基于指标检索的科技查新服务模式探析
2023-12-22毛一雷李琳珊
毛一雷 曹 燕 李琳珊 孙 洁
(中国科学技术信息研究所,北京 100038)
0 引言
科技查新是以反映查新项目主题内容的查新点为依据,以计算机检索为主要手段,以获取密切相关文献为检索目标,运用综合分析和对比方法,对查新项目的新颖性作出文献评价的情报咨询服务[1]。科技查新作为科研管理过程中的一个重要环节,不仅能够引导科技创新过程,为立项、鉴定、成果奖励等提供参考,而且能够帮助科研人员了解行业现状,拓宽研发思路。国务院发布的《关于加快科技服务业发展的若干意见》中明确提出“加强科技信息资源的市场化开发利用,支持发展竞争情报分析、科技查新和文献检索等科技信息服务”[2]。在加快实施创新发展战略的大背景下,我国科技查新工作面临着来自市场的严峻考验,科技查新的服务模式也发生了相应的变化。在技术研发、产品开发过程中,技术或产品的指标参数是其技术水平或产品性能的直接反映,如何充分利用各类查新资源,借助传统查新手段建立起支撑科技决策和产业创新的精准查新服务模式是本文要解决的主要问题。
1 国内外研究进展
1.1 科技查新服务模式
我国科技查新可追溯到20世纪80年代,其本质是专业化的信息检索[3]。在发达国家,查新(Novelty Search)一般只与专利文献检索相联系。隆新文等[4]将科技查新工作定义为以社会科学研究方法为基础,依靠期刊、报纸、会议论文、学位论文等公开文献信息资源,以文献检索和综合评述法等定性分析方法为主的信息服务方式。曹建勇[5]认为科技查新工作的核心就是对项目与成果等要素的创新性进行评价,而这一评价的本质就是信息分析的过程。从定义上看,依靠各类公开的文献资源,采用专业化的信息检索手段实现对各类创新要素的评价是科技查新服务的核心内容。
科技查新服务模式的发展主要分为粗放式查新阶段、精准查新服务阶段、定制化查新服务阶段3个阶段。在传统的粗放式查新阶段,主要以文献检索为核心,围绕用户的查新检索需求,开展以查新点为依据的定题检索,最终以查新报告的形式提供给用户。由于科技查新用户存在很强的异质性,不同类型的查新用户对查新服务的要求存在显著差异,传统的粗放式查新模式已经不能满足查新用户的实际需求,查新服务逐渐转向精准查新服务[6]。在精准查新服务阶段,主要聚焦于查新流程的精准化改进。邢春国等[7]指出“精准查新”是将“精准”的理念应用于从查新委托受理至查新报告撰写、审核的整个查新过程;梅梅等[8]将科技查新数据和互联网数据进行结合,以丰富的数据资源为基础,综合利用大数据技术为查新用户提供精准服务 ;马兰梦等[9]建立了一套“数据维度-需求特征-精准服务”的查新流程,基于研究领域、时间序列和服务对象揭示了查新用户特征,并从团队建设、资源配置、合作互联、宣传推送、评价反馈的角度制定精准查新策略。在定制化查新服务阶段,科技查新服务模式更多地将服务主体纳入查新服务过程,针对不同的服务场景开展定制化的查新服务。王红等[10]将知识服务的理念引入科技查新,在开展常规科技查新以外开发专题/定题服务、竞争情报分析和决策辅助研究等;王欣等[11]将科技查新工作嵌入并应用到创新主体创新活动的整个链条,提出了科技创新服务于“创新活动前期、创新活动中期、创新活动后期”的“科技查新+”服务模式;陈峰等[12]将技术尽职调查的理念引入传统科技查新,从服务侧和用户需求侧的双重视角构建了基于技术尽职调查的科技查新服务模式。
从查新现有业务来看,当前我国查新机构的查新业务主要包括立项查新、专利查新、成果查新、产品查新等[13],多数查新机构服务模式的多样性和主动性都有待提升。针对现阶段用户差异化、定制化的查新需求,从查新资源层面出发,探讨利用专业化的查新检索能力,将原有的粗粒度查新内容进行细化,推出以指标查新为核心的新型查新业务,对改进传统查新服务、提高查新业务的市场价值和应用价值、满足用户的个性化需求具有一定的实用价值和现实意义。
1.2 指标查新现状
指标查新在标准研究中应用较为广泛。在标准研究中常用产品/技术指标对比分析的方法,如对比分析国内外指定领域内的产品指标,助推我国产品走向国际市场[14-15],并且指标对比分析后建立的关键技术指标清单[16]也能为行业研发人员提供参考。又如姚灵等[17]针对水表产品标准关键性能指标进行对比分析,帮助水表企业更好地理解新国标的基本要求和标准贯彻中的重难点,为技术人员的方案设计提供参考。在标准研究领域,国内已有机构开始探索指标查新在标准服务中的应用。如河北省标准化研究院建立的标准指标数据库,用户可以通过产品名称、指标名称等进行标准指标检索[18];中国标准化研究院标准信息研究所推出标准内容指标对比服务,提供国内外标准的技术指标提取和对比分析服务[19]。虽然标准研究的技术指标对比分析涉及文献类型仅包含标准文献,但标准研究中的指标对比、指标检索等方法为科技查新提供了新的思路。在科技查新过程中纳入更细粒度的指标对比,完善传统的科技查新服务思路,探究如何为用户提供更客观、更细粒度的主动科技查新服务具有一定的现实意义。
2 指标查新的内涵及特征
2.1 指标查新与传统查新的流程对比
从业务流程上来讲,指标查新与传统查新大致相同,但在具体操作的侧重点上仍有所不同。表1从查新目的、查新内容、查新点、数据库资源、检索字段、检索策略和查新结果等方面将“传统查新”与“指标查新”的特点进行对比。
2.2 指标查新内涵及特征
根据指标查新与传统查新在业务流程上的区别,参考科技查新的定义,本文认为指标查新是指以公开数据为查新依据,以计算机检索为主要手段,以获取技术或产品的参数、指标相关的文献为检索目标,提供与参数、指标相关的技术分析、技术监测、技术预警、决策咨询等产品的情报咨询服务。与传统查新相比,指标查新在数据源、查新过程和查新结论上具有多源性、协同性和精准性的特征。
(1)数据的多源性。指标查新所利用的数据不仅包含传统的论文、专利、标准、成果等数据,还包含产品库、企业网站、科普文章、科技新闻、科技论坛等数据资源,而基于各类文献资源加工得到的指标数据库能够大大提高指标查新效率。从数据类型上看,这些数据源包含的数据类型有数据库中的结构化数据,还有从网页等提取到的文本、图片、表格等类型的数据。而从这些数据里对所需指标信息进行抽取加工,以更全面地发现有价值的情报,是科技服务工作面临的新挑战。在字段选择上,数值、指标信息多出现在论文正文、专利说明书中,因此更强调数据库中的全文、专利说明书等字段的选择。
(2)过程的协同性。在指标查新过程中,查新员不仅仅充当信息检索的角色,更多地是由知识服务者向知识交流者转变。查新员根据自己的查新经验和初步检索结果与需求方、领域专家、情报专家等相关方进行交流沟通,并及时根据反馈意见调整下一阶段的查新策略,提高查新产品与用户需求的适配度。
(3)结论的精准性。传统查新中查新结论是核心,查新结论中着重以技术特征对比的方式强调查新点中技术特征与相关文献技术特征的差异性,涉及指标层面的较少。指标查新结论涉及技术或产品的具体参数指标,对指标值、参数值的数据精准性较传统查新要求相对较高,尤其是数值大小、数量单位。因此,在指标查新的产品内容上,用户需要得到关于这个技术领域、产品性能等更详细的刻画描述,从而更准确地了解这个领域的发展概况和前沿进展,以保证情报服务能够正确、科学、有效地辅助决策过程。
3 基于指标检索的查新服务模式
基于指标查新的科技查新服务模式由需求感知层、查新资源层、方法工具层和产品服务层构成(图1)。需求感知体现在情报服务的全过程,需要将服务对象纳入整个服务体系中,根据反馈意见修正和完善查新服务过程。查新资源层、方法工具层、产品服务层之间通过对底层数据的采集、组织等过程形成由“资源-信息-知识-情报”的完整链条,有效地为各类用户提供情报决策支撑。
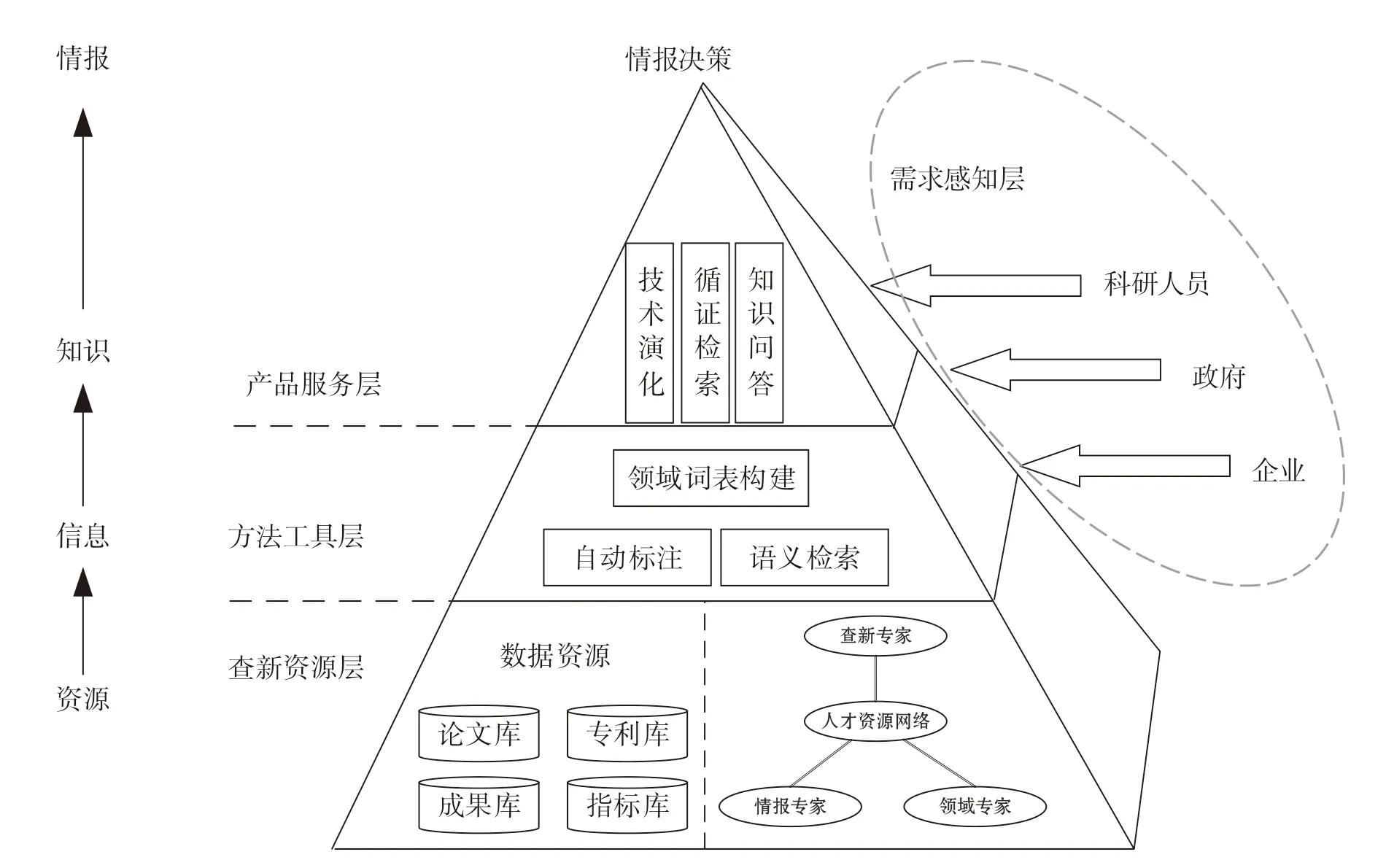
图1 基于指标检索的查新服务模式
3.1 需求感知层
精确感知不同类型查新用户的需求是提供精准查新服务的关键。指标查新的服务对象包括企业、科研人员、政府决策机构等,不同类型的用户在指标查新的需求上各有侧重。①对于企业,除了常规的政策、市场、法律等信息外,产品的技术参数对企业进行技术研发、明确市场地位、开拓新市场尤为重要。如在进入市场前,企业可根据产品的技术参数数据,识别和发现同类型产品的竞争对手,从而为企业做好市场布局、制定并购策略提供决策支撑。②对于科研人员,指标参数信息是了解当前科技前沿、明确技术国际定位的重要参考。在产品研发阶段,指标查新可以获取同类型产品的技术参数,可以通过同类型产品的产学研合作加快产品研发进程。此外,指标查新作为技术萌芽阶段的一种早期探测方法,指标查新监测到的一些技术研发过程中的早期迹象对科研人员研发方向的确定具有一定的指导意义。③对于政府决策部门,指标查新作为技术监测的一种方式和手段,依据指标查新建立起关键核心技术的“卡脖子”指标清单可以为政府部门做好项目布局的顶层设计提供决策支持。对项目管理等类型的政府机构来讲,客观、科学、公正地评估科技项目,已经成为科技项目管理工作的当务之急。早期的科研评审过程中多采用同行评议法,邀请领域专家对项目成果提出意见和判定,但此方法在评审过程中受专家先验知识的影响较大,评估结果的主观性较强。文献计量被引入科研评价后,可以通过既定的文献计量指标,对项目产出论文、专利等成果的数量和质量进行评估,但这类评价尚未深入到技术内容层面。从这个角度来看,以项目涉及的技术参数、产品参数等指标来衡量项目产出,为科技进步、解决科技问题等贡献提供良策。
3.2 查新资源层
3.2.1 数据资源组织体系
数据资源是指标查新的保障,数据资源组织体系主要包含数据资源采集和数据资源组织两个过程。其中,数据资源采集的主要目标是从各类数据库及互联网资源上获得指标数据。在数据类型上,传统查新以中国知网、万方数据、Web of Science、EI、Dialog等综合性文献数据库为主,指标查新所依赖的文献资源除了现有的论文数据库、专利数据库等科技文献数据库外,更依赖全源性的情报采集工作,包括政府、企业、智库的各类统计数据、标准数据库、新闻媒体报道等。数据资源组织是对获得的指标数据进行再加工,包括指标数据抽取、标引、链接等,构建服务于指标查新的指标库。从技术实现的角度来讲,一是根据基于本体的逻辑推理等技术构建起各项指标数据之间的关系,二是通过按照特定的元数据管理规则建立指标数据的元数据管理体系,以实现对指标的准确检索,保证指标查新过程的准确率。
(1)指标管理体系
对于大多数专业领域来讲,指标的定义是统一的,但指标名称不同其实质含义却相同的情况依然存在,所以对于描述或表达不一致但指向的指标相同、描述或表达重复但指标名称不同等情况应加以处理,构建起包含描述对象的各项指标、指标间的层级关系、所属领域等信息的指标管理体系。指标管理体系以指标描述对象为主体(图2),即指标I={ID,Name,Definition,When,Who,What,Where}。其中,ID为指标的唯一标识符;Name是指标名称;Definition是指标的定义及计算方法、计量单位等描述特征;When是指标值公开报道的具体日期;Who是该指标值对应的机构或研究人员;What是该指标对应的指标值;Where是该指标值公开报道的来源,包括新闻、专利、论文等。需要指出的是,指标和指标值之间存在一对一、一对多等不同关系,如指标I和指标值What之间存在着一对多的关系,即一个指标对应多个指标值。多个指标构成指标描述对象,指标描述对象在参考专家领域知识的基础上实现对描述对象的分类分级,各节点的描述对象共同刻画出这个技术领域的主要产品/技术特征;根据树状结构的层级关系,根节点往往代指的是整个技术领域,最深层节点是指标数据的最小描述单元。
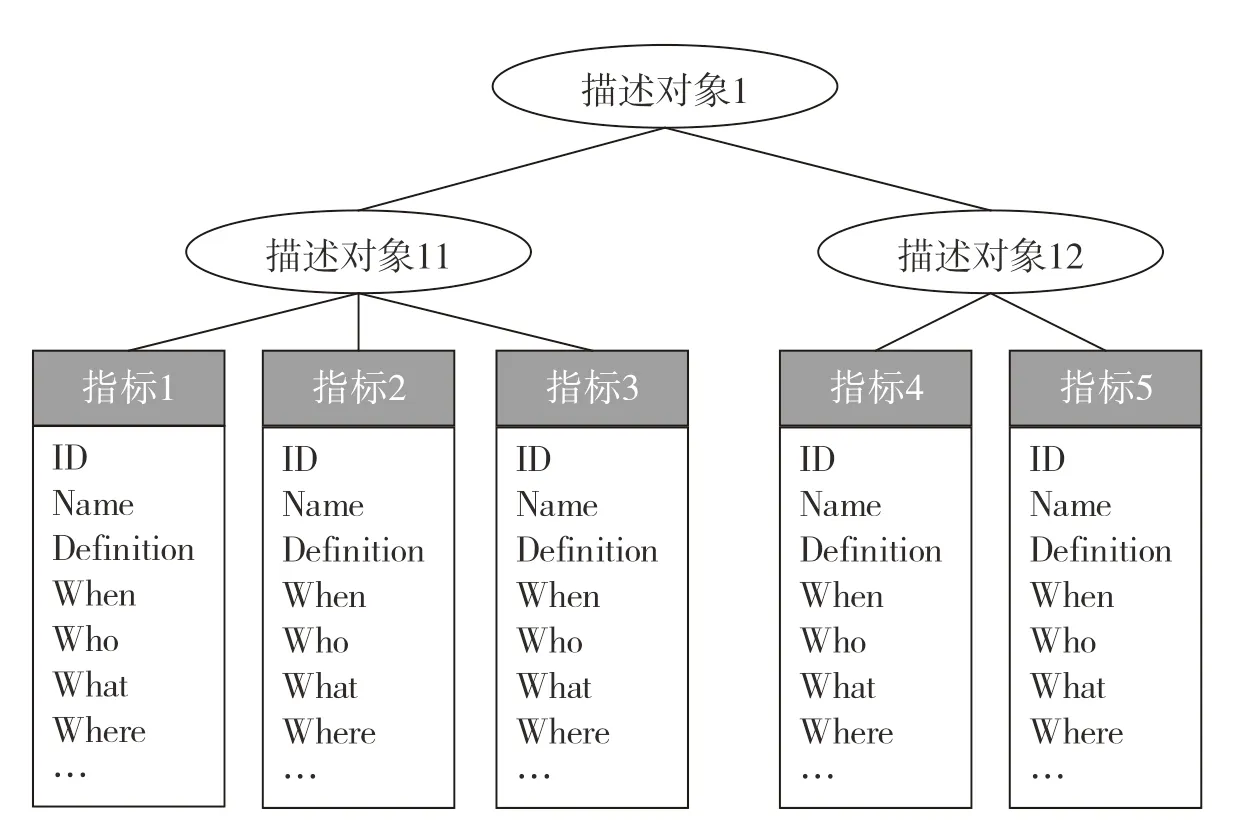
图2 指标及描述对象的树状结构
(2)指标数据的链接关系构建
指标数据之间的链接网络由指标和指标间的关系构成,可以表示为S=(I,L,R),其中I表示指标节点集合,L表示指标之间的链接关系,R表示指标链接规则。具体的链接规则包括R={同一机构、同一时间、同一描述对象}。如指标1和指标2之间属于同一描述对象,可记为即i1表示指标1,i2表示指标2,指标1和指标2之间存在链接关系,链接的规则为r1,r1表示i1和i2隶属于同一描述对象。指标之间的链接关系如图3所示,具体分为指标层和数据层,指标层包括指标及其属性信息,数据层包含文献库、机构库、国家库、期刊库等各类数据资源。
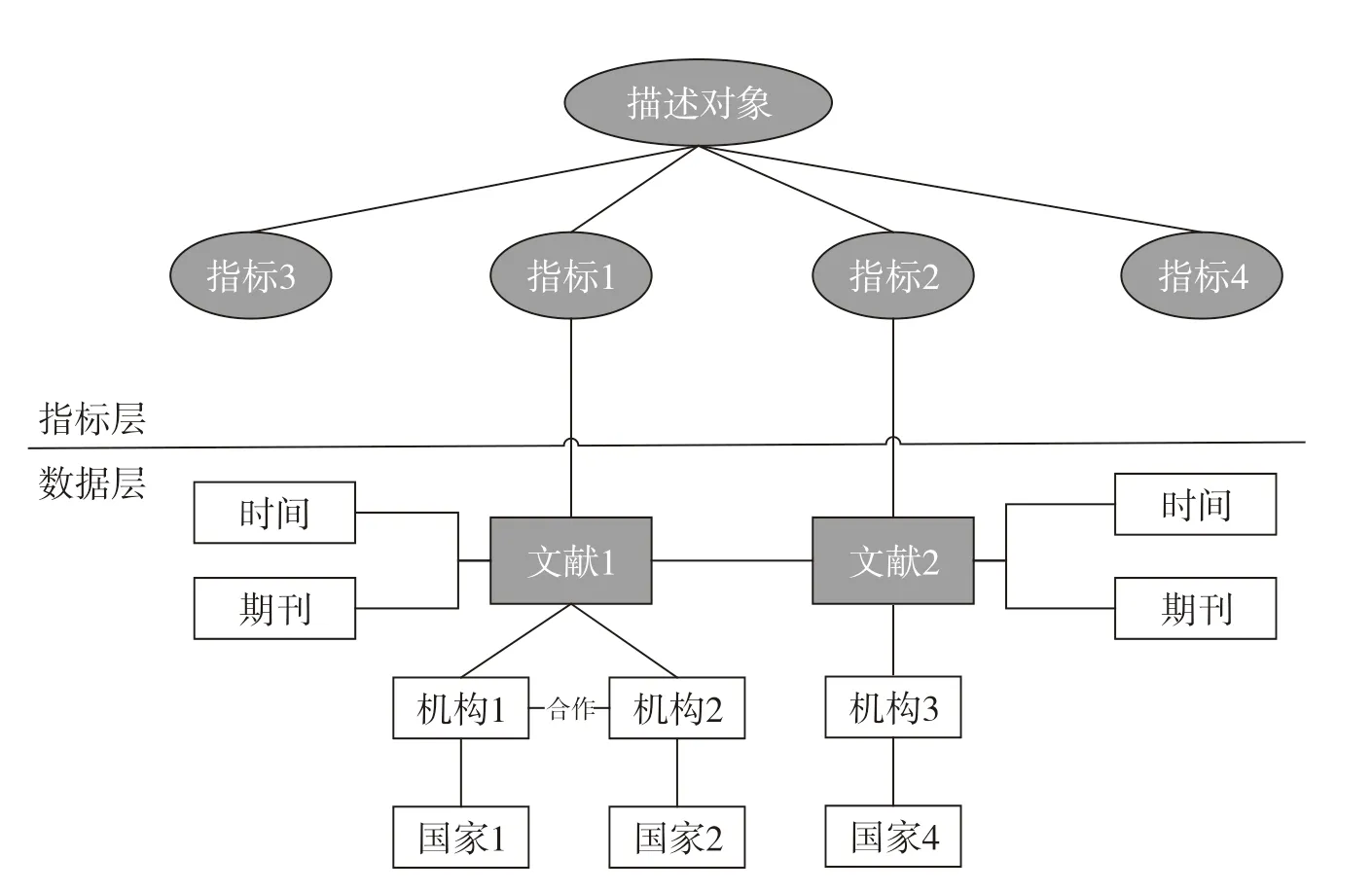
图3 指标数据链接网络
3.2.2 人才资源协同体系
人才资源体系是指标查新走向精准服务的关键,人才体系主要包含查新专家、情报专家和领域专家(图4)。查新专家即科技查新人员,在精准抓住用户需求、快速提炼主题,将用户所关注的领域问题转化成检索问题上具有长期的经验积累。情报专家在情报服务工作中积累了丰富的情报信息搜集、加工、分析等经验,能够广泛开展情报研究工作,真正打破情报问题和以政府、企业为代表的决策者之间的“语境鸿沟”。领域专家贯穿于情报服务的整个过程,在前期指标库建立、后续指标数据的分析过程中,都需要领域专家依靠自身的经验知识实现指标准确性的判断和指标数据的快速解读,从而将抽取出的指标数据与专家的经验知识相结合形成准确可靠的情报服务成果。查新专家、情报专家和领域专家在整个情报服务过程中沟通协同,最终形成以科技查新人员和情报分析人员为主,以领域专家为辅的协同服务网络,最大程度地发挥科技查新人员、情报分析人员和领域专家的专业价值,真正形成以科技查新人员、情报分析人员和领域专家共同构成的“科学共同体”,通过指标数据的“采集-抽取-整理-序化-推理”等全链条,实现精准化的查新服务。
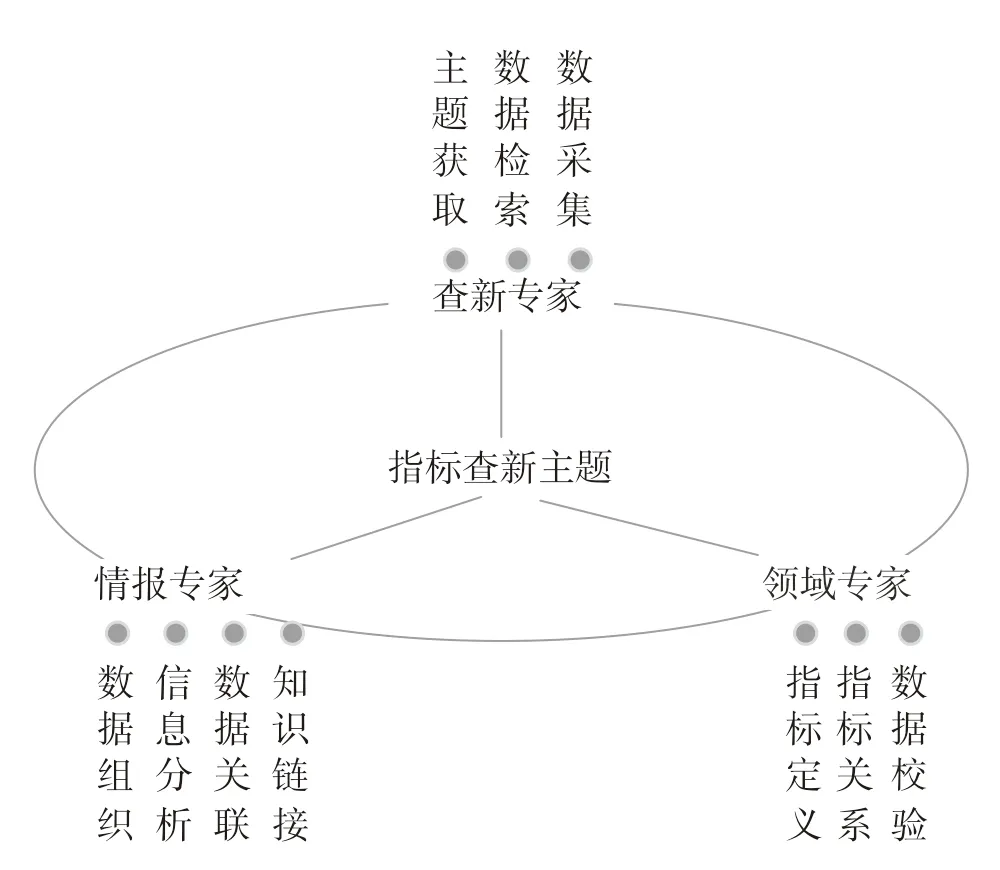
图4 人才资源网络
3.3 方法工具层
3.3.1 领域词表辅助构建技术
领域词表的构建是为了满足查新人员在指标检索过程中尽可能完整、正确地选用检索词,以便保证检索的查全率和查准率。作为指标所在技术领域的专用词典,领域词表罗列了这个领域内的简要技术清单,为指标查新后续开展技术演化、循证检索和知识问答等产品服务提供支撑和铺垫。具体来讲,领域词表构建过程包含指标词汇抽取、词间关系识别、词表更新和完善等过程。从词表结构来看,领域词表应包含指标总表、技术领域表和中英文对照表。指标总表在结构上包含指标词汇的全部信息,包含词间关系(同义词、相关词等),以及所属学科领域、技术领域、中英文形式等。其中词间关系之所以是指标总表中的重要内容,是因为在查新检索过程中各类规范词、同义词和缩写词、相关词等经常使用,通过词间关系对检索词进行扩充能够大大提升检索效率。技术领域表的构建主要是考虑同一指标描述词汇在不同的技术领域有不同的解释含义,方便查新人员从技术分类的角度实施检索。如在食品检测领域,F值是指在一定的致死温度下将一定数量的某种微生物全部杀死所需的时间;在光学领域,F值表示镜头的最大光圈;在机器学习领域,F值表示是精确率和召回率的加权调和平均。中英文对照表在检索国外资源时可以大大提升检索效率,保证检索的查全率和查准率。
3.3.2 指标词汇自动标注技术
指标查新要想实现精准检索离不开对各类数据资源的细粒度描述,充分利用上下文信息,为进一步的知识关联和推理作准备,以满足查新人员和普通用户对资源的个性化需求。在指标词汇的自动标注上,采用基于词典和条件随机场(CRF)算法相结合的方式,提高待标注文本的识别精度。根据指标查新需求,标注的主要对象为指标词汇及与指标词汇相关的所属机构、所属时间、描述对象3种关系。标注过程分为人工标注和模型标注两个部分。首先,针对训练文档进行人工各自标注和双人交叉审核,对有异议的标注进行讨论,形成一份较为完善的标注规范,作为后续训练集的丰富语料,完成标注语料库的构建。根据得到的标注语料库,另一部分作为训练集用于训练CRF实体识别模型,其余部分作为测试集用于测试模型效果。然后,以不同来源采集得到的数据作为目标文档,对目标文档进行过滤、分词、去停用词等预处理后,根据已有的领域词典库采用字符串匹配的方式进行初步识别,利用训练得到的CRF模型进一步对待标注文档进行识别。最后,人工完成对标注后文档审核,根据人工审核后的标注文本,及时更新领域词典,完成对CRF训练模型的迭代更新,形成指标词汇及其关系的自动标注模块。
3.3.3 基于语义的查新检索技术
传统的查新检索过程是根据文献资源的元数据特征完成底层索引库的构建,根据查新员的检索式,通过标题、摘要、关键词、主题词等从文献检索系统中获取相关文献。通过语义扩展和推理技术,借助推理规则,利用自动标注、信息抽取、关系发现等技术从目标文档中发现更细粒度的指标信息,从而完善现有的文献检索系统,将符合用户检索需求的信息传递给用户。基于语义的查新检索技术能够在传统检索系统的基础上,根据上文提出的领域词表辅助构建技术和指标词汇自动标注技术对检索词进行概念扩展、关系推理和语义匹配,实现对目标文档中隐性知识的抽取,得到更加丰富的指标、关系和属性映射,从而能够形成以指标为中心的语义检索模型,得到具有更高检索性能以及更高查全率和查准率的检索结果返回给用户。
3.4 产品服务层
根据情报服务过程与获取用户需求的先后顺序,可将情报服务产品分为被动型服务产品和主动型服务产品。被动型产品以传统的科技查新报告、检索分析报告、技术分析报告为主,是在充分了解用户真实需求的基础上,围绕查新主题展开检索分析后得到的具有结论性的分析报告。主动型产品在整个情报服务链条中将服务过程前置,通过对技术领域的主动性监测、扫描等过程实现前置性的情报服务。根据指标查新的主要特征,产品服务的类型可以包括技术演化时间轴分析、基于指标的循证检索、基于指标的知识问答等。
3.4.1 技术演化时间轴分析
通过各项指标数据的统计、关联、分析后进行可视化展示,可以发现趋势变化及各指标的关联关系。以光刻机为例,常见的描述指标有工艺节点、分辨率、投影物镜、光源波长、产率等。纵向对比各个参数值的演化趋势,可以发现企业在每一代产品革新过程中的演化特征和核心技术研发方向;横向对比各项指标,可以看出各研发企业在不同技术上的优缺点。产率是指光刻机在单位时间内可完成曝光的晶圆数量,是衡量光刻机产业化及经济效益的重要指标。图5展示了当前光刻机厂商的产率。产率最高的光刻机是ASML采用ArF光源的TWINSCAN NXT:1470光刻机,产率达到300 wph。EUV光刻机虽然在分辨率和最小工艺节点等技术指标上取得了明显的进步,但是现有的产率还停留在170 wph,未来仍有很大的发展空间。
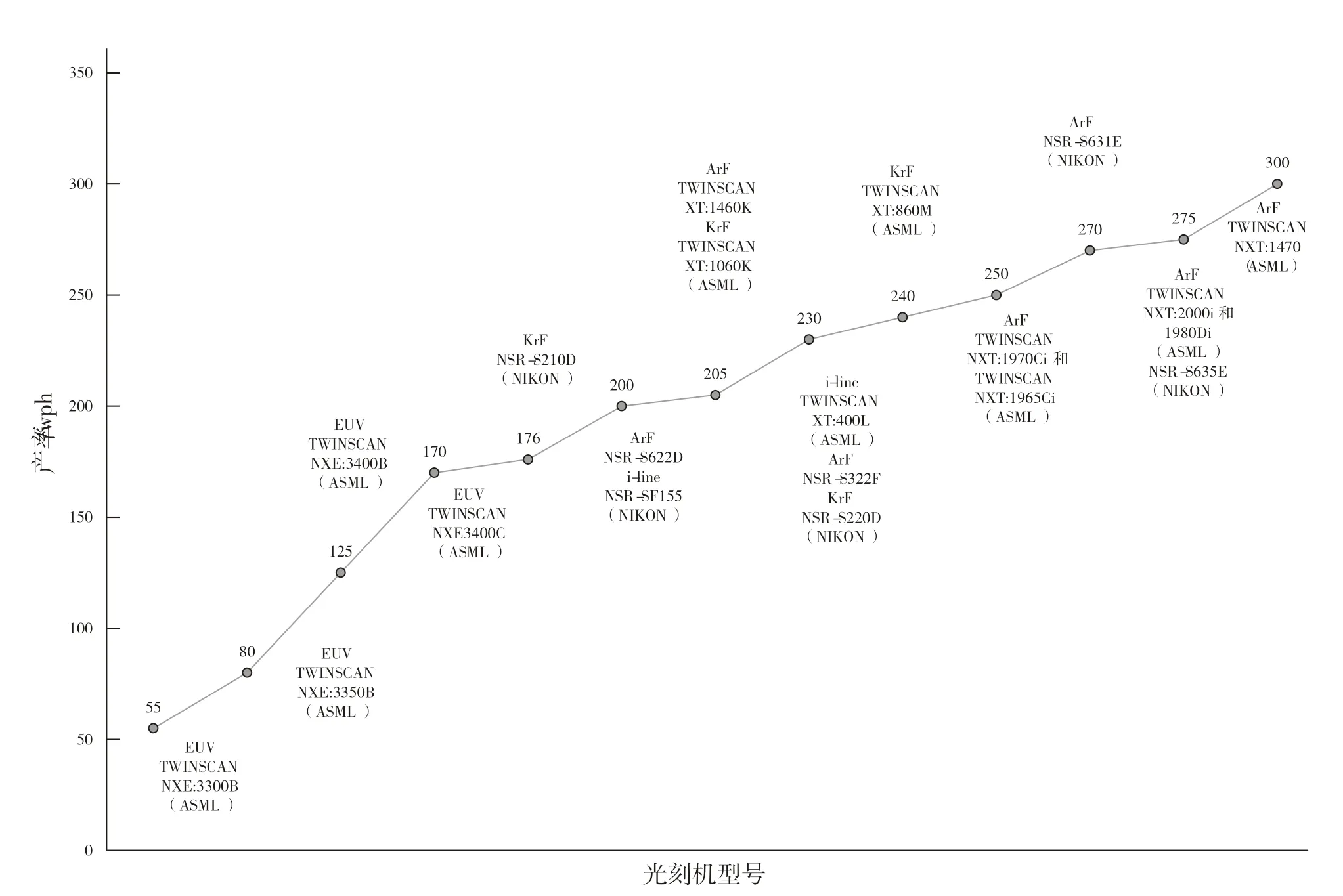
图5 光刻机产率的发展趋势
3.4.2 基于指标的循证检索
在循证研究中,一些随机对照试验的Meta分析往往被纳入循证分析的高质量证据资源。在这个过程中检索质量的高低将直接影响被纳入的证据资源是否具备全面性、客观性和真实性,并最终影响Meta分析的有效性。在一项维生素D对多囊卵巢综合征代谢及内分泌指标影响的Meta分析中[20],笔者在证据选取阶段主要以包含25羟维生素D水平、内分泌指标(胰岛素敏感性检测指数、胰岛素抵抗指数、甲状旁腺激素、空腹胰岛素、总睾酮、睾酮、脱氢异雄酮硫酸盐、代谢指标(总胆固醇、低密度脂蛋白胆固醇、甘油三酯、超敏C反应蛋白、高密度脂蛋白胆固醇、空腹血糖)等指标的文献作为Meta分析证据来源,在这类循证研究中,检索的准确性对提高证据的可靠性有着至关重要的作用。针对领域指标库中包含的指标及其链接关系,可以根据用户循证研究中对目标证据的需求,快速定位到与证据选择中所包含指标相关的目标文献,并获取与指标相关的机构、国家等相关信息,形成指标相关的语义链接网络,帮助用户发现与循证证据相关的指标及其关联关系。
3.4.3 基于指标的知识问答
基于指标数据的知识问答模块主要包含问题理解、指标数据检索和答案生成3个模块。知识问答的核心是对问题的理解,根据用户提问对问题进行分解,通过系统接口获取用户输入的问题语句,对问题语句进行预处理,获取问题语句中的疑问词和中心词,根据领域词表建立起中心词与指标名称的映射关系,并匹配相应的问题模板。随后将模板信息传送至指标数据检索模块。根据指标名称在现有的指标数据库中进行检索,借助预设的答案生成模板生成自然语言的回复语句,将检索得到的数据结果传入预先定义的答案回复模板。最后把通俗易懂的答案语句反馈给用户,并将历史问答内容存储到后台数据库,以便进一步提升问答系统的准确率。
4 结语
科技查新始于查新而不应止于查新。随着我国建设创新型国家的快速推进,对查新服务内容和服务形式都提出了更高的要求。本文基于科技查新实践,构建了基于指标检索的科技查新服务模式,涵盖了指标查新的数据资源建设、方法工具建设等多方面内容,充分发挥了查新人员、情报人员和领域专家相互融通的决策支持体系和能力,进而推动传统经验范式驱动下的查新服务向精准型、主动型查新服务转变。高质量的指标数据库是指标查新服务体系建设的核心,未来将进一步结合查新用户的实际需求,对指标查新的数据资源组织方式、指标查新分析工具和方法进行更加深入的研究,最大限度地发挥指标查新在查新工作发展转型中的积极作用。同时,努力推动以指标查新为核心的制度、标准等保障机制建设,以确保指标查新服务体系的正常运行,从而能够充分发挥科技查新工作在我国创新链条中的推动作用,为我国科技创新贡献力量。
