基于区块链的自适应权重趋势感知联邦学习方案
2023-12-18刘振,吴宇
刘 振,吴 宇
(东莞理工学院网络空间安全学院,广东东莞 523808)
近年来,人工智能[1](Artificial Intelligence,AI)的研究主要在机器人[2]、语言识别[3]、图像识别[4]等方面,这些研究领域使得人工智能的发展不断成熟,应用领域也不断扩大。21 世纪初,人工智能进入以深度学习[5]为主导的大数据时代,深度学习被引入机器学习使得其更接近于最初的人工智能目标。深度学习的训练是含多个隐藏层和多个层感知器的深度学习结构,需要联合多方数据进行机器学习模型的训练。
联邦学习[6](Federated Learning,FL)可以在没有集中训练数据的大量边缘设备(客户端)上实现协作式机器学习,但是设备之间有限的网络带宽资源以及传统联邦学习依赖中心化服务器进行模型训练的问题,给联邦学习带来了一系列的通信效率和扩展性等问题,而这些问题都会影响机器学习模型的训练效果。为了解决以上问题,提出了一种新的联邦学习方案,能够在训练过程中自适应获取阈值,并以此筛选和全局模型更“一致”的客户端本地模型,该方案不仅节省了大量训练过程中的网络带宽,提高了机器学习模型的收敛率和精确度,使得训练过程安全性得到保障。
1 问题分析
网络带宽资源的紧缺成为阻碍联邦学习获得更高精确度机器学习模型的瓶颈之一,并且传统的联邦学习需要中心化服务器进行全局模型的更新,这些都会影响到机器学习模型的训练效果。在对联邦学习的研究中提出了多种缓解通信开销的解决方案,其中,文献[7]是根据每个客户端节点的本地模型更新是否符合全局模型更新趋势来筛选参与到全局模型更新的客户端本地模型。但是该方案中的阈值选择方式存在浪费训练资源的现象,例如:通过手动遍历所有可能阈值,然后对比所有阈值下的全局模型来选取最佳阈值。该训练过程中不可避免地增加网络的通信开销和计算开销,并且在全局模型的训练过程中会消耗更多的训练资源。
基于CMFL 筛选算法,该方案设计了一种自适应阈值更新算法,算法在每一轮训练过程中自适应更新筛选阈值,能够有效筛除无助于全局模型更新的客户端本地模型,节约全局模型训练过程中的训练资源,并且结合区块链[8]技术解决了联邦学习中心化服务器进行全局模型聚合以及存在的模型隐私[9-11]安全问题。
2 CMFL筛选算法分析和改进
2.1 CMFL筛选算法的介绍
目前在对联邦学习通信开销的研究中,主要有两种方法[12-13]可以减少模型训练期间的通信开销:1)减少每个客户端更新上传的总比特数在;2)减少每个客户端上传的更新总数。
CMFL 利用式(1)计算全局模型和客户端本地模型的相关性,其中,-u表示客户端节点梯度方向向量矩阵,e表示它们的相关性,u表示上一次全局更新服务端的方向向量矩阵。
图1 展示了客户端节点和模型需求方的梯度方向向量矩阵相关性计算过程。首先,提取客户端1模型梯度和客户端2 模型梯度的方向向量矩阵,再与上一轮全局模型梯度的方向向量矩阵进行对比,计算相同位置上相同方向(正负)占整个梯度数据个数总和的比例。通过手工设置的阈值T,判断当前客户端节点的方向向量矩阵-u与上一轮全局更新的方向向量矩阵u的相关性e是否达到阈值T,以此决定该客户端节点的本地模型是否可以参与到当前迭代的全局更新。但是该方法需要通过对比多个手动设置固定阈值训练得到的全局模型来决定最优全局模型,该方法存在浪费训练资源的现象,并且需要中心化服务器进行全局模型的聚合。
2.2 基于CMFL筛选算法分析和改进
通过分析CMFL 筛选算法中寻找适合全局模型训练阈值的方法,发现阈值是经过线性递增的方式来手动设定,如设置阈值为{0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9},然后通过比较在每个设定阈值下训练得到的最终全局模型的训练效果来获得最佳的阈值设置。在全局模型的训练过程中,使用手动设置固定阈值的CMFL 筛选算法除了需要占用大量的训练资源外,在全局模型的训练过程中还存在客户端不断更新的情况,包括无助于全局模型训练的数据加入,新客户端节点动态加入到训练中等情况,这些情况的出现使得全局模型的训练过程复杂化。如果采用手动设定固定阈值的方式,控制参与整个全局模型训练过程中的客户端,不能有效适应动态变化的联邦学习训练场景。
实验中记录了多次手动设置的固定阈值以及首次满足阈值的客户端本地模型与全局模型的相关性。如图2 所示,左边第一组柱状图是进行联邦学习时筛选算法设置的四个固定阈值,右边两个柱状图是对应固定阈值下,利用如式(1)所示获取的首次通过筛选的两个客户端本地模型与全局模型的四个相关性数值。通过柱状图可以发现首次通过筛选的客户端本地模型的相关性与固定阈值相近,并没有超出阈值太多。另外相关性与固定阈值的变化成正相关,随着固定阈值的增大,通过筛选的客户端本地模型与全局模型的相关性也增大,并且全局模型的精确度也提高了。假设在全局模型训练过程中,不是固定单个阈值完成整个全局模型的训练,而是在每轮训练过程中,通过筛选的客户端本地模型与全局模型的相关性,来获得下一轮用于筛选客户端本地模型的阈值,对每一轮全局模型的训练进行筛选,使全局模型的每轮训练效果达到最优,从而使得最后的全局模型达到最优。
通过以上假设分析,根据上一轮全局模型与客户端本地模型的相关性与手动设定阈值之间的变化关系,设计了如式(2)所示自适应阈值更新算法来获得每一轮训练用于筛选客户端节点本地模型的阈值。其中,tk表示本轮每一个通过筛选的客户端本地模型与上一轮全局模型的相关性数值,T表示各个tk求和之后取小数点后一位获得新阈值(采用断尾法)。图3展示了获取新阈值的过程,累加通过筛选的客户端本地模型与全局模型的相关性数据,没有通过筛选的客户端本地模型与全局模型的相关性数据不进行累加,再对累加之后的数据计算平均值并取小数点后一位,将获得的数据作为下一轮全局模型训练用于筛选的新阈值。

图3 获取新阈值过程
接下来,将通过具体的实验对改进后的缓解联邦学习通信开销的方案进行测试,并结合区块链技术,实现去中心化的自适应权重趋势感知联邦学习。
3 实验与分析
3.1 实验设置
通过在联盟链Hyperledger Fabric[14]1.4 上部署十个客户端节点来模拟评估方案。设置十个客户端节点,使用经典的手写数字识别神经网络[15]和卷积神经网络[16]对联邦学习方案进行评估,每个客户端节点含有5 000 个训练数据,1 000 个测试数据,每轮训练随机使用300 个训练数据,100 个测试数据。实验设置了八个客户端节点,使用原始的手写数字识别数据集,两个客户端节点作为干扰节点,即无助于全局模型训练的节点,对干扰节点数据设定为含有80%的均值为0.6 和20%的方差为0.6 高斯噪声[17]的手写数字识别数据集。
3.2 实验结果与分析
3.2.1 自适应神经网络联邦学习
实验在基于区块链的联邦学习中测试自适应阈值更新算法对神经网络模型训练的效果。使用实验设置中的十个客户端节点来模拟大量参与联邦学习的场景。在训练开始,十个客户端节点同时参加联邦学习,观察使用不同阈值更新方式对基于区块链的神经网络联邦学习过程的影响。
如图4 所示,方块构成折线图表示使用固定阈值为0.8 的实验结果,圆圈构成折线图表示使用自适应阈值更新算法的实验结果。实验结果表明,随着全局模型训练的进行,使用了自适应阈值更新算法的模型训练效果优于使用固定阈值模型训练的效果,因为在训练过程中,使用自适应阈值更新算法的全局模型训练将干扰全局模型优化的客户端节点训练得到的本地模型进行了自适应筛除,有效减少了含有干扰数据的客户端本地模型参与到全局模型的聚合中。

图4 阈值选择方式对神经网络模型的影响
通过分析实验结果得出,干扰数据在训练到第三、四轮阈值自适应调整为0.9 时被筛除,但是在使用手动设置固定阈值时,如果直接设置阈值为0.9,实验发现在训练开始阶段没有一个客户端本地模型与全局模型的相关性能够达到这个数值,导致使用手动设置固定阈值方法无法筛除含有干扰数据的客户端节点。如图4 所示,使用动态阈值筛选方式的全局模型比使用阈值为0.8 时筛选算法的全局模型收敛的速度更快,并且全局模型的精确度更高,没有使用自适应阈值更新算法的全局模型精确度明显低于使用了自适应阈值更新算法的模型精确度,并且设置固定阈值为0.8 时,含有干扰数据的客户端节点还在继续参与全局模型的训练。固定阈值选择方式需要手动设置多个阈值,经过多次实验才能将阈值调整为可以筛除含有干扰数据的客户端节点的阈值,在面对客户端数据不确定的情况下,甚至都不能达到筛除含有干扰数据的客户端节点的效果,整个过程会占用大量的训练资源。
表1 所示为使用自适应阈值更新算法与使用固定阈值的筛选算法获得的模型精确度,以及减少计算开销和通信开销的数据。发现使用自适应阈值更新算法可以有效筛除含有干扰数据的客户端本地模型,相比较于使用固定阈值方式,自适应阈值更新算法可以减少获得机器学习模型的时间并且提高精确度。由表1 可以得到,在实验中,使用自适应阈值更新算法比使用固定阈值在进行模型训练时,减少了训练过程中20%的通信开销,并且提高了4.4%的模型精确度。
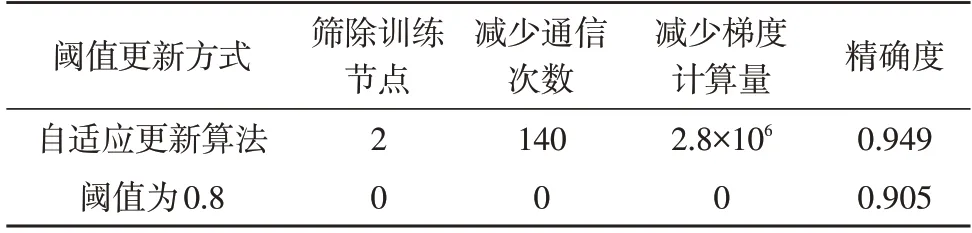
表1 神经网络筛选结果
3.2.2 自适应卷积神经网络联邦学习
实验在基于区块链的联邦学习中测试自适应阈值更新算法对卷积神经网络模型训练的效果。使用十个客户端来模拟大量参与联邦学习的情景,并在其中两个客户端的手写数字识别数据集中加入噪声以模仿含有干扰数据的客户端节点。为了进一步验证使用了自适应阈值更新算法能够更好地处理客户端数据不断更新的情况,实验在训练开始时和训练第65 轮时,将两个含有干扰数据的客户端节点分别加入到全局模型的训练中。在实验中发现,含有干扰数据的客户端节点训练的本地模型与全局模型相关性可以高达到0.8 以上,利用手动设置固定阈值递增的方式去寻找最优固定阈值,会占用大量训练资源。
如表2 所示,实验测试多个固定阈值下获得的全局模型精确度与筛除的客户端的数量,在卷积神经网络模型训练的实验中,自适应阈值选择方式不仅提高了通信效率,节约了区块链的计算资源,而且在获得最优模型的训练过程中节约了至少五倍的训练资源,因为通过递增寻找阈值0.8,需要进行多次的实验比较,并且训练刚开始设定阈值为0.9 就会出现全局模型无法训练的情况,该过程也会占用大量的训练资源。

表2 阈值选择方式比较
如表3 所示,表中统计了使用自适应阈值更新算法与使用手动设置固定阈值获得的模型精确度,以及减少计算开销和通信开销的数据。从表3 实验结果可以得到,在实验过程中,使用自适应阈值更新算法比手动设置固定阈值进行模型训练,可减少训练过程中10%的通信开销,并且提高了2.6%的模型精确度。如图5 实验结果显示,使用自适应阈值更新算法可以快速筛除含有干扰数据的客户端节点的本地模型,并且可以有效应对训练过程中客户端节点数据不断变化的情况。

表3 卷积神经网络的筛选效率

图5 阈值选择方式对卷积神经网络模型的影响
4 结束语
基于Hyperledger Fabric 区块链技术提出了一种自适应权重趋势感知的联邦学习方案。根据上一轮全局模型与每个通过筛选客户端本地模型的相关性与设定的阈值之间的变化关系,设计了一种简单有效的自适应阈值更新算法,使得在训练过程中能够根据相关性自适应调整用于筛选客户端本地模型的阈值。相比于传统联邦学习,该方案结合区块链进行实现,利用自适应阈值更新算法提高了干扰场景下的全局模型精确度,在训练过程中缓解了全局模型训练过程中的通信开销、减少了训练资源的占用以及提高了模型训练过程的隐私安全保障。
