智能算法模型转换工具的设计与实现
2023-12-20叶亚峰寇金桥李墈婧
叶亚峰,王 昕,寇金桥,李墈婧
(中国航天科工集团第二研究院 七〇六所,北京 100854)
0 引 言
人工智能算法模型在实际的应用场景中对算力的需求呈指数级增长,相比之下,硬件平台的发展受摩根定律的约束和限制,其性能优化的速度远远跟不上需求的增长。边缘计算(edge computing)[1,2]是一种新型的网络计算模型,它将原有依赖于服务器的计算与存储资源部署迁移到互联网的边缘,紧邻终端设备和数据采集单元,拥有更快的时间响应速率,更高的数据处理效率。边缘计算集网络、计算和存储为一体,对于低延时、高带宽、高可靠性应用场景有很大的优势。
随着国产化芯片的不断发展,出现了很多,如华为昇腾、百度昆仑、寒武纪、瑞星微等人工智能算法推理加速的边缘计算设备。相对于云端服务器,边缘计算设备存在着算力不足、数据存储量小(内存资源少、处理器性能不高、功耗受限)等缺点,为了让深度学习算法可以部署到边缘计算设备并高效运行,研究人员从不同的角度进行研究。比如轻量化网格结构[3,4],在保持模型精度,不影响其性能的基础上减少模型参数的数量和复杂度,对神经网络轻量化和小型化处理;模型压缩[5]是另一种维度,其方法包括量化、剪枝、知识蒸馏、低秩分解等[6-8]。
针对边缘计算中国产化异构智能加速硬件种类繁多,算法模型在不同硬件平台上运行环境的部署过程繁琐、上手难度大等问题,本文设计并实现了一种智能算法模型转换工具,可以将开源框架下训练的深度学习算法模型快速转换为国产化智能加速硬件平台支持的模型文件,实现算法模型快速部署和高效运行。
1 研究现状
人工智能算法的应用包括训练和推理两部分,训练框架囊括深度神经网络(deep neural networks,DNN)训练所需要的基础库和工具,深度学习框架简化了模型训练的过程,但不同的深度学习框架训练出来的模型格式各不相同。TensorFlow框架训练得到的算法模型的文件格式是.pb[9],Caffe框架训练后的算法模型的文件包括模型文件.prototxt和参数文件.caffemodel,MXNet框架训练得到的算法模型文件格式是模型参数文件.params和模型结构文件.json,PyTorch框架训练得到的算法模型文件格式是.pth等。不同硬件加速平台所支持的模型也不尽相同,比如百度昆仑芯片需要将算法模型转换为model.pdmodel/model.pdparams格式文件进行推理加速,华为昇腾芯片需要将算法模型转换为.om格式文件进行推理加速[10],国产FPGA需要将算法模型转化为.bin格式文件进行推理加速等。
针对以上问题,相关学者做了以下研究:文献[11]将基于开源框架训练的YOLO v4算法模型,通过昇腾310提供的模型转换工具-昇腾张量编译器(ascend tensor compiler,ATC),实现模型转换,将转换后的.om离线模型直接部署到昇腾310处理器上进行边缘计算,实现了电力视觉巡检;文献[12]设计并实现了一种基于Hi35XX SoC的智能处理系统,其中AI加速模块(neural network infe-rence engine,NNIE)是海思芯片专门针对神经网络特别是深度学习卷积神经网络进行加速处理的硬件单元,但NNIE配套软件仅支持Caffe框架,因此在其它深度学习框架训练的算法模型需要转化为Caffe框架支持的模型;文献[13]针对智能算法模型之间差异大导致的部署效率低的问题,设计并实现了一种基于Docker的轻量级智能算法模型部署平台,将算法模型打包为Docker镜像,并利用镜像仓库托管镜像,数据库管理模型部署信息,实验验证了其平台的可行性和高效性;文献[14]针对因算法模型和硬件平台分离使算法模型部署复杂度高的问题,设计了一种以矩阵运算为核心的神经网络加速器,与CPU结合构成了一个SoC系统,并实现了一套快速部署工具链,包括系统初始化、加速器驱动和内存管理等API,为SoC提供了软件支持,在ResNet18的测试中,能效比大大提高。
综上所述,针对不同的智能加速平台所支持的算法模型文件格式不尽相同的问题,研究学者给出了相应的解决方案,但仍存在功能单一、适配性能差的问题。本文设计并实现的智能算法模型转换工具,可以将主流算法模型转换为om文件、pdmodel/pdparams文件、bin文件等,实现在华为昇腾CANN、百度飞桨(PaddlePaddle)和国产FPGA不同硬件平台上的推理加速。
2 总体框架
智能算法模型转换工具基于QT实现界面化设计,重点针对主流的Tensorflow、Pytorch、Caffe等框架的智能算法模型进行转换,得到可以在国产嵌入式异构加速硬件平台(如华为昇腾、百度昆仑、国产FPGA等)运行的模型,从而实现算法模型在不同硬件平台下的统一化部署和推理加速。
智能算法模型转换工具的设计与实现主要包括界面设计和接口设计两部分,其中界面设计包括:硬件平台选择、参数设置、开始转换、结果显示4个模块;接口设计包括:模型转换参数传输、模型转换、结果回传3个模块。模型转换工具是开放的,留有可扩展接口,可根据实际需求进行功能扩展,其设计框架如图1所示。
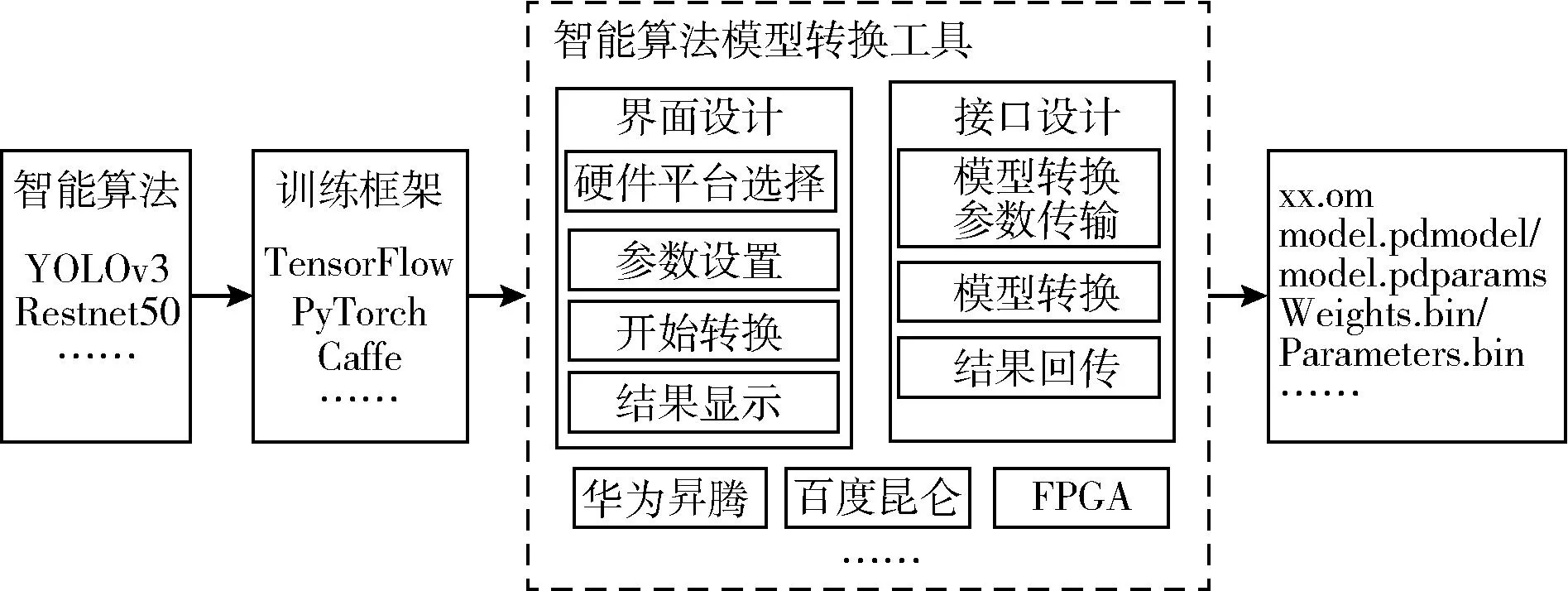
图1 智能算法模型转换工具设计框架
界面设计使用基于C++&QT开源图形框架实现,通过QT内置的槽函数机制,将界面组件(按钮、文本框、下栏菜单等)与后台功能形成映射关系,为用户提供外部接口以对软件进行操作。
接口设计中模型转换参数传输模块将用于设置的参数传输到后端,模型转换模块根据用户定义的参数基于相应异构平台模型转换程序将开源框架训练的模型文件转为目标平台支持的模型文件,通过多线程和线程交互技术实现界面交互和数据传输,将转换结果回传到界面显示。
3 技术方案
3.1 界面设计
模型转换工具的用户界面包括一个主界面和3个不同的子界面,主界面上半部分由一个选择下拉窗口和两个按钮组成,下半部分为一个文本显示框,如图2所示。“目标平台选择”按钮可通过下拉窗口选定不同的目标平台,本文设计了3个目标平台分别是华为CANN平台、百度PaddlePaddle平台和国产FPGA平台。“模型转换参数输入”按钮可以根据用户需求选择目标平台弹出对应的子窗口,供用户完成模型转换参数的设定;“开始转换”按钮可以执行模型的转换;“转换结果显示”文本框将显示模型转换的进程信息和最终的转换结果。

图2 智能算法模型转换工具界面
其具体的设计过程如下:
主界面设计如图2(a)所示,目标平台选择使用了QComboBox实现平台类型的选择;模型转换参数输入和开始转换均使用QPushButton作为按钮控件,使用时点击按钮便可触发相关功能;转换结果显示使用了QTextEdit显示模型转换过程的信息。
华为CANN平台子界面设计如图2(b)所示,输入模型路径和输出名使用QTextEdit作为显示窗口显示相关信息;输入类型、输入名、宽、高、batch_size、通道数以及输出节点信息使用QLineEdit控件以输入相关信息;模型选择和参数保存使用QPushButton按钮控件进行点击操作,使用时点击按钮便可触发相关功能;芯片类型选择则是使用QComboBox以选择对应的芯片种类。
百度PaddlePaddle平台子界面设计如图2(c)所示,输入模型路径和选择输出路径使用QTextEdit作为显示窗口显示相关信息;源模型类型使用QComboBox以选择对应的源模型种类;选择和保存使用QPushButton按钮控件进行点击操作,使用时点击按钮便可触发相关功能。
国产FPGA平台子界面设计如图2(d)所示,转换模式使用QComboBox以选择对应的转换;选择输入模型和选择输出路径使用QTextEdit作为显示窗口显示相关信息;保存使用QPushButton按钮控件进行点击操作。
3.2 模型转换参数
(1)华为昇腾平台
本文设计的华为昇腾平台模型转换功能是基于华为公司针对AI场景推出的异构计算架构体系(compute architecture for neural networks,CANN)下昇腾张量编译器(ascend tensor compiler,ATC)实现的,它可以将开源框架的网络模型转换为昇腾AI处理器支持的.om格式离线模型[15],其功能框架如图3所示,在模型转换过程中,ATC工具会将在开源深度学习框架下训练好的网络模型转化为统一中间图IR Graph,然后通过Graph Optmizer实现图准备、图拆分、图优化、图编译等操作,对原始的深度学习模型进行进一步的调优,得到离线模型.om文件,从而实现算法模型在华为平台下的快速部署、高效运行。
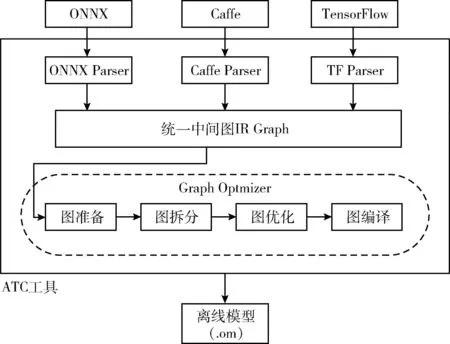
图3 华为CANN模型转换工具功能结构
1)模型转换流程
模型转换流程如下:①安装CANN软件包,获取相关路径下的ATC工具;②将准备好待转换的算法模型,保存在任意路径下;③配置模型转换参数及输出节点信息并保存;④调用编译器程序,生成华为昇腾平台支持的.om文件。
2)模型转换参数说明
模型转换参数说明如下:
输入模型路径:选择待转换的通用框架模型;
输出名:存放转换后的离线模型的路径以及文件名;
输入类型:选择模型输入数据排列方式,一般Caffe默认为NCHW,TensorFlow默认为NHWC;
芯片类型:模型转换时指定芯片版本,如昇腾310、昇腾910;
输入名:模型训练时的输入名称(字符串类型);
Batch_size:模型推理时的数据批处理量;
宽和高:设置输入图片的动态分辨率参数,用于执行推理时,每次处理图片宽和高不固定的场景;
通道数:输入图片的通道数;
输出节点信息:指定输出节点。
(2)百度飞桨平台
本文设计的百度平台模型转换功能是基于是飞桨(PaddlePaddle)生态下的模型转换工具X2 Paddle实现的,它用于将开源深度学习框架的模型迁移至飞桨框架,支持开源框架训练的模型一键转为飞桨的预测模型,并可以使用PaddleInference、PaddleLite进行CPU、GPU、NPU和ARM等设备的部署[16]。X2 Paddle支持Caffe、TensorFlow、ONNX等模型直接转化为Paddle Fluid可加载的预测模型,考虑到不同训练框架得到的模型文件API、预测方式的差异,X2 Paddle还提供三大主流框架API的差异比较,通过深入了解API实现方式降低模型迁移带来的损失,其功能结构如图4所示。

图4 百度PaddlePaddle模型转换工具功能结构
1)模型转换流程
模型转换流程如下:①安装依赖环境,导入“x2paddle.convert”模块;②准备好待转换的开源深度学习框架模型;③输入待转换模型路径和转换后的模型保存路径;④运行x2 Paddle转换工具得到model.pdmodel/model.pdparams模型文件。
2)模型转换参数说明[17]
模型转换参数说明如下:
framework:源模型类型 (TensorFlow、Caffe、onnx);
prototxt:当framework为Caffe时,该参数指定caffe模型的proto文件路径;
weight:当framework为Caffe时,该参数指定caffe模型的参数文件路径;
save_dir:指定转换后的模型保存目录路径;
model:当framework为TensorFlow/onnx时,该参数指定TensorFlow的pb模型文件或onnx模型路径;
caffe_proto(可选):由caffe.proto编译成caffe_pb2.py文件的存放路径,当存在自定义Layer时使用,默认为None。
(3)国产FPGA平台
本文设计的国产FPGA模型转换工具是基于IP2工具链实现的,它可以将代码编译过程和运行过程解耦,硬件后端只需要轻量级的运行文件,通过过程调用即可在后端实现前向推理,并完成硬件性能的自动调优,解决了主流深度学习框架不支持FPGA的问题。
国产FPGA模型转换工具包含用户模式和测试模式,其功能结构如图5所示。用户模式是给用户使用开启的,在用户模式下,onnx解析工具可以将用户模型(.onnx)文件进行解析生成和编译得到的输入文件和模型数据,编译器输入变量解析脚本,通过IP2编译器得到国产FPGA平台可以支持的权重文件Weights.bin和模型文件Parameters.bin。测试模型在对IP核进行测试的过程中使用的,在测试模式下,onnx解析工具对模型文件进行解析的同时,随机比对数据生成工具会产生测试数据和.prototxt文件,工具会自动生成golden模型,然后生成测试IP核 的比对文件。
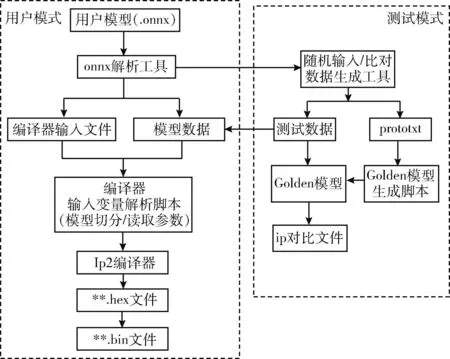
图5 国产FPGA模型转换工具功能结构
其中onnx解析过程是国产FPGA模型转换工具的核心,主要功能:通过onnx的图机制遍历模型的各个节点,获得节点的算子类型(op),可以得到该层节点的参数,各层节点参数组合成prototxt文件;通过卷积、BN(或全连接)节点的Tensor,可以得到存储的weight和bias文件,生成对应的.mat文件;通过Tensor的GetQuanParam方法可以得到各节点的量化参数信息,依次得到各节点的bias、input、output、weight这4个Tensor的位宽和小数位。
1)模型转换流程
模型转换流程如下:①onnx模型解析工具读取用户的onnx模型结构和权重(已量化),生成编译器需要的模型结构文件(.prototxt文件)、模型参数文件(.mat文件)和模型配置文件;②调用编译器程序,完成模型的.hex文件生成和.bin文件转换。
2)模型转换参数说明
模型转换参数说明如下:
转换模式:可选res18_imagenet、YOLOv3、ResNet50等模型类型;
选择输入模型:输入待转换的模型文件所在路径,一般为.onnx类型;
选择输出路径:输出转换后的模型文件。
3.3 接口设计
模型转换软件内部接口设计为该转换工具重要部分,外部接口主要基于内部接口进行封装,用于用户与软件的交互,内部接口设计包括对应平台模型转换参数传输函数设计、对应平台模型转换函数设计、模型转换结果回传函数设计。
对应平台模型转换参数传输函数set_args是对应平台模型转换参数传输接口,输入/输出数据元素包括:string modelpath、string modelname、string parameters。打开模型转换软件,手动输入对应参数,将参数在进程之间传输,输入正确的转换参数,成功后会将用户设定的转换参数,传给异构平台的模型转换或编译工具,错误返回ERROR。其局部数据元素的数据类型和数据表示形式见表1。

表1 模型转换参数传输函数局部数据元素
对应平台模型转换函数model_convert是对应平台模型转换接口,输入输出数据元素是待转换的模型和转换后对应平台的模型,手动输入对应参数后,点击模型转换按钮调用模型转换程序,成功后在指定路径下生成转换好的模型文件,错误返回ERROR。其局部数据元素的数据类型和数据表示形式见表2。

表2 对应平台模型转换函数局部数据元素
模型转换结果回传函数send_res是模型转换结果回传接口,模型转换开启后,模型转换过程中自动触发该函数,模型转换成功后在主界面“转换结果显示”窗口中输出模型转换命令行的打印信息。其局部数据元素的数据类型和数据表示形式见表3。

表3 模型转换结果回传函数局部数据元素
3.4 多线程技术
多线程技术一方面可以优化程序的设计逻辑,另一方面可以提高系统的响应速率,为了充分利用系统资源,提高系统的并行度,本文在模型转换工具的设计中引入多线程技术。在模型转换工具中,主要包括模型转换和界面程序两个任务,模型转换模块是在界面程序外部独立运行的,即模型转换过程和界面程序实际是运行在两个不同的进程中的,因此需要将模型转换进程和界面交互进程建立连接,并使其可以进行数据通信。其设计框架如图6所示。

图6 模型转换工具多线程设计框架
本文设计的模型转换工具界面包括主界面和多个子界面组成,模型转换的过程中,计算机CPU和内存占用率大,多线程技术可以保证主界面和每个子界面可以流程运行,每个模型转换模块可以在不同的线程中同时进行,这些线程互相独立,互不干扰。
在模型转换过程中,该工具会先根据需要通过主线程使用QThread建立若干个子线程,然后把用户设置好的模型转换参数和算法模型文件数据同步给子线程,在子线程中通过QProcess函数开启外部独立的模型转换进程如ATC转换进程、X2paddle转换进程、FPGA模型编译进程等,转换完成后,外部进程会将所有过程信息传回给子线程,子线程通过主线程进行结果显示。
4 实验验证
在PyTorch框架下得到训练好的ResNet50算法模型,并导出onnx格式的模型文件resnet50.onnx,通过本文设计的模型转换工具将模型分别转换为华为昇腾平台可以运行的resnet50.om模型文件,百度昆仑平台可以运行的model.pdmodel/model.pdparams模型文件以及国产FPGA平台可以运行的parameters.bin/weights.bin模型文件,验证了该工具的可行性。以舰船目标识别为例验证了模型转换工具的性能,结果显示算法模型转换前后识别精度误差不超过1%。
4.1 实验环境
本实验环境所涉及硬件、软件的名称及版本号如下:
硬件环境:飞腾D2000/8核CPU,32 GB内存,1 TB存储,麒麟V10操作系统;
软件环境:gcc 7.3.0,g++ 7.3.0,python 3.7,paddlepaddle 2.1.1,x2paddle 1.2.3,qt 5.11.2,qmake 3.11.3,Ascend-tooklit 5.0.2,国产FPGA 模型编译工具1.3.0。
4.2 模型转换
(1)华为昇腾平台
将通用框架模型resnet50.onnx放到已安装本软件且具备软件运行环境的机器上,路径无特殊要求。打开模型转换工具,在主界面选定“昇腾平台”,然后点击“模型转换参数输入”按钮,进入到该子界面,输入相应模型转换参数:输入模型路径:/root/ksbs/model_shift/resnet50.onnx、输出模型名称:resnet50、输入类型:NCHW、芯片类型:Ascend310、输入名:input、batch_size:1、通道数:3、宽:224、高:224等,然后点击“保存”按钮。在主界面点击“模型转换”按钮便可以在新的线程内,开启新的模型转换进程,此时可以通过下面的“转换结果显示”窗口查看模型转换进程的实时打印信息。当模型转换完成后,在“转换结果显示”窗口显示:“ATC run success,welcome to the next use”,便可到相应路径下找到转换完成后的模型“resnet50.om”,其转换过程如图7所示。

图7 华为CANN平台模型转换
(2)百度昆仑平台
将通用框架模型resnet50.onnx放到已安装本软件且具备软件运行环境的机器上,路径无特殊要求。打开模型转换工具,在主界面选定“百度平台”,然后点击“模型转换参数输入”按钮,进入到该子界面,输入相应模型转换参数:输入模型路径:/root/ksbs/model_shift/resnet50.onnx,选择输出路径:/root/projects/resnet/interence_model,源模型类型:onnx,然后点击“保存”按钮。在主界面点击“模型转换”按钮便可以在新的线程内,开启新的模型转换进程,此时可以通过下面的“转换结果显示”窗口查看模型转换进程的实时打印信息。当模型转换完成后,在“转换结果显示”窗口显示:“Exporting inference model from python code”,便可到相应路径下找到转换完成后的模型“model.pdmodel”和“model.pdparam”,其转换过程如图8所示。

图8 百度PaddlePaddle平台模型转换
(3)国产FPGA平台
将通用框架模型yolov3.onnx放到已安装本软件且具备软件运行环境的机器上,路径无特殊要求。打开模型转换工具,在主界面选定“FPGA平台”,然后点击“模型转换参数输入”按钮,进入到该子界面,输入相应模型转换参数:转换模式:res50_imagenet,选择输入模型:/root/ksbs/model/resnet50.onnx,选择输出路径:/root/ksbs/mo-del,然后点击“保存”按钮。在主界面点击“模型转换”按钮便可以在新的线程内,开启新的模型转换进程,此时可以通过下面的“转换结果显示”窗口查看模型转换进程的实时打印信息。当模型转换完成后,在“转换结果显示”窗口显示:“Generate output/Weights.bin”和“Generate output/Parameters.bin”,便可到相应路径下找到转换完成后的模型“Weights.bin”和“Parameters.bin”,其转换过程如图9所示。

图9 国产FPGA模型转换
4.3 精度误差
以舰船目标识别为例,测试集收集包括舰船、舰体、舰岛等目标的测试集1350张。
将基于Pytorch框架训练好的模型ResNet50.pt保存到x86服务器的指定路径下,并将测试集数据放到同级目录,启动模型精度测试程序,加载保存的模型和测试集数据并执行推理,运行结果如图10(a)所示,识别准确率约为93.48%。

图10 模型转换前后识别精度对比
将ResNet50.pt模型导出为ResNet50.onnx模型并拷贝到已安装模型转换工具的国产设备上,启动模型转换工具,加载ResNet50.onnx模型文件并输入转换参数,转换为ResNet50.om模型,并将其部署到Atlas 200DK推理加速设备的指定路径下,同时将测试数据集放到同级目录下,启动Atlas 200DK上的模型精度测试程序并执行推理,加载保存的模型和测试集数据,运行结果如图10(b)所示,识别准确率约为92.52%,从而计算出模型部署前后精度误差约为0.96%。
5 结束语
针对智能算法异构加速硬件的多元化带来的模型应用与转换过程繁琐、冗余的问题,本文设计并实现了一种智能算法模型转换工具,该工具可以将开源框架下训练的智能算法模型一键转换为不同硬件加速平台支持的模型文件,使得智能算法模型转换功能集成化和统一化。
其主要创新点和贡献如下:
(1)该工具内嵌华为CANN平台ATC转换工具、百度PaddlePaddle平台X2 Paddle转换工具以及自研国产FPGA平台转换工具,可以将resnet50.onnx/yolov3.onnx模型文件转换为om文件、pdmodel/pdparams文件、bin文件,在不同硬件平台上实现智能算法推理加速,且功能可扩展,支持多种异构加速平台;
(2)该工具基于QT开源图形框架实现的界面化设计,并在基础的模型转换工具上进行上层封装,为用户提供简便直接的操作和交互方式,使得模型转换操作简单易懂,无上手门槛。同时可以支持YOLOv3、ResNet50、VGG16等多种智能算法模型和参数设置,多线程和进程通信技术支持多种模型同时转换,互不干扰,保证了工具的流畅运行。
由于时间原因本文研发的模型转换工具只涉及到常见的几种硬件加速平台、主流的深度学习框架和算法模型,对于其它设备和算法模型仍需要适配和验证;本文分别通过模型转换和目标识别算法测试了该工具的有效性和误差精度,其鲁棒性和兼容性也是下一步的工作重点。
