一类调查与二类调查森林蓄积量数据对接方案分析研究
2023-12-22白星雯布日古德
白星雯,胡 晟,布日古德,阳 帆
(1.国家林业和草原局林草调查规划院,北京 100714;2.国家林业和草原局产业发展规划院,北京 100010)
森林蓄积量是反映一个国家或地区森林资源总量和管理水平的基本指标之一,也是衡量森林生态环境优劣的重要依据[1-2]。我国主要采用一类调查和二类调查对大区域尺度上的森林蓄积量进行监测[3-4]。自1977年开始研讨一类调查体系构建,以省级行政区为总体采取系统抽样,严格控制抽样精度,5年获取一次省级行政区尺度上的森林蓄积量信息[5-7],但无法获取县(市、区)尺度区域内森林蓄积量信息[8]。二类调查以县为总体,每10年获取一次县域尺度蓄积量信息。相比一类调查而言,二类调查的优点是以图斑为调查单元,监测信息落实到图斑内,能获取县级尺度区域内蓄积量信息;缺点是多采用小班调查法获取蓄积量信息会因为人为测量因素导致较大的误差,监测精度得不到保障[9-15]。
我国一类调查与二类调查已开展多年,监测成果体量大、时间跨度长,但是两种监测体系采用的监测技术不同,因此存在森林蓄积量一个地区两套数的问题[16-20]。鉴于此,为提高监测数据成果的科学性,保障监测数据一致性,实现县(市、区)森林蓄积量与省级成果数据对接,本文进行一类调查与二类调查森林蓄积量数据对接方案分析研究,以期为历年小班监测数据更新及今后实现“一套数,一张图”提供技术方法参考,进而为全国森林资源评价及经营管理方案的制定提供更为精确详实的蓄积量监测数据。
1 基础数据
研究所应用的数据(1)国家林业局调查规划设计院.森林资源一类调查、二类调查数据.2016.包括河北省保定市行政区划界限、2016年河北省一类调查数据、2016年保定市二类调查数据。
2 研究方法
以保定市2016年二类小班调查数据(2)国家林业局调查规划设计院.森林资源一类调查、二类调查数据.2016.为基础进行树种组划分;以2016年河北省一类调查固定样地数据(3)国家林业局调查规划设计院.森林资源一类调查、二类调查数据.2016.为建模样本,分树种组构建小班蓄积量预估模型。通过所构建的模型,将蓄积量监测数据更新到小班层面,并采取平差法将小班蓄积量数据进行校正,分县(市、区)统计保定市森林蓄积量监测信息,从而实现一类调查与二类调查蓄积量监测数据的对接。
2.1 树种组划分
以保定市小班调查数据为基础,将保定市小班内现有的主要优势树种划分成落叶松组、油松组、栎组、桦木组、杨树组、硬阔组、软阔组等7个树种组,并分别树种组构建蓄积量预估模型。各树种组包含树种信息如表1所示。

表1 树种组划分信息
2.2 分树种组构建小班蓄积量预估模型
以河北省1 550个蓄积样地数据为建模样本,样地蓄积量为因变量,样地相关林分调查因子为自变量,分树种组构建小班蓄积量预估模型。根据文献资料[21-24]可知,影响林木层蓄积量的主要变量有平均树高、样地平均胸径、样地林木株数、海拔、坡度、坡向、郁闭度、平均年龄。本文选取以上8个指标作为基础变量,其中坡度与坡向两个定性指标进行组合量化。分树种组对所选取样地的平均树高、样地平均胸径、海拔、坡度坡向联合转换、郁闭度、平均年龄等变量进行显著性检验分析,即采用IBM SPSS Statistics 27数据统计分析软件计算P值。只有通过显著性检验(P<0.05)后的自变量参与模型构建。本文采用非线性指数形式进行模型构建[式(1)]。
(1)

2.3 模型评价
为保障预测目的性回归模型的拟合效果、预估精度,蓄积量预估模型选取确定系数(R2)、估计值标准差(SEE)、总体相对误差(TRE)、平均系统误差(ASE)、平均预估误差(MPE)、平均标准误差(MPSE)等6个指标进行模型评价。
R2和SEE为模型评估常用指标,R2反映模型的拟合度,SEE反映因变量离差状况;TRE和ASE,这两个统计量值越小,表示模型拟合效果越佳(为保证模型拟合效果,两个统计量应当控制在±5%以内);MPE和MPSE,这两个指标体现模型的预估精度。

(2)

(3)
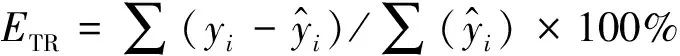
(4)
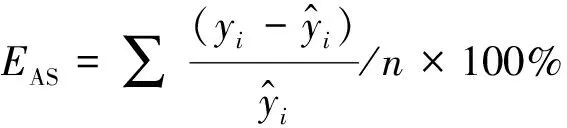
(5)

(6)

(7)
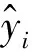
2.4 县(市、区)一体化蓄积量预估及更新
应用所构建的不同树种组小班蓄积量预估模型反演保定市内各个小班的蓄积量。分县(市、区)统计蓄积量,各县(市、区)累计后,估算出保定市总蓄积量。由于模型预估值与真值之间存在一定的误差,因此保定市蓄积量累计值与一类调查监测值之间也存在一定大小的差值。为实现两个监测体系的数据衔接,依据各县(市、区)蓄积量的权重大小对误差值进行逐级平差。平差调整计算如式(8)、式(9)所示。
(8)
(9)

3 研究结果
3.1 分树种组模型构建
3.1.1各树种组小班蓄积量预估模型变量显著性检验
对建模选取的变量进行显著性检验分析,显著性检验结果如表2所示。通过显著性检验结果可知:1)平均胸径、平均树高两个变量的P值都小于0.001,达到极显著水平。因此平均胸径、平均树高两个变量均进入蓄积预估模型。2)其它自变量参数在不同树种组模型构建中略有差异。因此构建模型时,变量选取根据显著性检验结果分树种组而定。
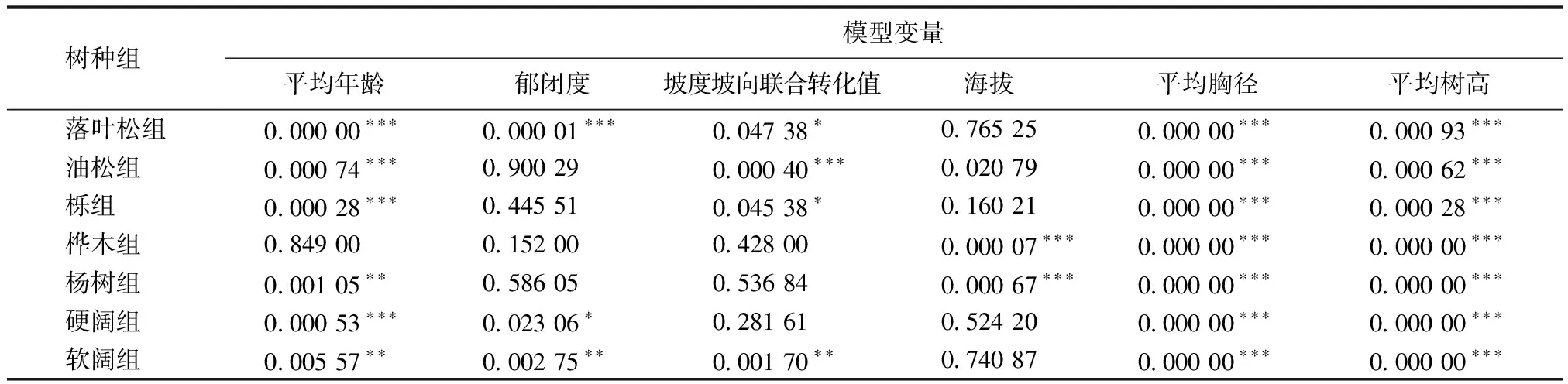
表2 各树种组模型变量显著性检验结果
3.1.2各树种组小班蓄积量预估模型构建
选取通过显著性检验(P<0.05)的相关变量参与模型研建,分树种组构建蓄积量预估模型。小班蓄积量预估模型采用式(1)进行拟合。采用式(2)—式(7)计算模型各项评价指标统计量。模型构建结果如表3所示,模型评价指标如表4所示。
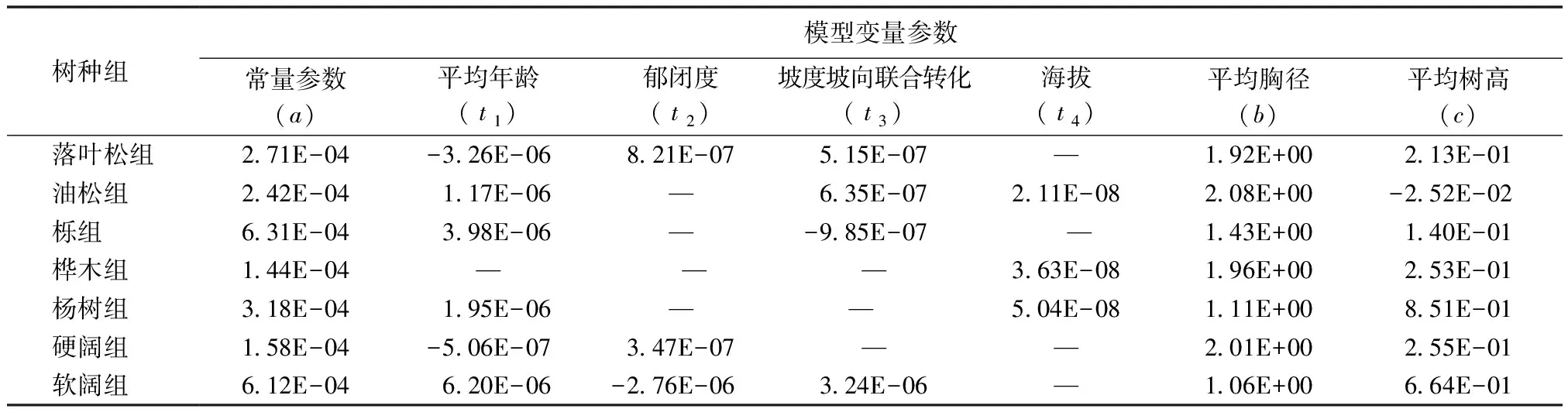
表3 各树种组蓄积量预估模型

表4 各树种组蓄积量预估模型评价指标统计
从表4可知,决定系数(R2)、估计值标准差(SEE)、总体相对误差(TRE)、平均预估误差(MPE)、平均百分比标准误差(MPSE)等5个指标表现均较好,这表明模型具有较好的预估能力。
3.2 县(市、区)一体化蓄积量预估更新
采用分树种组构建的小班蓄积量预估模型,对保定市内所有小班进行蓄积量更新,统计获取保定市各县(市、区)蓄积量模型预估值。把2016年分层抽样获取的保定市森林蓄积量预估值看作一类调查监测真值,全市单位森林蓄积量真值为38.42 m3/hm2[25]。采用式(8)、式(9)对各县(市、区)的模型预估值进行逐级平差调整,从而将二类调查数据进行更新,最终实现与一类调查数据的对接。各县(市、区)模型预估值与平差调整后蓄积监测信息如表5所示。模型预估平差调整监测、二类调查与一类调查蓄积量监测结果对比精度如表6所示。

表5 各县(市、区)蓄积量监测结果
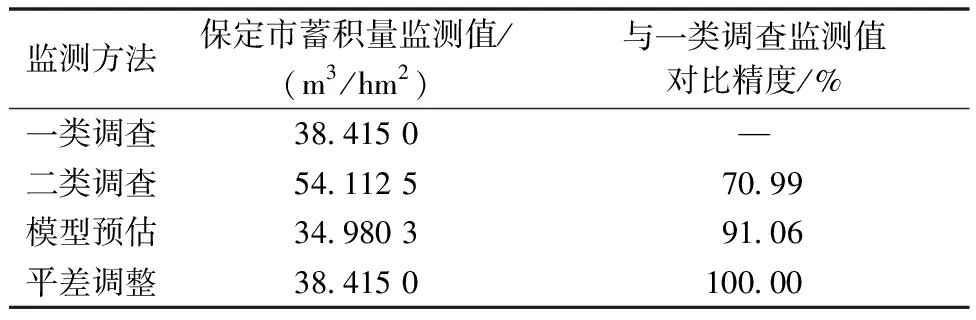
表6 各监测方法对比精度分析统计
表6显示:1)一类调查,保定市单位森林蓄积量监测值为38.42 m3/hm2;二类调查,保定市单位森林蓄积量监测值为54.11 m3/hm2,对比精度为70.99%。2)本文构建的小班蓄积量预估模型[式(1)]监测值为34.98 m3/hm2,与一类调查监测值的对比精度为91.06%。可见,通过蓄积量预估更新模型将小班蓄积量进行初步调整后,大幅度降低了二类调查与一类调查监测值之间的相对误差,也说明了本文构建的小班蓄积量预估模型[式(1)]监测结果的可靠性。3)采用平差调整法,将蓄积量预估更新模型监测值进一步进行调整。平差调整后,保定市单位森林蓄积量监测值为38.42 m3/hm2,与一类调查蓄积量监测值的对比精度为100%,实现了二类调查监测值与一类调查监测值的对接。通过本文的研究方案,能够成功获取保定市各县(市、区)尺度范围内的森林蓄积量,并可实现一类调查与二类调查成果数据的对接。
4 讨论
对于一类调查监测体系而言,通过系统布点严格把控抽样精度,其监测数据的精准性更高,但是只能获取省级区域尺度内蓄积量信息,无法监测县域尺度蓄积量信息。二类调查采用区划调查方法,其监测数据内容更为详实,监测数据落到图斑内,可以获取较小区域尺度森林蓄积量信息,但是往往因为人为调查误差,导致数据的精准性较低。因此,本文结合两个监测体系的优势开展县(市、区)森林蓄积量数据一体化更新方案研究:以一类调查为建模样本分树种组建立蓄积量预估模型,从而保证模型预估数据的准确性;用预估模型将数据落实到小班尺度上,可以更好地将小班层面详细的监测内容进行对接,从而达到一体化监测的目的。
森林资源监测一体化是多个森林资源监测体系融合的研究工作,不同监测数据的对接、各项监测因子信息的传递都是一体化监测的重点研究工作。本文仅针对蓄积信息的衔接开展一体化监测工作研究,后续的研究中,将从多个角度、多个层次出发,开展一体化监测方案的研究探讨。
5 结论
首先,采用本文所研建的小班蓄积量预估模型获取的保定市蓄积监测值与一类调查监测值的对比精度为91.06%,表明模型具有较好的预估能力及模型预估监测值的可靠性;其次,通过进行平差调整将模型预估值进一步更新调整,调整值与一类调查监测值的对比精度为100%,实现了一类调查与二类调查成果数据的对接。综上所述,表明本研究提出的一类调查与二类调查森林蓄积量数据对接方案的可行性,可为全国各省级行政区域内小班蓄积量更新调整以及实现“一套数、一张图”提供技术参考。
