基于ICEEMDAN-ICSSA-CKELM-TCCA 的短期风电功率预测研究
2023-12-18汤占军贺建峰
韦 权, 汤占军, 贺建峰
(昆明理工大学 信息工程与自动化学院, 云南 昆明 650504)
0 引 言
能源危机早已被世界各国所重视。风力发电技术成为缓解能源短缺问题和环境污染问题的有效方法[1]。精准的风电功率预测方法对于高效利用风能资源和保证电网安全运行具有重大意义[2]。较成熟的功率预测方法主要分为物理预测法和统计预测法[3]。
由于风力资源的不稳定性以及预测模型的限制,导致风电功率预测的准确度不能令人满意[4]。近年来,研究者借助信号分解技术降低风电功率的波动性和复杂程度,实现预测精度的提高。文献[5]提出将神经网络与经验模态分解(Empirical Mode Decomposition, EMD)相结合,并运用在多步提前的风电功率预测中。文献[6]提出一种结合了LSTM 和支持向量机的模型,并引入集合经 验 模 态 分 解(Ensemble Empirical Mode Decomposition, EEMD)来应对风电功率的不确定性和强波动性。文献[7]基于多方面角度的优化,结合鲁棒回、变分模态分解(Variational Mode Decomposition,VMD)以及长短期记忆网络,提出了一种组合风电功率预测方法。
学者们各自从不同的角度丰富了风电功率预测方法,且预测精度也得到提高。然而,研究方法仍需改进:
1) 常用的分解算法因其局限性,仍会阻碍预测精度的提高,如EMD 会导致模态混叠、EEMD 产生残余噪声、VMD 参数难设定等[8]。
2) 重构后得到的序列具有各不相同的特征和复杂性,单一模型往往难以全面地捕捉到这些特征信息。
3) 预测误差与预测精度关系密切,然而针对预测误差的分析与修正往往会被学者们忽略。
为了进一步提升风电功率预测精度,本文提出一种ICEEMDAN-ICSSA-CKELM-TCCA 的风电功率预测组合模型。采用改进的带自适应噪声的完全集合经验模式分 解(Improved Complete Ensemble Empirical Mode Decomposition With Adaptive Noise, ICEEMDAN)将原始功率序列解析,得到一定数量的本征模态函数(Intrinsic Mode Function, IMF),降低了原序列的波动性,并引入样本熵对IMF 序列进行重构,得到新序列。同时,结合Poly 核函数和RBF 核函数构建组合核极限学习 机(Combined Kernel Extreme Learning Machine,CKELM)对新序列进行功率预测。通过叠加各模型预测结果得到初步预测结果及初步预测误差。针对CKELM 模型核参数选取困难的问题,利用改进混沌麻雀 搜 索 算 法(Improved Chaotic Sparrow Search Algorithm, ICSSA)对CKELM 的核参数进行优化。ICSSA 引入Tent 混沌映射函数,丰富了种群多样性,结合动态惯性权重和自适应t变异策略提升了算法的寻优精度和收敛速度,可更好地提升模型的学习能力和泛化性。最后,将时间卷积网络(Temporal Convolutional Network, TCN)和高效通道注意力(Efficient Channel Attention, ECA)模块构造成具有更强提取功率时间、空间特征能力的TCCA 模型对初步预测结果进行修正,进一步提升功率预测精度。采用实际风电数据进行实验,结果表明该模型针对功率预测具有较高的预测精度。
1 风电功率的分解与重构
1.1 ICEEMDAN 算法
为了降低原始功率序列的强波动性,本文采用ICEEMDAN 对功率数据进行预处理[9]。ICEEMDAN 分解过程如下:
1) 通过EMD 计算V(i)=V+β0E1(α(i))的局部平均值,得到一阶残差R1和相应的本征模式函数IMF1。
式中:V表示原始信号;i∈{1 ,2,…,K};β0表示信噪比;Ej( ·) 算子是进行EMD 分解得到的第j个模态,j∈{1 ,2,…,m};α(i)是均值为0,并且方差为1 的白噪声;M( ·) 被定义为生成信号的局部平均值的运算符。
2) 通过EMD 计算R1+β1E2(α(i))的局部平均值,得到二阶残差R2和IMF2。

1.2 样本熵
样本熵(SE)是一种用于分析时间序列数据的非线性分析方法,它可以度量时间序列中相邻子序列之间的相似程度。相比于传统的线性分析方法,SE 更适用于复杂非线性系统的分析[10]。SE 可以通过计算相邻子序列之间的距离差值的比率来反映时间序列的复杂程度。具体而言,SE 值越大,说明时间序列越复杂,包含更多的无规则变化。样本熵的具体计算步骤见文献[11]。
2 ICSSA-CKELM 功率预测模型
2.1 CKELM 模型
单核极限学习机受限于自身所选的核函数,在针对不同特性样本时所展现出的预测性能有明显差异,应用的范围受到局限[12]。为了能让核极限学习机可以更好地解决各类问题,本文将RBF 函数与Poly 核函数相结合,得到一个组合核函数,并用该组合核函数构成CKELM,进而强化模型的学习能力和泛化能力,进一步提升模型的预测性能。组合核函数表达式为:
式中:σ表示高斯核函数中用于控制径向范围的参数;u、v分别表示多项式核函数的常数参数和指数参数;ρ是组合权重。核参数对于CKELM 的性能有着决定性作用。
2.2 ICSSA 算法
尽管麻雀搜索算法在许多应用领域中取得了不错的效果,但是它仍然存在种群随机初始化、局部收敛性能较差的不足[13]。
鉴于SSA 算法中麻雀种群随机初始化问题,本文引入Tent 混沌映射函数对SSA 进行改进。鉴于混沌变量的随机特性,可以用来增加原始SSA 种群的丰富程度,从而增强算法跳出局部最优解的能力,以及提高全局搜索的质量。Tent 混沌映射算子是一种常用的算子,可以在[0,1]区间产生均匀的混沌序列,同时具有较快的迭代速度。
Tent映射函数如下所示:

式中N为 Tent 混沌序列中的粒子个数。
针对SSA 运行中常遇到的局部收敛性能较差的问题,往个体位置更新公式中加入动态惯性权重因子,以达到兼顾局部及整体搜索的作用。动态惯性权重因子a1的公式如下所示:
式中:c指目前的迭代次数;M′指最大的迭代次数。
改进后的发现者和加入者的位置更新方程如下:

为了更好地兼顾麻雀种群的全局搜索和局部搜索,本文引入自适应t 变异对麻雀位置进行更新。自适应t 分布的自由度参数用于调整分布曲线的形态,自由度参数越大,分布越接近高斯分布;自由度参数越小,分布越平缓,并且具有更大的尾部概率。这种自由度的可变性使得自适应t分布在不同数据情况下可以更好地拟合数据,具有更好的适应性。鉴于自适应t 分布曲线的特性,将迭代周期c代入自由度参数。迭代初期,c值较小,算法表现为与Cauchy 变异相近的特性,其全局搜索的能力更为突出;迭代后期,算法表现出与Gaussian 变异相近的特性,其局部搜索的能力更为显著。改进后麻雀位置更新如下所示:
式中,t(c)表示为t 分布,并将SSA 迭代c次设为自由度参数。
为了确保动态策略下的适应度值达到最优,本文引入贪婪算法来决定是否要更新位置。贪婪算法表示为:
式中f(x)指某处的适应度值。
3 TCCA 误差修正模型
3.1 TCN 模型
TCN 是有效针对时间序列预测的新网络结构。采用一维扩张因果卷积层,以及灵活结合残差连接方式,TCN能够有效地捕捉时间序列中的长期依赖关系[14]。
图1 展示了扩张因果卷积的结构。与普通卷积不同的是,扩张卷积通过多个扩展的随机卷积层逐渐增加感受领域,使得输出包含更多信息。扩张卷积凭借设定卷积核尺寸、扩张系数d、卷积层数等参数,实现了有效地挖掘长序列的总体特征。扩张卷积具体计算如下:
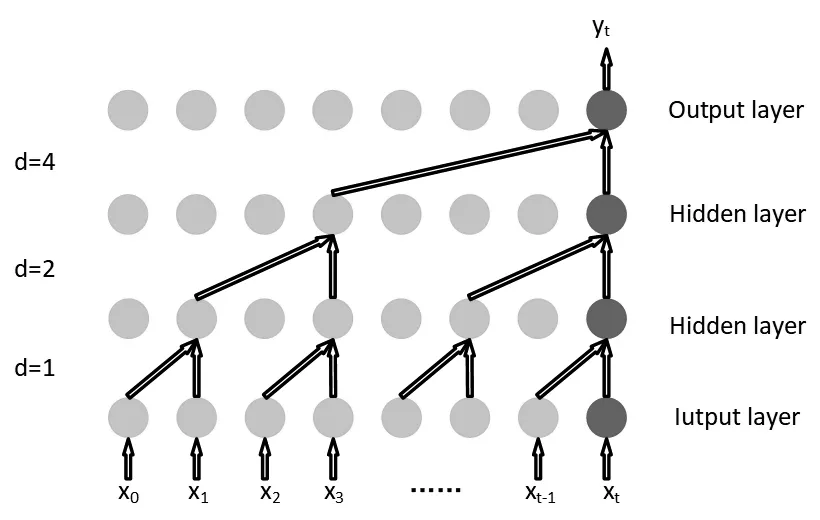
图1 扩张因果卷积的结构
式中:k为过滤器大小,即卷积核尺寸;d为扩张系数;f(i)为卷积运算中第i个元素;xt-d·i为历史数据,即只使用该元素及其之前的输入数据进行卷积计算。
神经网络的表达能力随着网络深度的增加逐渐增强,但是网络结构深度的增加会导致梯度消失、梯度爆炸等一系列问题。在TCN 中,加入了残差连接来应对上述问题。图2 为TCN 残差块连接结构图。
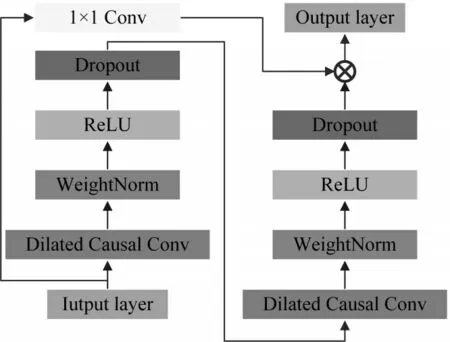
图2 TCN 残差块的结构
3.2 ECA 模块
ECA 模块无需降维操作便可有效地维持通道与通道之间信息的交互性能[15]。ECA 模块的本质是采取一种特殊的跨通道交互策略,其特殊之处便是仅与周边局部范围内通道交互,而范围的大小取决于一维卷积核的大小k,k会基于输入通道c发生相应的变化,k与c的对应关系如下所示:
式中:γ和b为固定值,分别取2 和1;通道数目往往是2 的n次幂,所以底数设定为2。得到输入通道c后,自适应一维卷积核的大小可由下列公式算出:
式中 |t|odd代表最靠近t的奇数。在ECA 中,各通道学习获得的注意力权重彼此共同拥有,以此实现了结构简化,计算公式如下:
式中:σ为Sigmoid 激活函数 的运算符;αj表示彼此所共同拥有的注意力权重;Ω ik表示yij周围的k个通道的集合。
ECA 模块的工作原理图如图3 所示。图中:H为输入序列的长度;W为其宽度;C为其通道数;GAP 为对各通道进行全局平均池化。
3.3 TCCA 修正模型构建
鉴于TCN 针对时间序列的优势,以及ECA 模块在通道间特征提取上的优势,本文提出一种TCCA 模型对预测误差进行修正。TCCA 误差修正模型由TCN-ECA残差结构串联而成。细分到每个TCN-ECA 残差结构而言,它是将ECA 嵌套入常规的TCN 残差块组合而成,同时加入Dense 层承接TCN-ECA 模块之间的输出特征。TCCA 模型结构如图4 所示。

图4 TCCA 模型的框架
误差修正模型工作原理如下:初始的输入序列首先经过TCN 残差块进行特征学习;为了规避网络的梯度爆炸问题,添加了WeightNorm 层来约束隐藏层的输入;为了突出神经网络各层之间的非线性关系,线性单元(ReLU)被用作神经网络的激活函数;利用Dropout 正则化网络避免过拟合,从而增强模型的泛化性;ECA 模块连接到常规 TCN 残差块的下采样部分,将TCN 残差块输出的特征信息进行全局平均池化,依靠自适应卷积得到各通道不同的重要性占比,快速捕获通道与通道之间的相关性。将原始序列特征与ECA 捕获到的权重占比加以融合,最后映射输出。
4 组合预测模型的框架
ICEEMDAN-ICCSA-CKELM-TCCA 模型的框架如图5 所示。
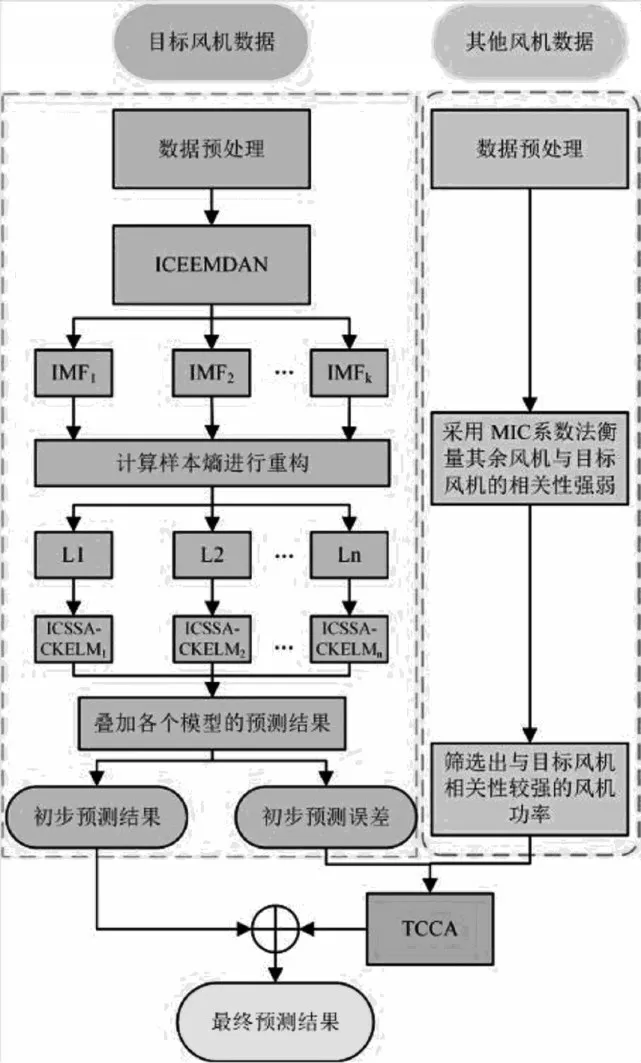
图5 组合预测模型框架
模型的建立可总结为以下步骤:
1) 对目标风机原始风电数据进行必要的预处理,并将前80%的数据集作为训练集,后20%的数据集作为测试集。
3) 计算各个IMF 序列SE 值,将SE 值相近的IMF 序列进行叠加重构,得到新序列L1,L2,…,Ln。
4) CKELM 模型分别对L1,L2,…,Ln进行功率预测,每个CKELM 模型引入ICSSA 进行核参数的优化。
5) 各个模型预测结果y0,y1,y2,…,yn叠加得到初步功率预测值Y0和初步预测误差值E0。
6) 引入Spearman 等级相关系数法筛选出与目标风机功率相关性较强的其他风机组。
7) 将目标风机的初步预测误差值和筛选出的风机组的功率一起输入到TCCA 模型中进行误差修正,得到修正后的误差值E。
8) 将预测目标的初步功率预测值Y0与修正后的误差值E叠加,得到最终功率预测值Y。
5 算例分析
5.1 数据集介绍
本文采用中国云南省某风电场实际采集到的风电数据。该数据采用SCADA 系统进行采集,采集时间为2020 年9 月—10 月,采样间隔均为10 min,采样点共4 446 个。
将外部期待内化为内部需要。通过宣传、讲解、辨析等途径,让工科新教师清楚认识到学生、学校、社会对其的期待,认识到自身承载的社会责任与角色担当,促进其将外部的角色期待内化为内在的培训需要。
5.2 评价指标
从不同的角度分析实验结果,所选择的衡量指标也有所不同。为了更全面地评估预测模型的优劣,本文引入3 个指标来衡量预测的优劣,评价指标计算公式如下:
1) 平均绝对误差(Mean Absolute Error, MAE):

式中:M为采样点总量;Pi为第i个时刻的真实风电功率值;P^i为第i个时刻的预测风电功率值;Pˉ为M个风电功率的平均值。
5.3 信号的分解与重构
本文利用ICEEMDAN 算法对原始风电功率序列进行预处理,ICEEMDAN 的噪声权重设置为0.2,噪声添加50 次。ICEEMDAN 分 解 结 果 如 图6 所 示。
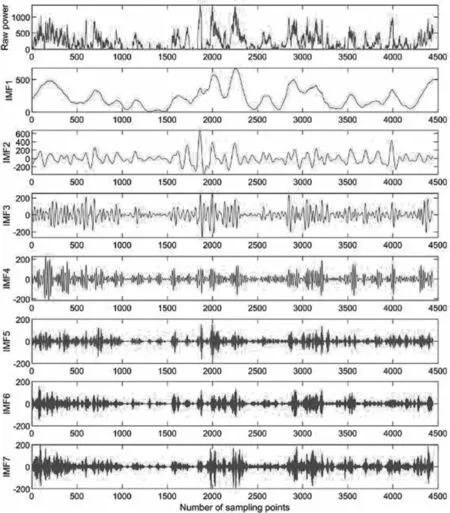
图6 ICEEMDAN 分解结果
原始功率序列被ICEEMDAN 很好地划分为各频段的IMF 序列,其原本包含的复杂信息也被很好地分离。
为了简化数据结构并降低模型建立的复杂程度,利用SE 理论对IMF 序列进行重构。各IMF 序列的SE 值情况如图7 所示。
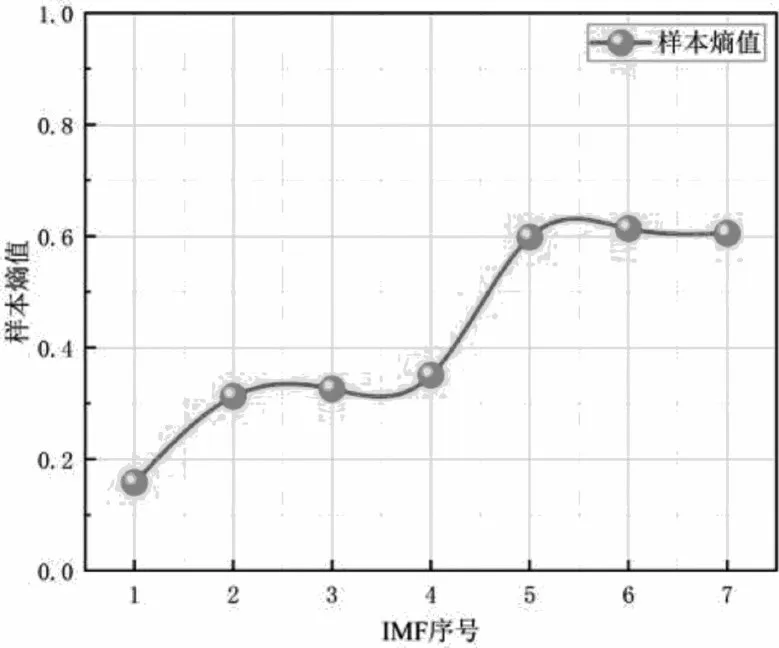
图7 各序列的样本熵值
IMF2、IMF3以及IMF4的SE 值接近,说明三者的复杂程度相近,因此把它们合并成一个新序列。同样地,由于IMF5、IMF6以及IMF7的SE 值相近,所以把它们合并成一个新序列。重构后得到的新序列记作L1、L2、L3。
5.4 ICSSA-CKELM 性能分析
本文建立CKELM 模型来进行功率的初步预测。针对新序列L1、L2、L3分别建立CKELM 模型进行功率预测。利用ICSSA 对每个CKELM 模型的核参数进行优化,ICSSA 的参数设置如下:最大迭代次数为50 次,种群大小为30,观察者占种群大小的20%,最大安全阈值设为0.7。CKELM 模型需要优化的核参数包括正则化系数C、控制径向范围的参数σ、多项式核函数的常数参数u和指数参数v、组合权重ρ。将各模型预测结果进行叠加,得到初步功率预测值和初步预测误差值。
同时设置SSA-KELM、SSA-CKELM 和ICSSA-KELM作为对照实验,图8 为各模型的预测结果曲线。各模型具体的误差结果如表1 所示。
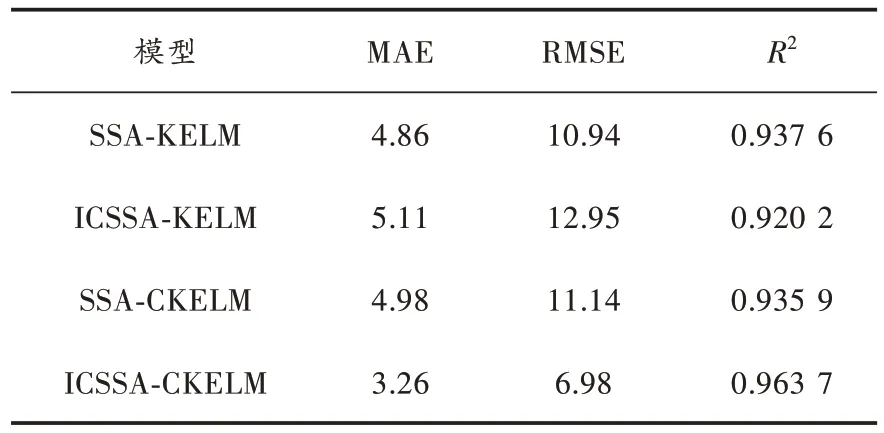
表1 各模型预测结果的评价指标

图8 各模型预测对比
从图8 可以看出,ICSSA-CKELM 模型的预测结果不仅在单调变化区间内可以很好地拟合实际功率,而且在一些拐点处也能很好地跟随实际功率的变化趋势。结合表1 的评价指标来对比,ICSSA-CKELM 模型的MAE为3.26,RMSE 为6.98,R2为0.963 7,各指标都是最佳。综上所述,ICSSA-CKELM 模型的预测性能更优秀。
5.5 TCCA 性能分析
由于ICEEMDAN-ICSSA-CKELM 模型的初步预测结果精度更高,所以本文后续仅针对此模型的预测误差进行分析与修正。基于风电的空间相关性原理[16],本文引入目标周边风机的功率变化情况对目标预测误差进行修正。周边风机的功率变化趋势如图9 所示。
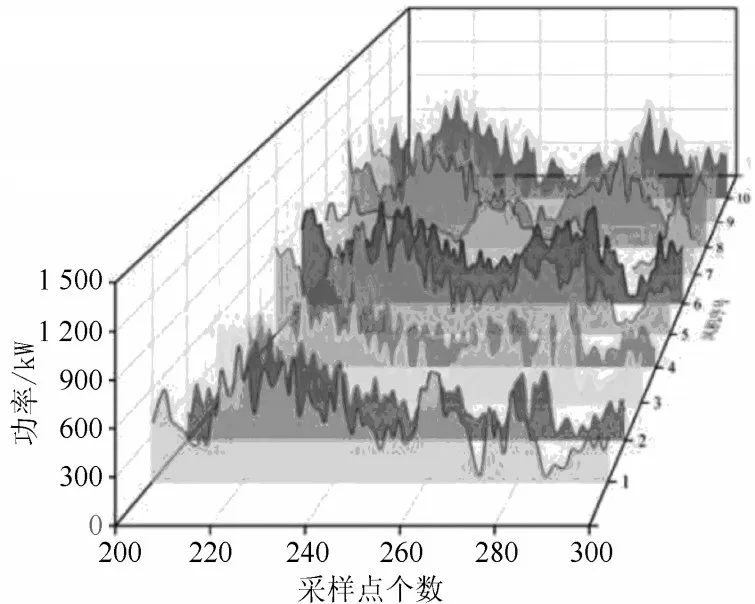
图9 周边风机的功率变化趋势
从图9 可知,其余风机组的功率变化趋势与5 号风机的情况大体相似,这符合空间相关性的规律。为了提升误差修正模型的效果和效率,需要选出与5 号风机功率相关性较强的风机。由于通过功率曲线进行筛选局限性和主观性,因此本文利用Spearman 等级相关系数法[17]来筛选风机,提高筛选方法的解释性。考虑到风机间的距离、地形、排布方式等因素,选取1~10 号风机进行筛选,Spearman 等级相关系数的计算结果如图10 所示。结果显示:功率相关性较强的风机有4 号、6 号、8 号、9 号。
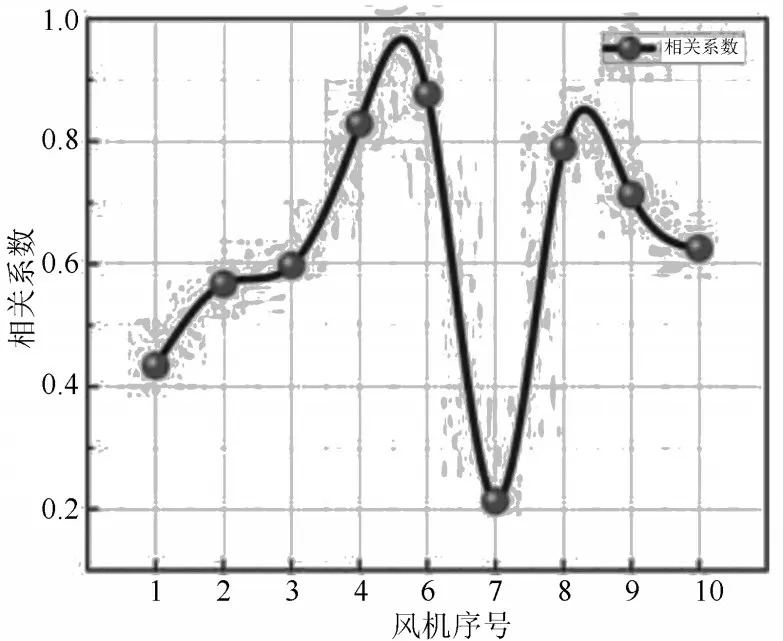
图10 各风机Spearman 等级相关系数
结合初步误差序列与筛选出的风机功率建立TCCA 模型进行误差修正。本文提出的TCCA 模型参数设置如表2 所示。修正后的误差如图11 所示。
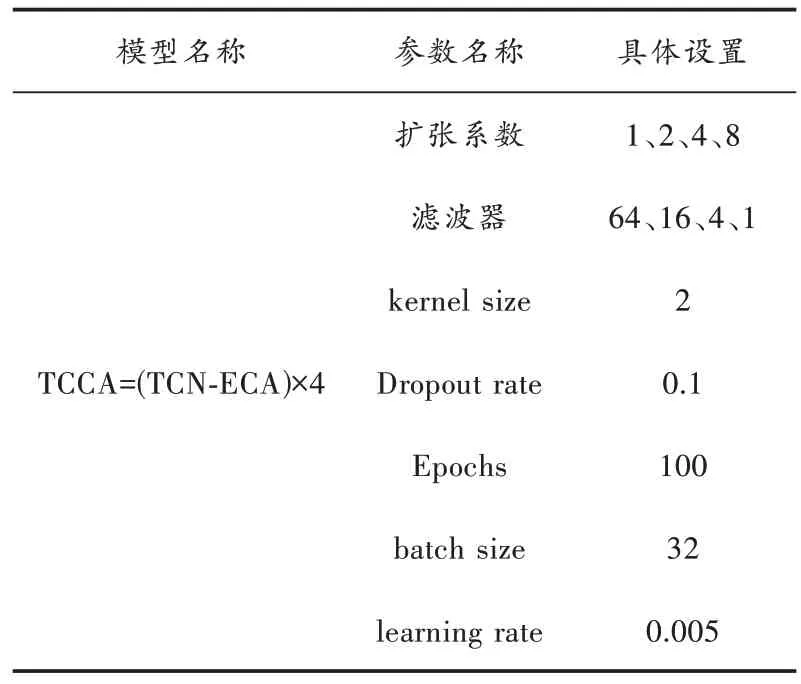
表2 各预测模型的参数设置
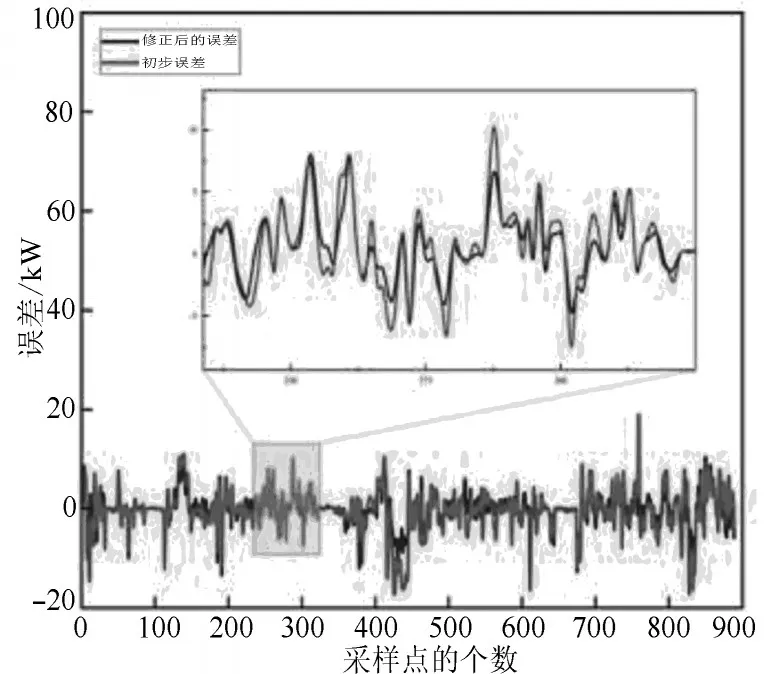
图11 修正后的误差
从图11 可知,对比初步误差功率曲线,修正后的误差功率曲线变得更加收敛。将初步预测结果与TCCA模型修正后得到的误差进行叠加,得到最终预测功率,如图12 所示。经过TCCA 模型的修正后,最终的预测功率曲线与实际功率曲线的拟合度有了很大提升。
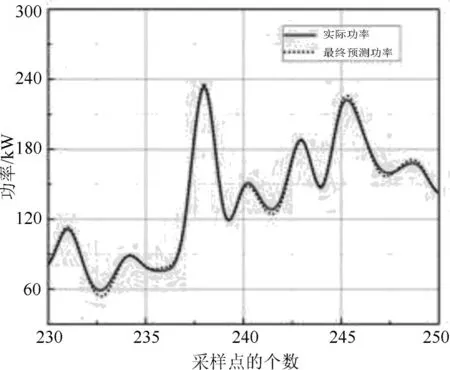
图12 最终预测结果
为了进一步验证TCCA 模型的有效性,本文以ICEEMDAN-ICSSA-CKELM 模型初步预测结果为基础,设置了以下实验进行对照:仅进行初步预测,没有误差修正操作(称为模型1);使用TCCA 模型进行误差修正(称为模型2)。对照实验的结果如表3 所示。

表3 各模型预测结果的评价指标
与模型1 作比较,模型2 的MAE、RMSE 分别下降了1.93 kW 和3.13 kW,且R2上升了2.39%,这说明了TCCA在拥有强大时序特征捕捉能力的同时,也具备了高效地提取风电功率空间特征的能力,更突出了跨通道间重要信息对于修正结果的影响,使得误差修正效果更优秀,从而进一步提升了功率预测精度。
6 结 论
从信号分解与重构、修正误差等多方面考虑,本文提出一种ICEEMDAN-ICSSA-CKELM-TCCA 的风电功率预测组合模型。采用中国云南省某风电场的数据集进行多组对照实验后,可得出以下结论:
1) 经过ICEEMDAN 的预处理,风电功率序列被分成频段互异的模态分量,其波动性被有效降低且重要信息被更好地提取。
2) 结合全局性Poly 核与局部性RBF 核函数的CKELM 模型具备优秀的学习能力与泛化能力。采用ICSSA 对CKELM 模型的核参数进行优化,有效降低了核参数选取的难度并提高了功率预测精度。
3) TCCA 模型具有强大的提取风电功率时空特征的能力,可以更好地捕捉到不同风机功率间的相互关系,对预测误差序列的修正效果显著,进一步提高了功率预测精度。
4) ICEEMDAN-CSSA-CKELM-TCCA 模型可以有效提升风电功率的预测精度。
