中文大规模谜语问答数据集构建与评测方法研究
2023-12-14李建华陈涛贾旭东常青玲
李建华,陈涛,贾旭东,常青玲
(1.五邑大学 智能制造学部,广东 江门 529020;2.加州州立大学北岭分校 计算机科学与工程学院,加州 北岭 91330)
谜语是一种融合了多种语言现象的智趣游戏,猜谜者需要依据谜语所提供的表层信息,分析得出隐藏背后的答案[1].回答谜语是一个具有挑战性的认知过程,它需要非常复杂的推理能力.随着智能问答研究的不断深入,机器自动回答谜语越来越引起研究者的关注.Lin 等[2]首次提出一个回答常识性谜语问答的英文数据集RiddleSense,旨在测试机器进行自然语言理解所必需的能力,但由于语言文化的差异,该数据无法用于中文谜语自动问答任务.Tan 等[3]构建了一个中文汉字字谜数据集,并提出了一种通过从现有的汉字谜语中识别短语和字符之间的隐喻关联规则来求解和生成汉字谜语的方法,但该数据集注重汉字的结构,而不是字谜答案的含义.Efrat 等[4]提出了一个基于隐藏交叉字词的大规模文字游戏数据集,该数据集主要解决自然语言中文字游戏的歧义问题,兼顾了语言的复杂度和来源的便利性.Lu 等[5]围绕汉字嵌入模型对汉字进行研究.Han 等[6]研究了汉字特征分解对机器翻译的影响.Li 和Sun 等[7-8]将每个字符渲染成一个灰度图像,并将符号特征合并到字符嵌入空间中,使得汉字的文字信息纳入预训练语言模型中.上述研究均是对汉字本身的字形、结构和汉字字谜的生成进行研究,并没有利用语言模型对汉字谜语问答做出探索,因此,构建一个中文汉字谜语问答数据集,利用现有的自然语言处理技术解决谜语问答问题是十分必要的.
在建立通用智能问答数据集方面,Yang 等[9]提出了WikiQA 开放域问答数据集.Rogers 等[10]对近年来的问答和阅读理解任务的基准数据集进行了综述.Huang 等[11]提出了一种常识问答数据集COSMOS QA.Talmor 等[12]提出了CommonsenseQA 数据集.常识问答数据集里的问答描述比谜语更容易理解和推理,解答谜语不仅需要常识,还需要逆向思维.一般的常识性问题会引导读者找到正确的答案方向,而谜语往往会故意误导人类.此外,机器还需要理解谜语语言的比喻和模糊效果,与常识问答相比,解答谜语更加困难.随着智能问答模型在通用问答数据集和常识问答数据集上的性能越来越好,难度更高的谜语智能问答也越来越引起大家的关注.
因此,构造一个大规模多类型的中文谜语数据集,对于弥补现有中文谜语数据集的缺失,推动中文谜语智能问答的发展具有重要意义.本文拟提出一个中文大规模多类型谜语问答数据集及其构建方法,希望该谜语数据集能够作为衡量智能问答模型对语言文字和常识的深层理解能力的基准数据集被使用,也希望通过本文提出的数据集构建方法能够构建出更多质量更好的谜语数据集,推动中文谜语自动问答的发展.
1 中文大规模多类型谜语问答数据集构建方法
本节分两个步骤介绍创建中文大规模谜语问答数据集(以下简称MDRiddle 数据集①https://github.com/canwuying/MDRiddle)的方法,第一步收集与整理谜语,第二步生成人工与机器相结合的干扰选项.
1.1 谜语的搜集与整理
汉谜网②汉谜网:http://www.cmiyu.com/、语文迷③语文迷网:https://www.yuwenmi.com/my/和便民查询网站④便民查询网:https://naojinjizhuanwan.bmcx.com/上包含了大量不同类型的谜语,种类包含动植物谜语、脑筋急转弯、数字和汉字等谜语.本文从这些网站上爬取了20 989 对中文谜语问题答案对.爬取的数据包含许多噪声,例如一些字词的错误拼写、乱码、重复数据等.通过对数据进行清洗得到18 066 条干净的谜语.另外还有一类谜语属于多种类型谜语的问题,处理方式是把它归类于某一类谜语,例如“什么字永远也写不好?——孬”既属于脑筋急转弯谜语也属于汉字谜语,根据脑筋急转弯的特性把这种谜语归类于脑筋急转.又如“旭日东升——9(九)”既属于汉字谜语又属于数字谜语,谜题答案更侧重数字就归类于数字谜语.此外对于汉字谜语中不同的谜语问题对应同一个汉字的情况,本文把它们算作不同的汉字谜语,因为它们对同一个汉字的描述是完全不同的,例如“出口国外——回”和“洞中有洞,孔中有孔——回”,虽然谜底均为“回”字,但谜题描述不同,则不算作重复谜语,在第4 节统计了汉字谜语出现频次较高的谜题.最后得的18 066 条谜语问答对,其中中文脑筋急转弯1 000 条,中文数字谜语300 条,汉字谜语16 766 条.
1.2 干扰选项生成
由于谜语问答既需要常识知识,同时又要具有反常识思维,因此,无论对人还是机器,在没有参考范围的情况下,仅阅读谜语中的问题直接回答谜语是十分困难的.前期实验表明当前主流问答模型在MDRiddle 数据集上的性能过低,无法充分发挥数据集的价值.为了降低任务的难度,本文采用选择题问答的方式来比较人类与问答模型在谜语问题上的推理能力.通过给正确答案添加干扰选项,让机器从多个选项中选择一个正确答案,比直接回答问题难度降低了很多.
在选择题问答任务中,干扰选项是与正确答案相似或相近但又不能是正确答案的答案.例如谜语问答“什么鱼不是鱼——(A)鲨鱼、(B)美人鱼、(C)金鱼、(D)鳄鱼、(E)娃娃鱼”中“美人鱼”是正确答案,“鲨鱼”、“金鱼”等其他选项为干扰选项,可以看出“鲨鱼”、“金鱼”等干扰选项满足“什么鱼”而不满足“不是鱼”这一范畴,而“美人鱼”这个答案同时满足了谜题中是否为“鱼”的矛盾.这表明干扰选项在“鱼”这个特征上与正确答案一致,区别在于“不是鱼”这一特征.高质量的干扰选项对于多项选择题回答任务是必不可少的,人工为每个正确答案编写干扰选项是非常昂贵和耗时的,而机器自动生成的干扰项又往往质量不高.因而,对于大规模问答数据集来说要获得高质量的干扰选项是具有挑战性的[13].
基于上述考虑,本文遵循主流谜语问答数据集(BiRdQA[14]、RiddleSense[2])构造干扰选项的数量,采用人工编写与机器自动生成相结合的方式为每条谜语产生4 个干扰选项.Zhang 等[14]将干扰项分为全局干扰项和局部干扰项,其中采用Song 等[15]提出的干扰项单词嵌入的余弦距离与正确答案相近的称为全局干扰项,考虑到谜语类型的特性和数据集数量多少的原因,本文仅限在脑筋急转弯数据集上通过人工替换或增减正确答案选项的单词或通过谜语和常识结合联想获得全局干扰项.例如,从谜语“什么东西是你左手能拿而右手不能拿的——(A)脑袋、(B)左手、(C)右手、(D)胳膊、(E)脚”中的正确答案“右手”联想到“左手”、“脚”、“胳膊”、“脑袋”等人体躯干.局部干扰项是从其他问题的正确答案中提取出来的,例如“扭头走开——丑”与“提前出发——选”两个字谜中的“丑”和“选”互为局部干扰项.
由此可见,全局干扰项往往干扰能力更强,但设计难度也更大,通常需要人工完成.本文主要为1 000 条中文脑筋急转弯人工设计了共4 000 个干扰项,其中大多数是全局干扰项.为了保证干扰项的可信度和对抗性,人工编写干扰项时设计了以下规则:1)干扰项应是人们更容易想到的,容易出错的;2)与正确答案相似或相近但又不能是正确答案;3)干扰项是限定在一定范围内与谜题内容是有关联的.
为了避免生成的干扰选项成为正确答案,本文通过人工检查、筛选词汇重叠的干扰选项,例如“星星”和“恒星”可以认为是一样的,以及一个谜语中存在两个或两个以上的正确答案的情况,例如谜语“什么泥不长草——橡皮泥”中,干扰项“跳跳泥”与“橡皮泥”实际上是同一种物品的不同称呼.在检查筛选时将类似上述情况的答案人工替换成其他选项.
2 数据集分析
本节对MDRiddle 数据集的关键数据进行统计和分析.MDRiddle 数据集中各类型谜语占比情况统计如图1 所示,从图中可以看出汉字谜语在MDRiddle 数据集中所占比重最大,达到了93%,其次是脑筋急转弯占比5%,中文数字谜语占比最低,仅为2%.
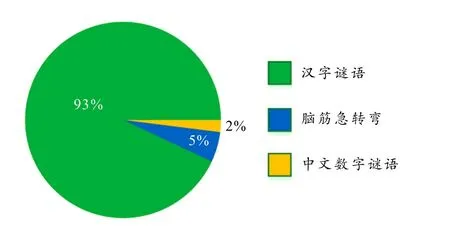
图1 MDRiddle 数据集中各类型谜语占比情况统计
此外,对MDRiddle 数据集中各类型谜语问答数据的训练集、开发集和验证集进行了统计,统计结果如表1 所示.其中,各类型数据集中训练集、开发集与测试集占比均为8:1:1,,脑筋急转弯的平均长度和最大长度都远长于其他类型的谜语,字谜的长度一般较短.由此可见,脑筋急转弯需要较多文字才能描述清楚,而字谜中提供给解答者的信息含量最少.
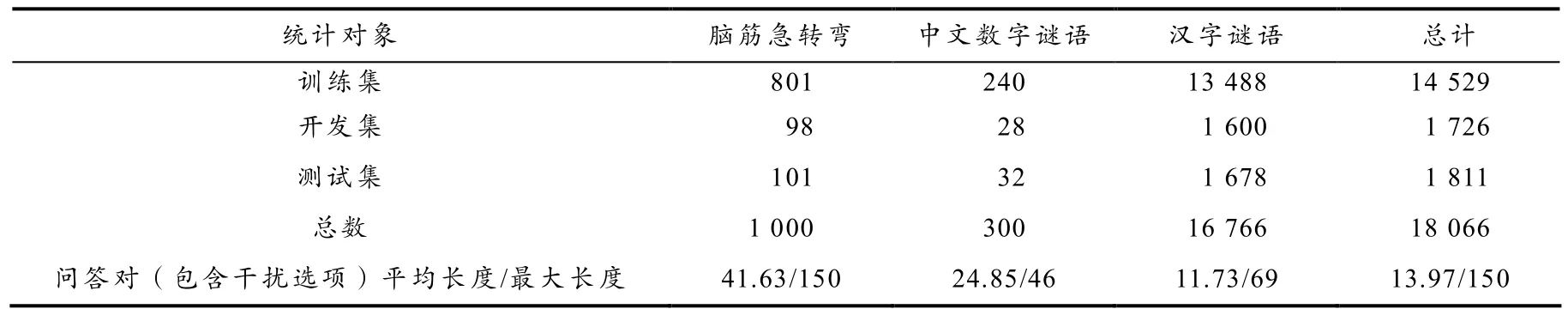
表1 MDRiddle 数据集的统计信息
本文的 MDRiddle 数据集的谜底除了中文谜底外还包括少量英文单词谜底和阿拉伯数字谜底.例如脑筋急转弯“世界上最长的单词是什么?——smiles”中正确答案就包含英文单词.通过观察1 000 个脑筋急转弯谜语,只发现9 个谜语包含跨语言文本.而中文数字谜语和汉字谜语只包含阿拉伯数字和汉字,不存在跨语言问题.
此外,在汉字谜语中,对同一字谜的答案有不同的描述,但它们不是重复的谜语,例如“任人宰割”和“一千”都是以“壬”作为答案.本文统计了答案相同问题描述不同的出现频率最高的前10 个字,如表2 所示.

表2 MDRiddle 数据集中最常见答案出现频率统计
BiRdQA[14]和CC-Riddle[16]是与本文最相近的两个数据集.其中,BiRdQA 包含6 614 个英文谜语和8 751个中文谜语,每个谜语选项都包含对应的维基百科和百度百科的注释,每个中文谜语的问题包含一个小提示,干扰选项采取人工结合答案库抽取的方式半自动生成.CC-Riddle 包含34 656 条字谜,其中27 524 条由人工搜集,7 132 条由模型自动生成.本文与上述工作的不同之处在于:1)本文提出的数据集涉及的范围更广泛,不仅包含各种除人以外的实体,还包含人的各种动作和器官作为谜底,而BiRdQA 和CC-Riddle 只包含动植物实体、成语和汉字等;2)本文提出的数据集谜语类型更多,包括脑筋急转弯、中文数字和中文汉字等多种类型,上述两个数据集均不包含脑筋急转弯和中文数字谜语,由于每种类型谜语的解答思维方式不同,因而更具有挑战性;3)本文提出的数据集中的中文汉字谜语包含额外的干扰选项,CC-Riddle 中只包含问题答案对,而BiRdQA 中虽然也包含干扰选项但剔除了答案超过五个单词或符号的谜语.
3 实验
本节采用选择题问答(选项固定为5 个)的方式对当前主流问答模型在MDRiddle 数据集上的性能进行评估.
3.1 评价指标
准确率是一些选择题问答任务(如ARC[17]和OpenbookQA[18])常用的评价指标.其计算公式如下:
其中,P表示回答正确的谜语数量,Q表示全部谜语数量,Acc 表示准确率.Acc 值越高,模型效果越好.
3.2 基线方法与参数设置
给定一个谜题,有5 个不同的答案{c1,…,c5}供选择,其中只有一个是正确答案,其他都是干扰选项.智能问答模型需要对所有的选择进行评估,并选择其中一个作为最终的答案.最近的研究表明,大型预训练语言模型,如BERT[19]、RoBERTa[20]和ALBERT[21]在很多问答任务上都取得了较好的成绩,本文使用上述模型对MDRiddle 数据集进行评测,本实验所采用的基线及其变种模型有:
1)BERT_base_chinese①https://huggingface.co/bert-base-chinese模型是一个将 BERT 模型在大规模中文语料预训练得到的模型,具有12 个Transformer 编码器层,其中每层具有768 个隐藏单元和12 个自注意力头,总共有1.1 亿个参数,具有较强的中文语言理解能力.
2)Chinese_MACBERT_base②https://huggingface.co/hfl/chinese-macbert-base模型是一个基于BERT 模型框架的中文预训练语言模型,编码器层与参数量与BERT 模型一致,训练数据包含新闻、百科和论坛等多种领域文本,因此在处理多领域、多种风格的文本方面具有较强的泛化能力.
3)Chinese_BERT_wwm_ext③https://huggingface.co/hfl/chinese-bert-wwm-ext模型是基于BERT 模型的改进模型,采用了“whole word masking”(wwm)技术,将整个词作为一个单元进行mask(不将词拆分单个字符).这样做的优点是可以更好地处理中文语言中词语的内部复杂结构和相对固定的词序.
4)ALBERT_base_chinese④https://huggingface.co/hfl/chinese-roberta-wwm-ext-large模型作为BERT 模型的改进型,训练数据更多,模型更小,参数更少,在多种NLP 任务上效果更好.
5)Chinese_RoBERTa_wwm_ext_large⑤https://huggingface.co/uer/albert-base-chinese-cluecorpussmall模型采用RoBERTa 模型的架构,使用比原始RoBERTa模型具有更多的训练数据、更长的序列长度和更多的训练轮数,采用了和Chinese_BERT_wwm_ext模型一样的MLM 技术,可以更好地处理中文文本.
本文在Python3.10,Pytorch1.13 环境下实验.BERT_base_chinese、Chinese_MACBERT_base、Chinese_BERT_wwm_ext 和ALBERT_base_chinese 的学习率设置为5e-5,批训练大小为16 Chinese_RoBERTa_wwm_ext_large 学习率设置为3e-5,批训练大小为8.实验所有模型训练迭代次数为20 次,序列最大长度设置为128.本实验邀请了3 名以中文为母语的研究生进行人工回答谜语实验,从测试集中随机筛选200 条谜语,要求他们不能参考任何资料,仅凭自己已有知识回答谜语问题,然后计算3 人的平均准确率作为人类谜语问答的得分.
3.3 实验结果与分析
主流问答模型及人类在 MDRiddle 数据集的实验结果如表3 所示.从表中可以看出,ALBERT_base_chinese 模型在5 个主流问答模型中表现最好,取得了37.56%的准确率,但与人类解答谜语有77.33%的准确率相比,还存在明显的差距,这表明现有主流问答模型在解决谜语问答方面还有较大的提升空间.

表3 MDRiddle 数据集的谜语问答实验结果 %
从3 种不同类型的谜语子集上的结果来看,主流问答模型在脑筋急转弯上的表现均好于其他两种类型谜语上的表现.其中,主流问答模型在脑筋急转弯上的最好成绩达到了71.27%,较接近人类的水平,而在中文数字谜语和汉字谜语上的最高准确率分别只有51.72%和39.50%.可能的原因是脑筋急转弯的平均长度和最大长度都远长于其他类型的谜语,具有较多的文字描述,使上述基于预训练的问答模型能够从预训练网络中找的更多的“依据”来回答问题,而中文数字谜语和汉字字谜的长度较短,信息含量最少,基于预训练的问答模型难以发挥作用.此外,本文在构造干扰选项时,脑筋急转弯中的全局干扰选项较多,中文数字谜语和汉字字谜中的局部干扰选项较多,也是一个可能原因.
关于谜语问答中干扰项类型分布,脑筋急转弯主要采用全局干扰项(约占5%),数字谜语和汉字谜语采用局部干扰项(约占95%).类似物种种类替换与反常识替换这样的干扰项只存在脑筋急转弯中,考虑到脑筋急转弯数据集在MDRiddle 中占比较小,物种种类和反常识替换的干扰项数量更少(分别占MDRiddle 数据集中全部干扰项的约0.4%和1%),因此,物种种类和反常识替换类干扰项对模型影响也会较小.
为了验证主流问答模型在不同类型谜语上的泛化能力,本文还在MDRiddle 数据集上对主流问答模型进行了跨类型迁移谜语问答实验.该实验将不同类型的谜语两两组合成训练集,另一类型数据集为测试集,其中训练集数量为两类型谜语组合成一起为1 500 条,测试集受数字谜语数量限制,每个类型为300 条.例如以“脑筋急转弯+数字谜语”作为训练集,以“汉字谜语”作为测试集,将脑筋急转弯和数字谜语混合后,从中随机的抽取1 500 条输入到问答模型进行训练,然后从汉字谜语中随机抽取300 条谜语对训练好的模型进行测试.跨类型迁移谜语问答实验结果如表4 所示.从表中可以看出,目前主流的问答模型在跨类型迁移谜语问答上的效果较差,大多数结果仅比五选一随机选择概率(20%)稍高,最好成绩也仅有34.21%.由此可见,目前主流问答模型在跨类型迁移谜语问答任务上还有较大的改进空间.

表4 跨类型迁移谜语问答实验结果 %
考虑到不同干扰项数量对问答模型的影响,本文设计了相关的实验.该实验从MDRiddle 中随机抽取1 300 条谜语问答数据,在每条谜语问答原有的4 个干扰项上分别随机去除1、2、3 个干扰项和增加1 个干扰项,加上原有4 个干扰项不变的谜语问答数据,将1 300 条数据分别变为1、2、3、4、5 个不同干扰选项数量的数据集,每个数据集的训练集和测试集按照8:2 的比例分配,5 种基线方法在上述5 个数据集上的实验结果如表5 所示.
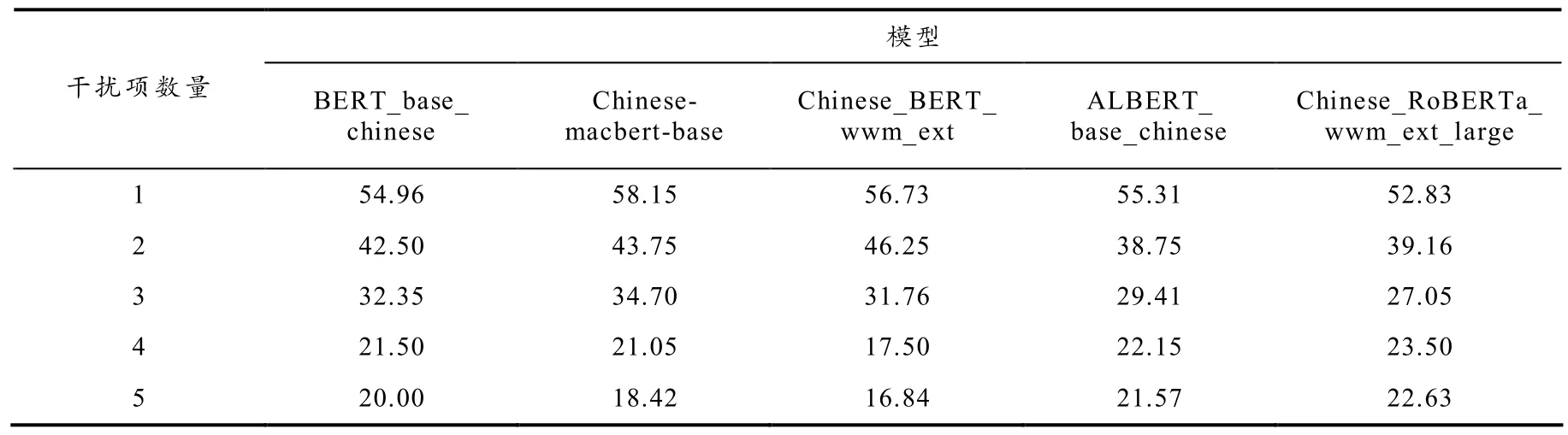
表5 不同干扰项数量的谜语问答实验结果 %
从表5 中可以看出随着干扰项数量从1 增加到5,模型回答谜语问题的能力逐渐减弱,其中干扰项数量从1 增加到4,模型回答谜语问题减弱趋势较大,干扰项数量从4 到5,模型回答谜语问题减弱趋势变小.考虑到现有的谜语问答数据集(如RiddleSense、BiRdQA)均采用4 个干扰选项,因此,本数据集在构造时亦选取4 个干扰选项.
3.4 错误案例分析
下面简单分析Chinese_RoBERTa_wwm_ext_large 模型在3 种类型谜语问答上的预测错误案例.例如,脑筋急转弯“什么东西越洗越脏——(A)金、(B)木、(C)水、(D)火、(E)土”被模型错误预测,该谜语利用了人类的常识知识和发散的思维方式,对于“什么东西越洗越脏”这个问题,一般人首先不会想到“水”,而是“水”洗什么东西会脏,干扰项是由“水”联想到中国传统文化中的其他五行属性“金”、“木”、“火”、“土”生成的.又如数字谜语“7÷2(猜一成语)——(A)三番五次、(B)接二连三、(C)不三不四、(D)一丝不苟、(E)无独有偶”,该谜语的解答需要分两个步骤:首先要算出结果“3.5”;再由“3.5”联想出这个数既不是“3”也不是“4”;最后得出答案“不三不四”.模型预测的答案是“三番五次”,该选项虽然包含“3”和“5”两个数字,但不能解释“3.5”这个答案的含义.最后,汉字谜语“才下眉头,又上心头.”要结合汉字的结构知识和汉语文化知识才能答对,谜底是结合谜题的含义将“眉”字里的“目”和“心”字里的“丿”组成“自”这个字.从上述案例中可以看出,目前主流的问答模型要回答上述谜语还是有一定难度的,本文提出的谜语数据集可作为衡量智能问答模型对语言文字和常识的深层理解能力的基准数据集使用.
4 总结
本文构建了MDRiddle 数据集,然后用几个主流智能问答模型对该数据集进行了评测.实验结果表明目前主流问答模型在谜语问答任务上与人类水平差距明显,还有很大的改进空间,MDRiddle数据集的发布能够激发更多关于谜题的研究,推动中文谜语自动问答的发展.在未来的工作中,计划在MDRiddle 数据引入外部知识(百科知识和知识图谱等),并且为每个谜语问答生成一个思维链(Chain of Thought,CoT),也就是从问题到答案的推理过程,使谜语问答模型的解答能够有更好的可解释性.
