基于深度学习的桥梁裂缝的智能识别与分类
2023-12-18彭家旭顾亦然
彭家旭, 顾亦然,2
(1.南京邮电大学 自动化学院、人工智能学院, 江苏 南京 210230;2.南京邮电大学 智慧校园研究中心, 江苏 南京 210230)
0 引 言
公路桥梁是我国交通基础设施体系中的一项重要组成部分。根据中华人民共和国交通运输部《2020 年交通运输行业发展统计公报》[1]显示,截至2020 年末,全国公路桥梁91.28 万座,其中特大桥梁6 444 座,大桥119 935 座。目前,我国桥梁多为钢筋混凝土结构,约占桥梁总数[2]的90%,在长期使用的过程中,由于受到车辆荷载、温度变化及其他因素影响,局部路面出现不均匀沉降、平整度不足等状况,桥梁路面结构也出现了裂缝、保护层脱落等问题。有关专家认为,我国40%的桥梁在役时间超过25 年,属于“老龄化”桥梁[3]。由于桥梁沥青路面养护多次大修中的铣刨、重铺,使路面结构与设计初期存在较大差异,部分路段裂缝问题严重;其次,有些路面未能及时监测保养,路面表面损害严重,行车舒适性显著降低,路面使用寿命大打折扣。
我国当前所使用的桥梁检测手段仍然是以传统的人工检测为主,但人工检测过程中需要占道施工,对行车安全以及检测人员的安全都造成了一定的威胁,而且人工检测的工作量大、效率低、主观性强,难以保证评估结果的准确性与客观性。
深度学习被广泛用于机器视觉、自然语言处理等领域,相比传统目标检测算法,基于深度学习的目标检测技术可以自动提取目标特征[4],使特征表达更具鲁棒性和泛化性[5]。根据有无候选框生成阶段作为区分[6],基于深度学习的目标检测技术主要分为双阶段模型和单阶段模型,双阶段模型有R-CNN[7]、FastR-CNN[8]、FasterRCNN[9]、MaskR - CNN[10]等,单 阶 段 模 型 有SSD[11]、DSSD[12]、YOLO[13]、YOLOv2[14]、YOLOv3[15]、YOLOv4[16]等。
YOLO 系列目标检测算法是一种检测精度高、速度快且检测性能好的单阶段检测器。因此,本文以YOLO系列中较为先进的YOLOv5s 算法作为研究对象。YOLO 的整体思想是将整张图作为神经网络的输入,把目标检测的整个过程转化成一个回归问题,通过搭建的整个网络结构输出目标的坐标位置和它属于哪一个类别,达到定位检测的目的。基于深度学习的目标检测弥补了传统方法硬件成本高、现场布置复杂等缺点,对桥梁检测工作有着较大的帮助,对未来桥梁养护也有着深远意义。
1 YOLOv5s 算法简介
YOLOv5s 网络是YOLOv5 系列中深度最小、特征图宽度最小的网络。YOLOv5s 由Input、Backbone、Neck、Head 四个部分组成,图1 所示为YOLOv5s 模型结构。
Input 部分进行Mosaic 数据增强、自适应锚框计算[16]及自适应图片缩放。Mosaic 数据增强丰富了图片信息,对图片随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。自适应锚框计算针对不同的数据集都会有初始设定长宽的锚框,训练时网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向更新,迭代网络参数。自适应图片缩放可以有效提高检测的准确率。
Backbone 部 分 主 要 包 含CBL 模 块、Focus 模 块、CSP[17]模块、SPP[18]模块。CBL 为标准卷积模块,包括普通卷积层Conv、批量归一化层BN 和Leaky ReLU 激活函数层。Focus 模块是对图片进行切片操作,具体操作是:在一张图片中每隔一个像素取一个值,类似于邻近下采样,可以得到4 张采样图片,4 张图片互补。CSP 模块是将原输入分成两个分支,分别进行卷积操作使得通道数减半,然后进行Bottleneck·N操作,Concat 两个分支使得Bottlenneck CSP 的输入与输出一样大小,让模型获得更多的特征。SPP 模块称为空间金字塔池化模块,通过引入不同的池化核来提取特征图中不同大小目标的特征。
Neck 部分采用了PANET[19]的结构,将特征金字塔网络(Feature Pyramid Network, FPN)[20]和路径聚合网络(Path Aggregation Network, PAN)[19]相结合。其中,FPN是自顶向下,将深层的语义特征传递到浅层,增强了语义信息,不过对浅层的定位信息没有传递;PAN 是对FPN 的补充,在FPN 的后面添加了一个自底向上的金字塔结构,将浅层的强定位特征传递到深层。FPN 和PAN又被称为“双塔战术”。Head 部分中的主体部分就是3 个Detect 检测器,即利用基于网格的anchor 在不同尺度的特征图上进行目标检测的过程。 采用了Boundingbox 损失函数和NMS 非极大值抑制。非极大值抑制主要是用来抑制检测时出现冗余的框。
2 YOLOv5s 算法改进
对现有YOLOv5s 网络结构进行扩展和优化,使网络结构更简单、更轻量。本文在删除部分网络结构的同时,还嵌入了注意力机制模块,这样网络就不会失去太多的准确性。CBAM 模块是一种的轻量级注意力模块,模块结构如图2 所示,可以在通道和空间维度上增加关注。CBAM 模块由通道注意力模块和空间注意力模块两个独立的子模块组成,分别在通道和空间中添加注意力模块,不仅可以节省参数和计算能力,还可以确保它作为即插即用模块插入现有的网络架构中。CBAM 模块在特征映射上操作,通过通道注意力模块和空间注意力模块更细化地提取特征,提高了模型的表现力。本文在C3 模块中相邻的瓶颈模块之间增加了CBAM 模块,如图3 所示,该模型称为YOLOv5s-CBAM 模型。
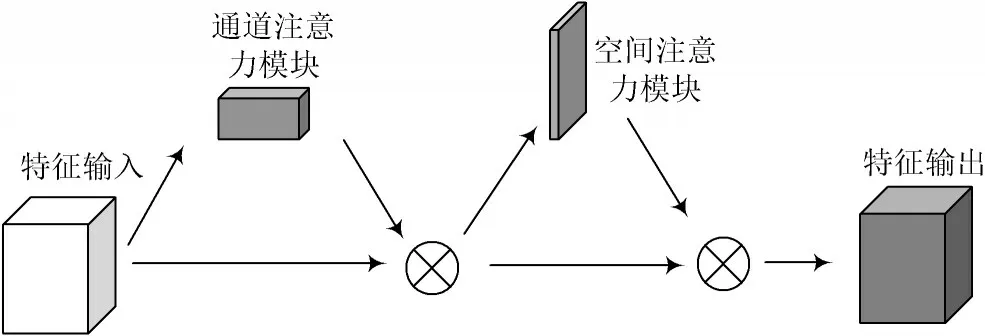
图2 CBAM 模块结构
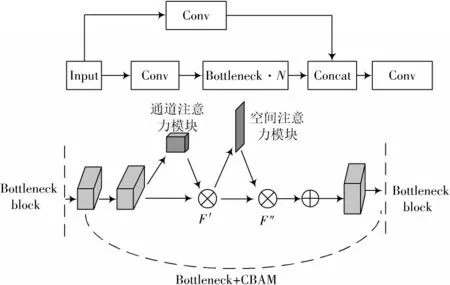
图3 本文CBAM 模块结构
通道注意力模块是将特征图输入注意力模块,分别为全局绘制池和空间最大池,然后分别变成两层神经网络,将这两个特征与Sigmoid 激活函数相结合,得到权系数Mc,将权系数与原有特征相乘可以得到新特征F,公式如下:
式中MLP 为多层感知机。
空间注意力模块是对获得的新特征进行平均池化和最大池化,然后把两个输出进行拼接,经过一个7×7的卷积层和Sigmoid 激活函数后,得到权系数Ms,再乘以F′得到F″。最后,将F″与原始输入相加,得到整个CBAM 输出的新特征,公式如下:
式中:AvgPool 为平均池化;MaxPool为最大池化。
由于原YOLOv5 模型结构大、层次深、参数多,考虑到模型的运行速度和精度,本文进行了信道修改和删除,删除了所有不重要的信道。但修改强度大、删除层数多会影响精度,因此,增加了CBAM 注意机制模块,确保在信道删除时通过调整注意力机制将模型保持到一定的精度。
YOLOv5s 模型的输入图像大小一般为640×640、80×80、40×40、20×20。特征图中的1 个像素分别对应输入图像的8、16 和32 个像素。当输入图像被下采样到20×20 时,图像中小于32×32 的像素目标会被压缩到小于一个像素点的大小,这样目标的特征信息会丢失更多,所以用20×20 的检测头检测更小的目标是没有意义的。桥梁路面裂缝经图像拍摄上传后,表现效果差异不大,属于小目标检测,由于大目标检测探头检测小目标意义不大,因此删除了20×20 大目标检测头,针对优化后目标尺寸的特点,YOLOv5s-CBAM 模型结构如图4 所示。
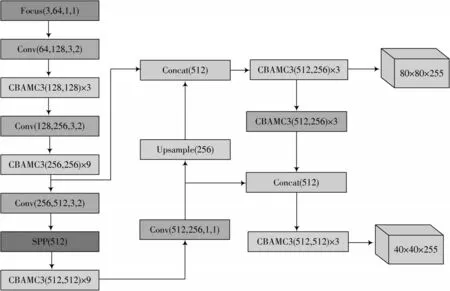
图4 YOLOv5s-CBAM 模块结构
3 实验结果及分析
3.1 数据集制作
本文研究对象为国内低等级桥梁,制作训练集的过程中,从Github 上的桥梁裂缝数据集的开源图片中选出了2 068 张裂缝的图片。由于数据集中的图像不足,因此本文决定使用数据增强来扩展数据集。
本文将原始图像按1∶4 的比例展开,对图像进行裁剪、旋转、平移、镜像等操作,最终获得8 190 张图片。5 000 张图分配给训练集,2 200 张分配给验证集,990 张分配给测试集。由于图像分辨率较高,直接计算量过多,因此将图像缩放到416×416 像素,并尽可能添加不同尺度和角度的桥梁裂缝,这样有利于避免训练过程中出现过拟合现象,从而提高网络的泛化能力。
根据要求,将图像转换为VOC 格式,使用LabeImg标注工具对图像进行标注,将桥梁裂缝的位置标记为横向裂缝(Transverse)、纵向裂缝(Longitudinal)、斜向裂缝(Oblique)以及交叉裂缝(Cross),如图5 所示。
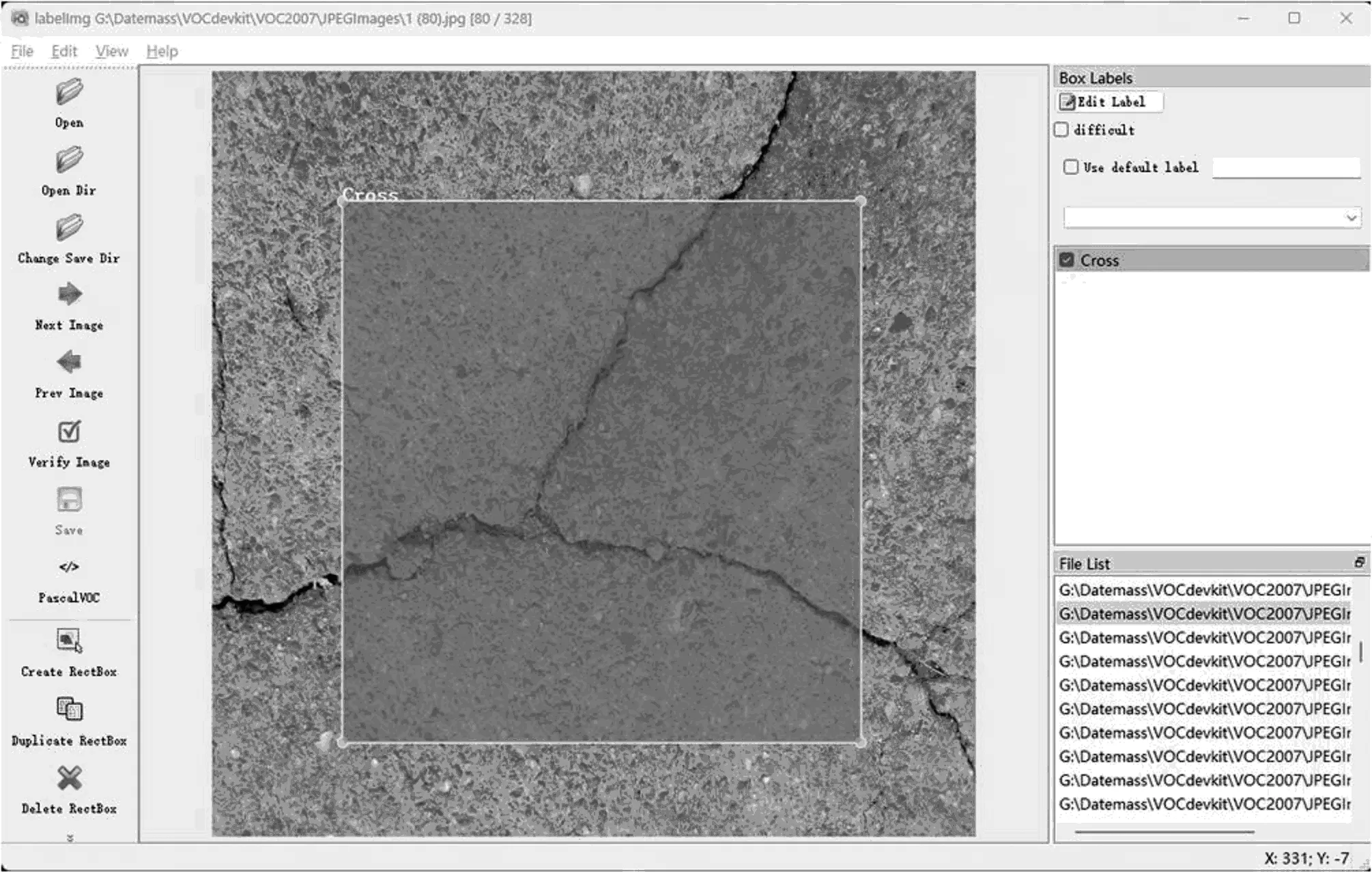
图5 数据集标注
3.2 实验环境
本实验使用的配置如下:计算机系统使用Windows 10, CPU 使 用 AMDRyzen55600X, GPU 使 用NVIDIAGeForceRTX3070,深度学习框架使用Pytorch。
3.3 模型对比
表1 所示为不同模型大小对比。从表1 可以看出,改进后的YOLOv5s 模型网络结构层数减少了36.3%,参数数量减少了77%,都比原来的YOLOv5s 模型要小得多,加快了运算速度,更容易放入移动设备中进行检测。
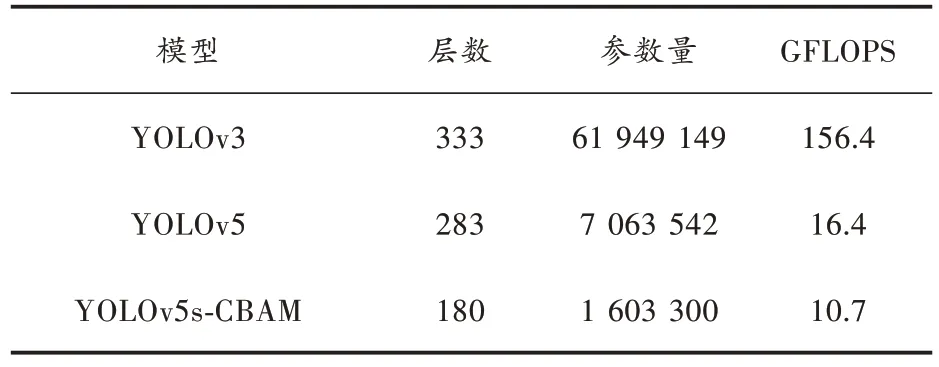
表1 模型大小对比
3.4 评价指标
实验采用准确率(Precision,P)、召回率(Recall,R)、F1分数(F1score)平均精度均值和每秒帧数来评价目标检测方法的性能。准确率、召回率和F1分数计算公式如下:
式中:TP 为被正确检出的目标数;FP 为被错误检出的目标数;FN 表示未被检测出的目标数。
3.5 实验结果分析
本文YOLOv5s-CBAM 的检测效果如图6 所示,利用改进模型对桥梁裂缝进行检测和分析,裂缝识别结果如表2 所示。从实验结果来看,改进的基于YOLOv5s 的桥梁裂缝检测模型对不同裂缝类型具有较好的识别效果。模型总体准确率、召回率和F1分数分别为91.8%、92.6%和91.9%。综上,YOLOv5s-CBAM 模型可实现高精度的裂缝识别定位。
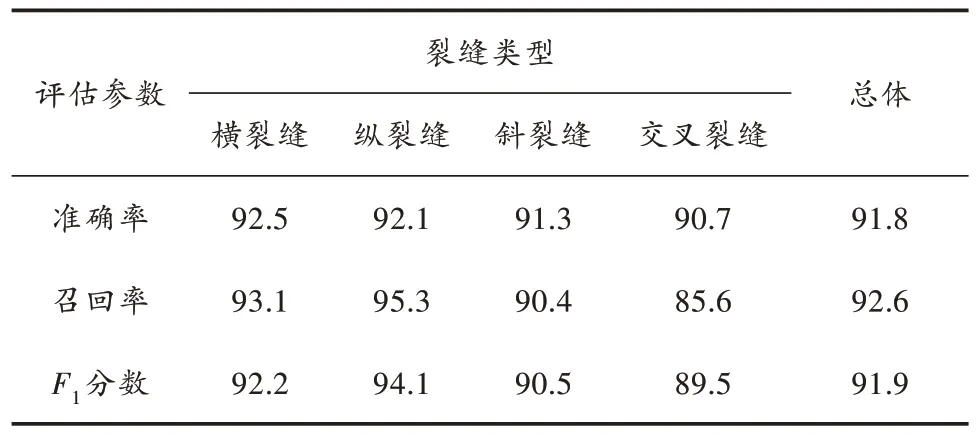
表2 裂缝识别结果 %

图6 YOLOv5s-CBAM 的检测效果
3.6 YOLOv5s-CBAM 与其他算法对比
本文算法与其他目标检测算法的对比实验结果来自COCO 数据集,将YOLOv5s-CBAM 与其他目标算法的性能进行对比,结果如表3 所示。
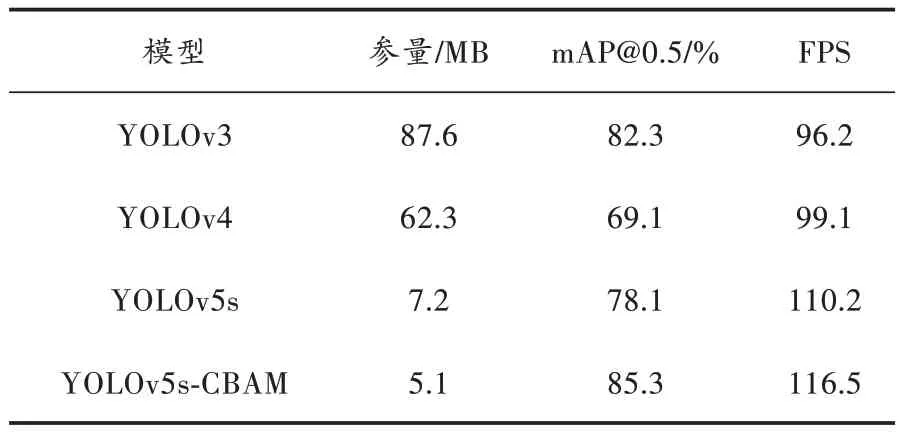
表3 不同模型的算法检测结果对比
由表3 可知:YOLOv5s-CBAM 和YOLOv3、YOLOv4、YOLOv5s 相比,模型参量更小,mAP 有明显提升,并且FPS 也有提升。实验结果表明,相较于YOLOv3、YOLOv4 这些模型较大的算法并综合模型参数量、mAP和FPS 来看,本文模型mAP@0.5 为85.3%,相比改进前提高了7.2 个百分点,模型参量仅为5.1 MB,相比之前降低了2.1 MB,YOLOv5s-CBAM 有更好的性能,在删除通道并嵌入CBAM 注意力模块后,增强了模型在复杂背景下的特征提取能力,提高了模型的检测精度,并且提升了检测速度。
4 结 语
本文针对桥梁裂缝检测模型内存消耗大、实时性差等问题,提出了一种基于YOLOv5s 目标检测模型的改进轻量级检测模型,在尽可能保证精度的前提下,根据目标尺寸的特点删减网络层数、裁剪通道、增加注意力机制。实验结果表明,与其他主流的目标检测算法相比,本文方法具有更高的准确率和效率,可以大大提高桥梁裂缝检测的效率和安全性。
