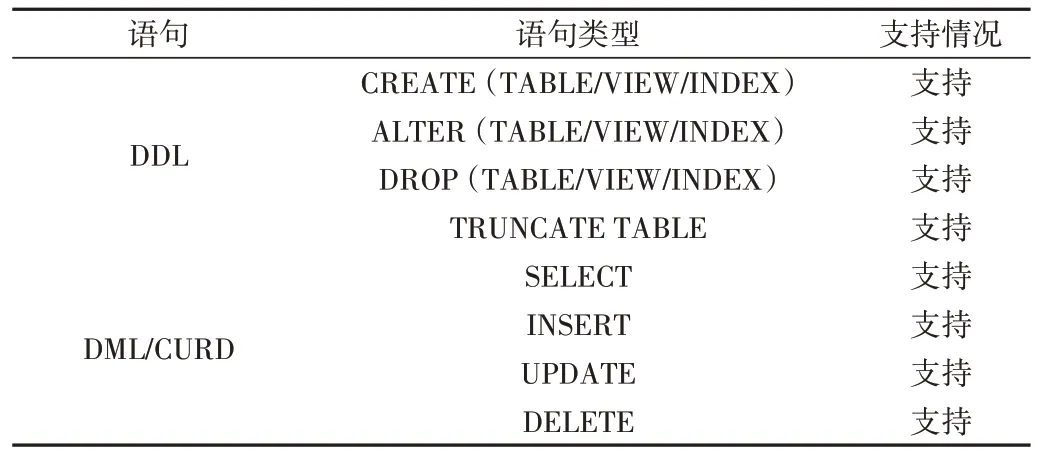
Table 5 Support for SQL statement表5 对SQL语句类型支持情况
其中,NoSQL 的CURD 操作对应关系型数据库的DML语句。MongoDB 的数据存储类型是BSON 文档,可以通过insert()、update()、delete()方法动态指定集合(Collection)、文档(Document)内部field 的数据类型。因此,MongoDB 对数据存储对象的DDL 操作不纳入测试。由表5 可知,解析转换器支持所有常见关系型数据库之间的DDL 与DML 互操作,以及关系型与NoSQL 的CURD 互操作。
4.3 性能测试
性能测试通过将系统与官方的mongo-jdbc 插入、删除、更新和选择操作的时间开销进行对比,以评估多源异构解析转换器的SQL 覆盖率和各项访问操作的性能。为有效评估解析转换器的跨平台访问性能,本节引入MongoDB 官方推出的mongo-jdbc 驱动插件,使用SQL 对MongoDB 进行异构访问,分别让MongoDB 数据库、mongo-jdbc和测试系统执行1 000 次INSERT、UPDATE、DELETE 与SELECT 操作,测试结果如表6 所示。其中,每个操作对应的执行时间为执行的平均时间,单位为毫秒(ms)。
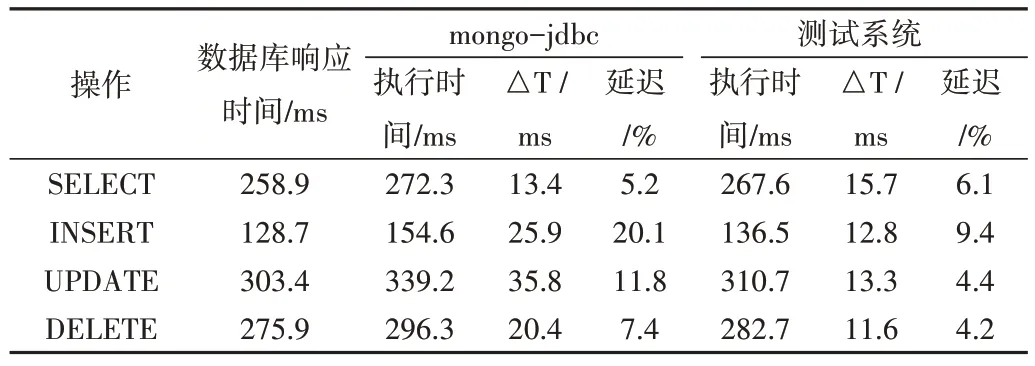
Table 6 Comparison of CURD performance testing表6 CURD性能测试结果对比
实验数据表明,查询系统在CURD 操作方面的总体性能优于mongo-jdbc。在同等条件下,测试系统执行CURD操作的响应时间较官方工具分别快了13.1 ms、8.8 ms、22.5 ms 与2.3 ms。其中,由于INSERT 操作的平均单次响应时间较短,因此延迟率高,但平均响应时间仅为mongojdbc 的49%。在SELECT 查询操作上,系统较官方驱动程序平均仅快2.3 ms,没有明显优势,主要由于相较于增删改操作,查询样例涉及嵌套查询、连接表、过滤条件式等复杂的query 业务,在解析优化和底层执行方面开销更多,因此平均执行和响应时间更长。
以上结果表明,面向多源异构数据库的SQL 解析转换器相较于mongo-jdbc 有着更优异的性能,且其运算成本始终保持在一个固定范围内,与操作类型无关。实验结果证明,面向多源异构数据库的SQL 解析转换器在功能和性能方面可满足预期需求,有效实现了对多个异构数据库的集成操作,且能保证一定的正确性。
5 结语
本文提出一种满足跨平台统一查询需求的SQL 解析和转换方法,详细设计了一系列查询语言的适配存储结构和语义一致性转换及性能优化策略,允许用户在异构关系数据库和NoSQL 数据库上进行准确、可靠的SQL 操作,屏蔽了不同执行平台间在语法逻辑、底层机制方面的差异,将多个异构数据库转换为一个统一的模式,并通过设计测试系统进行功能和性能验证,证明了解析转换器的可行性。实验结果表明,面向多源异构数据库的SQL 解析和转换方法在满足多源异构数据库跨平台访问功能需求的同时,还具有较好性能,且在集成系统的多对多数据访问环境下具有良好的可扩展性和准确性。
由于条件和时间限制,本文仍有诸多不足,有待进一步研究和改进,主要改进方向有:①增加对更多异构数据库的适配访问和操作业务支持。目前跨平台解析转换方案仅实现了对Oracle、MySQL 和MongoDB 等若干数据库的支持,对数据和事务的一致性支持尚不够全面,难以支持复杂的业务操作;②提升跨平台解析转换方案面对真实海量数据处理业务的性能。实验的测试数据在数据规模和复杂度上与真实业务差距较大,需要将方案置于接近真实海量数据环境中进行测试与改进;③进一步完善跨平台执行优化模块。目前优化器主要基于传统经验编写一系列静态策略以实现查询优化,在开发和使用效率上具有局限性,可以引入基于代价的优化(CBO)算法,获得所有等价的重构变换方案,进一步提升查询性能。
