云边协同下双数据源融合的轴承剩余寿命预测*
2023-11-28刘汝迪唐向红陆见光刘方杰柳鹏飞
刘汝迪,唐向红,陆见光,2,刘方杰,柳鹏飞
(1.贵州大学a.现代制造技术教育部重点实验室;b.公共大数据国家重点实验室,贵阳 550025;2.重庆工业大数据创新中心有限公司,重庆 400707;3.贵州新思维科技有限责任公司,贵阳 550001)
0 引言
轴承作为旋转机械中的重要组成部分,广泛应用在航空航天、轨道交通等诸多领域,若轴承出现退化或者损坏的趋势而未进行实时状况监测和处理,往往会造成更严重的设备损伤[1]。另外,伴随着工业物联网技术的蓬勃发展,由旋转机械产生的数据尤为突出,对轴承状态监测所采取的数据几乎占到了40%。将如此庞大的数据实时上传给云服务器,不仅会使网络面临巨大的流量压力,同时服务器处理海量数据也很难保证轴承状态监测的时效性[2-3]。那么,如何实时对旋转机械中的重要轴承进行健康状态监测和剩余寿命预测成为研究领域亟待解决的问题。
传统的轴承RUL方法主要从失效机理与统计概率角度进行预测,两种方法均存在建模困难、训练数据缺失的缺点,因此在轴承RUL方面存在很大的难度[4]。随着人工智能技术的发展,基于数据驱动的信息新技术方法广泛运用到轴承RUL。该方法通过提取表征轴承退化状态的特征值作为预测的协变量,实现对轴承剩余寿命的精确预测[5]。当前基于数据驱动的轴承RUL方法主要有两种形式:①仅将原始信号作为输入,利用时间卷积网络[6]、深度信念网络[7]等模型挖掘深层特征学习退化模式;②从原始信号中提取表征退化趋势的特征,再输入到深度学习模型中进行预测[8]。
上述方法需要大量数据进行训练与调整,并且难以从原始数据中充分提取退化特征。对于从原始信号提取退化特征,再进行轴承RUL的方法,循环神经网络以其显著的时序信号处理能力应用到RUL中。但处理时序数据时,RNN串行运行方式严重降低了运算速度,并且RNN对长时序依赖关系的捕捉能力较弱,容易产生梯度消失与梯度爆炸[9-10]。而Transformer模型通过其位置编码与多头自注意力机制实现了RNN无法做到的并行计算与长距离特征捕捉,在提高预测准确度的同时减少了运算时间。
综上所述,针对当前轴承剩余使用寿命预测准确率不高且未考虑到预测实时性的问题,本文提出了一种云边协同计算模式下双数据源融合的轴承RUL方法。同时,为提高预测的时效性与准确性,采用了可以并行计算与长时序捕捉能力的Transformer模型进行训练与预测,并运用双误差加权-DS证据理论对预测结果进行融合。实验结果表明,本文所提预测方法具有更高的精度与实时性。
1 基础理论
1.1 云边协同
云计算(cloud computing,CC)是分布式计算、并行计算的发展,其集中式的模型需要将所有数据传输到中心云进行处理,通过云端丰富的资源为终端用户进行服务[11]。
边缘计算(edge computing,EC)是将部分计算任务由云端下沉到边缘端,从而减少数据传输的延迟,缓解云计算中心的压力[12]。
云边协同计算模型框架通常由设备层、边缘计算层以及云计算层3个部分组成。本文提出的云边协同的轴承剩余寿命预测方法的基本框架如图1所示。
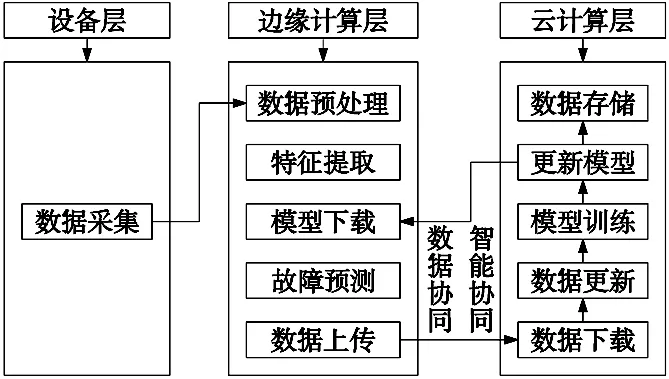
图1 云边协同计算框架图
设备层部署了物联网设备,对数据进行实时采集。边缘计算层作为云边协同架构的核心,利用各个边缘节点对实时数据进行预处理;云计算层对边缘端上传的数据进行模型训练、更新以及实时预测。
1.2 剩余寿命预测模型
Transformer模型主要有位置编码、多头注意力机制等模块组成。
不同于能够直接捕捉时序信息的循环神经网络,Transformer预测模型使用不同频率的正弦与余弦函数进行位置编码,进而捕捉数据之间的时序信息,如式(1)和式(2)所示。
PE(pos,2i)=sin(pos/100002i/dmodel)
(1)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
(2)
式中:pos为时间步,dmodel为输入特征的维度总数,i为输入特征的维度编号。
Transformer的编码器与解码器的主要部分由多头自注意力机制来构成。多头自注意力机制通过多个自注意力模块的线性变换实现,目的在于从输入特征序列中筛选重要信息,根据信息的重要性赋予权重,使模型对重要性高的信息赋予更高的权重[13],多头自注意力模块如图2所示。其主要计算方法如式(3)~式(4)所示。
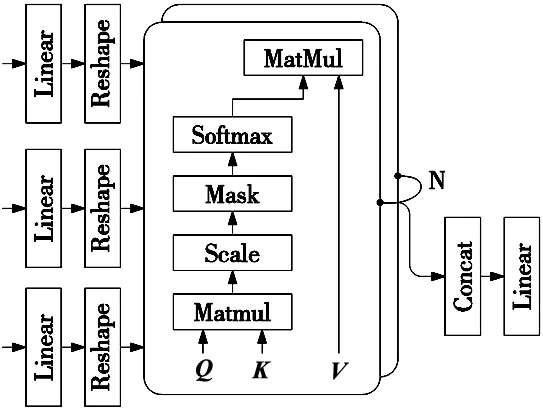
图2 多头自注意力机制模块
(3)
MulHead(Q,K,V)=Concat(headi,…,headn)W0
(4)
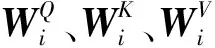
1.3 证据理论
DS(dempster-shafer)证据理论具有依靠证据的积累不断缩小假设集合的能力[14]。在DS证据理论中,证据的推理建立在一个非空有限集合的识别框架X上,识别框架X中的子集Ai两两相互排斥[15]。对于框架内的所有子集mi(Ai)映射到[0,1]内,mi(Ai)需满足以下条件:
(5)
式中:∅表示空集,即不可能发生的命题;mi表示证据的支持程度。
DS证据理论的融合策略是将证据体的概率函数进行正交运算,一般用⊕表示组合运算。对于两个证据体的DS融合策略表示为:
m(A)=m1(Ai)⊕m2(Bj)=
(6)
(7)
式中:k为冲突系数,反映了证据体之间的冲突大小。
2 云边协同框架下的双数据源融合方法
由于旋转机械设备结构的复杂性以及工作条件的多样性,导致采集的滚动轴承原始振动信号中含有大量的噪声信号[16],含有噪声的振动信号会影响退化特征的提取,进而降低剩余寿命预测的准确度。同时在时域与频域退化特征的选择上,合适的退化特征量能更好的表征轴承的退化状态。因此,在剩余寿命预测的过程中,离线阶段的前期工作中的去噪处理与退化特征的选择是相当重要的。
2.1 离线阶段工作
小波变换具有傅里叶变换保护局部特性的优势,同时又克服了短时傅里叶变换的窗口大小不随频率变化的缺点,可以对信号逐步进行多尺度细化,是进行信号良好去噪处理的方法之一。
离线阶段采用小波阈值去噪方法对历史退化数据进行去噪处理:对原始含噪信号进行以多贝西四阶小波为母小波的5层离散小波分解,对细节系数进行阈值处理及小波重构,以达到去除噪声及保留能表现退化特征的信息,方法如图3所示。

图3 小波阈值去噪
从小波阈值去噪后的信号中提取时域与频域的27个特征参数后,需要依据特征随时间的趋势变化进行初步筛选。在轴承的时、频域特征的选择与分析上,良好的退化特征应具有良好的单调性、趋势性和鲁棒性等特点[17]。对初步筛选后的特征进行单调性、趋势性与鲁棒性分析,以选定适合的退化特征参数。
单调性是用来衡量每个输入特征是否具有随退化而单调变化的趋势。趋势性是表示退化特征量与时间及剩余寿命的相关程度,相关性越高,特征更能表征退化趋势。鲁棒性良好的退化特征参数可以降低噪声、退化过程的复杂性等方面的干扰,并表现出平滑的退化趋势。可以由表1看出所筛选的特征参数具有很好的退化表达能力。

表1 退化特征和相应指标

表2 DS证据理论融合方法
离线阶段对历史退化数据进行去噪与时域、频域退化特征进行提取和筛选后,将水平与垂直退化特征训练集数据与标签进行归一化操作后,分别送入云端部署的两个Transformer模型中进行预训练。
2.2 云边协同计算阶段
离线阶段工作对历史退化数据的去噪处理与退化特征参数的选取在一定程度上可以提高寿命预测的准确度。那么为进一步提高对剩余寿命预测的准确度与解决寿命预测的实时性问题,本文提出了一种云边协同下双数据源融合的剩余寿命实时预测方法。如图4所示。

图4 云边协同计算模式下轴承剩余寿命融合预测模型
设备层将水平、垂直振动传感器部署于轴承上,负责实时采集轴承的水平与垂直振动信号,并将振动信号传输到边缘计算层进行预处理。
边缘计算层部署2个小型计算与存储单元,根据离线阶段对历史退化数据的分析,负责对设备层上传的水平与垂直振动信号进行小波阈值去噪处理并提取退化特征,构建并上传退化特征测试集。
云计算层部署了高性能计算系统,不仅可以在离线阶段对轴承的历史退化数据去噪、特征提取过程并行计算,以及完成对网络模型预训练,在云边协同计算阶段还负责:
(1)Transformer预测模型的更新策略:分别将水平与垂直特征进行最大最小值归一化操作后作为预测模型的输入,并将剩余寿命与全寿命的比值作为标签数据,以均方误差作为损失函数,Adam为优化器对模型进行训练。云端对边缘端实时上传的退化特征测试集进行预测,并将退化特征与实际标签归入训练集对模型进行更新。
(2)双数据源融合:本文采用双误差加权-DS证据理论融合方法。该方法分别以水平与垂直预测寿命的均方根误差(root mean square error,RMSE)与平均绝对误差(mean absolute error,MAE)为依据,赋予水平、垂直剩余寿命预测结果的初始权重,如式(8)~式(11)所示:
(8)
(9)
(10)
(11)
式中:RMSEx、MAEx为水平信号剩余寿命预测结果的均方根误差与平均绝对误差,RMSEy、MAEy为垂直信号剩余寿命预测结果的均方根误差与平均绝对误差,αx、αy是以均方根误差为依据确定的水平与垂直寿命预测结果的初始权重,βx、βy是以平均绝对误差为依据确定的水平、垂直寿命预测结果的初始权重。
在确定了水平、垂直预测结果的初始权重的基础上,分别以RMSE与MAE作为证据体,水平与垂直预测初始权重为命题,运用DS证据理论对初始权重进一步融合,从而确定水平与垂直剩余寿命的融合权重,融合方法如下所示:
(12)
(13)
predi=predx·Rulxi+predy·Rulyi
(14)
式中:predx、predy分别为依据DS证据理论融合的水平、垂直剩余寿命预测结果的权重,Rulxi、Rulyi分别为水平与垂直信号剩余寿命的预测结果,predi为依据融合权重对水平与垂直预测寿命的融合结果。
3 实验与结果分析
3.1 PHM2012数据集验证
3.1.1 数据集介绍
为验证本文提出的云边协同计算模型下双数据源的滚动轴承剩余使用寿命预测方法的有效性以及实时性,本文采用全寿命退化数据集[18],该数据集由PRONOSTIA实验平台所采集,采集装置如图5所示。实验设置原始振动信号振幅大于20 g为轴承完全退化的标准,振动传感器由两个相互定位为90°的微型加速度计组成,分别沿径向安置在轴承外圈的垂直轴与水平轴上。采集装置的采样频率设置为25.6 kHz,采样间隔为10 s,每次采样时间为0.1 s,即一次采样采集2560个振动数据。

图5 PHM2012滚动轴承加速寿命试验台
在本次研究过程中,采集装置分别在3种工况下进行了滚动轴承全寿命周期实验,此次研究仅使用了径向力为4000 N,1800 r/min转速下第4组全寿命退化数据集,该数据集共有1428个样本,每个样本均有水平振动信号以及垂直振动信号,并且水平加速度振动信号与垂直加速度振动信号都含有表征退化特征的有效信息,本文同时采用水平与垂直振动信号进行实验。
3.1.2 数据集划分与标签设置
本实验将特征数据集划分为训练集与测试集,根据先验专家知识判断该轴承故障产生点为第1085组处,并以故障产生到完全退化周期数据的60%作为模型的训练集,即以数据的1085组到1287组数据作为训练集对模型进行训练;以剩余40%数据,即141组数据作为云边协同计算模型的测试集进行预测。
以实际剩余寿命作为训练与测试的标签y,标签的设置为0到1,标签1代表轴承完好未使用,标签0代表轴承完全失效。该数据集共1428组数据,轴承的总寿命为1428×10 s=14 280 s,当目前样本为第1300组数据时,则轴承剩余寿命的标签为1-1300/1428 =0.089 6,以此类推,构建滚动轴承剩余寿命的标签。
3.1.3 云边协同预测平台
云边协同计算模型下双数据源融合的轴承剩余寿命预测平台基于Tensorflow深度学习框架进行设计,边缘端使用AMD Ryzen 5 3600 6-Core Processor(主频3.6 GHz)64位操作系统,内存为8 GB;云端采用超算中心的高性能CPU,Inter Xeon Gold 6330 28Core(主频2.0 GHz)56线程,内存为6 TB。
3.1.4 实验过程
实验过程选用Adam优化器对训练过程的loss进行优化,设置学习率为0.000 1,Adam是目前深度学习中较为流行的其中一种优化器,该优化器具有收敛速度快,内存需求小等优点。
本次研究主要测试云边协同计算模式下双数据源误差加权融合下滚动轴承剩余使用寿命的预测精度与实时性的表现,并与目前学者在云计算模式下只采用水平振动信号来进行其他模型预测进行对比。图6为几种预测模型在PHM2012数据集上的表现,图6a和图6b分别为采用循环神经网络中LSTM与GRU预测模型的结果,图6c为本文提出的云边协同计算模式下双数据源融合(CECC-DSF)模型的预测效果,表3为相应模型在PHM2012数据集上的评价指标与结果。
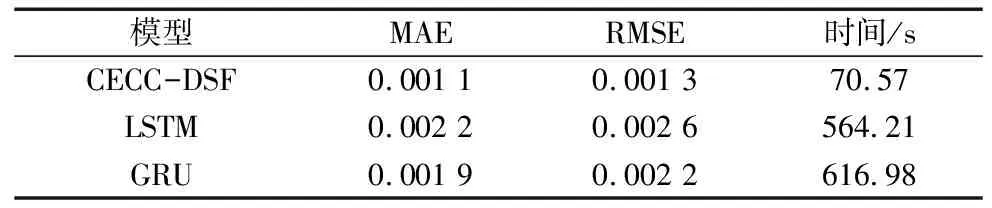
表3 PHM2012数据集上不同模型的效果对比

表4 消融实验结果分析对比

(a) LSTM预测模型 (b) GRU预测模型

(c) CECC-DSF预测方法
3.1.5 消融实验
为进一步验证云边协同计算模式下双数据源误差加权融合对提高模型预测性能的有效性,本文设计了另外3组实验与本文的预测方法对比进行消融实验。实验设计对比的模型有云计算模式下双数据源均值融合预测方法、云边协同计算模式下单一水平信号预测方法、云边协同计算模式下单一垂直信号预测方法。图7a和图7b为在云边协同计算下仅使用单一方向振动信号预测的结果,图7c为仅在云计算下运用均值融合的预测结果,图7d为在云边协同计算模式下双数据源误差加权融合的预测结果。

(a) 单一水平信号预测曲线 (b) 单一垂直信号预测曲线
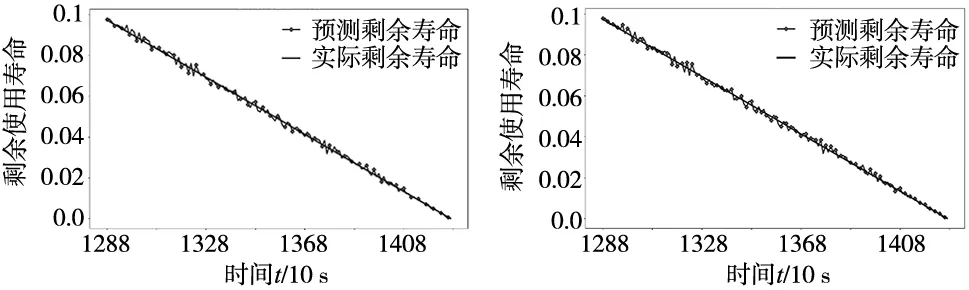
(c) 云计算均值融合曲线 (d) CECC-Transformer-DSF方法
3.1.6 实验结果分析
在PHM2012轴承退化数据集上进行对比实验与消融实验,从预测结果上可以得到以下结论:
(1)本文提出的云边协同计算模式下双数据源融合的滚动轴承剩余寿命预测模型与云计算模式下的其他预测模型相比,由于在离线阶段已将模型训练完成,以及充分发挥云边协同计算的协同能力,其实时性显著提高,预测时间由564.21 s降低到70.57 s。由于采用双数据源融合预测进一步提高了预测准确度,MAE与RMSE两项指标分别降低了42.1%和40.9%。因此,体现了云边协同计算模式实时性高与双数据源融合预测准确性好等优势。
(2)从消融实验结果可以看出,本文提出的CECC-DSF预测模型与云计算模式下的预测模型相比时效性提高了80%左右;双数据源融合预测方法与单一数据源预测结果对比,准确度指标MAE与RMSE分别降低了26.7%与31.6%,进一步证明了本文所提方法在轴承剩余寿命预测领域的有效性。
3.2 XJTU-SY数据集验证
3.2.1 数据集介绍
为了进一步验证本文中提出的云边协同计算模式下双数据源融合的轴承剩余使用寿命实时预测方法的有效性可行性,本次试验在XJTU-SY轴承数据集上进行[19],其实验平台如图8所示。该试验平台通过调节径向力和转速分别在3种工况下进行了加速寿命试验,试验以轴承平稳运行阶段水平或竖直方向振动信号最大幅值的10倍为失效阈值。测试轴承型号为LDK UER204滚动轴承,并将两个PCB 352C33单向加速度传感器分别固定在测试轴承的水平和竖直方向上,使用DT9837信号采集器采集振动信号。试验平台采集装置的采样频率为25.6 kHz,采样间隔为1 min,每次采样时长为1.28 s,即一次采样采集32 768个数据点。

图8 XJTU-SY轴承寿命试验平台
3.2.2 试验过程
为了验证本文提出的云边协同计算模式下双数据源融合预测方法的先进性与有效性,本次将试验与文献[20]的试验结果进行对比。本次试验同样使用径向力为10 000 N,2400 r/min转速下第2组全寿命退化数据集。该数据集共有2496个样本,但每个样本的水平与垂直振动信号都具有表征退化的能力。为验证双数据源融合预测的有效性,实验过程同时采用水平与垂直振动信号进行试验。
本试验依据上述方法进行小波阈值去噪与时频域特征提取,并将特征数据集划分为训练集与测试集。训练集与测试集的划分以及标签的设置与文献[20]相同,即以全寿命数据的前2400组数据作为训练集进行训练,剩余96组数据作为测试集进行预测,标签方法以1代表轴承尚未使用,以0代表轴承完全退化失效。
3.2.3 结果对比与分析
本次设计3种试验与文献[20]中的实验进行对比,3种试验的设计分别为本文提出的CEC-Transformer-DSF模型、基于Transformer模型的单一水平信号剩余寿命预测与基于Transformer模型的单一垂直信号预测。图9分别为3种模型在XJTU-SY数据集上的表现,表5为相应模型的预测结果与对比。
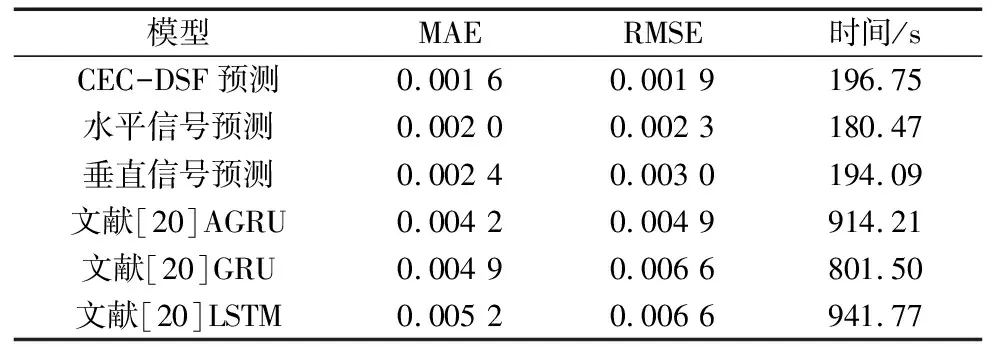
表5 不同预测模型在XJTU-SY数据集上的评估数据

(a) 单一水平信号预测模型 (b) 单一垂直信号预测模型
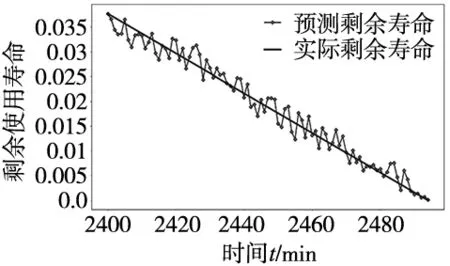
(c) CECC-Transformer-DSF预测模型
3.2.4 实验结果
从实验结果中可以看出,本文所提出的CECC-Transformer-DSF预测模型与文献[20]中的AGRU预测模型相比,其平均绝对误差与均方根误差分别降低了38.1%与38.8%;将文献[20]所提模型在本文云计算平台下进行试验,结果表明本文所提方法的时效性提升80%左右,进一步验证了本文所提模型的可行性与泛用性。
4 结论
本文针对当前滚动轴承剩余使用寿命预测实时性差与准确度不高的问题进行分析,提出一种云边协同计算模式下双数据源融合的滚动轴承剩余寿命预测的方法,通过试验与验证得出以下结论:
(1)在PHM2012数据集上进行试验得出,云边协同计算模式下双数据源融合的轴承剩余寿命预测方法在预测准确性上更高,预测效果更好。
(2)与目前云计算预测模型相比,实时性得到显著提高,证明了该方法的先进性与可行性。
(3)本文在XJTU-SY数据集上进行了进一步的验证,实验结果表明了本文所提方法的有效性与泛用性。
(4)本文提出的云边协同计算模式下双数据源融合的轴承剩余寿命预测方法为目前轴承剩余寿命实时预测提供了一种新的解决方案,具有重要的现实意义。
