基于图卷积网络的多交互注意方面级情感分析
2023-12-20武伟宁杨长春顾晓清严鑫杰马甜甜
贾 音,武伟宁,杨长春,顾晓清,严鑫杰,马甜甜
(常州大学 计算机与人工智能学院 阿里云大数据学院 软件学院,江苏 常州 213164)
0 引 言
方面级情感分析作为情感分析领域的子任务,旨在根据上下文识别句子中的方面项以及特定方面的情感极性(如积极、消极或中性)[1]。举例来说,对于一个句子“a group of friendly staff,the pizza is not bad,but the beef cubes are not worth the money!”,包含3个方面词分别是staff,pizza和beef cubes,对应的意见词分别为friendly,not bad,not worth,其情感极性分别为积极、中立和消极。特定方面的反馈,能够给人们提供有针对性的见解,帮助人们更准确地了解某个事物的具体信息。相比较于粗粒度的情感分析,方面级情感分析更具有研究意义和应用价值。
目前主要利用深度学习的方法进行方面级情感分析研究,但仍存在着提取语义句法信息不全面的问题:基于注意力机制的方法,大多只关注方面词与上下文词之间的语义关联,忽略了句法交互对情感分类结果的影响;而基于图卷积网络的方法仅提取句法信息而忽略了深层语义信息,且未能考虑句法相对距离,使得距离方面词较远的关键信息的权重被削弱。
针对上述问题,本文提出了一种基于图卷积网络的多交互注意(multi-interactive attention based on graph convolution network,MIA-GCN)模型。利用图卷积网络能够更有效提取深层特征信息的优点[2],基于注意力机制和句法相对距离重构语义和句法图邻接矩阵,更全面地提取语义和句法信息。除此之外,设计语义交互和句法交互,同时关注方面词与上下文词之间的语义关联和句法关联,最终进行特征融合。
1 相关研究
以神经网络为代表的深度学习具有良好的自动提取特征的能力[3],因此在方面级情感分析领域受到广大学者的欢迎。由于句子本身可以看作一个前后有关联的序列,循环神经网络(recurrent neural network,RNN)及其变体长短时记忆网络(long-short term memory,LSTM)作为最基本的神经网络方法,得到了广泛的应用[4]。基于注意力的方法通过进行方面词与上下文词的向量运算,以计算结果来反映单词之间的关联程度,从而给予与方面词语义相关性强的单词更高的权重来判断情感极性。因此,大多研究者将神经网络与注意力机制结合来提取语义信息,并挖掘与方面词语义上最相关的意见词。Tay等[5]将方面向量与上下文向量相连接来模拟方面词与上下文词的相似性,并利用注意力机制自适应地关注给定方面词的关联词。Chen等[6]提出了一种基于目标的注意力模型用于方面级情感分析。对上下文信息进行位置编码,在位置感知上下文矩阵之间以联合的方式计算上下文与方面词之间的注意力得分,并进行向量化,使得模型更具鲁棒性。Zhuang等[7]基于记忆旋转单元提取长期语义信息,并引入分层多头注意机制在计算注意权重时保留方面语义信息,最终实现方面词与关键词之间的交互。虽然这些基于注意力机制的方法取得了一定的成果,但是基本上是建立在语义关联上,注意力机制可能会关注到与方面词句法上不相关的意见词,造成情感极性判断错误。近年来,图卷积神经网络(graph convolutional network,GCN)由于其良好的处理非结构化数据的特点,被应用于方面级情感分析中提取句法信息。Liang等[8]构建方向图卷积网络将单词间的依赖关系整合到模型中,学习关键方面词的依赖特征和不同方面之间的情感关系。Pang等[9]提出一种动态多通道图卷积网络模型。分别利用依赖树和多头注意生成句法图和语义图来提取句法信息和语义信息,并将提取到的信息进行组合、优化和融合,使得性能得到了进一步提升。
2 方面级情感分析模型
本文提出的MIA-GCN模型从句法相对距离和语义关联强弱角度,结合图卷积网络,能够更加充分地学习语义及句法特征信息。并且可以增加交互注意层处理方面词与上下文词的语义和句法依存信息,进行特征融合。框架如图1所示,分别是嵌入层、Bi-LSTM层、图卷积网络层、方面掩码层、交互注意层以及输出层。
2.1 嵌入层
为了能够充分获取语义和句法特征信息,在处理文本时,首先需要进行文本向量化。文本向量化最常用的一种方式是词嵌入,即将每个单词通过嵌入矩阵的形式映射到向量空间中,使得句子中的每个单词转化为固定维度的词向量表示。本文利用预先训练好的词嵌入矩阵Glove来初始化单词向量。对于长度为n的句子,经过词嵌入后表示为:W∈Rdw×n, 其中dw表示词嵌入向量的维数。除此之外,由于同一个词因为其词性的不同在不同语境中有多种多样的表示,因此,考虑不同词性对方面级情感分析的影响是有必要的。受到Zhao等[10]工作的启发,将词性种类N设为4类,分别为形容词、动词、副词、其它,最终得到词性嵌入矩阵为P∈Rdp×|N|, 其中,dp为词性嵌入的维度。将词嵌入与词性嵌入连接起来,得到嵌入层的最终词向量表示为X={x1,x2,…,xn}, 其中xi∈Rdw+dp。
2.2 Bi-LSTM层
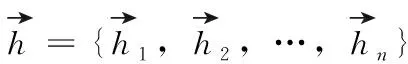
2.3 图卷积网络层
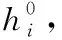
(1)
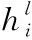
本文提出的MIA-GCN模型中的图卷积网络层包括语义图卷积模块和句法图卷积模块两个对称的网络,分别用来提取语义特征和句法特征,也是整个MIA-GCN模型的核心。对于语义图卷积模块,利用注意力机制构造注意得分矩阵;对于句法图卷积模块,根据句法相对距离构造句法权重矩阵以存储更多的句法信息。最后,将两个矩阵分别送入图卷积中进行语义和句法信息的学习。
2.3.1 语义图卷积模块
对于句法信息不敏感的句子,其语义信息对情感极性的判断影响比较大。因此,获取语义信息是有必要的。MIA-GCN模型考虑基于语义关联提取深层次语义信息。由注意力机制得到的注意得分矩阵能够反映句子中两个单词之间的语义相关性信息,对于提取语义信息有重要的作用。注意得分矩阵可表示为式(2)
(2)
式中:矩阵Q和K为前一层的图向量表示,WQ和WK为可学习的权重矩阵,d为输入节点特征的维数。其构造过程如图2所示。
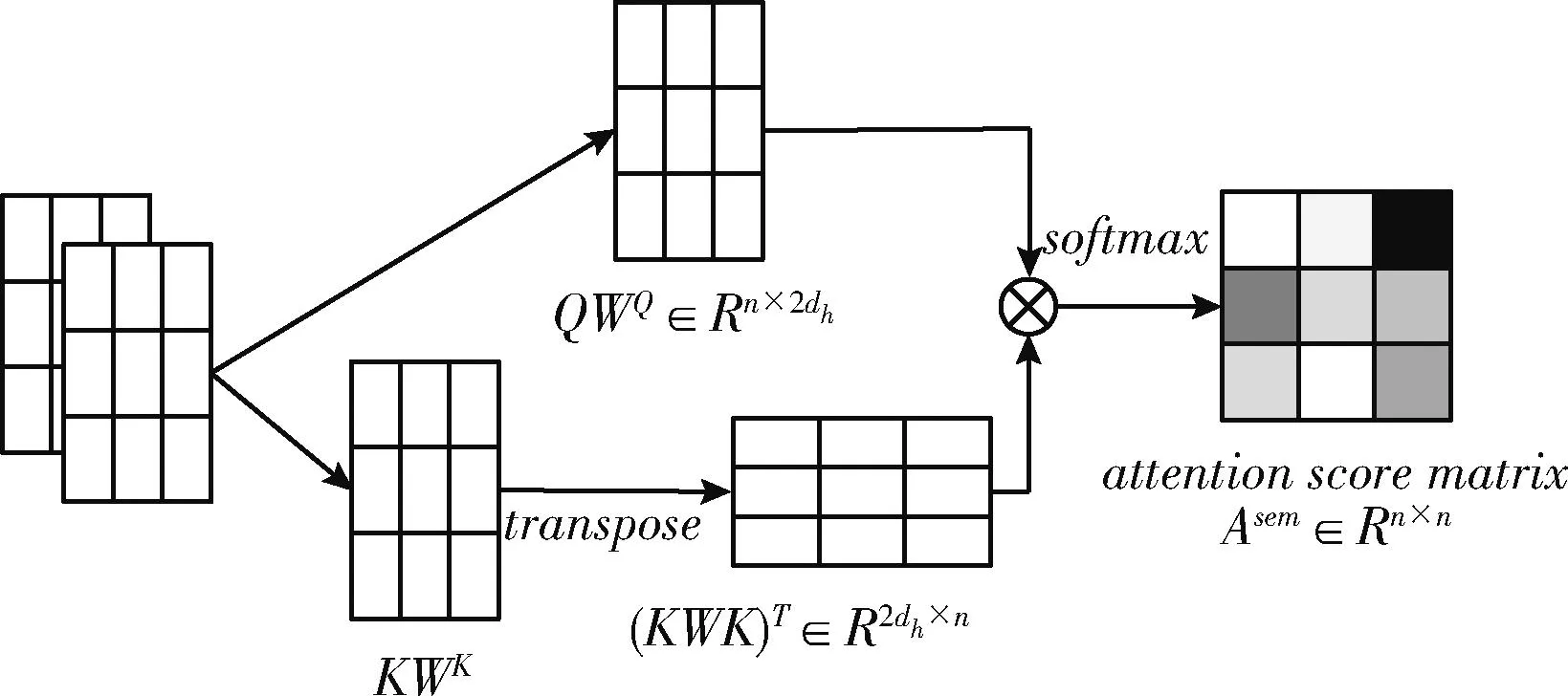
图2 注意得分矩阵构造过程
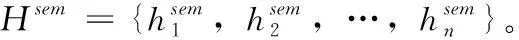
2.3.2 句法图卷积模块
以往基于句法的方面级情感分类模型中,通过依存句法分析树分析句子中单词之间的句法依赖关系,结合图卷积网络聚合相邻节点信息的优点,使得模型能够提取句法特征信息。本文延续使用这种方法,利用依存句法分析器SpaCy构造句法依赖树,并将句法依赖树以图结构的形式表示。以节点代表句子中的单词,边代表单词之间的依赖关系,得到邻接矩阵形式的句法依赖图,其中邻接矩阵D∈Rn×n, 矩阵D中的元素表示为式(3)
(3)
如果将上述矩阵D作为图卷积网络的邻接矩阵,则会忽略未直接相连的两个单词之间可能存在的联系。若关键意见词与方面词距离较远,就会导致其传播到方面词时,相对于方面词的权重被削弱了,从而导致情感极性判断错误。
因此,基于Phan等[13]提出的句法相对距离(syntactic relative distance,SRD),本文提出的MIA-GCN模型对句子中距离方面词不同句法距离的单词赋予不同的权重,来代表不同单词相对于方面词的重要性。在邻接矩阵D的基础上,首先计算除方面词a外的所有单词到a的SRD。SRD在句法依赖树中表示两个单词对应的节点之间的最短距离,在邻接矩阵中只需计算两个顶点之间的最短路径。以图3中(a)所构造的依赖关系为例,方面词为节点2和节点3,需要计算节点1,节点4,节点5分别到2,3之间的距离,并转化为图3中(b)的形式。

图3 句法权重矩阵构造过程
基于SRD,计算句法权重矩阵Asyn代替邻接矩阵D,Asyn的计算为式(4)
(4)
式中:p为设定阈值,Asyn∈Rn×n, 图3中(c)为n=5,p=2的句子构建的句法权重矩阵。通过构建句法权重矩阵来代替离散邻接矩阵,使得与方面词句法距离近的上下文词有较大的权重且削弱句法距离远的上下文信息。
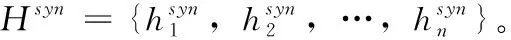
2.4 方面掩码层
(5)
(6)
由此可以得到提取到的语义特征的方面掩码向量hsemmask={0,…,ht+1sem,…,ht+msem,…,0} 和句法特征的方面掩码向量hsynmask={0,…,ht+1syn,…,ht+msyn,…,0}。
2.5 多交互注意层
为了同时关注方面词与上下文单词之间的语义关联和句法关联,通过计算上下文的隐藏向量与方面向量之间的语义及句法相关性,为每个上下文词分配相关的注意力权重,以完成方面与上下文的协调优化,便于下一步进行特征融合。
(7)
(8)
(9)
(10)
(11)
(12)
2.6 情感输出层
为了实现语义特征信息和句法特征信息的融合,将交互层得到的语义交互特征向量hsem与句法交互特征向量hsyn进行拼接,得到融合语义与句法的特征向量hf=[hsyn;hsem]。 将获得的最终表示hf输入到全连接层,最后通过softmax进行分类输出,即式(13)
(13)
式中:c为情感标签的维数即分类数,Wo和bo分别为权重参数和偏置项。模型的损失函数采用交叉熵损失函数,利用标准梯度下降法进行训练,如式(14)所示
(14)

3 实验与分析
3.1 实验数据与实验平台
实验在公开数据集SemEval 2014 task4的Restaurant数据集、Laptop数据集以及短文本数据集Twitter上进行,评估MIA-GCN模型的性能。这些数据集都分为训练集和测试集,且都是3分类的(积极、中性、消极)。除此之外,采用以往方面级情感分析的数据预处理方法,去除情感极性冲突的样本和没有明确方面词的样本,使得每条数据都包含一个或多个方面。数据集统计情况见表1。
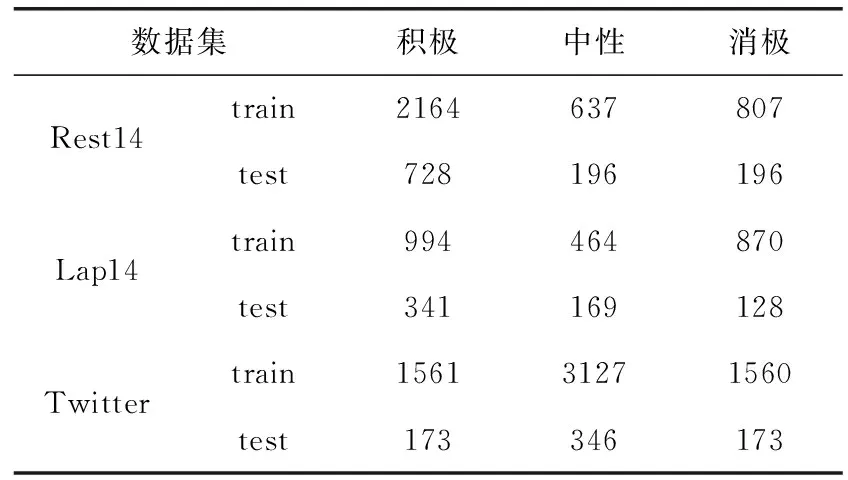
表1 数据集统计
本文的实验平台见表2。
3.2 实验设置与评价指标
为了保证对比实验公平,模型使用300维的Glove词向量初始化单词嵌入,模型中的权重采用均匀分布进行初始化。在对比实验中,计算句法权重矩阵时的阈值p设置为2,除此之外,模型利用dropout防止过拟合,同时采用early stop防止精度衰减。模型的超参数设置见表3。
MIA-GCN模型采用准确率(Accuracy,Acc)与宏平均F1值(macro average F1,MF1)作为评价指标。Acc是相关研究中最常用的评估指标,而MF1值是综合考虑了模型准确率和召回率的计算结果,为所有类别F1的平均值。在衡量模型性能时,Acc与MF1的值越大,模型性能越好。Acc与MF1计算公式如式(15)~式(17)所示

表2 实验环境

表3 超参数设置
(15)
(16)
(17)
其中,TP(true positive)为预测为正的正样本;FP(false positive)为预测为负的正样本;TN(true negative)为预测为正的负样本;FN(false negative)为预测为负的正样本;precision为精确率;recall为召回率。
3.3 对比实验
为了验证MIA-GCN模型的性能,本文使用以下模型作为对比模型:
(1)ATAE-LSTM[14]:基于注意力的LSTM的方面级情感分类方法。将方面向量嵌入到词向量和隐藏向量中,使得方面信息参与注意权重的计算。
(2)MemNet[15]:一种结合注意力机制的深度记忆网络模型。通过构建多个计算层,通过每个计算中层中的注意层自适应地选择更深层次的信息并捕获每个上下文词与方面之间的相关性,最后一个注意层的输出来进行情感极性判断。
(3)IAN[16]:将方面词与语境分离出来,并利用两个注意力网络交互方面词与上下文之间的关系,分别生成它们的表示。最后,连接两个表示来预测方面词在语境中的情感极性。
(4)AOA[17]:对方面和文本同时进行建模,生成的方面表示和文本表示通过注意力模块相互作用,学习其表示形式,自动关注方面和文本中最重要的部分。
(5)MGAN[18]:利用粗粒度和细粒度的注意机制提取嵌入信息并进行方面和句子之间的词语级交互。
(6)ASGCN[19]:在句子的依赖树上建立一个图卷积网络进行句法信息的提取,将掩码后的方面向量与语义信息进行注意交互,提高了情感分类性能。
(7)Bi-GCN[20]:针对利用句法结构的方法会忽略词语共现信息和不同句法依赖类型对结果有重要影响的问题,分别构造词法图和句法图,并进行交互和聚合。
(8)kumaGCN[21]:将句法依赖树和自动生成的特定类型图联系起来,动态地组合词依赖图和自注意力网络学习的潜在图的信息。
(9)AGGCN[22]:提出了一种方面门控图卷积网络模型。设计方面门控LSTM以生成特定方面信息,并在此基础上形成依赖树构建GCN,以充分利用句法信息和长距离依赖。
(10)AFGCN[23]:构建了一个句法依赖模块以集成句法相对依赖位置图,并结合注意力机制捕获与方面语义相关的突出特征,最终形成融合语义和句法特征的向量表示。

表4 不同模型的实验结果
表4为基准模型与本文模型的对比实验结果,表格内结果均为重复3次的实验结果的平均值。其中,加粗数据表示其对应数据集中效果最好的模型的数值。对表中实验结果进行分析,可以得到以下结论:
(1)基于注意力机制的模型(ATAE-LSTM、MemNet、IAN、AOA、MGAN):从表4中可以看出,利用交互注意力机制的IAN、AOA及MGAN模型整体上优于传统非交互注意的ATAE-LSTM、MemNet模型,且都实现了方面词与上下文之间的信息交互,从而获取语义信息。这表明在进行方面级情感分析时,方面词与上下文词之间的交互有利于提高分类性能。
(2)基于图卷积网络的模型(ASGCN、Bi-GCN、kumaGCN、AGGCN、AFGCN):与基于注意力机制的方法比较,基于图卷积网络的方法在数据集Rest14和Lap14上的性能均有明显的提升。这表明利用句法知识建立单词之间的句法依赖关系,确实有利于方面级的情感分析研究。但也存在一些问题:例如对于Twitter这种口语化评论数据集,基于图卷积网络的方法ASGCN、kumaGCN并没有基于注意力机制的方法MGAN的效果好。这可能是由于基于图卷积网络的方法未能充分考虑语义信息,忽略了方面词与上下文单词的语义相关性,因此,在考虑结构复杂或者非正式化的句子时,只考虑句法信息进行情感分析研究并没有基于语义关联的注意力机制的方法性能好。
(3)基于图卷积网络的多交互注意模型(MIA-GCN):相较于基于注意力机制的模型和基于图卷积网络的模型,本文提出的MIA-GCN模型的准确率Acc和MF1值均得到了明显的提升。在3个数据集上的准确率分别可以达到82.85%、77.78%和75.14%;MF1值可达到75.44%、73.85%、73.92%。MIA-GCN与基于注意力机制的模型相比,在3个数据集上的Acc值平均提高3.24%、5.85%、3.34%,MF1平均提升5.61%、6.55%、4.37%。由此可见,MIA-GCN模型在Lap14数据集上提升最好。这可能是因为Lap14对于句法信息更敏感,而MIA-GCN相比较于基于注意力机制的模型多考虑了句法信息;与基于句法信息的图神经网络的模型相比,在3个数据集上Acc值平均提升0.64%、1.97%、1.72%,MF1值平均提升2.11%、1.91%、1.93%。其中,MIA-GCN相对于模型AFGCN在Lap14数据集上效果相当。在Rest14数据集上,MIA-GCN的准确率略低于模型AGGCN,这可能是因为Rest14数据集对于特定方面信息比较敏感,而AFGCN从一开始就利用门控LSTM编码特定方面信息。综合而言,MIA-GCN模型在实验数据集上获得了比较好的性能,对不同领域的文本也可以处理得很好。主要原因在于MIA-GCN模型同时考虑了深层语义和句法信息。利用GCN来提取和学习评论中的语义信息与句法信息,并且对方面进行建模,利用交互注意力进行方面词与上下文词的语义和句法交互,增强了提取与方面词有紧密联系的上下文情感信息的能力。因此,模型MIA-GCN能够实现情感分类任务性能的提升。
3.4 消融实验
为了验证模型的有效性以及各个部分对情感分类结果的影响,设计消融实验在3个数据集上进行对比分析,结果见表5。其中,SynGCN表示只构造句法图卷积网络及句法交互;SemGCN表示只利用语义图卷积网络及语义交互;SynGCN_dep代表仅利用依赖解析器的0-1输出作为图卷积网络的矩阵而不利用句法相对距离进行计算权重;MIA-GCN w/o inatt表示去除交互注意层,同样的,MIA-GCN w/o syn或者sem表示只去除句法交互或者只去除语义交互。
从表5对比结果可以看出,在Rest14和Lap14数据集上,SynGCN的性能明显优于SynGCN_dep,因此,利用句法权重矩阵代替离散矩阵,可以获取更多的句法信息,有效提升情感分类的性能。SemGCN模型在Twitter数据集上的性能优于SynGCN,这是由于Twitter评论数据集大多是口语化和非正式的,对句法信息不敏感,因此对于这类语句,语义信息对性能的影响大于句法信息对性能的影响。除此之外,MIA-GCN w/o inatt相比MIA-GCN性能有所下降,原因是去除了交互注意层,方面词与上下文词之间不能进行交互注意,从而表明利用交互注意可以建模方面词与上下文词的语义关系和句法关系。对比MIA-GCN w/o syn和MIA-GCN w/o sem,去掉任何一种交互方式,与MIA-GCN相比,Acc和MF1值均下降,验证了语义交互注意和句法交互注意两者的重要性。

表5 消融实验
3.5 案例研究
为了进一步分析本文提出的模型对比其它模型的优点,通过几个具体的样例来分析。如表6所示,提取出一些典型样例的分类结果进行对比分析。其中数值negative、natu-ral、positive分别表示情感极性为消极、正常、积极。句子中阴影部分为所在句子的方面项。

表6 典型数据实验样例
对于第一个例句,由于存在两个方面词即“food”和“service”,基于语义关联的注意力机制模型ATAE-LSTM会关注到与方面词“service”相关的意见词“dreadful”,将其作为方面词“food”的意见词,导致方面词与意见词的错误匹配,从而判断情感极性为消极。第二个例句,“apple os”与其意见词“happy”的句法距离相距太远,基于句法信息的图卷积网络模型ASGCN未能捕获两者之间的关系,因此,ASGCN模型情感极性判断错误。第三个例句中,由于含有两个方面项,ATAE-LSTM未能准确匹配方面项与意见词,ASGCN模型未能捕获否定词“did not”的特征表示,而MIA-GCN可以结合语义关联和句法关联做出正确的判断。
除此之外,选取句子进行注意力可视化分析,如图4所示。其中,颜色越深,表示注意权重越大。从图中可以看出,对于方面词“staff”,在交互注意层使用语义交互还是句法交互都能关注到情感词“should be a bit”,因此,语义交互与句法交互都有助于情感极性的判断,也验证了语义信息和句法信息对于方面级情感分析的有效性。

图4 方面词“staff”注意力可视化
4 结束语
本文提出了一种基于图卷积网络的多交互模型MIA-GCN来解决目前方面级情感分析研究中存在的提取语义和句法信息不全面导致的情感分类不准确的问题。MIA-GCN的主要创新点在于分别重构了语义图和句法图提取语义和句法特征信息,并利用交互注意建模方面词与上下文之间的语义和句法关系,使得提取信息更加全面。在常用的3个方面级情感分类数据集上进行对比实验、消融实验以及案例分析。实验结果表明,本文提出的MIA-GCN模型的性能具有一定的提升。验证了带权重的邻接矩阵可以存储更具体的信息,而交互注意能够建模方面词与上下文词的语义关系和句法关系,完成方面与上下文的协调优化。下一步工作将与更先进的预训练模型BERT进行结合,探索更具有适应性的融合语义和句法特征的方法。
