基于迁移学习与细粒度文本特征的未见关系链接研究*
2023-12-23徐红霞
徐红霞
(中国人民大学信息资源管理学院 北京 100080)
基于知识图谱的智能问答(Knowledge Graph Question Answering, KGQA)能接受人们提出的自然语言问题,在图谱中查找相应答案,并返回给用户。KGQA包括三个算法模块,分别是实体识别、实体链接和关系链接。其中关系链接负责确定问题指向的知识图谱关系,是决定KGQA问答效果的关键模块。然而传统的深度学习关系链接模型一方面要求大规模的标注数据,需耗费大量的人力与物力;另一方面在用户的信息需求与知识图谱时常更新的现实情境中,提问与关系类型会常常增加,产生关系类型和提问频繁更新与模型无法频繁更新的矛盾,导致模型在这类情境下便不太适用。此外,关系链接中问题与关系字数相差悬殊也导致关系链接难度较大。
为解决上述问题,本研究通过优化关系的初始表示与语义表示之间的映射优化未见关系表示;通过迁移学习框架记住历史学习的通用知识与共性特征,缓解遗忘问题;通过在稠密向量中融入先进准确的抽象意义表示(Abstract Meaning Representation, AMR),并加入实体特征与问题变换捕捉细粒度特征,优化辨别性语义部分表示;实现任务共性特征学习和辨别性特征学习、关系语义和问句语义精准表示的双管齐下,一定程度上实现未见关系的链接。
1 相关研究
关系链接,又称为关系检测[1],在知识图谱问答中,它负责确定问题指向的知识图谱三元组关系。该任务与信息抽取中的关系抽取任务较为相似,却也有不同。关系链接旨在预测问题中主题实体的关系;关系抽取则是从文本段落中抽取左实体与右实体之间的关系。其相同点在于它们均从文本中抽取蕴含的关系。其不同之处主要包括两方面,其一,关系链接面向的实体通常仅有一个,关系抽取的对象则是两个实体之间的关系;其二,关系链接面向的文本为较为短小的问句,关系抽取面向的文本则为较长的段落文本,含有丰富的上下文信息。
根据现有研究的梳理,关系链接的方法能够分为两种:基于语义解析的方法与基于信息检索的方法。基于语义解析的方法是通过语义解析器将问题映射为语义逻辑形式[2],其基本思想是构造具有自然语言逻辑共性的语义图。基于语义解析的方法由于能够清晰地表示实体在句子中的结构,因此能够得到问题的深度表示[3],常见的语义解析方法有句法依存、AMR等。但语义解析方法的表示需要大量的语言语法知识,往往比较复杂,在进行标注时需要耗费大量专业的人力与物力资源,在训练时需要大量的复杂标注数据。而关系链接任务面向的关系字数较少,因此对问句的语义解析结果与知识图谱中的关系进行匹配将会放大语义解析带来的误差,导致关系链接效果差。综上,该方法应用到标注数据受限和获取代价昂贵的新领域时效果受限[4]。
基于信息检索的方法主要根据问题相关信息从知识图谱中检索得到候选答案[5],而后使用排序技术从候选中选择正确答案。根据语义学习方式的不同,基于信息检索的方法可以分为两种类别:特征工程策略与表示学习方法,特征工程策略属于人为工程,而表示学习是模型自主学习。随着深度学习技术的不断发展,表示学习方法获得大量关注,也被引入到关系链接任务中[6]。基于表示学习的关系链接通过在低维向量空间中编码问题与答案[7],得到二者的稠密向量表示,之后计算问题与答案向量表示的相似度分数,拥有最高分数的候选答案作为最终答案。在低维向量空间中将问题与答案编码为稠密向量表示的过程,也被成为嵌入(Embedding)表示学习过程。神经网络方法在基于表示学习的关系链接中得到了广泛的研究,代表性的神经网络模型有记忆网络[8]、字符级长短时记忆网络[9]、融入attention的卷积神经网络[10]等。Yu等于2017年[1]将残差连接的设计融入深度循环网络中,提出HR-Bilstm关系链接模型,该模型取得了当时最先进的关系链接效果,刷新了关系链接的SOTA(State-of-the-Art)结果。除了基于神经网络嵌入表示学习的关系链接方法外,Wang等[11]提出了知识图谱向量化关系表示学习方法,采用TransE方法进行关系表示。
研究证明基于信息检索的方法相比基于语义解析的方法较优[12]。现有基于信息检索的方法大多基于监督深度学习算法,一方面,模型训练需要大量的高质量标注数据,另一方面,当领域的知识图谱越来越庞大或进行更新与更换时,模型会遇到长尾问题,即在现实问答场景中会遇到大量训练中未见的关系类别,这导致模型不太适用于快速更新的场景。为减少昂贵的人力与物力标注成本,解决长尾问题,本文构建了未见关系链接任务,其中“未见”表示测试集中的关系类型从未出现在训练集中。针对该任务,本文重点关注如何提高未见关系链接的精准性和泛化性。一方面,人类具备跨领域的关系链接泛化能力。人类通过学习大量通用知识,同时捕捉辨别性部分进行未见关系的准确识别。另一方面,在深度学习的实际应用中,通常会汇聚多个数据集增强泛化能力,但由于多个数据集并非独立同分布,因此模型简单地跨数据集效果较差。迁移学习则放宽了传统深度学习中数据集必须服从独立同分布的因素,它旨在挖掘领域不变的本质特征和结构,同时度量数据之间的细粒度差异部分,有效地综合利用两个数据集,使得数据可以在领域间实现迁移和复用[13]。基于以上两个方面的分析,本文旨在探讨通用知识学习与细粒度辨别性部分的捕捉这两种优化思路,并对其进行深入研究。
2 研究框架与方法
2.1 模型的提出
在通用知识的学习方面,Bert等大规模预训练语言模型包含了大量的通用知识,被广泛应用于各项自然语言处理任务中[14]。Bert是在掩码语言模型任务和句子对分类任务上训练得到的深度transformers网络,通过无监督学习在大规模语料上进行预训练,得到通用知识模型。掩码语言模型任务是通过在大规模数据上随机隐藏词汇进行无监督训练,模型将词汇随机替换为[MASK]字符,旨在特定的上下文中还原被遮盖的字符,从而得到上下文相关的动态分布式表示模型。句子对分类预训练任务输入句子对,旨在判断两个句子是否有衔接关系。微调是自然语言处理中的有效泛化机制。在具体任务中,Bert利用标注数据进行微调获得特定模型。
通过预训练,Bert模型学习到了丰富的通用知识。通过微调,Bert模型能够融合通用知识与领域知识,获得较好的特定任务模型。然而,微调是在小规模任务数据集上的监督学习方式,预训练则是大规模语料上的无监督学习方式,这是两种截然不同的学习方式,导致微调时会造成灾难性遗忘问题[15],而出现对任务数据集的过度拟合的现象。在这种情形下,模型会遗忘大量学习到的历史知识,当任务数据集较少时,模型可能只能对训练数据提供准确预测,而对新数据的预测能力低下。此外,现实情况通常会汇集多个来源数据进行微调。而在深度学习模型中,会假定训练集和测试集来自同一分布,现有的研究也多用同一分布下的数据测试研究的有效性。由于现实情况多不符合假定条件,因此模型在遇到分布外的数据时,效果会大幅下降。在未见关系链接任务中,以上三个问题导致基于Bert的微调模型对未见关系预测能力较差,模型泛化能力较低。为缓解基于Bert的关系链接模型对先前知识的灾难性遗忘和对领域数据的过拟合问题,提高模型泛化能力,本文引入了Adapter-Bert框架,该框架引入多个adapter层,在微调时,将预训练层进行固定,只更新adapter层,能够更大程度保留历史知识。
在细粒度辨别性部分的捕捉方面,本文引入AMR形式化语义表示、实体与问题变换细粒度特征。AMR是不同于深度学习的分布式表示的形式化语义表示方法,与它类似的表示方法还有句子依存关系树,相对于句子依存关系树,AMR的语义表示结构更为完整。AMR具备较完整准确地表示文本语义的能力,可以作为文本辨别性语义部分的一个重要维度。实体特征包括实体文本与实体位置两部分。实体文本是问题中的主要关注对象,KGQA需要根据实体文本在图谱中进行查找,获取关系类别。实体位置对问句中的关系语义也有重要的影响,不同的实体位置可能会导致不同的关系类型,例如“患有糖尿病的高血压病人应该吃什么药”与“患有高血压的糖尿病人应该吃什么药”,虽然是同样的实体名,但不同的位置导致第一句主题实体为高血压病人,第二句话主题实体为糖尿病人。因此,实体的文本特征与位置特征均对问句关系语义产生重要影响。
2.2 基于迁移学习与细粒度文本特征的未见关系链接模型
本文基于Adapter-Bert框架提出了未见关系链接模型。该模型的总体结构如图1所示。模型通过将实体候选关系与问句进行语义匹配,获得是否匹配成功的分类标签。匹配成功的分类标签即为正确链接的关系。模型输入包括四个部分,分别是问句抽象意义表示、实体指称项、问题、关系,输入首字符为CLS特殊字符,四个部分之间通过SEP特殊字符分隔。模型通过大规模预训练语言模型初始化输入,从而将通用知识融入模型中。模型选用Adapter-Bert框架,减轻了灾难性遗忘问题,同时保证了本任务的学习能力。模型输出字符的语义表示,取CLS特殊字符的表示,经过线性变换层与softmax输出层得到是否匹配的概率分布,最终得到分类标签。以下分别针对框架的选择、实体特征、问题变换、抽象意义表示特征进行说明。
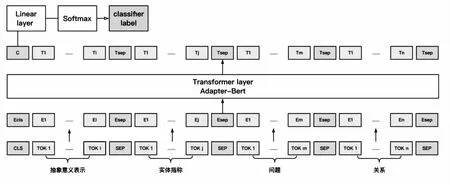
图1 模型架构
2.2.1 框架的选择
基于2.1部分的分析,可见基于Bert的微调存在任务数据过拟合、历史知识遗忘、模型泛化性差的问题,基于此,谷歌团队Neil Houlsby等人于2019年提出Adapter-Bert[16]迁移学习模型。该模型在对Bert中的Transformer层进行了改进。Adapter-Bert模型将adapter层插入 Transformer模块中,在Bert的原有atttention层和Feed-forward层之外,加入了两层Adapter层,用于两个子层的输出映射,adapter 将隐层向量从d维映射为m维,而后重新映射为d维。该框架的优势在于只有少量参数被修改,微调得到的模型参数与原预训练语言模型的参数很相似,避免了下游任务微调过程中的过拟合和泛化性差的问题,固定原 BERT 的参数还极大地缓解了遗忘问题。因此,基于Adapter-Bert的微调在低资源和跨域场景中比基于Bert的微调有更好的效果。此外,该框架在微调中梯度不会下降太大,不会出现梯度消失问题,降低了训练中的优化难度,因此效果也更加稳定[17]。
2.2.2 细粒度特征
a.实体特征。实体文本与实体位置特征有助于模型对问题细粒度辨别性部分的捕捉。其一,主题实体在问题中位置不同,句子语义依存关系也不同,因此无论是实体还是其上下文,语义表示都会有变化,即问题的语义表示会发生变化,所以对实体进行位置特征编码是必要的。其二,实体的文本特征也对问句语义有重要影响,例如“糖尿病怎么治”与“熊孩子怎么治”,这两个问句虽然都是怎么治,但糖尿病与熊孩子是两个完全不同的实体语义,这导致了问句中的“怎么治”呈现不同的语义。其三,问句中可能不仅包含一个实体,实体位置能对不同位置的实体进行有效区分,以便关系链接的召回阶段,即实体的关系查询阶段,能够召回特定实体对应的关系类型。基于以上原因,本文将问句中的实体文本与位置作为模型的重要特征。
b. 问题变换。本研究将问题中的实体使用特殊字符表示进行问题变换,旨在增强泛化性与语义准确性。问题变换方法受到了基于问句模版匹配的关系链接方法的启发。问句模版匹配是关系链接任务的一个传统研究方法,该方法通过人工构造每一种关系的若干模版,将用户问句进行转换,并与模版进行字面匹配。本研究的问题变换思路正是借鉴了这一方法,将实体用特殊字符表示,问句从而转换为问句模版,进而模型能够学习到去除实体文本后的问句共性特征。同时,这一处理方法由于将实体相应位置进行统一替换,能够帮助模型进行实体位置捕捉。综上,该方法在学习问句共性特征的同时,能够捕捉到实体位置细粒度特征,提升模型泛化性和对细粒度辨别性特征的学习能力。
c.抽象意义表示特征。在日常生活中,我们常常会见到存在歧义的自然语言,一个语义可以用多种词或句进行描述,同样的词或句在不同的语境下也会呈现出不同的语义。准确的语义表示是自然语言处理模型的基础与关键。语义表示技术一直有两种流派,分别是基于语言学语义分析的形式化符号表示方法与基于统计的分布式表示方法。形式化表示方法通过词与词之间关系进行表示,如句法分析、抽象意义表示等,分布式表示方法则通过稠密向量进行表示。
随着深度学习的不断发展,分布式语义表示方法近年来被研究人员与业界所青睐,同时形式化符号表示方法近年来也在继词法分析、句法分析后有所突破。AMR在依存句法树的基础上突破了树结构,采用了表示力更强的图结构,其以句法语义为基础,兼顾词汇语义,允许增删词语,表示能力强[18]。李斌等[18]于2017年针对汉语特有的语法特点完善标注体系,构建了中文AMR,该团队于2021年又发布了中文AMR2.0版本的大规模数据集[19],该大规模数据集的发布大大提高了AMR表示模型的准确度和可用性。本文也采用了基于该大规模数据集的AMR模型生成问句AMR表示。
综上,两种语义表示方法各有优势,形式化表示方法更加接近人类理解语言的方式,能够进行准确的模仿学习。分布式表示方法则全然基于统计学方法,通过大量数据得到规律与特征,能够进行准确的自学习。本研究将两种语义表示方式进行融合,在分布式表示中融入抽象意义表示这一形式化表示方法,提高模型对问句结构与形式的捕捉能力。
抽象意义表示的基本结构是单根有向无环图,它将实体抽象为概念作为图中的“节点”,将没有实在意义的虚词抽象为“边”。单根的目的是保证句子语义和句法的整体性。有向边是为了保证语义和句法的传递,无环是为了避免语义和句法传递陷入死循环。如图2所示,图中为“余华写的许三观卖血记讲述了一个什么故事”这一问句的AMR图,该表示将问句的语义呈现地十分清楚,例如主题实体(许三观卖血记)与问句重要语义(讲述)的关系、问句中询问的对象(amr-unknown)与其他部分之间的关系、其他实体(余华)与主题实体(许三观卖血记)之间的关系等。综上,有理由假定将抽象意义表示融入模型将提高模型对主题实体、其他实体、动作关系及其他关联关系等细粒度辨别性特征的捕捉能力,从而提升未见关系链接效果。

图2 抽象意义表示示例
3 实验及结果分析
3.1 实验设计及数据
为验证本研究所提方法在泛化上的优越性,本文收集了多源数据,包括NLPCC(Natural Language Processing and Chinese Computing)会议与CCKS(China Conference on Knowledge Graph and Semantic Computing)会议的知识图谱问答数据,训练集与测试集按照7:3进行划分,同时保证测试集中的关系均为训练集中所没有见过的关系类型,问句的AMR形式化语义表示通过Hanlp开源自然语言处理库生成,该三方库的AMR模型的数据采用了上述提到的AMR2.0大规模数据集。最终构建未见关系链接数据130 300条。基于构建的未见关系链接数据集,本文的实验目的如下:
a.对比Bert基线模型验证模型在未见关系链接任务上的效果。
b.对比在分布式表示中融入抽象意义形式化表示对未见关系链接任务的影响
c.对比引入实体特征与问题变换对未见关系链接任务的影响
d.对比两种语义表示方法的融合与实体特征和问题变换的加入对未见关系链接任务的共同影响。
基于上述实验目的,本文共设计了4组分离与对照实验,具体设计如下。
实验一:对比分析Bert基线模型(基于预训练Bert进行微调)与Adapter-Bert基线模型(基于预训练Adapter-Bert进行微调)的实验效果。
实验二:对比模型分布式表示(Bert和Adapter-Bert)与在分布式表示中融入抽象意义形式化表示(Bert+AMR和Adapter-Bert+AMR)的实验效果。
实验三:对比分析实体特征与问题变换分别加入Bert模型(Bert+ENT)、Adapter-Bert模型(Adapter-Bert+ENT)的实验效果。
实验四:对比分析实体特征与问题变换分别加入Bert模型、Adapter-Bert模型,并在各自模型的分布式表示中融入问句抽象意义形式化表示后的实验(Bert+AMR+ENT与Adapter-Bert+AMR+ENT)效果。
以上4组8个实验能够进行Bert与Adapter-Bert效果比较、在分布式表示中融入抽象意义形式化表示与否效果比较、实体特征与问题变换加入与否效果比较以及两种语义表示方法的融合与实体特征和问题变换的加入二者是否有协同作用效果比较,能够达到上述4个实验目的。
3.2 实验配置及评估指标
本文所采用的参数设置如下表1所示。由于本研究为分类任务,因此实验采用准确率指标进行评价。指标计算方法如式1所示,其中,TP表示正确预测的数量,FP表示错误预测的数量。

表1 模型参数
(1)
3.3 实验结果及其分析
在未见关系链接数据集上,8个对照与分离实验结果如表2所示,可以看出:
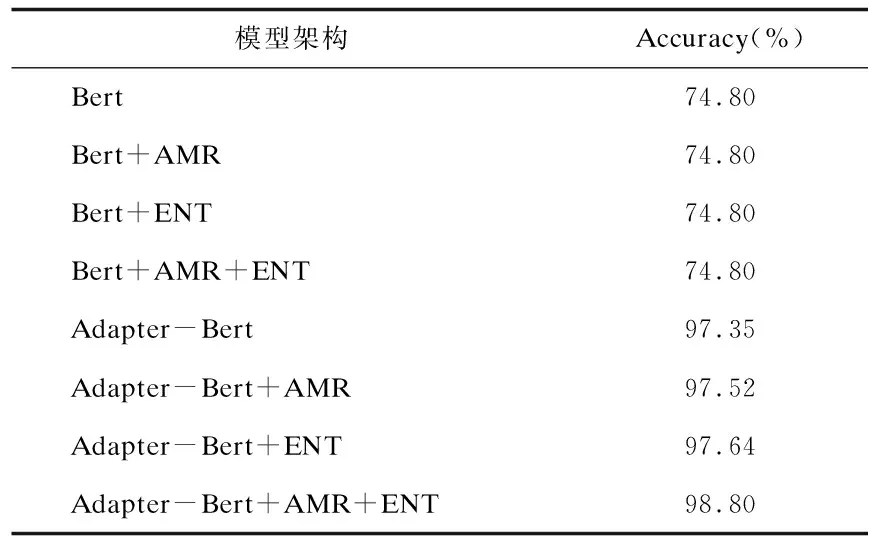
表2 模型在未见关系链接数据集上的实验结果
a.Adapter-Bert基线准确率为97.35%,比Bert基线模型准确率高20.4%,因此本文选取的框架在未见关系链接任务中相比目前常用的Bert框架具备优越性,能够缓解bert模型存在的灾难性遗忘与过拟合问题。
b.Adapter-Bert+AMR相比Adapter-Bert提高了0.17%,由于基础准确率已达97%以上,因此本文加入的语义解析特征能够为模型添加多维度语义信息。
c.Adapter-bert+ENT相比Adapter-Bert提高了0.29%,由于实体特征与问题变换强调了关系中涉及的实体语义和问题信息,因此同AMR特征,该特征能够更准确地识别问句所指向的关系。
d.Adapter-Bert+AMR+ENT相比Adapter-Bert提高了1.45%,该值相比上述单独特征加入的提升效果(0.17%、0.29%)之和有显著升高,这说明两个特征在未见关系链接模型中能够达到1+1大于2的效果。
e.从特征分别加入Bert和Adapter-Bert模型的效果来看,Bert模型分离实验,即Bert+AMR、Bert+ENT、Bert+AMR+ENT与Bert这一组对比实验,说明了AMR语义表示、实体特征与问题变换在Bert模型中未产生作用。这是由于基于Bert的微调模型产生了灾难性遗忘、对任务数据集的过拟合、分布外数据效果大幅下降等问题,导致模型学习能力较弱。在本研究构建的未见关系链接数据集中,测试数据中的关系类别在训练数据中未曾出现,由于遗忘与过拟合问题,基于Bert的模型对未见类别的语义表示能力较弱,本研究所提出的基于Adapter-Bert的模型在未见类别表示上具有显著优势。在Adapter-Bert模型分离实验中,即Adapter-Bert+AMR、Adapter-Bert+ENT、Adapter-Bert+AMR+ENT与Adapter-Bert这一组对比实验,证明了本研究提出特征的有效性,且Adapter-Bert+AMR+ENT模型的效果说明了细粒度辨别性特征之间还具有协同促进作用。
f.实验结果表明分布式表示与AMR形式化表示的融合所带来的提升相对整体准确率较小,这可能是由于二者的融合方式需进行进一步探索与优化。但由于这方面的研究较少,还没有找到更好的融合方式。但本文提出对二者的融合探索是价值的,一方面形式化表示含有问句中各个成分的类别及其之间的关系,能够为问句提供较强的辨别性信息;另一方面分布式表示在语义表示方面有很强的优势,能够对语义相似的对象进行准确计算。因此两种表示各有千秋,对二者融合的探索有较大的价值,能对未来研究产生积极推进作用。
综上,本文提出的模型在未见关系链接任务最终准确率达到98.80%,能够较好地满足现实场景应用需求。
4 结 语
Bert模型在任务中的微调存在灾难性遗忘、过拟合、分布外数据效果断崖式下降等问题。在知识图谱问答中,知识图谱常常更新或更换,会出现大量未见关系类别。基于这两点, Bert关系链接模型无法满足问答需求,且时常进行未见关系的数据标注与模型更新也需要大量的人力与物力。为解决这一问题,提高关系链接模型的泛化性,本文提出了基于迁移学习和细粒度语义特征的未见关系链接模型,该模型能够利用迁移学习框架adapter-bert缓解模型的通用知识遗忘问题,降低模型对于任务数据集的过拟合程度,增加模型训练的稳定性,提高模型的泛化能力。细粒度特征的加入使得模型在提高泛化性的基础上,增强其对辨别性部分的捕捉能力,更好地表示问句间的细微差异,提高模型的语义匹配准确性。本研究探索了形式化语义表示与分布式语义表示的融合方式,在深度学习模型的低维稠密嵌入表示基础上,融入先进的AMR。通过融合两种不同形式的语义表示,模型能够学习到多维精准的问句与关系语义表示。此外,本研究受到传统基于模版匹配的关系链接方法的思路启发,将问题通过实体替换转换为模版形式。由于不同的实体指称名会导致不同的问题语义,不同的实体位置也会导致全然不同的语义,因此本研究融入了实体内容与位置特征。
为验证上述方法的有效性,本研究构造了中文未见关系链接数据集,并验证了模型效果。研究结果发现,在未见关系链接中:a. Adapter-Bert基线模型较Bert基线模型有大幅提升;b.基于Bert的未见关系链接模型存在着灾难性遗忘与任务数据集过拟合问题;c.在Adapter-Bert中,单独的细粒度辨别性特征能够提升模型效果,多个细粒度特征能够有协同效果提升。本文所构建模型较Bert基线模型提高了24%,能够应对知识图谱常常更新的现实需求,具有较好的应用前景。未来的研究一方面能在更多领域、更大规模数据上进行实验,检验本研究提出模型的有效性;另一方面,随着领域的不断发展,对形式化表示与分布式表示的融合能在未来进行更深入的研究。前述相关研究中有研究通过TransE进行关系表示,抽象意义形式化表示与知识图谱表示同属于图表示,因此未来可以探索诸如图表示学习方法等其他形式化表示与分布式表示的融合方式,进一步提高模型的精度。
