基于通道特征金字塔的图像分割算法
2023-12-05莫光萍
孙 红,杨 晨,莫光萍
(上海理工大学 光电信息与计算机工程学院,上海 200093)
语义分割是将图像的每个像素标记为相应类别来达到分割效果,是当前计算机视觉中的一个重要主题[1],其在自动驾驶系统和自主移动设备等领域中应用广泛[2-9]。然而,这些应用大多需要较高的分割精度,但提升分割精度需要大量增加参数数量。增大模型大小会减慢推理速度,导致无法满足实时性要求,例如PSPNet(Pyramid Scene Parsing Network)[10]和DeepLab[11]在语义分割方面具有良好的性能,但它们包含数千万个参数,且推理速度不到每秒1帧。显然这些大型网络达不到完成实时语义分割任务的能力。在考虑内存需求和推理速度后,应用实时语义分割的应用程序具有较强竞争力。因此,构建一个高效的语义分割网络逐渐成为一个重要课题。
现有高速语义分割模型例如ENet[12]和ESPNet(Efficient Spatial Pyramid Network)[13]具有较高的推理速度,但都以牺牲分割性能为代价。其他网络例如ICNet(Image Cascade Network)[14]已经成功地实现了更好的性能,但牺牲了推理速度和模型大小。因此本文力图寻求能平衡分割准确度、推理速度和模型大小的方法。文献[15~16]证明了多尺度卷积的潜力,其能够感知各种大小的感受野。该方法允许网络利用多级特征提取并结合各种规模信息。此外,空洞卷积已被证明是一种可在保持参数总数的同时提取大规模特征的有效方法[17-18]。然而,这两种方法都具有局限性。作为一个通道模块,即使应用了分解卷积,Inception模块[19-22]仍然包含大量参数。而模块中仅有单一空洞卷积率的卷积通道只能从较大目标物体上提取特征信息,无法识别小型目标物体。
基于上述观察,本文提出了一个新的语义分割网络模块,使用该模块构建一个基于编码器解码器结构的网络来提取密集特征。本文主要的工作和创新点如下所示:
1)提出通道特征金字塔模块来处理多尺度特征信息,将N个通道处理后的特征信息融合后优化边界分割细节;
2)将空洞卷积和可分离卷积用于改变网络复杂性降低网络参数量,实现模型的轻量化;
3)在网络块的末端嵌入一个卷积注意力机制模块(Convolutional Block Attention Module,CBAM),其由通道注意力和空间注意力子模块组成,进一步提升了网络对特征信息的提取能力。
1 网络框架
1.1 网络主体结构
本文所提算法模型如图1所示,主要由初始特征提取模块、通道特征金字塔模块和轻量级卷积注意力机制模块(CBAM)共3个部分组成。在特征提取模块首先使用3个3×3卷积作为初始的特征提取器,在第1个和第3个3×3卷积层后,将卷积得到的特征信息再进行一次1×1卷积,从而将输出特征信息作为输入特征输入轻量级注意力机制中。在下采样阶段使用ENet中的下采样策略即将步长为2的3×3卷积与2×2最大池化相结合,经3次下采样之后输出的特征图为原输入图像的1/8。初始特征提取模块的输出经下采样后输入通道特征金字塔模组,将处理后的特征信息分别作为下一个下采样层和1×1卷积的输入特征,将低层的特征信息与卷积后得到的高层特征信息进行融合,最后在上采样后加入轻量级注意力机制进一步提取特征信息作为高阶特征信息输入到CBAM3中,将最终得到的特征信息经上采样得到最终的语义分割图。
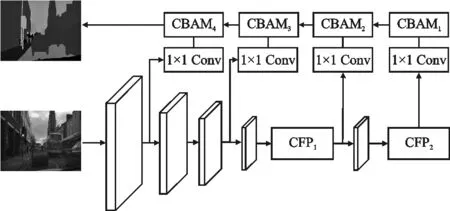
图1 网络结构Figure 1. Network structure
1.2 通道特征金字塔模块
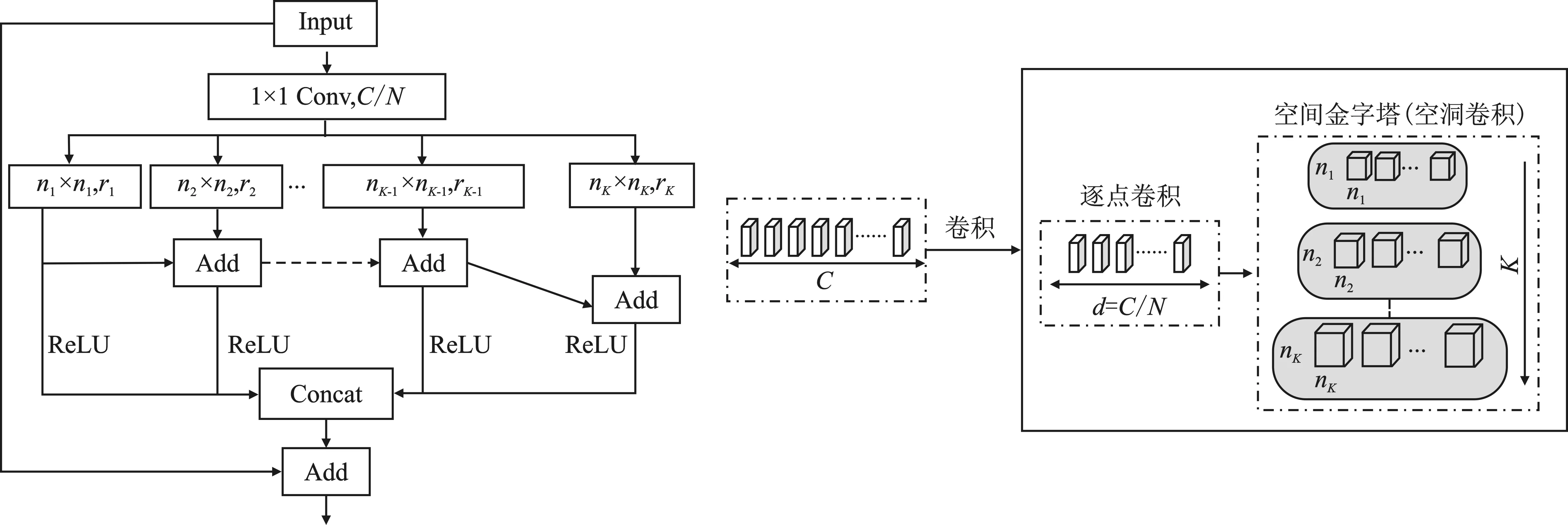
图2 通道特征金字塔模块Figure 2. Channel feature pyramid module
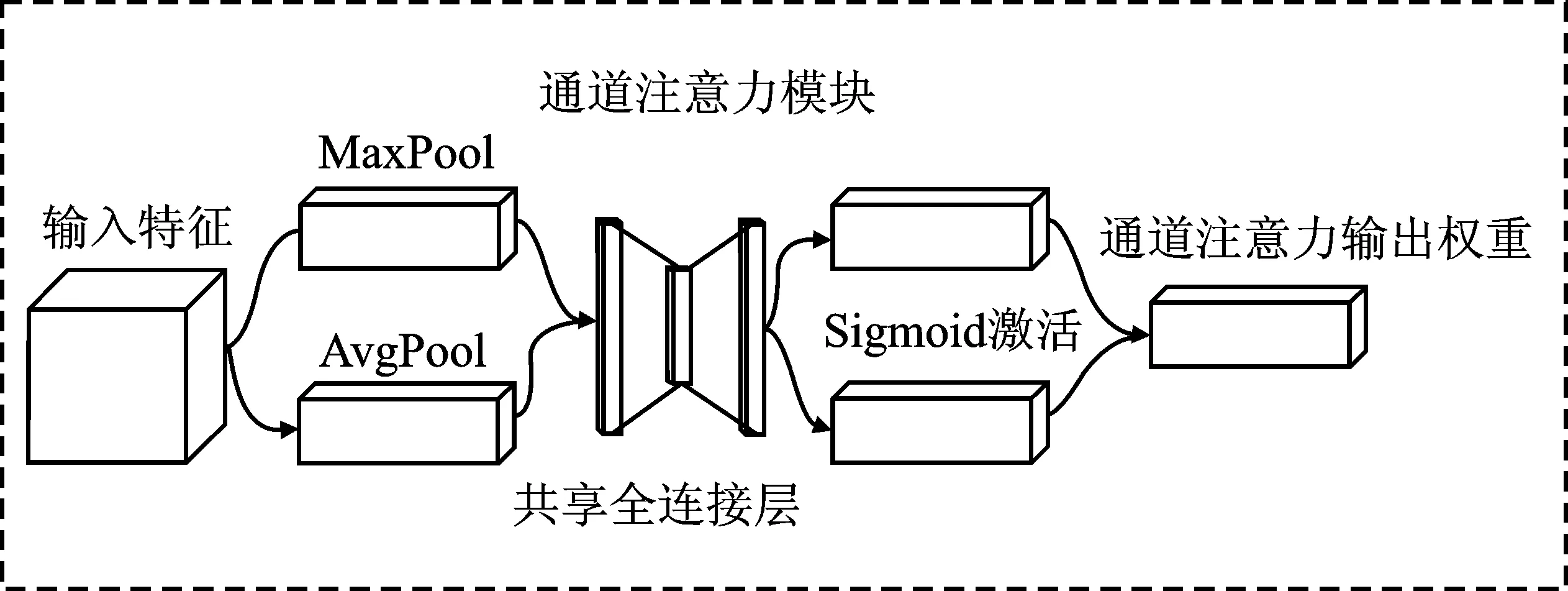
图3 通道注意力模块Figure 3. Channel attention module
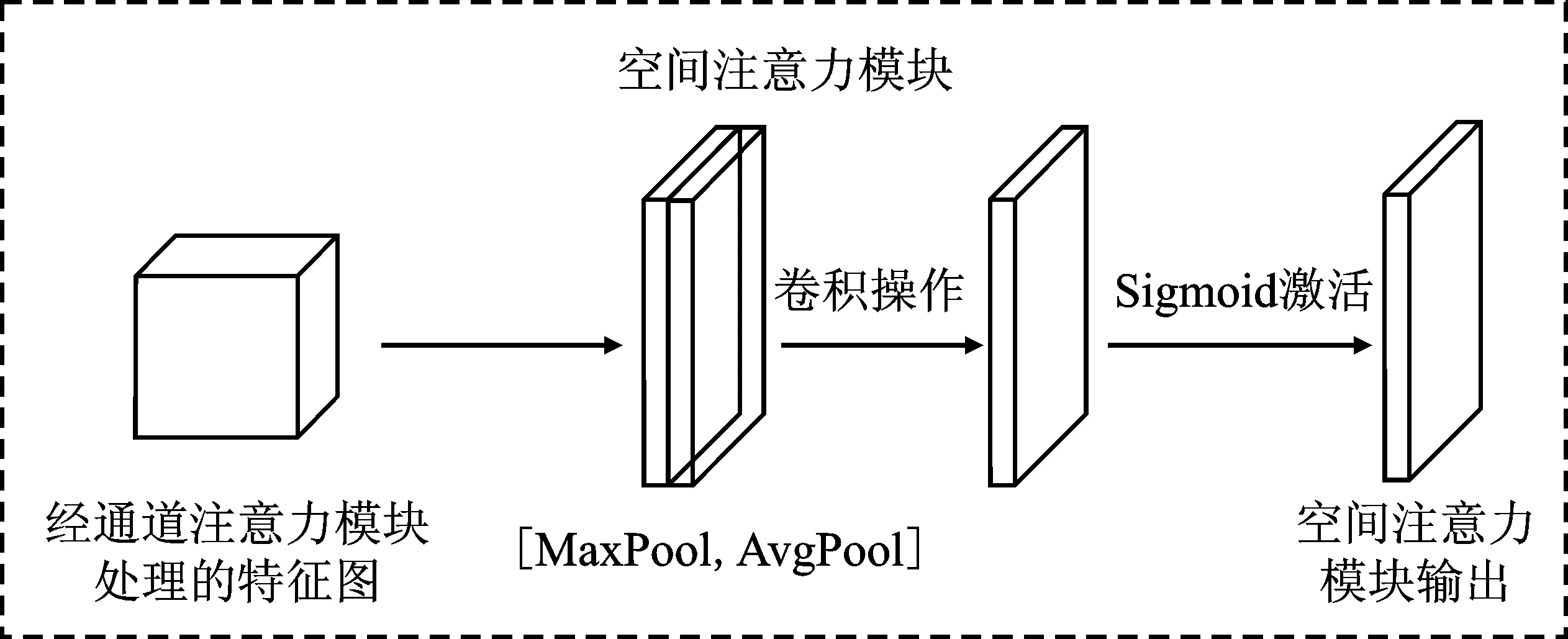
图4 空间注意力模块Figure 4. Spatial attention module
1.3 注意力机制
CBAM由通道注意力机制和空间注意力机制两个子模块组成,分别从通道和空间两个维度提取特征信息。CBAM的整个过程可以由式(1)和式(2)表示。
F′=Mc(F)⊗F
(1)
F″=Ms(F′)⊗F′
(2)
其中,Mc(F)表示输入特征经通道注意力子模块处理后得到的特征信息;Mc(F′)表示通道注意力子模块输出特征与原输入特征融合后的特征信息;F″表示经空间注意力子模块处理后的输出特征与原输入特征融合后的最终输出特征。
在通道注意力部分,输入特征分别进行最大池化和平均池化,具体如式(3)和式(4)所示。
MA(F)=MLP(AvgPool(F))
(3)
MM(F)=MLP(MaxPool(F))
(4)
其中,MA(F)表示输入特征经平均池化的输出;MM(F)表示输入特征经最大池化的输出。池化过程用于提取高阶特征信息,经过共享感知机压缩特征通道并将特征信息融合,再将通道数扩张到与输入特征相同,经激活函数得到两个池化后的输出结果。将输出结果进行逐元素相加后经Sigmoid激活函数得到通道注意力机制的输出结果,并和最初的特征图信息相乘得到最终的通道特征信息Mc(F),过程如式(5)所示。
Mc(F)=σ(MA(F)+MM(F))
(5)
在空间注意力模块中,将通道注意力输出的特征信息作为输入特征,首先会进行一个全局最大池化和全局平均池化,然后将池化后的结果进行融合后经过一个卷积层将双通道的特征信息降维为一维特征信息,经过激活函数生成空间注意力特征图,最后将生成的特征信息与模块的输入特征信息进行相乘输出得到最终的特征图,具体过程如式(6)所示。
Ms(F)=σ(f7×7[AvgPool(F);MaxPool(F)])
(6)
2 实验过程
在公开街景数据集CamVid和Cityscapes上进行分割效果和推理速度实验,采用的评价指标分别为均交互比(mean Intersection over Union,mIoU)、帧率(Frames Per Second,FPS)、参数量(Parameters)。mIoU的计算式如式(7)所示
(7)
其中,pij表示真实值为i但被预测为错误值j的情况;pji表示错误值为j但被预测为正确值i的情况;pii表示预测值和实际值均为真实值i的情况。
果然,没有几天,杰克领着杨律师走进客厅,向苏穆武和苏母介绍:爸,妈,这是杨律师!苏穆武和老伴不知杰克葫芦里卖的什么药,面面相觑。杰克说:爸,妈,我想了一下,咱们的问题,还是请律师解决比较好。苏穆武懵懂地:什么问题?杰克说:关于人权问题,我不想争论了,用婷婷的话说,会伤感情的。苏穆武好像明白了,不满地:用律师解决就不会伤感情? 杰克说:当然,法治社会最好的办法就是通过律师。我已经跟杨律师说过了,我现在回避一下,爸,妈,你们跟杨律师谈谈吧!苏穆武朝杰克的背影:谈你个腿!
2.1 实验环境
为保证实验结果具有可对比性,本文所有对比实验采用的实验环境如表1所示。采用初始学习率为0.007的poly学习策略来动态调整学习率,poly学习策略的表达式如式(8)所示
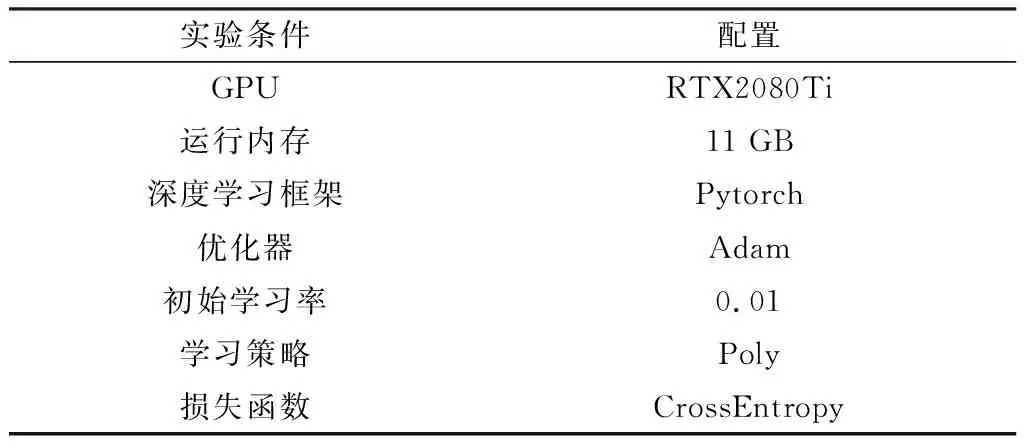
表1 实验条件
(8)
其中,Ir表示初始学习率;iter和max_iter分别为训练迭代次数和最大迭代次数;将power设置为0.9,输入图像的batch_size设置为4。由于实验过程中不使用任何预训练方法,因此将最大训练时间设置为1 000。
2.2 数据集及预处理
本文实验一共使用了两个公开街景数据集,分别是CamVid和Cityscapes。
CamVid是一个从驾驶汽车角度拍摄的街景数据集,总共包括701幅图像,其中367幅图像用于训练,101幅图像用于验证,233幅图像用于测试。这些图像的分辨率为960×720,共有11个语义类别,在训练前将这些图片尺寸大小调整为360×480。
Cityscapes是一个城市景观数据集,包含5 000幅精细标注和20 000幅粗标注图像。该数据集是从50个不同城市在不同季节和不同天气中捕获。对于精细标注集,其包含2 975幅训练图像、500幅验证图像和1 525幅测试图像。原始图像的分辨率为1 024×2 048。整个数据集包含19个类别,属于7个大类(例如汽车、卡车和公共汽车属于车辆大类)。
2.3 消融实验
本文提出的融合轻量级注意力机制的轻量化网络的骨干网络主要由通道特征金字塔模块和轻量级卷积注意力机制(CBAM)组成。为了说明各个系统模块的搭建过程以及它们在语义分割中的作用,对两个模块的结构细节和分割效果在CamVid数据集上进行对比实验。在通道特征金字塔模块对比实验中,在未加入轻量级注意力机制的情况下,保证网络其余结构参数不变,改变通道特征金字塔模块参数进行实验,根据实验结果确定通道特征金字塔模块的重复次数和空洞卷积率的大小,实验结果如表2所示。
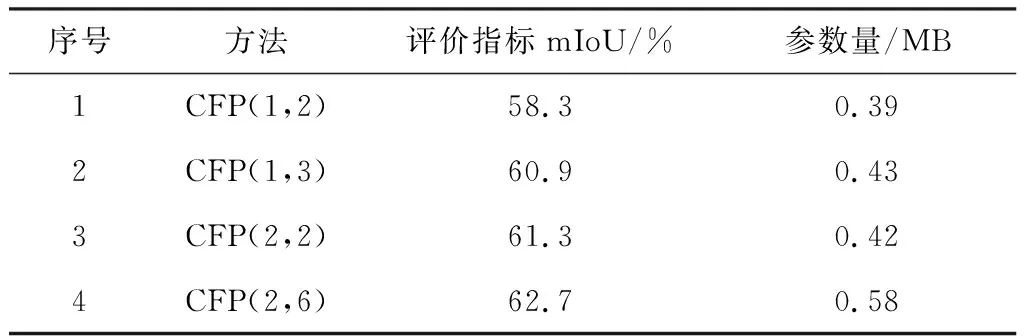
表2 通道特征金字塔模块消融实验
改变通道特征金字塔模组重复次数进行消融实验。通道特征金字塔模组在本文网络中的位置如图1所示,CFP1(Channel Feature Pyramid)表示第1个通道特征金字塔模组,之后经下采样输入第2个通道金字塔模组CFP2。
表2中序号1的实验表示在CFP1模组中通道特征金字塔模块重复一次,在CFP2模组中重复两次,第1个通道特征金字塔模块中的空洞卷积率为4,而第2个通道特征金字塔模块中的空洞卷积率分别为8和16;序号2的实验表示通道特征金字塔模块在CFP1模组重复1次,在CFP2模组中重复3次,CFP1中的空洞卷积率为4,CFP2中空洞卷积率分别为4、8和16;序号3的实验表示通道特征金字塔模块在CFP1模组和CFP2模组中都重复两次,其中第1部分的CFP空洞卷积率分别为2和4,第2部分的空洞卷积率为8和16;序号4的实验表示通道特征金字塔模块在CFP1模组中重复两次,CFP2模组中重复6次,其中第1部分空洞卷积率均为2,第2部分空洞卷积率分别设置为4、4、8、8、16、16。
通过序号1和序号3对比实验可知,特征金字塔模块的增加使模型提取到更多的特征信息,分割准确率提升了2.6%。序号2和序号3的对比实验证明了膨胀率更大的空洞卷积在卷积过程中获取了更多的多尺度信息,mIoU提升了0.4%。但过度增加空洞卷积将导致模型参数量增加并降低运行速度,因此最终本文选择序号3的模型参数进行后续的模块消融实验。
确定骨干网络的模型参数后,为了探究CBAM对最终实验结果的影响,分别在CFP2模块后添加CBAM1模块,在CFP1模块后加入CBAM2模块后并与CBAM1模块的特征信息进行融合,在第1个和第3个3×3卷积层之后依次加入CBAM4、CBAM3模块,最后进行上采样得到最终的分割图。消融实验结果如表3所示。
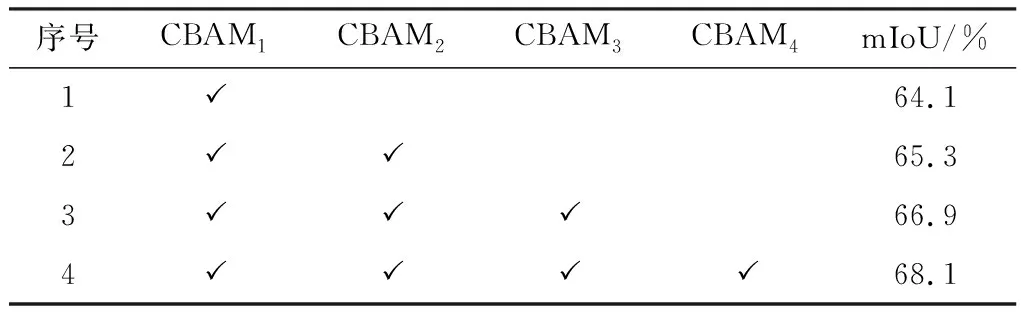
表3 CBAM模块消融实验
由表3中实验1和实验2的结果对比发现,加入CBAM2模块后模型分割精度提高了1.2%,CBAM3模块的加入模型精度提升了1.6%。这是由于模块对高阶特征信息的权重进行获取,并将其与低阶语义特征进行加权操作,使得高级特征信息能够对低级特征信息进行指导,从而更有效地提升了分割精度。在序号4的实验中,分割精度相对实验3提高了1.2%。如图5所示,浅层特征信息的加入提升了模型对边界信息的敏感性,添加CBAM模块后的模型对于小目标对象的分割效果明显优于未加入CBAM模块的骨干网络模型。最终本文网络模型在4个CBAM模块加成下达到68.1%的分割精度。在本文后续的Cityscapes数据集速度测试对比实验中也将采用融入CBAM模块的网络模型。
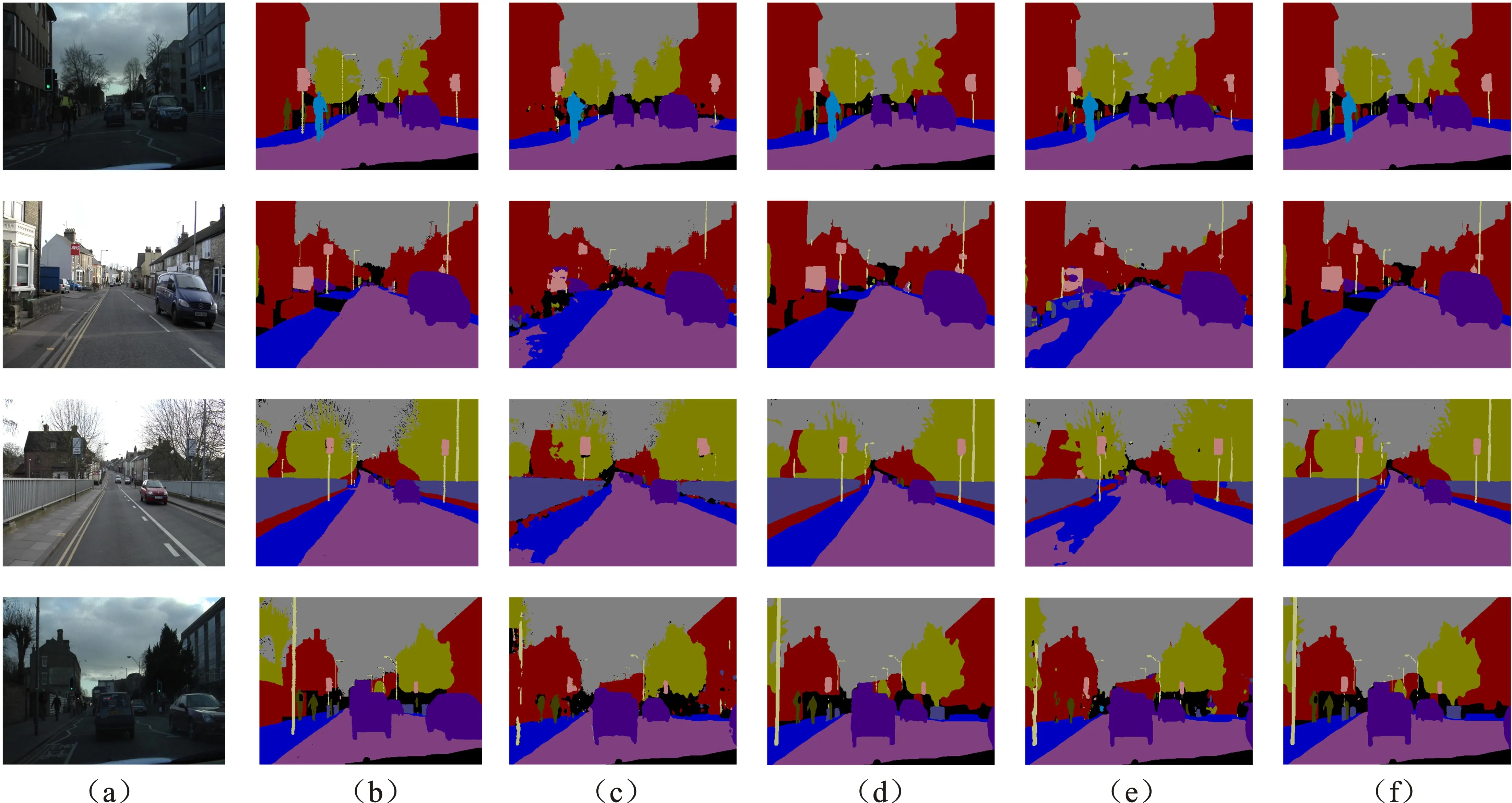
图5 CamVid数据集分割效果对比(a)输入图像 (b)标注图像 (c)SegNet (d)BiseNet v2 (e)本文算法(无CBAM) (f)本文算法(加入CBAM)Figure 5. CamVid data set segmentation effect comparison(a)Input image (b)Annotation image (c)SegNet (d)BiseNet v2 (e)The proposed algorithm(without CBAM) (f)The proposed algorithm(with CBAM)
2.4 CamVid数据集语义分割实验
为了评估模型的分割效果,将CamVid作为测试数据集进行实验,同时本文还与其他公开的优秀语义分割模型算法进行分割效果的对比,实验结果如表4所示。本文模型在小参数量的情况下也依然展现了出色的性能,模型较DABNet[23]参数量下降了近10倍,但在分割效果上依然具有竞争力。相比于ICNet,本文模型虽然在分割效果上较差,但参数量只有其1/36。在参数量小于100万的网络中,本文模型的准确率相对较高,平均交互比达到了68.1%,高于ENet的51.2%和ESPNet的54.6%。在表2中,本文模型在未加入CBAM模块的情况下均交互比达到了61.3%,说明通道特征金字塔模块中空洞卷积和可分离卷积的组合在提取特征信息方面具有良好表现。此外,与SegNet[24]、DeepLab v2等参数超过1 000万的网络相比,本文模型不仅实现了轻量化,且分割准确度分别高出14.8和3.0个百分点。
为了更清晰地体现本文模型在Camvid数据集上的分割效果,将本文模型得到的语义分割掩码与其他优秀网络模型进行对比,对比效果如图5所示。对于小目标对象例如路灯、交通标识牌等,由图5(f)可知,得益于特征金字塔池提取的多维特征信息以及轻量注意力机制融入的浅层特征信息,本文模型相较于大模型更加敏感且分割精度更高,说明本文通道特征金字塔模块设计有效。
由于在图5(f)中引入通道注意力子机制和空间注意力子机制相融合的轻量级注意力机制模块,可以明显看出图5(f)中对与物体边界信息的提取效果优于未添加卷积注意力机制的图5(e)。对于浅层特征信息的融合也进一步提高了图5(f)的分割准确性,从而提升了整个神经网络的分割精度。
2.5 Cityscapes数据集速度测试实验
为了验证本文提出的轻量化网络模型可适用于实时语义分割任务,在Cityscapes数据集上进行速度测试实验,同时与其他优秀的语义分割模型进行参数量、速度和分割精度指标对比,实验结果如表5所示。
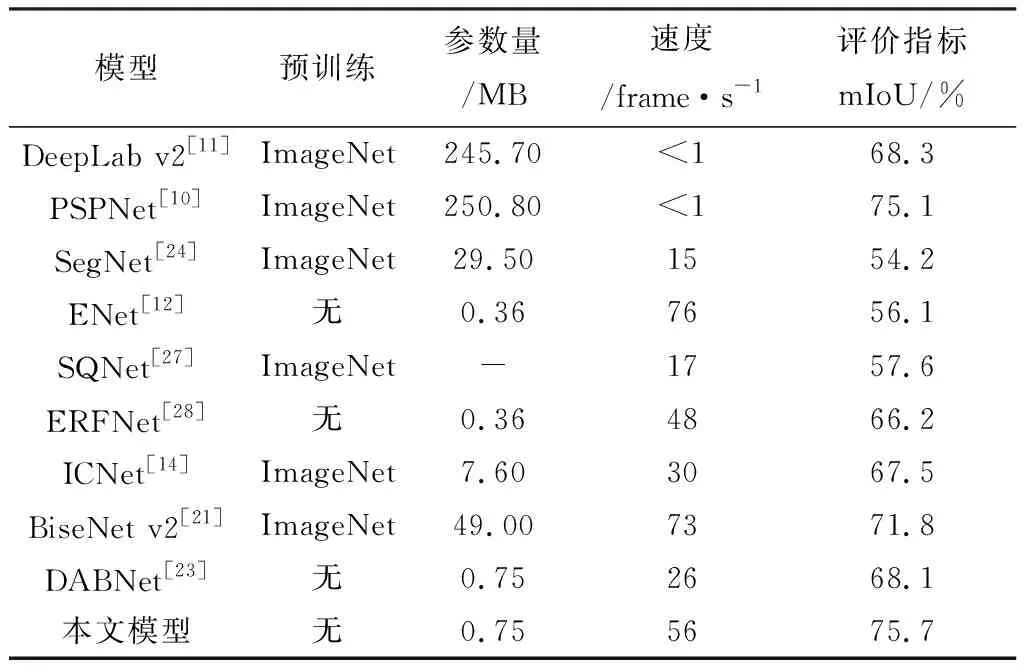
表5 Cityscapes数据集速度测试实验
在分割效果方面,本文模型的分割效果具有一定的竞争力,平均交互比达到了75.7%,不仅分割效果较传统分割网络精度更高,而且在参数量大小和推理速度上更具优势。相比于ICNet和DABNet(Depth-wise Asymmetric Bottleneck Network),本文模型均交互比分别提高了8.2和7.6个百分点。在运行速度方面,本文模型能够以56 frame·s-1的速度处理1 024×2 048大小的输入图像。BiseNet v2[26]是最快的实时语义分割网络,虽然其速度快于本文模型,但分割精度只达到了71.8%,比本文网络模型的分割精度低。速度测试对比实验表明,本文模型能够以较快的推理速度处理高分辨率图像,同时保持高精度的分割效果。
3 结束语
本文提出了一种通道特征金字塔模块来联合提取局部特征和上下文特征。在特征金字塔模块的基础上,嵌入多个轻量级注意力机制模块提升模型对边界信息提取能力。通过分析和定量实验结果证明了该方法的有效性。本文模型在仅使用75万个参数的情况下,在Camvid数据集上取得了68.1%的分割准确性,在Cityscapes测试集上达到了75.7%的平均交互比,在1 024×2 048高分辨率图像上的运行速度为56 frame·s-1。与其他优秀方法相比,本文所提算法模型在分割准确性、运行速度和参数量方面都有较好的表现。
