基于改进决策树的充电桩故障预测方法
2023-12-30袁单刘鸿鹏陈良亮窦真兰
袁单, 刘鸿鹏, 陈良亮, 窦真兰
(1. 东北电力大学 电气工程学院现代电力系统仿真控制与绿色电能新技术教育部重点实验室,吉林 吉林 132012; 2. 南瑞集团(国网电力科学研究院)有限公司,江苏 南京 211106; 3. 国网上海市电力公司,上海 200433〕
0 引 言
随着国家政策的大力支持和电动汽车的大量普及,电动汽车充电桩的数量增长迅猛[1]。然而,当前国内的充电站多呈现出数量多和位置分散等特点,并且多数充电站经常处于无人值守或者少人值守的状态,这给充电桩的日常维护工作带来了巨大的挑战[2]。
大数据技术的发展给充电桩的故障预测以及维护工作提供了新的解决思路。通过对充电桩以往运行数据的处理和分析,可以挖掘出充电桩的故障规律,以此来预测故障的发生[3-4]。从而,使得充电桩的日常维护工作更加方便和智能,大大降低充电桩的维护成本[5]。基于决策树的故障预测是一种典型的数据挖掘方法,由于其具有计算简单、可解释性强和预测效果好的特点,受到了广大学者的关注。文献[6]通过权重系数的引入,解决了C4.5算法可能偏袒属性值较多的属性和计算复杂等问题。文献[7]引入基尼系数,选择信息增益率与基尼系数比值最大的属性作为划分节点,每个节点采用二元划分,提高了分类精度。以上文献均对传统的决策树算法进行优化,然而对预测准确率的提高则是以提高算法计算量为代价实现的,且多数算法的有效性均未在实际工程应用中进行验证。
为此,本文提出了改进决策树的充电桩故障预测方法。通过优化对参数选取的方式,提高决策树预测故障的性能。
1 故障预测原理及模型构建
1.1 基于粒子群的改进决策树算法
决策树算法使用多叉树分类,效率偏低,占用空间较大,无法解决大量的数据。使用二叉树分类运算速度快,但容易陷入局部最优。为此,本文采用CART算法和调整后的ID3算法,将多叉树结构简化为二叉树结构,并选择预测分类效果好的二叉模型进行测试集的预测分类。此外,通过引入粒子群算法,可以优化剪枝,尽可能地正确分类训练样本,减少过拟合现象发生,从而优化决策树模型。
基于粒子群算法改进决策树的运算步骤如下。
(1) 图1为确定的决策树结构。根节点为输入数据,数据通过分类准则遍历每一个特征,选取最优特征进行分类。

图1 决策树基本结构
ID3分类准则:
(1)
(2)
式中:Pk为样本集D中第k类样本所占的比例;|Dv|为数据集D
中所有在特征A上取值为Av的样本总数;k的取值为1和2。
CART分类准则:
(3)
(4)
式中:Ci,D为D中标签为Ci的元组集合;Dj为样本集划分的子集,j的取值为1和2。
(2) 对决策树中的剪枝参数进行范围限定。
(3) 设定适应度函数。
(4) 引入粒子群算法对剪枝参数寻优。寻优过程如下:
在一个D维的目标搜索空间中,有N个粒子组成一个群落,其中第i个粒子表示为一个D维的向量:
Xi=(xi1,xi2,…,xiD),i=1,2,…,N
(5)
第i个粒子的“飞行”速度也是一个D维的向量,记为:
Vi=(vi1,vi2,…,viD),i=1,2,…,N
(6)
第i个粒子迄今为止搜索到的最优位置称为个体极值,记为:
Pbest=(pi1,pi2,…,piD),i=1,2,…,N
(7)
整个粒子群迄今为止搜索到的最优位置为全局极值,记为:
gbest=(g1,g2,…,gD)
(8)
在找到这两个最优值时,粒子根据式(9)、式(10)来更新自己的速度和位置:
vij(t+1)=vij(t)+c1r1(t)[pij(t)-xij(t)]+c2r2(t)[pgj(t)-xij(t)]
(9)
xij(t+1)=xij(t)+vij(t+1)
(10)
式中:c1、c2为学习因子;r1、r2为[0,1]范围内的均匀随机数;vij为粒子的速度,vij∈[-Vmax,Vmax],Vmax为常数。
(5) 由寻优后的参数构建决策树,并预测分类。
1.2 故障预测模型构建
图2为基于粒子群算法改进决策树的充电桩预测故障模型。

图2 基于粒子群算法改进决策树故障预测模型
具体步骤如下:
(1) 预处理,对充电桩特征数据进行分析,进行异常值剔除和缺失值填补工作。
(2) 设置优化目标函数即适应度函数,函数方程为:
fitness(Ti)=acc(Ti)
(11)
式中:Ti为每组参数构建的决策树;acc(Ti)为每棵决策树分类精度。
(3) 设置粒子群算法相关参数以及决策树参数区间。
(4) 将预处理的数据代入决策树中训练,不断更新粒子个体以及群体的速度和相应位置,寻找最优解以及相关适应度的值。
(5) 重复迭代,完成后输出最优解即最优决策树的参数和其代表的适应度的值。
(6) 寻优后的参数代入构建决策树预测模型。
(7) 将测试集和交叉验证集相关数据输入决策树模型进行预测,输出预测结果。
2 仿真结果分析
2.1 数据选取
本文采用2019年百度新手赛充电桩故障检测的数据集。数据集拥有六个特征x1~x6,其中:x1为K1K2开关门禁信号;x2为电子锁驱动信号;x3为紧急停闸电压数值;x4为门禁电压数值;x5为谐波失真的电压数值;x6为谐波失真的电流参数。原始数据包含80 000组数据,故障与正常数据各占一半。每台充电桩设置一个数字编号,以数字“1”和“0”分别代表充电桩处于故障状态和正常状态。随机将每组数据70%设置为训练集,剩余的30%数据设置为测试集。充电桩故障数据示例如表1所示。

表1 充电桩故障数据示例
2.2 模型训练
随机选取100条充电桩特征数据作为训练集构建决策树,如图3所示。
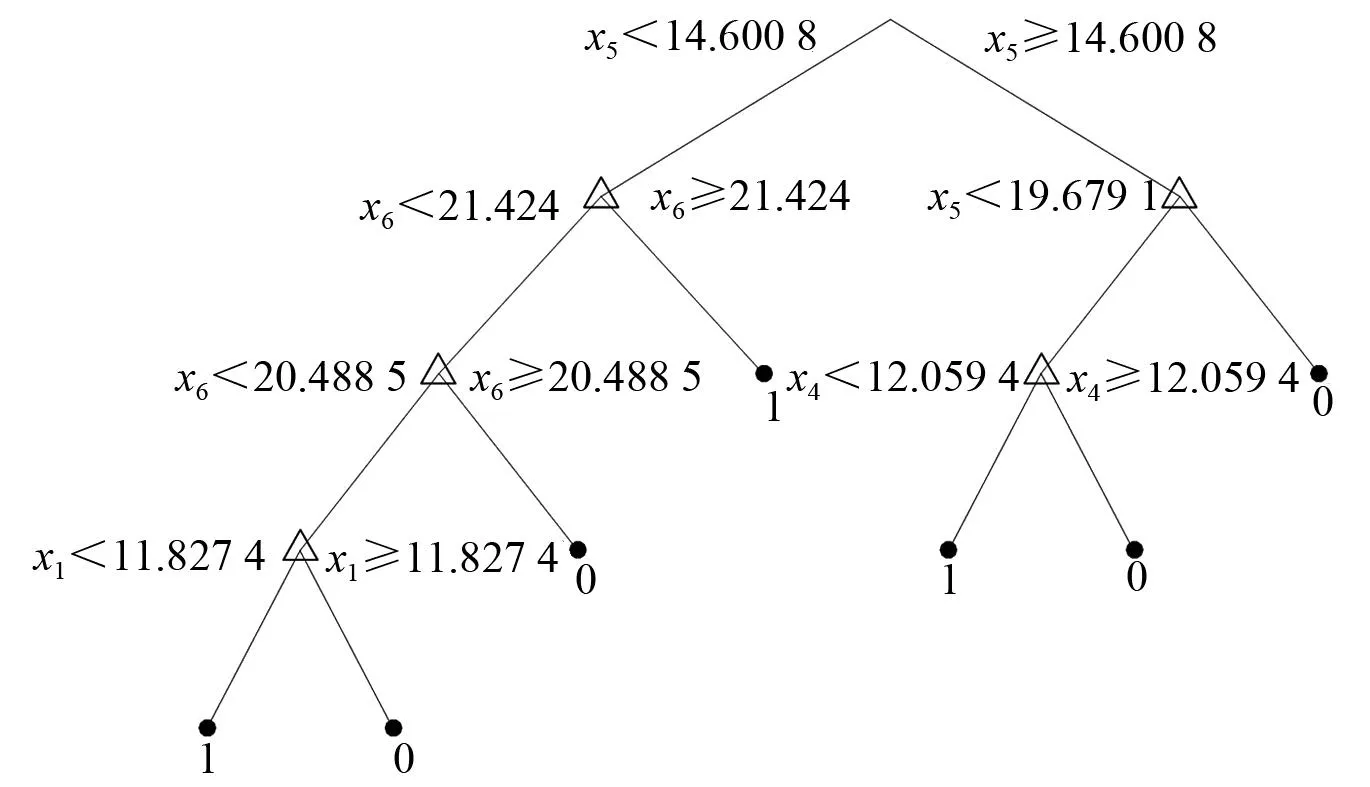
图3 100条训练数据构建的决策树模型
构建决策树后,用测试集数据对决策树进行验证。由构建的决策树模型可以得到充电桩运行特征重要性,如图4所示。x5在决策树分类递归生成模型中起到关键作用,对故障预测有着重大影响。
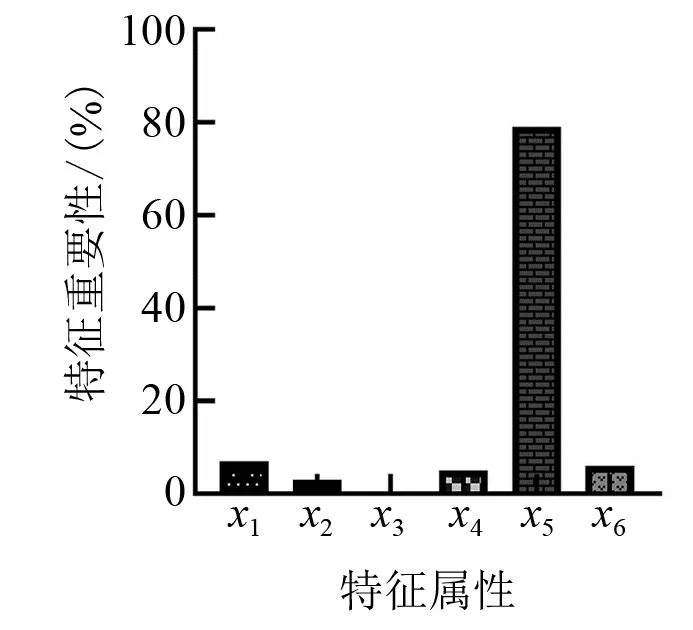
图4 充电桩数据特征 重要性对比图
2.3 预测性能分析
图5为不同数量的数据集使用不同算法的准确率对比。根据对比可知,所有算法预测准确率均超过80%,但改进后的决策树分类准确率更高。另外,随着数据量的增加,所有算法预测准确率都有显著提升,过拟合现象逐渐减少。

图5 各类数据集在不同算法下的准确率对比图
图6~图9为不同数据量下各算法的性能指标。对于精准率指标,交叉验证集和测试集均为100%,训练集稍小但也超过了90%。与ID3和CART相比,改进决策树算法的优势明显,特别是在准确率和召回率两个指标下,性能提升的幅度达到5%~10%。因此,改进决策树算法所构建的分类预测模型较传统决策树模型有更好的分类预测效果。
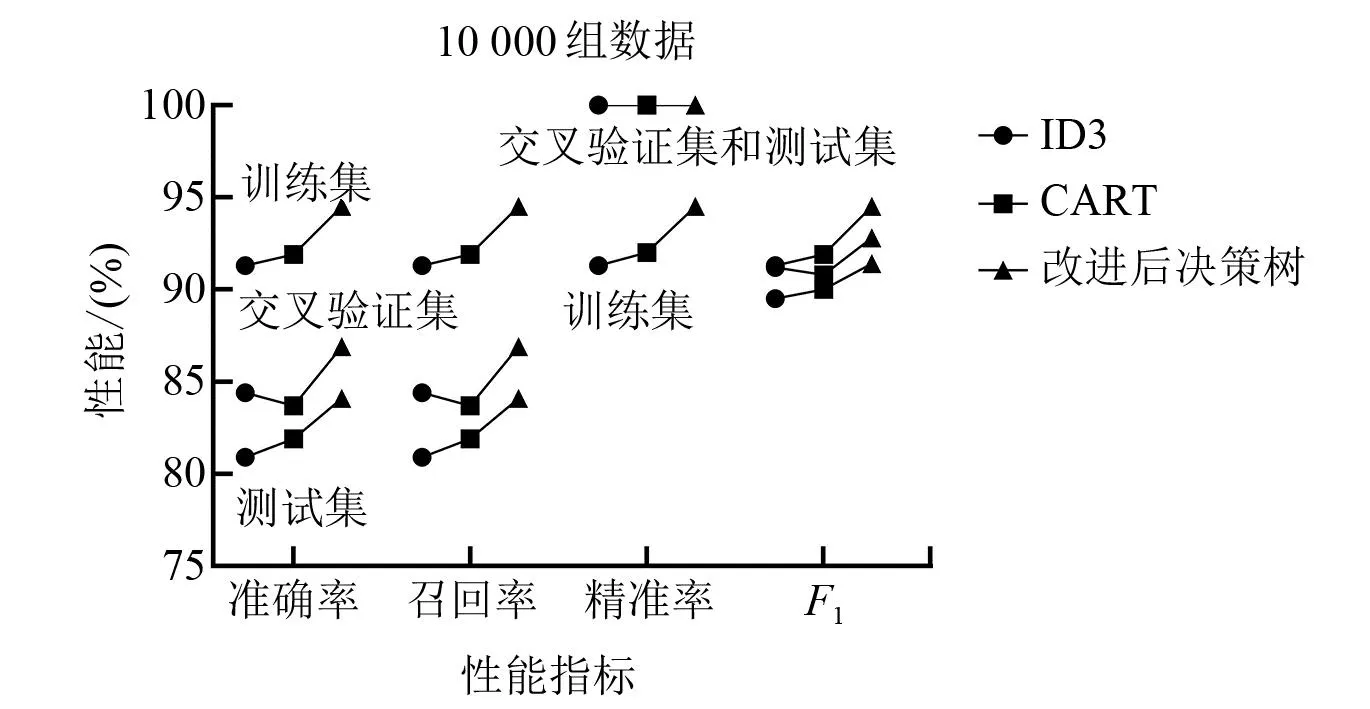
图6 10 000条数据在各算法性能指标对比图

图7 20 000条数据在各算法性能指标对比图
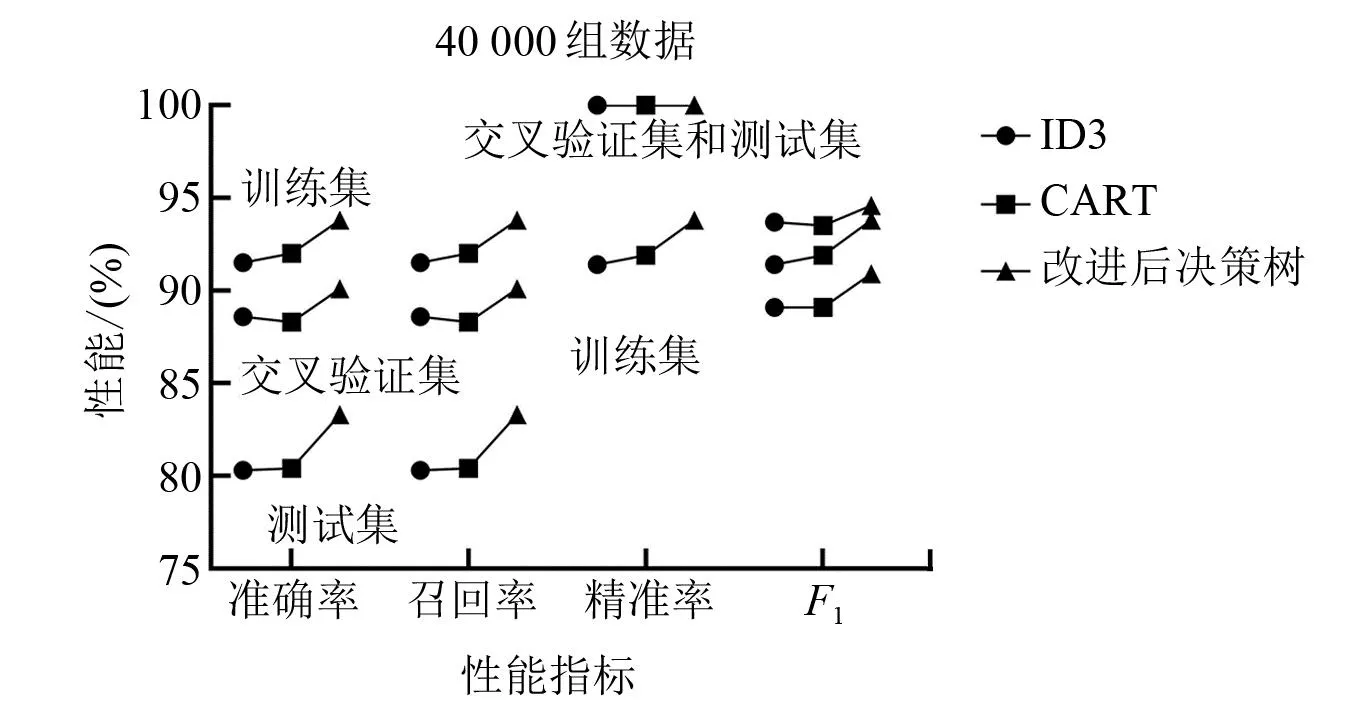
图8 40 000条数据在各算法性能指标对比图
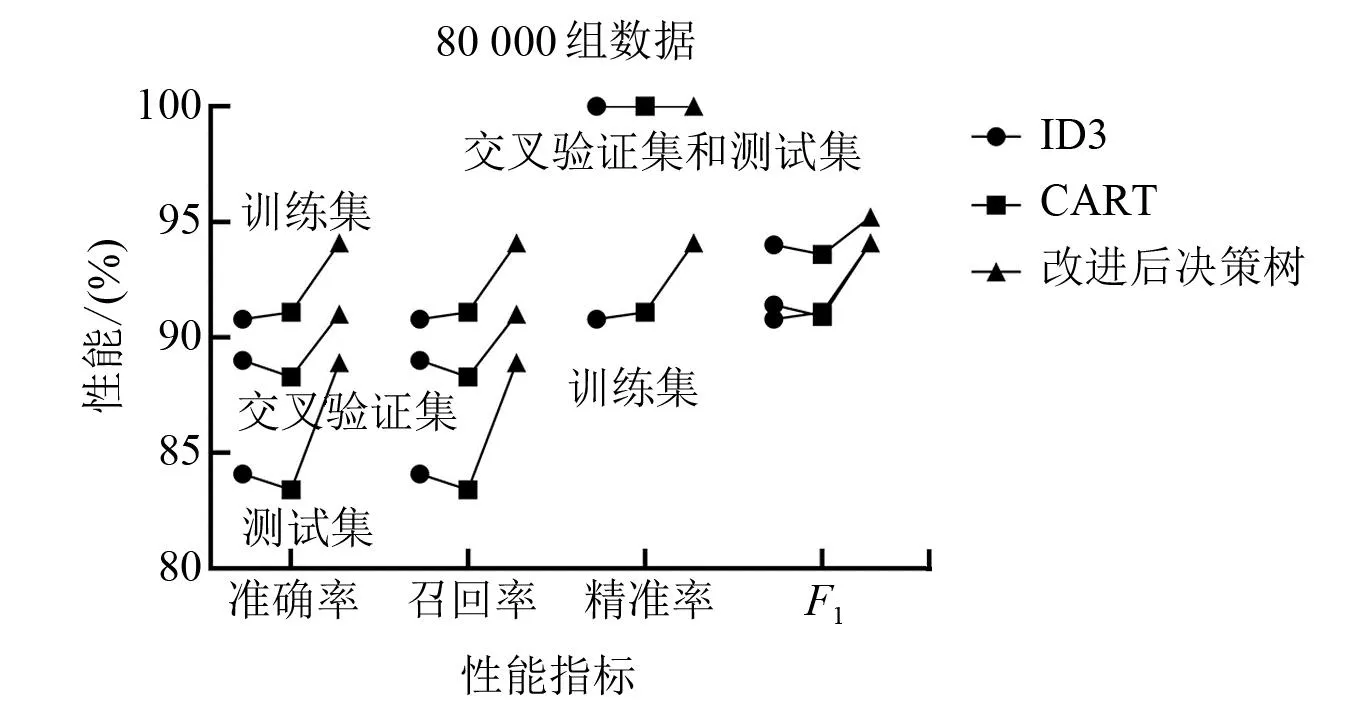
图9 80 000条数据在各算法性能指标对比图
3 结束语
本文提出了一种优化的决策树算法,通过引入粒子群算法优化决策树参数的选取,生成充电桩故障决策树模型,并根据充电桩运行数据训练和验证决策树。仿真结果证明,改进的方法能够合理地选择决策树方法并对树进行剪枝处理,从而提高了模型预测准确性和有效性,减少过拟合的出现。
