一种优化空天地一体化网络吞吐量算法
2023-11-28杜丹冰
杜丹冰
(长春师范大学教育学院,吉林 长春 130032)
0 引言
为了满足全球全面的三维覆盖和在将来随时随地访问的长期需求,空天地一体化网络已成为当今世界的重要研究方向。在空天地一体化网络[1]中,无人机(unmanned aerial vehicles, UAV)[2]作为空中基站(base stations, BS),为地面用户提供视距(line-of-sight, LoS)通信链路,提高蜂窝网络对地面用户覆盖率和网络吞吐量。
然而,基于UAV-协助的通信系统面对诸多挑战。例如,UAV的移动和位置对通信系统性的影响。此外,由于频谱资源稀缺,如何有效管理UAV的频谱资源也是空天地一体化网络的关键。文献[3]讨论了频谱资源的分配问题,并提出基于连续凸优化技术的UAV轨迹和功率分配策略[4]。
除了频谱资源分配问题外,回程链路的连通也是空天地一体化网络必须考虑的问题之一。文献[5]采用宏基站提供回程链路通信,并通过优化UAV的二维轨迹最大化吞吐量。文献[6]讨论了基于卫星-UAV网络的资源分配问题,并采用单近地轨道(low earth orbit, LEO)卫星为UAV提供回程链路。然而,该策略并没有优化UAV的位置。
为此,针对空天地一体化网络,文中提出基于强化学习的链路优化(reinforcement learning-based link optimization, RLLO)算法。RLLO算法通过优化卫星-基站和基站-用户间资源分配,资源管理和UAV的轨迹,提高系统吞吐量。具体而言,先建立目标问题,再利用强化学习求解。仿真结果表明,文中所提出的RLLO算法有效地提升了吞吐量和地面用户端的可达速率。
1 系统模型
1.1 网络拓扑
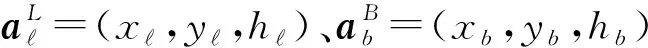

图1 系统模型Fig.1 System Model
以rb,k表示用户k与基站b间的平面距离(二维距离),以db,k表示用户k与基站b间的三维距离。
以二值变量Kb(t)表示在时刻t的用户k是否与基站b∈B关联,其中B=S∪U,时刻t的时长为Ts,且t∈{1,2,…,N},其中N为总时刻数。若Kb(t)=1,则表示它们关联;否则,Kb(t)=0。
此外,时长Ts足够小,致使每个UAV在一个时隙内的位置不变。假定所有通信是在毫米波段完成,并且不考虑卫星对用户接入链路的干扰。
1.2 回程链路
在卫星的回程链路中,卫星均匀分布在环形轨道,并且在y轴移动方向上的高度H固定[7]。卫星在轨道平面内的轨道速度为[8]:
(1)
式中:G,M分别为地球的万有引力常数、质量;R表示地球的半径。轨道周期为:
(2)
假定回程链路的总带宽为wBCK。将wBCK等间隔地划分为L个带宽。每个卫星与每个BS间链路为视距链路(line-of-sight, LoS)[7]。因此,卫星与基站b间的自由空间的路径衰耗为:
L(t)=32.45+20lgfc+20lg(d(t))
(3)
式中:d(t)为卫星与基站b间在时刻t的距离。
依据香农公式[6],卫星给基站b提供的速率:
(4)
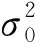
(5)
式中:G,Gb,G分别为卫星的发射天线增益,基站b的接收天线增益;为基站b离卫星的最大距离[9]:
(6)
式中:rb,o为基站b离地球中心的距离;rb,L为基站b离卫星的最短距离。
1.3 接入链路
用户依随机游走移动模型进行移动。在时刻t,用户k∈K在速度范围[Vmin,Vmax]内随机移动。
以Q表示接入链路的可用信道集,wACC表示可用的带宽。将总带宽wACC划分为Q个正交信道。
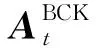
依据香农公式,基站b为用户k提供的最大速率可表示为:
(7)
式中:γb,k(t)为与基站b关联的用户k端的信干扰比,其定义为:
(8)
式中:pb(t)为基站b的传输功率;gb,k(t)为基站b与用户k的信道增益;b′∈B/b;ρb(t)为在时刻t基站b的负载[10]:
(9)
式中:ϑk为数据包达到率;ζk为用户k的数据包尺寸的均值。
为了简化表述,令ρb(t)=fb(ρ(t)),且ρ(t)=ρ1(t),…,ρB(t)。因此,将式(9)改写为[11]:
ρ(t)=f(ρ(t))
(10)
式中:f(ρ(t))=(f1(ρ(t)),…,fB(ρ(t)))。
利用标准干扰函数迭代求解式(10)得到[11]:
ρm=min(f(ρm-1),1)
(11)
式中:ρm为第m次迭代后的输出,其中m∈{1,2,…,Mt};Mt为总的迭代次数。
依据文献[12],用户k与基站b间链路呈LoS链路的概率可表示为:
(12)

(13)
式中:(xb(t),yb(t))为时刻t的基站b的位置;(xk(t),yk(t))为时刻t的用户k的位置。
因此,时刻t基站b与用户k间信道增益为:
(14)
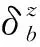
(15)
2 RLLO算法
2.1 目标问题

(16)
式中:Pb为基站b的可用传输功率集;条件第1行对基站b的传输功率和信道进行约束;条件第2行对基站负载进行约束,使基站的负载率不高于1;条件第3行、条件第4行对基站关联的卫星数进行约束,使每个基站至少关联到一个且只有一个卫星;条件第5行、条件第6行对用户关联的基站数进行约束,使每个用户至少关联到一个且只有一个基站。
为了能有效地求解式(16)所示的目标问题,将该目标问题分解成两个子问题:1)回程链路的基站与卫星间的关联问题(以下简称第一子问题);2)接入链路中用户与基站的关联,资源管理和UAV轨迹的设计的联合问题。
可表述为:
(17)
由式(17)可知,每个基站选择离自己具有最强的信号强度的卫星为自己服务。
2.2 基于增强学习的目标问题求解
提升接入链路的吞吐量是设计RLLO算法的主要目的。RLLO算法通过优化基站的传输功率和信道以及UAV的轨迹,最大化接入链路的吞吐量。由于穷尽搜索算法求解联合问题的计算量过大,RLLO算法引用强化学习算法求解。强化学习算法能够通过观察、奖励和动作来学习对输入的正确反馈。
在强化学习算法中,基站扮演玩家,即将基站集B作为玩家集;值得注意的是,基站包含微基站SBS和无人机UAV。UAV作为空中飞行基站,如图2所示。
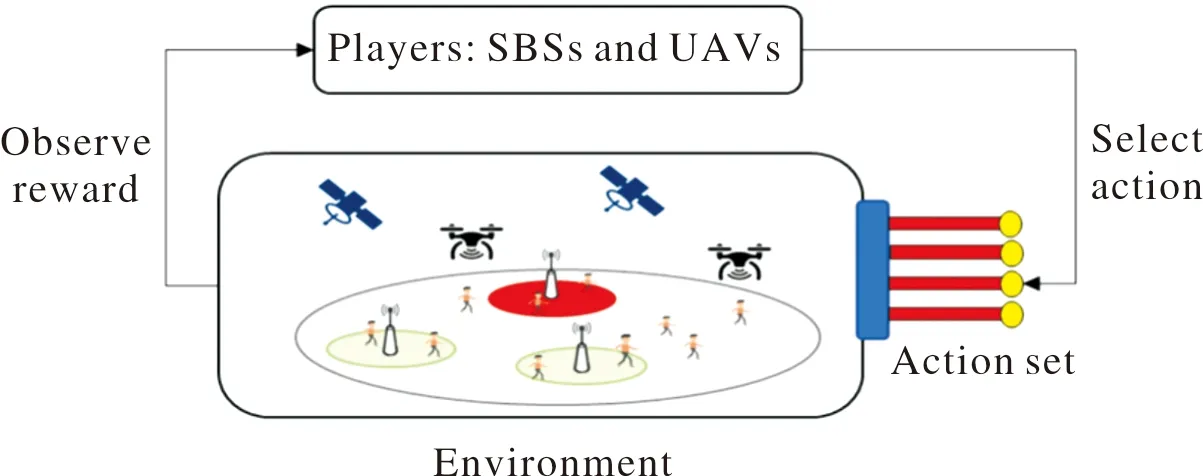
图2 强化学习框架Fig.2 Reinforcement learning structure
由于SBS和UAV的特性不同,它们采取不同的动作。具体而言,对于编号为s的SBS,用as,i表示其动作,由SBS的传输功率和信道两项信息构成,即as,i=(ps,qs),其中i∈{1,2,…,AS}。而AS=Ps×Q,且ps∈Ps,qs∈Q分别表示s的传输功率和信道。
对于编号为u的UAV,令zu和Zu分别表示其移动方向和移动方向集,即Zu={up,down,left,right,forward,backward,static}。用au,i表示其动作,由传输功率,信道和移动方向三项信息构成,即au,i=(pu,qu,zu),其中i∈{1,2,…,AU},且pu∈Pu,qu∈Q,zu∈Zu。
此外,利用式(18)计算选择编号为u的UAV作为空中基站b的奖惩函数:
(18)
式中:Cmax为归一化因子。
2.3 基于多臂老虎机问题的强化学习
强化学习算法通过不断获取周边环境的反馈来达到学习目的,即强化学习算法根据当前环境进行判断,并选择相应的动作措施,从而迫使环境状态发生改变,环境的改变带来潜在的“奖赏值”。再将奖赏值反馈算法,进而达到学习目的。
一般而言,在多步动作之后,才能观察到强化学习任务的最终奖赏。考虑最简单的情形:最大化单步奖赏。即在当前时刻,在所有能采取的动作集合中,选择能使奖赏最大的动作。多臂老虎机问题(multi-armed bandits problem, MAB)是强化学习任务对应的理论模型。MAB就是如何在有限时间内,获取最大化摇臂机的累计奖赏的理论算法。
在MAB问题中,赌徒对应玩家;手臂对应动作。每位赌徒从手臂动作集中选择一个手臂,然后再观察所选手臂的奖励。为了获取基站最优的动作,采用上限置信区间(upper confidence bound, UCB)算法求解MAB问题。UCB考虑的是每个手臂奖赏的置信区间的上界。
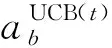
(19)
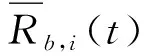
3 性能分析
3.1 仿真参数
在1 000 m×1 000 m区域内均匀分布用户和基站。系统的仿真参数如表1所示。除最大传输率为24 dBm外,基站的其他相关参数如表2所示。

表1 系统仿真参数Table 1 System parameter
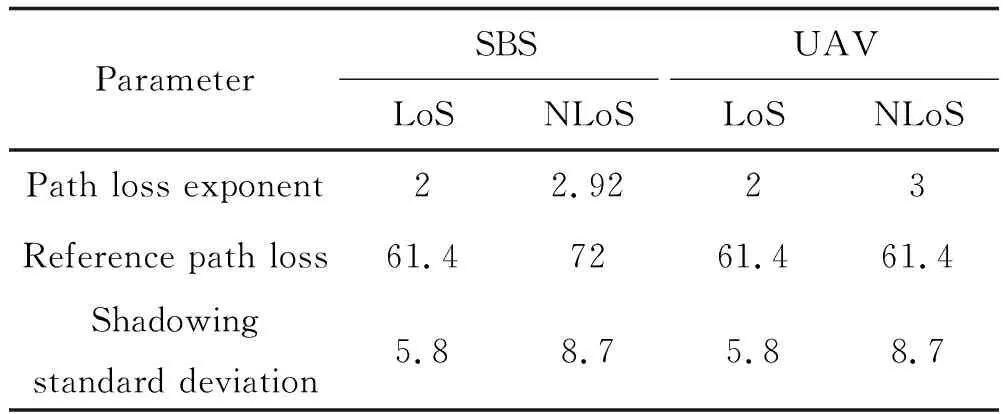
表2 基站的相关参数Table 2 BS parameter
为了更好地分析RLLO算法的性能,选择两个基准算法进行比较:随机选择(Random)和基于Q学习(Q-Learning)算法。Random算法表示每个基站以等概率随机选择其动作;Q-Learning算法表示基站通过Q-Learning学习选择其传输功率和信道。同时,UAV随机地选择其移动方向。
3.2 微基站的平均吞吐量
首先,分析UAV数对接入链路中的微基站的平均吞吐量的影响,设用户数为300,如图3所示。由图3可知,当UAV数从0增加至2,微基站的平均吞吐量也随之增加。但是当UAV数大于2后,微基站的平均吞吐量就随之下降。原因在于:最初UAV数的增加,UAV扮演空中基站并分担了微基站的负载,致使微基站的平均负载下降。因此,每个微基站的平均吞吐量就随之上升。
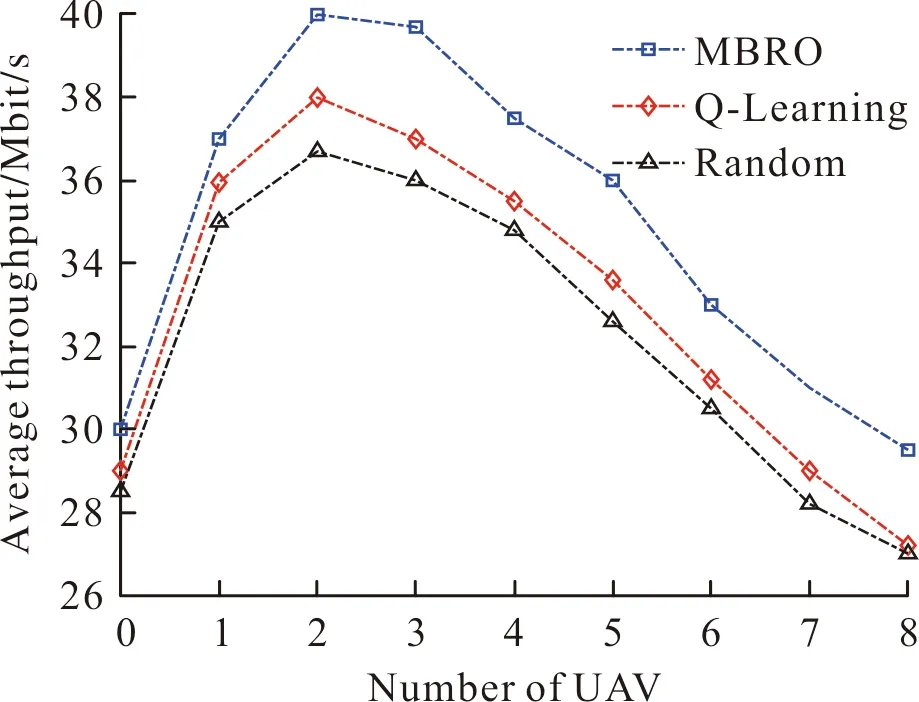
图3 基站的平均吞吐量Fig.3 Average throughput of BS
但当UAV数增加到一定数量时,UAV分担的负载更多。由于用户数固定,每个微基站的平均负载下降,最终导致吞吐量下降。此外,相比于Random和Q-Learning算法,RLLO算法有效地提升了吞吐量。
3.3 用户的平均速率
分析接入链路中用户的平均速率,设用户数为300,UAV数为1~8,如图4所示。由图4可知,用户的平均速率随UAV数的增加而增加。原因在于:UAV数越多,每个UAV为用户分担的负载越少,分配的带宽越宽,速率就越高。相比于Random算法和Q-Learning算法,提出的RLLO算法有效提升用户的平均速率。这归功于:RLLO算法通过分配带宽、传输功率的调整,最大化了用户的平均速率。
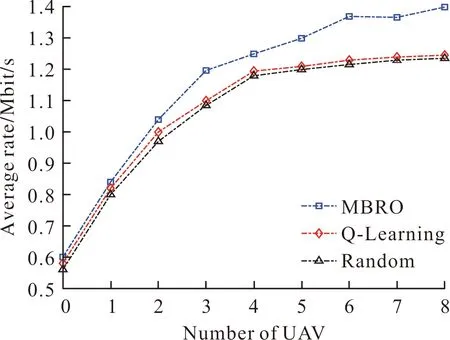
图4 UAVs数对用户的平均速率的影响Fig.4 Average rate versus the number of UAVs
图5给出用户数对用户的平均速率的影响,设用户数为50~400,UAV数为4。由图5可知,用户数的增加,导致用户的平均速率下降。原因在于:每个微基站可获取的资源一定,当用户数增加,每个微基站的负载就随之增加。最终,导致用户端的信干比下降。
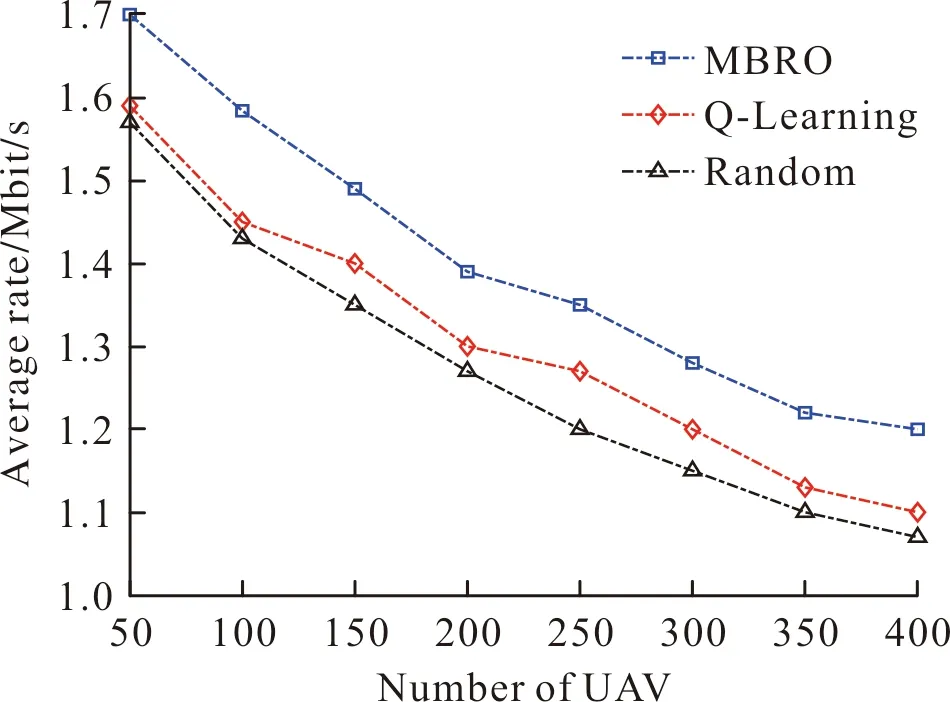
图5 用户数对用户的平均速率的影响Fig.5 Average rate versus the number of users
3.4 链路中断的用户数
下面分析链路发生中断的用户数,设用户数为50~400,UAV数为4。如图6所示。
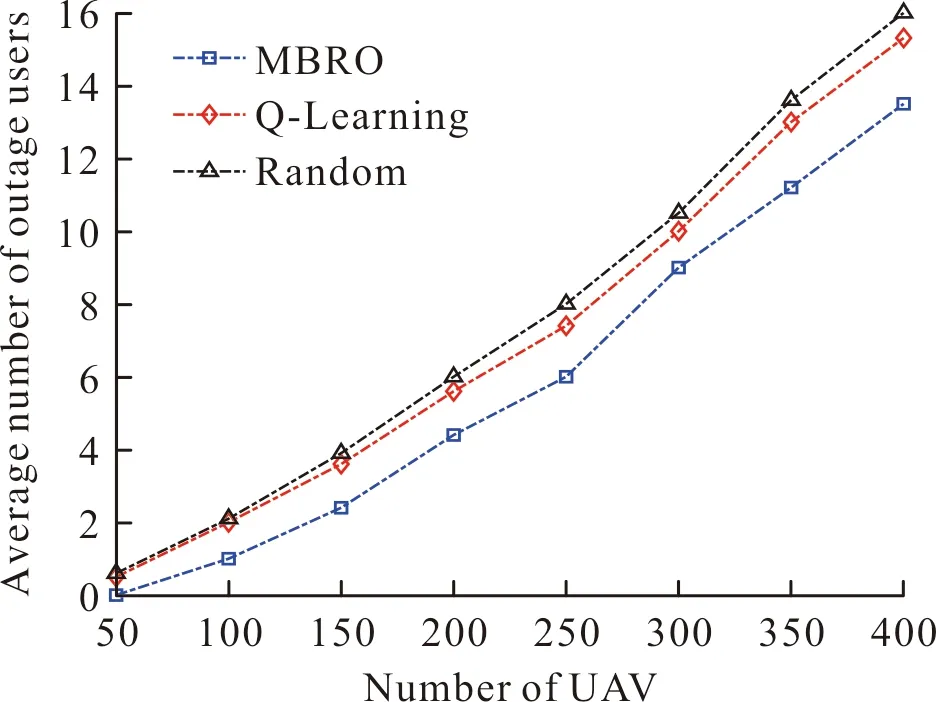
图6 链路中断的用户数Fig.6 Average number of outage users versus the number of users
由图6可知,链路中断的用户数随用户数的增加而上升。原因在于:用户数越多,网络资源竞争越激烈,导致更多链路发生中断。相比于Random算法和Q-Learning算法,RLLO算法减少了发生链路中断的用户数。这说明RLLO算法有效分配了网络资源,为用户提供了稳定的数据传输链路。
3.5 算法的运算性能
分析RLLO算法、Q-Learning算法和Random算法的运算性能,利用运行时间评估其运算性能。运行时间越短,算法复杂度越低,运算性能越优。
表3为RLLO算法、Q-Learning算法和Random算法的运行时间。运行时间取独立运行次数为20时的平均值。

表3 运行时间Table 3 Runtime
由表3可知,RLLO算法与Q-Learning算法的运行时间相近,且RLLO算法的运行时间略高于Q-Learning算法。RLLO算法和Q-Learning算法均采用强化学习算法,但由于Q-Learning算法采用随机方式设定UAV移动方向,并没有优化。因此Q-Learning算法的运行时间低于RLLO算法。此外,由于Random算法只以随机方式选择动作,并没有利用算法优化选择动作的过程,复杂度低,运行时间最短。
4 结论
文中通过联合优化回程链路和接入链路的资源,提高了空天地一体化网络的吞吐量。RLLO算法假定LEO卫星提供回程链接,而微基站和UAV为地面用户提供服务。为了使基站能够学习到最优的策略,RLLO算法采用强化学习,并利用基于MAB算法优化UAV的三维轨迹和基站的资源分配。仿真结果表明,相比于Random和Q-Learning算法,RLLO算法提高了网络吞吐量和用户端的速率。
