基于改进YOLOv5算法的钢管焊缝缺陷检测*
2023-11-28蔡绪明王文武
蔡绪明,王文武
(1.中石化石油机械股份有限公司沙市钢管分公司,荆州 434001;2.武汉科技大学信息科学与工程学院,武汉 430081)
0 引言
钢管广泛应用于石油、化工、天然气、页岩气传输等高危高压的场景,如果钢管焊接处存在某种缺陷,则可能导致严重事故,因此钢管焊缝缺陷检测在实际作业中具有重要意义。随着中国市场对钢管的需求量的不断增长,越来越多的企业、甚至国家都开始重视钢管焊接的质量,钢管焊缝缺陷检测和评价技术也成为科研工作者热衷的研究课题。当前X光无损探伤(non-destructive testing,NDT)是工业无损检测的主要方法之一,其检测结果已作为焊缝缺陷分析和质量评定的重要判定依据。NDT检测能有效地检测出钢管焊接过程中可能存在的缺陷,但还是离不开人工的参与来确定钢管焊缝缺陷的类型和位置[1]。因此,研究钢管焊缝缺陷智能检测和识别方法能有效提高检测效率和推动工业自动化的发展。
钢管焊缝的缺陷通常独立于焊缝背景,适合采用计算机视觉领域中的目标检测技术以实现缺陷的自动化检测和识别。在之前的工作中大多使用传统的计算机视觉的方法做钢管焊缝缺陷检测[1]。WANG等[2]使用多阈值支撑向量机(support vector machine,SVM)的方法对钢管焊缝裂纹的X光图像检测的准确率达到了96.15%;MALARVEL[5]用固定阈值分割结合多类支撑向量机(multi-class support vector machine,MSVM)的方法对X射线图像的焊缝缺陷实现了多分类检测,并且准确率达到了95.23%。如今随着基于深度学习的目标检测算法不断发展[5],识别准确率和检测时间相比于传统的计算机视觉方法有了很大的提升。已有研究将基于深度网络的模型应用于钢管焊缝缺陷的检测,且取得了不错的效果,但仍然存在一些不足,比如:①准确率有待进一步提升;②缺陷类型单一,难以应用至工业领域;③检测时间过长,不能做到实时检测。本论文针对以上问题,先对输入X光图像去模糊处理,其次尝试将动态区域感知卷积,高效的特征融合机制和可学习权重参数检测头技术引入到业界领先的YOLOv5算法中,并应用于钢管焊缝缺陷检测任务,并取得了一定的成果。
1 YOLOv5算法原理
YOLOv5是在YOLO系列算法[6-10]基础上改进后提出的,根据模型参数规模分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个版本,依次参数量越大,精度越高,单张图片的检测越慢。YOLOv5的网络结构由输入端、Backbone特征提取网络、Neck中间层和Prediction输出层4个部分。
YOLOv5输入端使用Mosaic数据增强,自适应锚框计算与自适应图片缩放方法提升模型的训练速度和网络的精度。Mosaic数据增强对4张图片进行随机裁剪,随机排列和随机缩放的方式拼接得到一张新图,同时将标注的目标框映射到新图送入网络进行训练。该方法一次读入4张图片,丰富了检测物体的背景,减小了对batch size的依赖。在早期YOLO系列算法针对不同的目标和数据集,通过单独的程序回归出特定长宽的初始锚点框,YOLOv5训练程序根据数据集自适应的计算出最佳的锚点框。在目标检测算法中将原始图片统一缩放到一个标准尺寸,再送入检测网络中。很多图片长宽比不同,缩放填充之后,两端的黑边大小不相同,如果填充过多,会存在大量的信息冗余。YOLOv5中采用一种自适应的添加最少的黑边到缩放之后的图片中,进一步提高了推理速度。
YOLOv5的Backbone 网络主要由Focus、CBS、BottleneckCSP和SPP等模块组成。Focus对图片进行切片操作,实现下采样功能,减少计算量,加快计算速度。CBS的功主要功能为卷积,获取特征。CSPNet[11]的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的,CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。图像进入BottleneckCSP[12]结构后分为两条支路,第一条将输入图像进行Bottleneck操作,降低输入图像的维度,另一条将输入图像按照网络结构不断进行Bottleneck,保证输入和输出的图像大小保持不变,最终得到所有层的输出,将所有输出拼接再进行1×1的卷积减少输出通道数得到最终的输出。
YOLOv5的Neck和YOLOv4中一样,都采用FPN+PAN的结构。FPN使用自顶向下的侧边连接,在所有尺度上构建出基于特征金字塔的高级语义特征图;FPN中间经过多层的网络后,底层的目标信息非常模糊,因此PAN加入了自底向上的路线,弥补并加强了目标的定位信息。YOLOv5的输出端包括损失函数(分类损失、目标置信度损失和定位损失)、边界框计算和目标高宽比匹配3部分。
2 改进的YOLOv5算法
2.1 输入图像预处理模块
输入图像预处理模块包括去运动模糊和数据增强3部分。
2.1.1 去除运动模糊
当圆柱型的钢管在流水线上旋转时,用于拍摄钢管焊缝缺陷X光摄像机和钢管在焊缝的方向上会有相对运动,所以当摄像机拍摄焊缝缺陷时会产生运动模糊。根据KUPYN等[13]的研究,运动模糊会对YOLO系列的目标检测算法产生精度上的影响,所以有必要将有些图片中的运动模糊去除。运动模糊去除的过程如图1所示。首先,本文用霍夫变换将缺陷边缘的直线检测出来,由直线的角度可以估计钢管运动的方向(也就是图片模糊的角度);然后,本文使用估计的模糊核对原始的模糊图像进行反卷积操作得到图1c的结果。

(a) 原始模糊图像 (b) Hough直线检测结果 (c) 去模糊结果
2.1.2 数据增强
卷积神经网络往往需要大量的训练样本才能有效提取图像特征并分类,为了有效提升数据质量、增加数据特征多样性。本文使用明暗变化,随机旋转,随机减去,添加高斯噪声,水平翻转,饱和度、对比度、锐度随机调整,长宽比变化及随机裁剪将原始数据增强到原来的3倍。从而有效地减少了训练阶段的过拟合,提升网络的泛化能力。
2.2 主干网络中引入动态区域感知卷积
传统的卷积操作在空间域进行权值共享,在全局区域通过增加卷积的数量来获取更丰富的信息,这样既增大了计算量,又带来网络优化困难。局部卷积在不同的像素位置使用不同的权值,高效地提取丰富的信息,但是破坏了平移不变性,带来与特征图大小相关的大量参数。动态区域感知卷积[14]先使用可学习的引导掩模将特征图中的像素划分为不同的区域,然后使用卷积核生成模块针对不同的区域动态生成对应的卷积核。如图2所示,引导掩模中不同颜色区域为不同区域,G(X)为生成的卷积核。相较于标准卷积,动态区域感知卷积在保持计算量的基础上,增加了卷积的表征能力;同时相对于局部卷积,减少参数量的同时,仍然保持局部卷积的表征能力。

图2 m个卷积核大小为k×k的动态区域感知卷积示意图
2.2.1 可学习的引导掩模
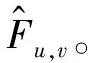

图3 可学习引导掩模示意图
(1)

在获得可学习的引导掩模过程中进行式的argmax(·)操作,该操作不可导,导致梯度不能进行反向传播。Mu,v具有[0,0,1,0,0]的one-hot形式,利用式近似引导掩模中的argmax(·)操作,实现梯度传播。
(2)
2.2.2 卷积核动态生成模块
动态区域感知卷积[14]另外一个重要结构为卷积核动态生成模块,可学习的引导掩模先将特征图中的像素划分为不同的区域,然后使用卷积核生成模块针对不同的区域动态生成对应的卷积核。卷积核动态生成模块如图4所示,先对维度为U*V*C的输入特征图X进行自适应平均池化,得到K*K*C的特征图,然后通过1×1的卷积,sigmoid激活得到K*K*m2的特征图,再将特征图均分成m组,每组进行1×1的卷积,最后得到对应的m个区域的卷积核。
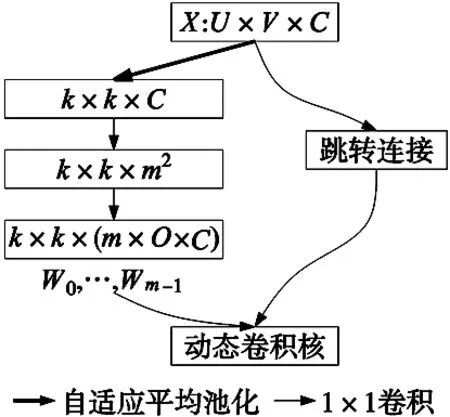
图4 卷积核动态生成模块示意图
2.3 改进检测头
在检测头引入自适应空间特征融合(adaptively spatial feature fusion,ASFF)[15],在FPN将各层特征相加的基础上,引入可学习权重参数,实现检测头中的特征自适应融合。以融合后特征ASFF-3为例:N1、N2和N3分别来自对应尺度RFF输出的特征,与来自不同层的特征乘上权重参数α、β和γ后相加求和,得到新的融合特征。权重参数α、β和γ通过对相应N1、N2和N3应用1×1卷积获得,并通过网络反向传播进行学习。ASFF能够在空间上过滤冲突信息以抑制梯度反传时不一致,实现融合特征的比例自适应变化,同时降低推理开销。
2.4 基于高效特征金字塔(EFA-FPN)的特征融合模块设计
一般来说,特征融合技术是当前目标检测网络中必备的模块,用于融合主干模块输出的多尺度特征。简单来说,其作用是将低层级特征中的细节信息补充到高层级特征中,同时将高层级特征中的语义信息注入低层级特征中。然而,现有的特征融合模型存在融合准则过于简单的问题,难以从原理上分析不同层级中哪些有用的信息在融合过程中进行了交互。本文引入高效特征金字塔(efficient feature aggregation-FPN,EFA-FPN),提出了一个基于加权注意机制的全局特征聚合模块。在每个尺度上,首先通过整合上下文特征和那些跨尺度的抽象特征获得一个自适应的权重图。该权重生成过程以一种原理上可解释的方式很好地聚合了精细和粗略的特征。图5为提出的高效特征融合模型框图。
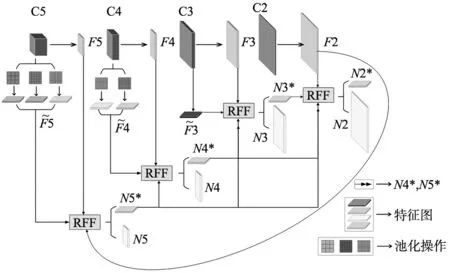
图5 特征融合模块示意图
图5中,Ci为主干网络第i个尺度输出的特征。Fi为通过一个1×1的卷积层将Ci的通道数进行缩减的结果。由于从主干网中提取的特征本身具有不同的属性,包括尺度和语义层次,因此基于FPN的方法通常致力于设计合理的聚合标准来以最佳方式处理这些属性,提高输入特征的表示能力。同样,在第阶段,本文提出的丰富特征聚合模块(rich feature fusion,RFF)利用具有不同属性的特征图来生成富含上下文的特征Ni,即Fi的优化特征图。同时,本研究还从RFF中提取一个辅助特征图Ni*,为第i阶段的特征聚合提供丰富的特征信息。需要注意的是,本文精心设计了不同尺度之间的特征交互准则,以充分考虑从不同层提取的特征的特点。即RFF的输入在每个阶段都有不同的特征融合路径。
为了捕捉来自多个阶段的全局信息,RFF的职责是双重的:①通过融合不同属性的特征来优化当前阶段的特征;②同时为下一阶段的另一个全局特征聚合模块提供辅助信息。为了有效地利用具有不同属性的特征,本文使用分组卷积来生成每个特征图的特征权重表示,RFF用它来使金字塔的特征连接得更紧密。在不同尺度的特征图之间,RFF上的输入是不同的。以附属于F5的RFF为例,其实现细节如图6所示。

图6 以附属于F5的RFF为例,其输入特征结构图
(3)
式中:Fi是用来优化Fi的权重,fC是通道串联操作,[·]g1×1,g3×3是分组卷积操作。最后,空间权重要经过非局部运算,用来学习不同尺度的特征图之间的像素的位置关系。本文采用的非局部(non local,NL)操作如图7所示。
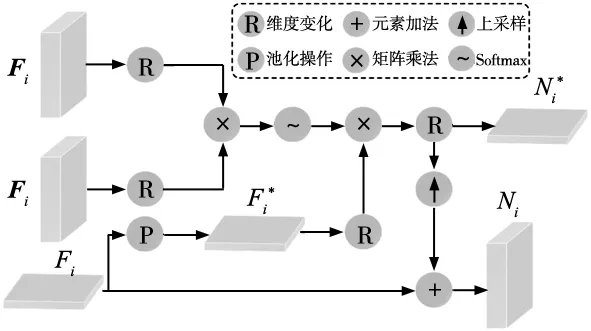
图7 非局部操作流程图
由于NL操作协调了整个空间中特征之间的相关信息,本文把它作为一个全局表示Ni*来解决两个任务。一方面,它为其他阶段的特征聚合提供辅助信息。另一方面,Ni*在第i阶段被进一步用来增强原始的降维输出,从而得到优化的特征Ni,它将取代Fi用于检测。
与F5生成的过程类似,式(4)分别描述了RFF在处理其他尺度特征时的融合路径。
(4)
3 实验
3.1 试验环境和参数设置
本文改进的YOLOV5模型训练硬件配置为:Intel Xeon Silver 4210R、运行内存64 GB、显卡型号为NVIDIA GeForce RTX 3090、显存24 GB。软件环境为:操作系统Linux-5.4.0、深度学习框架Pytorch 1.80、CUDA11.1。YOLOV5网络模型训练时,特征提取网络初始权重采用ImageNet上预训练好的模型参数,参数优化算法为自适应矩估计。具体的参数设置为:批处理数设为4,衰减系数为0.000 5,总训练次数为2000个世代,学习率采用warmup优化方法:在0~50个世代期间,学习率为0.001;在51~1200个世代期间,学习率为0.01;在1201~2000个世代期间,学习率为0.002。
3.2 试验数据集
本文试验样本从某钢管厂车间,收集了5000张包含各类缺陷的钢管焊缝静态DR图像,图像大小为1024×1024,DR平板为某公司PaxScan1313DX。焊缝缺陷包括裂纹、未焊透、未熔合、咬边、气孔等。用LabelImg软件对图像进行手工标注;然后对图像进行适当增广,随机对图像进行对比度、亮度变换、变换,水平,垂直反转,最终图像扩充至15 000张。将上述数据集随机分为3组,训练集10 500张,验证集1500,测试集3000张。
3.3 结果与分析
3.3.1 定性结果与分析
对改进前后的YOLOV5网络模型(都选用YOLOv5s网络)分别进行训练和测试,主要评价使用模板检测模型中常用的每秒处理帧数(frame per second,FPS)、 平均缺陷的(average precision,AP)和平均精度均值(mean average precision,mAP)。FPS数值越大,代表检测的速度越快,AP值为P-R曲线包围的面积,mAP为所有类别AP值的均值,mAP值越高意味着目标检测的准确度越高。改进YOLOv5算法对各类缺陷检测结果如图8所示。

(a) 气孔 (b) 咬边

(c) 裂纹 (d) 未熔合
3.3.2 定量结果与分析
在3000张测试集上,将原始YOLOv5与改进YOLOv5算法进行对比测试,检测结果如表1所示。
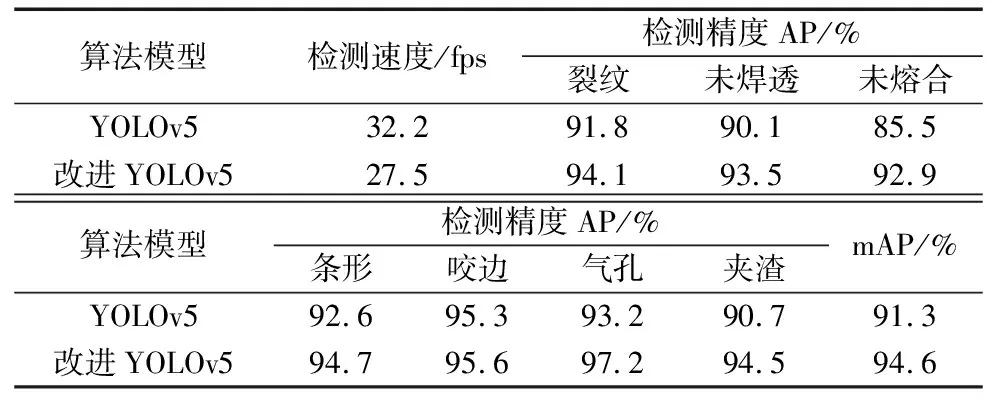
表1 改进YOLOv5与原始YOLOv5对比结果
由表1可以看出,改进YOLOv5算法由于增加了部分模块,检测速度虽然从32.2 fps下降到27.5 fps,但是检测速度仍然达到实时检测水平。原始YOLOv5算法表现相对较差的未焊透、未熔合和夹渣缺陷,共同特点是缺陷部位不太显著,在改进YOLOv5算法中增加了去模糊图像增强算法后,检测精度取得了相对较大的提高。通过引入动态区域感知卷积和改进检测头模块,算法模型提取各类缺陷的特征能力进一步增强,检测进度有2~3个百分点的提高。最终改进YOLOv5算法的mAP达到94.6%,基本满足实用需求。
3.3.3 消融实验分析
同上小节实验配置相同,这里针对本文中对YOLOv5进行的改进进行了消融实验,具体实验结果如表2所示。

表2 改进YOLOv5中各项模块对于最终性能的贡献
其中,DRConv表示主干网络中引入动态区域感知卷积;EFA-FPN表示采用本文中引入的高效特征金字塔替代原始YOLOv5中基于CSP的FPN模块;ASFF为引入的自适应空间特征融检测头。
表2的结果显示了本文采用的改进方法均能够一致提高原有YOLOv5的检测性能。同时也注意到,采用的高效特征金字塔在3个改进中对检测性能的提升最大。
4 结束语
本文以工业生产场景下的钢管焊缝缺陷实时检测为研究对象,提出一种改进的YOLOv5钢管焊缝缺陷检测算法,实现了焊缝缺陷自动检测。本文结合数字DR图像的特点,对原始YOLOv5算法进行了输入图像增强,引入动态区域感知卷积和改进检测头模块3方面的改进。在训练阶段,采用Mosaic数据增强方法,增加了训练数据集的规模,有效得减少了训练的过拟合。从实验结果看,图像中对比度不太显著的缺陷类别,经过图像增强算法后,检测精度的提高较明显,AP值从85.5%增大到91.3%。引入动态区域感知卷积、高效特征金字塔和改进检测头模块,进一步提高了检测网络提取缺陷特征的能力,各类缺陷的mAP值从91.3%提高到94.6%,基本达到实用的要求。在测试过程中发现当前算法对两类缺陷表现相对较差:特别小的目标和由系列小目标随机组合构成而成的缺陷,比如疏松缺陷由大量小气孔随机组合而成,提高这两类缺陷的检测率是下一步研究的重点。
