基于区块链和动态评估的隐私保护联邦学习模型
2023-11-24唐琮轲
刘 炜 唐琮轲 马 杰 田 钊 王 琦 佘 维
1(郑州大学网络空间安全学院 郑州 450002)
2(河南省网络密码技术重点实验室(信息工程大学)郑州 450000)
3(郑州市区块链与数据智能重点实验室(郑州大学)郑州 450000)
4(郑州大学图书馆 郑州 450001)
(wliu@zzu.edu.cn)
近年来,数据泄露事件剧增,而作为使用个人数据极为频繁的服务——机器学习(machine learning)备受关注.随着我国《网络安全法》《个人信息保护法》以及欧盟《通用数据保护条例》等旨在保护用户个人隐私和数据安全法规的出台,工业界和学术界对机器学习的隐私保护越来越重视,Google 在2016 年提出了联邦学习(federated learning)[1]解决隐私保护等问题.联邦学习是一种协同分布式训练模型.传统联邦学习分为中心服务器和参与方两种角色,参与方在中心服务器的协调下共同训练机器学习模型,训练数据仅保存在各参与方本地,依靠参与方本地迭代和与中心服务器的通信完成模型训练和聚合[2].
联邦学习作为一种新的训练机制,在保护隐私和解决数据孤岛的同时对多方数据进行训练聚合,在医疗、金融等用户信息高度保密的行业有很好的前景.但是随着联邦学习的广泛应用,它的问题也逐渐浮现出来.在机器学习中,训练数据可以通过梯度和模型被反推出来[3-4],而在联邦学习这种服务器和参与方每轮迭代都能看到模型梯度的情况中,用户信息就更容易被反推出来[5-6].除了隐私泄露的问题外,联邦学习还面临各种各样的恶意攻击,例如投毒攻击[7-8],通过修改训练数据,可以使经过训练的模型出现特定的错误;模型投毒攻击[9]通过修改训练数据的标签,造成模型的判定错误;成员推理攻击[10]中攻击者能够通过机器学习模型和样本来确定该样本是否存在于建立机器学习模型的训练集中.除此之外,系统还面临服务器的单点故障以及缺乏奖励导致的参与方不愿贡献数据和算力的问题[11].
为了解决这些问题以及应对联邦学习不断发展的需求,使用联邦学习结合隐私保护技术、区块链、边缘计算和云计算等技术,逐渐成为研究的热门方向[12].利用区块链的可追溯、去中心化、不可篡改等特性和智能合约功能,帮助联邦学习克服单点故障、缺乏激励机制、审计困难等问题,在隐私保护和审计记录等方面有很大的提升[13].
本文提出一种基于区块链和动态评估的隐私保护联邦学习模型——SPFLChain(security privacy federated learning blockchain).利用区块链的去中心化、不可篡改等特性,为联邦学习建立可信、隐私安全的训练环境.在模型交互阶段采用稀疏化和差分隐私结合的方式进行隐私保护;在本地局部模型训练完成后对其进行身份验证和性能评估,反映参与方训练出的模型准确率和泛化能力.最后通过使用深度梯度泄露(DLG)攻击对局部模型和全局模型进行攻击实验,证明SPFLChain 的安全性.
本文的主要贡献包括3 个方面:
1)提出一种基于区块链的联邦学习隐私保护模型SPFLChain,实现安全的去中心化联邦学习评估模型.
2)利用加密算法和数字签名技术验证参与方身份,本地训练采用稀疏化保证链下模型交互的安全性与可信性,并在模型更新时使用差分隐私添加噪声保证模型上链后的隐私安全.
3)提出三权重动态评估方案,计算单轮模型和参与方评估值,为参与方进行动态评估,确保激励机制的公平性.
1 相关工作
联邦学习是一种基于隐私保护的分布式机器学习框架,许多参与方在中心服务器的协调下共同训练模型,同时保持训练数据的分散性,在不暴露数据的前提下分析和学习多个数据拥有者的数据,做到数据的可用不可见.将区块链网络应用于联邦学习系统中,在发挥联邦学习优势的同时,还能够解决联邦学习面临的单点故障、隐私安全和缺乏激励等问题[14].
Kim 等人提出名为BlockFL[15]的区块链与联邦学习系统框架,详细描述了从局部模型更新到上链再到全局模型更新的全过程,其中矿工使用区块链智能合约实现模型的交换和验证,并通过记录为矿工和关联设备分配奖励.Liu 等人[16]提出名为FedCoin的支付系统,该系统中包含区块链网络和联邦学习,联邦学习完成本地训练和模型聚合,区块链共识节点协同计算贡献值,为联邦学习提供去中心化无第三方的支付方案.Peng 等人[17]提出了一种基于区块链实现的可验证和审计的联邦学习系统框架VFChain,将可验证的记录证明存储在区块链中并设计了一种安全轮换委员会的方案,提出了支持多模型学习任务的方案以优化搜索效率,为区块链结合联邦学习提供了审计和验证的新思路.Li 等人[18]提出了一种基于区块链的去中心化委员会共识的联邦学习框架BFLC,其设计的创新型委员会共识机制能够有效减少共识的计算量,降低中心服务器和节点恶意攻击的可能性.但文献[15-18]的研究工作解决的大多是联邦学习的中心化问题以及区块链结合联邦学习架构中缺乏激励机制的问题,没有考虑模型参数交换和更新带来的隐私泄露问题.
为了解决上述问题,高胜等人[19]提出了一种基于区块链的隐私保护异步联邦学习,利用区块链解决联邦学习的中心化问题,并结合差分隐私的指数机制选择高贡献率的模型,分配隐私预算保证全局模型的隐私,使用双因子调整机制提高全局模型的效用.Wainakh 等人[20]为了增强联邦学习的隐私安全,设计了一种分层的联邦学习架构,即在传统的联邦学习的基础上加入组服务器,将组服务器插入到服务器与参与方之间当作保护层,对有问题的模型进行筛选,同时可以降低用户噪声,提高模型质量.Shayan 等人[21]提出了一种隐私安全的区块链系统Biscotti,这是一个去中心化的提供安全私密的多方机器学习系统,提出联邦证明(proof of federation)共识,并结合了防御手段,有很好的扩展性和安全性.Zhao 等人[22]提出了一种基于区块链的物联网设备联邦学习系统,利用边缘计算服务器制造初始模型,将局部模型发送到区块链进行聚合,使用差分隐私结合归一化进行特征提取来保护隐私,并设计了激励机制鼓励参与方训练.周炜等人[23]提出了一种基于区块链的联邦学习模型PPFLChain,使用同态加密对交互的模型进行加密,通过秘密共享方案对密钥进行安全管理,同时使用信誉值机制保证公平.
区块链技术已经广泛成为解决联邦学习应用中安全问题的工具.通过联盟链的身份认证和权限设置对参与方进行一定条件的限制,提高系统的安全性.但是现有研究大多针对链下模型交互时的安全性,对链上存储的安全保障有所欠缺,并且在对局部模型验证评估和参与方贡献评估方面缺乏研究.
2 预备知识
2.1 区块链
区块链这一概念随着2009 年比特币的诞生而产生,其本质上是由P2P、密码学、共识机制、智能合约等一系列技术组合而成的去中心化分布式账本[24].它的优势在于使用密码学方式保证了不可篡改和伪造的特性,利用链式结构验证存储数据,利用共识算法在各个分布式的节点之间生成和更新数据,利用智能合约的设计完成对数据的操作.
区块链可以分为公有链、私有链和联盟链.公有链对任何人都开放,并且能被参与区块链的任何人维护和读取.私有链由单个组织或机构单独控制,只有授权用户才能访问链上数据,有着更高的隐私性与效率.而联盟链由多个组织或机构控制,兼顾了去中心化和隐私安全性.
2.2 稀疏化
稀疏化[25]本质上属于梯度压缩的一种,通过构建d维的掩码矩阵m∈{0,1}d,将梯度g的d维向量稀疏表示为,g=m⊗g,⊗表示元素相乘,能够减少其通信传递量减轻负载和保护隐私,稀疏比prop定义为:
在联邦学习中,常见的有2 种稀疏化方法:Top-K和Rand-K稀疏化.
Top-K的思想是基于每个客户端根据绝对值最大的K个梯度进行掩码矩阵的构建,但是对于规模大的神经网络时,需要进行计算量很大的排序操作.
而Rand-K稀疏化则是构建随机的掩码矩阵,与Top-K相比,Rand-K在复杂度和效率上更好.但是因为其随机性,误差概率也更大,在很高的稀疏比例中表现不佳.
2.3 差分隐私
差分隐私[26-27]由Dwork 提出,它是一种隐私保护方法,通过对数据添加干扰噪声,使得攻击者无法通过已知的发布信息推断出其他有用的信息,保护了数据中的用户隐私.
相邻数据集.相邻数据集指2 个数据集D与D′中最多只有一个数据或元素不同,即 ||D-D′||1≤1.
敏感度.敏感度衡量了相邻数据集查询结果之间的最大差异,定义为 Δf=
ε-差分隐私.拉普拉斯机制定义为M(D)=f(D)+Y(Y1,Y2,…,Yk),f为查询函数,M为随机函数,Y为服从拉普拉斯分布的随机噪声.当拉普拉斯概率分布时,拉普拉斯机制就满足 ε-差分隐私:Pr[M(D)∈S]≤eε·Pr[M(D′)∈S],ε 为隐私预算.当 ε越小时,表明2 个数据集经过随机化以后输出结果的概率分布越接近,隐私保证的级别就越高.严格差分隐私对机制有很高的要求,但是又不能添加过多的噪声以免造成信息的损失,因此就引出了(ε,δ )-差分隐私,其敏感度定义为:
其中 δ为松弛项,表示有1-δ 的概率满足差分隐私,σ为噪声尺度.
2.4 数字签名
数字签名是基于非对称加密的验证文档或信息真实性和完整性的技术,通过对信息进行加密和签名生成数字签名,接收方使用其公钥对签名进行解密验证,确保数据没有被篡改,具体流程为:
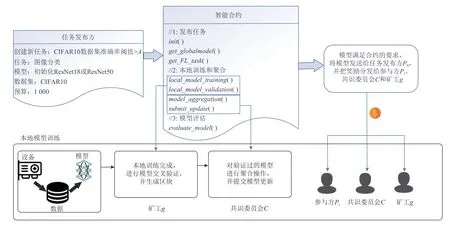
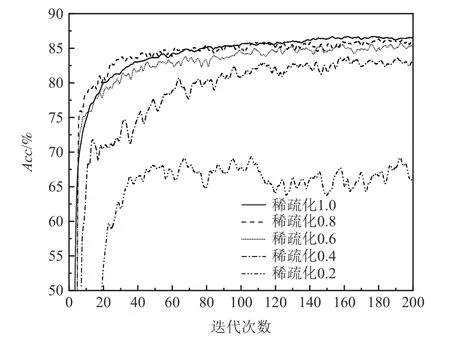
密钥生成KeyGen():用户随机选择大素数p和q,计算N=p×q,以及φ(N)=(p-1)×(q-1),随机选择r满足0 签名Sign():首先对要发送的信息m进行Hash运算,h=hash(m),然后对其哈希值进行加密签名,生成密文C=Sign(hash(m))=hdmodN. 验证签名VerifySign():接收者需要对发送方的签名进行验证时,按照2 个流程进行验证: 1)使用发送方公钥pk对签名进行解密,h′=CrmodN. 2)对消息m进行Hash 运算,若h=h′,签名有效,否则验证签名无效. 联邦学习中,中心服务器面临单点故障、梯度参数收集和更新中可能出现的隐私泄露风险.针对此问题,本文提出了一种基于区块链的联邦学习模型SPFLChain,将多个互不信任的参与方整合到一起协同管理,符合联盟链的应用场景,其中包括任务发布方、区块链、矿工、参与方和共识委员会. 在执行各自任务之前,需要在区块链上进行注册并进行身份验证.区块链为联邦学习的参与方和矿工提供可信身份认证,只有被成功授权的节点才能加入到区块链网络中. 1)任务发布方P0.联邦学习训练模型的需求方,当任务发布方想要训练机器学习模型,但是设备或数据储备不完善时,可以委托共识委员会进行有偿代训练. 2)矿工g.没有关联训练设备,达不到训练条件或拒绝参与训练的参与方,仅作为区块链中的矿工去生成区块和验证参与方的模型. 3)参与方Pi(i=1,2,…,n).数据拥有者,有关联设备能够参与训练,并且能够作为矿工对其它参与方进行模型的验证和生成区块. 4)共识委员会C.共识委员会由全节点随机组成,成员总数要根据实际情况控制在一个范围内,避免因为成员人数过多造成资源浪费,或者又因为成员人数过少造成模型误差过大.主要完成对验证通过的局部模型进行聚合操作,在聚合后把收敛的全局模型上传给任务发布方. 在SPFLChain 中,假设参与方、矿工、共识委员会是半诚实的,严格按照联邦学习中的协议执行,会为了自身利益正确履行训练模型和聚合模型的职责,但是有兴趣推断其他参与方训练数据或者有意义的标签信息.参与方完成本地训练后,聚合模型交给区块链网络中委员会节点,由区块链网络矿工节点进行局部模型验证.如图1 所示,具体流程如下: Fig.1 SPFLChain training process图1 SPFLChain 训练流程 1)训练需求发布.作为联邦学习训练模型的需求方,在身份验证完成后,任务发布方P0根据自己的不同需求将训练任务请求广播到区块链上,其中包括要训练的数据集D、初始全局模型w0、支付预算BP0和要求达到的准确率等. 2)记录查询.共识委员会相当于区块链网络中的全节点,存有区块链中的所有历史信息.任务发布方P0广播请求后,由共识委员会C检索记录中是否存在要求相同的训练模型.如果共识委员会C在本地记录中查询到有符合训练请求的模型,根据本地记录中的Hash 值,通过getBlockByHash()在链上获取到模型,并发送给任务发布方P0,如图2 所示,除了模型的基本信息以外,全局模型包括聚合所用的局部模型序号(sub_model),用于模型出现问题后的溯源工作. Fig.2 Consensus committee local storage record structure图2 共识委员会本地存储记录结构 3)局部模型训练.如果查询不到记录,由共识委员会广播任务,参与方Pi(i=1,2,…,n)监听广播.参与方接收到训练请求后,根据需求选择是否参与此任务发布方的训练.由参与方P1,P2,…,Pn计算局部损失本地模型梯度 ∇L(θ;b),并进行本地模型更新. 4)模型发送.参与方进行本地的迭代训练,利用初始模型和本地数据训练局部模型,完成后用私钥ski以及矿工公钥pkg将局部模型签名加密发送给矿工. 5)模型验证.矿工通过解密与双重Hash 对比后验证参与方提交模型的所有权. 6)局部模型发送.局部模型通过验证,由矿工发送给共识委员会C进行聚合. 7)全局模型聚合.只有当共识委员会C收集的模型达到一定数量或者超过一定的时间上限,才能触发智能合约,通过智能合约完成模型聚合,并加入高斯噪声: 其中,Δt为t轮聚合后的全局模型差值,N(0,σ2)为服从高斯分布的噪声. 8)模型评估.完成验证并在聚合完成后的局部模型要通过智能合约评估,通过其准确率acc、全局模型w与局部模型wk的欧氏距离等因素来为其计算出一个评估值Eval. 9)生成区块并上链.评估完成后将本轮次的全局模型打包生成区块并执行共识上传到区块链上.参与方从链上获取全局模型作为初始模型进行下一轮的迭代训练,直至全局模型的收敛. 共识委员会C计算的全局模型收敛或者达到迭代轮次上限,将全局模型交付给任务发布方,并把奖励分发给参与方Pi(i=1,2,…,n)、矿工g和共识委员会C.评估和奖励分发过程如图3 所示. Fig.3 Reward distribution process图3 奖励分发过程 任务发布方P0需要根据参与方Pi(i=1,2,…,n)、矿工g、共识委员会C等做出的贡献进行转账,其中包括参与方Pi(i=1,2,…,n)的训练奖励、数据贡献奖励、矿工的验证评估奖励、共识委员会C的模型聚合奖励以及区块生成奖励. 在整个流程中,一旦模型进入区块链网络,后续所有验证和聚合操作都会被系统记录在链上.最终训练结束后为参与方Pi(i=1,2,…,n)生成一个评估值Score,这为系统数据流转的溯源和激励机制的公平分配提供了保障.如果出现问题,可以通过查询记录来锁定问题源头,变相降低了参与方、矿工和共识委员会作恶的可能性. 针对半诚实参与方造成的隐私威胁,SPFLChain用区块链网络替代传统的中心服务器,解决联邦学习的单点故障问题.训练过程分为本地训练和模型聚合,本地训练使用稀疏化,模型聚合使用差分隐私添加噪声来保护隐私. 在本地训练阶段,采用随机稀疏化构建一个服从伯努利分布的d维随机矩阵m={0,1}d,设置其中的稀疏程度字段prop,prop值越大,掩码矩阵中的“1”值越多,在本地训练完成后,将梯度和掩码矩阵相乘,计算模型参数,再将参数差值传递给矿工. 具体过程如算法1 所示. 算法1.本地稀疏化算法. 接收到局部模型进行聚合后,采用添加服从高斯分布的噪声进行模型更新.具体过程如算法2 所示. 算法2.模型聚合算法. 通过迭代直到模型收敛或者达到训练轮次,由共识委员会将聚合后的最终模型交付给任务发布方. 局部模型的验证评估对全局模型精度和隐私安全都至关重要,模型评估也可以作为最终激励机制奖励发放的重要依据.通过对模型准确率、训练时长、数据集大小等多种因素综合考虑,本节提出一种模型验证评估方法,由矿工正确验证参与方模型的身份和所有权后,在全局模型聚合后对参与方提交的局部模型进行基于多权重的质量评估.保证联邦学习安全性的同时,为后续的激励机制提供证明,提高参与方训练积极性. 为了验证参与方身份,矿工对参与方所发送模型进行验证,参与方随机挑选一个矿工,将本地训练的局部模型提交,由矿工进行验证,验证流程如下. 1)模型加密.被选中矿工g通过KeyGen()得到公私钥对:公钥pkg=(Ng,rg),私钥skg=(pg,qg,dg).参与方Pi使用pkg对其模型m进行加密,然后将加密后的密文Cm提交矿工. 2)模型签名.参与方Pi计算得出公私钥对:公钥pki=(Ni,ri),私钥ski=(pi,qi,di).首先使用Hash 算法对模型进行加密,h=hash(m),使用私钥ski对h签名生成密文Ch=hdmodNi. 3)Hash 对比.矿工使用自己的私钥skg对Cm进行解密得到模型m,使用相同的Hash 运算对m加密得到h0,再用参与方Pi的公钥pki对Ch解密得到h1,对比h0和h1,如果相等,则签名有效,否则签名无效. 4)二次Hash 对比.在当前训练任务中,为了防止模型上链后被懒惰参与方直接取用,矿工需要承担在本地存储局部模型及全局模型的Hash 值.矿工完成第一次Hash 对比后,使用hash(m)检索本地模型Hash 值记录,完成对记录的遍历后无击中即可证明模型有效. 局部模型的评估需要考虑多种因素,为了保证模型准确率的同时防止过拟合,通过多个因素分配不同权重值来完成评估值的计算.提出一种三权重评估方法,三权重的值分别为ρ,ξ,ω,分别为准确率、欧氏距离、参与方本地训练数据集大小赋予权重,满足ρ,ξ,ω∈[0,1]且ρ+ξ+ω=1,共同计算模型评估值Eval. 1)准确率.在联邦学习,最终目的是向任务发布方交付一个高性能的模型,准确率是衡量模型的重要指标,准确率定义函数为 式(5)表示单轮结束后样本分类结果与真实值进行对比,统计正确分类样本数,将其除以总样本数得到准确率.仅考虑准确率可能会忽略过拟合的情况,所以需要结合其他因素来综合考虑. 2)欧氏距离.欧氏距离反映模型在预测时的泛化能力,本文定义欧氏距离的函数为 其中,x和y分别表示局部模型和聚合后全局模型对矿工拥有的同一测试样本的预测输出. 3)数据量.参与方训练数据集D过小会导致训练模型过拟合,即使在训练数据上表现很好,但是也会在新数据的表现不佳.本地训练数据集的大小也是衡量参与方贡献以及模型质量的一个重要指标. 4)单轮模型评估值计算.评估值计算需要考虑1)~3)三种因素的综合表现,参与方Pi在第k轮的模型评估值函数定义为 5)参与方评估分计算.评估分依据前面每轮评估值的计算,每轮评估值都被赋予权重q,权重值递增,满足且qj-qj-1=qj-1-qj-2,E为总迭代轮次,参与方Pi在E轮迭代结束后的评估分计算公式为: 评估方案赋予后期迭代更高的权重值,当参与方前面因为各种因素导致训练效果不佳时,能够依靠后期训练提升评估分.参与方的评估分Score将作为激励机制奖励分配的重要依据,以保证奖励分配的公平性. 联邦学习允许各个参与方在不贡献本地训练数据前提下,协同训练共享全局模型,因此本地的原始数据得到保护[28].但是联邦学习训练过程中会遭受深度梯度泄露等隐私攻击.SPFLChain 引入差分隐私技术实现全局模型链上安全存储、链下局部模型加密传输以及稀疏化保证隐私安全,通过采用高斯机制的差分隐私实现在保障安全的情况下均衡模型性能,构建安全的训练过程. 本文实验使用ResNet18 训练CIFAR10 数据集,损失函数定义为交叉熵损失函数.实验中设置10 个参与方,每次参与训练的参与方有3 个,设置batch_size为32,学习率α为0.005,本地迭代次数为3,全局迭代200 轮. 实验采用CIFAR10 数据集.CIFAR10 为尺寸32×32 的10 分类RGB 彩色图片,数据集中一共包含50 000 张训练图和10 000 张测试图. 实验所用的开发工具为Jupyter Notebook 和PyCharm.编程语言为Python3.8,智能合约由Solidity语言编写.配备Intel®CoreTMi5-10500 CPU @ 3.10 GHz 处理器、16 GB 运行内存以及NVIDIA GeForce RTX 3 060 显卡,操作系统为Windows 10. 实验先通过局部训练找出稀疏程度prop,以固定的稀疏程度prop训练局部模型,全局模型更新时添加噪声,再通过不同的噪声参数σ进行实验对比.通过DLG 攻击实验证明,SPFLChain 不论是在局部模型传输还是全局模型上链,都能在实现隐私保护的同时保证模型效用. 如图4 所示,使用了0.2,0.4,0.6,0.8 和1.0 的稀疏程度进行联邦学习,对比不同稀疏程度对联邦学习模型准确率的影响.实验结果证明,在随机稀疏程度为0.8 时,模型准确率下降仅为0.3%. Fig.4 Comparison of model training under different sparsity levels图4 不同稀疏程度下的模型训练对比 本地训练进行稀疏化和全局模型使用差分隐私添加噪声.实验结果如图5 所示,采用0.8 的稀疏度和0.003 的隐私噪声,在损失1.5%准确率的情况下,保证了局部模型和全局模型的隐私. Fig.5 Comparison of model training with different noise added by differential privacy图5 差分隐私添加不同噪声的模型训练对比 DLG 作为一种能够利用梯度还原数据的攻击方法,在联邦学习图像分类这种需要多次交互的模型中更能很好地发挥作用,所以本节采用具有代表性的DLG 攻击证明隐私安全实验的可行性. 实验对使用稀疏化和差分隐私方法后的模型梯度进行DLG 攻击,对CIFAR10,CIFAR100,MNIST,Fashion-MNIST 多个数据集进行抽样攻击表明本文方案对模型保护的泛化能力. 如图6 所示,说明了稀疏程度在0.7,0.8,0.9 和1时对恢复图片的效果对比.在稀疏程度为0.8 时,DLG 攻击已经造成对绝大多数的图像像素点无法复原,能够很好地保护原始数据集的隐私.如图7 所示,显示全局模型聚合时使用差分隐私添加噪声对DLG攻击的影响对比,在噪声参数为0.003 时,能够保护大部分像素不被复原. Fig.6 Comparison of the effect of different degrees of sparsity on the recovery of DLG attack images图6 不同稀疏度程度对DLG 攻击图片恢复影响对比 Fig.7 Comparison of the effect of different differential privacy noise values on the recovery of DLG attack images图7 不同差分隐私噪声值对DLG 攻击图片恢复影响对比 模型评估值设置3 个参与方,其中1 个为恶意参与方,在训练期间对本地数据集进行毒化训练.测试使用CIFAR10 中测试集的图片182_bird.jpg,分别使用参与方1、参与方2 和恶意参与方的局部模型与聚合的全局模型对该图片进行预测识别,计算局部模型和全局模型的差值作为模型评估的一个标准.在权重值ρ=0.7,ξ=0.2,ω=0.1 时分别对比它们在前50轮中的评估值. 如图8 所示,显示3 个参与方在前50 轮的评估值变化对比.实验结果表明,本文方案能够有效识别和辨别恶意参与方使用本地毒化数据对局部模型造成的影响. Fig.8 Comparison of evaluation values among different participants图8 不同的参与方评估值对比 本文提出了一种基于区块链的隐私保护联邦学习模型SPFLChain.该模型使用区块链网络替代中心服务器,实现了分布式协同解决计算问题,同时避免了数据泄露风险.为了提高模型的隐私保护性能,在局部训练过程中采用稀疏化,模型聚合更新采用基于高斯机制噪声的差分隐私.经实验证明,提出的模型实现了链下局部模型和链上全局模型的隐私保护,在略损失训练准确率的前提下,保证了模型的隐私安全.此外,本文还提出了模型验证和三权重模型评估方法,用于动态评估参与方的训练效果,识别检测参与方的恶意行为.下一步将优化区块链结合联邦学习的效率,并深入探讨激励机制的公平分配. 作者贡献声明:刘炜、唐琮轲提出了算法思路和实验方案;唐琮轲、马杰负责完成实验并撰写论文;田钊、王琦、佘维提出指导意见并修改论文.3 系统模型
3.1 模型概述
3.2 系统流程


4 基于稀疏化的差分隐私
5 模型验证评估方案
5.1 模型验证
5.2 模型评估
6 实验
6.1 实验设置
6.2 性能评估

6.3 隐私安全评估


6.4 模型评估

7 总结
