智能化期刊投审稿系统自然语言处理模块的应用探索
2023-12-29张芃捷袁皓伟
张芃捷 袁皓伟 唐 璞 冯 甜 石 芸
(重庆市卫生健康统计信息中心期刊部,重庆 401120)
目前,科技期刊发展正迎来难得的机遇与巨大的挑战。2019 年,中国科协、中宣部、教育部、科技部联合发布《关于深化改革培育世界一流科技期刊的意见》[1],文件提出要“全力推进数字化、专业化、集团化、国际化进程。实现科技期刊管理、运营与评价等机制的深刻调整,构建开放创新、协同融合、世界一流的中国科技期刊体系。”这为期刊积极探索未来办刊模式,开启融合转型发展提供了参考纲领。2021 年,中共中央宣传部、教育部、科技部印发《关于推动学术期刊繁荣发展的意见》的通知,提出科技期刊要顺应媒体融合发展趋势,通过流程优化、平台再造,实现数字化转型升级,这为期刊的移动化、智能化发展指明了探索方向。根据2022 年12 月中国科学技术信息研究所发布的《2022 年中国科技论文统计报告》,2010 年至2020 年(截至2022 年9 月)中国高被引论文数为4.99万篇,数量比2021年统计时增加了16.2%;2021年,中国卓越科技论文共计48.05 万篇,比2020 年增加了1.67 万篇,中国科技论文产出不断增加。在此关键时刻,引入人工智能相关技术,帮助期刊进行系统升级,应对未来的各项挑战具有极其重要的意义。
1.相关研究
2017 年,国务院印发《新一代人工智能发展规划》指出,要以技术突破推动科技期刊领域的应用和产业升级,以应用示范推动技术和系统优化,从而使科技期刊发展由数字化、网络化向智能化加速跃升。在这6 年间,已有众多学者为人工智能与期刊融合发展提供了思路。有学者提出,人工智能对期刊发展可能起到政治支持、技术支持、观念支持和行为支持的作用。[2]在顶层设计层面,科技期刊出版综合运用人工智能技术,将数据挖掘、机器学习、语音和图像识别及智能算法等技术应用到出版过程中,实现从经验到计算的选题策划、从辅助到自主的内容生产、从繁杂到效率的编辑加工、从粗略到精准的传播推送、从平面到场景的阅读体验、从大众到定制的内容服务,使科技期刊出版流程得以优化和升级。[3-4]在具体操作层面,学者提出,科技期刊可以考虑引入人工智能技术缩短稿件处理时间,提高期刊影响力[5],或是利用人工智能的协同系统进行科技论文内容生产,协助作者进行文献资料的整理、分析及写作[6],亦可通过“人物画像”实现内容的精准推荐等。
已有的研究成果为本研究提供了宝贵的研究思路和方向参考。然而,根据现有收集的相关资料进行分析,发现国内众多研究更多提供的是研究思路和发展方向,很少从具体操作层面,特别是落地应用效果的视角来研究和分析人工智能如何与科技期刊的发展相融合。基于此,本研究在已有研究进行讨论,以降低编辑处理投审稿的门槛要求、提高投审稿处理的速度和精度、优化稿件处理流程、节约出版时间为研发目标[7],采用人工智能分支技术之一——自然语言处理的相关技术,对搭建的实验用投审稿系统进行普适化通用智能升级探索和应用,归纳与总结经验,为我国科技期刊与人工智能的融合发展提供参考和借鉴。
2.投审稿系统升级需求分析
2.1 当前投审稿系统难点
“十二五”时期,众多科技期刊从传统的邮箱投稿逐步开发和升级使用投审稿系统。时至今日,传统的投审稿系统(或称为采编系统)运行效率已显得力不从心,逐渐成为限制期刊进一步发展的短板。一方面,投审稿系统在当初开发时,更加注重对投审稿流程的完整实现,流程复杂,操作多,与过去邮箱投稿相比进步巨大,但随着投稿量的不断上升,编辑和审稿专家更容易出现操作失误,需要更多的时间从多维度进行查询、参考,以此来判断稿件质量和创新性,影响审稿进度和审稿质量,造成巨大的人力资源浪费,也不利于青年编辑的平滑发展;而作者与编辑交流通过投审稿系统发送站内信息,存在信息滞后性,编辑很难在第一时间解决作者的燃眉之急,对编辑和作者的关系,及期刊发展产生负面影响。另一方面,当初的投审稿系统大多采用线性开发,每一条工作流程封闭且并未预留功能拓展空间,很难按需直接在系统环节定制开发新功能。例如,如果要将手动分配学科和专家,升级为智能分配学科和专家,不仅需要对整个送审环节进行重新开发,甚至可能导致系统不稳定,未知故障频出。但若要重新开发新系统,不仅需要巨大的财力和人力资源,还需要超前评估和预判期刊发展需求。如何在不影响科技期刊运行现状的基础上,在投审稿系统方面进行升级发展,这是众多科技期刊所面临的一大挑战。
2.2 编辑与专家审稿需求
在传统投审稿环节,编辑人员会根据自己的学科知识对稿件进行初步鉴定,评价其是否具有发表价值,而综合性医学期刊覆盖较多学科,受限于编辑专精方向,对稿件把握不够准确。[8-9]而在如今学科快速发展的背景下,根据关键词选择审稿专家,往往审稿专家并不是该方向的研究者,这样就会出现稿件送审被拒的问题,或者对审稿专家进行更换,延长稿件处理时间。[10-11]有文献报道,医学论文被拒审的原因中,69.8%(268/384)是因为专家对送审论文研究方向不熟悉,无法对来稿进行科学评价。[12]因此,新老编辑除了要持续学习提升所属领域的专业知识外,也需要能提升审稿速度和精度的辅助工具。而人工智能作为一项知识工具,能跨平台地进行信息补充和分类。审稿环节由传统的人审稿,转变为“机器+人”,首先让机器“阅读”大量科技期刊论文,然后将筛选后的相关论文让编辑阅读[13],以此提升编辑的知识服务能力,加速学术传播。
3.自然语言处理模块的实际应用
本研究的自然语言处理模块采用“外部挂载”的方式独立运行,以保障投审稿系统的稳定运行。
投审稿系统中,通常将浏览器作为前端,服务器系统、数据库作为后端。浏览器通过渲染代码,提取数据库中的数据内容,显示在页面上;同时,浏览器接受用户的指令和输入的内容,传入服务器系统,推动服务器系统进行下一步工作,最终将需要的数据内容存入数据库。由此,形成数据交互运行的基本循环。自然语言处理模块与投审稿系统相互独立,前者从投审稿系统数据库(后简称原数据库)提取所需信息进行处理,将预处理结果存入新的数据库“TabNLP”——“TabNLP”也与原数据库彼此独立。最终,通过对浏览器渲染内容进行略微修改,从数据库中提取预处理结果并显示在浏览器上,实现更多辅助信息的展示,推动审稿流程和编辑部管理工作的更高效运行。见图1。
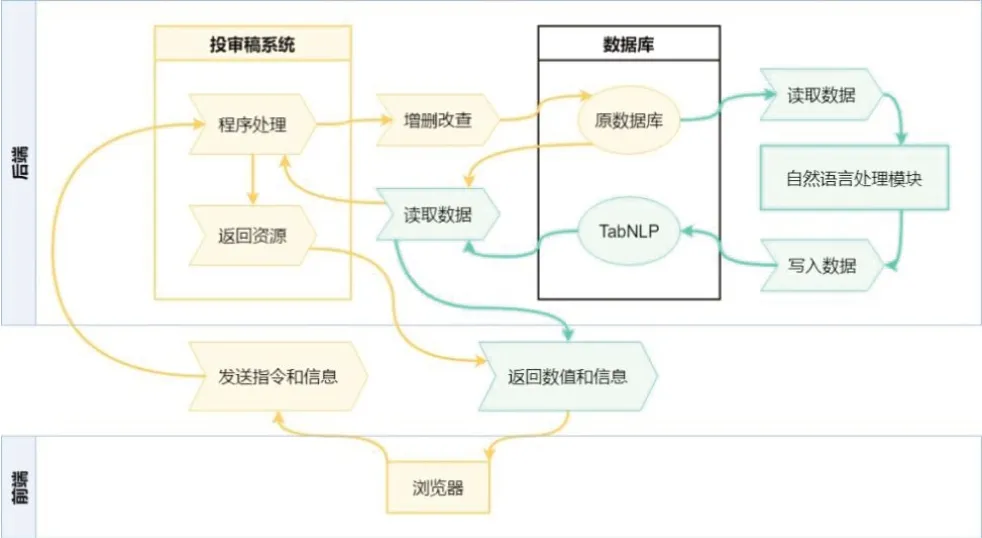
图1 投审稿系统自然语言处理模块运行流程
3.1 自然语言处理模块构造
投审稿系统自然语言处理模块主要包括4个部分,即核心模型、数据库“TabNLP”、训练部分、运行部分(见图2)。

图2 自然语言处理模块构造
3.1.1 核心模型
核心模型包括词嵌入层、均值化层、处理层。
设输入的论文标题为S,经过文本预处理,删除标点等特殊字符和并无实际语义的助词(如“的”“了”“于”等),得到输出S’。
(1)词嵌入层(embedding layer)。[14]使用分词模块将S’的每个字转为输入序列。假设该序列有N个字,则将S’的数据输入表示为{w1,w2,w3,…,wN},然后通过神经网络预训练的词嵌入模型,对输入序列进行向量映射,转化为词向量序列{v1,v2,v3,…,vN},vi ∈Rd,R 表示所有实体向量合集,d表示每个词的维度(本研究中d=128)。
(2)均值化层(Fasttext layer)。将词向量序列进行合并和均值化处理,得到S’的特征向量。计算过程如式(1)。
(3)处理层(process layer)。根据相应的功能需求,将算式(1)获得的结果wS’输入以下式子,分别获取不同结果,供最终调用。
一是用于中图法分类号和学科领域推荐功能,通过Softmax 函数处理。计算过程如式(2),其中,wi 表示wS’中第i 个向量值,d 表示向量维度(本研究中d=128),e 表示自然常量。具体模型采用Tensorflow 的Keras 进行构建。
二是用于发表相似文章提醒和智能问答功能,计算wS’与其他文本向量(wT)的余弦相似性。计算过程如式(3),其中wi 表示wS’中第i 个向量值,w’i表示wT 中第i 个向量值,d 表示向量维度(本研究中d=128)。具体模型采用sklearn的cosine_similarity进行构建。
三是计算文章创新性系数,计算过程如式(4),其中na 表示相似度超过预设阈值的文献条数,r 表示文章的文字复制比,nb 表示最大超阈值容忍文献数,e 表示自然常量。具体模型根据下列公式另行构建。
3.1.2 数据库“TabNLP”
“TabNLP”是自然语言处理模块新生成的数据库,存储核心模型计算出的所有数值和分析结果。由于其与原数据库相互独立,即使自然语言处理模块出现问题,也不会影响投审稿系统的运行,仅在网页显示时,缺少由自然语言处理模块输出的数值和分析结果。
3.1.3 训练部分
本研究以重庆市卫生健康统计信息中心下属期刊2020 年及以前的50000 余条投审稿数据(包括稿件信息、作者信息、审稿专家信息、已投稿稿件等)作为数据集,以8∶2的比例划分训练集和测试集进行训练,完成训练后独立保存模型,供运行部分调用。投审稿系统每天产生的新投审稿数据,都将按上述方式纳入训练和测试,对核心模型进行迭代。
3.1.4 运行部分
运行部分以“while True”作为永续运行条件,每隔2 秒从原数据库提取一次信息,发现有新投稿信息后即进行数据处理。设置定时启动的程序命令os.system,以命令提示符运行程序文件,可定时进行数据处理。如果由于新内容和新数据导致训练无法进行,运行部分可以采用保存好的模型继续进行计算和预测。
3.2 其他软件基础与资料
本研究以重庆市卫生健康统计信息中心下属期刊的投审稿系统为基础进行系统和数据库的安装和配置,系统为Windows Server 2012 R2,数据库为Microsoft SQL Server。采用Python 语言编写自然语言处理模块。为保证审稿系统与编程平台的相互独立运行,构建了Jupyter Notebook(支持实时代码、数学方程、可视化的Web 应用程序)进行编程与调试。
3.3 数据库
与数据库的通信包含2 个部分:从原数据库提取数据,向“TabNLP”数据库写入数据。
利用Python 的pymssql 工具库,于Python 程序端执行sql 语句提取数据库内容,再结合pandas 工具库将内容以数据矩阵模式存储。根据需求选取字段进行数据清洗,去除空值内容和不符合训练内容需求的数据。
TabNLP 数据库包含稿件ID(数据库内部ID)、稿件编号、用户ID、用户名、稿件名称、相似文章名称和相似度(1 ~3)、领域与专家推荐(1 ~3)、创新性系数、中图法分类号推荐(1 ~3)等27 个字段。
3.4 运行结果
自然语言处理模块可相关可能性最高的3 个学科领域及其中图法分类号、3 个已发表文章标题、3 位推荐审稿专家(见图3、图4);在接受作者问题后,自动将答案回复给作者,同时向负责该稿件的编辑发送邮件,提示编辑查漏补缺(见图5)。
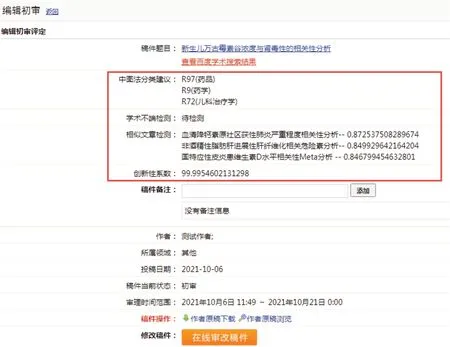
图3 初审、专审时提供的中图法分类号推荐、相似文章检测、创新性系数

图4 专审时的送审专家推荐
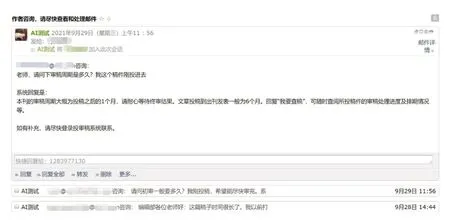
图5 系统向编辑发送提示邮件
单项学科领域测试中,准确率为60.19%;中图法分类号二级分类(如R56 呼吸系统)准确率为60.93%;中图法分类号一级分类(如R5 内科学)准确率为77.19%。
3.5 有待解决的问题
(1)单项学科领域测试整体准确率并不高,究其原因,在于医学类稿件存在学科交叉情况,例如稿件“老年肺炎的护理与康复研究”中,可涉及的学科领域包括老年科、护理科、呼吸内科、康复科等多个学科,在测试中以单一分类结果作为标准评判则必然会产生系统误差。(2)参与本课题计算的数据仅为期刊过去的投审稿数据,时效性、数量不足,未来可以考虑和国内知名数据库对接联系,导入更大规模的数据集进行训练。(3)本研究采用的服务器硬件性能不高,故课题组采用了折中的模型和算法,精度和准度均有待进一步提升,可尝试引入其他优化算法甚至预训练模型,提高拟合效果。
结语
随着软硬件的成熟,人工智能的意义逐渐凸显,尤其是科技部等六部门印发《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》[15],强调提升场景创新能力,加大应用示范,加速人工智能技术攻关,探索人工智能发展新模式新路径。本研究作为实际应用探索,为未来重新设计和开发符合智能化、融合发展趋势的新投审稿系统(编校平台)积累了技术和经验。通过研究,发现自然语言处理可以实现学科领域及专家推荐、中图法分类号推荐、已发表相似文章提示、智能问答和创新性系数计算等辅助功能,也可以采用“外部挂载”的方式对现有投审稿系统进行升级和过渡。
对编辑而言,人工智能带来了智能的一个关键组成部分:预测。[16]预测是利用手中已有的信息(亦被称为“数据”),填补缺失信息,生成编辑尚未掌握的信息;而在摸清文字和文章脉络规律后,可以根据具体使用场景和需求,进一步利用人工智能对文章进行体例、格式、内容方向的预测和判断。人工智能在给编辑审稿带来辅助信息提示的同时,也会逐步影响编辑思维,从主观感受往更为理性、数据化方向转变。对期刊行业而言,人工智能的引入也会对传统业务考核机制产生影响。以往对编辑在审稿方面的考核,除了审稿时间能直观掌握外,内容、主题方面因其更加主观,导致考核存在滞后性,即稿件在终审,乃至刊登后才可能因为内容方面存在的问题,倒查发现投审稿流程中存在的失误。但引入人工智能以后,人工智能可以基于稿件每个流程的数据,对下一个流程的操作给出判断和建议。一旦提前将与人工智能判断和实际操作相差甚远的稿件做进一步检查,可能提前及时清理错误处理的稿件,并可基于此进行规范和考核。
人工智能与科技期刊的融合之路并非坦途。早在人工智能技术刚兴起时,业界就提出了两者融合发展的众多构想,但在实际应用的过程中,这些构想要么脱离了科技期刊的行业背景,要么在软硬件实现方面存在困难:(1)众多编辑和期刊管理人员不具备人工智能相关的专业背景,难以理解算法的基本原理,不理解计算结果,遇到问题也较难清晰地表示和复现错误情况;(2)目前自然语言处理主要以预训练模型为主,而在涉及较为复杂的价值判断选题或敏感选题中,模型可能因数据存在的偏倚导致判断有误,难以稳定地代替编辑进行决策;(3)不同出版集团,乃至同一个出版集团的不同期刊间的数据通道尚未完全打通,导致人工智能模型训练的数据不足。此外,人工智能在对历史数据进行训练和无差别预测中,存在“过度拟合”现象。如果跳过编辑,直接采纳人工智能意见进行稿件处理,则有误判的可能,甚至导致闪光的潜力稿件被埋没。因此,越智能、越具有创新的内容编辑环节应当是人工编辑的产物,人机合理分工是自动编辑的关键。[17]
