安徽省历史文化名镇名村知识图谱的构建
2023-11-25汪俊逸史东辉胡涛
汪俊逸,史东辉,胡涛
(安徽建筑大学电子与信息工程学院,安徽合肥 230601)
0 引言
历史文化名镇名村是我国文化传承中不可或缺的一部分,它真实地记录了传统的建筑风貌以及民俗民风,这些古村镇承载了我国不同时期的文化与风俗习惯。社会经济飞速发展带来的城市化进程,加速导致了我国古村落的数量锐减。
目前,国内外对于古村落的研究多聚集在空间形态以及对地理学的研究。张泉,邹成东[1]等人借助网格维数推算对我国名镇名村的空间格局进行了特征分析,并基于这些空间特征提出了优化策略以助力名镇名村的保护措施。高旭宏[2]以及Xie[3]等人通过GIS技术对历史文化名镇名村进行空间特征分析,以此获取地势对村镇的作用。陆林、葛敬炳[4]对徽州地区文化古城镇的地理环境进行分析最终得出地形的特征能够有效延续古村落的文化传承。Chen,Wei[5]采用景观多功能研究方法对村庄改造相关因素进行了探究,结果表明生态、生活之间存在长期和同步相互作用。Gao,Wu[6]在研究传统村落保护问题中提到旅游业的发展是乡村振兴的关键点,而旅游也可以极大地解决名镇名村风俗文化的传承问题。本文在结合前人对古村镇研究的基础上,考虑如何将数字化技术融入名镇名村的保护工作,并将计算机技术与名镇名村相结合,由此促进文化名镇名村的旅游业发展以助力历史文化名镇名村的文化传承及保护事业。
近年来,知识图谱技术越来越频繁地被应用于各个领域,其中陈海玉[7]、刘爽[8]、Pandolfo[9]等人以及周亦[10]等人将知识图谱应用于历史文献领域。张云中[11]将知识图谱技术应用于历史人物游学足迹上,由此实现游学足迹可视化。Zhou[12]等人将知识图谱技术应用于药学领域,以助力药物管理。考虑到名镇名村相关资料的离散程度较高,且知识图谱技术在名镇名村领域的研究尚有欠缺。本文提出将知识图谱应用于名镇名村领域,以此解决名镇名村资料的关联程度低以及查询效率低等问题。
1 数据预处理
1.1 数据来源及获取
历史文化名镇名村完整地反映着历史时期传统风貌和地方民族特色。本文获取的数据以中国传统文化博物馆、安徽省历史文化名镇名村百科对名镇名村的介绍为主。经过对近20年的中国历史文化名镇名村名单的筛选,最终确定安徽省存在历史文化名镇名村数量为35 个。其中共有历史文化名镇11 个、历史文化名村24个,如表1所示。
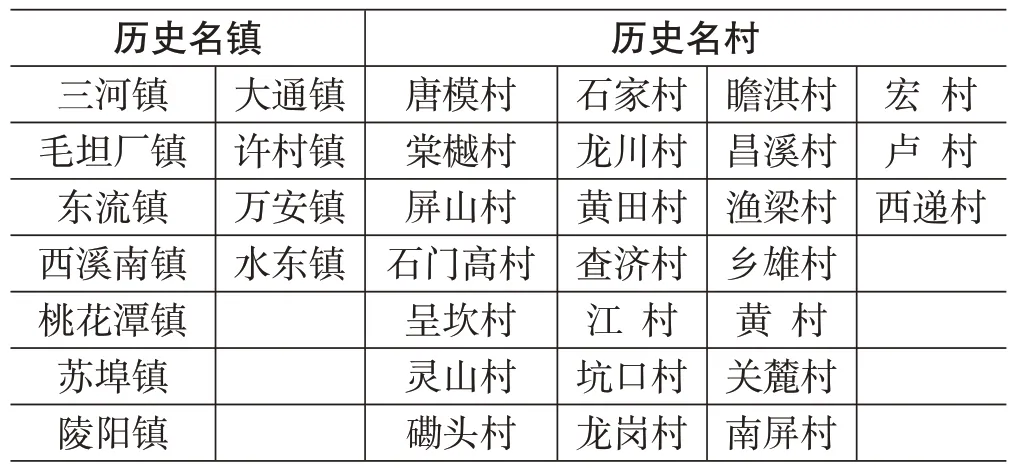
表1 安徽省历史名镇名村名称表
本文所使用的原始数据集是通过爬虫技术,从百度百科及历史文化馆等名镇名村科普网页爬取的非结构化文本。在数据采集的过程中,通过使用urllib包中的request 库函数对网页中HTML 格式的文本进行爬取;爬取数据完成后,使用lxml 包中的etree.HTML对获取的HTML数据进行解析,并使用xpath函数通过标签id 属性值匹配到原始数据集所需要的文本所在的标签,从而获取本文数据集所需数据。
为贴合本研究构建历史名镇名村的知识图谱用于助力古村落数字化发展以及促进其旅游业发展的初衷,本文构建知识图谱所使用的信息主要涉及历史文化名镇名村的地址、气候、景点、古建筑、特色美食以及特色产品等方面。
1.2 数据标注
本文标注所使用的文本数据集是通过爬虫等技术自动获取,并经过人工筛选得到的非结构化文本。为了保证训练数据的标签与实体映射之间的准确性,本文采用人工标注和运用jieba 库的分词技术对文本进行分词并结合词典匹配的自动化标注技术对非结构化文本数据集进行高效率、高精度的命名实体BIO标注工作,其中,实体的头部标注为B-XXX,实体剩余部分标注为I-XXX,非实体部分标注为O。
本文通过BIO标注了41万文字的非结构文本,其中存在实体类型17 个,关系类型14 个。该数据集共包含6 620句非结构化文本,17个类别共计5 631个标签实体,由图1中的标签统计分析得知,本文所使用的数据集标签分布较为均匀,不会由于某一样本数量过小而导致该标签的分类效果无法提升到最佳效果。其中训练集:验证集:测试集等于7:2:1。
2 安徽省历史文化名镇名村知识图谱的构建
2.1 Schema层的构建
本文基于Protégé 软件构建知识图谱的概念层(Schema层),具体的概念层如图2所示。Schema层的构建大致可以划分为以下4 个部分:1)类别的定义。2)类别的层次。3)对象属性。4)关系属性。
为了合理地构建适用于旅游推荐及历史文化传承的历史文化名镇名村知识图谱,基于安徽省历史文化名镇名村的相关知识进行分析,以名镇名村为核心实体,扩充与名镇名村的旅游业相关联的实体。根据对安徽省文化博物馆相关村镇介绍的分析,本研究的知识图谱定义了17个实体类,以及13个关系类别,具体如图3所示。
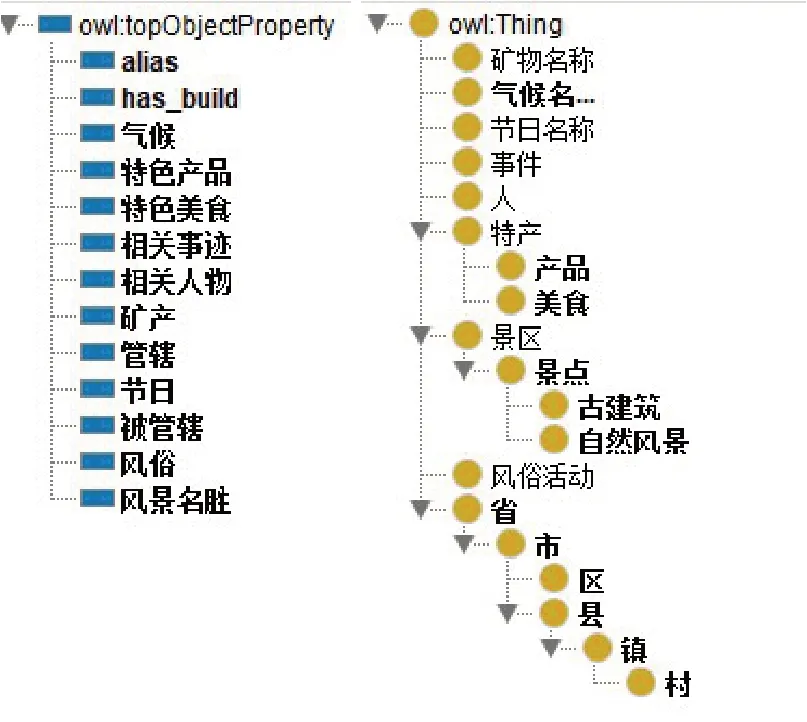
图3 Schema层实体类型和关系类型图
2.2 实体抽取
知识抽取技术可以应用于多种数据源,如表格类型的数据、纯文本的数据以及数据库中的数据都可作为知识抽取的源数据。本文中涉及的知识抽取技术在非结构化文本的基础上进行,通过命名实体识别技术以及基于词典匹配的关系抽取技术获取构建所需的节点、关系信息,具体内容有:名镇名村的地址、涉及的景点信息、相关人物以及相关事迹等。
为了从非结构化文本中快速找到构建安徽省历史文化名镇名村知识图谱的实体数据,本文将命名实体识别技术应用于实体的抽取任务中。将BIO 标注数据集输入基于对抗训练的Bert-BiLSTM-CRF 模型中进行训练,得到可以进行实体识别的模型。
2.2.1 Bert-BiLSTM-CRF命名实体识别模型框架
本文所使用的基础网络模型架构是基于BERT模型实现文本到词向量的转化,输入下层的BiLSTM 模型进行特征提取,并采用CRF模型作为序列标签的分类层。通过在Bert编码层加入对抗训练,向模型中输入一定的噪声样本,在一定程度上提升了模型的鲁棒性,其模型结构见图4。
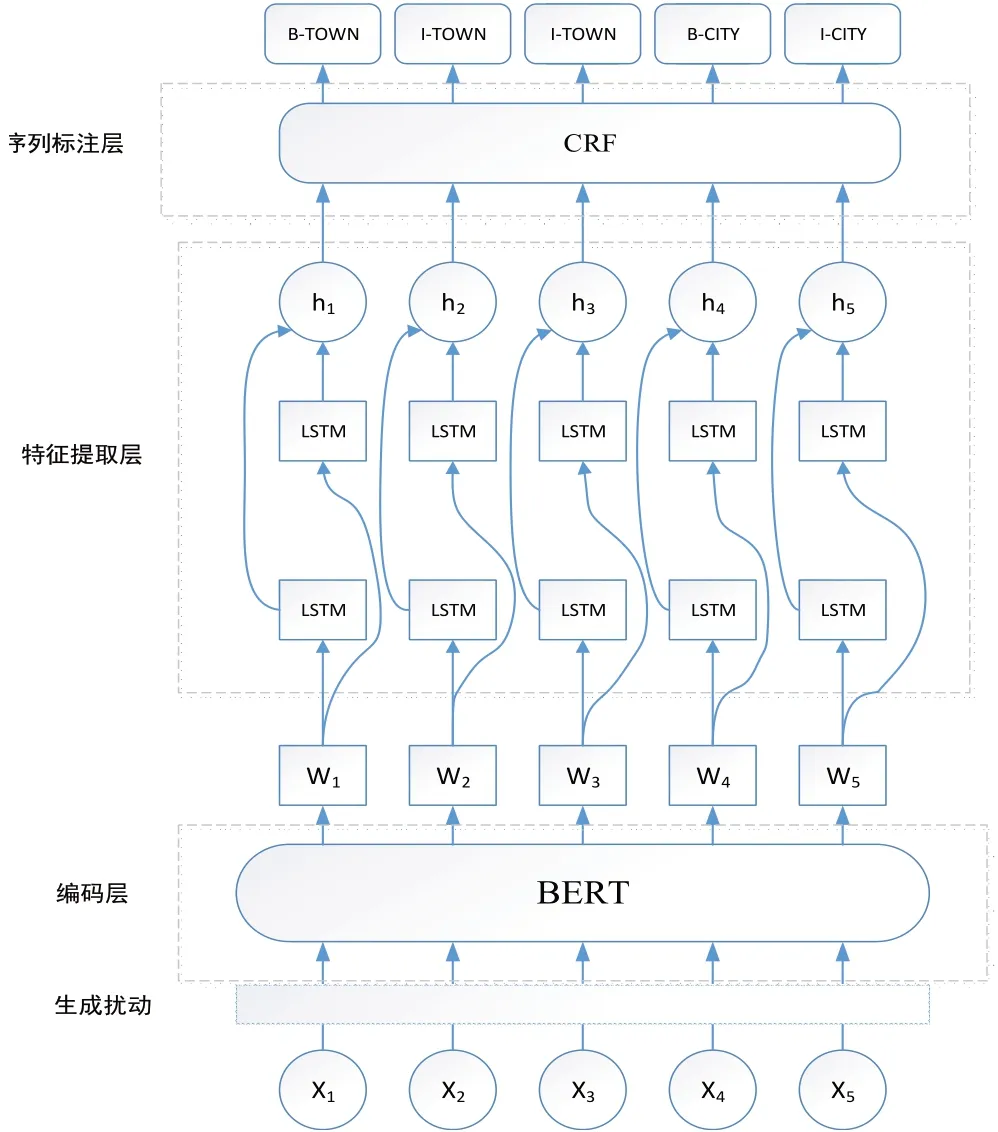
图4 BERT-BiLSTM-CRF+对抗训练的模型架构
1) Bert-编码层
Bert 模块是基于Transformer 模型的编码器部分进行加工得到的[13-14]。Transformer 模型是基于自注意力机制结合残差结构的一种语义神经网络[14]。通过Bert 层的自注意力机制对词向量的加权融合处理,使得原本的词向量得到了更加丰富的上下文语义信息,在一定程度上提升了模型的识别效果。
2)BiLSTM-特征提取层
将通过Bert 层获得的拥有丰富语义的词向量输入BiLSTM 层中进行特征提取,对于不重要的语义特征进行遗忘,对重要的信息进行保留。前向的LSTM层不断地提取拥有前文信息的语义特征,反向的LSTM 层从后往前提取后文的语义特征,将前文和后文的语义特征向量进行拼接,得到拥有上下文语义的特征信息,并输出每个字标签的得分值向量[15]。
3) CRF-分类层
CRF 线性层会根据上层模型的输出数据构建一个状态转移矩阵M,矩阵中的元素Mi,j表示由词性i到词性j的得分,Pi,j表示在j标签下是单词i的得分。对于句子s,标签序列为y=(y0,y1,...,yn),模型预测标签为y的得分可以通过公式(1)得到。
最终结果如公式(2)所示:
其中score()表示是正确的标签序列的分值,分母中的s 表示每种可能标签序列的分值。在CRF 中,当前状态不只与当前局部状态有关,而是考虑到了整个序列的状态,故CRF能在命名实体识别任务中发挥高效的作用[16]。
在实体识别步骤中,需要从文本中识别出可能的实体位置,这一步可以用公式(3)表示:
其中,hi表示第i个位置的上下文向量,Wentity和bentity表示实体分类器的参数,Pentityi表示第i个位置的实体类别概率分布。在实体分类步骤中,需要对识别出的实体进行分类,将其归为不同的实体类别,这一步可以用公式(4)表示:
其中,hentityi表示第i个位置的实体嵌入向量,Wclass和bclass表示实体分类器的参数,Pclassi表示第i个位置的实体类别概率分布。
在实体分类的过程中,通常会将不同的实体类别表示为独热编码,然后将实体嵌入向量与实体类别矩阵相乘,得到实体分类概率分布。
4)实验参数设置
本研究中所使用的具体的参数设置如表2所示。
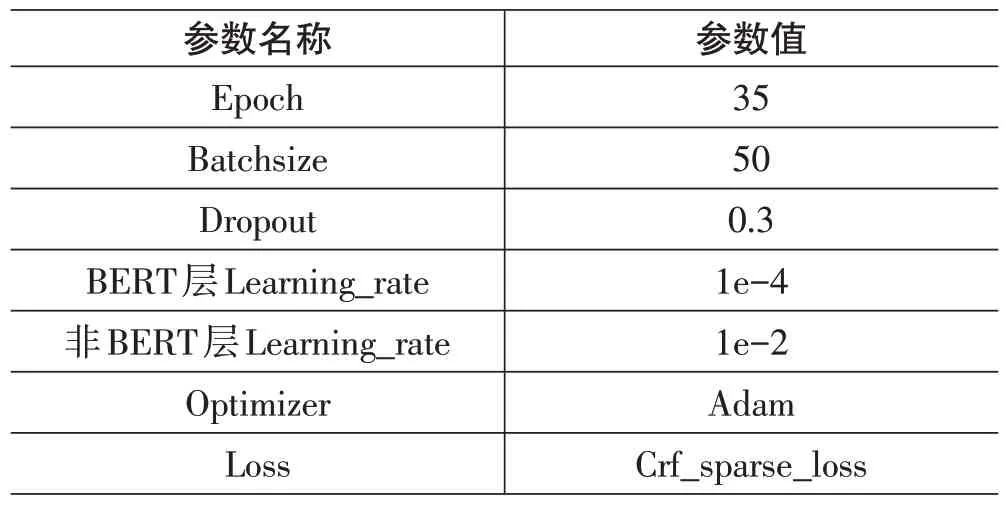
表2 模型参数设置
2.2.2 实验结果与分析
本节将本文所使用的模型与近几年的常用序列标注模型进行对比。在相同的实验条件下,将基于对抗训练的Bert-BiLSTM-CRF 与CRF 模型、LSTMCNNs-CRF 模型以及Bert-BiRNN-CRF 模型进行对比,实验结果如表3所示。
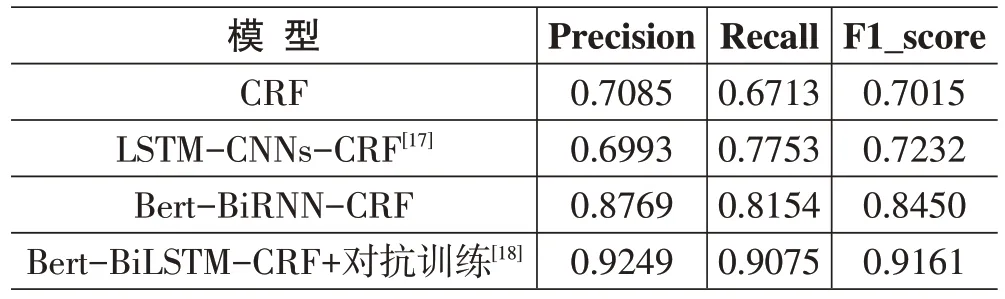
表3 不同模型的对比实验结果
本文模型相比于CRF、LSTM-CNNs-CRF、Bert-BiRNN-CRF 三个模型的F1 值分别提升了21.46%、19.29%以及7.1%。CRF 虽然具有一定的可解释性和较好的泛化性能,但是其准确率在序列标注任务中可能会受到序列长度的影响;LSTM-CNNs-CRF 模型将多种深度学习技术相结合,通过LSTM 来捕捉序列中的长期依赖关系,通过使用CNN网络来捕捉序列中的局部信息,最后使用CRF 层进行标签预测,性能上比CRF略好,但计算复杂度比较高;Bert-BiRNN-CRF模型相较于上述两个模型具有较好的性能,通过Bert层对词向量进行转化,并进一步通过BiRNN提取上下文语义特征,最后通过CRF 层进行序列的预测,能够很好地处理序列标注任务,但还未达到理想效果;与上述三个模型相比较,本研究通过使用BiLSTM 模型来替代BiRNN 模型,解决了BiRNN 在处理长文本时的长期遗忘造成的梯度消失的问题。通过结合上下文语义的特征提取方式,有效地提升了标签的分类能力。在训练过程中,通过加入对抗扰动样本,让网络在输入的扰动中学习到更为鲁棒的特征表示,提升了模型的鲁棒性和泛化能力。
通过上述实验,将安徽省历史文化名镇名村的非结构化文本输入训练好的模型中进行实体标签的识别。通过对实体识别的信息进行提取,将实体与标签通过字典的形式进行保存,如:{“岳西县”:”county”,”响肠镇”:”town”}的形式,以便于后续进行知识图谱的自动化构建过程。
2.3 关系抽取
上述实验的命名实体识别技术只能抽取出本文知识图谱所需的实体数据集,建立完整的知识图谱还需要考虑到不同实体间存在的语义关系,这是必不可少的。为实现关系抽取,本文采用预定义关系词典与命名实体识别模型相结合的方法,具体流程见图5。
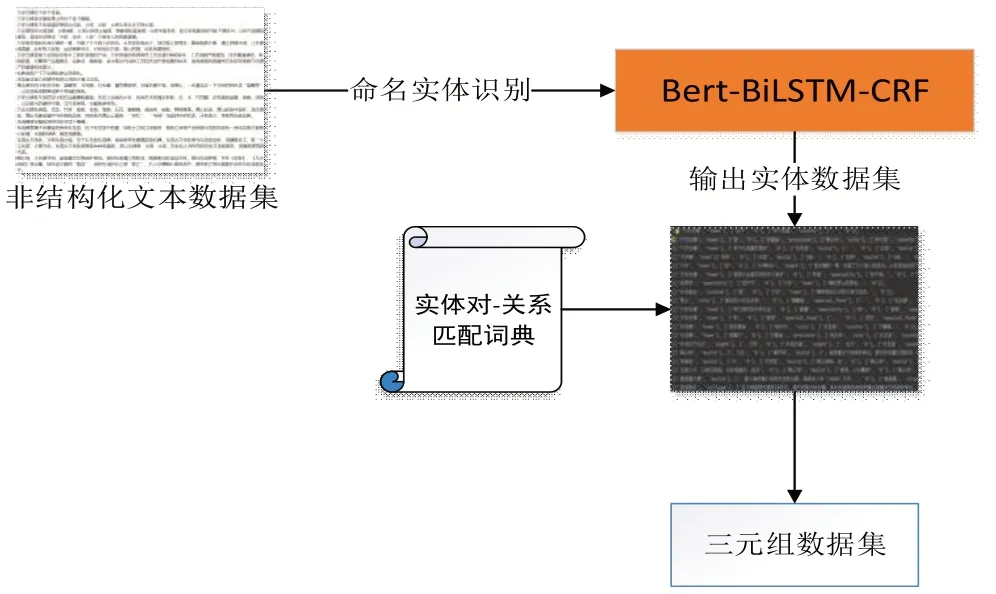
图5 关系抽取流程图
在命名实体识别模型训练完成后,通过将非结构化文本数据集处理成每句中至少包含两个实体的数据集,并输入命名实体识别模型中进行实体的预测,将预测的数据集与输入的文本进行匹配,得到构建知识图谱所需的实体列表。
结合关系词典与实体数据集进行实体之间的关系匹配,关系匹配词典如表4所示。若句子中存在如表4中所示的实体对,则将该实体对匹配到对应的关系,并将获取的关系与实体保存为三元组的形式,如{’三河古镇’:’town’,’特色产品’:’relation’,’羽毛贡扇’:’specialty’}。通过Py2neo包来进行安徽省历史文化名镇名村知识图谱的自动化构建。
2.4 知识图谱的构建
将上述实验所得到的实体以及关系通过字典的形式进行存储,并将三元组数据集存放于.TXT 格式的文件中。通过File库读取.TXT文件中的数据,并通过字典中的value值来区分所读取的数据是实体还是关系,再根据类别的不同,分别导入不同的构建程序中。
在构建关系的过程中,为避免同一个节点的重复构建,使用merge 函数进行节点的创建;在使用match函数时,需要加上first 函数来解决上述重复构建节点和关系的问题。在构建过程中,为降低代码的复杂度,将三元组数据集中的节点标签、节点属性通过参数变量的形式传入到for 循环结构中,通过复用代码的形式降低程序的冗余程度。通过图6所示的程序可以实现知识图谱的自动化构建过程,最终得到604个实体以及634个关系,构建好的知识图谱如图7所示。

图6 自动化构建程序示例
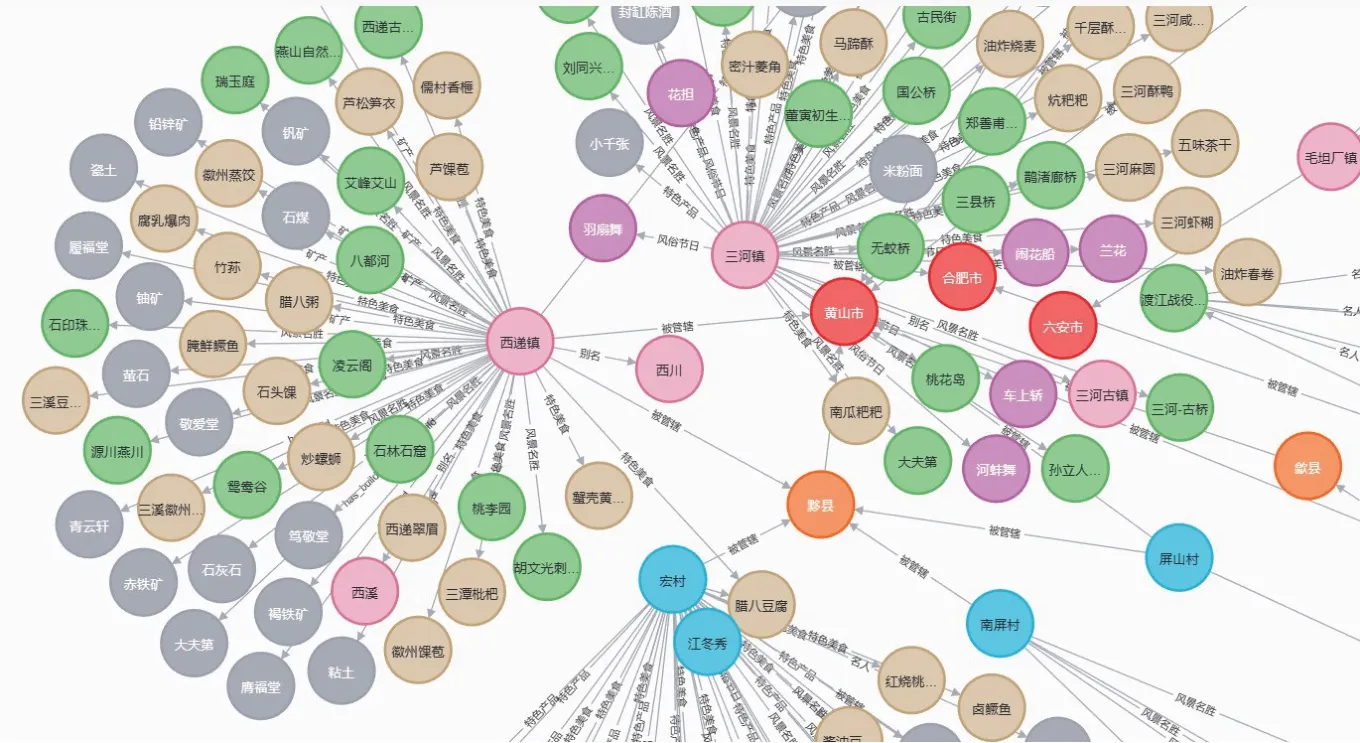
图7 安徽省历史文化名镇名村知识图谱总览
3 结论
本研究通过深度学习训练了可以自动抽取名镇名村知识图谱实体的命名实体识别模型,并且通过对抗训练提升了模型的鲁棒性,进一步提升了识别的精度。通过使用自动化抽取以及自动创建技术,极大程度提升了构建名镇名村知识图谱的效率;将知识图谱与名镇名村相结合,解决了非结构化文本数据搜索效率低、关联度低的问题,为历史文化名镇名村的文化风俗的传承提供了一定的帮助。
未来知识图谱的发展肯定不只限于静态的模式。人类的日常活动以及与知识图谱的交互活动,每时每刻都会产生新的数据以及大量的新事物,因此传统的静态知识图谱推理技术需要考虑如何对时序信息进行处理。在推理技术上逐步投入动态知识推理方向上的研究。
随着文本、视频、语音信息的大量出现,如何将多种模式的知识表示对齐,并构建多模态知识图谱,也将成为亟待解决的问题,因此基于多模态技术的知识推理技术的发展也将成为未来的研究热点。
