基于聚类与差异协调的协同过滤推荐算法
2023-11-24林建辉王茜冉詹可强
林建辉,王茜冉,詹可强
(福建信息职业技术学院 物联网与人工智能学院,福建 福州 350000)
0 引言
2022年发布的第49次中国互联网发展状况统计报告[1]显示,截至2021年12月,我国网民规模达10.32亿,上网比例达99%,网络视频用户、购物用户和新闻用户分别达9.75亿、8.42亿和7.71亿,大数据网络信息时代正悄然而至.协同过滤推荐算法[2]成为大数据时代信息过载[3]问题的福音,在数据海洋中为用户预测推荐节省了宝贵的时间.然而,为目标用户/项目提供准确的预测推荐,前提需要度量选取用户/项目的有效近邻,通过有效近邻,才能准确地为目标用户/项目做出相关的推荐.
针对用户/项目的相似性度量问题,国内外学者提出了不同的观点.Gediminas等[4]将用户/项目的属性视作一个向量,用夹角余弦计算两个向量的相似性,提出余弦相似性度量用户/项目相似性的观点.Ahn等[5]针对不同用户/项目的评价差异,通过减去平均值的方法提出修正余弦相似性度量用户/项目的相似性观点.YUE XI等[6]用皮尔逊相关系数度量两组线性用户/项目的评价相似性.Shardanand等[7]在Schafer的基础上分别提出考虑评分正负性的约束皮尔逊相关系数和考虑共同评分项的权重皮尔逊相关系数.张晓琳等[8]针对用户/项目的共同评价项提出杰卡德相似性度量的方法.事实上,由于用户/项目评价差异、数据稀疏性等问题,导致用户/项目的相似性度量不够准确.
本文提出基于聚类与差异协调的协同过滤推荐算法,通过目标用户近邻聚类可以有效缩减近邻搜索的时间与空间,结合时间权重的近邻聚类,减少用户在每个时间阶段的风格特色、人文喜好上差异的影响.通过评价差异因子协调目标与近邻的评价差异,完成预测推荐.实验结果表明,该算法能够提高协同过滤推荐系统的推荐质量和准确度.
1 基于聚类与差异协调的协同过滤推荐算法
在协同过滤推荐算法中,m个用户用集合U={u1,u2,…,um}表示,n个项目用集合I={i1,i2,…,in}表示,用户对项目的评分数据集用一个m×n阶的矩阵R表示[9].其形式为:
(1)
其中,Ri,j(1≤i≤m,1≤j≤n)表示用户ui对项目ij的评分,协同过滤推荐就是根据已知的用户和项目等数据为不同用户做出个性化的推荐.
传统的相似性度量需要通过计算用户/项目的评价数值,例如余弦相似性、皮尔逊相关系数和修正余弦相似性等.实际上用户评价存在个人尺度或者评价习惯,有的用户倾向于给高分,有的用户倾向于给低分.那么,在计算习惯给高分和习惯给低分的两个用户相似性时,通过传统相似方法得到的结果必然是两个用户不相似,或者相似性低.而事实上,两个用户的兴趣爱好极大可能相似.本文采用聚类方式筛选出目标相似的用户,结合时间权重聚类,完成目标用户在相近时间段内有过共同兴趣爱好的用户聚类.
1.1 用户/项目的近邻与时间权重聚类
大数据时代,协同过滤需要在用户/项目的数据集里计算出用户/项目的相似性,需要耗费大量的计算资源,且计算结果可能存在不确定性.本文通过近邻与时间权重共同聚类的方法,将用户/项目共同评分过的近邻进行聚类,进而缩减近邻的搜索时间与空间.
1.1.1 近邻聚类
近邻用户的搜索选取是协同过滤推荐的基础,从大数据库中快速而准确地选取近邻是推荐系统近邻选取的目标.对目标用户的近邻进行聚类的方法可表示为:
(2)
式中,NBR{ua,ui}表示目标用户ua的近邻聚类集合;Ia∩Ii是用户ua与ui共同评分的项目集合;Ia∪Ii是用户ua与ui有评分的项目集合,Ia和Ii分别表示用户ua与ui的评分的项目集合.该式表述的是两用户共同评分项目在两用户所有评分项目中的占比,占比越大,表示两用户对项目的选择就越接近,通过近邻聚类可以有效地将目标用户的最近邻进行聚类.
1.1.2 时间权重
每个时间阶段的用户在风格特色、人文喜好上或多或少都存在着差异,衡量用户在不同时间阶段的评价差异的公式为:
(3)
式中,T(ua,ui)表示用户ua与ui评价时间权重,取值范围为0到1,两用户的评价时间越接近,该时间权重值越大,表示两用户的相似程度越大.tua-tui表示两用户评价同一项目的时间差值,该差值越小说明两用户在某个时间范围内兴趣爱好越接近.
1.1.3 结合时间权重的近邻聚类
通过时间权重可以衡量用户在不同时间阶段的评价差异,结合时间权重的近邻聚类能够将目标用户在相近时间段内有过共同兴趣爱好的用户进行聚类,具体公式为:

(4)
式中,TNBR{ua,ui}表示目标用户ua结合时间权重的近邻聚类集合.
1.2 差异协调因子
传统的相似性度量无法衡量用户的评价习惯,因而在度量用户间的相似性时往往不够准确.本文结合时间权重的近邻聚类方法聚类目标用户的近邻,通过用户间评价的差异均值或差异方差衡量用户的评价差异.
1.2.1 差异均值
差异均值描述的是用户之间对共同评价的差异平均值,是项目受到用户喜爱的差异平均值,表达式为:
(5)
式中,AverDif(ua,ui)表示用户ua和用户ui的差异均值,Ri,j表示用户ui对项目ij的评分,Ra,j表示用户ua对项目ij的评分,n是用户之间共同评价项目的总数.
1.2.2 差异方差
差异方差描述的是用户之间对共同评价的差异标准方差,是项目受到用户喜爱的标准差异标准方差,表达式为:
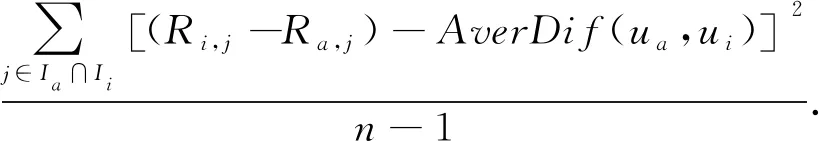
(6)
式中,s2Dif(ua,ui)表示用户ua和用户ui的差异方差.
1.3 预测推荐
对目标用户ua的未评分项目进行预测,首先需要找到目标用户的最近邻,借助公式(4)可得到用户/项目的共同评分的近邻与时间权重聚类用户集合TNBR,且可调整与目标用户ua最近邻的数量.根据公式(7)和(8)可计算目标用户ua对未评分项目的预测评分,在后续的实验中会对计算结果进行对比分析.
(7)
(8)
公式(7)和(8)式中,Pa,j为目标用户ua对未知评分项目ij的预测评分;K是近邻总数,n是用户之间共同评价项目总数.根据上式计算目标用户ua对未评分项目的预测评分,最终将评分最高的前N个项目作为目标用户ua的推荐结果.
1.4 算法描述
本文提出的基于聚类与差异协调的协同过滤推荐算法(CF-TNBRD),通过近邻与时间权重共同聚类的方法,缩减近邻的搜索时间与空间,改善了传统通过计算用户相似性选取近邻不够准确的问题,最后通过差异协调因子协调用户/项目间的评价差异.其算法流程如下:
(1)由用户、项目评分等数据构造出用户-项目评分矩阵;
(2)结合用户-项目的评价时间属性,对目标用户进行评分与时间权重的近邻聚类,根据需求选取最近邻聚类数量;
(3)根据公式(5)和(6)对聚类的最近邻计算用户间的差异;
(4)根据预测公式(7)和(8)进行预测评分;
(5)选取评分最高的前N个项目作为推荐结果,完成推荐.
2 实验与结果分析
2.1 实验数据集
实验采用的数据集[9]包括:①美国明尼苏达大学GroupLenps研究项目组提供的MovieLensML-100K数据集,包含了943个用户对1 682部电影共100 000条的评分记录;②百度电影推荐系统比赛使用数据集,包含了15万用户对15 000部电影约1百万条的评分记录,实验随机选择了943位用户对1 682部电影共62 507条的评分记录.两个实验数据集的评分范围均为1~5,数值越大表示用户对电影的喜欢程度越大.实验随机选取数据集中的80%作为训练集,20%作为测试集.
2.2 推荐的评价准则
本文采用的评价准则是广泛应用于评价协同过滤推荐算法的平均绝对误差[10](MAE)和精确度(Precision)[11],MAE通过计算预测评分与实际评分的平均误差来衡量推荐质量,MAE越小,说明推荐质量越好.其计算公式如(9)所示,式中,Pa,j表示预测用户对项目的评分值,Ra,j表示实际的用户对项目的评分值为,T为测试集的项目数量.
(9)
Precision是通过计算预测评分与实际评分相等的数量占整个测试集的比率来衡量推荐的准确度,Precision指标值越大,说明推荐准确性越好.其计算公式如(10)和(11)所示,用Nj表示用户对项目j预测评分值与实际评分值的关系,当预测用户对项目评分值与实际评分值相等时用1表示,否则用0表示.
(10)
(11)
2.3 实验结果分析
实验将所提算法、基于聚类与差异均值协调协同过滤推荐算法(CF-TNBRAD)、基于聚类与差异方差协调协同过滤推荐算法(CF-TNBRS2D)与传统的基于用户的协同过滤算法(UCF)[12]进行对比.取横坐标为聚类近邻数,其值从5逐渐增加到40,纵坐标分别为MAE和Precision,实验结果如图1和图2所示.
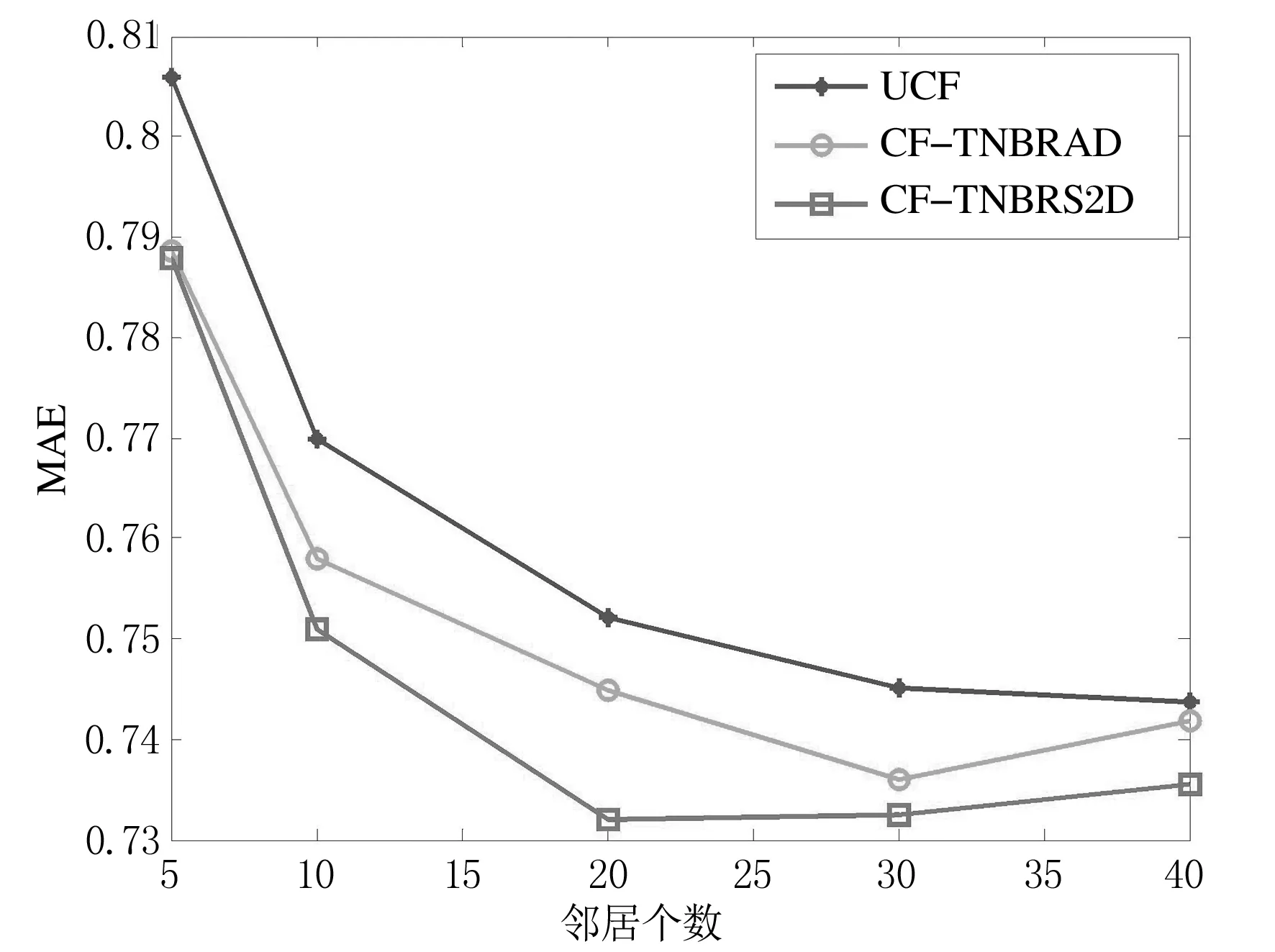
(a)MovieLens数据集下各算法MAE对比结果

(b)百度电影数据集下各算法MAE对比结果

(a)MovieLens数据集下各算法Precision对比结果

(b)百度电影数据集下各算法Precision对比结果
从图1(a)和(b)的实验结果可知,各算法随着目标用户近邻个数的增加,MAE逐渐降低,而本文算法MAE要比UCF算法低,表明了本文算法在推荐质量上优于UCF算法.从图2(a)和(b)的实验结果可知,各算法随着目标近邻数的增加,Precision逐渐提高,而本文算法Precision要比UCF高,表明了本文算法在推荐准确度上优于UCF.综上,本文算法在总体上优于传统基于用户的协同过滤算法(UCF),能够提高推荐系统的推荐质量和准确度.
3 结语
最近邻的有效选取是推荐系统预测中最为关键的环节之一,传统推荐算法在用户相似性度量方面存在不足.本文提出基于聚类与差异协调的的协同过滤推荐算法,采用用户间共同评分与评分时间属性相结合的方式将目标用户的最近邻进行聚类,改善最近邻的有效选取.通过评价差异协调因子协调用户之间的评价差异,实现目标用户的评分预测.实验结果表明,所提算法能够提高推荐系统的推荐质量和准确度.
