基于ReLASL算法的网络入侵检测模型
2023-12-07程磊满颖慧
程磊,满颖慧
(陆军军事交通学院镇江校区,江苏 镇江 212000)
0 引言
深度学习是机器学习领域的一个分支[1],相较于传统机器的学习技术,深度学习可以更加高效地学习样本数据的内在规律,当其应用于入侵检测系统时能够充分地挖掘流量数据中蕴含的各种信息,大幅提高系统检测精度,降低系统的检测成本。常用深度学习算法有卷积神经网络(Convolutional Neural Network,CNN) ,循环神经网络(Recurrent Neural Network,RNN) ,深度信念网络(Deep Belief Network,DBN) 等。通常入侵检测系统训练深度学习模型时对样本数据的规模以及分布情况都有一定的要求,而当前网络攻击手段变化较快,且网络数据中正常样本数据较多,异常样本数据较少,样本数据分布不平衡,导致可用训练样本较少,这就需要入侵检测系统能够具备小样本训练的能力。
可靠标签选择与学习的半监督学习算法Reliable Label Selection and Learning Base Algorithm for Semi-Supervised Learning,ReLSL) 可以进一步降低半监督算法对标记数据的依赖,避免由于初始信息量较少导致的模型启动困难以及伪标签噪声比困难导致的模型崩溃等情况,提高检测准确率[2]。本文对ReLSL 算法进行了研究,并通过自适应的方法对ReLSL算法中部分超参数进行了优化,提出了一种基于可靠标签选择与学习的自适应半监督学习算法的网路入侵检测模型(Reliable Label Selection and Learning Base Algorithm for Adaptive Semi-Supervised Learning,ReLASL) ,相较于入侵检测系统常用的深度学习模型,该模型能够适应网络数据分布不均衡的特点,可以通过较少的训练样本标签实现快速、准确地识别网络行为。
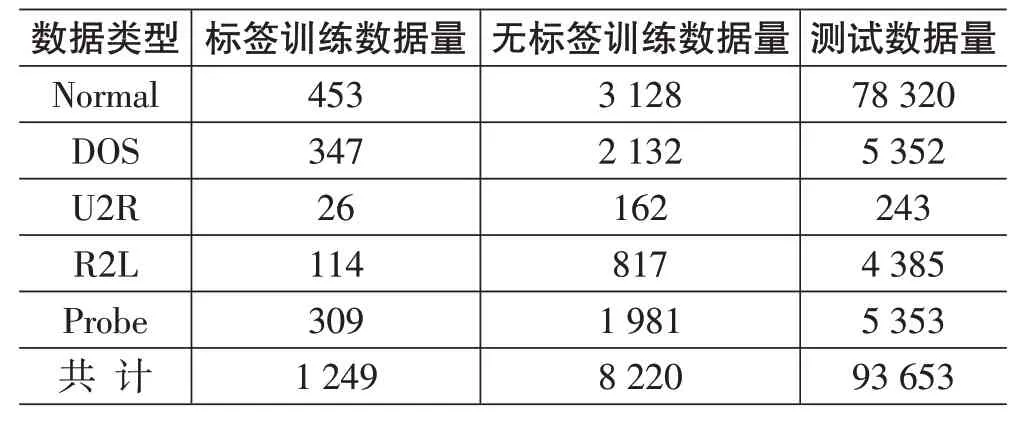
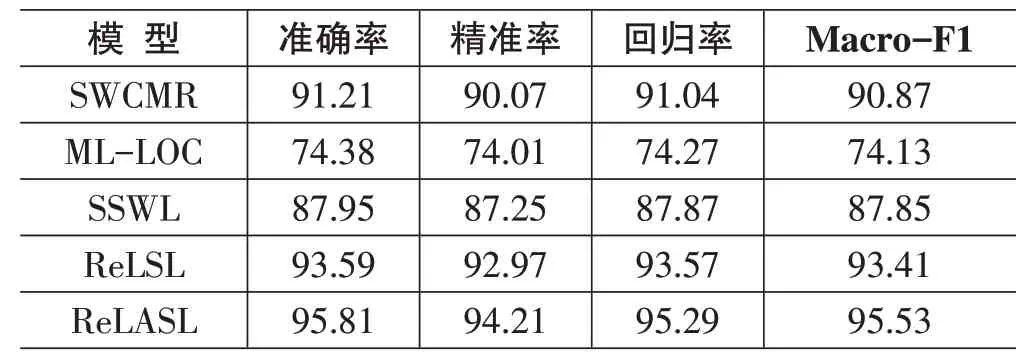
ReLSL算法将半监督学习(Semi-Supervised Learning,SSL) 问题转化为在数据集Α上训练深度学习神经网络ϕ(⋅),用于C分类问题[2],数据集Α包括无标签数据集与标签数据集,其中,为标签,通过one-hot向量表示,维度为C,在极少标签样本情况下,即KM< 特征提取与基于图的标签传染主要目的对无标签样本进行标定,主要分三个步骤,一是特征提取,即使用(Anchor Neighborhood Discovery,AND) 算法提取数据集Α 特征ei=φ(xi),其中φ(⋅)为AND 网络,采用了ResNet50结构;二是计算相似度,即采用式(1) 根据提取特征计算样本相似度矩阵S,并通过式(2) 对S进行规范化处理。 其中,α为超参数,值越大代表样本特征距离越大,相似度越小。 三是标签样本标定,即通过式(3) 获取伪标签隶属度向量。 其中,γ表示跳向相邻节点概率,I为单位矩阵,Y与Y′是维度相同的初始化标签矩阵,当获得Y′后,还需将其彻底转化为one-hot 向量,最终处理得到标签样本矩阵。 由于初始的训练标签样本不足,仅通过标签传染的方式还无法保证伪标签标定的准确率,因此需要对伪标签样本~Y'进行再学习与重新标定,ReLSL算法应用WRN-28-2 网络结构训练模型φ(⋅),并引入一致性惩罚项对φ(⋅)损失函数进行优化,如式(4) 所示: 为进一步准确挑选正确标记样本,算法通过记录样本训练后期的输出损失,综合训练损失的均值与方差,确定最终的标签样本,即由式(5) 确定标签样本。 其中,lossce(-ep:)表示样本xi在模型训练最后h次迭代获得的损失。 ReLSL算法计算每个训练样本的chi值后,以此为依据,对φ(⋅)输出的one-hot 标签进行排序,并保留前m 个样本,其余样本重新标定为未标记样本,则最终标定训练数据集记为Α′ 标签数据集为无标签数据集为,,在极少标签条件下 ReLSL算法使用LS与MSC策略进行半监督学习,LS策略是为缓解由错误标记导致的无法修正问题,即对Α′M样本中标签yi进行等比例平滑,如式(6) 所示。 其中: ε为平滑系数,随迭代逐渐变小,η为0 到1 之间的均匀采样随机数,λ为平滑因子,λ值越小,则输出的向量越平滑。针对yi,ReLSL 算法则是采用了指数加权平均操作,即对样本每次的输出结果进行了加权平均: 其中,ϕ(xi)表示样本xi在模型φ(⋅)训练时第t-1次迭代时的输出向量,为样本xi在第t-1次迭代时的移动平均值,δ为动量权重,主要用于控制更新力度。MSC 策略主要为降低错误标签以及扰动对模型训练的影响,首先通过式(8)对数据集Α′中每个样本在Softmax的输入向量进行指数加权平均操作。 进而对每一虚拟类中的输出进行平均操作,而对于无标签数据∈ΑN的输出向量,ReLSL算法采用了损失函数式(9) 进行了偏移校正。 ReLASL入侵检测模型充分利用ReLSL算法小样本训练的优势的同时根据网络样本数据分布情况,改进了ReLSL 算法超参数设置方法,保证能够快速、高效地检测网络异常数据。 相对于ReLSL,ReLASL 仅对特征提取与标签传染、伪标签学习与标定进行了改进,因此仅对改动部分做具体介绍。 本文特征学习方法同样选用AND 算法,采用ResNet50 结构提取训练样本特征值,获取特征。由于网络样本数据量较大,相同类型的数据特征值之间的距离差较大,无法通过简单的特征值距离计算相似度矩阵͂,因此引入样本特征值平均距离的概念改进式(1) 超参数α取值,通过该样本特征值与其他样本特征值平均距离决定对远距离样本的敏感程度,当样本特征值距离小于样本平均特征距离时,特征距离相差较大样本相似度越小,反之,特征距离相差较大样本相似度越大。如式(10) 所示。 而后通过式(2) 与式(3) 获取稳定的标签矩阵Y′,并按照原方法将其处理生成标签样本。 为进一步提高伪标签标定的准确率,同样采用WRN-28-2 网络结构训练模型φ(⋅),并引入一致性惩罚项对φ(⋅)损失函数进行优化,通常网络异常数据占比较小,噪声数据较多,增加了训练的不确定性,因此在伪标签学习与标定阶段,通过构建的异常数据集,以降低噪声样本的影响。异常数据集主要通过不断积累历史训练样本中的异常数构建而成,因此对式(4)中超参数β赋值如下: 当样本xi与平均距离较大,表示xi为噪声样本可能性较大,则损失函数需更加关注对标签的一致程度,反之,则更应关注其对样本的输出稳定性。 为进一步提高模型训练的效率,缩短模型收敛的时间,对损失函数中的超参数ς进行了进一步的优化,如式(12) 所示: 其中,Maxepoch为训练最大迭代次数,Currentepoch为当前迭代次数,从而引导损失函数先进行大幅度偏移校正快速接近收敛区域,再进行小幅度偏移校正保证损失函数能够更快地达到收敛状态。 基于ReLASL 网络入侵检测模型训练过程如下所示: 输出:训练完成的ReLASL入侵检测模型; 1) 采集网络数据并对数据进行预处理,构建onehot向量表示的入侵数据集。 2) 采用AND 算法提取样本特征值(ResNet-50结构)。 3) 采用式(10) 计算特征值相似度矩阵,通过式(2)与式(3) 获取稳定的标签矩阵Y′,并对其中的无标签样本进行处理,通过最大值将其转化为one-hot向量,最终获得标签矩阵。 4) 采用WRN-28-2网络结构训练模型φ(⋅),其中优化函数为式(4) 、式(11) ,并通过式(5) 最终确定标签样本。 5) 根据式(6) 最确定的标签样本进行平滑操作后代入监督学习losssl中进行训练,同时将式(9) 与式(12)代入半监督学习lossssl中进行优化。 6) 采用训练模型进行网络异常数据检测。 为验证本文提出入侵检测模型,使用KDD99数据集进行评价[3],该数据集包含了500多万数据,其中每个数据集包含了1 个标签与41 个特征。本文使用了9 469 个训练数据和93 653 个测试数据,其中训练数据包括了8 220个无标签数据以及1 249个标签数据,具体数量见表1所示。 表1 数据训练量 KDD99数据集包含了数值与字符特征,无法直接使用数据集进行训练检测,需进行预处理操作。 1) 数值化 KDD99 数据集中的字符型特征需进行数值化处理,因此采用属性映射的方式对标签protocol_type、service、flag、class进行数值化转换。 2) 归一化 对数值化处理后的数据进行归一化处理,保证数据处于[0,1]之间,如式(13) 所示为归一化公式: 其中,Rawdata为数据集中各字段所对应的入侵属性数据,Rawmindata表示该字段所对应的最小入侵属性数据,Rawmindata表示该字段所对应的最大入侵属性数据。Normaldata表示归一化处理后的入侵属性数据。 为验证ReLASL入侵检测模型性能与常用半监督分类方法SWCMR[3]、ML-LOC[4]、SSWL[5]以及ReLSL[2]在KDD99数据集中进行对比,结果如表2所示。 表2 检测性能表 与ReLSL相比,ReLASL入侵检测模型,结构更加优化,参数自动化程度更高,从表2可以看出,ReLASL的检测性能更优,此外,相较于其他半监督检测方法,ReLASL 模型的检测性能也达到了更优的效果,且具备了较好的小样本训练的能力,在复杂网络环境中,更具有一定的竞争力。 针对网络数据变化快,可用训练样本少且样本数据分布不均匀的情况,提出了一种基于ReLASL 算法的入侵检测模型,以提高入侵检测模型的小样本训练的能力。 模型以ReLSL算法为基础,对ReLSL算法中特征提取与标签传染阶段以及伪标签学习与标定阶段的中超参数进行了自动化改进,并将改进后的ReLSL算法应用于网络入侵检测中,提高了模型在小样本不均匀分布数据中的检测性能,从而使模型具备了一定的能够识别未知攻击的能力。 实验结果表明,ReLASL 入侵检测模型在实时的网络入侵检测中能够更准确地分辨攻击类型,与常用的检测模型相比,其能够显著的提高入侵检测模型对小样本不均衡数据的检测性能。但ReLASL算法步骤较多,需进一步降低算法的复杂度,进一步优化算法的整体框架。1 ReLASL入侵检测模型
1.1 特征提取与标签传染
1.2 伪标签学习与标定
2 实验结果及分析
2.1 数据
2.2 数据预处理
2.3 实验结果
3 结束语
