基于异质图注意力网络的重叠社区发现方法
2023-12-20赵宇红
孙 悦,赵宇红,薛 婷
(内蒙古科技大学 信息工程学院,内蒙古 包头 014010)
0 引 言
社区发现是将网络中的相似节点聚成一个社区,且同一社区内的节点连接紧密[1]。早期,学者把网络中的节点和边都为同一类型的网络称为同质网络,并提出基于图分割算法,基于模块度优化算法[2]等社区发现方法。但现实世界中多为异质网络,即节点和边是多种类型。同质网络社区发现方法适用于异质网络,但社区划分准确率较低。随着研究的深入,研究者发现真实网络中的社区存在重叠现象,即一个节点属于多个社区。而异质网络中的重叠社区发现尚在起步阶段,具有较大的研究空间。学者将SLPA算法[3]进行改进提出异质网络重叠社区发现算法NELPA[4]。研究表明图神经网络(GNN)可以充分提取网络中的各种信息,但传统的GNN不能利用异质网络不同的语义信息。本文基于GNN提出HAOCD(heterogeneous graph attention of overlapping community discovery)模型解决异质网络中重叠社区发现问题,其中贡献有以下几点:①结合异质网络多种元路径的结构和属性信息构建异质网络的节点特征表示;②改变基于GNN的异质图注意网络(HAN)[5]中语义级注意的激活函数,解决梯度消失问题,并生成新的节点特征向量,更好利用异质网络丰富语义信息;③通过图卷积神经网络[6](graph convolutional neural networks,GCN)生成社区隶属矩阵,并将Bernoulli-Poisson(B-P)模型的负对数似然函数作为损失函数优化社区重叠度,并通过社区划分的阈值得到最终异质网络重叠社区划分结果。
1 相关工作
1.1 图神经网络
图神经网络(GNN)的概念由Gori等提出,并由Scarselli等进一步阐明[7],它具有对图数据之间依赖关系进行建模的强大功能,并且可以对图数据进行特征提取和表示[8],可以用于节点分类、链路预测、社区发现等数据挖掘领域。
Bruna等基于谱图论(spectral graph theory)提出了GCN。GCN与卷积神经网络(CNN)本质上是一致的,都是将邻域信息进行聚合计算。不同点是CNN处理的是以像素点排列成的欧几里德结构的数据,而GCN处理的是由节点和边构成的非欧几里德结构的数据[9],例如社交网络、引文网络等。
1.2 注意力机制
注意力机制在计算机各个领域都有大量的应用,包括机器翻译、自然语言处理、图像识别等领域。例如在机器翻译领域,学者们发现上下文单词对目标单词的影响力不同,引入注意力模型(attention model,AM)可以得到不同单词相对目标单词的权重信息,来提高翻译的准确性。通过注意力机制可以学习到不同信息的权重,更好利用影响力高的信息。注意力机制具有不同的类型包括自注意力、多头注意力、硬注意力和软注意力、全局注意力和局部注意力等机制[10]。
随着图神经网络的提出,许多研究者将注意力机制与图神经网络结合并应用到各个领域中,并且相对传统算法都有良好的表现。注意力机制结合图神经网络有多种形式应用,包括聚合特征信息时向不同近邻分配注意力权重,根据注意力权重集成多个模型,以及使用注意力权重引导随机游走等。图注意力网络(GAT)[11]是将GCN与注意力机制进行结合,根据不同邻居节点特征对节点的影响力不同的特点,通过注意力机制得到不同邻居节点的权重,充分利用影响力高的邻居节点的特征聚合该节点的特征信息。
1.3 B-P模型
B-P模型是一种允许重叠社区的图生成模型,通过B-P模型可以优化重叠社区发现结果。Mingyuan Zhou[12]提出的边缘划分模型(edge partition model)中首先提出了泊松因子模型。为了将提出的泊松因子模型用于具有二进制邻接矩阵的非加权网络,研究者提出了伯努利-泊松链(BerPo Link)。
伯努利-泊松链可以衡量不同节点与多个社区的关系,所以可以用于重叠社区发现。Shchur O等[13]基于伯努利-泊松链提出可用于重叠社区发现的B-P模型,其公式如式(1)所示
(1)
式中:Auv∈N×N是节点的邻接矩阵;是社区隶属矩阵。Fu是F的行向量。从公式可以看出点积越高,即节点u和节点v共有的社区越多,节点u,v越有可能通过边连接。
同样,Adrien等[14]提出可用于重叠社区的马尔科夫链蒙特卡洛(Markov chain Monte Carlo)模型也应用了B-P模型,得到单个节点对每个社区从属程度的权重信息。
2 HAOCD算法
2.1 相关概念
定义1 异质网络:给定属性网络G(V,E,S,R), 其中V={v1,v2,…,vn} 是n个节点集合;E是边集,且|E|=m,m为总边数;S为节点类型的集合;R为边类型的集合。当网络中节点类型满足 |S|>1或关系类型满足 |R|>1时,称这样的网络为异质网络。
定义2 重叠社区:将图划分为k个社区,将其定义为C={c1,c2,…,ck}。 若节点i∈c1且i∈c2, 即存在一个节点属于多个社区。直观的解释是,一个作者可以在多个领域发表论文,一篇论文也可以同时属于多个领域。


2.2 HAOCD算法的基本思想
本文提出基于异质图注意力网络的重叠社区发现方法HAOCD模型,先构建异质网络架构,结合结构信息和属性信息将不同类型的节点和特征嵌入到统一的特征空间,使图神经网络适用于异质网络。然后基于异质图注意力网络,利用双层注意力机制捕捉节点级的重要性和语义级的重要性,融合所有重要性信息得到节点的特征向量。新的节点特征向量充分结合了异质网络不同类型节点的语义信息和重要性信息。然后将节点的特征向量经过GCN训练和B-P模型重构损失得到最终的重叠社区隶属关系矩阵。HAOCD模型图如图1所示。
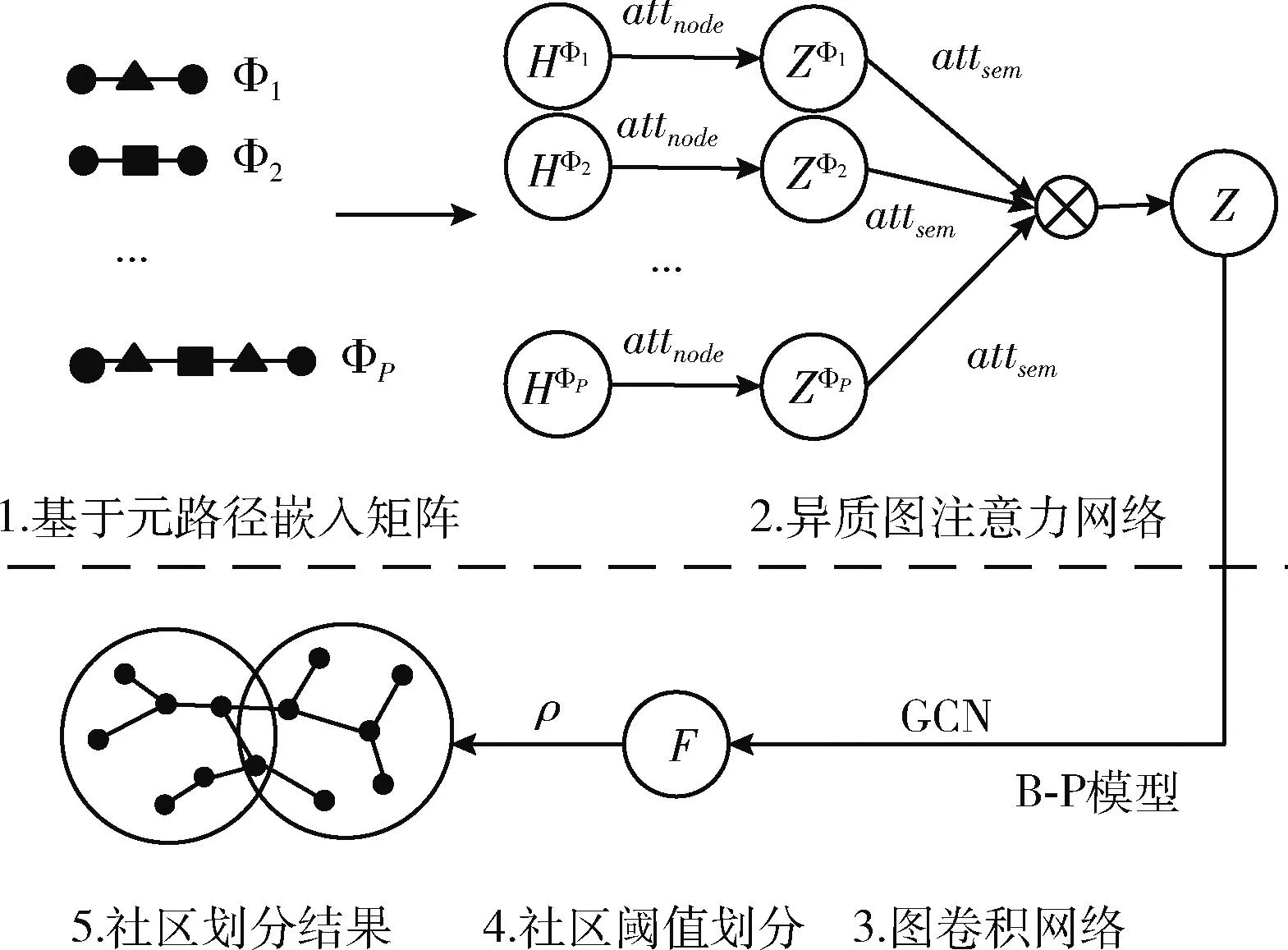
图1 HAOCD模型
2.3 基于异质图注意力网络的重叠社区发现算法
2.3.1 异质网络特征表示
异质网络包含丰富的结构信息和属性信息,本文首先将不同类型的节点根据指定元路径得到基于元路径的结构信息,然后将基于元路径的结构信息和节点的属性信息结合构建异质网络特征表示Hφi, 其公式如式(2)所示
Hφi=X·Aφi
(2)
式中:X表示节点的属性信息,Aφi表示基于元路径的结构信息。
2.3.2 异质图注意力网络
本文研究异质网络的重叠社区发现算法,异质网络中每个节点基于不同元路径的邻居具有不同的影响能力,而且不同元路径包含的语义信息不同,对社区发现任务也具有不同影响。因此引入HAN,它具有节点级和语义级两层注意力机制,捕捉节点级的重要性和语义级的重要性。本文将HAN的语义级注意的激活函数进行改进,采用RELU函数,解决训练过程中梯度消失问题。HAN节点级和语义级注意机制的聚合过程如图2所示。
(1)节点级注意力机制
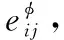
(3)

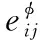

(4)


(5)
从公式可以看出节点i基于元路径φ的节点级注意的嵌入向量与它所有的一阶邻居节点有关。
由于单个元路径的单个注意力,不够稳定且图数据方差大,所以本文使用多头注意力,使训练过程更加稳定,其公式如式(6)所示
(6)
式中:X为注意力头数。最终得到P组基于不同元路径的节点级嵌入向量,P为选取的不同元路径的总数,嵌入向量表示为 {Zφ1,Zφ2,…,Zφp}, 节点级注意详细过程如图2所示。
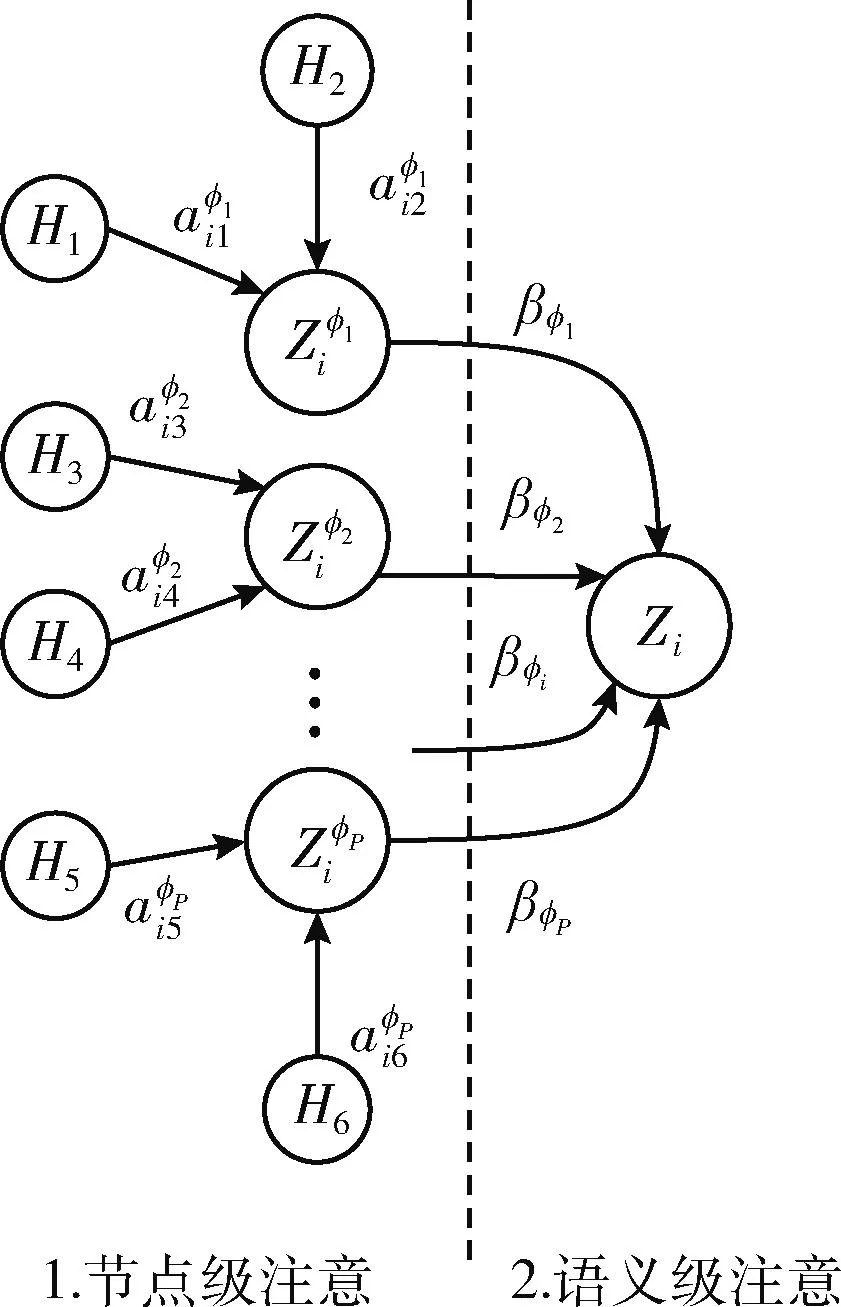
图2 异质图注意力网络双层注意机制
(2)语义级注意
不同元路径代表了不同的语义信息,对于社区发现任务,不同元路径对社区发现结果也有不同的影响能力。为了更好的捕捉不同的语义信息,使用语义级注意自动学习不同元路径对社区发现的重要性。将得到的P组基于不同元路径的节点级嵌入向量 {Zφ1,Zφ2,…,Zφp} 作为输入,通过语义级注意的神经网络学习每个元路径的权重,其公式如式(7)所示
{βφ1,βφ2…,βφp}=attsem(Zφ1,Zφ2…,Zφp}
(7)
式中:attsem表示语义级注意的图神经网络。
为了捕捉不同元路径的重要性,利用结合语义级注意力机制的单层感知机,并且将ReLU函数作为激活函数,得到该元路径对不同的节点的重要性,其公式如式(8)所示
ωφi=qT·f(Zφi)=qT·ReLU(W·Zφi+b)
(8)
式中:i∈P表示元路径i;ωφi表示元路径i对不同节点的重要性;f(·) 是所使用的单层感知机;ReLU(·) 是单层感知机所用的非线性激活函数;W是单层感知机的权值向量;b是单层感知机的偏差向量;q是语义级注意向量。
将特定元路径对不同节点的重要性ωφi的平均值作为这条元路径的重要性ωφi,其公式如式(9)所示
(9)
然后,上述得到的不同元路径的重要性需要通过softmax函数进行归一化处理,最终得到元路径的权重系数βφi, 其公式如式(10)所示
(10)
利用学习到的权重系数与特定元路径的嵌入进行融合聚集,获得最终的节点特征嵌入,详细过程如图2所示,其公式如式(11)所示
(11)
2.3.3 图卷积网络
基于异质注意网络得到了节点特征嵌入Z,然后以Z作为输入数据经过GCN得到社区隶属矩阵F,GCN的构成如式(12)所示
(12)
式中:A∈N×N是节点的邻接矩阵;是结合自循环的邻接矩阵;ReLU(·) 是非线性激活函数可以确保F的非负性;W是权重矩阵。
接着,将B-P模型的负对数似然作为损失函数,并且最小化B-P模型的负对数似然来优化社区隶属矩阵F,其公式如式(13)所示
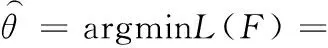
(13)
得到最终的社区隶属矩阵后,设置一个固定阈值ρ, 进行二元社区分配。具体过程为,如果节点i的隶属强度Fuv高于固定阈值ρ, 将节点i分配给社区c。
3 实验与结果分析
为了验证异质网络重叠社区发现HAOCD模型的有效性和可行性,本文选取了2个真实异质网络数据集和2个同质网络数据集与传统社区发现算法和其它基于图神经网络的算法进行对比实验分析。
3.1 相关数据集介绍
本文选取了DBLP、IMDB两个真实异质网络数据集和两个同质网络Facebook数据集。下面详细叙述这几个数据集,其参数见表1。

表1 数据集参数
DBLP数据集。此数据集是经典的记录计算机领域文献的数据集。本文选取DBLP-FOUR-AREA中的一个子集,包含作者(Author)、论文(Paper)、会议(Confe-rence)、术语(Term)4种类型的节点。作者分为数据库、数据挖掘、信息检索、机器学习4个领域。作者特征是由关键字组成的单词包构成。
IMDB数据集。此数据集是经典的电影数据集。本文选取IMDB中的一个子集,包含电影(Movie)、导演(Director)、演员(Actor)3种类型的节点。电影分为动作片、喜剧片、戏剧片3种类型。电影的特征是由情节组成的单词包元素构成。
Facebook数据集1(F1)和Facebook数据集2(F2)。此数据集是社交网络数据集。本文选取Facebook网络中两个小型同质网络数据集。Facebook用户为网络中的节点,社区由真实人际关系构成。用户的特征由用户的信息构成。
通过对节点类型、元路径语义、元路径长度的充分考虑与分析,在DBLP数据集选取APA、APCPA、APTPA这3条元路径信息,在IMDB数据集选取MDM、MAM两条元路径信息。
3.2 评价指标
社区发现的评价指标大致分为两类:一类是需要真实社区划分结果,例如标准化互信息NMI值和准确率precsion;另一类不需要真实社区划分结果,例如模块度Q。模块度Q是经典的社区发现评价指标,通过计算同一社区和不同社区之间边的关系,可以衡量社区发现的稳定度。扩展模块度EQ考虑了社区之间的重叠节点,适用于重叠社区发现算法。
本文所研究异质网络重叠社区发现算法,选择不需真实社区发现结果的评价指标扩展模块度EQ,并且根据异质网络不同节点类型的特点,结合特定元路径的邻接矩阵和元路径权重系数,将扩展模块度EQ函数改进为EQ*,其公式如式(14)所示
(14)

3.3 对比算法
本文提出的HAOCD模型与传统社区发现算法SLPA,异质网络重叠社区发现方法NELPA,基于图神经网络的算法GAT、HAN、NOCD进行对比。
SLPA:是一种传统的重叠社区发现算法,是LPA[16](标签传播算法)的扩展,它通过记录每次迭代所分配的社区来实现重叠社区发现。
NELPA:是一种基于SLPA的异质网络重叠社区发现算法,首先通过Metapath2vec异质网络嵌入方法获得节点嵌入向量,然后改进SLPA算法实现重叠社区发现。
GAT:一种基于图神经网络结合注意力机制的同质网络图嵌入方法,得到节点嵌入之后采用K-MEANS方法进行聚类得到社区发现结果。
HAN:一种基于图神经网络结合注意力机制的异质图嵌入方法,同样采用K-MEANS方法对得到的节点嵌入进行聚类得到社区发现结果。
NOCD:一种同质网络中基于图神经网络的重叠社区发现方法,采用B-P模型重构损失,使得到的社区结果更接近真实社区。
3.4 实验结果与分析
3.4.1 实验过程
对于基线算法,SLPA和NELPA算法设置标签阈值r为0.35。GAT算法设置注意力头X的数量为8。HAN算法设置注意力头X的数量为8,语义级注意向量q的维数为128。NOCD算法设置固定阈值ρ为0.5。为了对比实验的统一性,所有算法都采用100patience的提前停止策略。并都使用改进过的扩展模块度EQ*作为标准对实验结果进行测评。
3.4.2 参数分析
本文对两个异质网络数据集DBLP和IMDB进行实验,从模型的注意力头数X,语义级注意向量维度q,社区划分阈值ρ这3个参数进行分析。
本文研究不同注意力头数量X对社区划分结果的影响,X的数量影响节点级注意力机制过程的权重的生成,多个注意力头会学习到不同的节点权重信息并加以整合。以X=1作为初始实验参数,即只有单一注意力头。通过图3参数分析图可以看出,当X=1时,EQ*=0.65(DBLP)和EQ*=0.35(IMDB),相对多头注意力EQ*值偏低,原因是单个注意力头可能导致注意力机制学习到的权重不稳定。两个实验都可表明注意力头数越多,EQ*值越高,即社区划分结果更好。但当X>8时,DBLP实验中EQ*值增长缓慢,IMDB实验中EQ*值略有下降,并且注意力头数过多会使模型过于复杂,因此选取X=8作为不同数据集的注意力头数设置。研究语义级注意力向量的维度q对社区划分结果的影响,q的维度影响语义级注意力机制过程的权重的生成,维度越大权重信息表示越丰富。以q=32作为初始实验参数,之后成倍增加语义级注意力向量的维度。通过两个数据集的实验可以看出,当维度q设置为128时,EQ*值最高。当q>128时,EQ*值都呈降低趋势这可能是因为过拟合导致语义级注意力权重信息不准确,因此选取q=128作为最终的参数设置。社区划分阈值ρ的设置直接影响最后社区划分结果,ρ的取值偏大或偏小都会导致社区划分出现较大偏差。以ρ=0.1作为初始实验参数,依次获取阈值ρ在0.1,0.3,0.5,0.7,0.9取值的实验结果。通过两个数据集的实验可以看出当阈值ρ=0.5时EQ*值更高,说明此时社区发现结果更准确,因此选取ρ=0.5作为最终的阈值设置。
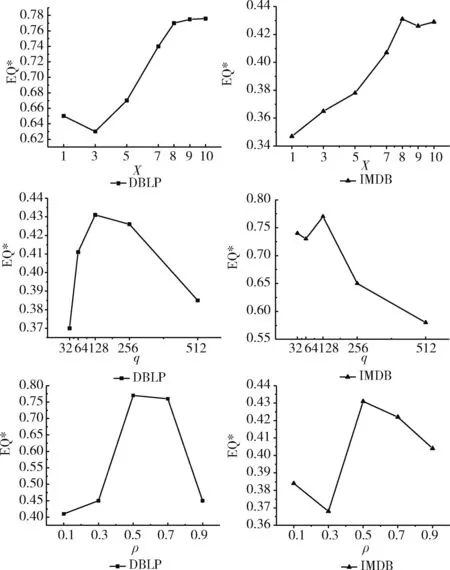
图3 HAOCD模型的参数分析
3.4.3 实验结果
图4展示了本文提出的HAOCD模型与SLPA、GAT、HAN、NOCD、NELPA算法在DBLP、IMDB两个异质网络数据集和两个同质网络数据集F1、F2上进行的实验对比结果,并采用EQ*作为评价指标。

图4 6种社区发现模型EQ*值对比
从两个异质网络数据集的实验中可以看出,本文提出的模型相比传统社区发现算法和基于GNN的社区发现方法都有一定程度的提升。传统社区发现方法SLPA在DBLP数据集实验中EQ*值只有0.35,IMDB数据集中EQ*为0.109。SLPA相对基于GNN的社区发现方法,不仅EQ*值偏低,而且所得结果不稳定。这可能与SLPA只利用了网络的结构信息进行社区发现,没有结合网络节点的特征信息有关。与基于GNN的算法不同的是,NELPA算法是通过Metapath2vec异质网络嵌入方法将异质网络的结构信息和属性信息结合并抽取不同元路径的特征信息,然后经过SLPA算法实现重叠社区划分。本文提出的HAOCD模型与NELPA算法相比也有小幅度提升。HAOCD模型基于GNN可以充分挖掘异质信息网络的节点信息和语义信息,具有较高的社区发现准确率。实验结果表明基于GNN社区发现方法在DBLP实验中EQ*值都大于0.6,表示基于GNN的社区发现算法可以更好结合网络的节点特征信息和结构信息并提高社区发现准确性。
HAOCD模型在与基于GNN的算法GAT、HAN、NOCD的对比中也有不同程度提高。GAT可以通过注意力机制得到邻居节点的权重,更新节点特征嵌入,但是没有利用异质网络的特点。HAN提出的双层注意力机制可以更好地利用异质网络的语义信息,但是没有关注到网络中存在的重叠社区现象。HAN与GAT相比在DBLP、IMDB实验中EQ*值都提升了大约10%,可以表明基于异质网络进行社区发现可以充分利用网络中的语义信息并使社区发现结果更准确。NOCD基于图神经网络结合B-P模型,关注到网络中的重叠社区现象,但是没有利用异质网络中的不同语义信息。本文提出的算法HAOCD相比其它基于GNN算法在IMDB实验中EQ*值提升明显,大约提升了20%,在DBLP实验中也提升了大约5%。HAOCD模型通过注意力机制充分提取异质网络的语义信息,并关注到社区中的重叠现象采用重叠生成模型B-P模型。
HAOCD算法在同质网络数据集F1、F2的实验中也有类似的结果。在同质网络数据集实验中HAOCD算法相对传统社区发现算法SLPA提升了大约20%,相对基于GNN的算法和NELPA算法提升了大约5%。因此实验结果表明HAOCD模型将异质图注意力网络与重叠生成模型B-P模型进行有效结合,不仅可以充分利用异质网络中的语义信息进行异质网络重叠社区发现并使社区发现结果接近真实社区,也可用于同质网络社区发现,提升社区发现的准确率。
4 结束语
本文研究基于异质图注意力网络的重叠社区发现问题,并提出了HAOCD模型。该模型首先基于改进的异质图注意力网络融合基于元路径邻居节点的权重和不同元路径的权重得到新的节点特征嵌入向量,然后通过图卷积网络结合B-P模型得到社区隶属矩阵,最后通过社区划分阈值取得最终社区发现结果。将提出的模型与传统社区发现方法SLPA和基于图神经网络的方法GAT、HAN、NOCD进行实验对比并以改进过的EQ*作为评价指标,结果显示HAOCD模型在真实数据集DBLP、IMDB、F1和F2上均有良好的表现。
但是,HAOCD模型只考虑了异质网络中节点类型不同的问题,但异质网络还存在关系类型不同的特点,所以未来可以全面考虑异质网络中节点类型和关系类型不同的特点,更好利用网络中的信息进行社区发现。
