基于改进PSENet 与CRNN 网络的智能电能表文本识别技术研究
2023-12-25魏伟苏津磷李帆仇娟于秀丽
魏伟,苏津磷,李帆,仇娟,于秀丽
(1. 国网湖北省电力有限公司计量中心,武汉 430080; 2. 北京邮电大学自动化学院,北京 100876)
0 引言
电力系统的不断发展与智能化带动了大量计量设备的铺设和升级,目前智能电能表、终端、互感器等计量装置的信息提取、档案管理、现场运维以及资料核对等工作主要基于人工输入操作,然而零散的信息采集方式、过多的人员投入和较长的信息采集时间不仅耗费了大量的人力、物力和财力,而且容易影响结果的准确性和客观性,非智能的人工信息采集方式已经严重阻碍了计量基础设施升级发展与采集安全,制约了电力资产管理的质量和水平。虽然已有部分工作研究以智能识别的方式来提取电能表图像中的有效信息,文献[1]提出采用移动端识别算法PCANet 进行电能表文字识别,适应其场景化做了相应的改进和特化,对光照变化,不匹配不对齐,遮挡等因素做了相应预处理改进;基于SIFT 算法提取的各文本区域特征,提出一种电能表特征匹配方法来识别电能表信息[2]; 基于图像预处理的研究,在图像的字符分割提取前,增加图片整体分割提取的步骤,以适应实际电能表文字排版多样化[3];针对电能表图像倾斜问题,提出了一种基于霍夫变换提取图像倾斜度的方法,来提高OCR 的准确率[4];针对电能表中的汉字定位与识别,提出基于K均值无监督预训练卷积神经网络的电能表文字定位[5];基于深度学习和注意力模型,提出一种端到端的文本识别模型,避免了对电能表图像的分割裁剪[6]。目前电能表文本识别技术适用于文本内容单一,排列规则的情况,难以解决高密度多聚集下,字符图标混杂的文本识别问题。文献[7]研究MASK LSTM-CNN 模型电力巡检图像识别方法,比Mask R-CNN、Faster R-CNN、R-FCN 等模型的识别率提高9% ~2%,有效解决了干扰信息较多的电力场景中的部件识别问题。
但是,由于智能电能表计量设备来源广泛,导致电能表类型多种多样。并且由于同类型智能电能表文本内容的元素多样导致在文本检测阶段,文本信息相互干扰,严重影响了电能表信息的提取。此外,图像采集环境多变,采集设备千差万别,使得图像质量参差不齐,严重影响了电能表文本识别精度。
文中通过设计一个两阶段的文本识别系统实现智能电能表信息的精准采集,将改进的PSENet 网络作为智能电能表信息提取的目标检测算法,精准地定位智能电能表图片中的所有文本信息,并列出所有文本候选框,再通过CRNN 文本识别算法对文本候选框进行识别。算法本身不受输入图像的质量和场景束缚,并且对智能电能表中文本检测与识别面临的字体大小不一、曝光过高或过低等问题具有较强的抗干扰能力,对电能表图片中的汉字、英文和数字都具有很高的识别精度。
1 智能电能表文本识别系统构成
文中设计了一种两阶段的系统对智能电能表图片文本进行检测和识别,其中文本检测模块将输入的电能表图片分割成一系列文本框,再经过文本识别模块获取文本框中的文本信息,最后将原始图片、文本框位置以及文本内容同时输出,系统框架如图1 所示。

图1 两阶段文本识别系统框架Fig.1 Framework of two-stage text recognition system
1.1 文本检测模块
针对智能电能表图片文本检测的特点,文中采用改进的渐进尺度扩展网络PSENet[8]作为文本检测模块,通过图像分割方法,像素级的检测目标区域提升了模型在高密度文本下的检测性能,比文本框的方式,检测更精准。其技术路线如图2 所示。首先对输入的电能表图片进行特征提取和融合处理,再将融合后的特征经过卷积获得n个分割结果,最后采用渐进尺度扩展算法得到电能表图片上文本检测的最终结果。
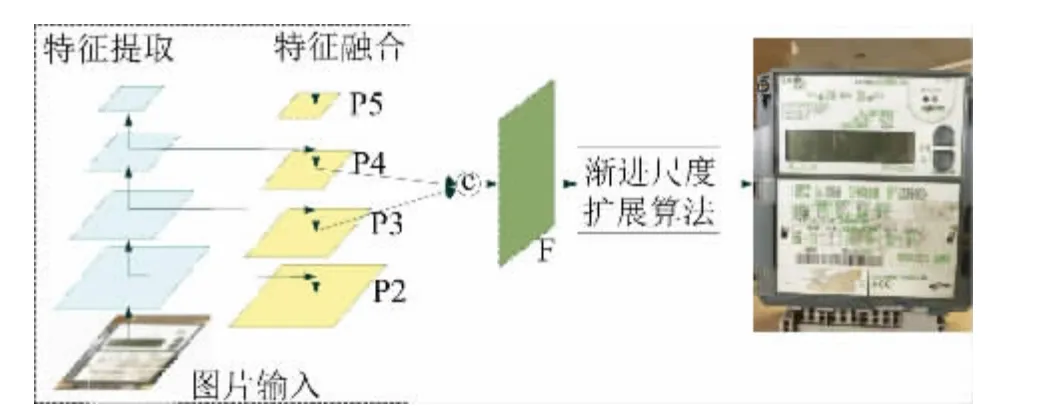
图2 电能表文本检测模块Fig.2 Text detection module of electricity meter
特征提取融合: 将输入图片通过残差网络Res-Net50[9]进行特征提取,在特征提取过程中构建特征金字塔( FPN)[10]并对不同深度的特征层进行融合。Res-Net 的核心思想是对每一层网络构造如图3 所示的残差块。
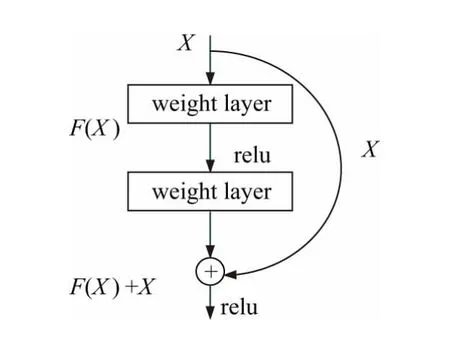
图3 ResNet 的残差机制Fig.3 Residual mechanism of ResNet
图3中每层的输出都叠加其上一层的浅层输出:
其意义在于当浅层网络具有较为优秀的特征时,训练参数会使深层输出F(X) 趋近于0,确保网络的加深不会导致精确度的降低。ResNet50 是具有50 个conv2d 层的ResNet 网络,其网络结构如表1 所示,分别提取Conv2,Conv3,Conv4,Conv5 最后输出的特征图构建特征金字塔。再通过自顶向下和横向连接的方式,依次将高层次特征图的上采样和低层次的特征图相结合,得到( P2,P3,P4,P5) 4 个256 通道的特征层,最后将( P2,P3,P4) 分别通过8,4,2 倍上采样并与P2 进行特征级联,得到1024 个通道的融合特征F。这种特征提取融合能够将高层特征的语义信息与底层特征的细粒度信息融合在一起,在有效地感知图像文本分布的同时,也保证了对文本边界更加精细的检测。将得到的融合特征F 经过Conv(3,3) -BNReLU 层使通道数量降低到256,再通过多个Conv( 1,1) -Up-Sigmoid 层输出n个分割结果S1,S2,…,Sn,每个分割结果具有不同的内核规模,S1,S2,…,Sn按照内核规模以从小到大顺序排列。通过渐进尺度扩展算法从最小内核S1开始依次进行尺度扩展,并采用先到先得的方式解决尺度扩展过程中产生的边界冲突问题,最终产生边界清晰的文本检测结果。

表1 ResNet50 网络结构Tab.1 Network structure of ResNet50
渐进尺度扩展算法: 选择内核规模最小的分割结果S1,得到图片中所有文本实例的最小内核( 即中心框) ,然后合并S2的分割结果,对文本实例的内核进行扩展,在扩展内核的过程中遇到像素点冲突问题时采用先到先得的方式( 即小规模内核优先) ,避免内核边界冲突,同理对剩余所有分割结果进行内核扩展,最后一次扩展的内核结果即为电能表图片文本检测的分割结果。
1.2 文本识别模块
通过上述的文本检测模块,可以从智能电能表图片中提取出一组精确分割的文本框,将所有文本框分别输入到基于CRNN[11-12]网络的文本识别模块中,并将识别结果和检测结果一一对应,即可生成原电能表图片的信息提取图,CRNN 的网络结构如图4 所示。

图4 CRNN 网络结构Fig.4 Network structure of CRNN
CRNN 网络实际上是由三部分组成的: 在自然语言处理技术中,文本通常被认为是一种序列,循环神经网络( RNN)[13]对序列的处理有着固有的天然优势,通过卷积神经网络( CNN)[14]将文本框图片变换为特征序列,以供后续的RNN 解码器进行解码识别,并将识别结果经过联接时间分类( CTC) 算法[15]进行转录,通过添加占位符的机制解决文本中重复字符信息丢失的问题。
特征提取部分( CNN) : CRNN 网络中的CNN 部分使用了VGG 结构,并提出了两处改进: 一是将第三和第四个maxpooling 层的核尺寸从2 ×2 调整为1 ×2,便于将CNN 网络的输出特征直接作为RNN 网络的输入;二是在第五和第六个卷积层之后加入BN 层以达到更快的训练收敛速度,调整后的CNN 网络结构如表2所示,首先将分割后的文本框图片按比例缩放成宽度为W的图片,然后通过CNN 卷积网络生成W/4 个512通道的特征序列。
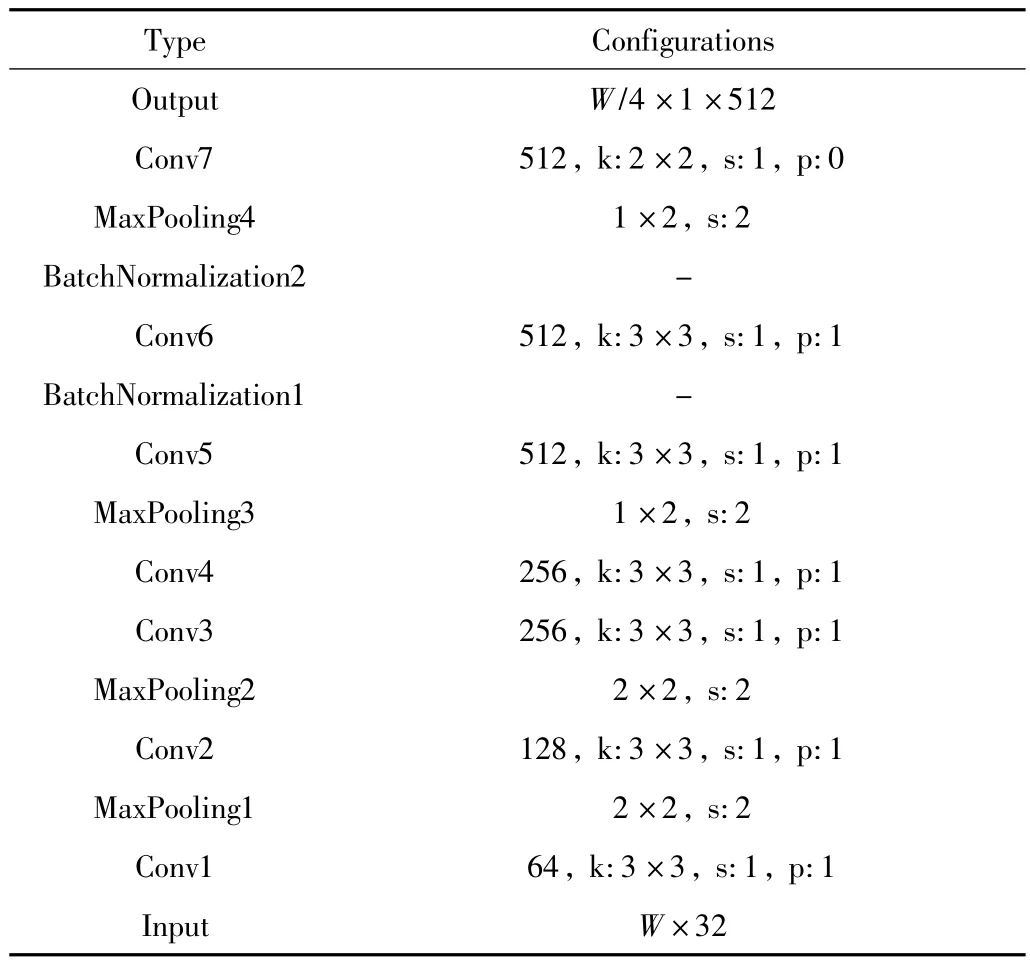
表2 调整后的CNN 网络结构Tab.2 Network structure of adjusted CNN
文本预测部分( RNN) :将CNN 网络提取出来的特征序列输入到RNN 网络中进行文本预测,为了提高捕捉上下文信息的能力以及宽字符和模糊字符识别的正确率,采用深层双向RNN 网络作为CRNN 中的RNN网络,其网络结构如图5 所示。

图5 深层双向RNN 网络结构Fig.5 Deep bidirectional RNN network structure
为了防止在RNN 网络训练过程中出现梯度消失的现象,选用长短时记忆单元LSTM[16]作为RNN 单元,LSTM 单元的内部结构有存储单元和输入、输出和遗忘门,存储单元只能存储过去的上下文,所以需要双向RNN 来对上下文进行双向存储,遗忘门可以清除单元的内存。
转录部分( CTC) :文本序列经过RNN 网络的预测结果需要经过转录层转换为字符标签,文中采用基于词典的CTC 算法进行字符转录,在这种基于词典的模式中预测结果是所有标签的概率,选择概率最大的标签作为识别结果。预测结果转录生成的文本存在大量堆叠现象,简单直接的去重处理容易对原本就是重叠的文本造成信息丢失。例如文本图片‘100006’经过RNN 网络预测的结果可能是‘1100000000666’,简单去重后输出‘106’作为最终结果,显然造成了原始信息丢失。为了解决这一问题,通过CTC 算法根据条件概率的原理将适当的位置设置为占位符‘ε’,上述预测结果可能变成‘110ε00ε0ε0εε6’,经过去重处理后再除去所有占位符即可得到最终预测结果‘100006’。
2 实验结果与分析
2.1 文本检测模块实验
n个分割实例的标签: 由于文中文本检测模块通过融合特征F 生成了n个分割结果,所以训练时需要提供n个分割实例以及对应的标签。通过Vatti clipping algorithm 对原始实例Gn进行缩减di个像素点得到新的分割实例Gi,Gi相对于Gn的缩小比例ri可以表示为:
式中k为缩小系数,n为分割实例个数。由此可以通过式(3) 计算Gi相对于Gn的具体缩小像素点数di:
式中Perimeter(Gn) 为Gn文本框的周长;Area(Gn)为Gn文本框的面积。损失函数: 文中文本检测模块的损失函数由Sn相对于原始实例Gn的损失LC和Si相对于缩小实例Gi的损失LS构成:
为了确定LC和LS,结合了dice coefficient 和在线难例挖掘( OHEM) 中的mask(M) :
数据集: 文本检测模块的训练集和测试集由ICDAR2015 ( IC15) 和ICDAR2017 RCTW 构成( 如图6 所示) ,其中IC15 中包括1000 张训练集和500 张测试集,内容为自然场景下拍摄的英文文本,主要来源有商场和指示牌; 从RCTW 中选择2000 张训练集和1000张测试集,内容为自然场景下拍摄的中文文本,主要来源有街道场景、手机截图、室内场景和证件照等。将数据集的标注格式统一调整为IC15 的标注格式:”x1,y1,x2,y2,x3,y3,x4,y4,lable”,分别注释了图片中所有文本框的四个顶点位置以及对应的文本内容。

图6 ICDAR 2015 和2017 RCTW 数据集Fig.6 ICDAR 2015 and 2017 RCTW dataset
2.2 文本识别模块实验
CTC 的标签:每一个预测值y1,y2,…,yT可以通过映射规则B 映射到一个标签序列I,其中标签序列I 只标记具体标签值而忽略每个标签的位置。
CTC 的损失函数:对于训练数据X={Wi,Ii},(Wi和Ii分别代表训练集的图片和标签序列) 损失函数定义为ground truth 的条件概率似然数的负对数:
其中p(Ii,yi) 为预测值yi对应标签为Ii的条件概率,计算公式为:
π 为y的所有可能性,即y1,y2,…,yT对应字符概率不为零的所有线性可能。
数据集:文本识别模块的数据集是通过Text Recognition Data Generator( TRDG) 方法人为生成的,一共生成5000 张英文图片和20000 张中文图片,每张图片上包含5 个单词或汉字,图片的名称即为图片的标签,生成的文本图片如图7 所示。

图7 TRDG 生成的文本数据集Fig.7 Text dataset generated by TRDG
2.3 实验结果及对比
文本检测模块: 迭代次数n_epoch 设置为600,初始学习速率设置为0.001,并且在训练过程中采用0.1的下降速率进行离散下降,分别在Batch Size 等于4,8,16 下进行训练,训练的效果以及在测试集上的测试结果如表3 和图8 所示。
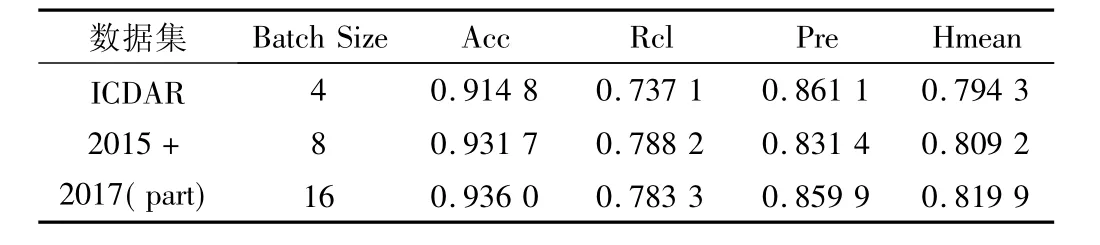
表3 batch size 等于4,8,16 时的模型指标Tab.3 Model index when batch size is equal to 4,8,16

图8 训练模型在测试集下的测试结果Fig.8 Test results of the training model under the test set
表3 中提供了训练参数batch size 分别等于4,8,16 时在训练集和测试集上的部分指标数据,ACC 是模型在训练集上表现的精确度,Rcl 和Pre 是模型在测试集上表现的查全率和准确率,Hmean 是两者的调和平均数,通过上述数据显示,batch size =16 时表现最好,在该模型下对智能电能表图片进行文本检测,检测结果如图9 所示。

图9 Batch Size 为16 下的电能表文本检测结果Fig.9 Text test results of electricity meter with 16 batch size
上述实验结果证明了文中的文本检测模块可以准确地检测出电能表图片中的绝大多数文本信息,并且对电能表图片中的近距离文本具有良好的分割效果。
文本识别模块: 将文本检测模块输出的文本框位置信息与电能表图片一同输入到训练好的文本识别模型中,将识别结果和输入融合处理后输出的结果如图10 所示。

图10 智能电能表文本识别结果Fig.10 Text recognition results of smart meter
通过对多组不同环境下拍摄的不同型号智能电能表图片进行文本检测和文本识别测试,证明了文中使用的文本检测模块和文本识别模块相结合可以克服光线,模糊等环境因素,较为准确且全面地检测识别出智能电能表所携带的电能表信息,部分实验结果如图11 所示。

图11 不同型号的智能电能表文本提取测试结果Fig.11 Text extraction test results of different types of smart meters
将文中设计的两阶段文本识别系统和Jinjin Zhang等人设计的attention ocr 文本识别系统( 开源项目) 进行对比实验,其文本检测算法由Tensorpack FasterRCNN 改进而来,文本识别算法引入了注意力机制,曾获得ICDAR2019 任意形状文本上稳健阅读挑战赛道的冠军,在电能表图片上识别的效果与文中设计的文本识别系统局部对比图见图12。

图12 文中设计的文本识别系统( 左) 与Attention OCR文本识别系统( 右) 在智能电能表图片上的识别部分结果对比Fig.12 Comparison between the results of the text recognition system designed in the article ( left) and the Attention OCR text recognition system ( right) on the smart meter picture
通过大量对比实验发现,文中设计的文本识别系统在电能表图片文本检测上的表现更加优秀,检测到更多文本框的同时很好地处理了文本框堆叠现象,在文本识别部分相较于Attention OCR 系统能够更好地识别密集数字编码,同时整体系统面对电能表图片亮度、模糊度、角度等干扰具有更好的鲁棒性。
3 结束语
文中基于改进的PSENET 与CRNN 算法设计了一种两阶段的电能表文本识别系统,实现了智能电能表信息的自动检测与识别功能,检测精度达到0.9360,算法实现了以下创新:
1) 设计精细的文本检测模块,加强对电能表信息细粒度特征的利用,使模型能够有效应对文本区域边界模糊的问题;
2) 基于电能表文本区域间的相关性,通过基于LSTM 的深层双向RNN 网络保留上下文关系,推理出难以识别的文本内容;
3) 设计完整的智能电能表文本识别系统,为远程电能表信息采集、智能电能表云管理等电能表智能化管理项目提供了关键技术手段。
文中高效精准的智能电能表场景文字识别技术有效地提取了高密度多聚集的字符图标混杂条件下的信息,提高资产信息提取的智能化水平。算法在电能表图像的识别具有良好的鲁棒性,降低人工采集的风险,提升资产信息采集的安全级别。为建立完善的贯穿整个生命周期的设备档案库提供了技术手段,能够有效地提升资产管理和运行管理的自动化水平。
