基于MRI影像组学特征构建脑胶质瘤IDH1突变预测模型
2023-12-25江少凡宋阳薛蕴菁蒋日烽
江少凡,宋阳,薛蕴菁,蒋日烽
胶质瘤是颅内最常见的恶性肿瘤,即使通过积极的手术、放化疗和靶向药物等治疗,预后仍然很差。近几年来有研究者逐渐开展了胶质瘤分子、基因层面的研究,所研究的基因主要有IDH、EGFR、MGMT及1p/19q等[1-2]。IDH基因中以IDH1突变最常见,其作用是降低肿瘤细胞增殖程度和减少血管生成,使胶质瘤侵袭性相对减低,故有IDH1突变的胶质瘤患者具有相对良好的预后[3]。针对IDH1突变型胶质瘤的靶向药物治疗手段已逐步开展。因此,对于胶质瘤尤其是无法切除的胶质瘤患者而言,无创性预测IDH1突变有助于指导临床尽早制订合理准确的治疗策略。
影像组学技术可基于常规MRI图像提取的肿瘤病灶的高通量定量特征,在脑肿瘤的诊断方面具有高度特异性和无创性的综合优势。既往的研究结果表明单一序列对脑肿瘤的诊断效能有限,多个序列组合能获得更好的诊断效能[4-5]。但既往对多种序列组合和多种机器学习(machine learning,ML)模型进行比较的相关研究报道较少或不全面。本研究中通过多种序列及组合、特征选择方式、降维方式及ML分类器的组合使用来构建多种ML影像组学模型,评价各模型对IDH1突变胶质瘤的预测效能。
材料与方法
1.一般资料
回顾性分析2014年1月-2021年12月在本院于术前接受3.0T MR检查并经病理证实的脑胶质瘤患者的病例资料。纳入标准:①病理诊断为脑胶质瘤;②首次接受胶质瘤手术治疗且术前未接受任何相关治疗;③术前行3.0T MR检查,检查序列需包括标准化采集的T2WI、T2-FLAIR、DWI及对比增强T1WI。排除标准:①图像质量较差,图像信噪比较低和/或有明显伪影等;②病灶过小(肿瘤直径<1.0 cm);③免疫组化检查未检测IDH1。根据纳入和排除标准,最终纳入161例脑胶质瘤患者:低级别(WHO Ⅰ~Ⅱ级)66例,高级别(WHO Ⅲ~Ⅳ级)95例;IDH1突变型70例,IDH1野生型91例。IDH1突变型病例中,男41例,女29例;年龄23~68岁,平均(44.05±12.15)岁。IDH1野生型病例中,男54例,女37例;年龄3~77岁,平均(51.36±16.77)岁。按照7∶3的比例将161例患者随机分为训练集和测试集。训练集113例,IDH1突变型与野生型例数比为50/63;测试集共48例,IDH1突变型与野生型例数比为20/28。
本研究经福建医科大学附属协和医院伦理委员会批准。为保护患者隐私,隐去患者姓名等识别信息,所有入组患者的影像资料以数字编号表示。
2.MRI检查方法
使用GE Discovery 750 3.0T、Siemens Trio Tim 3.0T或Siemens Prisma 3.0T磁共振仪,收集的横轴面序列有T2WI、T2-FLAIR、DWI及对比增强T1WI,各序列标准化采集参数如下。T2WI:TR 4000 ms,TE 90 ms,体素分辨率0.5 mm×0.5 mm×5.0 mm;T2-FLAIR:TR 9000 ms,TE 145 ms,体素分辨率0.6 mm×0.6 mm×5.0 mm;DWI序列:TR 4000 ms,TE 60 ms,体素分辨率1.4 mm×1.4 mm×5.0 mm,b值选用0和1000 s/mm2,自动生成ADC图(本研究提取的是ADC图的组学特征);对比增强T1WI:TR 1750 ms,TE 9.0 ms,体素分辨率0.6 mm×0.6 mm×5.0 mm。将患者4个序列图像的DICOM格式转化为Nifti格式后,采用SPM12软件将所有序列的图像向T2WI图像进行配准。
3.ROI勾画及特征提取
由2位放射科医师(分别具有5和10年工作经验)利用ImageJ软件(https://imagej.nih.gov/ij)共同进行ROI的勾画。勾画方法:对每例患者的前期已配准好的所有序列图像进行观察,对强化不明显或无强化的脑胶质瘤选择T2-FLAIR序列进行ROI的勾画(图1);对于强化明显的脑胶质瘤则在对比增强T1WI图像上进行ROI的勾画(图2);通过观察T2WI和T2-FLAIR图像,在肿瘤实体区域逐层勾画ROI,注意避开肿瘤内的液化坏死区。因所有图像先期均进行了配准,故在任意一个序列上勾画的ROI均可同步到其它序列。最后生成感兴趣体积 (volume of interst,VOI).利用FAE Pro V0.4.1软件(https://github.com/salan668/FAE)中的pyradiomics模块提取各序列VOI的影像组学特征。
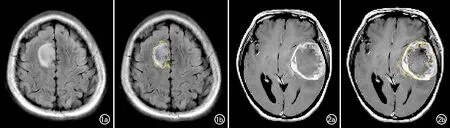
图1 右额叶脑胶质瘤ROI勾画示意图。a)T2-FLAIR序列显示肿瘤呈不均匀高信号;b)T2-FLAIR序列,沿肿瘤边缘勾画ROI。
4.最佳序列的筛选和模型的构建
使用FAE软件,将训练集和测试集中各序列所提取的组学特征按数据平衡化、数据归一化、特征选择、特征降维和分类建模的顺序进行。
首先,在测试集中筛选最佳的序列或组合,具体步骤如下。①数据平衡化:上采样;②数据归一化:均值归一化;③特征选择:采用方差分析法(analysis of variance,ANOVA)进行特征选择,特征数的范围设置为1~20;④特征降维:对每两个特征使用皮尔逊相关系数(Pearson correlation coefficient,PCC)法进行分析,如果其r值大于0.9,则在 FAE 软件中随机删除其中一个特征;⑤分类建模:分别采用四种算法即线性判别分析(linear discriminant analysis,LDA)、最小绝对收缩和选择算子(least absolute shrinkage and selection operator,LASSO)回归(LASSO regression,LR)、逻辑回归(logistic regression,LG)和支持向量机(support vector machine,SVM)建立机器学习模型。在训练集中采用10折交叉验证对模型进行训练。序列或组合总计15种,通过比较其ROC曲线的AUC筛选出最佳序列或组合。以上所有流程都是在Python 3.7.6上使用FAE Pro V0.4.1软件来完成的[6]。
然后,基于最佳序列组合,将其提取的组学特征采用多种算法按照上述步骤重新进行建模,主要步骤和方法如下。①数据平衡化:上采样;②数据归一化:均值归一化;③采用2种方式进行特征选择,分别是方差分析和特征权重算法(Relief),特征数的范围设置为1~20;④选用2种方式进行特征降维,分别是PCC和主成分分析(principal component analysis,PCA);⑤然后,采用LDA、LR、LG和SVM四种算法分别建立机器学习模型。通过上述步骤和算法的组合共获得16种机器学习模型。
训练集通过10折交叉验证对模型进行训练。在测试集中对16种机器学习模型进行验证,通过FAE软件的one-standard error法、ROC曲线和Delong检验筛选出具有较好拟合度和AUC最大的机器学习模型,记录其相应的诊断敏感度、特异度和符合率等效能指标值,然后,将此最佳机器学习模型联合临床指标(年龄、性别、病理分级及KPS评分)构建联合模型,分析联合模型的诊断效能。
所有AUC值的95%CI采用bootstrape法进行1000次重采样得到。
5.统计学方法
临床资料的组间比较使用SPSS 23.0统计软件。计数资料用频数表示,符合正态分布的计量资料采用均数±标准差表示。采用独立样本t检验比较训练集和测试集之间患者年龄和KPS评分的差异,采用卡方检验比较训练集和测试集之间患者性别构成、肿瘤病理级别和IDH1突变率的差异。采用Delong检验比较不同机器学习模型AUC的差异。以P<0.05为差异有统计学意义。
结 果
1.临床资料
训练集和测试集中患者年龄、性别、KPS评分、肿瘤分级和IDH1突变率的差异均无统计学意义(P>0.05),详见表1。

表1 训练集和测试集临床资料的比较
2.特征提取结果
T2WI、T2-FLAIR、ADC图及对比增强T1WI四个序列均各自提取了98个影像组学特征,包括灰度共生矩阵(gray level co-occurence matrix,GLCM)特征24个、灰度行程长度矩阵(gray level run-length matrix,GLRLM)特征16个,灰度区域大小矩阵(gray level size zone matrix,GLSZM)特征16个、邻域灰度差矩阵(neighbouring gray tone difference matrix,NGTDM)特征5个、一阶特征18个和形态特征19个。
3.筛选最佳序列或组合
基于15个序列或序列组合提取的组学特征所构建的预测IDH1突变型胶质瘤的四种机器学习模型在训练集和测试集中的AUC值详见表2。基于ADC图和对比增强T1WI序列提取的组学特征所构建的4种机器学习模型在测试集中的AUC分别为0.888、0.872、0.896和0.877,均高于其它序列或组合的AUC值,故此序列组合为最佳。
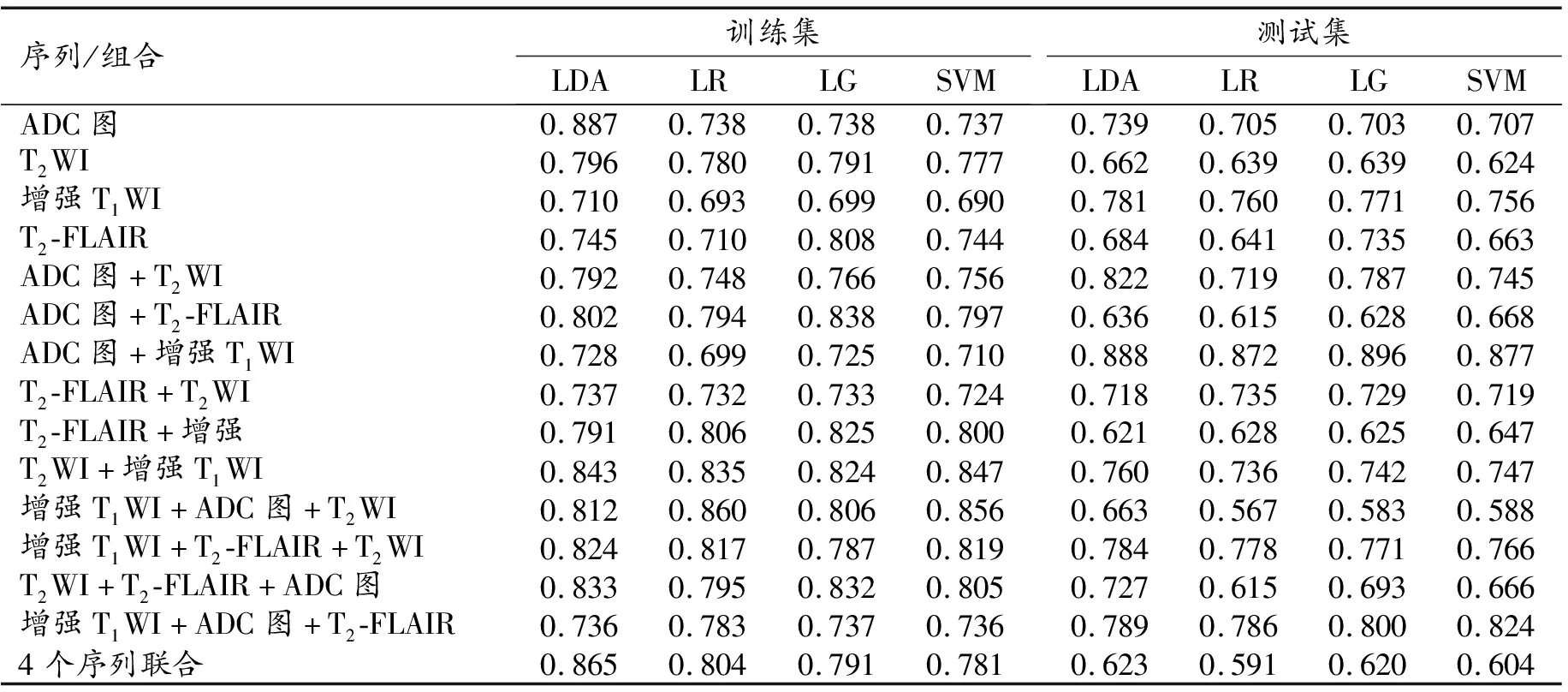
表2 基于不同序列及组合的四种机器学习模型预测胶质瘤IDH1突变的AUC值
4.基于最佳序列构建ML模型及其效能分析
基于ADC图+增强T1WI序列提取的组学特征,采用2种降维方式,2种特征选择方式以及4种分类器共构建了16种ML模型,通过FAE软件的one-standard error法排除过拟合或明显欠拟合数据后剩下5种ML模型,以其构建的算法组合命名,分别为PCA_ANOVA_LDA、PCA_ANOVA_LR、PCA_ANOVA_LG、PCA_ANOVA_SVM和 PCC_Relief_LDA。
5种ML模型在训练集和测试集中预测IDH1突变型的效能分析结果详见表3。5种模型在测试集中的AUC为0.656、0.766、0.854、0.814和0.810,在测试集中的AUC分别为0.596、0.829、0.808、0.821和0.818。Delong检验结果(图3):在训练集中,PCA_ANOVA_LDA的AUC低于另外4种ML模型(P=0.047、0.006、0.041、0.040),另外4种ML模型之间AUC的差异均无统计学意义(P>0.05);在测试集中,PCA_ANOVA_LDA的AUC低于另外4种ML模型(P=0.011、0.025、0.013、0.017),另外4种ML模型之间AUC的差异无统计学意义(P>0.05),其中以PCA_ANOVA_LR的AUC最大,为0.829(95%CI:0.658~0.966),特异度为0.864,敏感度为0.765,符合率为0.821,构建该ML模型的组学特征及权重系数见表4。

表3 基于ADC和增强T1WI序列的组学特征构建的不同机器学习模型的诊断效能

表4 PCA_ANOVA_LR模型中的组学特征及其权重系数
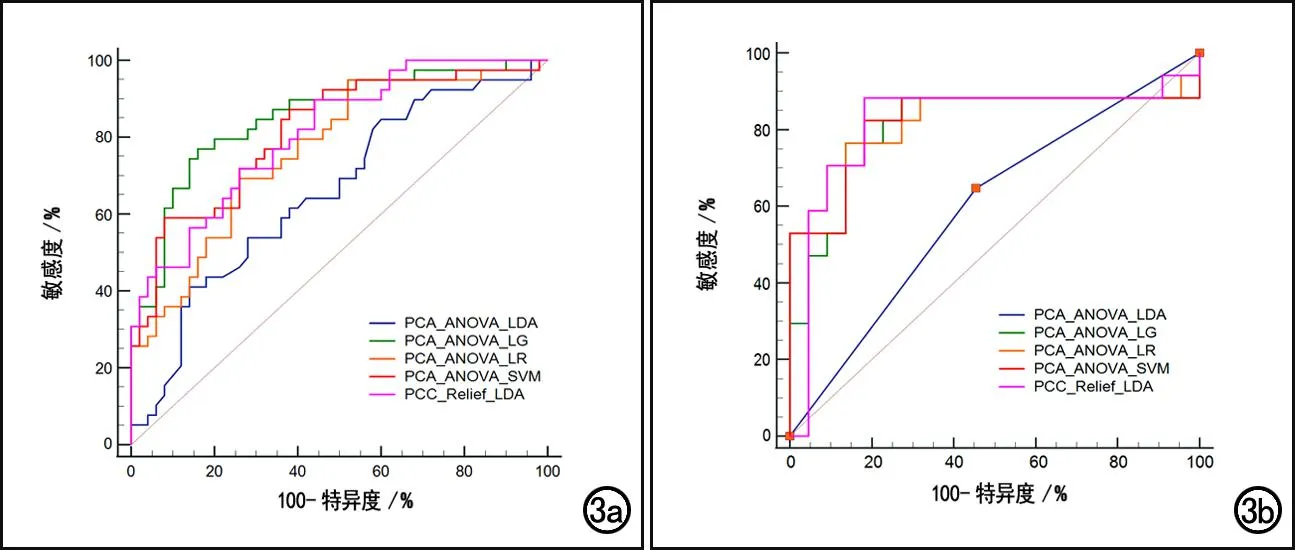
图3 数据拟合较好的5种ML模型在训练集和测试集中的ROC曲线,显示PCA_ANOVA_LDA模型在训练集和测试集中的AUC均低于另外4种ML模型。a)训练集;b)测试集。
5.临床资料结合最佳影像组学模型的效能分析
将最佳影像组学模型PCA_ANOVA_LR进一步与四项临床指标相结合构建组合模型,通过FAE软件的one-standard error法排除了过拟合和欠拟合的组合模型后,拟合度较好的各组合模型在训练集和测试集中的效能分析结果详见表5。在测试集中,以结合了KPS评分、病理分级和影像组学模型的联合模型的AUC最大,为0.874(95%CI:0.722~0.985)。

表5 临床资料联合影像组学模型构建的联合模型的诊断效能
讨 论
本研究结果显示基于ADC图+对比增强T1WI序列组合提取的影像组学特征所构建的4种机器学习模型在测试集中预测胶质瘤IDH1突变型的AUC值高于其它序列及组合,提示这个序列组合具有较好且稳定的诊断效能。基于该序列组合进一步构建的16种ML影像组学模型中,PCA_ANOVA_LR、PCA_ANOVA_LG、PCA_ANOVA_SVM和PCC_Relief_LDA这4种模型均具有较好的诊断效能,其中PCA_ANOVA_LR在测试集中的AUC最大,联合KPS评分、病理分级后的联合模型的AUC进一步提高。
决定胶质瘤患者预后的最主要因素是细胞增殖程度和血供程度,两者也是反映胶质瘤侵袭性强弱的指标,而与之相对应的MRI征象是DWI上肿瘤的扩散受限程度和对比增强T1WI上肿瘤的强化程度,胶质瘤IDH1的异质性能很好地在DWI的ADC图和对比增强T1WI序列上得以体现,这与既往相关研究中序列的选择结果相一致[7-9]。本研究结果亦显示出基于多序列组合所构建的影像组学模型较单序列模型更加具有优势,在建模时应重点关注ADC图和对比增强T1WI序列所提取的组学特征。
本研究的样本量并不多,未纳入随机森林和决策树这2种分类器,原因是这两者都属于同一类型的分类器,比较适合对大样本数据进行评价,在小样本数据的分析中出现错误的概率较高,容易出现数据的过拟合。如郁义星等[10]基于132例肝癌患者的肝胆期MRI图像提取的组学特征构建了6种机器学习模型来预测肝细胞癌微血管侵犯,结果显示随机森林和决策树模型在训练集中的AUC为1或接近1,提示数据可能存在过拟合现象。而 LDA、LR、LG和SVM这4种分类器对训练样本量的依赖较小,适合小样本高维数据的分类[11-13]。Peng等[14]对105例胶质瘤患者基于其T2WI+增强T1WI序列使用SVM分类器建立影像组学模型,结果显示模型在测试集中预测胶质瘤IDH1类型的AUC为0.799。Chen等[15]基于175例低级别星形细胞瘤患者的增强T1WI序列提取组学特征,并利用LDA分类器建立组学模型,模型在训练集和测试集中的AUC分别为0.801和0.799。上述研究中的病例数与本研究中相近且均未出现数据过拟合的情况,故本研究选择了对小样本二分类问题有较好训练效果的LDA、LR、LG和SVM这4种分类器进行建模。
本研究中还发现基于ADC图+增强T1WI序列提取的组学特征所构建的16个机器学习模型中,有11个模型出现了较明显的数据欠拟合。数据欠拟合即训练集与测试集之间AUC的差异较大,且训练集的AUC值低于测试集,出现欠拟合现象的原因可能是数据分布不平衡。笔者发现本研究中无明显数据欠拟合的5种机器学习模型中有4种是由PCA_ANOVA方法构建的,笔者认为可能有以下两方面原因:一、要改善训练集中数据欠拟合的问题即提高模型的诊断效能,主要解决方法有增加特征数、减少正则化参数和使用非线性模型(如SVM等),而PCA作为一种高维数据的降维方式,可以使得降维造成的损失最小,主要作用就是保留训练集的特征信息,相当于增加了训练集的特征数,而PCC的降维方式是如果2个特征的相关系数值大于 0.9,则随机删除其中一个特征,因此相较于PCC,PCA能保留更多的训练集特征数,从而可提高训练集的诊断效能[16];二、ANOVA特征选择方式是通过选择与目标变量相关性最强的指标,可以减少过拟合风险和提高训练集的诊断效能,而Relief特征选择方法是将权重小于某个阈值的特征移除,减少了训练集的特征数,从而可导致模型在训练集中的诊断效能降低。同时本研究结果显示在训练集和测试集中,LDA分类器所构建的PCA_ANOVA_LDA与PCC_Relief_LDA两个模型之间AUC均存在差异,笔者认为LDA作为一种线性分类器,其稳定性可能不及LR、LG和SVM。
患者的性别、年龄、肿瘤的病理分级及KPS评分均是评价胶质瘤的主要临床指标,既往研究中也有将临床资料与影像组学模型结合的报道[4,17]。陈洋等[18]通过Log-rank检验以及多因素逻辑回归分析,发现KPS评分、病理级别及IDH基因型均与胶质瘤预后密切相关,本研究结果亦显示影像组学模型结合KPS评分和病理分级后得到的联合模型的预测效能进一步提高。
此外,与以往的研究不同,本研究将高、低级别胶质瘤一起纳入研究,使组学模型不受病理分级的影响,更加适合在术前预测胶质瘤IDH1突变,在近期的研究中也有类似报道[17]。2021年发布的第5版中枢神经系统脑肿瘤分类标准进一步弱化了肿瘤分级对胶质瘤分型的作用,而IDH基因则是首个得到公认的与胶质瘤分型相关的关键基因。
本研究具有一定的局限性:第一,为单中心研究,没有外部数据的验证,这是由于外部机构的MRI扫描参数无法做到与本研究中完全一致;第二,由于本研究为回顾性分析,且入组条件较为严格,尽管纳入的样本是目前本中心能收集到的全部病例,但样本量还是相对较小,今后还将继续搜集相关病例以扩大样本量来进一步验证本研究的结果;第三,本研究中仅选用了常规序列进行研究和分析,没有将采用了新技术(如磁共振三维动脉自旋标记、扩散峰度成像等)的相关数据纳入研究,原因是目前相应样本量还较少。
综上所述,基于ADC+T1WI增强序列组合提取的影像组学特征,采用方差分析的特征选择方法、主成分分析的降维方法以及LASSO回归的分类方式所构建的机器学习模型对胶质瘤IDH1突变具有较好的预测效能,结合临床KPS评分和肿瘤病理分级所构建的联合模型可进一步提高预测效能。
