混合交通流环境下基于MSIF-DRL 的网联自动驾驶车辆换道决策模型
2023-12-30郭为安
韩 磊 , 张 轮 , 郭为安
(同济大学a.道路与交通工程教育部重点实验室,b.电子与信息工程学院,c.中德工程学院,上海 201804)
近年来,随着全球定位系统、无线通信、先进传感器和人工智能等新技术的快速发展,网联自动驾驶汽车(Connected and Automated Vehicles, CAV)已经从科学幻想变成了科学事实.伴随着CAV 的出现与应用,未来的交通运输系统将发生深刻变革[1-2]. 相较于人工驾驶汽车(Human-Driven Vehicles, HDV),CAV 的驾驶特性具有智能化和网联化的优势.一方面,CAV 能够通过对周围环境的动态感知和自主导航,在没有人为干预的情况下自主完成安全、高效的驾驶任务,从而有效降低人类驾驶员驾驶行为的不确定性和随机性对交通运输系统造成的负面影响.另一方面,CAV 具备与周围同类型车辆、路侧单元之间进行车辆到车辆(Vehicle-to-Vehicle, V2V)和车辆到基础设施(Vehicle-to-Infrastructure, V2I)通信的能力,这一能力使得CAV 在驾驶过程中可以获得更多有用的信息,有助于生成并执行更加合理、准确、智慧的驾驶策略.因此,各国学者普遍认为CAV 的混入有望从根本上改善传统道路交通流的通行能力、交通安全以及通行效率[3-6]. 其中,自适应巡航控制(Adaptive Cruise Control, ACC)和协同自适应巡航控制(Cooperative Adaptive Cruise Control, CACC)技术是目前较为成熟的CAV 技术,该技术也是当前落地最多的网联自动驾驶功能之一[7].然而,受限于新技术推广的渐近式发展特点,以及当前道路交通环境、制造成本以及相关安全隐私政策等客观因素的影响,距离CAV 的完全覆盖还需较长一段时间.因此,由CAV和HDV 共同组成的混合交通流将长期存在.换道行为是车辆两大基本微观驾驶行为之一,对车辆的行驶效率、行驶安全以及交通流的稳定性具有较大影响.因此,如何在混合交通环境的过渡阶段提出可行的CAV 换道决策模型具有重要意义.
现有的CAV 换道决策研究可分为基于规则的方法和基于学习的方法.基于规则的方法结合驾驶经验和交通规则等建立规则库,CAV 根据驾驶场景从规则库中选择合适的驾驶行为策略[8-11].然而,这种方法虽然可解释性强,但在灵活性和泛化性能上却存在较大局限性.随着数据采集和数据存储技术的不断发展,以及得益于深度神经网络在特征提取和非线性逼近方面取得的长足进步,基于学习的方法被逐渐应用于CAV 的换道决策中,并表现出优于基于规则方法的性能.根据训练方法的不同,可进一步将基于学习的方法分为深度监督学习(Deep Supervised Learning, DSL)方法[12-15]以及深度强化学 习(Deep Reinforcement Learning, DRL)方法[16-24].DSL 方法主要通过输入大量人工标记的训练数据来更新深度神经网络中的权重,学习驾驶环境与驾驶行为间的映射,并将其概念化和形式化,进而形成一种端到端的自动驾驶决策模式.研究表明,如果提供足够多的专家示范驾驶数据,DSL 方法可实现人类级别智能的决策能力[25].虽然DSL 方法在CAV 换道决策领域取得了较大的成就,但仍存在较多不足之处.例如,DSL 方法的性能不仅很大程度上取决于专家示范驾驶数据的质量和数量,而且还受到专家知识的约束;可解释性较低,出现错误时难以溯源和更正;训练成本较高,传感器输入的很多无关信息使得训练效率难以得到保证;泛化能力较弱,难以迁移至不同于训练场景的新场景中.DRL 作为一种高效的人工智能算法,通过不断试错的机制与外部环境进行交互,以最大化奖励值的方式不断迭代,学习最优的智能体动作策略映射,无需精确建模,同时能够适应复杂多变的外部环境.针对DSL 方法的局限性,学者们开始通过DRL 来提高CAV 的决策能力.Mirchevska 等[16]基于深度Q 网络(Deep Q Network, DQN)提出了适用于高速公路场景的CAV 换道决策模型;乔良等[17]针对全智能网联汽车环境下CAV 的匝道汇入问题,通过DQN 构建了一种基于深度强化学习的CAV 匝道汇入模型,使得自车可以根据周围环境车辆行驶速度的不同自动调节自身的驾驶策略;Wang 等[18]通过在奖励函数中引入变道配合系数,提出了一种以提升整体交通效率为导向的协同变道策略;罗鹏等[19]为了加快基于强化学习的CAV 换道决策算法的动作选择速度,利用专家知识来降低DQN 算法在动作探索过程中的随机性,提出一种以专家知识为引导的DQN 换道决策算法,并在高速公路三车道、合流区驾驶场景中验证了该方法的有效性和实用性;Li 等[20]提出了一种具有风险意识的CAV 深度强化学习换道决策策略,该策略将基于贝叶斯理论的风险评估模型和DQN 相结合,可以找到具有最小预期风险的最佳驾驶策略.
混合交通流环境下CAV 换道决策的难点在于如何充分融合自车运动信息、车载传感器感知范围内CAV 和HDV 运动信息、V2V 通信范围内上、下游CAV 运动信息,以及如何利用融合后的信息来指导主车安全、高效、舒适地自动换道[26-27].已有混合交通环境下CAV 换道决策模型为了降低建模难度,模型输入仅考虑了自车信息、感知信息,且必须采用预先指定好的格式(如固定大小的占用网格)对所驾驶的环境进行表示,在实际应用中存在安全隐患高、行车环境表征不充分、计算精度不足、计算成本较大等诸多缺陷[28-30]. 为了弥补上述缺陷,Huegle 等[31]利用Deep Sets 网络对各种序列长度的多源输入信息进行特征嵌入,并将其全部融合后再输入到Q 网络中以生成CAV 的换道策略.该方法虽然输入方式较为灵活且输入信息的长度不会影响策略网络的决策过程,但仍然存在诸多不足.首先,由于Deep Sets 的简单求和操作,所有高维特征都被压缩成一个固定大小的向量,造成一些关键信息如上下游车辆的速度、位置和具体所处车道在这个过程被丢失.其次,由于没有提供归一化项,特征嵌入的绝对值可能会随着周围车辆数量的增长而线性增长.此外,该方法对所获信息的价值差异没有明确考虑,即不同空间位置的车辆信息被赋予相同的重要性,这显然不合理,因为在实际驾驶过程中,来自不同信息源的信息对自车驾驶行为决策的影响程度不尽相同.
综上,本文为兼顾突出CAV 面对复杂交通环境时行车决策技术的强适应性,以及融合多源信息进行智慧换道的驾驶特性,提出了一种混合交通流环境下集成多源信息融合的深度强化学习(Multi-Source Information Fusion Deep Reinforcement Learning, MSIF-DRL)端到端网联自动驾驶换道决策模型.该模型首先综合考虑自车运动信息、传感器感知范围内周围车辆以及V2V 通信范围内上下游CAV 运动信息对自车换道决策的影响,并根据信息源相对于自车的空间位置对来自各车的信息赋予适当的权重;然后,通过集成一种编码网络对上述多源信息进行充分融合,以编码网络融合后的信息作为模型输入;最后,通过深度强化学习中具有优先经验回放机制的竞争双深度Q 网络(Dueling Double Deep Q Network with Prioritized Experience Replay, PER-D3QN)输出最终驾驶决策.MSIF-DRL 换道决策模型为主线、匝道CAV 设计了不同的奖励函数,故可解决多车道高速公路合流区驾驶场景中CAV 的自由以及强制换道问题.在不同渗透率条件下的多次仿真试验显示,所提MSIF-DRL 模型的行车效率、行车安全和乘坐舒适度均优于现有模型.
1 深度强化学习
深度强化学习问题可转换成一个马尔科夫决策过程(Markov Decision Process, MDP).MDP 可由状态集S、动作集A、状态转移概率P:S×A×S、奖励函数R和折扣因子γ(γ∈[0,1))5 个关键元组表示. 智能体(本文中为CAV)会在当前状态s(s∈S)中根据策略π来采取1 个动作,执行完所选动作后智能体会收到一个数值奖励r,环境则会根据p(:|s,a)随机抽样生成一个新的状态s′.智能体会依据上述过程反复迭代与环境进行交互,最终实现最大化累积奖励.深度强化学习的训练目标就是给定一个MDP,寻找最优的决策策略πθ*(a|s),从而最大化期望累积奖励.在寻找的前期过程中,智能体将采用随机策略(记为πθ(a|s)=π(a|s;θ),即智能体在状态s下采取动作a的概率)来探索环境并根据状态生成一系列动作;后期则聚焦于选择Q值最大的动作.其中,θ为深度强化学习中神经网络的参数.当智能体某一时刻的策略为π时,在状态s下采取动作a后所获得的期望累积奖励Eπθ,可用动作值函数Qπθ(s,a)来描述,具体计算式为
式中,k为迭代次数.
πθ*(a|s)的计算式为
式(2)可进一步转化为
在深度强化学习领域中,双深度Q 网络(Double Deep Q Network, DDQN)算法是一种经典的价值学习人工智能算法[32]. 为了进一步提高DDQN 算法的稳定性和学习效果,通过在DDQN 的在线网络和目标网络中引入竞争网络结构[33]对其进行改进,就可形成一种性能更强的深度强化学习算法,即D3QN 算法.竞争网络架构将隐藏层输出的状态信息分别输入到仅与状态有关的价值函数V(s;ω,β) 以及与状态动作都有关的优势函数A(s,a;ω,α)中进行进一步的数据处理,再将两个函数流的输出线性组合,最终得到输出的Q值,即
式中:Q(s,a;ω,α,β)为最终输出的Q值;ω为公共隐藏层的网络参数;α和β分别为价值函数和优势函数各自特有的网络参数;a′是智能体在下一状态s′所能采取的最优动作.
在D3QN 算法中,改进后的在线网络和目标网络的参数分别为θ和θ-.在线网络负责与环境不断进行交互且在每个时间步收集样本.每个样本中包含了4 个元素,即当前状态s、当前动作a、奖励r以及s′.由于在连续时间步收集到的相邻样本互相关联,拥有较强的自相关性,因此,不能直接进行训练.为了解决此问题,D3QN 算法将收集到的经验样本存放在一个经验回放池D中.每次在进行训练时,都会从回放池中随机取出一定批量的经验样本对评估网络进行训练,更新优化其参数θ.目标网络中的参数θ-却是固定的,只在一定间隔时间点复制评估网络中的参数大小,即令θ-=θ.在线网络的参数θ可以通过最小化神经网络的损失函数L(θ)来更新优化,L(θ)的计算式为
式中:
YD3QN的计算式为
为了加速整个训练过程,降低均匀随机取样导致的一些有巨大回报的经验(如成功的尝试或失败的教训等)无法被充分利用甚至被直接覆盖问题,本文使用优先经验回顾[34]的方式从经验回放单元中抽取样本,以此增加重要性较高的样本被抽取的概率.由于时间差分误差(Temporal Difference-error,TD error)能够衡量经验样本的重要性,因此,采用TD error 来计算每个经验样本被抽取的概率.每个经验样本被抽取的优先级pi为
式中:μi为样本i的TD error;φ为一个很小的正常数,该常数保证即使TD error 约为0 的样本也有一定的概率被抽取.
进而,经验样本被采样的概率P(i)为
式中:σ为经验回放时优先级权重所占的比例,若σ=0,则表示均匀采样;K为每次从经验回放单元中取样的样本量.
由于优先经验回放会带来修正误差,故在更新神经网络参数θ时,需要使用重要性采样权重ξi来进行纠正,具体为
式中:θ′为参数θ更新后的值;τ为网络更新频率;∇θQ(si,ai)为Q 值对θ的导数;C为经验回放单元D的大小;ρ为纠正的程度,取值范围为[0,1],若ρ=1则表示优先经验回放的优先取样概率被完全抵消.
与DDQN 相比,本文所提PER-D3QN 网络更好平衡了价值函数与优势函数之间的关系,同时采用优先级经验回放的方式抽取小批量样本作为算法输入,进一步提高了TD error 绝对值较大的样本利用效率,保证智能体性能的同时提高了优化稳定性.
2 MSIF-DRL 换道决策模型
2.1 模型应用场景描述及说明
所提模型的适用场景为文献[35-36]中的一类多车道高速公路合流区,具体示意图如图1 所示.图1中,主线上的车道数有M条,车道编号为车道1 至车道M;匝道道路由进口车道和平行式加速车道组成,加速车道编号为车道0.为简化模型复杂程度,提出3 条说明:模型旨在通过编码网络和深度强化学习解决混合交通流环境下多车道高速公路合流区内主线上CAV 的自由换道决策以及匝道上CAV 的强制换道决策问题;V2V 通信通过专用短距离通信技术实现,通信距离为300 m,车载传感器的感知范围为120 m[37];不考虑信息传输过程中的延迟及丢包等问题.
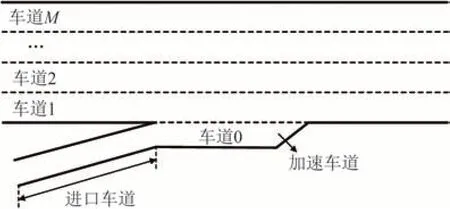
图1 多车道高速公路合流区示意图Fig.1 Schematic diagram of multi-lane freeway merging area
2.2 模型整体框架及建模
2.2.1 整体框架
针对混合交通流环境下的高速公路合流区CAV 换道决策问题,提出一种MSIF-DRL 端到端模型指导车辆进行换道.MSIF-DRL 模型的总体框架如图2 所示,由编码网络和PER-D3QN 网络共两个模块组成,分别用于CAV 的多源信息融合和换道决策生成.其中,编码网络的结构为Dense(64)+Dense(32),PER-D3QN 网络的结构为4×Dense(64)+Dense(32)+Dense(16)+Dense(8),两者均采用优先经验回顾从经验回放单元D中抽取小批量样本进行训练.对于每个小批量样本,MSIFDRL 模型的损失函数LMSIF为

图2 MSIF-DRL 模型整体架构Fig.2 Overall architecture of MSIF-DRL model
式中:B为批尺寸;YMSIF为MSIF-DRL 模型目标值.
2.2.2 状态空间建模
在当前时刻,交通环境状态是MSIF-DRL 换道决策模型的初始输入,主要由自车运动状态信息Hego、感知信息Hsen、通信范围内上下游信息Hcon进行表征.其中,来自Hego和Hsen的信息主要用来捕获车辆所处位置小范围驾驶环境,以保证车辆做出无碰撞决策,来自Hcon的信息起到扩大自车环境感知范围的作用,促进车辆生成具有长远利益的换道决策.Hego主要包含自车相对于驾驶环境的位置、速度、车道信息,即
式中:xego为自车绝对位置;xtotal为高速公路总长;vego为自车速度;lego为自车所处车道索引;ltotal为路段所有车道索引的和.
Hsen主要包含与自车同车道、相邻左侧、相邻右侧车道上车辆的驾驶信息,即
式中:、、分别代表了感知范围内相邻左侧车道、同一车道、相邻右侧车道上所有车辆的驾驶信息;xn,sen、vn,sen、ln,sen分别为感知范围内车辆的绝对位置、速度、车道索引;dxn,sen为车辆n相对于自车的距离,dxn,sen=为自车感知范围;dvn,sen为车辆n相对于自车的速度,dvn,sen=vmax为路段限速值;dln,sen为车辆n相对于自车的车道索引,dln,sen=ln,sen-lego(例如dln,sen=-1,代表车辆n位于自车的相邻左侧车道).
Hcon中包含了通信范围内上、下游CAV 相对于自车的距离、速度、车道信息,可分别表示为
式中:、分别代表了通信范围内上、下游CAV的信息;xm,con、vm,con、lm,con分别为通信范围内车辆的绝对位置、速度、车道索引;dxm,con为车辆m相对于自车的距离,dxm,con=为通信距离;dvm,con为车辆m相对于自车的速度,dvm,con=为车辆m相对于自车的车道索引,dlm,con=lm,con-lego.
由于Hsen、Hcon的输入长度始终处于动态变化中,故使用全连接神经网络ϕ将自车自身输入hego∈Hego、感知范围内各车道上车辆输入hsen∈Hsen、通信范围内上、下游输入hcon∈Hcon编码到高维特征空间,然后在特征空间中进行多源信息融合得到固定尺寸的输入(特征图).从Hego、Hsen中获得的全部特征嵌入可分别表示为
式中:Fego、Fsen为分别从Hego、Hsen中获得的特征嵌入;Wn,sen为感知范围内周围车辆原始信息输入权重.
对于从Hcon中获得的全部特征嵌入Fcon有
一般距离自车越近的车辆,对其决策结果的影响程度也越大.因此,本文根据不同车辆j相对于自车的空间位置,来决定其权重值的大小,即:
式中:V为自车感知到的车辆数以及与其通信车辆数的和,即V=n+m;loca 代表车辆V是感知到的车辆还是通信车辆,loca={sen, con}.
上述连接形成的特征图将进一步被铺平为向量,转入PER-D3QN 网络(记作Φ)中进行Q值Q(s,a;θ,α,β)的计算,即
2.2.3 动作空间建模
根据文献[18, 21-22, 24],在每一时间步,各个CAV 的离散动作空间包含了车辆j可能做出的动作,即
式中:alane为CAV 可以采取的换道动作,包括向左换道、向右换道或保持原先车道直行;aE为CAV可以采取的离散加/减速度,取值范围为-[-3m/s2, 3m/s2].MSIF-DRL 模型的整体动作空间A是所有CAV 动作的集合,即
2.2.4 奖励函数设计
在基于MSIF-DRL 算法的CAV 换道决策模型中,奖励函数的作用在于引导智能体与环境的交互,找到最大化累计奖励的换道决策策略.因此,奖励值函数的设计直接决定了智能体是否可以学习到最佳的换道决策策略,是整个算法中非常重要的一环.在高速公路合流区驾驶场景中,为了使得CAV 既能提高车流的整体运行效率,同时也能保证自身获得更高的行车效率、良好的舒适性和安全性以及增强多个CAV 间的协作性,本文CAV 换道模型中使用的奖励值函数主要考虑5 方面.
现医务处负责人伍姗姗2000年调入医院,后任质控科科长,负责医院医疗质量与患者安全。她见证了医院近十年间,甚至更早时候的医疗质量管理“进阶”。
方面1:车速相关项R1.高速公路一般都会设置道路最低限速,其目的就是为了防止车辆在行驶过程中因为速度较低而导致道路交通拥堵和通行效率下降的发生.因此,设置车速行驶奖励,鼓励CAV在保证驾驶安全、低于最高限速值的前提下进行高速行驶.设置车速行驶奖励函数R1为
方面2:合流相关项R2.匝道CAV 的行驶动机是汇入主线,成功完成合流行为.根据文献[22],将R2(该奖励只有匝道CAV 可获得)分为早期rearly以及最终合流成功奖励rsucc两部分,即
式中,xlego为CAV 未变道前所处车道的长度.
方面3:平稳相关项R3.为了尽可能增加车辆行驶的平稳性,以及减少车辆连续变换车道对交通流造成的负面扰动(指交通流的稳定性变弱和平均速度发生下降),根据文献[18, 21],设置变道惩罚函数R3为
式中:α为其他CAV 配合主车换道的协作系数.其中,R3决定了车辆的换道意愿强度;α则可以促使CAV 温和驾驶,防止发生一些不必要的变道行为,本文中的α取值为4[18,21].此外,本文判断CAV 是否连续变道的标准为两次变道间的时间间隔,若时间步差小于20 步(2 s),则对该CAV 进行施加惩罚.
方面4:安全相关项R4.对于车辆,避免发生碰撞是在合流区内安全行驶的最基本和最重要的要求.本文选择碰撞时间(Time-to-Collision, TTC)进行驾驶安全评估,保证TTC 在安全范围内以避免与前车发生碰撞.设置碰撞惩罚函数R4为
式中:TTCmax为TTC 的安全阈值,依据文献[28,38]取值为1.5 s;Δx为自车与前车间的车头间距;L为车长;vlead为前车速度.
方面5:舒适相关项R5.Jerk 又称急动度值,是加速度对时间的导数,表示车辆的突然移动[23].通常状况下,车辆的Jerk 值以及加/减速度越小,说明乘车舒适性愈好.因此,为了使CAV 能够学习到舒适性的驾驶行为,设置舒适奖励函数R5为
式中:rJerk、rG分别为急动度值、加/减速度奖励项;5.6 和2 分别为Jerk 的阈值和最大舒适加/减速度[23,28];表示自车的加/减速度.
综上,主线CAV 的总奖励值函数Rmain和匝道CAV 奖励值函数Rramp分别为
2.3 MSIF-DRL 算法步骤
为了能让智能体对环境进行充分的探索,获得足够多的经验,MSIF-DRL 算法设置了仿真预热阶段,在该阶段内所有的CAV 将采取随机动作,并从交通环境中收集相应的动作状态转移序列
步骤1:设置算法参数的初始值,包括γ、学习率η、采样批尺寸B、目标网络更新频率τ、探索概率ε、训练总回合数N以及每回合训练步数T.
步骤2:对于每个回合,初始化容量为C的回放经验单元D,在线及目标网络和参数θ及θ-.
步骤3:开始迭代,生成交通场景,得到初始的外部环境状态.
步骤4:进入预热阶段.在时间步t(t=1)至T1内,智能体采取随机动作a,得到当前奖励r以及新一轮合流区环境状态s,将四元组
步骤5:结束预热,开始训练.在时间步T1+1至总步数T内,生成一个随机概率值g,若g<ε,则随机选择一个动作a.否则,使用编码网络ϕ对多源信息进行编码,并利用PER-D3QN 网络计算Q值,输出动作
步骤6:执行动作a*t,观测获得的即时奖励r和下一状态s′,计算TD error.
步骤7:计算优先级pi、采样概率P(i)以及重要性权重ξi,将四元组
步骤8:将s′赋值给s,从经验回放单元D中以概率P(i)抽取B个经验样本进行更新.
步骤9:计算目标值YMSIFt,基于损失函数LMSIF进行随机梯度下降法更新优化网络参数.更新ε,每隔τ时间步,更新赋值目标网络的参数θ→θ-.若迭代次数未达到设定值,则进入步骤5,否则进入步骤10.
步骤10:结束整个流程.
3 仿真设置
3.1 混合交通流环境构建
为了实现混合交通流环境下CAV 基于MSIFDRL 端到端模型在高速公路合流区内进行主线自由换道、合流强制换道的仿真,首先需要构建CAV与HDV 混行的交通环境.因此,对于HDV,利用智能驾驶人模型(Intelligent Driver Model, IDM)[39]和最小化由换道引起的所有制动模型(Minimize Overall Braking Induced by Lane-change, MOBIL)模型[40]分别对HDV 的纵向跟驰与横向换道进行建模.此外,为了模拟驾驶人不可预测的驾驶特性,在每个HDV 的加速度中都加入均值为0、随机方差取值范围为[0,1]的正态噪声.对于CAV 的跟驰行为,文献[41]指出根据前车类型不同会存在两种跟驰模式.前车为CAV,无功能退化,继续以CACC 模式跟驰;前车为HDV,CAV 将退化为ACC 车辆.故本文分别采用ACC[42]、CACC 模型[43]来模拟两种跟驰方式,仿真时各模型中的关键参数值均取自上述相关文献.混合交通流环境中CAV 渗透率所有取值的集合为{20%,50%,80%,100%}.
3.2 场景搭建与试验设置
基于SUMO 仿真平台搭建仿真场景,并采用Python 语言调用SUMO 内嵌的Traci 控制接口来实现IDM、MOBIL、ACC、CACC、MSIF-DRL 模型的所有功能.仿真试验路段选取美国加利福尼亚州I405 和洛杉矶市I-5 两条高速公路.其中,I405和I-5 所选路段的总长度分别为3.4 km 和3 km,合流区长度分别为250 m 和200 m,主线车道数分别为3 条和5 条.根据检测器历史数据,每条路段主线和匝道上的交通需求可分为高、低两种水平.鉴于此,本文共设计了4 种仿真场景,具体设置情况如表1 所示.

表1 仿真场景设置Tab.1 Setup of simulation scenarios
仿真试验中用于MSIF-DRL 模型训练和测试的计算机配置为Ubuntu18.04LTS 系统,Intel Core I7-12700H @2.7GHz CPU,GeForce RTX 3060 GPU,16GB 内存.训练最大回合数设置为800,终止条件为CAV 单回合执行步数达到20 步或CAV在行驶过程中与其他车辆发生碰撞.仿真总步长设为106步,前2 ×105步(约200 个回合)用作仿真预热,后8×105步(约600 个回合)用作训练.模型采用Adam 优化器,设置的MSIF-DRL 模型超参数如表2 所示.

表2 MSIF-DRL 模型超参数取值Tab.2 Hyper-parameter values for MSIF-DRL model
4 仿真结果与分析
4.1 训练过程
智能体所获得的奖励值能够很好地反映其在训练过程中的学习表现,奖励值越高说明智能体学习到的驾驶策略也更优.图3 为MSIF-DRL 模型在各种渗透率PR 条件下的奖励值随训练回合数变化的趋势.由图3 可知:在训练初始阶段(仿真预热期间),CAV 智能体将采取随机动作来与环境不断试错交互,致使CAV 发生碰撞的概率增大,导致获得惩罚函数的次数增多,降低了所获得的单步奖励函数值;随着训练回合数的不断增长,MSIF-DRL 模型逐渐开始适应复杂的高速公路合流区驾驶环境,最终约在第300 个回合达到基本稳定,建立符合CAV 运行的换道行为模式;随着渗透率的不断提高,MSIF-DRL 模型收获的奖励值也不断提高,当训练回合数结束时,20%、100%渗透率条件下的匝道CAV 奖励值分别为1389、1665,其提升比例为19.87%;在同等渗透率条件下,同一训练回合内匝道CAV 收获的奖励值要高于主线CAV 收获的奖励值.

图3 不同CAV 渗透下MSIF-DRL 模型在训练过程中的奖励值Fig.3 Comparison of reward for MSIF-DRL model during training process under various CAV penetration rates
4.2 测试过程
为了验证所提MSIF-DRL 换道决策模型在高速公路合流区驾驶场景中的有效性和优越性,首先,选取基于规则的模型[11]、深度学习DBN(Deep Belief Network)模型[12]、DSQ(Deep Sets Q)模型[30]以及结合风险意识模型和深度Q 网络模型的组合模 型(Deep Q-Network with Risk Awareness,RA-DQN)[20]作为基准方法;其次,设置不同渗透率并在各种仿真场景中进行测试;最后,根据奖励值变化情况、主线换道成功率、匝道合流成功率、平均速度、不安全碰撞时间出现比例以及Jerk 值等性能评价指标,详细对比各模型在奖励值、行车效率、安全性、舒适性方面上的优劣.DSQ 模型、RA-DQN 模型中的状态空间与原文献相同,动作空间、奖励函数则与本文所提模型保持一致.
4.2.1 奖励值对比分析
图4 为各模型在各种仿真条件下进行100 次仿真获得的奖励值分布.由图4 可知:在同一仿真场景中,随着渗透率的上升,各模型均可得到更高的奖励;与其他模型相比,MSIF-DRL 换道决策模型在各种仿真条件下均能收获最高的奖励值,而在20%渗透率和高交通需求条件下,MSIF-DRL 模型依然可以保持稳定的收益;规则模型由于其固定的数学模型研究范式,甚至在仿真中出现了较大的负奖励值,且奖励值分布也较为分散,综合稳定性最差;在同一仿真路段和渗透率条件下,当交通需求处于较高水平时,各模型获得的奖励值要高于低交通需求水平下的奖励值,此现象主要由于此时交通流量的增加,导致需要换道的车辆总数也随之增多.
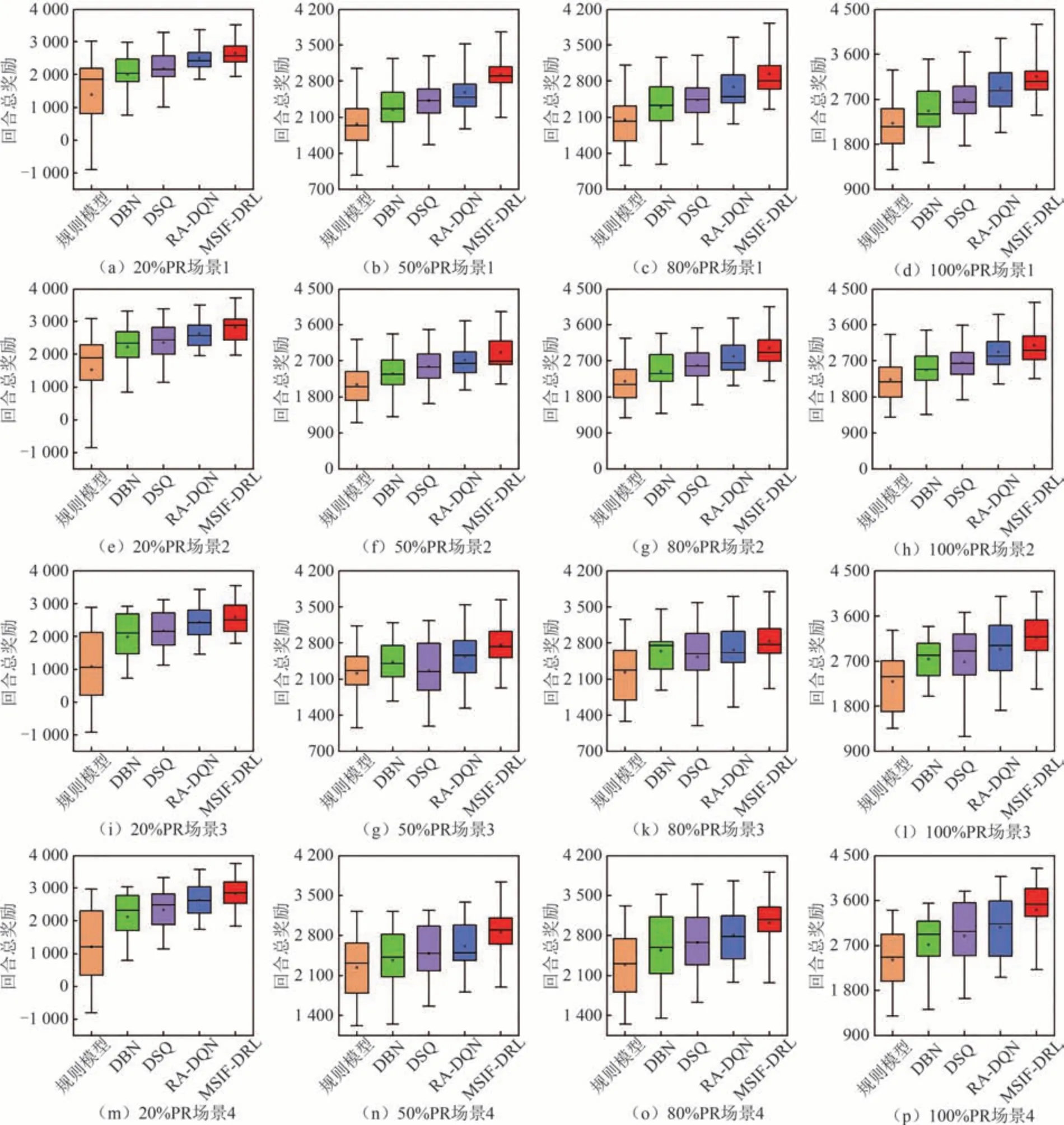
图4 不同渗透率下各模型在各场景中的奖励值对比Fig.4 Comparison of reward for models in different scenarios under varying penetration rates
4.2.2 行车效率对比分析
换道模型的行车效率主要通过主线换道成功率、匝道合流成功率以及车辆行驶过程中的平均速度大小进行对比分析.仿真时主线CAV 由原先车道成功换道至目标车道,且没有和其他车辆发生碰撞,则记为一次换道成功.匝道CAV 在加速车道上能够成功合流汇入主线,且没有和其他车辆发生碰撞,则记为一次合流成功,若到达加速车道末端仍未换道成功,或与其他车辆发生碰撞,则记为一次合流失败.图5 为不同仿真条件下各模型主线CAV 的换道成功率、匝道CAV 的合流成功率以及行车平均速度对比.由图5 可知:在同一仿真场景中,随着渗透率的上升,各模型均可得到更高的换道、合流成功率和平均行车速度;在各种仿真条件下,MSIF-DRL模型的换道、合流成功率均保持在90%以上,平均行车速度始终高于90 km/h,各项行车效率指标均为最优;交通需求水平的上升会导致测试场景复杂程度的增加,最后造成5 种模型的各项行车效率指标值较低交通需求状况时均发生了一定程度的降低,而MSIF-DRL 模型在两条试验路段上的各项行车效率指标受交通需求变化的影响最小,充分体现了该方法的强鲁棒性.

图5 不同CAV 渗透下各模型在各场景中的行车效率对比Fig.5 Comparison of driving efficiency for models in various scenarios under varying penetration rates
在低渗透率、高交通需求水平下,可以更加直观地看出本文所提换道模型对行车效率的提升.例如,在场景4 中使用MSIF-DRL 换道模型进行决策的CAV,相比基于规则模型、DBN 模型、DSQ 模型以及RA-DQN 模型控制的CAV,其换道成功率最大分别提升29.17%、14.73%、6.96%、6.26%,合流成功率最大分别提升27.71%、15.41%、7.64%、7.5%,行车平均速度最大分别提升17.43%、9.16%、5.84%、3.69%.
4.2.3 安全性对比分析
车辆行驶安全性主要通过碰撞时间TTC 衡量,TTC 值越小代表前后两车发生碰撞的可能性越大,碰撞危险程度高.图6 为5 种模型在不同场景和渗透率下,不安全TTC(TTC<1.5 s 时,碰撞几率大大提高[38])出现次数在测试过程中所占比例.由图6可知:使用MSIF-DRL 模型控制的车辆出现TTC值<1.5 s 的危险工况次数总体偏少,在各种仿真条件下均少于其他模型;DSQ 模型和DBN 模型相较于MSIF-DRL 模型、规则模型和RA-DQN 模型,出现不安全TTC 值的情况较多;当试验路段的交通需求由低变高时,各模型出现不安全TTC 值的次数均会变多,但MSIF-DRL 模型的增加幅度在所有模型中最低;当交通需求不变,渗透率逐渐增大时,各模型出现不安全TTC 值的次数均会减少;渗透率对MSIF-DRL 模型出现不安全TTC 次数的影响不如其他模型明显,主要因为MSIF-DRL 模型奖励函数中的驾驶安全项不仅考虑TTC,且学习效果优于其他模型,在低渗透率条件下就能明显降低车辆在换道过程中的碰撞风险,保证交通安全.
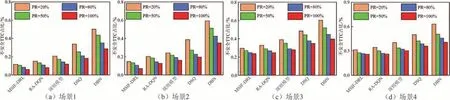
图6 各模型在不同仿真条件下出现不安全TTC 的比例对比Fig.6 Comparison of unsafe TTC percentage for each model under different simulation conditions
4.2.4 舒适性对比分析
车辆舒适性的强弱可由Jerk 值的大小来反映,较大的Jerk 值代表了车辆舒适性较差.图7 为5 种模型在不同场景和渗透率下,CAV 在行驶过程中的平均Jerk 值.由图7 可知:使用MSIF-DRL 模型控制的车辆Jerk 值相对较小,在各种仿真条件下均小于其他模型,能够生成更加平稳、舒适的驾驶决策,提高驾驶接受度;当试验路段的交通需求由低变高时,各模型中的CAV 平均Jerk 值会增大,而当交通需求不变,渗透率逐渐增大时,各模型中的车辆Jerk 值均会发生一定程度的降低;基于规则的方法主要通过在其模型加入固定的舒适性参数来提升乘坐舒适性,这种方法虽然简单,但却难以在车辆行驶过程中保证乘客处于舒适的状态.
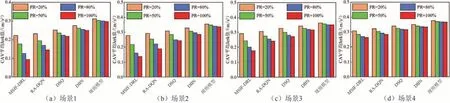
图7 各模型在不同仿真条件下的Jerk 值对比Fig.7 Comparison of Jerk for each model under different simulation conditions
综上所述,MSIF-DRL 模型可通过含有多源信息的状态空间以及多目标奖励函数反馈过程更好地理解高速公路合流区道路交通环境的变化,做出最优的CAV 换道驾驶行为决策,与规则模型、DBN 模型和DSQ 模型相比可获得更高的奖励值、行车效率、安全性和舒适性.
5 结论
1)针对混合交通流环境下高速公路合流区内CAV 的换道决策问题,提出了一种基于MSIFDRL 的端到端网联自动驾驶模型.该模型获取自车信息、感知信息、以及V2V 通信范围内上下游CAV信息作为状态输入,并根据信息源相对于自车的空间位置对来自不同车辆的信息分配权重,基于编码网络对拥有空间重要性(即权重)以及动态输入长度的多源信息进行了融合;通过含有行车效率、行车动机、平稳项、安全项、舒适项的多目标奖励函数来引导深度强化学习PER-D3QN 算法利用融合后的信息做出主线和匝道CAV 的换道行为决策.
2)仿真结果结果表明,相比于现有模型,不同仿真条件下的MSIF-DRL 模型在训练和测试时均拥有更高的奖励值、换道成功率、合流成功率、平均行车速度、舒适性以及安全性.即使在低渗透率、高交通需求的测试条件下,MSIF-DRL 模型仍能保持90%以上的换道成功率和合流成功率,体现了其面对复杂交通场景时的灵活性和较强的鲁棒性.
在后续的研究中,将考虑在深度强化学习算法中使用演员-评论家结构,将提出的MSIF-DRL 换道决策模型拓展到连续动作空间的驾驶行为决策中;同时随着协同感知技术的不断发展和数据存储容量瓶颈的突破,未来将进一步融合协同感知技术捕获的全局交通信息(即上下游CAV 感知的周围CAV、HDV 运动信息)以及含有时间尺度的历史环境信息,使得CAV 能够做出更合理的长期主动规避决策,提高决策的安全性.
