基于RFE-RF模型的太原市PM2.5浓度预测研究
2023-12-30李明明杨爱琴
李明明,岳 江,王 雁,陈 玲,杨爱琴
(山西省气象科学研究所,太原 030002)
引 言
细颗粒物(PM2.5)在当今社会严重影响气候、空气质量和身体健康,因此空气质量PM2.5浓度预报的准确性对于政府部门的准确决策及采取环境治理方案都有很重大的意义[1~3]。常用的预报方法包括:统计预报方法主要基于机器学习和数值预报方法主要基于大气物理化学模式[4]。数值预报方法需要有研究区域内详尽的污染源清单及大气物质的相互转换机制的输入理解,而大气系统非常复杂很难完全量化,而且污染源的排放也是时刻变化的[5~6]。基于机器学习的统计预报方法对污染源和化学机制的没有特别的要求[7~8]。太原市作为地处温带季风气候区是典型的北方城市,无论从气候还是从地理特点来说都具有内陆城市典型的特征,有关该地区污染物浓度预报相对较少,且已有的一些预测模型在预测污染物浓度时依然存在各自的一些局限性,尤其是普通的线性模型难以精确模拟污染物浓度与多种影响因素之间的非线性关系,而且很多学者进行了相关非线性方面的研究:李娟等,魏煜员等,芦华等分别基于机器学习方法对西安市、河南省、成渝地区的空气质量数值预报及PM2.5的数值模拟进行了优化研究[9~11]。夏晓圣等、杨瑞君等、杜续等、林开春等、孟倩等、夏润等研究者分别基于随机森林模型开展相关城市的空气质量浓度预测和空气质量分类预测研究[12~17]。郭飞等基于气象因素和改进支持向量机进行了空气质量指数预测[18-19],南亚翔等基于卡尔曼滤波预测空气质量指数[20],刘炳春等基于IG-LASSO模型预测城市空气质量指数[21]。张春露等基于采用LSTM模型对太原市空气质量指数进行预测[22-23]。邱晨、瞿英、田静毅、张珺、马井会等研究者基于BP神经网络的进行空气质量模型分类预测和浓度预测研究[24~28]。总体表明,对于非线性回归预测来说,随机森林、多元线性回归、Lasso回归、梯度提升树、BP神经网络等机器统计预报方法的性能要明显优于传统统计方法[29]。
从上述文献研究来看,空气质量预测的研究的输入变量主要是空气污染物浓度和与其强相关的气象条件[30~33],输出为未来的空气质量或者空气污染指数。而气象条件的选取主要集中在地面气象要素,缺乏高空气象要素的选取,本文提出了基于递归特征消除法(Recursive feature elimination,RFE)和随机森林(Random Forests,RF)相结合的PM2.5浓度预测模型,选取太原市的空气污染物浓度和美国国家环境预报中心(National Centers for Environmental Prediction,NCEP)气象再分析的地面要素和高空要素作为预报因子,建立包括环境监测数据和气象数据的预测数据库,通过RFE特征选取,然后将拣选过的特征作为输入,通过模型对比选用适合于本次研究使用的空气质量数据的随机森林(RF)模型进行预测,输出太原市PM2.5的预测浓度,通过选取最优的RF预测模型应用到日常的环境空气质量预报业务中,将进一步提高太原市PM2.5浓度预报的准确率,同时也为加强太原市的空气污染防治,实现环境综合管理和决策科学化提供了的重要科技手段。
1 材料与方法
1.1 数据来源
(1)空气质量监测数据:太原市6个环境空气质量监测站点(桃园、坞城、上兰、尖草坪、南寨和小店)空气质量监测数据(2015~2018),监测项目:PM10、PM2.5、SO2、NO2、CO、O3六种污染物的小时浓度值。
(2)NCEP再分析数据:NCEP再分析资料插值到对应太原市中心点的地面要素和高空要素,其中地面要素有海平面气压、24小时变温、变压,2m相对湿度,10m风速、10m风向。高空要素有500hPa、700hPa、850hPa、925hPa、1000hPa高度的相对湿度,水平风东西分量(U)和南北风(V)分量、水平风速、垂直速度、散度、涡度以及任意两层气压层之间的相对湿度、位温、风速的差值(高层减低层)等。数据使用时对空气质量监测数据和NCEP再分析数据按照时间点(北京时每日2时、8时、14时和20时)进行对应。
1.2 模型方法
1.2.1 递归特征消除法(RFE)
递归特征消除法(RFE),主要是针对影响PM2.5浓度的各种特征,反复创建模型,并在每次迭代时剔除掉最差特征,同时保留最佳特征,下一次迭代时,将上次建模时没有被选中的特征拿来构建下一个模型,直到用尽所有特征为止。然后它根据模型挑选出来的特征,按照重要性的顺序来进行排名,最终选出一个最佳特征子集。
1.2.2 特征选择与数据预处理
通过RFE算法选取20项预报因子作为模型的最终输入量(表1),本次选取的预报因子与气象的相关性较高,其中高空的气象要素:700hPa涡度和850hPa散度表明气团的旋转形态,空气的辐合与辐散以及925hPa的气压,对PM2.5浓度影响最为直接;前一观测时次的PM2.5、PM10、NO2等污染物浓度在大气稳定条件下具备一定的连续性;500hPa风速,850hPa风向、925hPa水平风东西分量和850hPa水平风南北分量,表明高空的风向和风速对于PM2.5浓度也有较大的影响;24小时负变温和正变压的大小可反映冷锋强度,对于近地层的尤其冷锋过境对空气污染有明显的清除作用;700hPa和500hPa风速差、位温差和温度差等也表征空气的垂直运动,是云团形成,雷鸣闪电、空气对流等天气现象的根本原因,对于PM2.5浓度也有一定的影响。地面的气象要素:2m相对湿度、10m风向、风速也在一定程度上影响污染物的稀释、扩散,进而影响PM2.5浓度。

表1 RFE法回归模型筛选的预报因子Tab.1 Forecast factors screening by RFE regression model
1.2.3 随机森林(RF)

1.2.4 基于RFE-RF的PM2.5浓度预测模型
(1)数据收集整理与预处理,收集太原市空气质量监测数据和NCEP再分析数据,对收集的数据进行数据清洗,包括缺失值得填补和异常值的剔除,并对清洗后的数据进行标准化处理。
(2)重要预报因子选择,利用RFE算法反复创建模型,在每次迭代时保留最佳特征或剔除最差特征,并通过绘制RFE算法的得分曲线,获取各个预报因子的重要性并进行排序,选出影响PM2.5浓度的重要预报因子。
(3)PM2.5浓度预测模型构建,采用机器学习的固定随机数的方法对样本按照70%:30%划分训练数据和测试数据,初始化RF预测模型的参数,通过不断优化调整模型参数,构建基于RFE-RF的PM2.5浓度预测模型。
(4)PM2.5浓度预测,利用训练好的模型对PM2.5浓度进行预测,并与其他机器学习模型预测结果进行对比分析(见图1)。
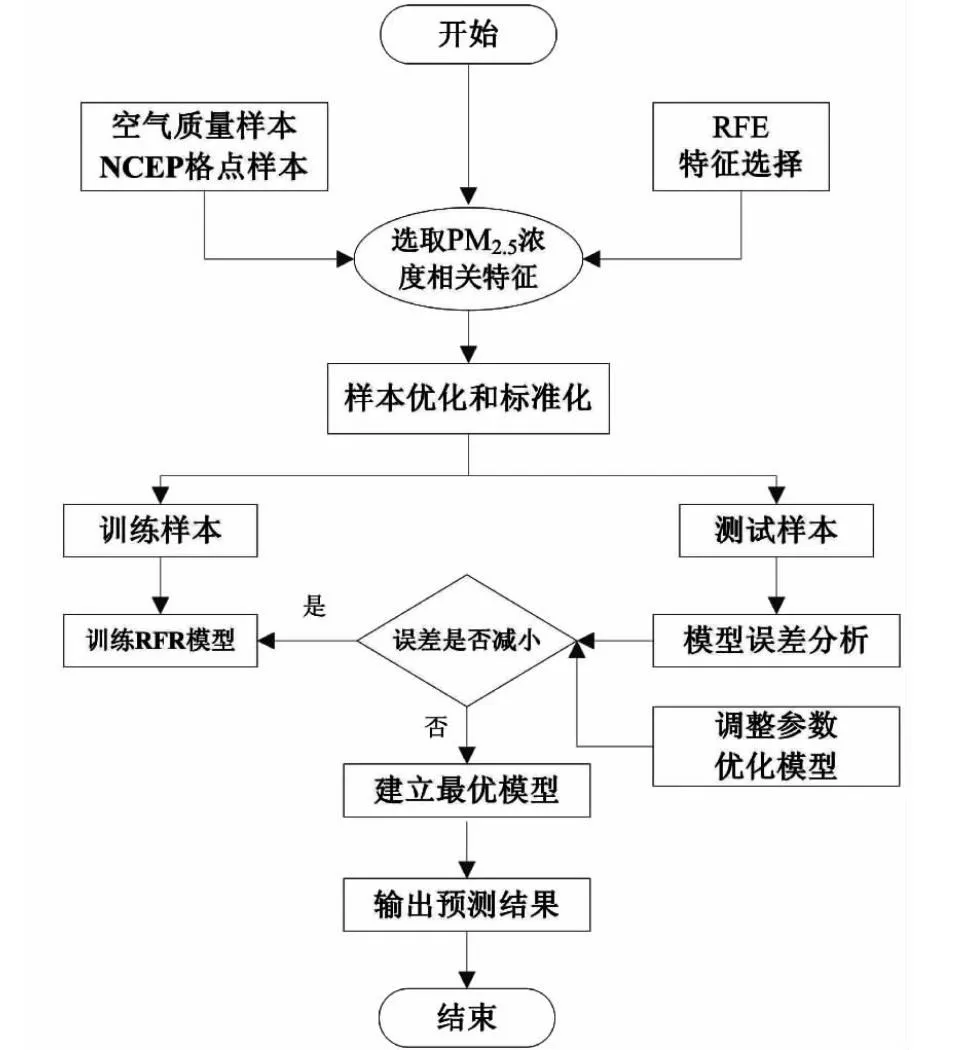
图1 随机森林模型设计流程图Fig.1 Flow chart of random forest model design
2 结果与讨论
2.1 模型模拟结果对比分析
为了验证随机森林模型(RF)的预报准确率,构建3个模型K邻近回归模型(KNN)、套索回归模型(Lasso)、支持向量机模型(SVM)作为对比模型。将基于RFE法进行模型最终选取20项预报因子作为3个对比模型的输入量,3个对比模型所使用的训练集及测试集也与随机森林模型(RF)相同,分别得到4种模型预测的PM2.5浓度。由图2可见,在预报趋势上,Lasso、RF两种模型对PM2.5浓度预测值与实测值均较为一致,KNN模型对PM2.5浓度预测值与实测值稍有些偏差,SVM模型预测值与实测值偏差较大。其中,与KNN和SVM模型两种模型相比Lasso、RF两种模型预测结果的方差较小,预报的峰值极个别情况与实况值相差较大,但是总体的峰值、谷值的预测与实况值较为接近,预测的精度较高,尤其拐点处RF模型的预测结果也好于Lasso模型。
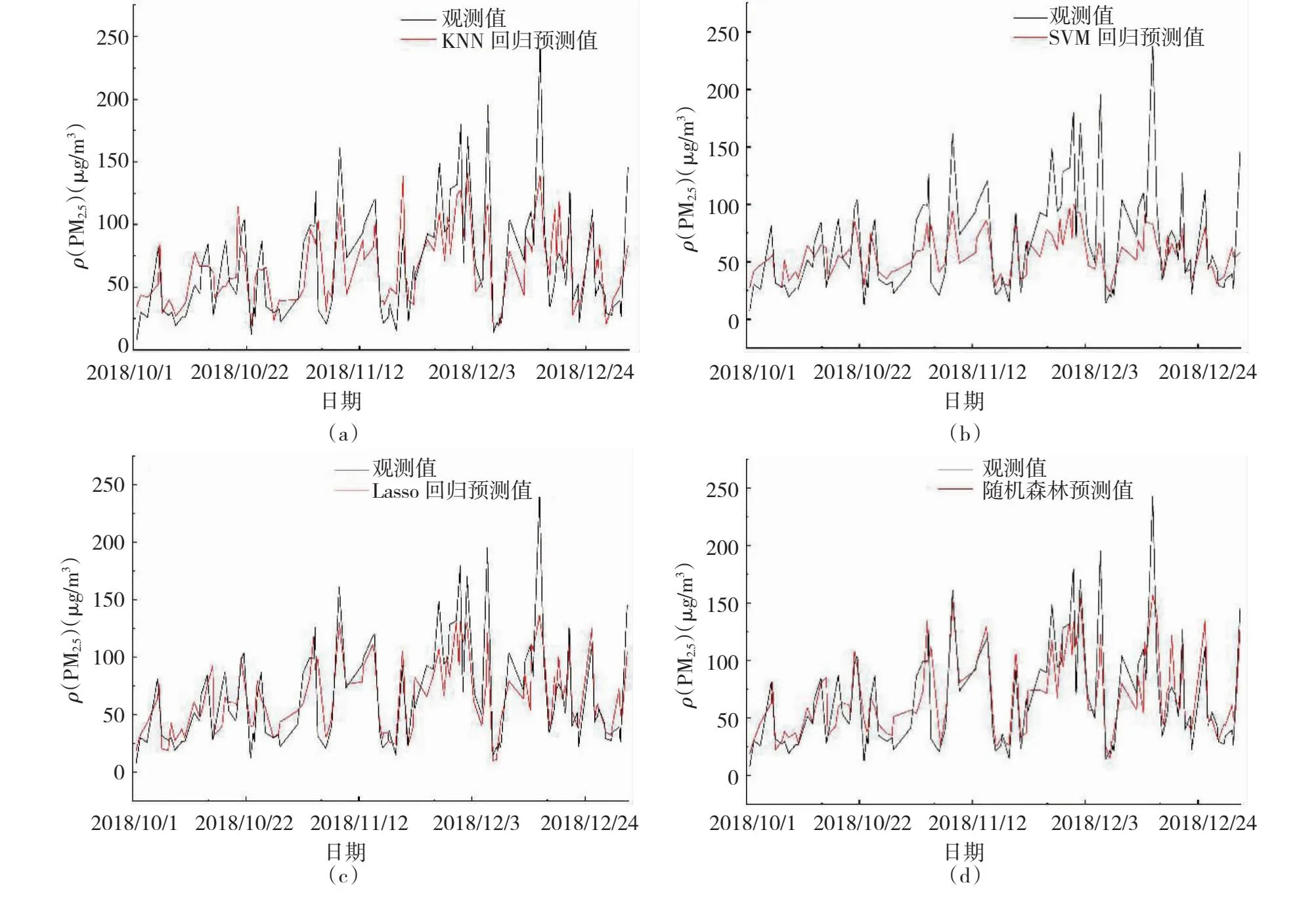
图2 模型预报值和实况值对比Fig.2 Comparison between model prediction value and real data
由4种模型所得预测值与实测值的散点分布可见(图3),SVR模型散点分布偏下,不在对角线上,说明预测值与实测值的偏差较大,当实测值<50μg/m3时散点多数在对角线左上方,说明预测值存在低估;当实测值>50μg/m3时散点多位于对角线右下方,说明预测值存在高估。KNN模型散点相对Lasso、RF两种模型较为分散,但是任大致在对角线方向,KNN模型的散点在PM2.5低浓度时(实测值<50μg/m3)位于对角线上方,预测值存在一定的高估;而散点在PM2.5高浓度时(实况值>50μg/m3)位于对角线下方,预测值存在一定的低估。Lasso、RF两种模型散点呈现出向对角线集中分布的形态,说明这2个模型预测结果和实测值较为一致。
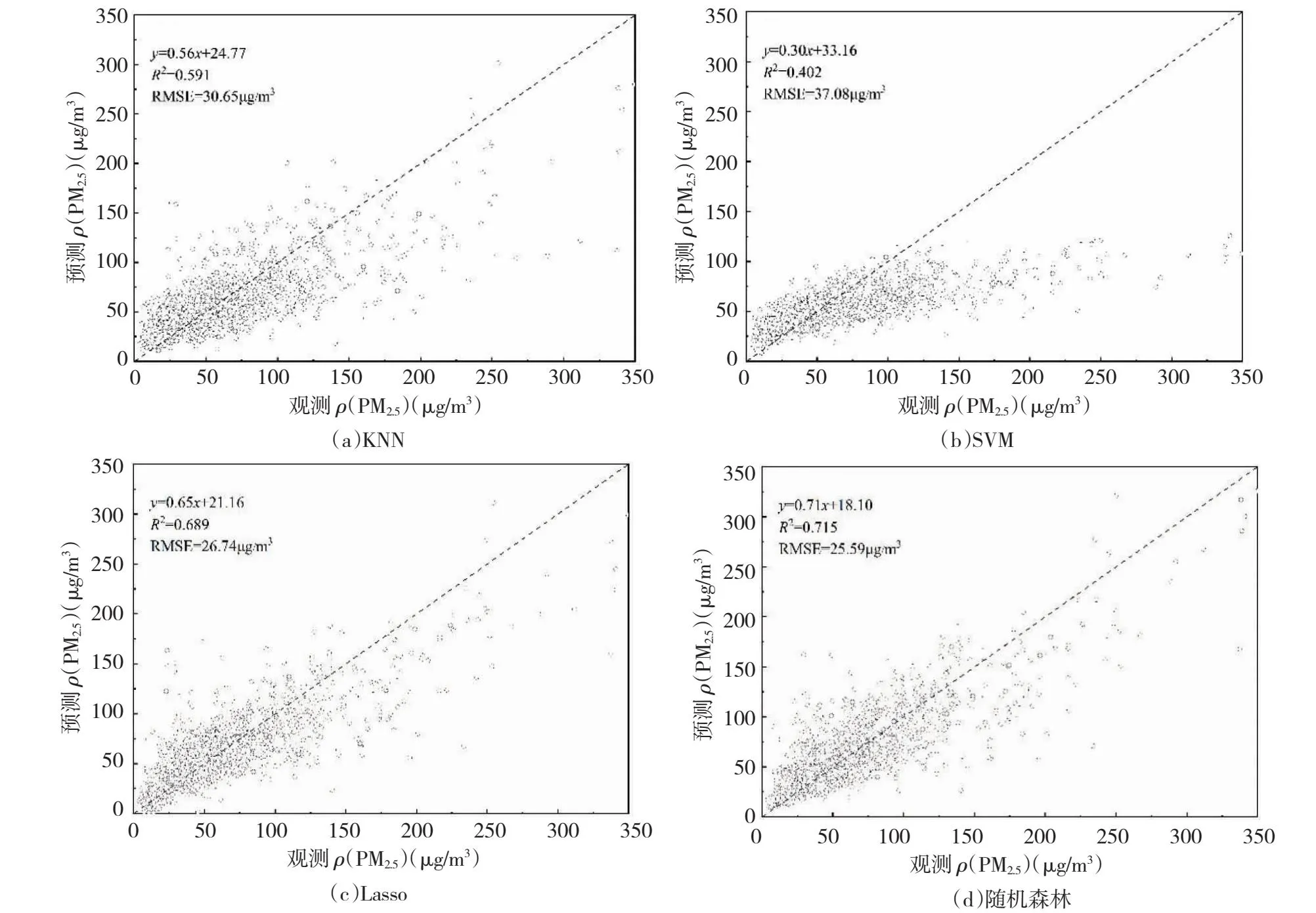
图3 模型的预报值和实况值散点图Fig.3 Scatter plots of predicted and observed values
2.2 模型评估指标对比分析
为定量评估4个模型的预测效果由图可见(图4),选取2018年9月~2018年12月PM2.5日均浓度实测值与相应日期的各个模型的预报浓度数据,分别计算上述4个模型预测值的评估指标,结
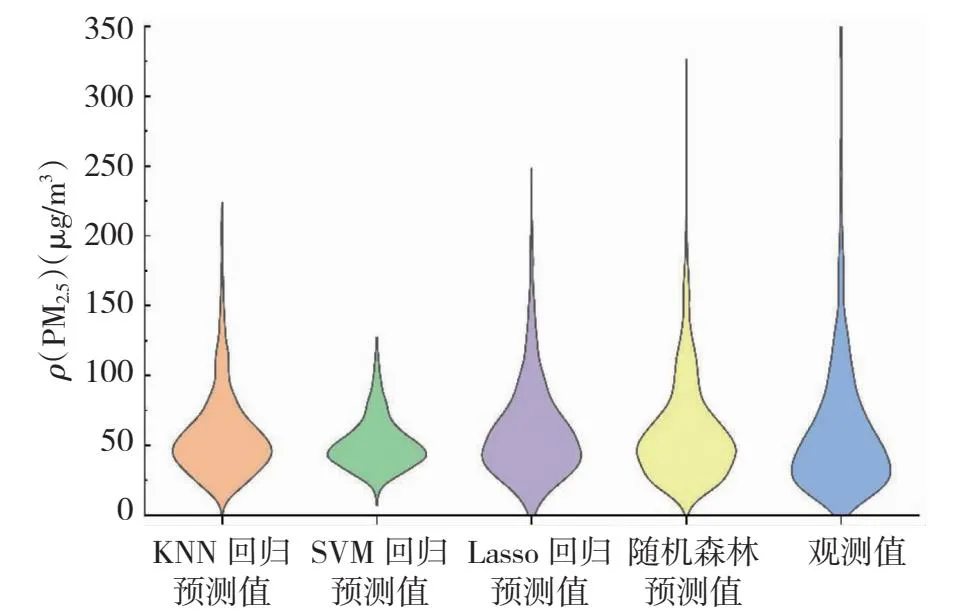
图4 4种模型预测值与观测值统计分布对比Fig.4 Comparison of the statistical distribution between the predicted values and the observed values of PM2.5 of the four models
果如表2所示。RF模型的MAE、MAPE、RMSE分别为17.19、38.17%和26.0,与Lasso模型相比,分别降低了7.7%、5.1%和2.7%;相比于SVM预测模型的MAE、MAPE、RMSE分别降低了23.1%、15.3%和29.9%;相比于KNN预测模型,RF模型的MAE、MAPE、RMSE分别降低了17.2%、19.8%和15.2%。结果显示,在测试集上RF模型具有良好的预测效果,R2达0.71,显著优于KNN模型、Lasso模型、SVM模型(R2均低于0.70),该性能评估指标也显示RF模型表现最佳。4种模型预测值与实测值的相关系数依次为0.76、0.78、0.82和0.84,RF模型的预报效果均好于Lasso模型、KNN模型和SVM模型。
RF模式预测值和实测值的均值、中值、25%分位数最为接近;SVM模型预测值与实测值的各项评估指标差别最大;对于75%分位数而言,Lasso模型与实测值最为接近,SVM模型预测值与实况值差别最大,KNN模型预测值与实况值差别也较大。两者均说明在PM2.5浓度较低的情况下,RF模式预测精度最高,Lasso模式预测精度次之,SVM模型最差,KNN模型介于中间;在PM2.5浓度较高的情况下,Lasso模式和RF模式预测精度相差无几,SVM模型最差,KNN模型介于中间。由4模型预测值与观测值统计分布对比可见:RF模式的预测值与观测值的数据分布形态最为接近,无论从总体PM2.5浓度的预测均值还是从高低PM2.5浓度的预测值都最为接近;Lasso模式预测值与观测值的数据分布形态也较为接近,但是该模型对高PM2.5浓度观测值略有低估,对低浓度5浓度观测值略有高估;KNN模型预测值与观测值的数据分布形态对比度一般,SVM模型预测值与观测值的数据分布形态差距最大。
由4种模型预报结果的泰勒图(图5),综合分析可知,RF预测模型对PM2.5预测精度更高,更接近实测值,通过模型预测结果对比分析,本文提出的基于RF的PM2.5浓度预测模型具有较好的预测结果,利用RFE算法对模型的输入特征进行了重要性选择,减少了模型输入特征的个数,不仅可以用较少的预报因子就可以实现对PM2.5浓度的预测精度的提高,而且大大提高了模型运算速度,实现了对PM2.5浓度预测模型输入参数的优化。
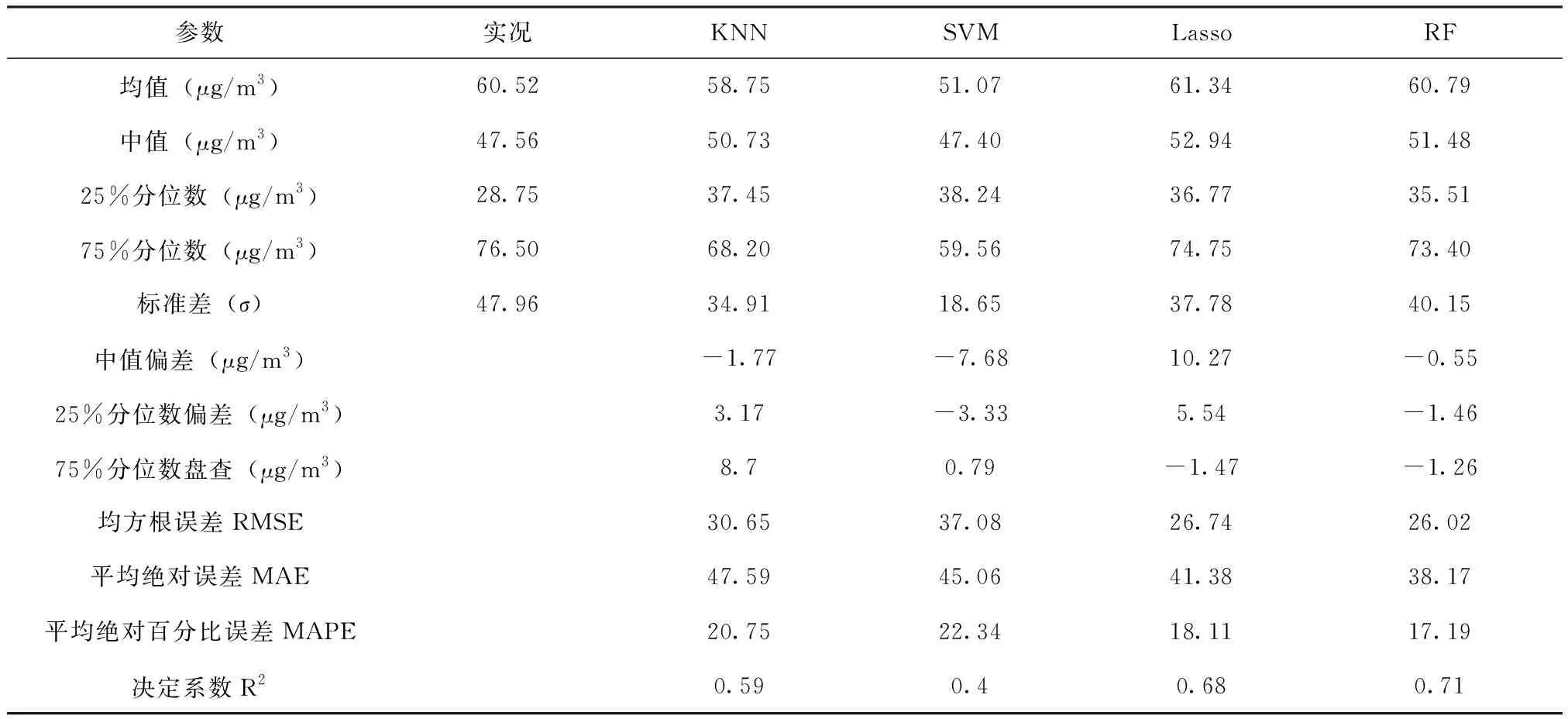
表2 4种模型PM2.5预测结果评估Tab.2 PM2.5 prediction results evaluation of the four models
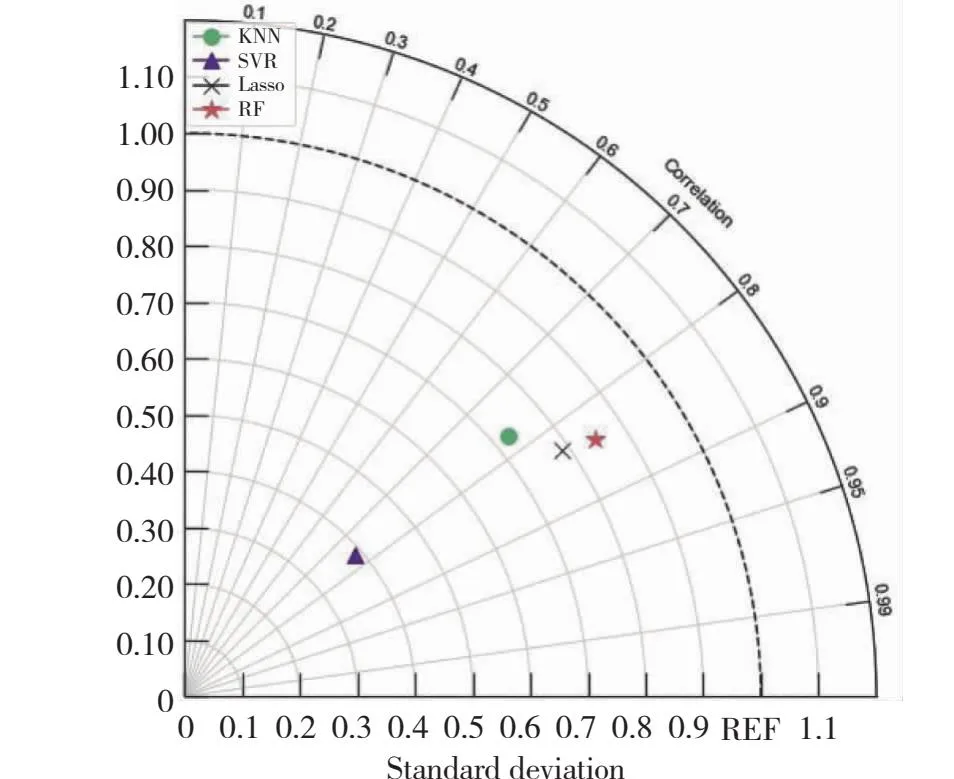
图5 4种模型预报结果泰勒图Fig.5 Taylor plot of PM2.5 by KNN,SVM, Lasso model and RF model
3 结 论
(1)根据RFE特征选择的结果,选取太原市PM2.5的浓度预测中最利于提升模型表现的预报因子,预报因子选择的结果,也表明太原市PM2.5的浓度在一定程度受到近地层风力和湿度的影响,同时高层气团的旋转形态,空气的辐合与辐散,高空的风向和风速,空气的垂直运动、冷锋过境等对空气污染有明显的影响。
(2)针对太原市的PM2.5的浓度预测4个模型的对比实验,RF模型显著优于KNN模型、Lasso模型、SVM模型,对PM2.5预测精度更高,同时利用RFE算法对模型的输入特征进行了重要性选择,减少了模型输入特征的个数,不仅可以用较少的预报因子就可以实现对PM2.5浓度的预测精度的提高,而且实现了对PM2.5浓度预测模型输入参数的优化。
(3)通过选取最优的RF预测模型应用到日常的环境空气质量预报业务中,将进一步提高太原市PM2.5浓度预报的准确率,同时也为加强太原市的空气污染防治,实现环境综合管理和决策科学化提供了的重要科技手段。
