突发事件情境下社交媒体用户的言语行为分类研究
2023-12-28孙冉安璐,2
孙 冉 安 璐,2
(1.武汉大学信息管理学院,武汉,430072; 2. 武汉大学信息资源研究中心,武汉,430072)
1 引言
社交媒体传播和在线讨论的普及深刻改变了大众间的交流互动方式,在疫情期间,社交媒体平台的舆情信息呈爆炸式增长。网络舆情的本质是一种言语行为,言语行为分析可以超越用户话语的字面意义,例如反讽属于一种间接言语行为,其言外之意是对其文本字面意义的否定或者对立。以往研究指出,主题分析和文本情感倾向分析等在政府舆情检测和治理中发挥着重要作用[1-2],然而从语言粒度出发对用户在文本中表达意图和心理状态进行细粒度分析的研究较少。言语行为理论(Speech Act Theory)是文本分析中最重要的语言学理论之一,可用于理解社交媒体中用户的行为、显式和隐式语言特征,例如机器人检测[3]、在线评论情感分析[4]、人格分类[5]、谣言识别[6]。在突发事件情境下,对网络各类言语行为进行网络舆论监督是十分必要的。由此,本文拟解决三个问题:①如何提高判定社交媒体用户进行言语交流过程中言语行为性质的准确性;②影响言语行为识别的特征有哪些以及它们如何影响模型效果;③不同言语行为在其影响力和情感上有何差异。
本文以新冠疫情期间推特平台上大众对疫苗的讨论为数据集,基于言语行为理论构建适用于社交媒体平台的用户言语行为分类体系,结合神经网络方法和机器学习方法构建突发事件情境下社交媒体用户言语行为自动分类模型,探究用户特征、文本向量特征、情感特征等在言语行为分类上的表现,分析不同言语行为在影响力和情感上的差异性。自动识别网络舆情中的言语行为,可以帮助更好地理解在突发事件情境下用户自生成内容背后的含义和意图,从而进一步揭示社交媒体用户心理状态和用户之间丰富的情感交互。
2 相关研究
2.1 言语行为理论
言语行为理论认为话语者不仅通过语言来传达其言内之意,还通过言外行为和言后行为对接受者产生影响[7-8]。Searle[8]首先将言语行为分为直接言语行为和间接言语行为,进一步根据基本条件、真诚条件、先决条件和命题条件将施事行为划分为阐述类或者断言类、承诺类、指令类、声明类和表达类。其中,阐述类或断言类主要是指话语者陈述或描述其认为的真实情况(如推测、断定等),承诺类是话语者对自己未来的行为进行承诺,指令类是指话语者试图通过言语使听者采取特定行动(如请求、命令和建议等),表达类是话语者表达自身的心理状态(如开心、感谢和抱怨等),声明类是指话语者试图通过话语改变世界。
目前,将言语行为理论应用到网络舆情领域的研究较多。大部分学者直接依照Searle言语行为理论进行分类[5],也有学者进一步将其分为陈述、提问、建议、评论、混合类[9],或者考虑到推文特征将其划分为阐述、推荐表达、提问、请求和其他[10],还有学者充分考虑了在线交流特征将言语行为划分为询问、请求、指令、邀请、告知、声称、期望、接受/拒绝、道歉、感谢等[11]。社交媒体用户自生成内容最常由表达性言语行为组成,其次是阐述[12]。不同事件或者话题下的推文具有不同的言语行为分布[9-10]。社交媒体意见领袖在与不同的用户群体交谈时,倾向于使用不同的言语行为[11]。李嘉等[13]基于SVM算法提出了网络舆情环境中的冲突类言语行为分类模型,发现句法特征和结构特征在言语行为分类上的积极效果。特别是在冲突性网络环境下,用户多采用批评、嘲讽等冒犯性言语行为去反驳对方[14]。Jahanbakhsh-Nagadeh等[15]验证了言语行为特征在谣言识别中的重要性,并且发现社交媒体谣言中常见的言语行为类别为叙述、质询和威胁。Zhao等[16]发现社交媒体用户倾向于评论包含表达和自信行为的帖子。Ordenes等[17]通过评估承诺类、表达类和指令类等信息对消费者分享的影响发现,与阐述类或表达性信息相比,指令性信息引起的消费者分享较少,而且推文情感的积极性与消费者分享具有显著的正相关关系。Argyris等[18]基于言语行为理论研究互动、话语、表达和诉求对引发投诉人积极情绪的影响发现,在投诉人的回应中使用言语行为可以引发积极的情绪。除了常见的五种言语行为分类,不少学者对社交媒体自夸[19]、反讽[20]、抱怨[21]、幽默[22]等言语行为进行了自动识别和分类。本文关注突发事件情境下社交媒体文本中语用特征,从语用学视角以言语行为的相关理论为指导,对社交媒体平台上文本语用功能进行划分,构建适用于社交媒体的言语行为分类体系。
2.2 言语行为分类算法
言语行为分类体系及自动分类的应用研究主要集中在电子邮件[23]、对话系统[24]、机器翻译[25]等。对社交媒体内容采用自动分析方法能有效理解用户行为,但基于日常对话式语料和电子邮件的言语行为分类方法,不能直接应用于微博、推特等社交网络上的言语行为识别。已有学者将朴素贝叶斯、决策树、逻辑回归等机器学习算法应用于社交媒体言语行为分类中[26,10]。模型选取的特征大多为词性标注、语义特征、句法特征、情感特征等,如话语中的第一个单词可以准确预测其言语行为类别[26]。Zhang等[9]构建了基于单词和符号特征的SVM言语行为分类器;Vosoughi等[10]通过对比分析决策树、朴素贝叶斯、SVM和LR模型的言语行为分类效果发现,逻辑回归分类器的性能最优。
近年来,循环神经网络模型及其变体等深度学习算法逐渐成为言语行为分类的重要研究方法。Algotiml等[27]对比多种机器学习方法发现,与SVM相比,LSTM、Bi-LSTM等深度学习方法在推文言语识别任务上具有其优越性;Yoo等[28]基于词性标注和依存关系,采用基于深度学习模型对言语行为进行分类。为更好地理解推文的内容和用户交流意图,Saha等[29]采用基于 CNN 的算法对声明、表达、建议、请求、问题、威胁这七种常见的推文行为进行分类。随后,他们又验证了结合BERT预训练语言模型和神经网络方法的推文言语行为分类器优于其他基线方法[30]。然而,现有基于深度学习的言语行为分类算法忽略了用户、时间、文本结构等特征在确定言语行为中的作用。
综上所述,直接以突发事件情境下社交媒体用户言语行为为对象的研究十分有限,并且大部分研究所采用的言语行为分类体系局限于五大类,没有对适用于社交媒体的言语行为分类进行细分。因此,对突发事件情境下社交媒体言语行为分类开展研究,将言语行为识别与机器学习、深度学习相结合,有助于了解突发事件中公众的行为规律,帮助相关部门做出准确的决策分析。
3 研究方法
本研究拟结合神经网络模型和XGBoost模型,提取用户特征、文本特征和时间特征,训练基于机器学习和深度学习的分类器,并且选择多种基线模型的性能进行比较。随后,利用SHapley Additive exPlanation(SHAP)[31]算法分析突发事件情境下社交媒体用户的言语行为分类模型中不同特征的解释能力,可视化单一特征变量对言语行为分类的定量影响,讨论突发事件情境下用户言语行为分类主要影响因素。最后,利用非参数检验方法Kruskal-Wallis对不同言语行为的情感、影响力等差异性进行检验。研究框架如图1所示。

图1 突发事件情境下社交媒体言语行为分类方法框架
3.1 社交媒体言语行为分类体系
依据Searle[8]提出的言语行为理论,并结合以往对言语行为的分类规则[5,9-11],本文将所有语料的言语行为分为阐述类、表达类、指令类、承诺类和其他,每一类的具体描述如表1所示。由于在社交媒体中,大部分舆情无法通过话语来实施权利,因而本文不考虑声明类言语行为。阐述类话语可以包含有断定、赞扬、批评、推测、析因等语用能力[32],因此除了陈述和引述,本文将阐述类进一步细分为断定、质询、析因等。
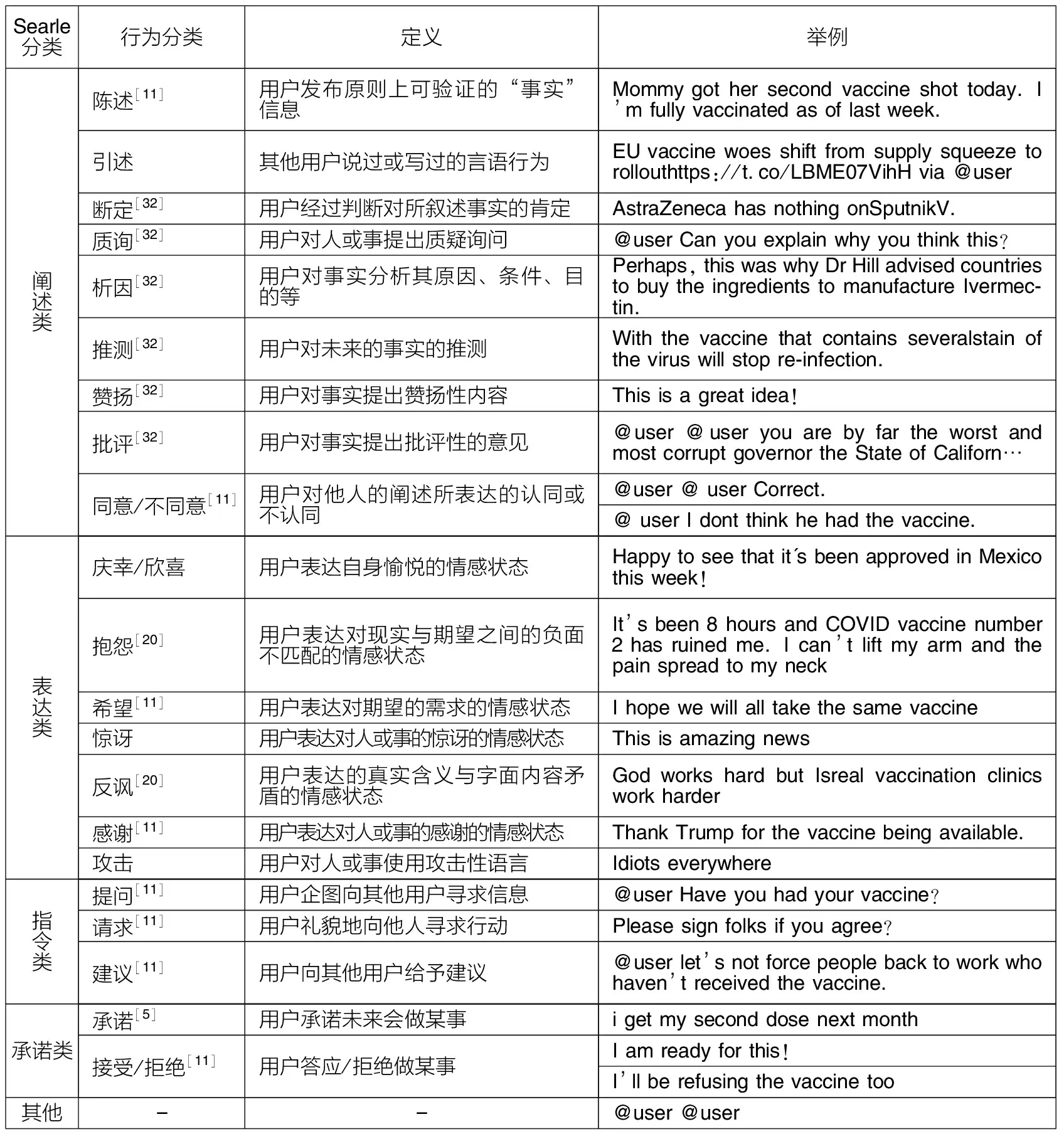
表1 社交媒体言语行为分类体系
3.2 言语行为类别的特征设计
本文在构建突发事件情境下社交媒体用户言语行为分类的特征体系时,考虑了以往言语行为分类研究中所考虑到的文本特征,如文本向量表示[30]、情感特征[10]、词性特征[28]、文本结构特征[13],另外,有研究发现,发布在周末和工作日的推文具有不同的情感分布模式[33],发布在星期六星期天的推文数量较低,周一开始逐渐增加,直到周三达到最高后开始下降。为了分析时间特征在用户言语行为分类的重要性,本文考虑到了信息发布的时间特征。由于不同话题下的推文具有不同的言语行为分布[9-10],不同用户在其发布信息时会有不同的言语风格[34],本文还将文本主题特征、用户特征(用户基本属性和用户行为特征)考虑在内,如表2所示。
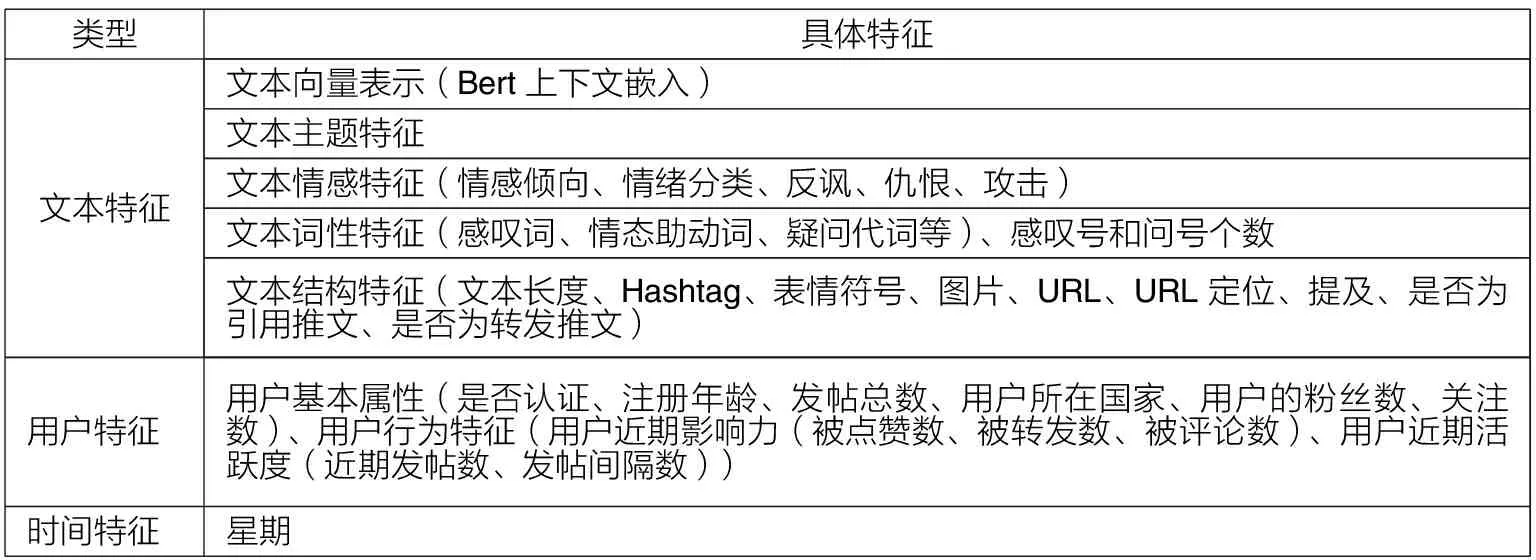
表2 社交媒体言语行为分类的特征体系
3.2.1 文本特征
(1)文本向量表示:应用 BERT 模型[35]来生成文本向量表示。BERT模型的输入为每条推文文本,进行向量化表示并用于BERT模型的训练,最终得到每条推文的特征向量与分类标签共同组成分类器的输入进行最终的分类。
(2)文本主题特征:利用 BERTopic[36]主题建模算法对推文进行话题提取,与经典的LDA、NMF 和 Top2Vec 等主题算法相比,BERTopic在 Twitter 数据上具有更好的主题建模效果[37-38]。BERTopic 主题建模包括以下三个步骤:①采用基于RoBERTa的大规模语言模型BERTweet[39]获取输入文本的嵌入向量,其中,本文采用的bertweet-covid-19-base-uncased预训练模型的语料库是由230万条Covid-19相关的推文组成;②采用UMAP 降维算法降低文本嵌入向量的维度,并且利用HDBSCAN自动选择最优的主题聚类结果;③使用基于聚类的 TF-IDF (c-TF-IDF) 来提取和减少主题数量。BERTopic允许为主题表示选择不同的 n-gram 模型,在实验中设置的n_gram取值范围为1—3。通过对上下文信息进行编码,并在使用 UMAP 进行文档聚类的过程中保留局部结构,从而提高了主题分析的质量。为了选择最佳的主题数量,调用gensim包中的连贯性得分(C_V coherence)衡量主题模型的性能,主题连贯性得分越高,代表主题模型越好[40]。
(3)文本情感特征:本文采用基于BERTweet预训练模型的 TweetEval分类器[41]进行推文的文本情感分析,TweetEval评估框架由七个异构的分类任务组成,包括情绪分类(悲伤、开心、悲观、愤怒)、情感分类(正、负、中)、表情符号、反讽、仇恨、攻击性语言识别。通过模型得到的各类情感得分将作为情感特征输入到分类器中。
(4)文本词性特征:不同类型的言语行为在词汇类型、标点符号上有所不同,如感叹词可以用来表达情感[25]。本文采用Python中的textblob词性标注工具包对推文进行词性
标注,可以得到每条推文中分别包含35类词性的词语个数。此外,本文统计了每条推文中感叹号和问号的个数。
(5)文本结构特征:推文内容中的各类符号可以加强语义的表达,本研究将是否有链接、链接的位置、哈希标签个数,是否包含图片、视频、提及(@)个数、表情符号纳入文本结构特征中。
3.2.2 用户特征
用户的基本属性包含是否认证、所在国家、用户粉丝数、用户关注数、用户发布微博总数、用户注册年龄。用户行为特征包括用户近期影响力和用户近期活跃度,其中,用户近期影响力是指用户在数据采集的前一个月内(2021年1月1日—2021年1月31日)的被点赞数、被转发数、被评论数;用户近期活跃度是指用户在数据采集的前一个月内的发帖数、发帖平均间隔天数。
3.3 言语行为分类算法
本文将言语行为识别看成多分类问题,基于主题特征、情感特征、文本词性特征、用户特征等,分别训练并构建支持向量机、逻辑回归模型、随机森林、XGBoost等分类方法,采用SMOTE算法[42]来减少样本不均衡对分类模型的影响。其中,XGBoost算法[43]是基于集成学习的提升树模型,其基础树结构为CART回归树,通过正则项和列抽样可以有效提升模型的稳健性。BERT模型中包含双向transformer编码层,能有效获取语句中的双向关系,因此,本文还利用BERT模型提取推文的上下文信息,将生成的文本特征向量分别输入到CNN、RNN等深度学习模型进行分类。
3.4 基于SHAP算法的特征重要性排序
特征重要性排序可用于评估预测模型中输入特征的相对重要性。SHAP算法通过计算每个特征对预测模型的边际贡献,以及该特征在所有特征序列中不同的边界贡献,最后该特征所有边际贡献的均值即为SHAP值。SHAP具有模型解释性较好、缺失无影响等多个优点,并且可以反映出每个特征对预测结果的正负影响力。
假设模型基准分(所有样本的目标变量的均值)为ybase,第i个样本为xi,第i个样本的第j个特征为xij,特征的边际共现为msij,边的权重为wk,模型对样本i的预测值为yi,则第i个样本的第j个特征的SHAP值f(xij)如公式(1)所示,同时SHAP值要服从公式(2)。
(1)
(2)
4 实验结果与分析
4.1 数据集
推特是最重要的在线社交媒体平台之一,因此本文的研究数据是从Twitter收集的与Covid-19疫苗相关的公开数据[44],数据选择的时间区间为2021年2月1日至28日,经过数据抽取和清洗后得到237674条推文,我们利用NLTK工具包中的emoji包将表情符号翻译成文本字符串,用户提及和url链接分别转化为特殊标记来规范化推文,随后对整个数据集进行主题聚类和情感分析。随机选择4000条推文进行言语行为分类标注,标注结果如表3所示。在突发事件情境下,社交媒体平台上阐述类言语行为占据最大比例,其次是表达类,承诺类言语行为的比例最低。
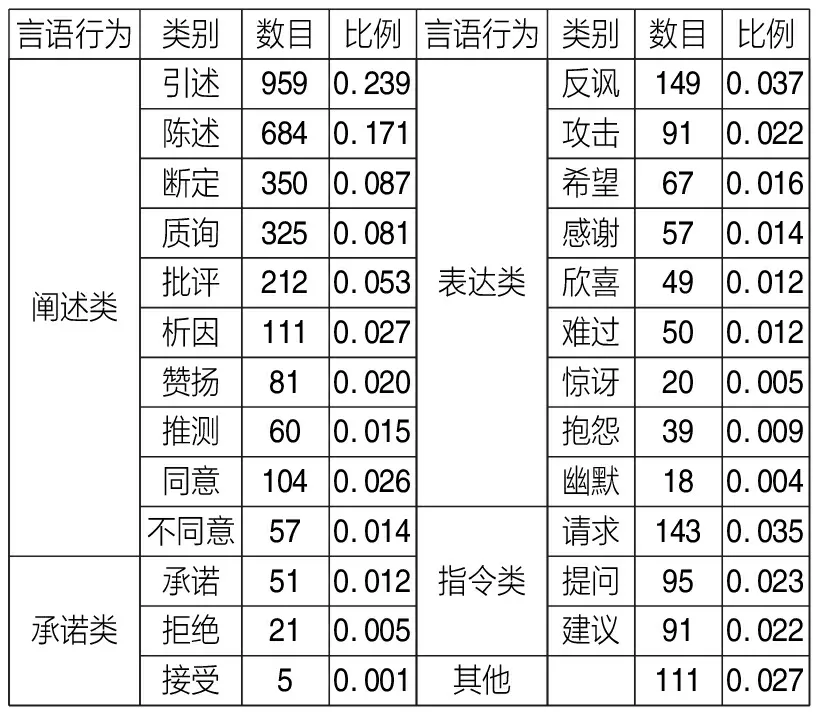
表3 推文的言语行为分布
4.2 主题的情感分布
基于连贯性得分的主题聚类的评估结果如图2所示,横轴代表设定不同的主题数,纵轴代表连贯性得分随着主题数的变化。结果显示,当主题的个数为23时,连贯性得分最高为0.4295。
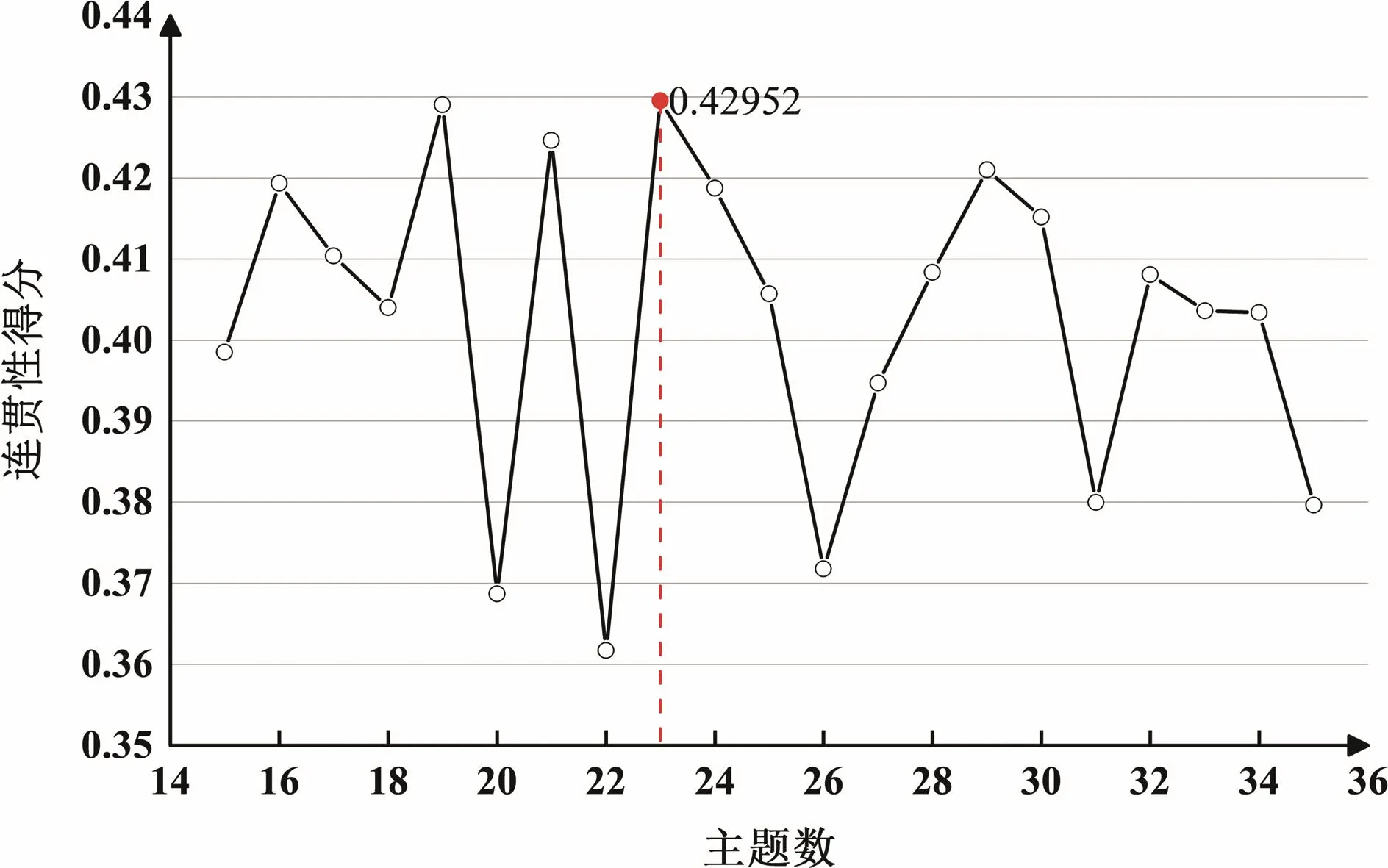
图2 主题聚类模型的效果评估
主题聚类得到的23个主题及其关键词的情感分布如图3所示,通过人工分析,将这23个主题划分为五大类:疫苗接种(主题1、2、3、4)、全球性疫苗问题(主题5、6、7、8、9、10、11)、疫苗知识(主题12、13、14、15)、公众对疫苗的态度和情绪(主题16、17、18、22、23)、疫苗接种服务和管理(主题19、20、21)。其中,反对疫苗运动(主题16)和需要接种疫苗(主题17)的讨论数最多。主题16、主题17、主题18(不想接种疫苗)、主题20(疫苗接种站点)、主题12(基因疗法)、主题2(给老师、工人接种疫苗)、主题5(各国疫苗推出)、主题8(疫苗分配)等在消极情感上的占比要远远高于在积极情感上的占比。一方面,社交媒体上充斥着大量反疫苗主义者,另一方面,因疫苗短缺大量用户表达出其强烈的接种愿望。主题1 (人们接种新冠疫苗)、主题23(开心)、主题22(感恩)的积极情感占比要高于消极情感占比。主题10(接种疫苗后的不良反应)、主题13(疫苗的有效性)、主题7(各类疫苗紧急使用授权)等的中立情感占最大比例。

图3 主题的情感分布
4.3 言语行为分类
本文选择已有研究中采用的支持向量机(SVM)[9]、逻辑回归(LR)[10]、卷积神经网络(CNN)[28]、BERT预训练结合神经网络模型[30],以及主流的文本分类模型TextCNN、FastText、Transformer作为基线模型。利用十折交叉验证和网格搜索方法进行分类器的参数优化。采用精确率、召回率、F1值的加权平均(weighted avg)和准确度(accuracy)来评估模型的分类效果。深度学习模型设置参数学习率为5e-5、随机失活率为0.1、批大小为128。采取Adam 优化器,通过设置早停法来避免模型过拟合的问题。实验环境为2* Intel(R) Xeon(R) E5-2640 v4 x86_64,2.4GHz,20核心,Nvidia Tesla V100,内存16G。模型的分类结果如表4所示,基于多特征融合的XGBoost模型在精确率、F1值和准确度上效果最佳。

表4 言语行为分类模型评估结果
4.4 用户言语行为分类的影响因素分析
根据特征重要性对言语行为分类的影响因素进行排序发现,文本特征、用户特征、时间特征的重要性依次降低。通过SHAP值可以对每一类言语行为的影响因素进行解释分析,其中,特征的重要性由SHAP绝对值的平均值来计算。如图4所示,除了文本向量特征(V),情感倾向为中性、是否包含链接、反讽、文本长度、人称代词、攻击性言语等特征的差异对分类模型的影响较为显著。

图4 社交媒体言语行为分类中前30个特征的重要性排序
图5中可以看出,在阐述类中,是否包含链接的特征重要性最高,包含链接的推文以及仇恨性、攻击性、反讽得分较低的推文更容易被归为阐述类。情感特征在表达类言语行为识别中具有重要作用,中性得分较低和反讽得分、攻击得分较高的推文更容易被归为表达类。当预测推文为表情符号emoji_7和emoji_5的得分较低时,推文不容易被归为表达类。中性和动词基本形式、问号的个数在指令类中的特征重要性较高,其中,推文的情感越中立,问号数量越多,越可能是指令类言语行为。文本向量特征、人称代词在承诺类中的重要性较高。
4.5 不同言语行为的差异性检验
本文选择效果最好的XGboost模型对待分类的推文数据集进行言语行为分类。对不同言语行为的转发数、点赞数等进行方差齐性检验,结果显示,数据不符合方差齐性,因此,本文采用Kruskal-Wallis检验对不同推文言语行为的转发数、点赞数、情感倾向进行分析。由表5可以看出,按照α=0.05的检验标准,Kruskal-Wallis检验结果显示,不同推文言语行为在转发数上没有显著差别,在点赞数和情感倾向上具有显著差异。通过查看原始数据样本发现,阐述类通常会产生较高转发,表达类则容易获得较高点赞。因此,当相关部门需要扩大信息的传播范围时,比如发布辟谣信息或者求助信息等,需要更注重于采用阐述类话语策略,当需要提高用户的认可度时,则可以采用表达类话语策略。

表5 Kruskal-Wallis H检验输出结果
5 结论
本文基于言语行为理论,构建社交媒体用户言语行为分类体系,提出了融合文本向量表示、主题特征、用户特征、时间特征的社交媒体言语行为分类方法,并在标注数据集上评估不同分类方法的性能。研究结果发现,基于XGBoost模型的分类效果最好,准确度达到0.792。文本向量特征在言语行为识别中的重要性最高,情感特征也能很好地识别不同的言语行为,但用户特征的重要性较低。不同的推文言语行为在转发数上没有显著差别,在点赞数和情感倾向上具有显著差异。
通过分析对言语行为预测有重要影响的特征,本文根据研究结果提出以下建议:①随机抽样的标注样本集在不同言语行为上的分布显示,突发事件情境下构成社交媒体疫苗辩论的言语行为的比例不同,政府部门应该有针对性地对大众不同类别的言语行为采用不同的应对策略,以满足其中用户所反映出来的信息需求和心理需求,比如指令类信息中通常会包含对疫苗短缺、疫苗有效性等问题的提问或者建议;②根据言语行为分类的影响因素分析结果,有关部门可以通过结合文本情感特征、词性标注特征等实现网络舆情的言语行为自动分类,比如包含链接的推文会更容易被归为阐述类,中性得分较低和反讽得分、攻击得分较高的推文更容易被归为表达类等;③不同言语行为的差异性检验表明,社交媒体文本中采用不同的言语策略所获得的用户认可(点赞)程度是不相同的,因此,突发事件情境下政务新媒体在发布信息时,可以从语言学视角出发,总结出符合当前舆情状态的应急言语策略,比如需要扩大辟谣或者求助等信息的传播范围时,可以采用阐述类话语策略陈述或描述真实情况,当需要提高用户的认可度时,则可以采用表达类话语策略。

(a)阐述类(b)表达类(c)指令类(d)承诺类图5 四类言语行为中特征的SHAP影响
本文存在以下不足:首先,承诺类等类别下的文本数量较少,而样本不均衡也会影响分类结果,未来需要在更多的数据集上验证模型的效果。其次,阐述类中请求、质询、批评等不属于表达类的文本也具有一定的情感倾向,未来应聚焦于突发事件社交媒体上的负面信息识别,如批评、抱怨、攻击等,从政府部门角度分析哪种言语行为更能引导舆论走向,从而减少突发事件中负面舆论的影响。
致谢:感谢图书情报国家级实验教学示范中心为本研究提供的实验支持!
