面向新浪微博的Top-N突发事件检测方法
2023-12-07徐洁
徐 洁
(徐州工业职业技术学院,江苏 徐州 221000)
0 引言
新媒体背景下,以微博、新闻客户端、微信等为代表的移动社交网络平台兴起,地域不再是限制突发事件影响力的因素,事件一旦爆发,其影响的深度、广度会急剧扩大,对国家安全和社会安定造成威胁[1]。新浪微博作为当下主流的社交网络平台,拥有海量的活跃用户。人们可以自由地在平台上发表言论,通过博文的发表、转发、点赞与评论,各种消息传播都极为迅速。很多突发事件相关信息都是先在微博上爆发,随后主流媒体才报道。微博成为人们迅速感知社会热点事件和参与社会热点事件讨论的重要平台[2]。从微博博文中获取数据价值,挖掘有效信息,进行事件检测,分析舆论态度,可以更好地指导相关部门进行舆情管控。因此面向微博的事件检测成为突发事件检测的研究热点。
本文主要面向新浪微博数据进行事件检测,对新浪微博网络数据进行采集与预处理,检测词的突发性以获取突发特征词集,对突发词进行聚类生成突发词簇,对突发词簇热度进行排序,从而检测出微博网络Top-N 突发事件,对把握公众动态、促进社会和谐有着积极的意义。
1 微博Top-N突发事件检测实现
1.1 系统框架
本文基于新浪微博数据进行突发事件检测,搭建出系统框架图如图1所示。
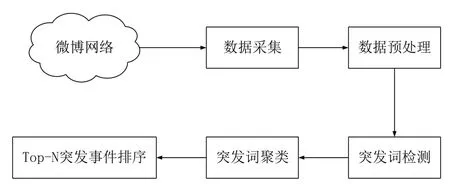
图1 面向新浪微博的Top-N突发事件检测系统框架
1.2 数据采集
本文所用的实验数据为采集的新浪微博数据。对于新浪微博数据的获取,通常有两种方式:第一种是通过新浪微博提供的应用程序编程接口(Application Programming Interface,API) 获取新浪博文数据;第二种是采用Python 编写代码实现网络爬虫。一方面,考虑到微博数据传播速度快、数据噪声多等特点;另一方面,考虑到爬虫所带来的道德风险和法律责任,本文最终采用第一种新浪微博提供的API 获取数据。
在正式开始进行数据采集之前,需要登录微博开放平台创建应用,按要求填写相关信息,基本信息中“App Key”和“App Secret”是获取微博API使用权限的关键,这相当于一个通行证,只有获得许可后才可以申请到开发者身份,然后才可以根据API 文档构造API参数。高级信息中 “Oauth2.0授权设置”模块设置两个回调地址,在Oauth2.0 认证通过后会返回Acess Token。之后便可以用“App Key”和“App Secret”获得访问密令并使用API提供的不同服务的接口[3]。
1.3 数据预处理
微博作为一个分享实时、简短信息的社交网络平台,用户在发表博文的时候具有很强的随意性,由此采集下来的源数据包含较多的无用信息,需要对其进行过滤,以提高后期的计算效率与准确度。
根据微博文本的特点,需对博文进行如下预处理:
1) 去除博文中的无用标记:对文本中的网址链接、“@”符号、“#”符号、“//”符号、表情符号等无用标记进行过滤删除。
2) 去除字数过少的博文:长度小于5个字的博文不具有分析价值,直接进行删除。
3) 中文文本分词:利用jieba 分词对博文进行分词,去除停用词,保留名词和动词[4]。
1.4 突发词检测
根据突发词的特性,本文提出融合词频热度、词频增长率以及词频权重的词突发性计算模型[5]。
1.4.1 词频热度
在某一时间段内,若某个词汇的出现频率明显上升,则可以认为在这段时间爆发了与该词汇相关的突发事件。
1.4.2 词频增长率
假设当前突发事件检测的时间段为t,与此前相邻的h个时间段的历史数据进行分析对比,根据数据获取与分析的成本综合考虑h的设置。但历史数据不宜过多,一方面历史数据的采集与分析会消耗大量时间,另一方面过量的历史数据会影响突发事件的实时检测。词增长率的计算公式如下:
其中,Fw,t表示在t时间段内词汇w的增长率,Nw,t表示t时间段内词汇w出现的频率,Nw,h表示与t时间段相邻的h时间段内词汇w出现的频率,Nw,n表示在n时间段内词汇w出现的平均频率。
1.4.3 词频权重
为保证突发事件发生时一些事件关键突发词具有较高的权值,对传统的TF-IDF方法进行了改进,计算公式如下:
其中,μ为词频权重初始值,Nmax,t是t时间段内最大词频数。
综合上述三个指标,最终计算词语w在t时间段内的突发值为:
其中,Mw,t表示词语w在t时间段内的词频热度,α、β、γ为调节系数,α+β+γ=1,α≥0,β≥0,γ≥0。
Bw,t越大,说明词w在t时间段内的突发性越大。计算出博文集中每个词的突发值后,按照词突发值进行降序排序,得到突发特征词集SW。
1.5 突发词聚类
基于获取的突发特征词集SW,构建出突发词关联网络SWN=(SW,R),其中R 为突发词之间的相关程度,词Wi、Wj的相关程度通过计算其在同一条博文中出现的次数获得。
得到突发词关联网络SWN 之后,通过开源的CLUTO 工具包对其进行聚类,从而得到突发词簇SWC={swc1,swc2,…,swcq}。CLUTO 提供3 种聚类算法,结合实际情况,本文采用凝聚层次聚类方法[6]。
1.6 突发事件排序
人们乐于在微博上发表与美食、明星、旅游等相关的博文,与这些主题相关的词汇出现频率会增高,而此类事件并不是突发事件。因此需要对经过聚类得到的突发词簇SWC按照热度进行排序,提取出更加准确的Top-N突发事件。
词簇swci的热度计算综合了词簇swci频率Fswci、词簇swci相关博文MNswci、词簇swci相关博文影响力MBIswci以及词簇swci相关用户UNswci4 个指标,计算方式为:
2 实验与分析
2.1 实验数据与评价指标
本文所使用的数据集来自新浪微博,采集了2023年4 月1 日和31 日共计约800 万条数据,包含原博文内容、评论内容、点赞数、转发数及相关用户信息等。以天为单位,验证各种事件检测方法的有效性。
通过访问多个新闻媒体平台,提取出4月1日~30日期间多平台共同报道的热点事件如表1所示。

表1 多平台媒体报道的突发事件
由于突发事件的发生是未知的、不可预测的,所以参考目前主流的研究方法。使用查准率P,查全率R和F1值作为评价指标。计算公式如下所示:
其中,x1表示使用本文方法检测出的突发事件与相应时间段内媒体报道的突发事件切合的事件数,x2表示检测到媒体未报道的突发事件数,x3表示未检测到媒体报道的突发事件数。
每天检测出的Top-N 突发事件与媒体报道的突发事件相比较,人工判断是否为突发事件。突发事件不可能每天发生,Top-N 检测出的事件数量较少,所以人工评测并不耗时耗力。
2.2 实验结果与分析
使用本文提出的方法进行微博网络突发事件检测,与利用传统的TF-IDF 方法进行词频权重计算的模型进行对比,实验结果如图2所示。
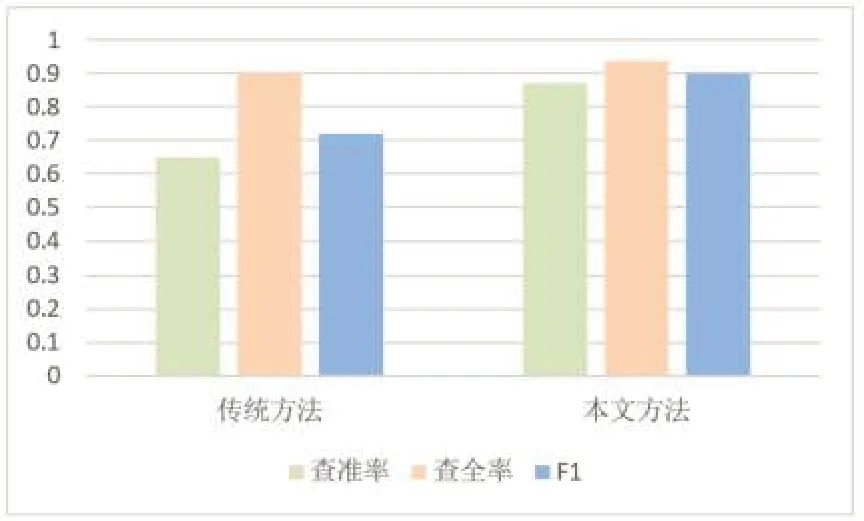
图2 实验结果对比
从图中可以看出,利用本文提供方法,各评价指标都有所提升。同时还检测出某些媒体未报道的“女子泼水节被众男子围着泼水撕雨衣”等社会民生类事件,在突发事件的检测方面有着良好的效果。
3 结束语
本文搭建了面向新浪微博网络的Top-N 突发事件检测的系统框架,包括博文数据的采集、博文的预处理、突发词的检测、突发词的聚类、突发事件热度排序等模块,对实际应用具有一定的参考价值,对突发事件的检测起到了较好的效果。在后续的研究中,还有下列问题需要进一步探讨:1) 面对大量的博文数据,如何实现更加准确的事件的实时发现与检测,需要引入大数据处理技术进一步地研究;2) 针对特定类别的突发事件,建立特定类别的事件检测模型,以更加准确地发现特定类别的突发事件。
