基于视觉的商场智能安防巡逻机器人设计
2023-12-19勾伯涛李鹏飞
勾伯涛,李鹏飞
(沈阳理工大学 信息科学与工程学院,辽宁沈阳, 110159)
0 引言
过去的几年,随着科技的发展和社会的变革,商场产业迅速发展,虽然人们的生活水平得到了提升,但是随之而来的一些安防问题却始终未能有效解决。目前对于商场的安防问题,一般只有监控和保安巡逻两种传统的方式,对于监控来说它本身就存在着监控死角以及停电无法工作的状态,而对于人工巡逻来说,也没有足够的精力去实现24 小时的不间断视察巡逻,且人对于周围环境的敏感程度也相对比较薄弱,不能及时发现并排除隐患。
针对上述问题,本文设计了一个基于计算机视觉的智能安防巡逻机器人,实现自主移动定位、人体检测与追踪、烟火检测系统和灭火弹丸的精准投掷等功能,有效地弥补了传统方法的漏洞。
1 系统总统设计方案
智能巡逻机器人主要由运动主控模块(下位机)和视觉环境检测模块(上位机)两个模块构成,两个模块之间通过虚拟串口进行通讯,实现各个功能的联调,系统结构框图如图1 所示。下位机实现对机器人的运动状态的控制,其中包括前进、后退、平移、旋转等多种运动状态;能够接收上位机下发的信息实现在商场中实现自主建图、定点巡视、烟火检测、自动瞄准发射灭火弹丸,以及危险人物的自动跟随与报警。上位机上装有视觉主控的MinPC,能够实现上电自启动,确保代程序实时运行,也装有海康工业相机,其图像质量优异。通过USB3.0 接口实时传输非压缩图像,最高帧率可达249.1fps。由于运动场景复杂,相对于普通USB相机,它的增益,曝光等参数调节更加便捷,且对图像处理的速度也有显著的提高。
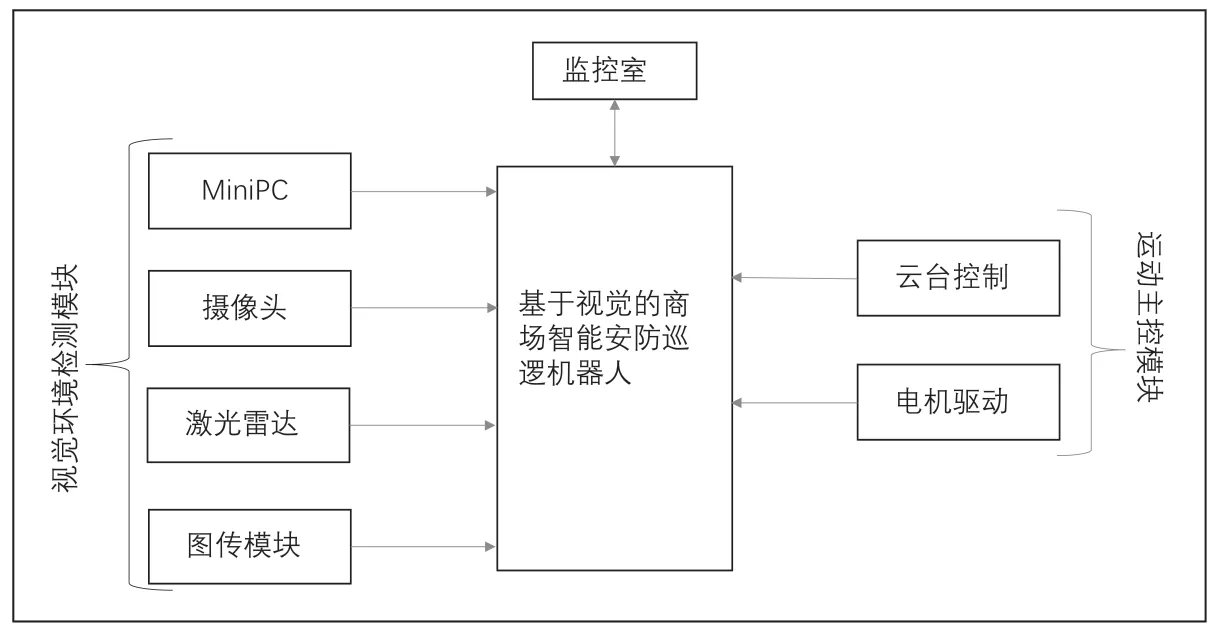
图1 系统结构框图
2 系统机械结构设计
■2.1 底盘框架
整体框架采用了铝方管立体式结构,并采用了薄壁粗铝方,在强度足够的情况下保持了车身的扁平化,减少了离地高度,并采用了大板材,进行合理的镂空,方便相关模块的布局和布线,如图2 所示。

图2 底盘框架
■2.2 轮组结构
轮组部分采用了上交的联轴器,在保证强度的同时,减少了相应的长度,采用了小摇臂,并利用soildworks 的拓扑运算功能进行了合适的减重,在转轴处利用了挡边轴承,减少了磨损,如图3 所示。

图3 轮组示意图
■2.3 云台结构
对于一个性能良好的机器人来说,三轴稳定性是必不可少的,同时还需要保证在高强度的环境中,拥有精准的抛投能力。因此在本次研发中,将重点放在机构的稳定性和弹道的精度上面,并对此进行测试与改进,如图4 所示。

图4 云台示意图
云台整体框架(见图5)采用的是利用板搭结构实现稳定性的Y 型框架。比较U 型框架结构和Y 型框架结构,U型结构便于对云台的零件进行摆放,拥有较大的俯仰角,其缺点是板件与连接件之间容易出现晃动现象。Y 型框架利用的板件自身的形状去抵抗变形,因此在稳定性上面有一定的优势。

图5 云台框架结构
图6 是连杆结构进行仿真分析,对俯仰角的分析,与设计预想值几乎一致。

图6 连杆结构仿真分析结果
图7 为电机在转动一定时间后停止的所受角力矩,经分析在电机所能承受范围内。
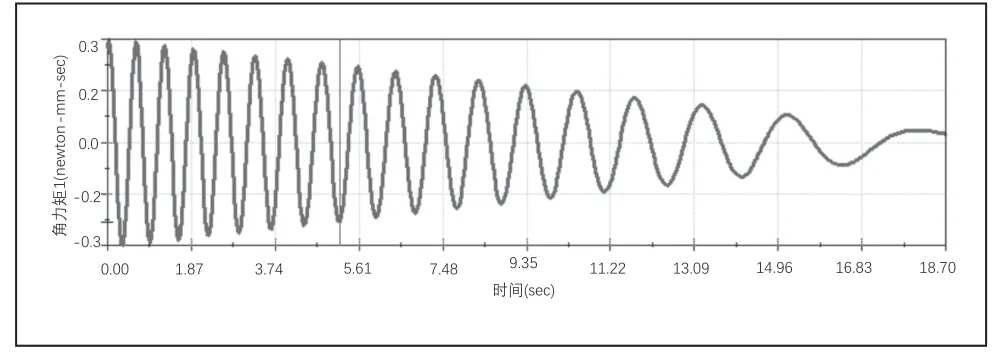
图7 电机在转动一定时间后停止的所受角力矩
3 系统硬件设计
■3.1 运动主控模块
Robomaster 开发板C 型采用了ST 公司的STM32F4系列微控制器作为主控芯片。该开发板具有丰富的外设和接口,包括多个PWM 输出、编码器输入、CAN 总线接口、USB 接口等。此外,该开发板还提供了丰富的扩展接口,可以方便与其他模块进行通信和连接。通过该开发板,我们可以方便地进行底盘、相机、激光雷达等各种硬件模块的控制和交互,真正实现了机器人自主运动和识别的功能。
■3.2 视觉主控模块
3.2.1 激光雷达
环境检测重要的一步就是需要知道机器人当前处于环境的哪个位置,故我们采用激光雷达来建立地图,从而实现自主巡逻功能。它通过发射激光束并测量激光束的反射时间和强度来扫描周围的环境,并据此计算物体的位置和距离。它可以通过其获取环境中物体的坐标信息,并将其转化为地图上对应的点或线段等几何形状,从而实现对环境的建模和定位。
3.2.2 MniPC
MniPC 是一种小型化的个人电脑,它作为我们机器人的控制器具有体积小、功耗低、高性能、易于编程等优点,能够提高机器人的灵活性和工作效率。它也是我们上位机的首脑,不需要实时检测,将数据发送至下位机,而且要监听下位机的信息,做好实时报警的准备,以引起周围工作人员的注意。同时也可以安装图传摄像头将画面实时传输到监控室,提高工作人员的工作效率。
4 系统软件设计
■4.1 总体运动流程设计
对于底盘的控制,机器人空间状态控制由底盘部分C板完成,底盘程序不断等待云台发送的空间状态控制指令,及底盘模式指令。并根据不同指令分别完成旋转模式、平移模式及正常行走模式的控制。在底盘启动过程中使用斜坡函数控制底盘起步的加速度防止轮子打滑又能有效控制功率。机器人运动过程中先对麦克纳姆轮解算然后通过PID 计算控制电流值。通过功率控制算法对PID 输出进行缩放进而实现软件层面的功率控制。
云台的控制,视觉识别到烟火及其他状态下首先对获得的视觉数据进行卡尔曼预测,并根据卡尔曼预测结果进行灭火弹丸下坠的计算:
并更新云台目标角度。云台控制时通过AHRS 算法结算陀螺仪数据完成云台的PID 控制。总体运动示意图如图8所示。
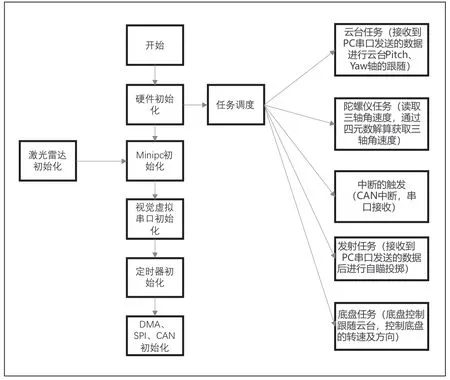
图8 总体运动示意图

图9 数据处理代码
■4.2 激光雷达定位
激光雷达和A-LOAM 都具有高精度的定位和运动估计能力,可以实现准确的自我定位和环境建模,为机器人导航和路径规划提供更加准确的参考数据。机器人可以使用这些信息来避开障碍物并规划最优路径,从而实现高效、安全的移动和任务执行,故本设计选其进行三维SLAM。
首先使用激光雷达扫描周围环境,并获取点云数据。激光雷达传感器由两部分组成,激光雷达发射系统通过多次发射激光束进行测量,层数越多则测量精度越高,但传感器也会变得更大。当激光束击中障碍物并反射回来时,形成了一组点云数据,这些数据实际上是根据激光束的反射时间测得的。
对点云数据进行特征提取,根据曲率和高度来识别地面点以及建非地面点。其次通过匹配不同时间戳下的点云数据,估计机器人在空间中的运动轨迹,并计算每个时间戳下相邻两帧之间的运动变换矩阵。将不同时间戳下的点云数据进行配准,生成一个组合的点云地图。最后使用基于因子图的优化方法,对机器人的位姿和地图进行优化,以最小化所有观测到的点云数据与预测点云数据之间的误差。将优化后的机器人位姿和地图更新到全局地图中,用于后续的导航和避障。主要实现步骤如下:
①配置激光雷达参数:
sensor_msgs::LaserScan laser_scan;
laser_scan.angle_increment = angle_increment; // 激光束角度分辨率
laser_scan.angle_min = angle_min;
// 最小扫描角度
laser_scan.angle_max = angle_max;
// 最大扫描角度
laser_scan.range_min = range_min; // 最小扫描距离
laser_scan.range_max = range_max; // 最大扫描距离
②处理激光雷达数据
首先,该程序利用ROS 中的sensor_msgs::LaserScan消息订阅激光雷达的数据,并将其转换为pcl 库中的点云数据格式(PCL::PointCloudpcl::PointXYZ)。 转换过程中,遍历每一个激光束并计算激光束对应的点的坐标,最终存储在点云变量laser_cloud 中。其次,使用PreprocessPointCloud 函数对点云进行预处理。最后,使用Mapping 函数利用点云数据进行建图。将每个时刻的点云数据与之前的地图数据进行匹配,并估计机器人的轨迹;根据需要使用拓展卡尔曼滤波(Extended Kalman Filter,EKF)等算法对机器人的运动进行估计和预测。最终,建图的结果通常是一个二维或三维的栅格地图或点云地图,用于机器人自主导航或环境探测。图10 为A-Loam 建图的结果。

图10 构建地图效果
■4.3 人体检测与跟随
为了避免人体四肢、复杂的遮挡、自相似部分以及由于着装、体型、照明,以及许多其他因素。我们采用MediaPipe 结合OpenCV 来对人体姿态估计(预测各种人体关键点)。MediaPipe Pose 是一种用于高保真身体姿势跟踪的ML 解决方案,利用我们的BlazePose 研究从RGB视频帧解算出全身33 个3D 地标,该研究也为ML Kit 姿势检测API 提供支持。为了实现对人体姿态的检测,本设计采用对MediaPipe 的人体关节夹角来对人的位姿进行检测。例如举手的时候,手臂与水平方向夹角是一定大于0 度的;双手垂下时,大臂与小臂的夹角大于0 度小于180 度,所以这样就可以将一些基本动作分类。图11 为双手下垂时的检测结果。

图11 双手下垂检测画面
接下来我们使用OpenCV 对识别到的人进行人体姿态解算。本设计采用SOLVEPNP 算法求解3D 到2D 点的运动,给定相机内参矩阵k、n 个空间点在图像上的像素坐标pi 和它们在世界坐标系下的坐标piw,需要求解相机的位姿,即计算世界坐标系到相机坐标系的旋转矩阵R 和平移向量T。图12 为坐标系转换过程。

图12 坐标系转换
在角度解算中,我们首先利用SOLVEPNP 函数计算出旋转向量和平移向量,然后使用罗德里格斯公式将旋转向量转换为旋转矩阵,接着使用欧拉角转换公式将旋转矩阵转换为欧拉角。最终,我们就可以得到物体在相机坐标系中的位置和Yaw、Pitch 轴等角度信息。最后将角度信息和距离信息发送给下位机,使得云台能够实时的跟踪目标物体。图13 为代码实现过程。
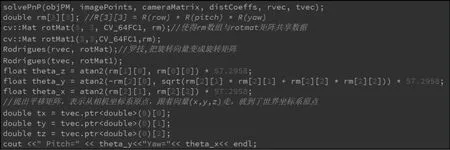
图13 角度解算
对于灭火弹丸的投掷,由于距离、弹道、环境等因素的影响,弹道会产生偏差,从而导致命中率下降。为了提高命中率,使用了传统的视觉弹道补偿方案。当云台接收到距离目标物体的距离时,结合弹丸的初速度和角度信息,推算出需要增加的Pitch 轴角度,从而能够精准抛投实现灭火。具体实现过程如图14 所示。

图14 弹道补偿

图15 模型实现代码
首先,输入参数包括“ShootSpeed”(炮弹射出速度)、“PitchAngle”(炮弹发射角度)和“CoordinateActual”(实际弹道的三维坐标)。代码中定义了弹丸的空气阻力系数“KAPPA”和质量“M”。然后,根据输入参数计算出发射点到落点的水平距离“p”和与水平面的夹角“pitchAngleRef”。接下来,将三维坐标转换为实际的距离(将坐标值从毫米转换为米)。然后,根据公式计算出弹丸在空气阻力下的速度变化,并根据经典力学计算出炮弹的飞行时间和轨迹。最后,通过解方程的方式计算出调整后的发射角度“pitchAngleRef”,并返回该值。
■4.4 烟火检测
考虑到机器人的实时性能和应用的场景,本设计采用了Yolov5 的5s 模型,它相较于其他版本和模型而言,虽然在精度方面有所降低,但在烟火检测任务中仍然表现良好。而且Yolov5 框架提供了易于使用的API 和预训练模型,可以更轻松地完成模型训练和部署。烟火检测步骤如下:
①收集1500 张带有烟火的图片,手动标注每个图片中烟火的位置以及类别,我们使用开源的标注工具LabelImg。但由于标注量大,故我们选择先标注少量数据集,再通过Yolov5 训练一个初始的模型来辅助标注,这样大幅缩短了工作量。
②将已经进行标注的数据集按照一定比例划分成三个部分:训练集、验证集和测试集。然后使用train.py 脚本来对Yolov5模型进行训练。同时需要定义模型架构、超参数、优化器等。
③验证模型:首先使用torch.hub.load()函数从本地加载YOLOv5 模型,然后使用cv2.imread()函数加载待检测的烟火图像。接着进行预处理。将预处理后的图像输入模型进行检测,得到每个检测框的坐标、置信度和类别。最后,在原图像上绘制检测结果并显示出来。
需要注意的是,训练样本的数量和质量、数据集的划分、模型的超参数等都会影响模型的准确度,因此我们进行了多次实验才找到最佳的实验配置。图16 为检测效果。

图16 烟火检测效果
该测试成功实现了智能巡逻机器人的烟火识别功能,试验的效果如表1、表2 所示。

表1 火焰检测结果

表2 烟雾检测结果
5 结语
本文以当下商场安防问题为背景,设计了一款能够自主巡逻的智能安防机器人,它搭载了电机驱动模块、激光雷达以及视觉处理等多种模块,实现了机器人对环境的自主监测、人体的自主跟随、烟火的识别及自主抛投灭火等多种功能,有效解决了单靠人工和远程监控的弊端。试验结果表明,此机器人搭载的一个高性能的悬挂能够在复杂的环境中灵活自主的运动,进入到人无法进入的地方进行工作,及时排除存在的安全隐患,实现了24 小时无差错的工作,真正意义上减少了对人力物力资源的浪费。结合多个传感器的共同作用,使机器人的智能化程度不断提高。
