TSN网络下基于网络周期的流调度方法
2023-12-04林佳烁王卓薇詹双平
林佳烁,王 涛+,王卓薇,詹双平,成 剑
(1.广东工业大学 自动化学院,广东 广州 510006;2.广东工业大学 计算机学院,广东 广州 510006;3.鹏城实验室 宽带通信研究部,广东 深圳 518055)
0 引 言
时间敏感网络(time sensitive networking,TSN)是一种新兴的确定性网络传输技术,其通过时间同步、路径计算、资源预留等机制在以太网的基础上保障网络中实时业务流的确定性网络传输[1]。不同于其它只能单一传输实时数据的时间敏感型网络技术(如Profinet、EtherCAT、POWERLINK等),时间敏感网络支持在同一网络下混合传输非实时业务流数据及实时业务流数据。而保障实时业务流数据的网络传输不被非实时业务流干扰的关键机制就是时间同步机制(IEEE 802.1AS[2],以下简称802.1AS)以及门控机制(IEEE 802.1Qbv[3],以下简称802.1Qbv)。
时间同步机制是时间敏感网络的基石,802.1AS定义了网络的时间同步协议,保证网络中的所有设备时钟都与全局时钟在一个误差范围内同步。而802.1Qbv则在交换机的出口端口处通过门控制列表(gate control list,GCL)对出口队列进行开和关操作,来实现对网络数据流的管控。
时间敏感网络中基于802.1Qbv机制的调度算法大致分为两种[4],第一种是离线式调度算法,其一般将网络建模为一个整数线性规划问题(ILP),然后使用SMT(satis-fiability modulo theories)求解器(如Z3等)或线性规划求解器离线求解[5-7]。第二种是使用启发式算法来降低算法运行所需要的时间,使得其可以在可接受的时间范围内在线求解[8,9]。文献[7]将网络周期分为多个小的时间槽,然后在每个时间槽里只调度一条实时业务流。尽管这种方法可以有效保证业务流之间的隔离,但也降低了网络中可调度流的数量。文献[10]将时间敏感网络中的流调度问题映射到运筹学领域的作业安排调度问题(no-wait job-shop scheduling,NW-JSP),然后使用禁忌搜索算法对该问题进行迭代求解。其中,No-wait约束指的是实时业务流在网络中不会在出口队列中排队。但由于其仅假定所有业务流的应用周期都是相同的,难以在实际应用中对具有不同周期的业务流部署。而文献[5]同样基于No-wait约束来进行调度,其定义了业务流之间的冲突程度,并在离线调度情况下联合路径来进行优化,最终使用ILP来进行求解。文献[11]针对大规模网络下采取了类似No-wait约束的传输调度方法,其保持门控队列开关常开并最后使用SMT来求解。
总体而言,No-wait约束的流调度算法可有力保障业务实时性并且其简单可实现,受到研究人员重点关注,但由于No-wait约束比较严格,其可调度的业务流数量受到较大限制;同时,实际场景中动态出现的众多未知业务流也迫切需要实时在线增量的No-wait约束流调度。如何有效提升TSN中No-wait约束下的流调度能力,包括针对不同周期业务流的支持度、在线增量调度的实时性与容量等性能,是值得深入研究的关键问题。
本文首先提出一种基于No-wait约束的多周期业务流在线调度方法,可适用于多周期业务流混合调度的场景。该算法根据网络流周期的特点,将业务流的宏周期(hyper-cycle)分为多个小的网络周期,然后使用最早调度原则在线地对网络业务流进行调度,从而实现多周期业务流的No-wait约束在线实时增量调度。为进一步提升在线调度的容量,根据该在线算法的特点,提出一种基于重合度的离线调度算法,在离线调度场景下使用了禁忌搜索算法以获得更优的调度结果,提高了剩余可调度空间,为后续的在线调度运行调度奠定良好的基础。最后,对算法的性能进行实验分析,并在仿真平台Omnet++上验证调度结果的正确性。实验结果显示,对于每一条业务流,在线调度算法调度计算耗费时间约为3.98 ms,满足实时性要求。并且,对离线调度算法的仿真实验显示其可以有效解决在线调度无法适用的场景,将网络的可调度业务流数量提高58%。
1 问题建模
1.1 系统建模
1.1.1 IEEE802.1Qbv模型
图1展示了时间敏感网络中一个典型的交换机结构,其支持802.1Qbv标准,在其每个出口端口处,有8个转发队列。该交换机根据转发数据报文中的PCP(priority code point)字段,将数据帧放置入对应的队列中。然后,通过GCL列表来控制对应的队列开关。当队列的状态是“开”时,队列中的数据帧能够被转发,否则不能被转发。这种机制可以将实时业务流与非实时业务流隔离到不同的队列,以实现实时业务流的转发不受到干扰。并且,通过与时间同步机制进行结合,可以达到对数据流报文逐跳的严格精细控制,从而实现数据报文的确定性转发。

图1 支持802.1Qbv标准的交换机出口端口架构
1.1.2 网络模型
本文所使用的符号表示及其意义见表1。给定网络拓扑G=(V,E),其中vi∈V表示的是网络节点,ei=(vi,vj)∈E表示的是网络中节点之间的链路。对于链路e∈E,spe表示该链路的传输速率。

表1 符号表示及其意义对照
对于业务流fi∈F,其中F表示所有业务流的集合,si、di、sizei、pi、ri分别表示该业务流的源节点、目标节点、数据大小、应用周期、转发路径。

(1)
1.1.3 网络周期(基期)
由于网络中业务流的应用周期不相同,所以设置一个较小的时隙为网络周期,本文将这个网络周期称为基期(base period,bp),使得所有的业务流的应用周期都为基期的整数倍。此时,将业务流的应用周期与基期的比值称为RR(reduction ratio)。如图2所示,基期值为1 ms,两个业务流Flow0及Flow1的应用周期分别为2 ms和3 ms,则其RR分别为2和3,网络的宏周期为这两个应用周期的最小公倍数6 ms。

图2 网络周期(基期)、应用周期以及宏周期
1.2 问题描述
时间敏感网络中的流调度问题是一个NP-hard问题[12],为了确保实时业务流的确定性网络服务,对业务流的传输有诸多约束条件。本文提出的算法旨在在线求解出满足约束条件的调度解,该调度解不影响已调度的业务流的传输。其包括实时业务流的起始转发时间,其路由路径上的交换机的GCL列表配置。其约束条件如下:
约束1:实时业务流fi在其路径上的链路的传输窗口不应与其它已分配的窗口冲突,如式(2)所示
∀fj∈F,j≠i,∀e∈ri
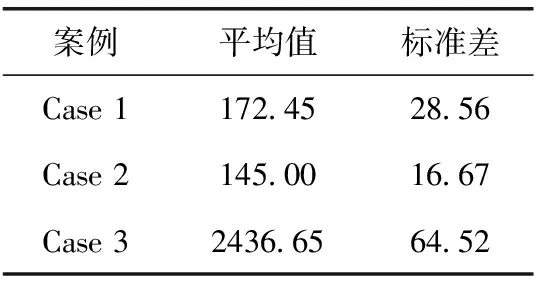
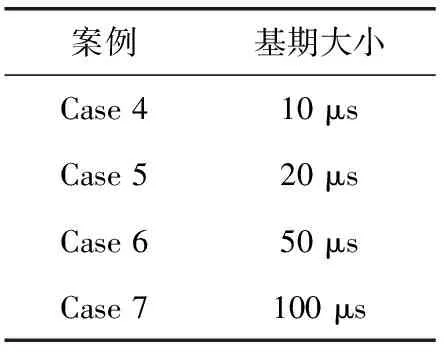
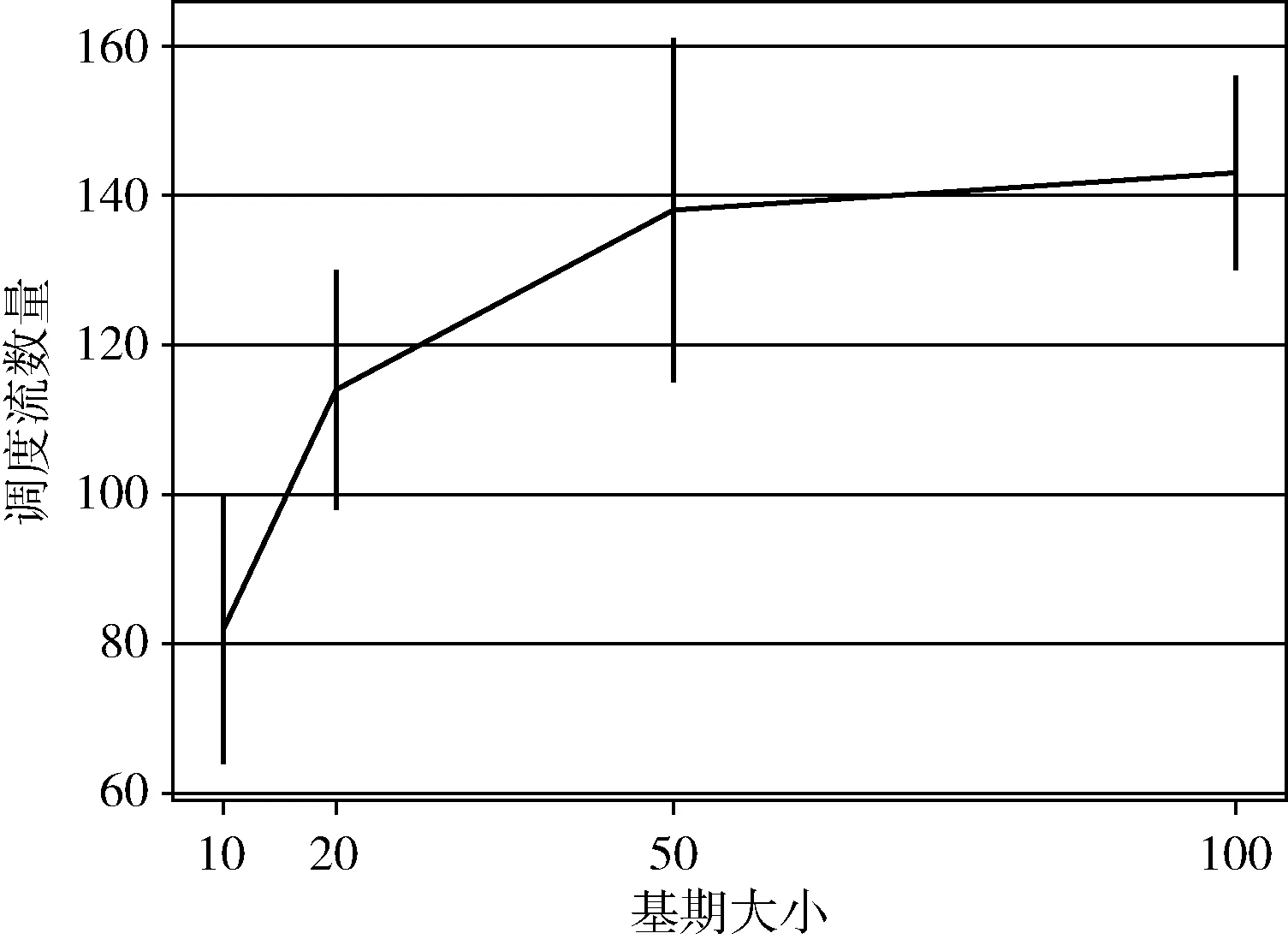
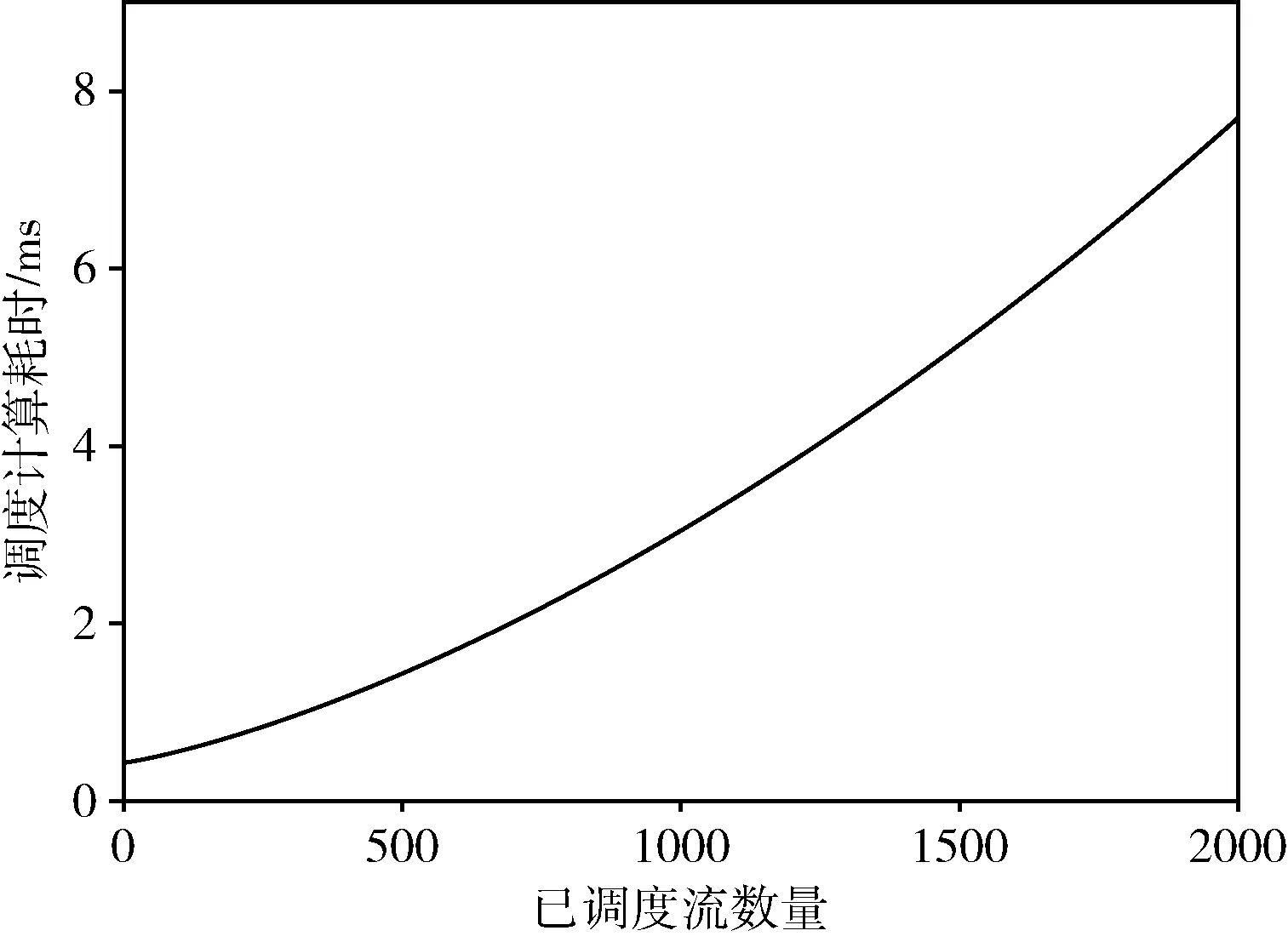
∀α∈{k∈N|0≤k ∀β∈{k∈N|0≤k (2) 其中,tIFG表示该出口端口的帧间隙(interframe gap,IFG),该值为该端口传输96个比特所需要的时间。 约束2:传输窗口约束:实时业务流fi在链路上的传输窗口大小应刚好等于其数据大小与链路速率的比值,如式(3)所示 ∀e∈ri, (3) 约束3:No-wait约束[10]:该约束保证实时业务流fi在网络中不会排队,即业务流的队列时延为0,如式(4)所示 ∀(u,v),(v,w)∈ri, (4) 其中,tprop及tproc分别表示链路的传播时延及交换机的处理时延。 根据TSN网络部署过程的不同,可以将流量调度问题分为离线调度与在线调度。离线调度与在线调度的不同在于,离线调度问题中所有的业务流都是已知的,而在线调度中,未来所要调度的业务流是未知的。一个典型的离线调度例子是,在一个新的工厂中根据已有的设备及装配流程来规划TSN网络的部署及调度。由于工厂的设备以及对应的应用都是已知的,可以在离线状态下计算出一个较优的调度方案。而在线调度可以认为是在现有的TSN网络增加额外的设备及应用,此时调度新的业务流不应对原有的实时应用造成影响。在耗费时间方面,离线调度允许较长的计算时间,而在线调度所允许的计算时间较短。 在实际的TSN部署中,大多数情况下设备及应用是已知的,从而可以使用离线调度来进行计算,并进行部署。在本文中,考虑混合调度,其指的是在该已部署的网络下新增业务流,所以在这种情况下,需考虑离线调度所计算出的调度方案性能。 本文所提出的基于No-wait约束的在线流调度方法是一种在线的增量式调度算法,其旨在在线地为实时业务流计算出调度结果,即该业务流在源节点的起始发送时间以及其转发路径上交换机的GCL列表。 该算法运行流程如图3所示,首先在初始化阶段设置基期值及网络拓扑,然后进入在线计算阶段。对于每个输入的实时业务流,首先使用最短路径算法(如Dijkstra算法等)计算该业务流的最短路径,然后使用最早调度算法(见下文2.2节)计算该业务流的调度结果。若调度成功,则更新网络的GCL列表,否则停止算法运行。 图3 算法运行流程 在该算法中,设置了一个基期,使得所有业务流的应用周期都是该基期的整数倍(见1.1.3节),然后将实时业务流尽可能地分散调度到各个基期中,来提高可调度流的数量。由于在线运行算法时,未来输入的业务流特征是不可知的,这就要求该基期的值设置得足够小,使得其可以被所有未来可能出现的业务流的应用周期整除。 另一方面,基期值又不应设置得过小。这是因为,过小的基期值会导致调度结果过于分散而出现大量时隙碎片,减小了解空间,最终导致可调度流的数量降低。 所以,基期值应刚好设置为可能出现的所有业务流应用周期的最大公约数。在这种情况下,能够取得最大的流调度数量。 本文所提出的算法旨在在线增量式地求解出调度结果,这就要求新调度的业务流不能干扰已调度的业务流,即已预留的时隙不应被更改。 在该算法中,应将业务流尽可能地调度分散到各个网络周期中,并且将业务流尽早调度到其网络周期的前部。这是由于未来所输入的实时业务流是不可知的,若流的调度过于集中,则可能会导致当需要调度的实时业务流周期太小而无法调度。并且,当每次对新业务流进行调度时,尽管无论调度结果如何,总的剩余可调度时隙都是一样的,但是应可能地使每个基期的剩余可调度时隙更大,即,应将总的剩余可调度时隙尽可能地分散到各个基期中,从而提高未来网络的可调度性。 图4展示了一个案例,其中有3个业务流Flow0~Flow2,RR(应用周期与基期的比值)分别为2/2/1。此时网络中已调度了业务流Flow0。当要调度新的数据流Flow1时,方案(a)与方案(b)都是可行的。然而,如果使用方案(a),将会导致调度结果过于集中,这减小了未来的调度问题解空间。例如,当此时有RR为1的实时流Flow2要调度计算时,若采用方案(a),无论将Flow2放在何处都无法满足约束;而方案(b)因为其对Flow0及Flow1的调度较为分散而能够正常对Flow2进行调度。 算法伪代码如算法1所示,当调度新实时业务流时,首先根据新的流应用周期来更新宏周期(见算法第(3)行,其中lcm函数是求最小公倍数运算),并计算该流的RRi。然后,在其RRi周期内计算其最早的调度时间offset,其结果应满足约束条件式(1)~式(4)。最后选择这RRi周期内最早调度时间作为调度结果。当该业务流在其所有RRi周期都无法调度时,算法停止。此时网络资源已不足以为该业务流预留时隙。 尽管该算法只输出了实时业务流在源节点的起始传输时间,但这已足够得到该流在网络中各节点的传输窗口。这是因为在No-wait约束下,业务流数据帧在网络中不会排队,所以,当确定了实时业务流的起始传输时间,就可以根据式(4)计算出该业务流在其转发路径上的每一跳所需预留的时延窗口。 算法1:最早调度算法 输入:实时业务流fi 输出:起始传输时间start_time (1) cycle_idx =-1 (2) offset = +∞ (3) hyper-cycle = lcm(hyper-cycle,pi) (4) RRi= hyper-cycle/pi (5) for i in range(RRi): (6) tmp = 计算fi在基期i的最早调度时间 (7) if tmp >bp then//在该基期i无法调度 (8) continue (9) if tmp (10) offset = tmp (11) cycle_idx = i (12) if offset == 0 then (13) break (14) return cycle_idx * bp +offset 另外,若该算法能够求解出调度结果,则其一定能满足业务流的最差时延要求,否则,表明此时网络资源已不足以调度新实时业务流。这是因为,影响业务流时延的最大因素是其在网络中的队列时延,而在该算法中,首先为该业务流计算出的路径是最短路径,并且,在后续的调度计算过程中,引入了No-wait约束,该约束又保证了业务流在网络中不会排队,所以使用该算法可以保证为该业务流计算出的调度结果端到端时延是最低的,其一定能满足流的最差时延约束。 在上文中,由于需要调度不同周期的业务流,引入了网络周期的概念,并且,上文所述的在线调度算法分散地将业务流调度到各个基期中以使得剩余可调度空间最大。而在离线调度情况下,由于无需满足调度计算的实时性要求,可以在上一章节所述在线算法的基础上进行改进,从而在离线调度情况下获得较优解。在本章中,提出一种基于重合度的离线式调度算法,其使用禁忌搜索算法来对业务流进行调度。具体地,其尝试以不同顺序对业务流进行调度,来提高调度结果的重合度,增大网络剩余的可调度空间,以使得算法在在线调度时可以调度更多的业务流。 为了衡量调度结果的好坏,对于每一个链路e,定义了一个已调度空间指标me,来表示该链路的调度结果在每一个基期的偏移的并集的时隙长度,该指标的值越小,说明调度结果重合度越高,则调度方案越优。如式(5)所示 (5) 例如,在图4中,将方案(a)与方案(b)进行对比。显然,在方案(b)中,由于Flow0与Flow1在该链路的预留窗口偏移一致,也就是说,Flow0与Flow1的预留窗口偏移的并集小于方案(a)中的并集,即mb 本算法使用重合度来作为网络调度结果评估的重要指标,调度结果的重合度越高,表明该调度方案越优。为了便于计算,对于每一个链路e,计算该链路每个基期的预留窗口偏移的并集,来作为评判指标,记为已调度空间me。该指标越小,则说明各个预留窗口的重合度越高。对于给定网络的调度方案,该指标等于网络中重合度最低(即已调度空间最大)的端口的已调度空间指标,如式(6)所示 mG=max{me},fore∈G (6) 对于某一条实时业务流fi,其评判指标为其路径上的每一条链路的重合度的平均值,如式(7)所示 mfi=avg{me},fore∈ri (7) 在离线模式下,本文使用禁忌搜索算法来对实时业务流进行调度。为了使得算法在后续的在线调度过程中能够调度更多的业务流,该算法选用已调度空间指标mG(见式(6))来评估算法调度结果的性能,即,最小化网络链路中最大的已调度空间,减小网络总体的已调度空间,增大网络的剩余可调度空间。 本算法采用的禁忌搜索算法架构与文献[10]相似,但在critical flow选择、以及解的迭代过程有所不同。本文主要阐述这两个过程,对于其它过程如初始解生成、邻域生成等,这里不再赘述。 3.2.1 Critical Flow的选择 传统的算法一般使用流完成时间,即FlowSpan来定义Critical Flow,其中FlowSpan的含义指的是所有业务流中最慢完成传输的流的时间。而在本文中,由于引入了网络周期的概念,使得业务流在各个网络周期中都有分布,此时FlowSpan就失去了其原有的意义。在本文中,对于某一个给定的调度方案,采用已调度空间mG来评估调度方案的性能。而对于critical flow,类比于FlowSpan中最晚完成的业务流,其应该是导致已调度空间mG缩小的实时业务流。 本算法根据式(7)来对每一条业务流计算其已调度空间指标,即,该流路径上的链路指标的平均值。然后,根据选择出的critical flow,在迭代过程中生成对应的邻域。 3.2.2 当前解的迭代过程 在算法的每一次迭代过程中,都需要对邻域中的每一个邻居使用第2章所介绍的在线调度算法进行调度计算,即,按照该邻居方案的实时业务流调度顺序,以此使用算法1进行调度。然后,使用式(6)计算每一个邻居节点的已调度空间,然后选择最优的(已调度空间指标最小的)邻居节点作为当前解,然后继续迭代,直到超过连续Y次迭代无法找到更优解,停止迭代[10]。 本节对上文所提出算法进行实验,并将所调度结果在Omnet++仿真平台上使用NeSTiNg[13]框架验证算法的有效性。本文所使用算法为C++编写,仿真环境为Ubuntu 18.04。 本文所采用的仿真网络拓扑参考了文献[14]所使用的Medium-mesh网络拓扑,如图5所示,其中交换机之间的网络链路速率为1 GE,终端与交换机之间的网络链路速率为100 Mbps。交换机处理时延tproc为1 μs,链路传播时延tprop为1 μs。为保证数据准确性及可靠性,对每次实验运行了20次,然后计算这20次实验的平均值,得到实验的可靠结果。 图5 仿真网络拓扑 本节实验主要验证在线调度算法在不同实验设置下能够调度的业务流数量。具体的实验流程为,使算法在线运行并随机地生成不同数据特征的实时业务流(其中源节点与目标节点随机选取),当算法无法求解出调度结果时停止运行,得到此时网络中已调度的实时业务流的数量。 4.1.1 实验1-1:流周期影响 本实验主要研究业务流周期大小对可调度流数量的影响。在该实验中,设置了两个实验,其中实时业务流的周期大小设置见表2,流的其它参数设置为:源节点与目标节点随机选取,数据帧大小设置为100 Bytes。基期值设置为100 μs。 表2 实验1-1实时流应用周期设置 实验结果见表3,在该网络拓扑下,Case 3能够调度的流数量远超过其它两个案例。这是由于Case 3中的实时流应用周期相比Case 1及Case 2较大,而应用周期较大的流占用的时隙资源较小,与其它流的冲突约束(见约束1)较少,容易取得较高的流调度数量。 表3 应用周期对流调度数量的影响 注意到Case 3中的流应用周期为Case 2中的流应用周期的10倍,即,平均来说,Case 3中的每一条流所占用带宽为Case 2的十分之一。直觉地,那么Case 3所能调度的流的数量应为Case 2的10倍,但实验结果显示其能够调度的流数量却达到了Case 2的将近20倍。这是由于尽管Case 3中的业务流占用带宽为Case 2中的十分之一,但是其可以分散到不同的基期中调度,受到的约束较小,相对地,其解空间也相比Case 2大。 4.1.2 实验1-2:基期大小影响 如2.1节所述,基期值的设置会影响可调度流数量,基期值太小会使得调度结果过于分散,产生大量的时隙碎片而减小了解空间。在该实验中,维持实时流的流量特征(实验设置为Case 2)不变,而改变基期值的大小见表4。 表4 实验1-2基期值设置 对于该实验设置的业务流,其应用周期的最大公约数是100 μs,由于基期必须整除所有流的应用周期,所以此时基期所能设置的最大值为100 μs。 实验结果如图6所示,随着基期从10 μs到100 μs不断增大,网络平均可调度流的数量也不断增多。当网络周期达到100 μs时,流调度数量达到最大,达到了最差情况下(Case 4)的176%。 图6 基期大小对流调度数量的影响 实验结果显示,基期大小对网络可调度性有较大影响。在实际部署中,算法的基期应设置得较大,来保证网络的可调度性。由于算法是在线运行的,未来的实时业务流数据特征是未知的,此时应估计所可能出现的业务流应用周期的值大小,并将基期值设置为其最大公约数。 4.1.3 实验1-3:调度计算时间 本文提出了一种在线调度算法,由于算法需要在线运行,所以对实时流调度计算耗费的时间成为了一个重要的指标,本实验主要研究该算法在在线调度情况下的调度计算时间。 本实验选取Case3的实时流生成设置,其中数据帧大小为100 Bytes,基期为1 ms。 实验结果如图7所示,图中数据已做平滑处理。随着已调度流数量的增加,算法调度计算所耗费的时间也呈一个上升趋势,并且其波动也越大。这是因为当网络中已调度的实时流数量较多时,对于当前实时流,所受到的约束(见约束1式(2))增多,其所可能受到的冲突也就越多,所以计算次数增加,耗费时间增大。 图7 流调度耗时 总体来说,对于单条实时业务流,算法调度计算平均只需要3.98 ms的时间,满足算法在线运行的要求。 本实验对第3章提出的离线调度算法进行实验验证。在该实验中,首先使用在线调度器对业务流进行在线调度,并不断生成业务流。当在线调度计算失败时,改用离线调度器对前面的所有业务流重新进行调度计算。调度成功后,在该调度结果的基础上,继续使用在线调度器为后续的业务流进行在线调度。直到离线调度器也无法调度时则停止计算,实验流程如图8所示。该实验可以验证本文所述离线算法的有效性,并且同时具有实际意义。例如,在实际部署应用中,由于未来增加的业务流是未知的,所以首先使用在线调度算法来进行增量式调度。当在线调度算法已经无法正常调度业务流时,需要对原来的已调度业务流重新进行计算以使得所有业务流都可以得到调度。 图8 实验2流程 其中,实时业务流的流量特征见表5,基期大小均设置为100 μs,业务流的帧数据大小在对应范围内取平均分布。 表5 实验2实时流设置 实验结果如图9所示,可以看到,相比平均仅能调度40条业务流左右的在线调度,离线调度的调度业务流数量平均提高了58%。并且,观察到使用离线调度成功调度计算的次数为1~2次。即,平均来说,每次使用离线调度器能使得调度流的数量增加29%~58%。这反映了,对于某一条关键业务流,该业务流可能受到的约束较多,当在线调度已经无法对其求解出调度结果时,此时使用离线调度可以重新规划出一个较优的调度结果,从而使得算法可以在线调度更多的业务流,优化效果较为显著。 本文对时间敏感网络No-wait约束下的实时业务流调度问题进行研究,提出了一种在线增量式流调度方法,该方法基于网络周期,可以对不同应用周期的实时业务流进行增量式调度。并且,为了提高网络的可调度流数量,该算法将调度结果分散到各个网络周期。然后,提出了一种基于重合度的离线调度算法,在离线模式下,减小调度结果的已调度空间,以增大剩余可调度空间,为后续的在线调度过程提供了良好的基础,从而提高了业务流的可调度数量。 当前基于No-wait约束实现的调度器由于约束太大,难以调度较多的业务流。在后续研究中,将研究放松No-wait约束来对业务流进行调度,以提高网络的可调度性能。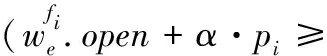




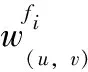
1.3 离线调度与在线调度
2 基于No-wait约束的在线流调度方法

2.1 基期值设置
2.2 尽早调度算法
3 基于重合度的离线流调度算法
3.1 重合度

3.2 基于禁忌搜索算法的离线调度算法
4 实验与分析

4.1 在线调度实验

4.2 离线调度实验


5 结束语
