基于国产GF-3雷达影像的农田洪涝遥感监测方法
2023-12-28阳驰轶官海翔吴玮刘美玉李颖苏伟
阳驰轶, 官海翔, 吴玮, 刘美玉, 李颖, 苏伟
( 1. 中国农业大学土地科学与技术学院,北京 100083; 2. 农业农村部农业灾害遥感重点实验室,北京 100083; 3. 应急管理部国家减灾中心,北京 100124; 4. 中国气象局河南省农业气象保障与应用技术重点开放实验室,郑州 450003; 5. 河南省气象科学研究所,郑州 450003)
0 引言
洪涝灾害是最常见和最具毁灭性的自然灾害之一,往往造成严重的经济损失,威胁人类生命安全,近年来,洪涝更加频繁地威胁着世界上许多地区[1]。在全球气候变化背景下,极端气候引发的自然灾害对我国农业生产影响巨大[2]。洪涝灾害对农作物产量影响较大,会造成土壤肥力流失、农作物减产,甚至死亡等一系列问题。得益于遥感和计算机技术的快速发展,基于遥感影像的洪涝灾害监测方法能够克服传统实地调查的不足,已成为快速、大范围监测洪涝灾害的重要手段[3]。
由于水体在近红外波段的强烈吸收,以及植被的强烈反射,光学遥感数据被广泛用于洪涝监测。王国杰等[4]基于高分一号卫星数据,采用ResNet,VGG,DenseNet,HRNet这4种卷积神经网络方法提取地表水体信息,结果表明DenseNet在遥感水体识别领域有很好的应用前景。刘宇晨等[5]利用哨兵二号(Sentinel-2)年内长时序影像,提出了一个结合像元时间特征的大尺度、长时序的多指数组合的水体提取方法,完成了长江流域的地表水体遥感提取。Shao等[6]基于风云四号卫星数据多时相合成影像,结合归一化植被指数法和近红外波段信息,对南亚东北部流域的洪涝灾害进行监测。然而传统的光学影像易受云雾、降水等天气因素的强烈干扰,合成孔径雷达(synthetic aperture radar,SAR)技术具有较强的穿透能力,不受云雨的干扰。开阔水域的主要散射机制是镜面散射,水的介电常数相对恒定,由此产生的能量很少能够传回传感器,因此开阔水域的后向散射系数通常很低,利用目视解译或阈值法即可将其与非淹没区区分开来[7]; 然而,当水淹没在农作物冠层以下时,由于双弹散射机制的影响,反射回卫星的信号强度会增强[8]。在平静的开阔水域中,共极化(HH/HV)是被使用最广泛的,因为它能提供最高的对比度[9]; 尽管交叉极化受作物茎叶的影响存在较强的去极化效应,但由于对体积散射敏感,因此对于监测部分被淹没的农作物具有较高潜力。与单极化相比,使用双极化来监测洪涝农田可以提高分类精度[10]。高分三号卫星(GF-3)是我国首颗有高分辨率、多成像模式、大成像幅宽的C频段、多极化SAR卫星,能够全天候、全天时监测全球海洋和陆地信息[11]。
目前基于SAR影像进行农田洪涝淹没区提取的方法主要有阈值分割法、机器学习法、深度学习法等。郭山川等[12]在时序哨兵一号(Sentinel-1)A数据和GEE(Google Earth Engine)平台支持下,结合阈值分割法,提出一种洪水动态监测方法以实现广域尺度的洪水事件自动检测和淹没过程动态监测。郁宗桥等[13]利用随机森林(random forest,RF)指标重要性评估功能,在提取的138个纹理特征中筛选出得分较高的纹理特征来提取水体。Nemni等[14]基于卷积神经网络方法,利用Sentinel-1 SAR影像数据,使用半自动技术和目视解译训练模型,实现进一步自动化和提高洪水监测速度。在这些方法中,阈值分割法利用了图像的灰度特征,计算简单、效率高,但受作物生长和洪水分布的空间异质性影响,监测结果往往会存在严重的“椒盐”现象,对于图像灰度差异较小的区域分割精度较低; 机器学习法具有较高的鲁棒性,能够捕捉到洪涝区域的时空差异和变化特征,但是需要依据先验知识预先选取分类样本,对样本需求量大[15],可能出现过度拟合、迭代次数过多等问题; 深度学习的基础是神经网络,能够应对具体场景建立模型,学习能力强,适用范围广,但深度学习建立模型时也需有大量数据支撑、建立过程复杂,对硬件的要求较高,在数据不平衡、算法偏差的情况下可能出现“歧视”现象。
GMM基于高斯混合分布的假设,能够对不同类别地物间的复杂混合进行概率估计,适用于具有高空间异质性的农田环境; 其次GMM的计算复杂度相对较低,可在区域尺度上实现作物动态快速监测。然而,目前还没有学者探讨GMM在作物洪涝监测中的适用性。针对阈值分割法可能出现的精度不高问题,传统的机器学习算法和深度学习法所需样本标记量大的问题,本文基于双极化GF-3雷达影像,构建了一种弱监督GMM的洪涝监测方法来提取研究区农田洪涝淹没范围。
本研究基于GMM的弱监督分类和RF、支持向量机(support vector machine,SVM)、K最近邻(k-nearest neighbor,KNN)分类、平行六面体分类(parallelepiped classification,PC)的监督分类共5种机器学习方法,在“7·20”河南暴雨事件的背景下,应用Sentinel-2影像目视解译选取样本集作为输入,利用国产GF-3 SAR的HH,HV这2种极化方式的影像对豫北地区进行农田洪涝提取,对比农田洪涝中2种极化方式的后向散射特征,分析评估不同方法的水体提取精度,为洪涝灾害的农田水体提取提供参考,结果表明,构建的GMM弱监督分类模型可以在少样本的情况下提高农田水体监测精度。
1 研究区概况及数据源
1.1 研究区概况
研究区位于河南省北部,见图1,地理坐标E113°
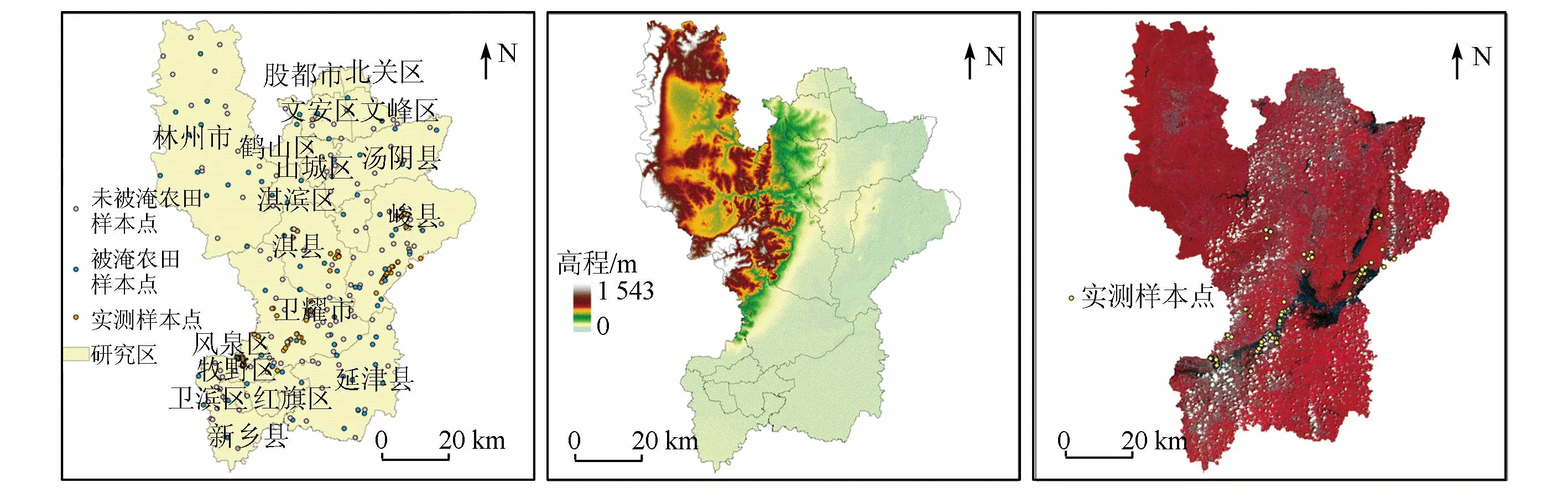
(a) 研究区区位 (b) 研究区高程 (c) Sentine1-2影像
38′~114°43′,N35°36′~36°22′,覆盖安阳市、鹤壁市、新乡市3个地级市,共包括18个市区县,邻近太行山,总体地势西高东低,总面积为7 610 km2,温带大陆性季风气候,雨热同期,全年10 ℃以上活动积温在4 000~5 000 ℃左右,年均降雨量580 mm,降水量在季节分配上极不均匀,与冬、夏季风的进退大致相同。研究区种植的主要农作物是玉米、小麦,东部种植了很多花生,玉米和花生在五月左右播种,九月底左右收获,小麦在十月中旬播种,次年五月底六月初收获。
台风“烟花”于2021年7月中旬开始影响中国的东部和中部地区,7月21日开始,强降雨北移,河南省北部洪涝灾害严重,其中受洪涝影响最严重的4个城市是郑州市、洛阳市、新乡市和鹤壁市[16]。
本研究使用了基于Sentinel-2假彩色合成影像进行人工目视解译后得到的样本点来训练和验证农田洪涝淹没范围和未淹没范围。根据2021年8月对研究区进行野外调查获得的实测样本点,在 Sentinel-2假彩色合成影像中,可以看出水体呈现黑色,植被呈现红色。水体呈现黑色是因为水体在电磁波谱的近红外波段有强烈吸收作用,植被呈现红色是因为其在近红外波段反射强烈[17]。根据此原理在Sentinel-2假彩色合成影像中选择研究所需样本点,其中被淹农田样本来自完全和不完全淹没的农田区域,最终获得被淹农田样本点和未被淹农田样本点各110个,采用随机抽样方法选择被淹农田样本点和未被淹农田样本点各40个作为验证样本,剩余为训练样本。
根据2021年7月15日—31日20时安阳市、新乡市、鹤壁市3个地级市和浚县、淇县2个县的气象站点监测的降水量,见图2。从图2可以看出,总体上5地17和18日出现小规模降雨,大暴雨、特大暴雨从19日持续到23日,后逐渐消退,21日降雨量达到顶峰,5个观测站中淇县21日降雨量最大,超过350 mm。

(a) 安阳市 (b) 新乡市 (c) 鹤壁市 (d) 浚县 (e) 淇县
1.2 数据源与预处理
1.2.1 数据源
本研究采用的研究数据包括国产GF-3 SAR数据、土地覆被类型数据、Sentinel-2数据、降水数据。GF-3 SAR数据下载自中国资源卫星应用中心(https: //data.cresda.cn/#/2dMap),成像时间为洪涝发生后(2021年7月27日),10 m分辨率,条带成像模式为精细条带(FSII),L1A级产品,极化方式为双极化的HH和HV。基于Sentinel-1和Sentinel-2数据的10 m分辨率的2021年土地覆被类型数据来源于欧空局(https: //developers.google.cn/earth-engine/datasets/catalog/ESA_WorldCover_v100)。Sentinel-2-Level-1C级产品数据获取于欧空局,成像时间为2021年7月27日。降水数据来自气象站点的监测数据,包括安阳市、鹤壁市、新乡市、浚县、淇县共5个观测站,采集时间为2021年7月15日—31日的20时。
1.2.2 数据预处理
在PIE-SAR软件中对GF-3影像进行预处理,依次进行复数据转换、多视处理、滤波操作、地理编码、DB转换的操作。PIE-SAR软件内已做辐射定标处理。幅度特征是SAR影像反映不同后向散射强弱的特征,幅度计算公式为:
,
(1)
式中:A为SAR影像中像点的幅度;r为SAR影像中像点复数中的实数;i为虚数。
在本研究中,GF-3 SAR影像在方位向和距离向视数为3×3时被重采样为10 m分辨率的规则网格。首先,基于3 m×3 m的滤波窗口,采用增强型Lee滤波(EnLee滤波)降低影像噪声; 然后,利用外部的数字高程模型(digital elevation model,DEM)数据对GF-3 SAR影像的L1级产品数据进行地形辐射校正,生成L2级地理编码产品; 再进行DB转换输出雷达后向散射系数,获得对应地物绝对的后向散射值; 最后,利用土地覆被类型数据作为掩模来剔除研究区内非农田的地物类型,以获得研究区范围内预处理完的SAR影像数据。
2 研究方法
本研究首先将HH,HV极化的GF-3影像数据进行预处理,获得HH和HV通道的后向散射系数; 然后,将训练样本连同HH和HV极化的后向散射作为输入,通过GMM的弱监督分类和RF,SVM,KNN,PC分类的监督分类共5种分类方法来提取研究区的农田洪涝淹没范围; 最后基于验证样本评价上述5种分类方法的精度。技术流程见图3。

图3 技术流程
2.1 高斯混合模型弱监督分类算法
GMM采用若干个高斯分布的线性叠加来表示,将一个事物分解为若干个基于高斯概率密度函数形成的模型[18]。GMM在遥感领域主要应用于遥感影像分割、遥感时序拟合等。样本数据X为一维数据的高斯模型称为单高斯模型,遵从以下概率密度函数:
(2)
式中:μ为数据的期望;σ为数据标准差。
GMM可以看作S个单高斯混合模型组合而成的模型,它的概率密度函数也可看成是S个服从均值为μi、方差为Σi的子成分的高斯分布的加权平均和,此时的样本数据X= [X1,X2,…,Xm]T是m维数据,x= [x1,x2,…,xm]T是X的一个实例,表达式如下:
,
(3)
式中:αi为各成分属于第i个子模型的概率,满足:
,
(4)
参数θ为每个子模型的期望、方差(或协方差)、在混合模型中发生的概率,公式为:
。
(5)
在本实验中需要分离被淹农田与未被淹农田,S设置为2,x是选取的训练样本,子模型被分为属于被淹农田和未被淹农田2类,所以GMM模型可以简化如下:
p(x|θ)=α1φ(x|θ1)+α2φ(x|θ2)
,
(6)
式中涉及到的参数α1,α2,μ1,μ2,Σ1,Σ2分别为训练样本属于子模型的概率、训练样本的均值和方差。本研究采用EM算法迭代GMM参数,每次迭代分为2步: E步,求期望E(Qji|X,θ),计算每一个数据j来自子模型i的概率,公式为:
,
(7)
式中:j= 1,2,…,140;i= 1,2。M步,求极大,计算新一轮迭代的模型参数αi,μi和Σi,公式为:
,
(8)
,
(9)
,
(10)
式中:i= 1,2,…,140,且在计算Σi时,μi应用此轮迭代更新后的值。重复计算E步和M步直至收敛,即满足||θi+1-θi|| <ε,ε为一很小的正数,可以任意小,此时认为取到比较合理的模型参数。
2.2 监督分类方法
1)RF。RF的基本原理是利用自助法(bootstrap)重采样技术,本研究中从原始训练样本集R= {R(1),R(2),…,R(140)}中有放回的重复随机抽取q个样本R1,R2,…,Rq,再对这q个样本分别建立决策树,这些决策树构成的集合组成RF,通过每棵决策树对样本的预测结果投票输出最终农田分类结果。
2)SVM。SVM最早是由Vapnik[19]提出的一种二分类模型,是一种基于统计学习理论的机器学习方法,是在高维特征空间上间隔最大的线性分类器,基本原理是求解能够正确划分训练数据集且集合间隔最大的分离超平面[20],得到最优的分类结果,适合少量样本时进行分类。
3)KNN分类。KNN最初是由Cover[21]提出的一种经典的简易惰性学习方法,是最近邻分类的扩展,在特征空间中的所有训练样本N中寻找待分类样本附近的K个最近的样本,再按照投票法等分类决策规则把农田分为被淹与未被淹的2类。
4)PC。PC是一种传统的监督分类方法[22],根据训练样本的亮度值不同划分成n维的平行六面体数据空间,规则由标准差阈值决定,待分类波段像元的光谱值属于任一训练样本的范围,则被划分到对应类别。
2.3 精度评价指标
为对比不同方法的精度,基于提取的农田洪涝淹没结果及验证样本建立混淆矩阵,计算4种精度评价指标,包括总体精度(overall accuracy,OA)、Kappa系数、生产者精度(producer accuracy,PA)、用户精度(user accuracy,UA),计算公式为:
,
(11)
,
(12)
,
(13)
,
(14)
式中:n为类别,此研究中n=2;N为类别个数的总和即总验证样本个数;xii为混淆矩阵对角线元素;xi+为类别的列总和;x+i为类别的行总和;x11为验证样本中被标记为被淹的农田且结果中被提取为被淹的农田的样本;x12为验证样本中被标记为被淹的农田且结果中被提取为未被淹的农田的样本;x21为验证样本中被标记为未被淹的农田且结果中被提取为被淹的农田的样本;x22为验证样本中被标记为未被淹的农田且结果中被提取为未被淹的农田的样本。
3 结果与分析
3.1 后向散射特征分析
分别统计被淹农田未被淹农田样本在HH和HV极化的后向散射特征,见图4。从图中可以看出,HV极化中被淹农田与未被淹农田的可分性高于HH极化,因为HH极化对二次散射敏感,在洪涝场景下,仅有水位较高,且植被保持垂直结构时才会构成此类散射机制。研究区农田农作物主要为玉米,由于此次洪涝较为严重,玉米大多被完全淹没,因此上述类别的被淹玉米在研究区内并不占据主导; 而HV对于体积散射较为敏感,虽然被淹没玉米区域以镜面反射为主,但未被淹玉米的体积散射贡献仍可作为区分其与被淹玉米的有效机制,这导致HV比HH具有更高的敏感性。
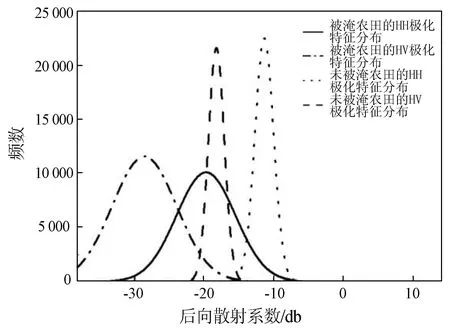
图4 被淹农田与未被淹农田在HH、HV极化的后向散射系数
3.2 提取农田洪涝淹没范围对比与精度验证
为对比机器学习方法的性能,选取4种场景,分别为建筑物稀疏区域的被淹农田、建筑物密集区域的被淹农田、以未被淹农田为主的农田区域、有河流存在的山区,见图5。对于完全被淹的农田,其表面被镜面反射主导,导致低后向散射系数,而建筑物密集区内建筑物与开阔水域之间的相互作用会产生二次散射,导致该地区SAR影像的后向散射系数上升。因此,影像中农田与建筑物边缘存在的亮斑,可能会干扰农田洪涝识别; 此外,山区地形起伏较大,会使SAR影像产生几何位移、顶底倒置和局部形变等失真现象,因此通常需要额外的辅助数据或处理步骤消除。
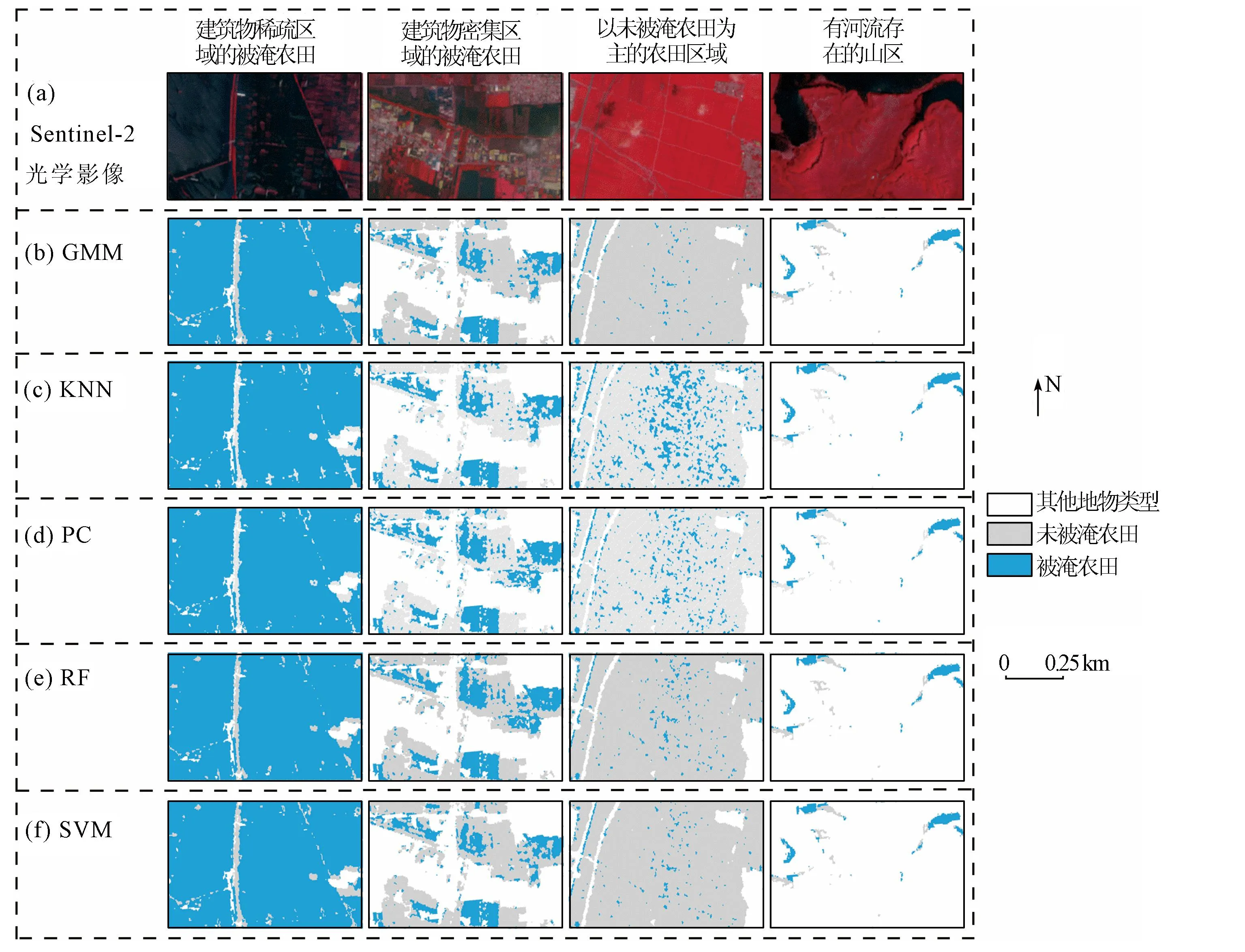
图5 Sentinel-2光学影像和分类结果的局部图
图6为5种机器学习方法结果精度验证,根据图6,GMM的OA为0.95,Kappa系数为0.90,OA和Kappa系数均最高。GMM(图5(b))方法所得结果的斑点噪声少于其他4种方法,被淹农田空间分布连贯。GF-3影像中存在着很多小面积的被淹农
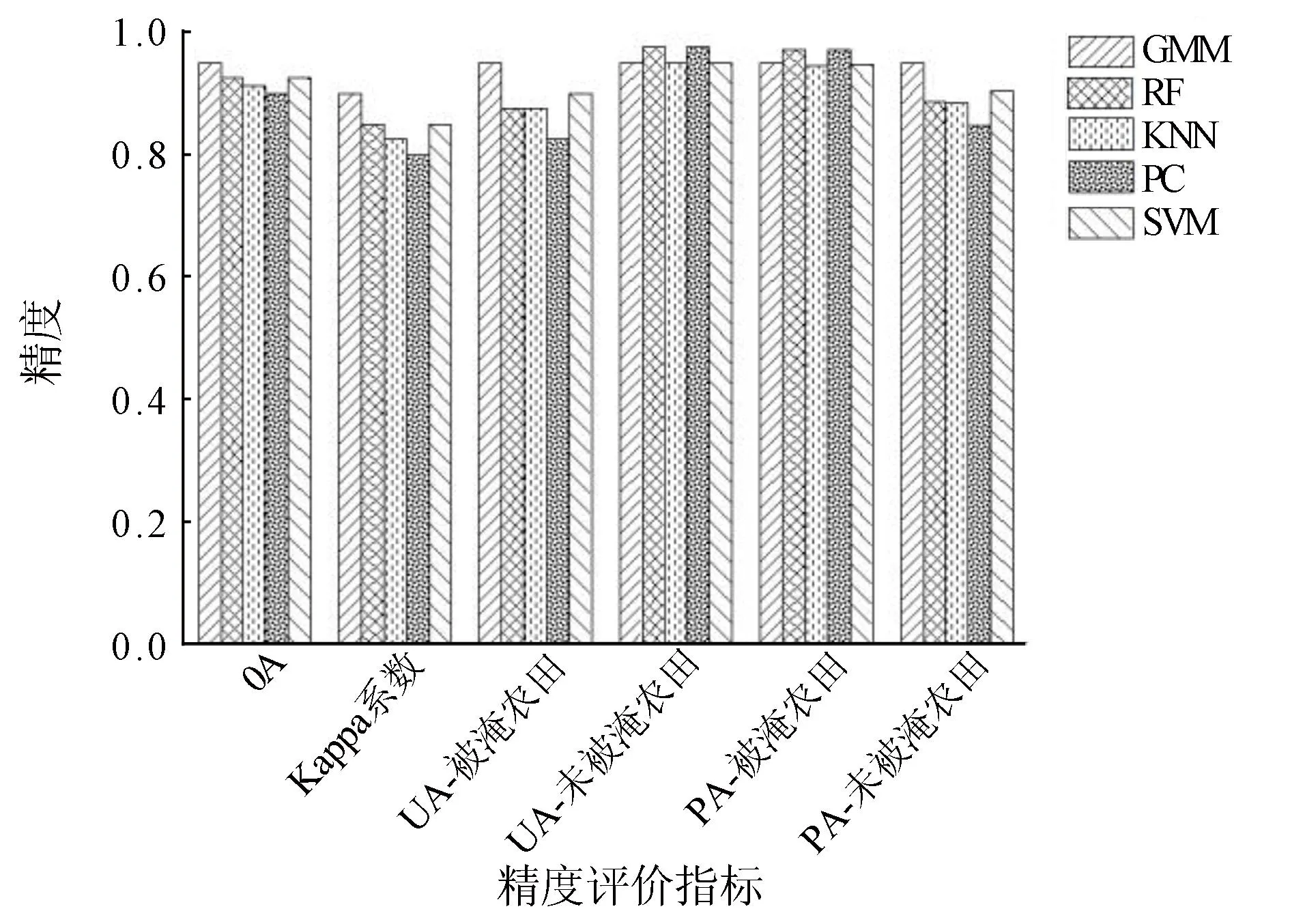
图6 5种机器学习方法结果精度验证
田像元与未被淹农田像元亮度值接近的情况,这部分地物在分类时容易被混淆,所以PC(图5(d))分类结果存在大量零星的斑点噪声。RF(图5(e))、SVM(图5(f)) 把部分未被淹农田、山体阴影误分为被淹农田,也有一些遗漏的被淹农田,这类农田为轻度淹没,淹没水位较低,绝大部分已下渗为地下水。在SVM分类中,不同训练样本被映射到不同的特征空间并用于构建分类超平面,然而,在某些情况下,SVM可能无法发现相应的决策边界,例如,部分未被淹农田、山体阴影的特征与被淹农田的反射特征区分度较小,这可能导致将其误分为被淹农田; KNN(图5(c))、PC错分、漏分现象多且明显,各类精度指标都较低(图6),这些错分、漏分现象多与KNN、PC算法本身原理简单有关。其中KNN存在大量、小面积的错分现象和许多漏分现象,在非洪涝区把许多农田误分为被淹农田,因为KNN算法对样本的依赖性高,往往需要大量训练样本以保证运行分类算法时结果收敛,注重考虑像元领域间的空间关系,对于小面积、破碎的洪涝区域敏感度低。
3.3 洪涝范围的空间分布分析
图7为Sentinel-2光学影像和5种机器学习方法的农田洪涝淹没全局图,总体来看,研究区西北部山地较多,被淹没相对较少,被淹农田主要集中在研究区的中部和北部,大部分在蓄滞洪区,此次河南省暴雨的国家蓄滞洪区共有9处,涉及安阳市、鹤壁市、新乡市的汤阴县、内黄县、安阳县、浚县、淇县、卫辉市等6个市区县。河流距离对洪涝发生有显著影响,距离河流越近,越容易发生洪涝,尤其是大江大河沿岸地区[23],研究区属于卫河流域,是此次暴雨事件重灾区,卫河流经研究区的新乡县、淇县、浚县、汤阴县,河流很多地方流水湍急,洪涝发生时淹没影响较大,中下游洼地多,部分被扩建为正式行洪、滞洪区,安阳地区和汤阴县有大型水库可一定程度上减缓洪涝影响。安阳市南部有郑庄山,北部有灵寿山,山地较多,相比鹤壁市和新乡市,高程值较大,因此洪涝淹没情况也较轻。
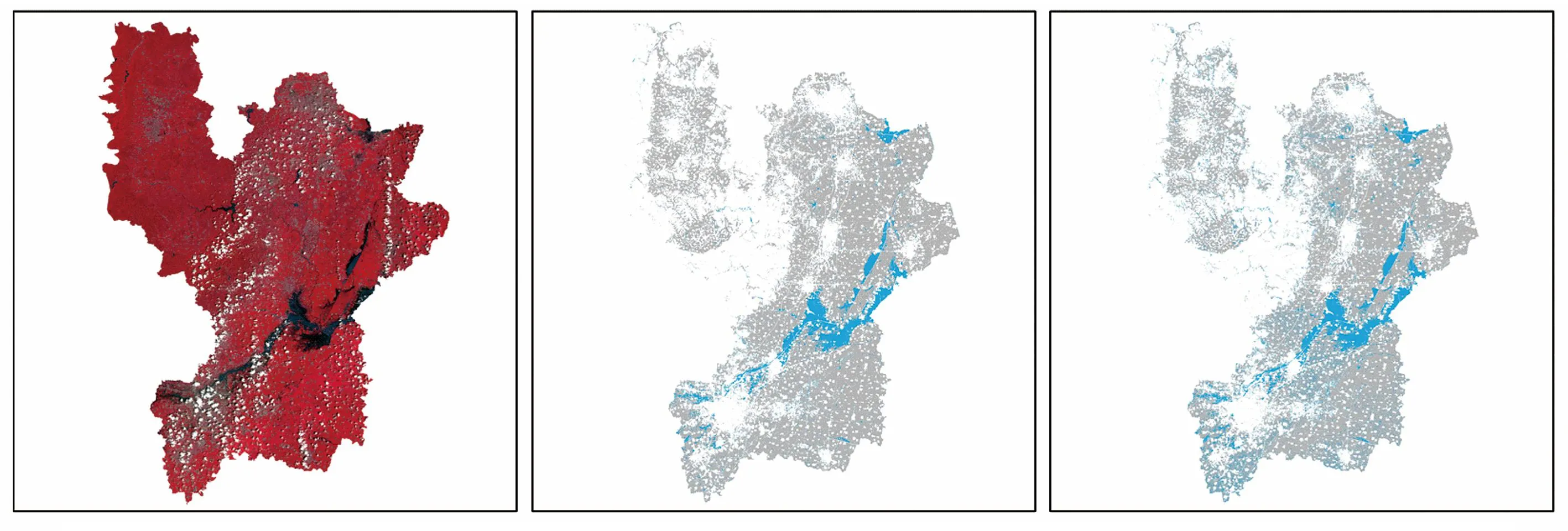
(a) Sentinel-2光学影像 (b) GMM(c) KNN
GMM估计的各市区县的被淹农田面积见表1,被淹农田总面积为398 km2,占研究区农田总面积的9.44%,农田淹没最严重的3个地区是牧野区、凤泉区和卫辉市,3个地区都地处新乡市内,其中卫辉市农田洪涝淹没面积最大,有100.13 km2,而安阳市总体淹没水平相比其他2市较低,GMM分类结果与实际农田受灾情况基本相符。
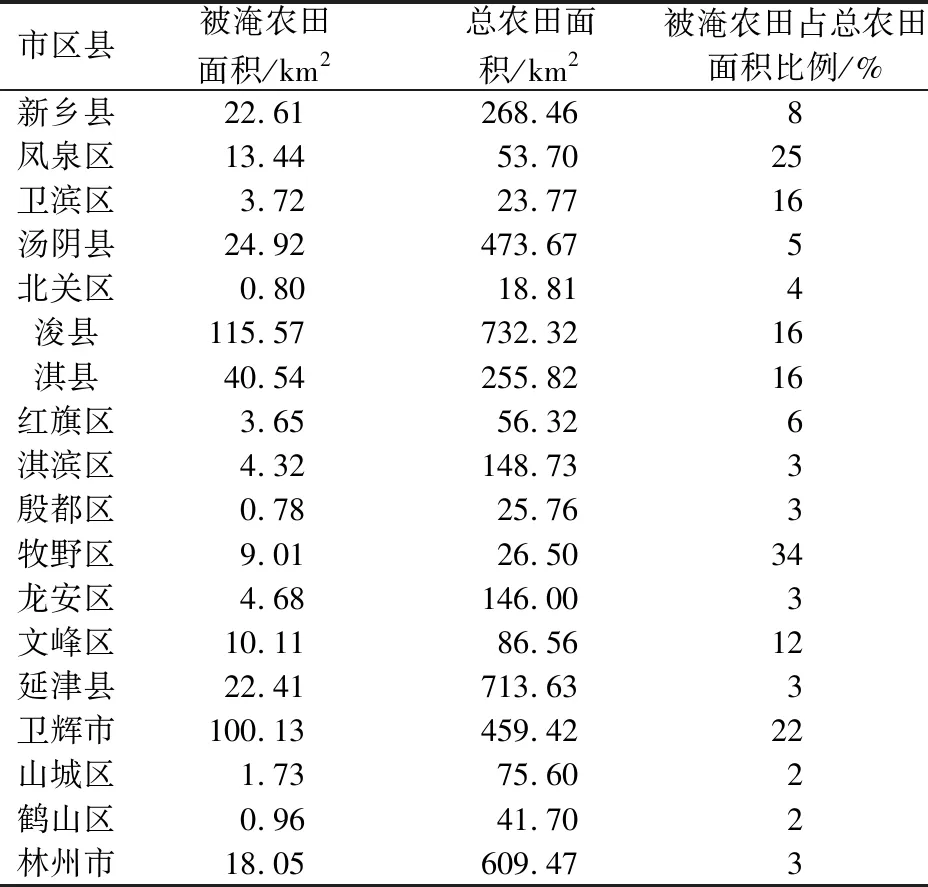
表1 各市区县农田洪涝淹没面积
4 讨论
4.1 不同场景下的被淹农田提取
对于不同场景,SAR影像提取洪涝作物的能力可能会受到不同因素的影响。在以农作物为主的耕作区,建筑物与开阔水域之间的二次散射和影像中的亮斑都会影响洪涝的提取; 此外,建筑物产生的阴影可能会被误认为是水体,从而导致洪涝范围的过度监测。
由于SAR传感器的侧式几何结构,地物可能会因为城市建筑和较高大的植被等自然特征的相对位置而被错分。而雷达阴影的产生是由于相邻建筑物的位置和SAR传感器的侧式几何结构,雷达波束无法照射到表面,导致这些区域在影像上看起来很暗,在干燥的情况下却被误分类为洪涝区,造成洪涝的过度监测。
与平原地区相比,山地和丘陵地区的地形更加复杂,地势凹凸不平。这使得洪涝覆盖的地表形态更加多样和复杂,雷达回波对不同斜率和高程的地形反射效果不同,导致SAR影像中洪涝区的后向散射信号强度的高度空间异质性[24]。
在实际应用中,需要结合多种数据和方法,如遥感影像、地理信息系统、气象数据等进行不同场景的数据处理和分析,消除干扰因素,提高农田洪涝识别的精度和可靠性。
4.2 5种机器学习法在农田洪涝提取上的优缺点
4.2.1 监督分类方法在农田洪涝提取上的优缺点
本研究利用GF-3 SAR影像HH和HV 2种极化方式的数据,建立弱监督GMM分类,与其他4种机器学习方法(RF,SVM,KNN,PC)对比,结果表明GMM分类结果的精度最高,对比其余4种机器学习方法在农田洪涝提取的优缺点如下:
1)RF能够有效缓解决策树模型的过拟合问题,能输出特征重要程度,减少冗余信息对分类结果的影响。但是它的训练速度比较慢,对于非线性结果计算量会增大,且容易受到SAR斑点噪声的影响。
2)SVM在处理小样本数据时具有较好的适应性和泛化性,处理高维度数据时表现较好,因而适用于处理多维遥感数据。由于SVM需要进行数据预处理和特征选择,并且随着范围的增大,计算量也增大,因而不适用于实时提取被淹农田。
3)KNN可以处理非线性特征,对于决策边界分布不规则的情况有较好的适应性,且不需要预先训练模型,可直接应用于实际的农田洪涝场景。然而KNN对于噪声和异常值较为敏感,需要对K值合理设定,增加了人工干预过程。
4)PC使用阈值分类,是一种基于阈值分割的方法,阈值选择影响分类结果的准确性,分类精度相对复杂模型较低,对于特征较少的数据分类不佳,在使用多光谱遥感数据进行被淹农田提取时,PC可能会受到植被遮挡和阴影的影响。
4.2.2 GMM在农田洪涝提取上的优缺点
GMM方法可以有效解决其他机器学习方法遇到的样本量小、样本分布不均、斑点噪声等问题,它在农田洪涝提取的优点如下:
1)GMM属于软分类模型的范畴,可以给出每个像素被分类为被淹农田的概率,因此可以估计混合像素中淹没作物的比例。
2)GMM处理偏态数据能力强,在实际中,被淹农田的分布并不均匀,所以可能出现数据偏态分布情况,GMM可以拟合各种分布可能,从而更好地适应这些数据。GMM使用不同的协方差矩阵来表示不同方向上的方差,可更好地适应各向异性的数据的形状差异。
3)GMM支持多模态特征识别,可以对SAR影像中的几何、纹理和强度等多模态特征进行检测和分类,提高分类精度。
但是在本研究中仍然发现了一些GMM的不足:
1)GMM对初始值很敏感,如果训练样本选取不当,可能使EM算法求出的解收敛到局部最优,而不是全局最优。
2)本研究采用的GMM模型需要预先确定混合高斯子分量个数,并且随着高斯成分个数的增加,算法拟合数据能力增强,模型变复杂,可能出现大量冗余参数。未来可以采用适当的评价准则来辅助判断选取的混合高斯子分量的数目。
5 结论
本文运用国产GF-3 SAR卫星数据,对比分析GMM,RF,SVM,KNN,PC共5种机器学习方法,对研究区农田洪涝灾害进行监测,得到结论如下:
1)在农田洪涝灾害场景中,基于镜面反射的主导机制,HV极化比HH极化敏感,更适用于提取被淹农田。
2)有高分辨率和敏感性能的国产GF-3 SAR卫星在暴雨天农田洪涝实时提取中体现较大优势,准确性和鲁棒性得到了保障。
3)在相同的少量训练样本前提下,对比其他机器学习方法(RF,SVM,KNN,PC),本研究使用的GMM弱监督分类来提取农田洪涝淹没范围时表现最优,OA为0.95,Kappa系数为0.90。
在未来的研究中,可以考虑以下方面的改进:
1)结合高分辨率的SAR影像数据和地理信息系统数据,提供更准确全面的农田洪涝灾害监测信息,进一步提高分类精度和稳定性。建立统一的数据采集和处理流程标准,提高数据质量和结果的可靠性。
2)改善模型参数的选择和调整方式,自动选取最优的模型参数,保证在简化人为干扰模型的前提下进一步提高被淹农田提取精度。
3)深入研究基于低洼田、山地田和平原田等不同场景的农田洪涝淹没提取,增强模型在具体实际中的适应性。
