基于注意力机制的CNN-GRU 煤层气产能预测方法研究
2023-12-29赵海峰诸立凯刘长松张先凡
赵海峰 ,诸立凯 ,刘长松 ,张先凡
(中国石油大学(北京) 石油工程学院,北京 102249)
煤层气生产数据包含煤层气井的生产特征动态变化规律,通过对这些规律的研究,可以从煤层气井历史生产里得到新的认识,这对将来煤层气井的指导生产具有重要意义[1-3]。煤层气数据量繁多复杂,其中包含许多类型,具有多种数据维度,再加上原始数据均来自排采现场,难免会出现数据丢失和不相关的数据,这意味着生产数据的处理及挖掘数据间的关联性至关重要[4]。目前,大多数学者在研究煤层气产量主控因素问题上,都倾向于对地质因素进行分析;运用渗流理论和吸附解吸理论等方面的知识来开展数值模拟研究[5-7]。然而,这种方法往往只适合理论研究,难以应用到实际现场。许多学者提出了人工智能神经网络算法模型来进行处理[8-12],取得不错效果,为神经网络在煤层气产能预测领域的后续发展提供借鉴。由于煤层气产能变化具有时序性,排采参数间存在一定特征性,历史序列过长时模型训练过程中容易丢失关键历史信息。为解决这一问题,以韩城区块的煤层气井数据作为依托,通过随机森林特征重要性方法对排采参数与日产气间的重要性进行分析;在此基础上建立一种基于Attention 机制的卷积门控循环单元网络组合模型CNN-GRUA,利用CNN 模型所具备的局部特性感知能力来提取输入数据间的高层特征;GRU 模型按照时序顺序接收由CNN 模型处理后的数据特征的时间信息,加入 Attention 机制给予输入特征不同的概率权重,提高关键信息对煤层气产能的影响,实现对煤层气产气量的预测。
1 算法原理与模型
1.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)包含卷积层和池化层[13]。卷积层负责提取输入序列参数特征传入池化层,再通过全连接层得到最终结果。在时间序列问题的研究上,常采用一维结构。卷积神经网络结构图如图1。
1.2 GRU 原理结构
LSTM 用于分析时间序列数据,解决了RNN处理长周期数据出现梯度爆炸和梯度消失的问题。GRU 对LSTM 结构改进,只包含重置门和更新门[14]。两者预测精度差距不大,但GRU 模型收敛速度快,运行成本低。重置门负责将当下输入信息与过去信息相结合,更新门通过设置时间步来保存记忆信息。GRU 神经网络结构图如图2。
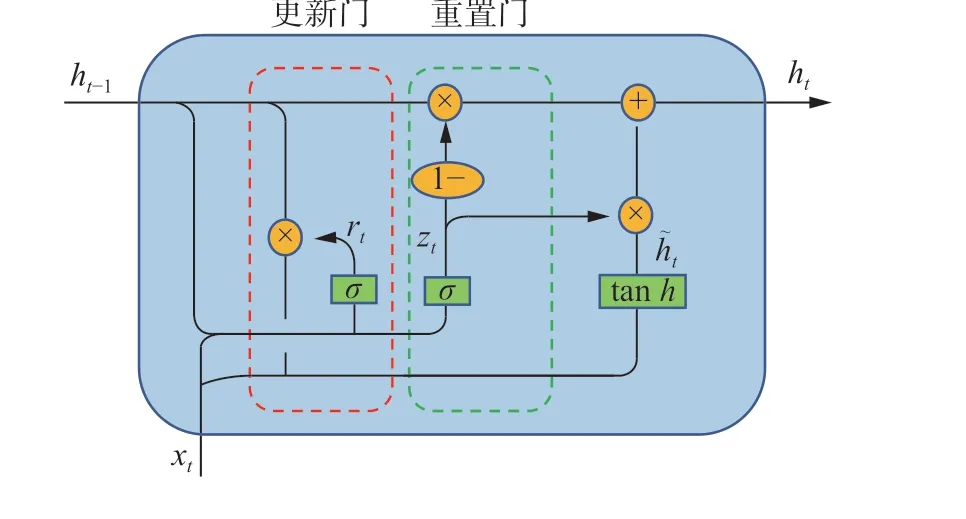
图2 GRU 神经网络结构图Fig.2 Structure diagram of GRU neural network
计算公式如下:

1.3 Attention 机制原理
Attention 作为资源分配机制,主要提高对关键信息关注,降低无关信息干扰,类似于人类大脑的注意力分配功能[15]。通过赋予不同时刻输入序列隐藏层向量相应的权重,考虑关键信息作用提高模型预测精度。Attention 机制结构图如图3。

图3 Attention 机制结构图Fig.3 Attention mechanism structure diagram
图中:xi为输入值;hi为GRU 隐层状态输出;βi为注意力权重值;y为输出;i为数据数。
2 参数优选及模型构建
煤层气开采具有间歇性和不稳定性的特点,排采数据以天为单位随时间变化,是时间序列数据。在煤层气产能预测中,排采数据包含煤层气生产特点和动态数据变化规律。传统神经网络方法难以考虑到历史排采序列前后关联性及其内在规律。CNN 通过卷积层和池化层提取数据间高层特征,提高模型预测精度。GRU 针对煤层气开采不稳定的特点,用于处理数据动态变化,从中挖掘煤层气生产规律。但煤层气开采周期较长,导致GRU 网络会出现丢失信息的状况。因此,引入Attention 机制通过赋予不同时刻输入序列相应的权重,提高模型对关键信息的学习,避免关键信息丢失。基于上述分析,提出一种基于Attention 机制的卷积门控单元网络CNN-GRUA。
以韩城区块某煤层气井排采数据为例进行分析,包括井底流压、套压、动液面高度、日产水量、冲次、泵效、泵径等,将这些特征因素代入模型训练之前,利用随机森林算法进行优选挑选,提高神经网络的预测效果,防止过拟合。
2.1 基于随机森林排采参数优选
随机森林是一种集成算法[16],由许多决策树按照特定方式相互连接组成。决策树数据由当前数据序列随机划分,最终结果由各决策树结果决定。基于这种方式,会产生未被决策树划分的数据,称作袋外样本(OOB),而特征序列重要性判定由袋外样本决定[17]。计算公式如下:
式中:V IM为特征重要性;errOOB1 为每棵树的袋外样本误差;errOOB2 为加入噪声数据后重新计算的样本误差;N为决策树个数。
选取排采过程中井底流压、套压、动液面高度、日产水量、冲次、泵效、泵径等因素作为输入特征,日产气量作为目标值,利用随机森林算法对排采过程中7 个参数进行特征重要性评价。各排采参数的重要性如图4。

图4 各排采参数的重要性Fig.4 Importance of each drainage parameter
从中选出靠前的5 个因素分析其与日产气之间的关系,同时也将这5 种因素序列作为后续模型建立训练的输入端,分别为:井底流压、套压、动液面高度、日产水量、冲次。
2.2 日产气量与排采参数间相关性分析
基于上述随机森林特征重要性分析可知井底流压、套压、液柱高度、日产水量、冲次等排采参数与日产气量相关性较高,通过皮尔逊相关系数进行相关系数运算,计算公式如下:
排采参数之间相关系数热度图如图5。

图5 排采参数之间相关系数热度图Fig.5 Heat map of correlation coefficients between drainage parameters
由图5,日产气量与各排采参数间的关系主要表现为:日产气量与冲次呈现正相关性,日产气量与井底流压、套压、日产水、动液面呈现负相关性。
煤层气生产井通过调节气井冲次控制排采速度(产气、产水)。当进入气水两相流阶段时,气井冲次越高,产气量越高。因此,在考虑煤储层排采过程中的速敏、应力敏感性条件下,冲次与日产气存在正相关关系。
动液面高度变化体现排采强度,随着液柱高度降低,储层压力减小,煤层气产量增大,产气量与液面深之间呈负相关关系。造成上述现象的原因,主要在于套压和液面深之间存在正相关关系,液面深度受套压控制,致使液面深与产气量的关系受控于产气量与套压的关系,因此产气量与液面深之间呈负相关关系。
煤层气井投产初期,煤层气井进入饱和水单相流阶段,通过控制产水速度,降低井底压力及压降范围。当井底压力降低到临界解吸压力以下,煤层气井进入初始产气阶段,一般井底流力下降幅度越大,产气量越高,两者存在负相关关系。
套压值可反映煤层气的产出状况,“见压放气”也是煤层气井生产常用的技术手段。当煤层气井进入饱和水单相流阶段时,套压值为0。气水两相流及单相气流动阶段,两者关系存在多重性,但总体趋势为在保证稳定产气的前提下,套压值降低时,产气量上升,两者存在负相关关系。
煤层气井不同排采阶段产水量及产气量的关系具有多重性。在饱和水单相流阶段,井底流压未降低到临界解吸压力以下,产气量为0。在气水两相流阶段,保证连续性生产条件且产水量充足条件下,水相渗透率下降,气相渗透率上升,两者存在负相关关系。
2.3 模型构建及运算过程
历史序列是日产气量变化的表现,它包含了日产气预测规律的重要信息。CNN 模型作为组合模型的上层,其卷积层最先接收到影响煤层气产能的各排采数据参数。作为卷积层可以充分提取输入序列数据间的高层特征,再通过池化层筛选提取较为主要的数据特征,减少计算量。GRU 模型作为组合模型的下层,可以按照时序顺序接收由CNN 模型处理后的重要排采数据特征的时间信息,由于其门结构的构造,可以考虑前后数据之间的关联性。Attention 机制通过赋予不同特征向量相应的概率,对权重参数矩阵实现不断更新。CNN-GRUA 模型预测流程图如图6。
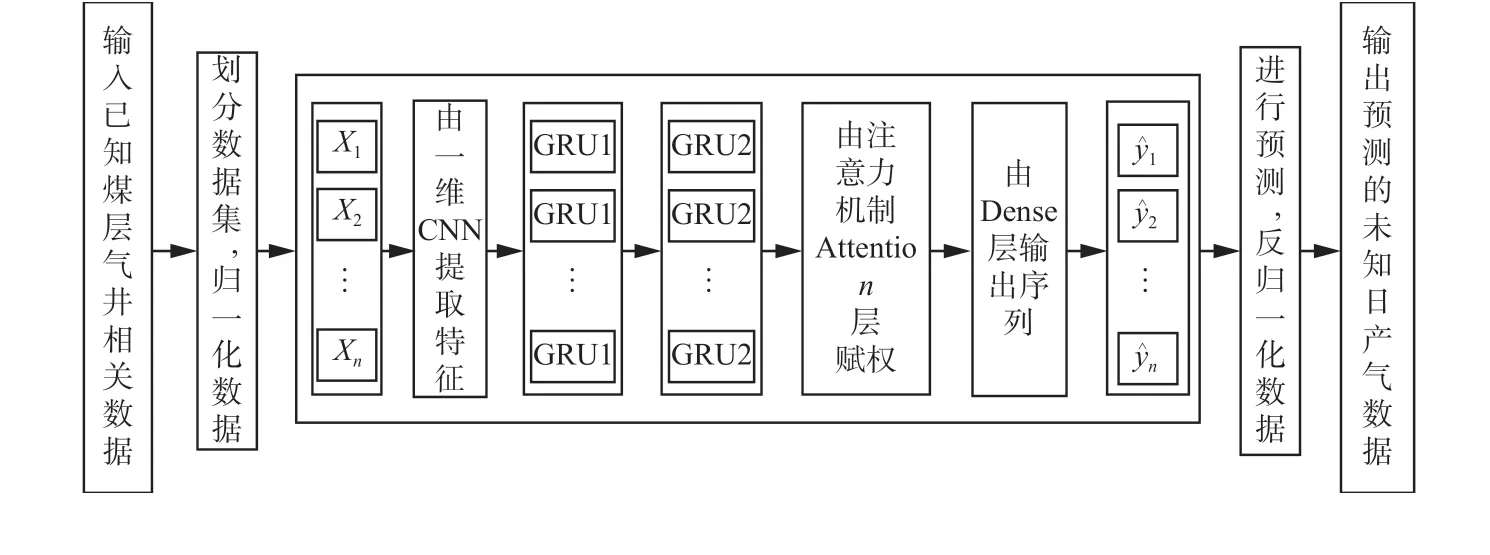
图6 CNN-GRUA 模型预测流程图Fig.6 Flow chart of CNN-GRUA model prediction
2.4 评价指标
性能评价标准用来衡量模型的预测效果。选取2 种评价标准:均方根误差(RMSE)、平均绝对误差百分比(MAPE)。其计算公式如下:
式中:y(i)为 实际值;y′(i)为 预测值;N为y(i)的个数。
3 算例分析
3.1 数据选择及归一化
韩城区块主要开采山西组3 号煤和太原组5 号、11 号煤层,以11 号煤层为研究对象,埋深738~835 m,平均埋深865 m,煤层厚度3~7 m,镜质组反射率为1.81%~3.09%,为无烟煤。煤层含气量4.75~19.73 m3/t,煤岩孔隙度1%~8%,煤层渗透率介于0.05×10-3~12×10-3μm2,综合分析表明,11 号煤层孔隙未被矿物充填,对煤层气储集有利,煤岩孔隙结构中,以大中孔隙为主,外生裂隙相当发育,孔、缝间连通性好,有利于煤层气的储集和开发[18]。
为验证所提煤层气产能预测方法的精确性和有效性,利用某井区的某井数据进行验证。选取2012 年4 月至2016 年8 月共1 600 d 的煤层气排采数据作为数据集,将其划分为训练集与测试集,其中训练集1 440 d,测试集160 d。数据每日采集1 次,模型输入特征维度为5 维,分别为:冲次、套压、井底流压、日产水、动液面高度,输出特征维度为1 维的日产气量。
为加速训练及提高模型预测的精度,对数据进行归一化处理。

3.2 模型结构参数确定及训练
根据确定的煤层气排采参数与日产气量所构成的训练集,基于Adam[19]优化学习算法,对CNN-GRU 神经网络进行训练,初始状况下经过不断实验调试,CNN 模块参数设计结果对比见表1,GRU 模块参数设计结果对比见表2。

表1 CNN 模块参数设计结果对比Table 1 Comparison of CNN module parameters design results
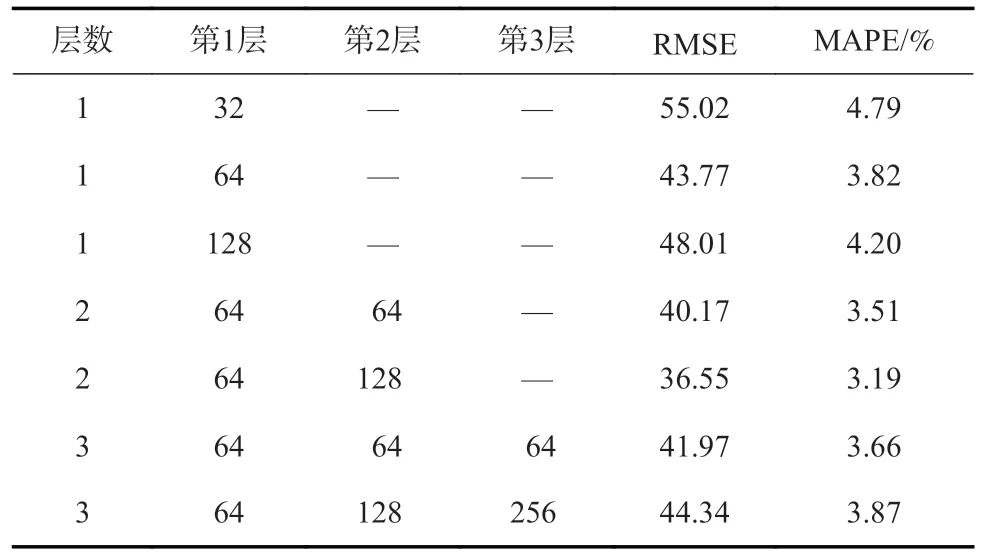
表2 GRU 模块参数设计结果对比Table 2 Comparison of GRU module parameters design results
由表1、表2 数据最终确定模型最优网络结构设置具体如下:CNN 卷积层层数为2,第1 层和第2 层卷积核个数分别为32 和64,大小为3,取Relu 激活函数激活,池化层池化方法采用最大池化,GRU 层数为2,隐藏神经元个数分别为64 和128,训练次数epochs 设置为300,防止训练过程中出现过拟合现象,在每层门控循环单元网络后采用Dropout 方法,大小设置为0.25。
将排采数据代入所设计的组合模型CNN-GRU进行历史日产气量拟合,日产气量预测值与日产气量实际值对比如图7,两者结果非常接近说明模型在训练过程中并没有出现过拟合或者欠拟合的状况,具有较好的泛化能力,可以应用解决煤层气产能预测问题。

图7 日产气量预测值与日产气量实际值对比Fig.7 Comparison of predicted daily gas volume and actual daily gas volume
3.3 煤层气产能预测对比
在训练效果最优的CNN-GRU 神经网络模型基础上,引入Attention 机制进行优化,对未来160 d 的产气量进行预测,与煤层气日产气量实际值相比较,预测值的平均绝对误差百分比为1.72%,预测值与实际值基本一致,最优模型获得的评价指标结果见表3,不同模型日产气预测值与实际值比较如图8。
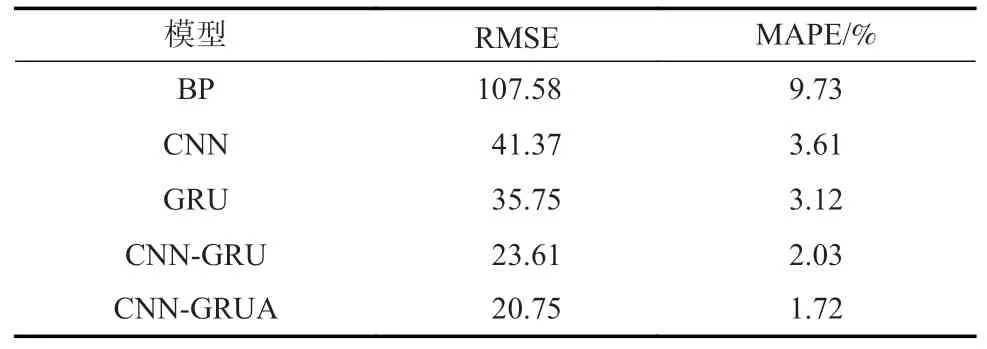
表3 最优模型获得的评价指标结果Table 3 Evaluation index results obtained by the optimal model

图8 不同模型日产气预测值与实际值比较Fig.8 Comparison of predicted and actual daily gas output from different models
由表3 和图8 可以看出:在RMSE 和MAPE这2 种模型评估标准下,引入注意力机制的模型CNN-GRUA 的预测效果最好,BP 模型的预测效果最差;从数据上来看,RMSE 分别下降了80.71%、49.84%、41.95%、12.11%;MAPE 分别下降了82.32%、52.34%、44.87%、15.27%。可以看出,本文所提出的方法相对于其他方法在这2 种评估标准下有较大提升,能对煤层气井产气量进行精准预测。
为了验证模型的适用性,选取了该地区平均日产量不同的5 口井进行实验,其中平均日产气量在500~1 000 m3的井记作L-1,平均日产气量在1 000~2 000 m3的井记作L-2、L-3,平均日产其量在2 000 m3以上的井记作L-4 和L-5,来预测未来160 d 的日产气量情况。煤层气井实际产量与模型预测产量见表4。
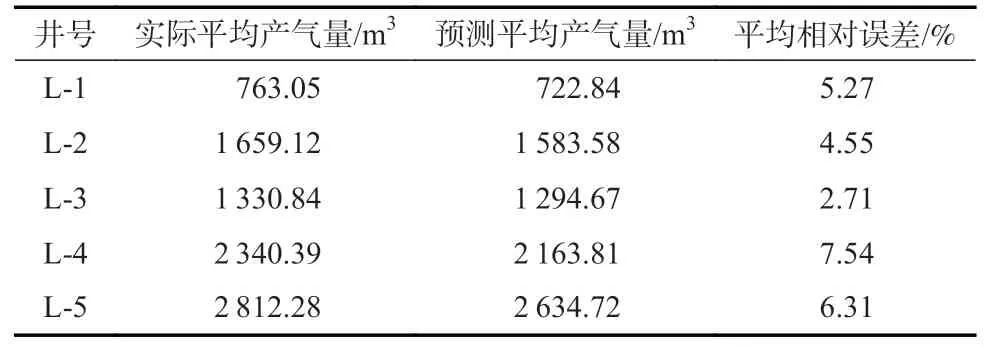
表4 煤层气井实际产量与模型预测产量Table 4 Actual coalbed methane well production and model forecast production
由表4 可以发现,CNN-GRUA 模型的预测结果与实测值的误差平均值都小于10%,证明本文所提的模型具有较强适应性。
4 结 语
1)基于随机森林特征重要性判断方法从排采参数中选出影响煤层气日产气量的主要因素,解决了模型构建过程中原始数据维度复杂的问题,避免了无关因素的干扰,提高了模型预测的精确性,节约了时间成本。
2)利用CNN 网络善于提取数据间高层特征的特性,避免了人工选取数据特征的局限性,利用GRU 网络善于学习长时间历史数据前后关系的特性,解决了长时间学习造成的梯度爆炸问题,利用Attention 机制提高模型对关键信息的关注,避免出现重要信息丢失,实现对排采数据的充分挖掘。
3)针对煤层气开采现状,将本文所提出的CNN-GRUA 网络模型应用到煤层气产能预测问题上。结果表明:该模型预测效果好,预测精度高,具有一定应用潜力。
