基于Pandas的农产品产销数据预处理研究
2023-12-07胡世洋刘威
胡世洋,刘威
(贺州学院,广西 贺州 542899)
0 引言
随着我国农业现代化的加速推进[1],农业产业化、市场化程度的提高,农产品数据的规模和复杂程度不断增加,这给农产品生产和流通带来了前所未有的机遇和挑战。然而,这些数据来源多样,存在规范化、标准化程度低等问题,这给数据的处理和分析带来了很大的难度。为了更好地理解和应用农产品数据,研究者们已经开始探索和应用各种数据处理和分析方法,其中基于Pandas 库的数据预处理方法已逐渐成为一个热门领域。Pandas 作为一种快速、灵活、高效的数据处理和分析工具,在清洗、去重、缺失值处理、异常值处理、特征提取等方面都有着得天独厚的优势[2]。因此,本文旨在应用Pandas 库中的各种数据处理方法,以实现对农产品产销数据快速、准确和可靠地处理。
1 问题的概述
收集来的农产品数据往往需要二次加工,其原因包括以下几个方面:第一,农作物成熟之后也可以成为农产品的一部分,所以农作物数据表有时候需要与农产品数据表合并在一起分析。第二,需要将原来农产品信息表与农产品产量表合并在一起形成一个更全面的农产品数据表。第三,需要将农产品数据表、商家数据表、顾客数据表、商品销售表合并为一个宽表。第四,需要将数据表中记录重复的、特征重复的数据删除掉。第五,需要用可信赖的方式填充某些为空的字段值。第六,需要用可信赖的方式将明显脱离正常范围的字段值纠正到正常范围。第七,需要将不同量纲的字段标准化处理。第八,需要将非连续字段转换成虚拟变量[3]。第九,需要将连续数值离散化从而利于回归分析。由于Pandas 可以高效地处理数据集。所以要以Python作为开发语言,以Pandas为数据分析工具来解决这些问题。
2 数据预处理过程
由于数据存放在MySQL数据库中,所以要连接到MySQL数据库。首先安装pymysql工具包。其次利用sqlalchemy 库中的create_engine 函数建立Python 程序与MySQL 数据库的连接[4]。最后利用Pandas 中的read_sql_table读取MySQL数据库中的任意数据表。
2.1 合并数据
1) 纵向堆叠
农产品既包括农作物又包括对农作物进行二次加工过的产品,因此农产品应包括农作物里的内容。采用纵向堆叠的方式将农作物数据表的信息堆叠进农产品数据表之中。首先连接到MySQL数据库,把农产品数据表和农作品数据表读出来并放在DataFrame对象里面。其次使用Pandas 中的concat 函数来实现堆叠,设axis=0 可实现纵向堆叠,由于农产品和农作物的数据表字段未必完全一致,在此仅取它们两张表字段的交集,因此将join参数设置为inner。最后将堆叠后形成的DataFrame 对象能过Pandas 中的to_sql 函数重新写回到MySQL数据库中的农产品数据表,此时设置if_exists 参数值为replace,从而刷新整个数据表中的数据,纵向堆叠过程如图1所示。
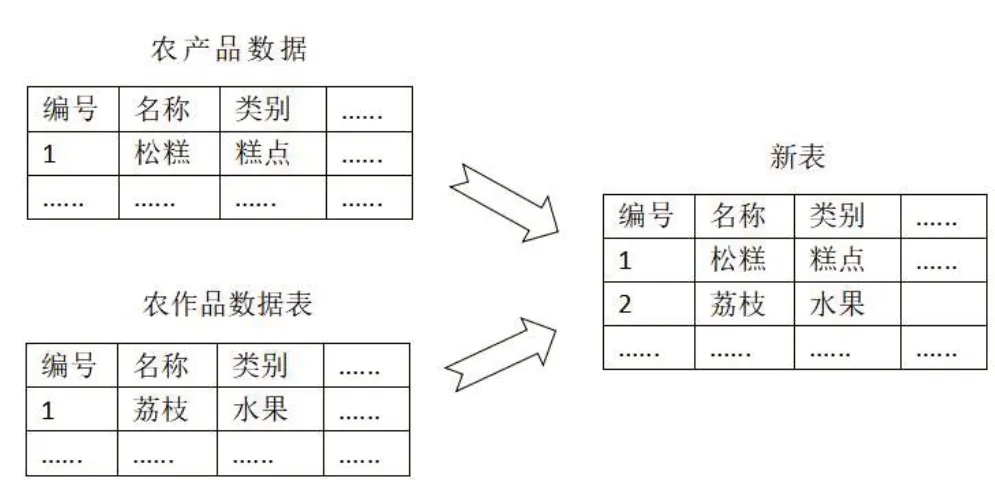
图1 纵向堆叠示意图
2) 横向合并
原来收集的农产品数据表未涉及数量级别的字段,而农户产量统计表中涉及农户所管理的农产品数量内容。如果能将这两个数据表合并成一个表,那么所生成的新的数据表将具备农产品特性和数量两种类别的字段。这里采用横向堆叠的方式来解决这个问题。将农产品数据表和农户产量统计表在X 轴上进行拼接。首先连接到MySQL数据库,把农产品数据表和农户产量统计表读出来并放在DataFrame对象里面。其次使用Pandas中的concat函数来实现堆叠,设axis=1实现横向堆叠。在堆叠时排除掉农户产量统计表中的编号一列。最后将堆叠后形成的新的DataFrame 对象重新写回到MySQL 数据库中,横向堆叠过程如图2所示。
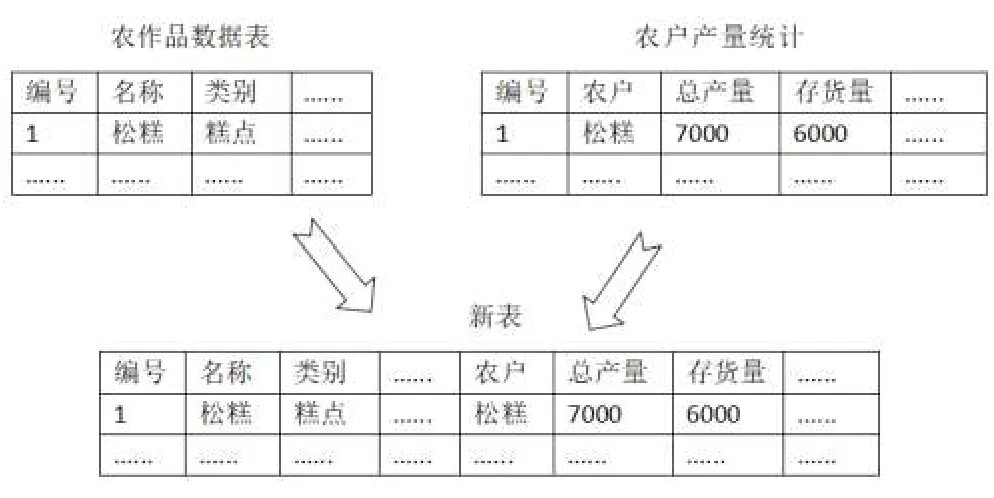
图2 横向堆叠示意图
3) 主键合并
在数据分析时需要多个表连接在一起形成一个宽表。主键合并就是将多个数据集通过它们关联的键连接起来。本文将以农产品数据表、商家数据表、顾客数据表、商品销售表为例进行主键合并。利用农产品数据表中的主键“编号”和商品销售表中的外键“商品”,可以将两个表连接起来。利用商家数据表中的主键“编号”和商品销售表中的外键“卖家”,可以将两个表连接起来。利用顾客数据表中的主键“编号”和商品销售表中的外键“买家”,可以将两个表连接起来。在这个过程中,使用Pandas 中的merge 函数来实现数据的主键合并。最后将主键合并后形成的宽表重新写回到MySQL 数据库中,主键合并过程如图3所示。
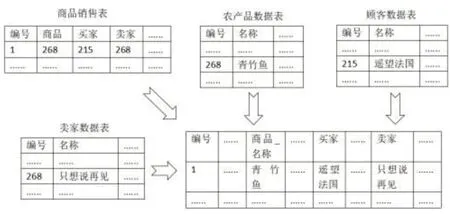
图3 主键合并示意图
2.2 清洗数据
1) 记录重复
在数据收集过程中由于数据的来源是多方面的,而且前期数据模型的设计难免有不周到地方,这样就会造成数据的部分重复。记录重复在数据重复中比较常见,那些重复出现的数据记录需要被删除掉[5]。在这个过程中需要使用Pandas中的drop_duplicates函数来实现记录去重。由于宽表的字段特别多,全面匹配才认为是重复的做法是不可取的。因此选取几个重要的字段比如商品编号、卖家、买家和交易时间,作为是否重复的判断依据。由于同一交易时间不可能出现两次相同的交易,所以这些选取的字段出现了重复就认为这条记录是重复的,可以被删除掉。最后将去重后的DataFrame 对象能过Pandas 中的to_sql 函数重新写回到MySQL数据库中农产品销售宽表,记录重复如图4所示。
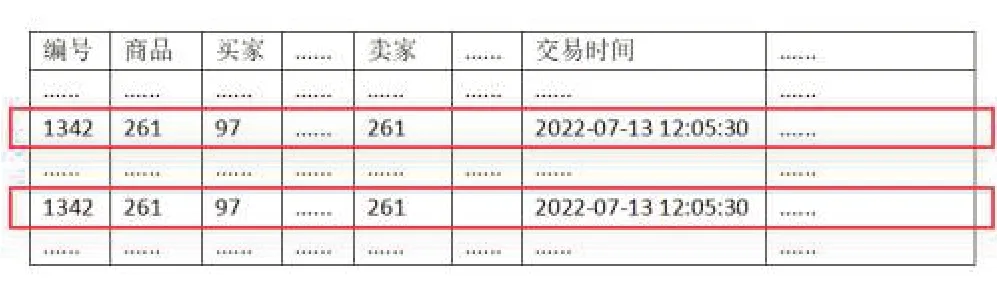
图4 记录重复示意图
2) 特征重复
将农产品数据表、商家数据表、顾客数据表、商品销售表四合表进行主键合并,从而形成农产品销售宽表。这个宽表里面的数据必然存在冗余的情况。例如:原农产品数据表中的“编号”和原商品销售表中的“商品”这两个字段在新的宽表里面显然是重复的。这些冗余的字段不仅造空间的浪费而且不利于后面的数据分析与挖掘。所以这些冗余字段需要被找出来并删除掉。在这个过程中,需要建立一个行和列都等于农产品销售宽表列数的布尔数组。通过DataFrame.equals 方法将农产品销售宽表的不同列进行比较,如果值都相等就将布尔数组对应的行和列的元素置为“真”,否则置为“假”,这样就得到一个布尔矩阵。然后遍历这个布尔矩阵,将重复的字段找出来,并使用Pandas的drop函数删掉。最后将去重后的DataFrame 对象写回到MySQL 数据库中,特征重复如图5所示。
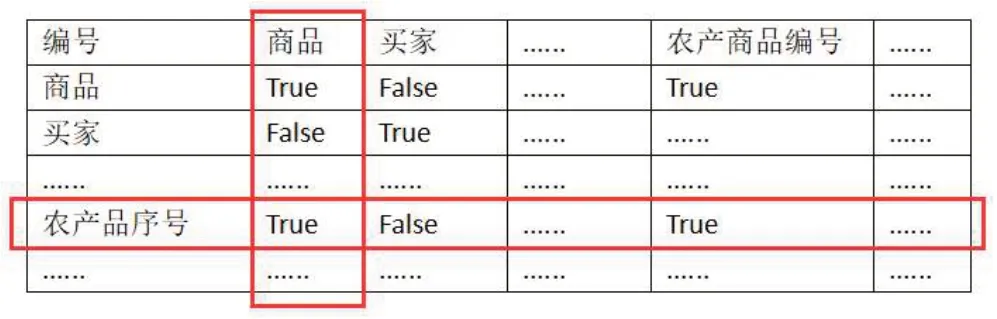
图5 特征重复示意图
3) 检测与处理缺失值
收集到的数据可能存在缺失值,即某几条记录的某些字段值为空。解决这些空值有多种方法。比如删除法、替换法和插值法等。删除法是利用Pandas中的dropna 方法将含有空值的记录删除掉。这样做存在明显不合理之处,存在空值的记录不一定都要删除,该记录的其他非空字段很可能也存在重要的研究价值。替换法则是利用该字段下的平均数、中位数等统计量来填充记录中的空值。利用平均数、中位数等来填充空值可能会影响数据的标准差,导致信息的波动。插值法是通过求解多项式来得到一个值,然后让这个值来替换记录中的空值。此处采用插值法来解决这个问题。要使用插值法需要找到与本字段相关的另一个没有空值的字段。以商品信息表为例,存货量存在空值,找到跟存货量有一定关联的字段,即总产量。首先要根据总产量和存货量这两个字段拟合出来一个多项式函数。再根据存在存货量为空的记录对应的总产量和多项式函数计算出该记录存货量的值,将这个值再插入数据表里面。
4) 检测与处理异常值
在农产品数据表里面也会出现明显偏离正常的数值。这些数值可能来源于数据收集时的错误,或者程序调试时遗留的脏数据。这样的数值也称为离群点[6]。这些离群点的存在会给以后的数据分析带来极大的隐患,甚至会导致预测的结果出现偏差。可以使用3σ 原则来进行数值的异常检测,也可以使用箱线图分析法来进行数值异常检测。此处以农产品的销售金额为例,使用箱线图分析法来阐述异常数值检测与矫正过程。首先从数据库读取农产品销售表。其次计算箱线图的五个统计量。使用quantile函数再加上0.25 的参数可以计算出下四分数(即QU) ,如果参数改成0.75可算以上四分数(即QL) 。由上四分数减下四分数可计算机中位数(即IQR) 。利用公式QU +1.5×IQR 可计算出最大值,如果数值超过了最大值就用上四分数来替代其原有值。利用公式QL-1.5 ×IQR可计算出最小值,如果数值超过了最小值就下四分数来替代其原有值。最后将新的DataFrame对象写回到数据库当中,日销金额箱线图如图6所示。
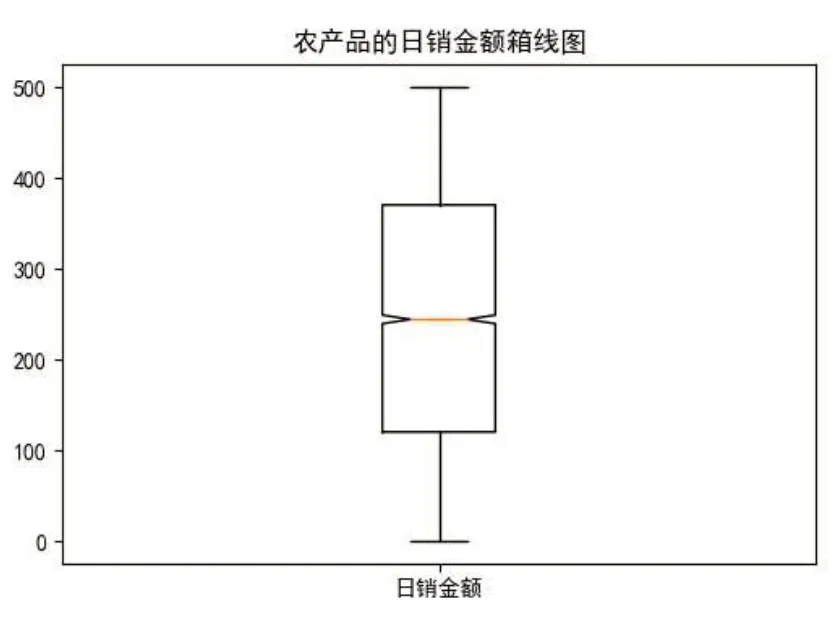
图6 农产品日销金额箱线图
2.3 标准化数据
想要根据农产品的存货量、总产量和日销量等这些因素来分析农户的年度利润就会面临特征字段量纲不同的问题。存货量和总产量的数值远远高于日销量。但是日销量对年度利润的影响也很大。为了不影响以后数据分析的准确性,就需要消除这些量纲的差异,即进行数据标准化处理。数据标准化处理常用的方法有离差标准化[7]、标准差标准化、小数定标标准化等。为了不改变数据原有的分布情况,这里采用小数定标标准化处理方法[8]。小数定标标准化转换公式如公式1所示:
通过这个公式可以看出小数定标标准化的关键是k值的确定。把待处理的这列数据作为一个Series对象。再对Series对象里面数值的绝对值的最大值求10 的对数作为k 的取值。按照转换公式对相关字段进行标准化处理,最后将处理的DataFrame 对象通过tosql函数重新写回数据库中。
2.4 转换数据
1) 哑变量处理
为分析不同地区农产品价格的差异,把字段“市”进行哑变量处理。因为“市”作为一个地区类别的字段并非连续型的。非连续字段的值不能做加减计算,不利于以后对农产品销售情况进行回归分析,因此需要将“市”这个区域类别转换成虚拟变量。再利用这些虚拟变量做回归分析。这个过程需要利用Pandas的get_dummies 函数转换成哑变量DataFrame,将哑变量DataFrame与原商品信息进行横向合并。最后将最终的DataFrame 对象写回数据当中,哑变量处理过程如图7所示。
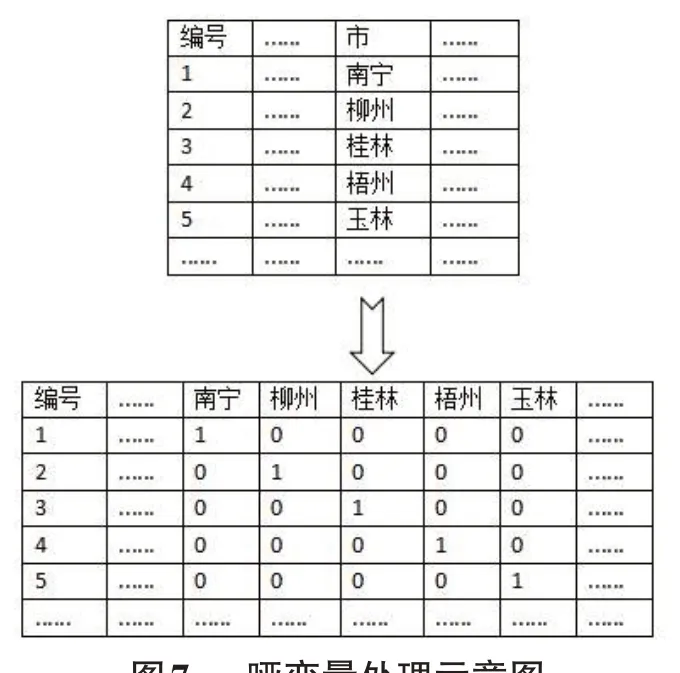
图7 哑变量处理示意图
2) 离散化连续性数据
分析农产品在8月份的销量变化情况需要将7、8月份农产品的销量数据离散化。按照销售量的大小将其分成几个区间,然后用变量表示每个区间的销售量范围,哑变量作为自变量,以时间为因变量,进行回归分析,以评估销售量区间之间的相关性和趋势。通过这种方法,可以更好地理解销售量的变化趋势和影响因素。在具体处理过程中,利用聚类分析法将商品信息统计表中的销量一列数值划分为5个类别,形成一个新的Series。然后将新的值再进行哑变量处理。将处理后形成的DataFrame再与商品信息统计表进行横向堆叠。最后将形成的最终DataFrame写入数据库当中,离散化处理过程如图8所示。

图8 离散化连续性数据示意图
3 结束语
本文介绍如何利用Pandas 技术来实现农产品产销数据预处理。经过预处理之后的数据可以更为方便地被理解和分析。这也为将来对农产品市场的预测、供应链的优化、市场竞争力的提升提供技术支持,这也利于农产品的市场监管和市场推广。同时探索、研究和应用更加先进的数据处理方法,也是农业数据化建设和现代化进程的必然要求。
