基于YOLO-GR算法的轻量化钢材表面缺陷检测*
2023-11-28吴亚尉明帮铭何剑锋钟国韵
吴亚尉,明帮铭,何剑锋,钟国韵
(东华理工大学a.江西省核地学数据科学与系统工程技术研究中心;b.江西省放射性地学大数据技术工程实验室;c.信息工程学院,南昌 330013)
0 引言
随着“中国制造2025”规划的提出,钢铁生产在自动化程度上有了较大的提高,但针对带钢表面缺陷种类繁多、形态复杂,传统人工检测方法已无法满足企业自动化生产要求。因此探索开发高效且高精度的自动化检测方法将是实现钢铁自动化生产的关键之一。计算机视觉技术的发展,特别是深度学习技术的应用,为带钢表面缺陷检测提供了新的解决方案。
在计算机视觉领域,深度学习技术已经成为目前最为先进的技术之一,其中许多学者基于深度学习提出的目标检测技术具有广泛的应用前景。而其中作为Two-stage目标检测算法中经典的Faster R-CNN[1]被大量用于工业缺陷检测。相比于传统机器学习模型,Two-stage目标检测模型虽然在检测精度上有显著提升,但在实时检测方面存在较大的局限性。近年来,部分研究者探索了可能实现实时检测的one-stage目标检测模型[2]。
One-stage检测算法中的YOLO(you only look once)算法[3]因其具有检测速度快、精度高等优点,是目前工业缺陷检测领域应用最为广泛的目标检测算法之一。针对带钢表面缺陷检测中存在的检测效率和检测精度较低等问题,研究者通过改进YOLO系列模块实现了高精度、实时性的缺陷检测模型[4-5]。但随着YOLO算法的不断改进和升级,YOLOv5算法成为目前性能最为出色的版本之一。然而,对于带钢表面缺陷检测这样的特殊应用场景,传统的YOLOv5模型仍然存在一些不足之处,如对大尺度目标类别的检测能力较差、网络结构复杂、模型较大等。王子豫等[6]引入注意力机制对YOLOv5进行改进,有效的提升网络特征提取能力。闫钧华等[7]通过对空间金字塔图进行跨层级通道特征融合以及结合位置注意力机制CA,提出一种融合多层级特征的遥感图像地面弱小目标检测YOLO算法。但只针对网络检测精度方面的提升无法满足模型在自动检测设备上的部署。
本文在保证效率的前提下,通过引入了GhostV2 Bottleneck轻量化模块、RepLK大卷积和W-IoU损失函数改进了YOLOv5模型,实现高精度的轻量化带钢表面缺陷检测。
1 算法模型
1.1 网络结构
YOLO-GR是一种轻量化的目标检测模型,其网络结构分为3个部分:Backbone、Neck和Head。整体网络结构如图1所示。
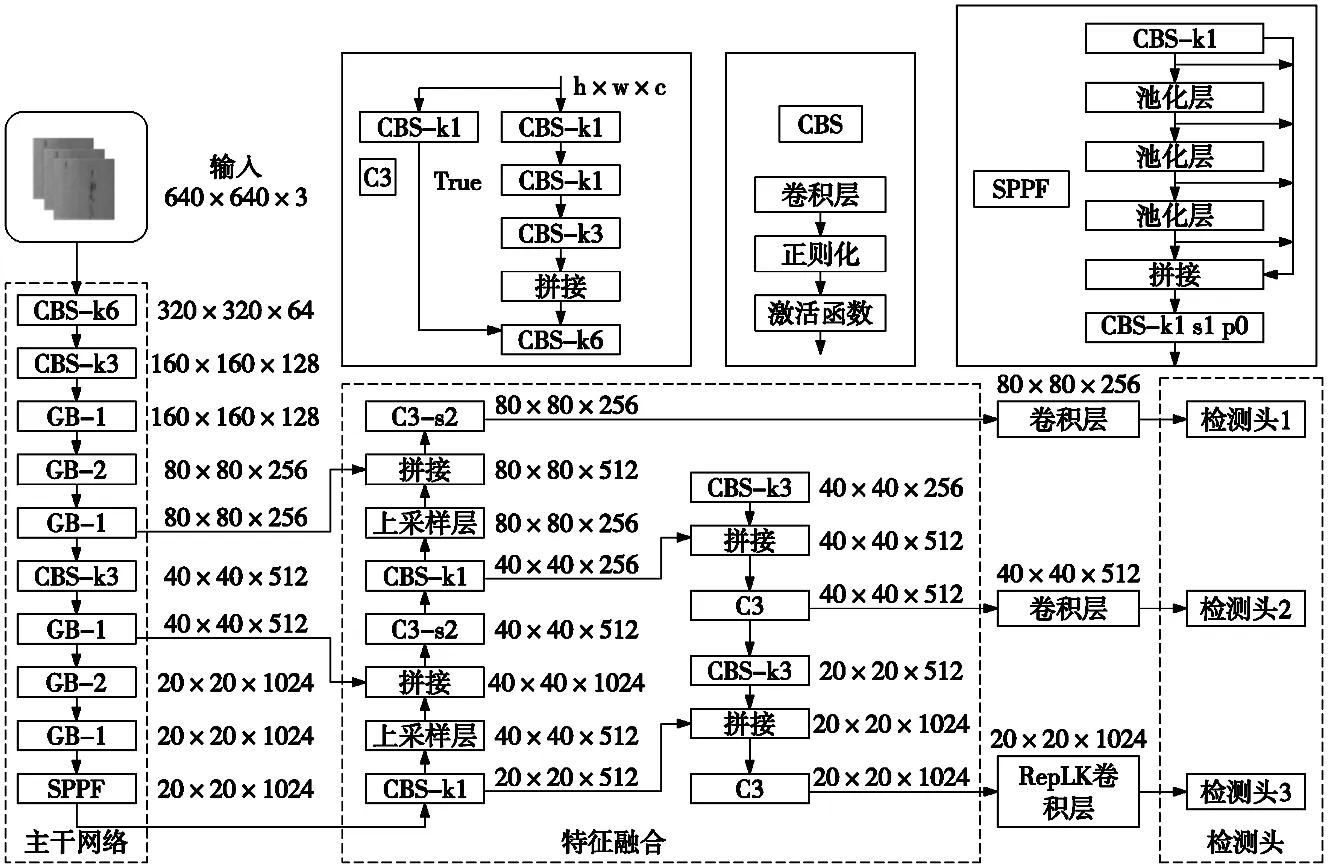
图1 YOLO-GR网络结构图
YOLO-GR的Backbone主干网络主为网络特征提取部分,采用CSPDarknet53网络结构[8],其中GB-1、GB-2为本文替换的轻量化模块,能够减少模型的计算量和参数数量,并且可以提高模型的准确率。Neck特征融合部分采用SPP(spatial pyramid pooling)结构,这个结构可以自适应地将不同大小的目标框中的信息提取出来,使得模型对不同大小的目标具有较好的适应性。此外,还采用了PAN(path aggregation network)模块[9],可以将不同层次的特征图进行聚合,增强了模型的感受野,提高了检测性能。Head检测头部分依旧采用YOLOv3[9]中的结构,并且在此基础上加入了RepLK卷积进行了改进,YOLO-GR中的head部分包含了3个不同大小的检测头,分别用于检测不同大小的目标。每个检测头都由3个卷积层组成,用于检测目标的类别、位置和置信度。此外,还采用了FPN(feature pyramid network)结构[10],能够自适应地将不同层次的特征图进行融合,提高了检测性能,边界框损失计算采用的是CIoU loss[11]。
1.2 GhostnetV2轻量化模块
1.2.1 GhostNet Bottleneck结构
GhostNet[12]是一种SOTA轻量级模型,它的主要组成部分是Ghost模块,它可以通过使用较少的计算量来生成更多的特征映射来替换原来的卷积,可消除一些冗余特征,减少计算量,使模型更轻量化,原理图如图2所示。
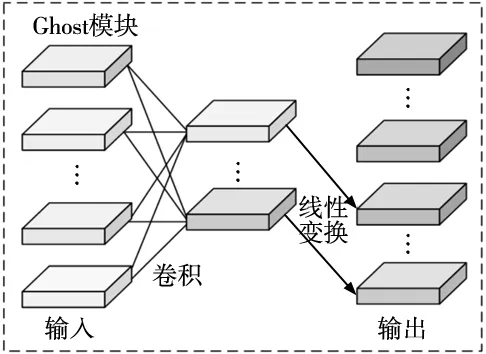
图2 Ghost模块原理
Ghost模块主要分两步构成,第一步对其中一部分特征图进行卷积操作,对于给定输入特征X∈RH×W×C使用F1×1卷积核生成m个内在特征Y′:
Y′=X*F1×1
(1)
第二步再使用计算量较小的操作(如深度卷积滤波器Fdp)根据内在特征Y′生成n=ms个输出特征Y∈RH×W×Cout,两部分特征沿通道维度连接,如式(2)所示[13]。Ghost模块经计算可将运算量缩小至普通卷积的1/s。图4a所示为两个步长不同的GhostNet Bottleneck模块。
Y=Concat([Y′,Y′*Fdp])
(2)
1.2.2 解耦全连接注意力机制
在计算机视觉信息处理过程中引入注意力机制,不仅可以将有限的计算资源分配给重要的目标,还能够产生出符合人类视觉认知要求的结果。
在GhostNetV2[13]中,根据所需要注意力机制的3种特性:长距离、高效率部署、模块简单,设计了一种针对端侧架构的解耦全连接注意力机制。它采用了一种更简单,更容易实现的具有固定权重的全连接层(FC)来生成具有全局感受野的注意力图,如式(3)所示[13]。
(3)
给定输入特征zi∈RC,i.e.,Z={z11,z12,…,zHW},其中⊙是逐元素乘法,F是全连接层中的可学习权重,A={a11,a12,…,aHW}是生成的注意力图。式(3)可以通过将所有标记与可学习的权重聚合来捕获全局信息它的计算过程仍然需要二次复杂度即(i.e.,ο(H2W2))2。特征的2D形状提供了一个视角来减少FC层的计算,即将式(3)分解为两个FC层,并分别沿水平和垂直方向聚合特征。
(4)
(5)
式中:FH和FW是转换权重,将原始特征zi作为输入,分别应用于式(4)、式(5)[13]中,沿两个方向捕获远程依赖,如图3的解耦全连接(DFC)注意力机制所示[13]。由于水平和垂直变换的解耦,注意模块的计算复杂度可降低到ο(H2W+HW2)。
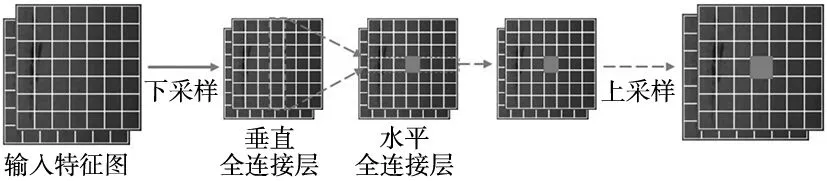
图3 DFC注意力机制信息流聚合过程
如图4b所示。在相同的输入下,Ghost模块和DFC注意是两个并行分支,从不同的角度提取信息。输出是它们的元素乘积,其中包含来自Ghost模块的两个特征和DFC注意力模块的注意力的信息,其中DFC注意增强了扩展的特征,以提高表达能力。

(a) GhostNet Bottleneck

(b) GhostNetV2 Bottleneck
YOLOv5s网络中的Bottleneck结构对输入特征图先后使用32个1×1卷积核和64个3×3卷积核进行卷积操作,因此本文采用步长为1的GB-1替换网络中的C3模块,使用步长为2的GB-2替换网络中的CBS模块,在保证能相对增强图像特征提取能力的同时减少模型的计算量。
1.3 使用RepLK大卷积
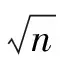
(6)
采用单个大卷积核相比于添加网络深度能更高效地提升有效感受野,在RepLkNet中,DING等[14]使用深度可分离超大卷积、加入shortcut、使用小卷积核重参数化,以此来解决大卷积核不够高效,难以兼顾局部特征等缺点,并提出RepLKNet的CNN架构。
本文借鉴RepLKNet网络的思想,设计并使用RepLKDext大卷积核代替原卷积,利用更大的有效感受野在检测头部分处理大尺度方差,结构图如图5所示。整个结构由多个RepLKBlock模块和CBS模块组成,根据RepLKNet设计准则,在RepLKBlock模块中使用27×27深度可分离(DW)卷积之前使用1×1卷积,之后使用5×5卷积核进行重新参数化。除了提供足够感受野的大型卷积层以及聚合空间信息的能力外,模型的表征能力也与深度密切相关。为了跨通道提供更多非线性和信息通信,使用1×1层来增加模型深度。
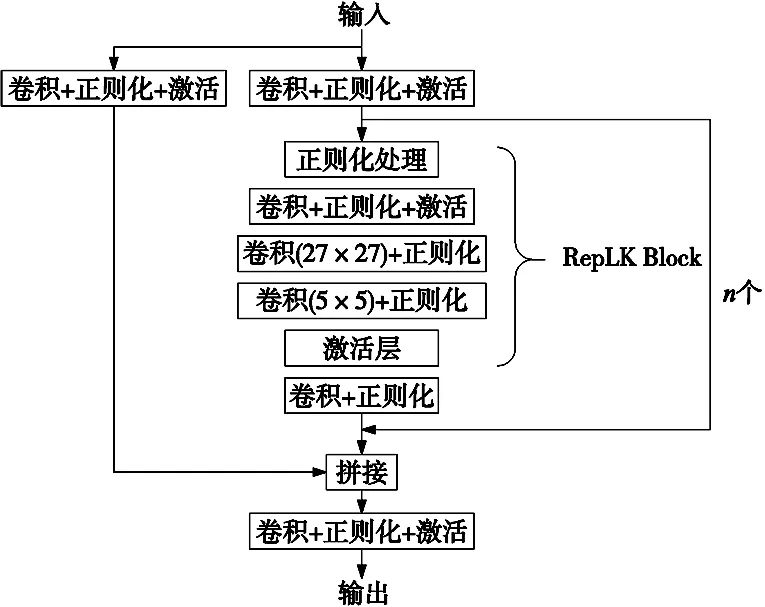
图5 RepLKDext模块
1.4 使用Wise-IoU损失函数
边界框回归(BBR)损失函数作为目标检测损失函数的重要组成部分,在目前的目标检测任务中,通常使用IoU[16]损失函数来作为BBR损失,IoU表示预测框与真实框的重叠程度,能够很好地平衡对大物体和小物体的学习。但当预测框和真实框的交并比相同,预测框所在位置不同,所计算出来的损失一样,无法找出更准确的预测框,现有的BBR损失为考虑了许多与边界框相关的几何因素,提出了式(8)[16],构造了惩罚项Ri来解决这个问题。
(7)
Li=LIoU+Ri
(8)
损失函数应该在锚框与目标框较好地重合时削弱几何度量的惩罚,不过多地干预训练将使模型有更好的泛化能力。以此为基础,根据距离度量构建了距离注意力,如式(9)和式(10)所示[16],得到了具有两层注意力机制的Wise-IoU(W-IoU)[17]:RWIoU∈[1,e),用于放大普通质量锚框的LIoU;LIoU∈[0,1],用于降低高质量锚框的RWIoU并在锚框与目标框重合较好的情况下显著降低其对中心点距离的关注。为了防止RWIoU产生阻碍收敛的梯度,将Wg,Hg从计算图(上标*表示此操作)中分离,因为它有效地消除了阻碍收敛的因素。
LWIoU=RWIoULIoU
(9)
(10)
2 实验及结果分析
2.1 数据集
本文实验所采用钢材表面缺陷数据集(NEU-DET),包含6种带钢表面缺陷类型:氧化轧皮(Rolled-in_Scale,Rs)、点蚀面(Pitted_Surface,Ps)、斑块(Patches,Pa)、夹杂(Inclusion,In)、裂纹(Crazing,Cr)、划痕(Scratches,Sc),各类缺陷如图6所示,每种类型300张共计1800张图片。将数据集按照8:2比例随机划分成1440张的训练集和360张的测试集。

图6 各类钢材表面缺陷
2.2 模型轻量化
YOLOv5s-G模型是通过使用GB-1,GB-2轻量化模块替换YOLOv5s原主干网络中的C3和CBS模块,模型在In和Sc的检测进度有明显提升,如表1所示。但模型检测效率提升不明显。加入轻量化模块后模型大小有了明显的下降,解耦注意力机制也可以捕捉到远距离空间位置的像素之间的依赖性,增强了轻量化模型的表达能力,补足了模型对空间信息的捕获能力。YOLO-G虽然可以在准确性和速度之间实现更好的权衡但对于检测精度上并没有太大提升。
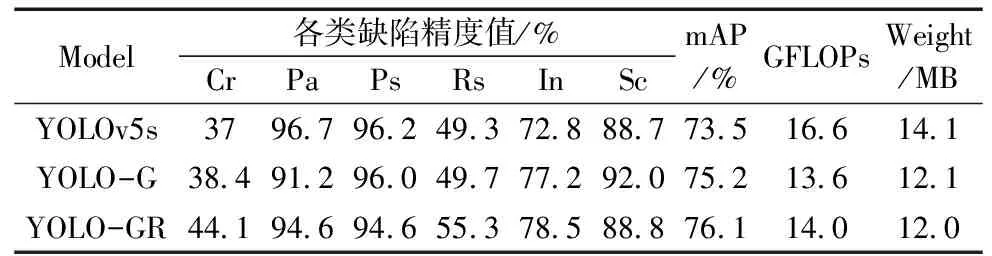
表1 各改进模型性能对比
基于此,YOLO-GR模型进一步在YOLO-G的基础上,在head部分的尺度20×20检测层中使用具有足够的感受野及聚合空间信息能力的RepLKDext大卷积替换原卷积结构进行实验。如表1所示YOLO-GR模型在裂纹(Cr)和氧化轧皮(Rs)这两类分别提升有7.1%、6.0%,其他的类别也均有提升,平均精度提高了2.6%,相对于原YOLOv5s模型运算量仍减少了2.6GFLOPs,权重下降有1.7 MB。YOLO-GR模型相比于原YOLOv5模型在轻量化上有较大的提升,但精度方面表现并不理想。
2.3 更换损失函数
表2是在前两个改进点的基础上加入了不同的IoU损失函数,从而进行对比实验的结果以验证实验改进效果。对比实验分别加入了D-IoU(Distance IoU Loss)[11]、E-IoU(Focal and Efficient IoU Loss)[18]、G-IoU(Generalized IoU Loss)[19]、α-IoU(Alpha IoU Loss)[20]、W-IoU(Wise IoU Loss)[17]进行了5次实验,从实验结果中可以看到,在NEU-DET数据集上,除了G-IoU、α-IoU、W-IoU对精度有一定提升,其他的IoU Loss函数对模型无太大效。其中D-IoU在回归过程中未考虑边界框的纵横比,导致在精度上反而下降了1.6%;G-IoU在检测框和真实框出现包含现象时会退化成IoU,最后精度上也下降有0.6%。而E-IoU引入Focal Loss来解决难易样本不平衡的问题,但比较依赖于数据集的分布和锚框的设计,并不具备较好的泛化能力,所以精度上仅仅提升了0.4%。W-IoU能比较好的处理质量较好与质量较差的样本之间的平衡,对数据集的泛化能力做的比较好,能使模型拥有更好的泛化性能,在此数据集上有效的提升了1.2%的平均精度,明显优于其他IoU函数。图7是原YOLOV5s模型与更换W-IoU损失函数的YOLO-GR模型结果对比图,更换W-IoU损失函数后的YOLO-GR模型在各个类别的检测精度以及平均精度上有着明显提升。
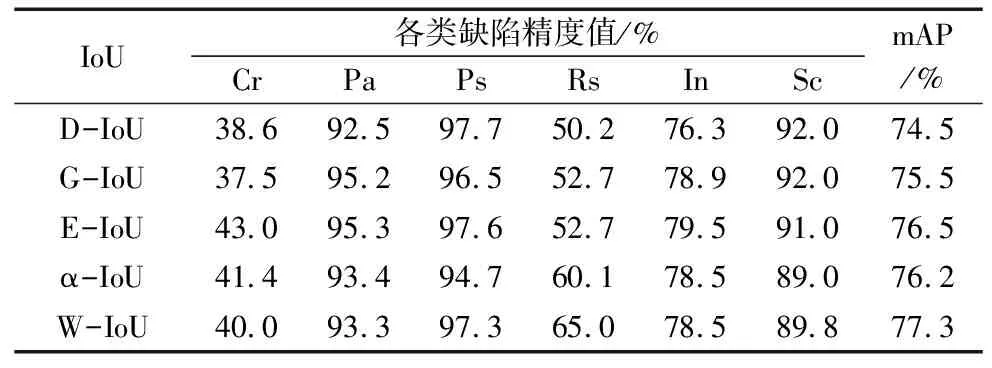
表2 更换不同IoU损失函数实验结果对比
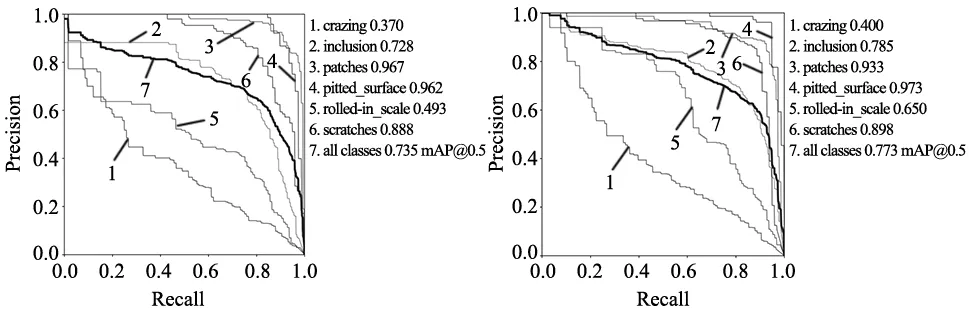
图7 YOLOv5改进前后结果对比图
表3为本文额外选用的4种目标检测模型在NEU-DET数据集上的与改进后的YOLOv5s模型的性能对比结果。根据实验结果可知,主流的一些目标检测模型SSD、YOLOv3、YOLOv4检测效果都有着一定局限性,平均精度都低于70%,模型也较大。文献[5]是基于YOLOv4-tiny所改进的模型,检测精度达到73.3%,检测速度高达85 fps,在检测速度方面较为优秀,但对于精度以及模型大小方面并不理想。

表3 不同算法模型性能对比结果
本文改进的使用W-IoU的YOLOv5s-GR轻量化模型在平均精度上高达77.3%,模型大小只有12 MB,检测速度为78 fps,完全能满足实时检测的需求。对主要缺陷类别的检测结果如图8所示,模型对各类别缺陷的检测都较为平衡,尤其是在对Cr和Rs这些主流的目标检测算法效果都较差的类别检测上效果提升比较明显。但总体上Cr、Rs这两类别依旧只能分别达到40%、65%的精度,本文推测应该是在数据集标注上有部分误差,之后可通过重新进行人工标注进行数据集的调整从而达到更好的检测效果。

图8 检测结果图
3 结论
本文提出了一种基于YOLOv5s改进的轻量化带钢表面缺陷检测模型。该模型采用了YOLOv5s算法作为基础,将主干网络中CBS模块和C3模块使用GhostNetv2 Bottleneck轻量化模块代替,在检测层上使用RepLKDext大卷积代替原卷积,以及更换原有的C-IoU,使用泛化性能更好的W-IoU,使得模型在轻量化的情况下能够有效地检测出带钢表面的缺陷。改进后的模型不仅轻量化,而且检测精度达77.6%,相较于原模型提升了3.8%,模型大小缩小了15%。它可以用于工业生产,自动识别带钢表面的缺陷。未来的工作将探索如何检测其他种类的缺陷,例如焊缝、毛刺等,以及如何进一步简化网络结构,实现移动端的模型部署。
