基于深度学习的闽浙赣GPM降水产品降尺度方法
2023-12-28李新同史岚陈多妍
李新同, 史岚, 陈多妍
(南京信息工程大学地理科学学院,南京 210044)
0 引言
在地球水循环的环节中,水循环通过降水连接陆地、大气和海洋的水分交换过程。降水对气候、水文、植被等方面有着重要的意义,降水量影响大气中的水循环过程、局地气候和全球粮食作物的收成[1-4]。研究降水的空间分布,有利于监测洪涝灾害,做到提前预警,同时也能提前应对干旱地区的缺水情况。虽然获得降水数据依靠地面气象站点监测,但是受到地形的限制和气象仪器设备缺少的影响,有些区域甚至没有完整连续的多年降水数据,因此很难获取某些地区的实测降水数据[5]。在海洋上,由于没有地面气象站点,所以对研究降水时空分布造成了很大的困扰,而卫星遥感则没有这些限制,它为获得全球降水数据提供了便利。
全球降水测量计划(Global Precipitation Measurement,GPM)卫星于2014年由美国国家航空航天局地球科学办公室和日本空间发展署发射,目的是为星载定量降水估计建立新的标准,提供下一代新的降水产品[6-7]。GPM产品与上一代的卫星降水产品热带降雨测量(Tropical Rainfall Measuring Mission,TRMM)比较,观测范围更大,由原来的50°N~50°S扩大成90°N~90°S,也更加适用于研究中国区域降水。
GPM的空间分辨率(0.1°×0.1°)虽然比TRMM高,但在地形复杂的地区,其精度仍然不高,需要用降尺度的方法提升GPM降水产品的精度。目前已有国内外学者基于降水主导因子对GPM降水卫星产品建立降尺度模型,如Lu等[8]以中国天山山脉为研究区域,基于地形因子和植被指数构建地理加权回归降尺度模型,与逐步回归降尺度模型进行对比; 史岚等[9]引入水汽数据,结合地形因子和植被因子,构建地理加权回归降尺度模型; 胡实等[10]研究将GPM降水产品与植被指数和高程结合,构建时滞地理加权回归模型; Brocca等[11]结合GPM早期降水产品、雨量计和欧洲中期降水中心天气预报再分析3种降水产品,提出3种不同的降水径流模型。虽然GPM降水产品基于降水主导因子的研究众多,但是运用深度学习方法研究降水降尺度的相关研究较少。
深度学习由Hinton等[12]在2006年提出,它由机器学习演变而来,可以一次性学习所有特征,具有更强大的学习能力。深度学习有多种算法,如前馈神经网络、卷积神经网络、循环神经网络(recurrent neural network,RNN)等。深度学习在其他领域获得了不小的成果,使得更多的学者将深度学习应用在降尺度方面。如Afshin等[13]选取了卡隆盆地的降水量、南方涛动指数、海平面气压和海表面温度等数据,将人工神经网络、模糊逻辑和小波函数结合,海平面气压和海表温度达到了最佳的结果。国内外学者不仅将深度学习方法应用在海温降尺度方面,而且更偏向于利用深度学习方法预报降尺度的研究。Bonnet等[14]运用视觉预测深度学习算法预测巴西圣保罗的降水量,指出视觉预测深度学习算法作为辅助临近预报具有很大的潜力; 王慧媛[15]基于雷达回波数据和气象站数据,运用多时间尺度支持向量机估测华东地区短时动态降水; 周康辉等[16]结合多源观测数据和高分辨率数值天气预报,运用深度学习算法,可视化强对流天气并解释预测过程,发现该算法得出的结果比单一数据的预报更加可靠; 郭瀚阳等[17]利用卷积循环网络模型预报高分辨率的强对流天气; 徐海龙等[18]基于长短时记忆网络(long short-term memory neural network,LSTM)算法,结合最小二乘法,提高了日长变化预报的精确性; 袁建刚等[19]根据递归神经网络算法建立全球电离层模型,成功模拟出电离层的物理变化; Xiang等[20]提出了新的基于参考和梯度引导的降尺度深度学习模型。深度学习的算法多应用于图像识别、无人机和预测等领域[21-24],在降水降尺度研究领域应用较少。
目前,降水降尺度研究大多基于年尺度、季尺度和月尺度,很少研究日尺度,同样也缺乏构建深度学习降尺度模型。本文选择闽浙赣作为研究区,基于2015—2019年日降水数据,对GPM卫星遥感降水产品运用深度学习方法构建降尺度模型,获得研究区高精度的降水数据,并对模型结果进行评估。
1 研究区概况及数据源
1.1 研究区概况
闽浙赣地区(如图1)位于中国的东南部,处于中国地形第三级阶梯,东濒东海,西临湖南和湖北,南近广东,北与江苏和安徽接壤。该区域经纬度范围为E113.5°~122°,N23.5°~31°。研究区包含福建、浙江和江西三省行政区域,有杭州市、南昌市、福州市等31个地级城市,三省总面积大约是39万km2。海拔由西向东升高,地势起伏较大,地形多为高山、山地、丘陵,同时也有平原。该研究区域的气候类型属于亚热带季风气候和亚热带季风性湿润气候,具有雨热同期的特点,夏季高温多雨,盛行东南季风,冬季低温少雨,盛行西北风。研究区域的年降水量可以达到1 000~2 000 mm左右。从春末到夏季都是多雨时节,容易发生滑坡、泥石流等地质灾害和洪涝灾害,同时也容易出现风雹、台风等气象灾害。因此,研究闽浙赣地区降水的时间和空间分布具有十分重大的意义,可以为监测、预测自然灾害提供技术支撑。
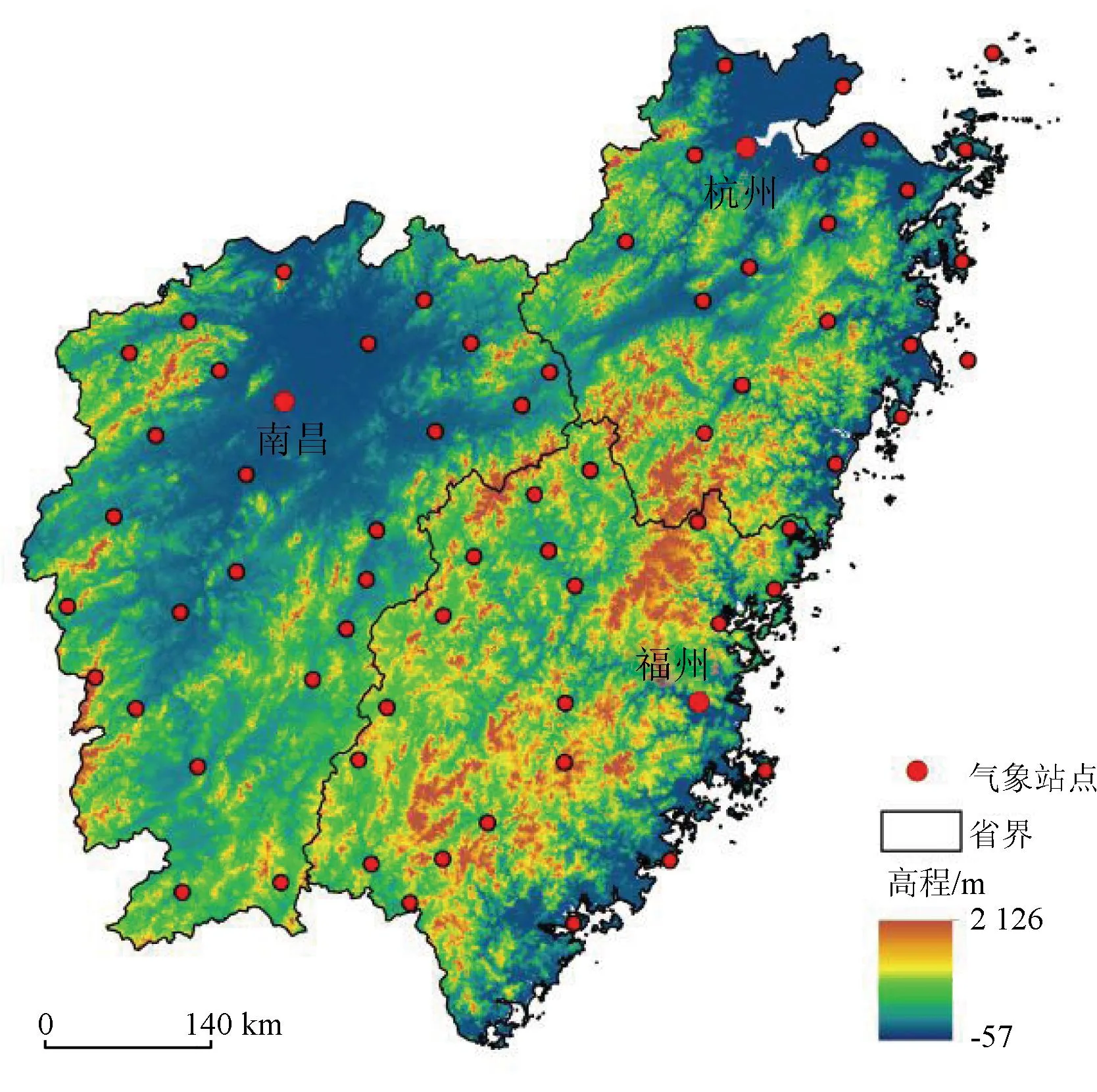
图1 闽浙赣地区的地形和气象站点分布图(该图基于自然资源部标准地图服务网站下载的审图号为GS(2016)2923号的标准地图制作,底图无修改。下文同。)
1.2 数据源及其预处理
1.2.1 GPM数据
本文采用的GPM数据来自美国国家航空航天局(http: //disc.gsfc.nasa.gov/datasets?keywords=i-merg&page=1)。该降水产品的数据范围是180°W~180°E,产品格式是nc4。研究时间为2015年1月—2020年12月,时间分辨率为1 d,空间分辨率为0.1°×0.1°。在ArcGIS软件平台上对GPM降水数据进行预处理操作。
1.2.2 气象数据
气象站点数据来自于中国气象科学共享服务网(http: //cdc.nmic.cn/)的中国地面日值数据集(V3.0),时间为2015年1月—2020年12月。数据文件有站点编号、高程、逐日降水量和站点的经纬度等信息。常规气象站点一共有78个,鄱阳湖流域加密站84个,经质量控制之后得到了153个站点,根据气象观测数据与GPM IMERG降水产品的观测时间不一致,将观测数据的北京时间订正为世界时(UTC)时间。其中将常规气象站点2015—2019年数据集作为训练集,2020年降水数据集作为个例年验证数据集,鄱阳湖流域84个加密站作为加密站验证数据集。
1.2.3 基础地理数据
数字高程模型 (digital elevation model, DEM)来自国家基础地理信息数据库(http: //www.g-scloud.cn),分辨率为1 km×1 km,比例为1∶100万,采取正轴等积割圆锥投影(Albers equal area project),在ArcGIS软件平台上投影,提取DEM的坡度、坡向等地形信息。
1.2.4 植被指数数据
归一化植被指数 (normalized difference vegetation index,NDVI)数据为MOD13A2中国区域NDVI合成产品,来自于美国国家航空航天局的官方网站(http: //ladsweb.modaps.eosdis.nasa.gov/),空间分辨率是1 km×1 km。NDVI产品从MODIS的TERRA卫星上获取,产品格式是HDF。数据前期处理包括: 校正、拼接、裁剪、投影转换、单位换算等。
2 研究方法
2.1 降尺度模型构建
2.1.1 模型构建
根据前人的研究[25-26],地理因子和植被指数均对Integrated Multi-satellite Retrievals for GPM(GPM IMERG)降水精度有影响。本文引入高程(H)、坡向(aspect)、坡度(slope)、经度(lon)、纬度(lat)和植被指数(NDVI)作为自变量的因子,模型运行成功后的GPM降水数据作为降水主导因子,建立降尺度模型,公式为:
GPM=f(Lon,Lat,Slope,Aspect,H,NDVI) 。
(1)
将降水主导因子输入深度学习降尺度模型中,构建空间分辨率1 km×1 km的GPM降尺度模型。
2.1.2 基于LSTM的降尺度模拟
RNN与普通神经网络相比没有太多的限制因素,应用于序列数据集更优,但是在训练过程中容易出现梯度消失或者梯度爆炸的问题,尤其是长序列的时候,问题更加明显。在此基础上,Hochreiter等[27]对RNN进行了算法提升,提出了LSTM,LSTM克服了RNN的不足之处[28]。如图2所示,LSTM由
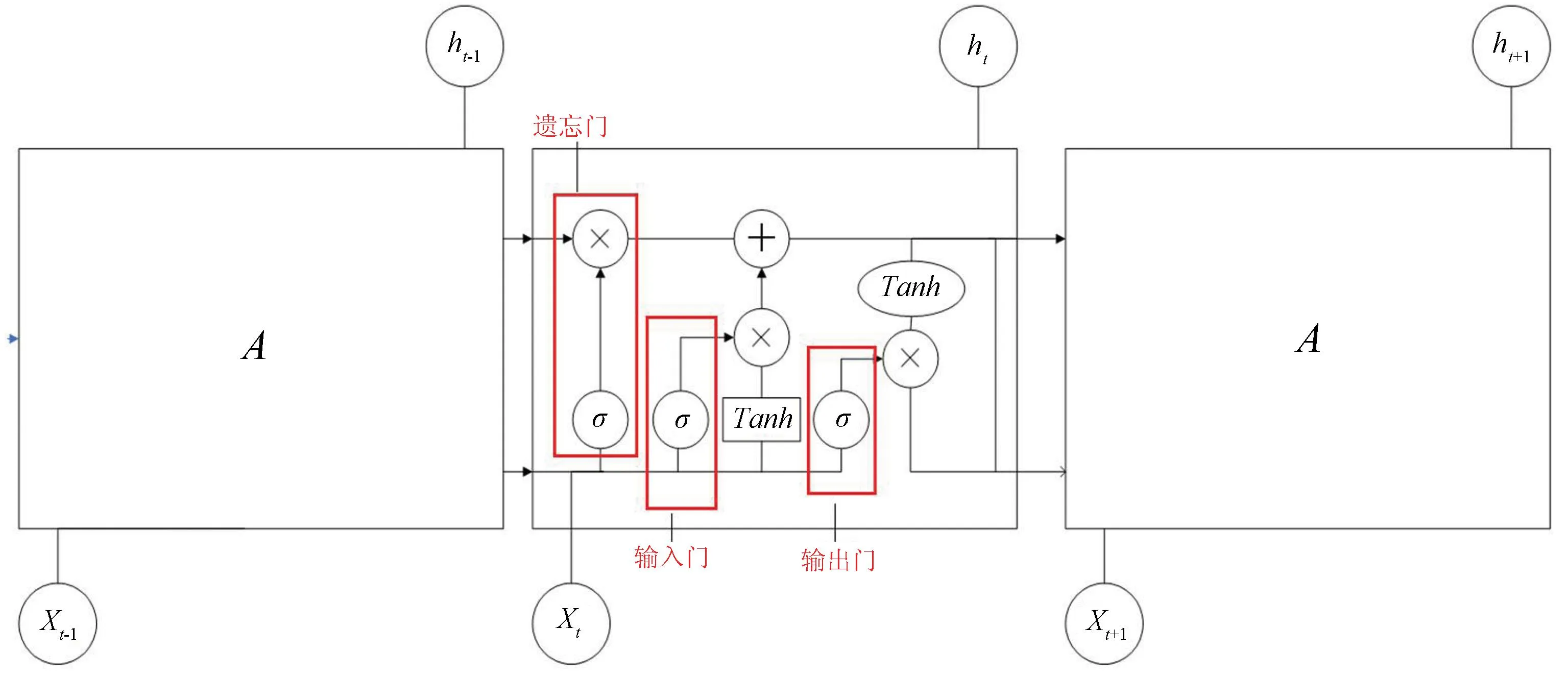
图2 LSTM结构图
单元状态(cell state)和门控(gates)构成,在每个序列索引位置t的门是由输入门、遗忘门和输出门构成,输入门控制信息流入,遗忘门控制状态更新,输出门控制信息输出。图2中,Xt和ht分别为t时刻的输入和输出,σ和Tanh分别为sigmoid和Tanh激活函数,⊗表示乘法,输出结果的值域为[0,1],表示允许输出多少数据,值越小,表示输出数据越少,反之,输出数据越多,⊕为加法,A为其他时刻的LSTM结构。
一般LSTM可解决长时间序列的问题,随之而来的局限性是当前时间t的目标值不仅与t-1时刻的变量有关,还和当前时间t的变量有关,事实上,当前时间t的变量并不存在,因为t时间的变量与输出结果共同存在。在此基础上,本文考虑将第一个数据集输入LSTM模型中,输出的结果和下一个数据集再次输入到LSTM模型中,对LSTM进行优化,得到优化后的LSTM(optimized LSTM, OLSTM)算法,具体如下: ①调整算法网络,初始化权重值、迭代次数等参数; ②将2015—2019年的数据集分为训练集和测试集,输入第一个训练集主导因子,输出的结果和下一个训练集主导因子输入模型中,得到OLSTM模型; ③将数据的测试集输入降尺度模型中进行测试并计算精度指标,以检验降尺度模型。
2.2 误差验证
本文从加密站和个例年2方面进行验证,以说明模型在空间和时间上的普适性。采用相关系数R、平均相对误差(mean relative error, MRE)以及均方根误差(root mean square error, RMSE)对估算降水量与实测降水量比较,分析两者之间的误差,评估降尺度模型结果精度。采用标准差σ、相关系数R和RMSE,3个指标组成一个极坐标图,评估降尺度模型在极坐标图中的监测精度。各指标计算公式分别为:
,
(2)
,
(3)
,
(4)
,
(5)
,
(6)

3 分析与讨论
3.1 模型调整参数
不断调整隐含层L、神经元N和迭代次数epochs,得到降水数据的训练集和测试集的决定系数R2、RMSE和MRE,根据降水数据集的长度,神经元数量N为300,隐含层L和迭代次数的调整结果如表1所示。从表1可知,当L=5,N=300,epochs=250时,训练集的决定系数R2为0.89,RMSE为0.39 mm,此时决定系数最高,RMSE最低,拟合出的降水精度理论上是最优的,但是此时的测试集R2和MRE不是最优解,过分追求评估指数最优,导致结果过于拟合,模型将会表现出极差的泛化能力,甚至得到的降水精度不如预期的理想,这是因为迭代次数过多,拟合了训练集数据的噪声和训练样例中没有代表性的特征。为了解决过拟合的问题,本文逐渐减少隐含层的层数和迭代次数,直到隐含层为4,迭代次数为150时,损失值(loss)慢慢收敛稳定,故选取模型的参数为:L=4,N=300,epochs=150,将参数和降水数据集输入模型中,得到2015—2019年降水数据集。

表1 模型调整参数表
3.2 降尺度的结果分析与验证
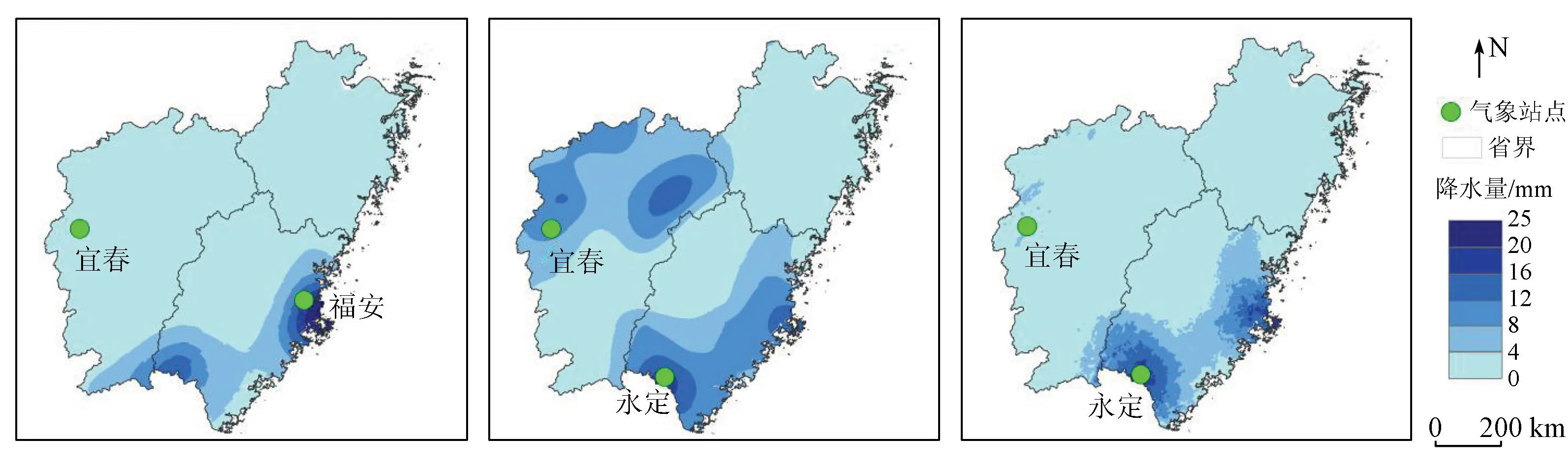
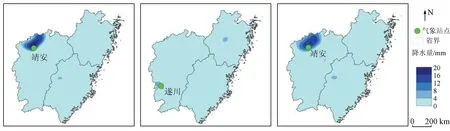
图3—6分别为2019年四季中某一天的气象站降水、遥感卫星GPM IMERG和降尺度结果的对比图,可以看出降尺度结果降水的分布图比气象站降水分布图和遥感卫星GPM IMERG降水分布图具有更高的空间分辨率,还精细地刻画了研究区降水的空间分布差异。从整体上来看,GPM IMERG降水产品对研究区进行了严重的低估,降尺度结果则与气象站降水量比较接近,但是在7月12日,GPM降水产品对研究区局地进行了高估,比如江西宜春。降尺度结果的空间分布情况与气象站降水数据的空间格局也更为一致,但是空间差异性较气象站降水数据更为精细,在降水的最值区域三者有差异: 在1月17日(图3),气象站降水最大值在浙江玉环,降水量是42.1 mm,GPM和降尺度结果的最大降水量分别在浙江上虞和平湖,数值较低,分别是11.2 mm和25.1 mm; 在4月7日(图4),浙江云和的气象站降水量最大,为52.8 mm,GPM和降尺度结果的最大降水量都位于福建福鼎; 在7月12日(图5),福建福安的气象站最大降水量达到了75.7 mm,GPM和降尺度结果的最大降水量都在福建永定; 在10月16日(图6),江西靖安的气象站降水量最大,为14.5 mm,GPM降水量在江西遂川最大,达6 mm,降尺度结果的最大降水量位于江西靖安,为13.5 mm,与气象站最大降水量所在位置和数值都更为一致。总体而言气象站降水的最值区域与GPM的最值降水区域有区别,与降尺度结果的最值区域更为接近。
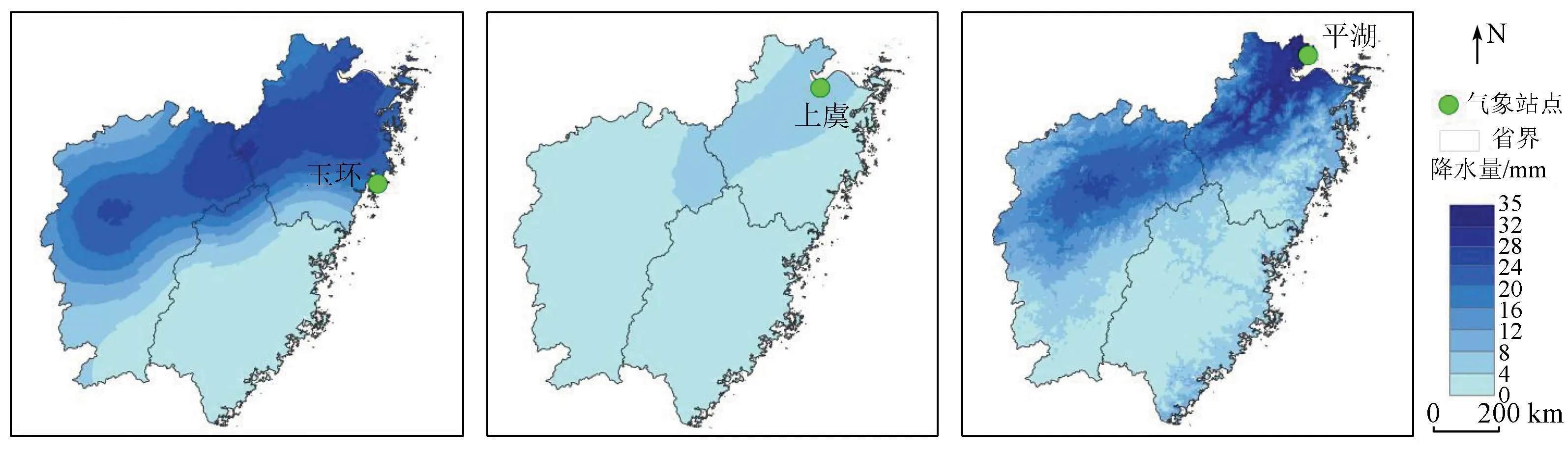
(a) 气象站降水 (b) GPM降水 (c) 降尺度结果
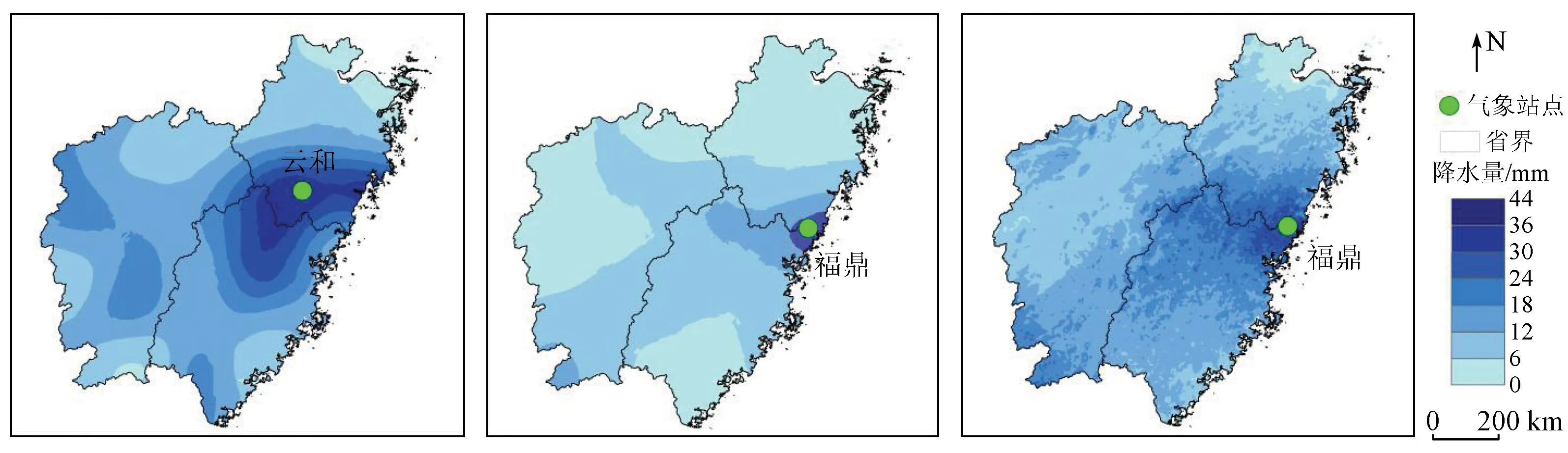
(a) 气象站降水 (b) GPM降水 (c) 降尺度结果
(a) 气象站降水 (b) GPM降水 (c) 降尺度结果
(a) 气象站降水 (b) GPM降水 (c) 降尺度结果
从降水时间分布来看,1月17日,图3(a)和图3(c)可知,闽浙赣地区降水分布由西北向东南方向递减,降水集中在浙江北部,浙江东北沿海地区降水量最多,达到了大雨级别,而降尺度结果的级别仍是中雨,在福建地区降水最少; 4月7日,从图4(a)和图4(c)可以看出,气象站降水集中在浙江和福建交界处、江西中部和西部,降尺度结果在浙江和福建交界处降水量较多,在其他地方是少量降水; 7月12日,由图5(a)可以见到,研究区大部分地区是少雨,除了福建地区沿海和南部地区仍有降水,降尺度结果的空间分布格局与气象站一致; 10月16日,图6(a)和图6(c)可知,气象站降水集中在江西西北部,其他地方仍有少量降水,而降尺度结果也集中在江西西北部。运用深度学习算法订正降水数据的方法提高了原始GPM IMERG数据的精度,该方法在一定程度上是可靠的。本文降尺度结果虽然能够较好地反映出闽浙赣降水的时间和空间分布情况,但是在一些细节上仍有偏差。主要在4月7日这一天,降水集中在浙江南部和福建北部,处于暴雨强度,而降尺度结果并没有达到暴雨强度,即降尺度结果在4月7日订正效果并不好,未来将引入水汽含量、风向等其他降水因子,提升深度学习降尺度模型的效果。
3.3 模型验证
3.3.1 典型区域加密站验证
利用鄱阳湖流域84个加密气象站点2015—2019年平均月降水量对OLSTM降尺度模型进行验证。为更好地验证OLSTM深度学习的降尺度效果,本文将降尺度结果绘制成平均月降水的泰勒图。从图7可知,平均月降水量的相关系数R都超过了0.7,其中,10月的降尺度结果最优,比其他月份表现更佳,R达到了0.91,RMSE为1.19 mm,标准差是2.46,最接近标准差之比2.5; 7月和4月次之,7月的R是0.9,RMSE是3.01 mm,标准差是5.23,4月的相关系数是0.8,RMSE是1.66 mm,标准差是1.66。但是1月误差偏差较大,R是0.7,RMSE是1.9 mm,标准差是0.78。这是因为1月降水量少,降尺度模型存在高估的现象。
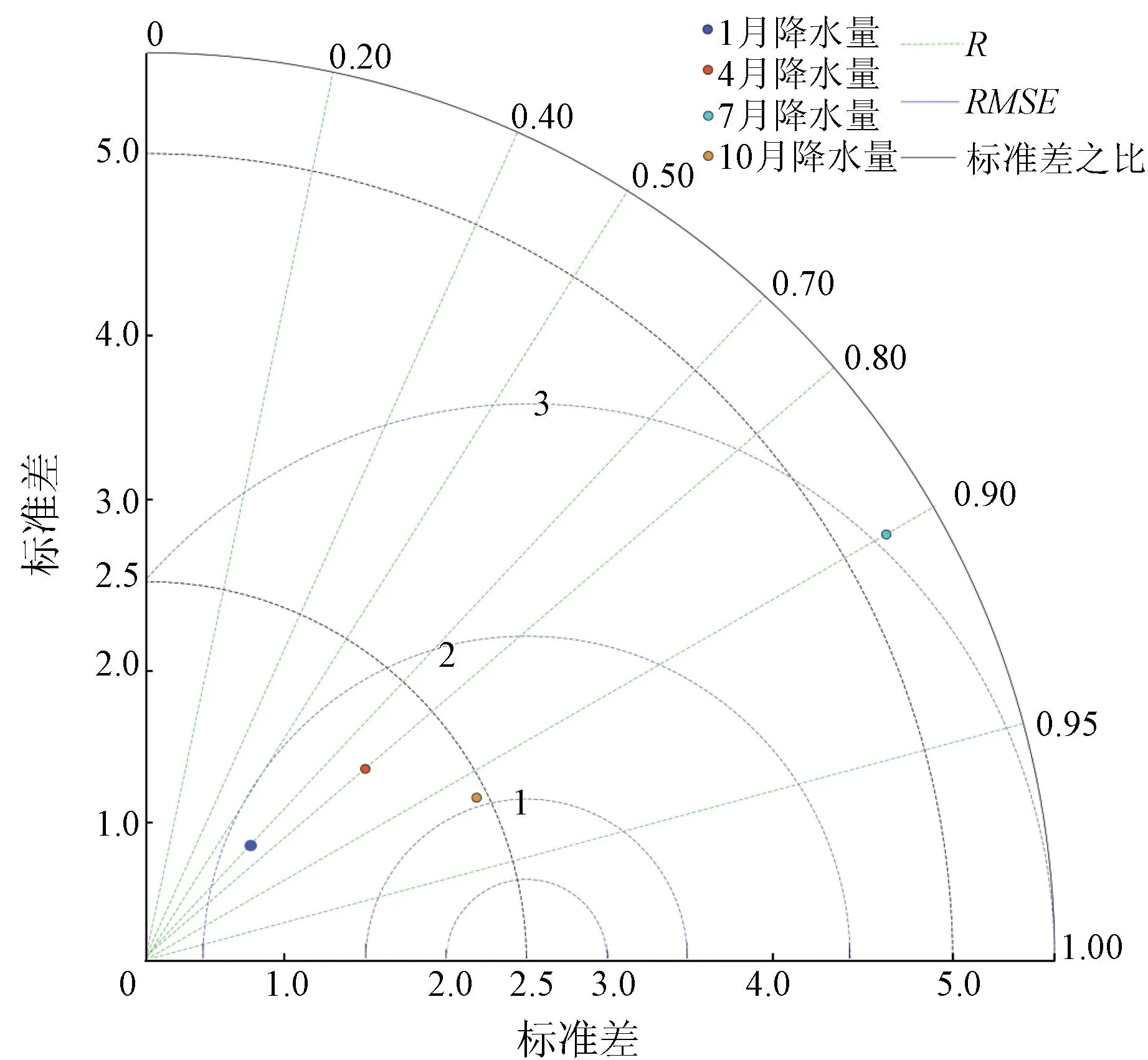
图7 平均月降水的泰勒图
3.3.2 个例年验证
为了验证深度学习降尺度模型在时间尺度的模拟水平,本文选取未参与模型训练的2020年降水数据,对研究区的空间降水进行降尺度,将降尺度后的降水数据与气象站点数据分别从日尺度和月尺度2个时间尺度进行精度评估,计算降尺度前后的精度指标R,RMSE和MRE以评估模型的实用性。
1) 日尺度降水精度评估。为对比分析日尺度下GPM降水数据与降尺度结果的降水数据的精度,图8是气象站点降水数据分别与GPM降水数据、降尺度结果据的对比图。从图8可知,降尺度结果在R指标上相比较GPM有提升,提升了0.115,MRE和RMSE均有降低,MRE从26.71%降至9.43%,RMSE从10.26 mm降到了5.23 mm,通过深度学习降尺度模型,降尺度后的降水数据误差更小,相关系数更大,说明降尺度结果的精度比GPM IMERG更高。

(a) 站点降水量与GPM降水量散点图 (b) 站点降水量与降尺度结果散点图
2) 月尺度降水精度评估。为对比分析月尺度下GPM降水数据与降尺度结果的精度,表2是2020年各月的2种降水数据的误差对比。从表2可以看出,降尺度结果的质量比降尺度前更优一点,每月的相关系数R都提升了,R的平均值达到了0.882,10月的R甚至达到了0.893,但4月的R比较低,只有0.879,2个月相差了0.14,体现出降尺度结果与实测值有较好的一致性; 4个月的MRE在5.71%~7.87%之间,大大降低了GPM降水数据与实测数据的误差; 每月的RMSE在0.324~4.123之间,降低了0.359~3.269,提升了GPM 降水产品的精度。其中,降尺度结果最好的是7月和10月,1月和4月降尺度结果稍微较差,这与以前学者研究的结果一致[29]。GPM由于自身的算法的限制,对微量降水和固态降水敏感,有可能出现少雨强高估的现象[30],也有台风登陆,带来强降水,造成误差的原因。总的来说,利用深度学习降尺度模型对GPM降水产品进行降尺度具有一定的效果。

表2 GPM降水数据与降尺度结果精度指标
4 结论
本文根据深度学习模型的特点,构建OLSTM深度学习降尺度模型,基于2015—2019年的逐日降水数据和植被数据以及高程数据,对GPM降水产品订正,得到研究区的降水空间分布。通过降水实测值和降尺度结果的误差验证,得出如下结论:
1)从降水空间分布来看,降尺度结果与气象站降水数据的空间分布趋于一致,比GPM IMERG降水产品更能体现出闽浙赣地区的降水空间分布,气象站降水的最值区域与降尺度结果的最值区域相同; 从降水的时间分布来看,降尺度结果在1月17日,7月12日和10月16日与气象站降水具有一致性,1月17日降水都集中在浙江北部,7月12日降水全集中在福建地区沿海和南部地区,10月16日降水中心皆集中在江西西北部。
2)加密站验证表明,OLSTM降尺度模型在7月和10月的降水量表现较好,1月和4月相对较差,即在每月的降水量的相关系数大于0.7,说明该模型较为可靠。
3)个例年验证表明,OLSTM降尺度模型的空间降水估算方法效果良好,能够在一定程度上提升GPM产品的降水精度和空间分辨率,2020年降水数据经过降尺度后R在0.8以上,说明模型适用于闽浙赣区域。但是2020年降尺度结果有季节性区别,7月和10月拟合效果较好,1月和4月次之。主要原因是4月台风登陆南边沿海城市,带来的强降水使得GPM产品的捕捉降水能力减弱。
综上,本文提出的优化深度学习降尺度模型无论在日尺度还是月尺度都有较高的精度,且在时间和空间具有一定的普适性,后续将引入水汽含量、风向等其他降水因子,以期进一步提升深度学习降尺度模型的效果。
