基于Ghost-CA-YOLOv4的果园障碍物检测算法
2023-12-01鲍致远
景 亮,鲍致远
(江苏大学 电气信息工程学院,江苏 镇江 212013)
0 引言
农业是国民经济的基础,现代农业装备是现代农业的重要支撑。近年来,随着我国老龄化程度逐渐加重,劳动力出现短缺,导致果园运营成本直线上升。因此,果园机器人成为替代繁重体力劳动、改善生产条件、提高生产效率、降低生产成本的关键装备。
无人农机在果园的实际作业中存在一些障碍物,并且经常会出现人与无人农机协同作业的情况。为了确保无人农机作业时的安全性与可靠性,设计一个准确、实时的障碍物检测算法十分必要。
目前,障碍物检测包含激光传感器检测[1]、超声波传感器检测[2]和图像传感器检测[3]方法。在果园作业环境中,图像传感器具备价格低廉、不易受干扰、响应迅速等特点[4]。采用图像传感器检测果园障碍物属于目标检测的子任务,随着近年来计算机计算能力的飞速增长,深度学习方法已成为目标检测领域的主流,主要分为:先候选区域再分类的两阶段检测算法,例如R-CNN[5]、Fast RCNN[6]、Faster-RCNN[7];直接回归物体位置与类别的单阶段检测算法,例如YOLO[8-10]系列算法和SSD[11-12]算法。其中,单阶段检测算法精准度较低,但检测速度快、计算需求资源小。
目前,陈成坤等[13]将YOLOv4 算法应用到嵌入式设备中,但存在实时性较差的问题。陈斌等[14]提出一种改进的YOLOv3-tiny 算法,通过融合浅层特征并引入残差模块,但存在模型参数量较大的问题。魏建胜等[15]提出一种改进的YOLOv3 算法,将损失函数改进为DIoU,但存在精确度较低的问题。
针对上述问题,本文提出Ghost-CA-YOLOv4 网络,采用GhostNet[16]作为主干特征提取网络,并在GhostNet 中引入注意力机制进一步增强主干网络对障碍物特征的关注。同时,将传统YOLOv4 的DIoU-NMS 改进为Soft-CIoUNMS,以降低误检概率。
1 模型设计
1.1 YOLOv4
YOLOv4 的网络结构分为Backbone、SPP、PANet 和Head。其中,Backbone 由一个CBM 模块和多个Resblock_body 叠加块组成,进行初步的提取特征任务;SPP 在原有特征基础上增加13×13、9×9、5×5 的感受野,能更好地处理上下文特征;PANet 将Backbone、SPP 中提取到的特征进行不同尺度的融合,以强化Backbone 的特征提取能力;Head 通过卷积操作输出物体坐标与概率。YOLOv4 的网络结构与模块组成如图1所示。

Fig.1 YOLOv4 network structure and module composition图1 YOLOv4网络结构和模块组成
1.2 改进模型
1.2.1 GhostNet
2020 年,轻量化网络GhostNet 被提出,主要对常规卷积进行优化。由于常规卷积操作会生成大量冗余特征图,而Ghost Module 利用线性变换生成指定比例的冗余特征图,在计算精度几乎相同的情况下,消耗的计算资源更少。
Ghost Module 的具体实现、常规卷积与Ghost Module的区别如图2 所示。首先,Primary Conv 使用1×1 卷积获取必要的浓缩特征,Cheap Operation 使用3×3的深度可分离卷积获取相似特征图;然后将两者进行拼接。

Fig.2 Difference between conventional convolution and Ghost Module and the specific implementation of Ghost Module图2 常规卷积与Ghost Module区别与Ghost Module的具体实现
在线性变换和普通卷积的卷积核大小一样的情况下,假设输入矩阵为A×B×C,输出矩阵为A′×B′×C′,普通卷积的卷积核为K×K,Ghost Module 中总卷积与常规卷积的比例为M,通常M≪C。常规卷积与Ghost Module 的计算量的比值如式(1)所示。
常规卷积与Ghost Module 的参数量比值如式(2)所示。
Ghost Bottleneck 的结构如图3 所示。当步长(Stride)为1 时,由两个Ghost Module 和一个残差边组成Ghost Bottleneck。第一个Ghost Module 扩展输入矩阵的通道数,第二个Ghost Module 缩减通道数。当步长为2 时,在两个Ghost Module 间添加[2×2]的深度可分离卷积完成宽高压缩操作,其他部分不变。Ghostnet 由多个Ghost Bottleneck叠加块组成,结构如表1所示。
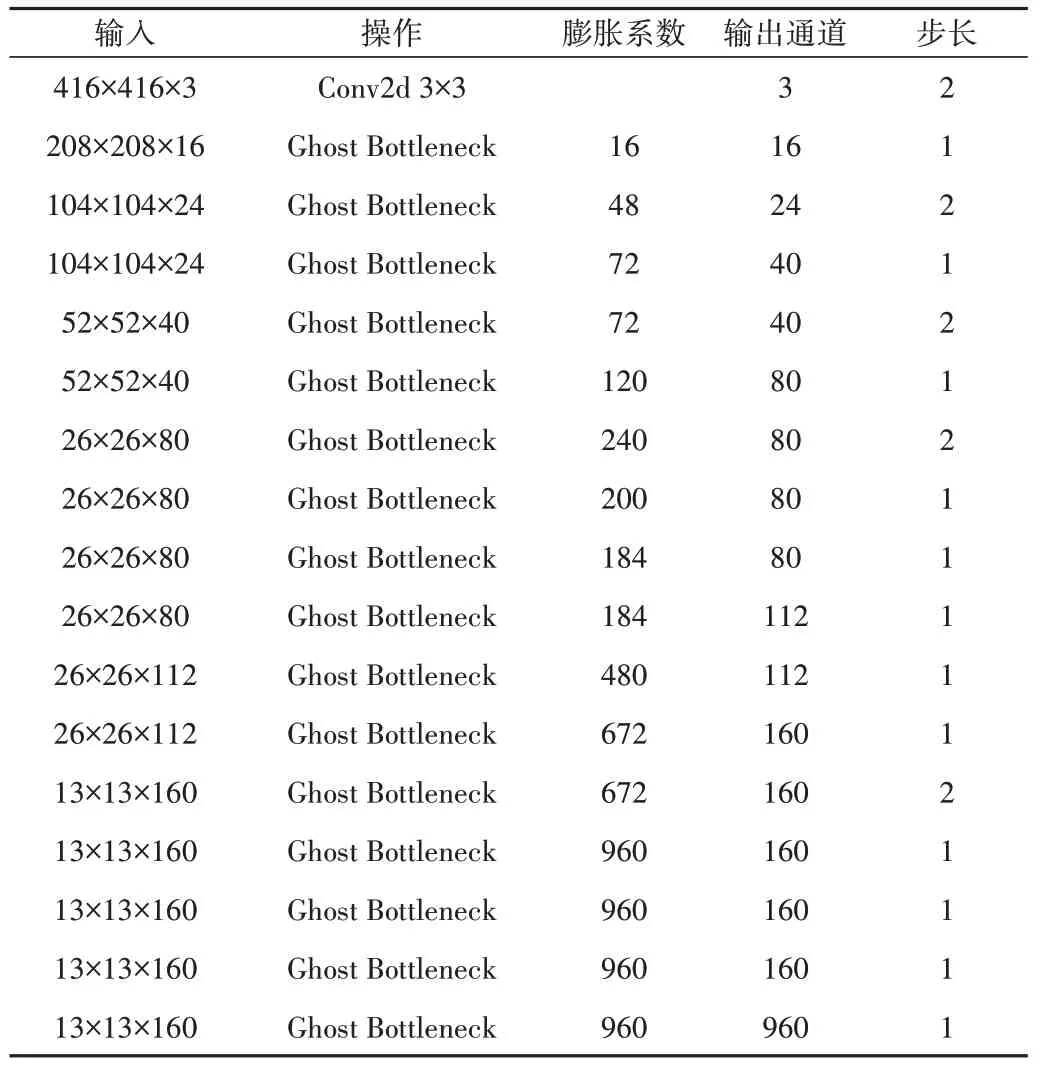
Table 1 Ghostnet structure表1 Ghostnet结构
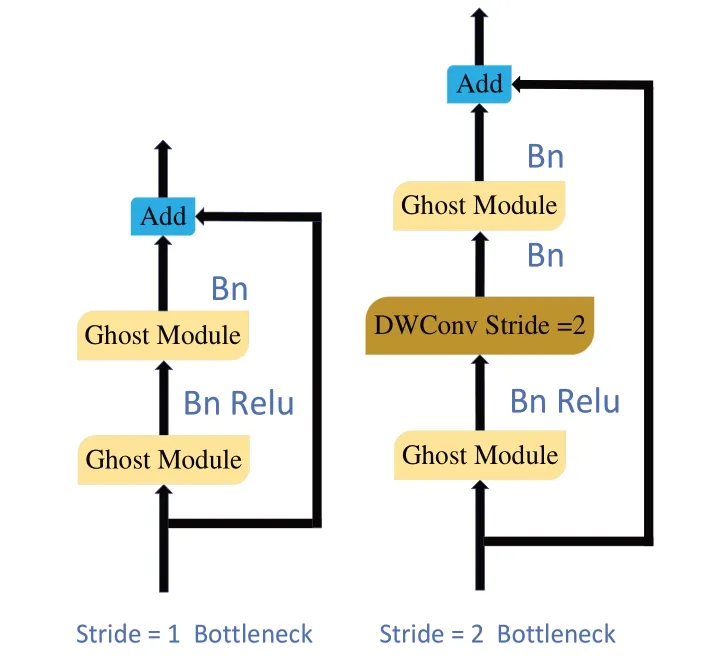
Fig.3 Ghost Bottleneck structure图3 Ghost Bottleneck结构
1.2.2 注意力机制
注意力机制(Coordinate Attention,CA)[17]结合了通道维度信息和空间位置信息,首先进行Coordinate 信息嵌入,然后进行Coordinate Attention 生成,具体结构如图4所示。
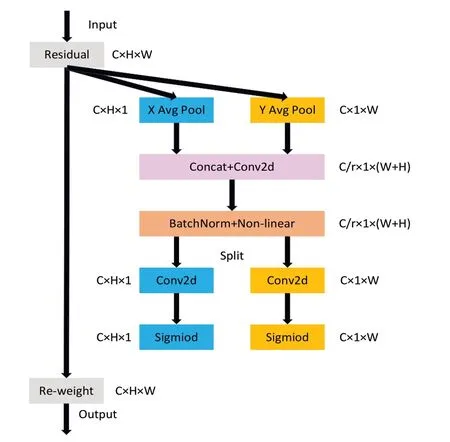
Fig.4 Structure of coordinate attention mechanism图4 CA注意力机制结构
Coordinate 信息嵌入描述如下:沿着输入矩阵的水平(X)轴和垂直(Y)轴分别进行全局池化得到两个不同的空间方向特征。其中,水平(X)轴使用H×1 的卷积核进行全局池化,将输入矩阵C×H×W转换为C×H×1 的矩阵。
垂直(Y)轴使用1 ×W的卷积核进行全局池化,将输入矩阵C×H×W转换为C×1 ×W的矩阵。
Coordinate Attention 描述如下:将两个空间方向特征先进行特征融合,然后进行1×1 卷积,最后通过非线性激活函数变换,得到中间特征映射f。
式中:[]为特征融合操作;δ为非线性激活函数;F1为1×1卷积变换函数。
对中间特征映射f进行空间维度分解,经过1×1 卷积和Sigmoid 函数得到特征gh、gw。
式中:σ为Sigmoid 函数;Fh、Fw为1×1卷积变换函数。
将输入矩阵的残差与gh、gw相乘得到最后的输出矩阵。
式中:yc为最后的输出矩阵;xc为输入矩阵的残差。
本文对Ghost Bottleneck 进行改进以提升检测精度。当步长为1 时,在两个Ghost Module 间引入CA 注意力机制;当步长为2 时,在深度可分离卷积后引入CA 注意力机制。改进后的Ghost Bottleneck 如图5所示。

Fig.5 Improved Ghost Bottleneck图5 改进Ghost Bottleneck
1.2.3 改进后的网络
改进后的网络Ghost-CA-YOLOv4 结构如图6 所示,采用Ghostnet 作为主干特征提取网络,并在Ghostnet 中引入CA 注意力机制。
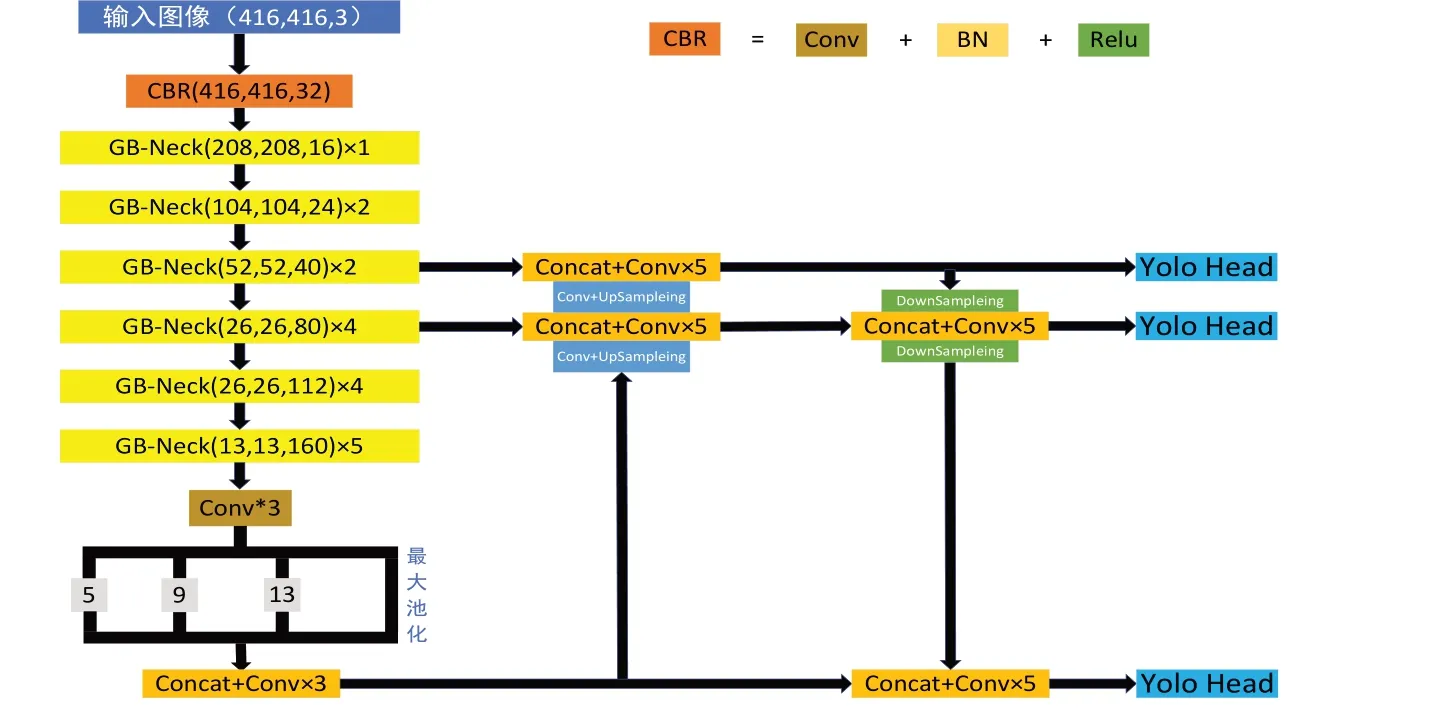
Fig.6 Improved Ghost-CA-YOLOv4 network structure图6 改进Ghost-CA-YOLOv4网络结构
1.2.4 Soft-CIOU-NMS
YOLOv4 使用的DIoU-NMS 算法计算其余预测框与置信度最高检测框重叠的程度,仅保留低于阈值的框。由于果园环境中存在检测目标相互遮蔽的情况,DIoU-NMS 存在漏检误检的问题[18]。为此,本文提出Soft-CIoU-NMS 算法,首先保留高于阈值的检测框,然后根据重叠程度对其置信度进行调整,重叠程度采用CIoU 计算。Soft-CIoUNMS的计算公式如式(9)—式(11)所示。
式中:Si为当前预测框的置信度得分;RCIoU表示CIoU损失函数的惩罚项;Bi为当前类别中全部的预测框;μ为置信度最高的预测框;ε为预先设定的阈值;b为预测框的中心点;bgt为真实框的中心点;ρ为两个框中心点的欧式距离;C为两个预测框的外接框的对角线像素长度;α为权重函数;ν为度量宽高比一致性的量化指标;wgt为真实框宽度;hgt为真实框高度;w为预测框宽度;h表示预测框高度。
由此可见,Soft-CIoU-MNS 相较于DIoU-NMS 虽然增加了一部分计算,但仅占整体计算量的小部分,并不影响检测速度。
2 实验结果与分析
2.1 数据集
本文数据集为在江苏大学拍摄的1 600 张图片,通过Labelimg 标注工具对拍摄图片进行真实框标注,标注格式为PASCAL VOC,数据集包括树(Tree)、人(People)、杆(Pole)3 种障碍物,其中人的姿态主要有站立、坐和蹲,按照8∶1∶1 的比例将数据集划分为训练集、验证集和测试集,如图7所示。

Fig.7 Self-made dataset图7 自制数据集
为了进一步提升模型的泛化能力,在训练前对数据集进行数据增强操作。本文实验采用的数据增强方法包括随机翻转、裁剪、对比度调整、颜色变换,使得数据集图片数量增加到3 200张。
2.2 实验环境
计算机硬件为Inter(R)Core i7-10870H CPU、NVIDIA RTX 3070 Laptop GPU、运行内存16 GB;训练框架为Pytorch 1.7.1 和Cuda 11.2;编程语言版本为Python 3.8.5,操作系统为Windows 10。本文具体训练参数如下:图像输入尺寸为416×416,优化器SGD 的批尺寸为8、动量为0.94、权重衰减系数为0.001,初始学习率为0.001,衰减率为0.95。
2.3 评价机制
本文使用准确率(Precision,P)、召回率(Recall,R)、类别平均精度(mAP),模型参数大小(单位为MB)和每秒传输帧数(FPS)对模型进行评价,如式(12)—式(14)所示。
式中:TP代表被正确分类的正样本;FP代表被错误分类的负样本,FN 代表被错误分类的正样本;AP代表某个类别的平均精度;NoC代表数据集中待检测目标总类别数。AP计算公式如式(15)所示:
2.4 比较实验
为了验证改进模型的效果,对YOLOv4、YOLOv4-Tiny、MobileNetv3-YOLOV4 和Ghost-CA-YOLOv4 进行比较,每个模型均在自制数据集上训练200 个周期(Epoch),各性能指标如表2所示。

Table 2 Comparison of detection indicators of different models表2 不同模型检测指标比较
由表2 可知,Ghost-CA-YOLOv4 模型相较于YOLOv4,在精准率、召回率、mAP 方面分别提升0.78%、0.55%、0.87%;相较于YOLOv4-Tiny 分别提升9.88%、12.77%、13.61%;相较于MobileNetv3-YOLOV4 分别提升1.71%、3.39%、3.63%。在模型大小方面,Ghost-CA-YOLOv4 相较于YOLOv4 缩小82%;相较于YOLOv4-Tiny 增大97%,相较于MobileNetv3-YOLOV4 缩小17%。Ghost-CA-YOLOv4 的FPS 在4种模型中仅次于YOLOv4-Tiny。综合而言,Ghost-CA-YOLOv4 在检测精度和速度方面性能更好。具体检测效果如图8、图9所示。

Fig.8 Detection effect image1图8 检测效果图1

Fig.9 Detection effect image2图9 检测效果图2
由图9 可见,在面对目标重叠或密集的情况下,Soft-CIoU-NMS 算法、Ghost-CA-YOLOv4 依然能保证检测的准确性,YOLOv4、YOLOv4-Tiny、MobileNetv3-YOLOV4 存在漏检或检测精度较低的现象。
2.5 消融实验
为了验证Ghostnet、CA 注意力机制和Soft-CIoU-NMS提升YOLOv4 性能的有效性,在训练集和验证集相同的情况下设计消融实验,如表3 所示。由此可见,替换主干网络导致模型的mAP 下降3.32%,模型大小缩减82.44%;引入CA 注意力机制后mAP 提升3.48%,模型大小小幅增加,表明CA 注意力机制可有效提升模型的特征提取能力;加入Soft-CIoU-NMS 后模型的mAP 提升0.81%,表明该部分能降低误检概率,进一步提升模型性能。

Table 3 Results of ablation experiment表3 消融实验结果
3 结语
本文提出一种基于Ghost-CA-YOLOv4 的果园障碍物检测算法,将Ghostnet 作为主干网络对模型进行轻量化操作,并在Ghostnet 中结合CA 注意力机制,以提升模型对位置信息和通道信息的关注程度。在后处理部分,将DIoUNMS 改进为Soft-CIoU-NMS 以增强模型在目标重叠或密集时的检测能力。
实验表明,Ghost-CA-YOLOv4 模型检测精度更高、检测速度快且模型较小,能更好地满足果园机器人的作业需求。未来可通过通道剪枝技术获得最佳轻量化模型,使其能在嵌入式设备上有具有更快的检测速度和更高的检测精度。同时,由于在实际果园场景中会出现大量喷雾的情况,后续工作也可研究去雾算法,将其与现有目标检测算法结合,在实际作业中更好的完成避障感知任务。
