基于机器学习和全岩成分识别东昆仑祁漫塔格斑岩-矽卡岩矿床成矿岩体和贫矿岩体
2023-11-22刘嘉情钟世华李三忠丰成友戴黎明索艳慧郭广慧牛警徽薛梓萌黄宇
刘嘉情 ,钟世华,* ,李三忠 ,丰成友 ,戴黎明 ,索艳慧 ,郭广慧 ,牛警徽 ,薛梓萌 ,黄宇
(1. 中国海洋大学,深海圈层与地球系统教育部前沿科学中心,山东 青岛 266100;2. 中国海洋大学,海底科学与探测技术教育部重点实验室,山东 青岛 266100;3. 中国海洋大学海洋地球科学学院,山东 青岛 266100;4. 青岛海洋科学与技术国家实验室,海洋矿产资源评价与探测技术功能实验室,山东 青岛 266100;5. 中国地质科学院勘探技术研究所,河北 廊坊 065000)
祁漫塔格成矿带作为东昆仑造山带的重要组成部分,东起乌图美仁乡一带,西至阿尔金断裂,北与柴达木盆地相邻,西南与库木库里盆地相接,东西长约为550 km(丰成友等,2010;钟世华等,2018;Zhong et al.,2021a;张向飞等,2023)。区内岩浆活动强烈,持续时间长,岩性从超基性岩到中酸性岩均有出露,但以花岗岩类岩体为主(Mao et al.,2014;Zhong et al.,2018,2021a;田龙等,2023)。长期以来,对祁漫塔格成矿带花岗岩类的研究是人们关注的焦点,这是由于花岗岩类作为陆壳的最重要组成部分,花岗岩类的研究对认识该地区陆壳生长方式、查明青藏高原地质演化规律均具有重要意义(Yu et al.,2017a;Chen et al.,2018)。此外,更为重要的是,祁漫塔格成矿带是中国西北地区著名的铜钼铁铅锌多金属成矿带,发育了卡尔却卡、野马泉、维宝、鸭子沟等一大批斑岩-矽卡岩多金属矿床(李世金等,2008;丰成友等,2011;高永宝等,2012;钟世华等,2017),而这些矿床的形成与该地区中酸性岩浆活动密切相关(Zhong et al.,2018,2021a)。因此,深入开展花岗岩成因研究、查明花岗岩成矿潜力,已经成为实现该地区金属矿产储量增长的重要突破口。
大量的研究显示,形成斑岩-矽卡岩矿床的中酸性成矿岩体与贫矿岩体(又称为非成矿岩体)具有显著不同的地球化学特征(Rezeau et al.,2019;Rezeau et al.,2020;Pizarro et al.,2020)。研究发现,能够成矿的中酸性岩体通常具有高氧逸度和富水的特征(Richards,2011;Sun et al.,2013;Rezeau et al.,2020),这是由于高氧逸度、富水的岩浆可以确保深部金属不会过早达到饱和,而以硫酸盐相形式被迁移至浅部成矿系统(Ballard et al.,2002)。基于对成矿岩体的这些认识,大量用于识别斑岩系统成矿岩浆的地球化学勘查指标被提出,如基于全岩成分的Sr、Y、La、Yb以及Sr/Y和La/Yb等(Richards,2011;Chiaradia et al.,2012)。这些地球化学指标的提出和建立,极大丰富了全球斑岩系统成矿岩浆的识别方法与找矿勘查理论,推动了该类型矿床的成因研究(Hedenquist et al.,1998;Du et al.,2020)。然而,仅基于少数岩浆特征及对应的元素含量或比值建立的地球化学勘查方法也容易受到热液蚀变、结晶分异、岩浆同化混染等其他因素干扰,从而导致误判。例如,普朗斑岩铜矿的成矿岩浆由于岩浆混合和同化混染,使岩浆氧逸度发生了剧烈震荡(Leng et al.,2018)。此外,随着测试手段和分析仪器的持续进步以及人类生产和科研活动的不断实践,斑岩系统成矿岩体的数据数量正在以可见的速度增加。然而,如何利用如此丰富“海量”的地球化学数据获取更多的成矿信息,传统的地质数据处理方法已显得捉襟见肘(Petrelli et al.,2016;Nathwani et al.,2022)。因此,急需采用新的技术方法,通过充分利用地质大数据,查明成矿岩浆特征,建立识别成矿岩浆新方法,指导找矿勘查和深化矿床成因研究。
因此,在系统收集祁漫塔格成矿带典型斑岩-矽卡岩多金属矿床的成矿岩体和非成矿岩体的全岩主量和微量元素数据基础上,选取28种常见的全岩地球化学特征,借助最常用的机器学习算法之一——随机森林,开展机器学习模型训练,建立能够识别成矿岩体(斑岩-矽卡岩多金属矿床)和非成矿岩体的新方法。研究结果可以为该地区斑岩-矽卡岩多金属矿床的找矿勘查提供有效方法,从而更好的服务新一轮找矿突破战略行动。
1 区域背景
东昆仑造山带是一条位于青藏高原北部的巨型构造岩浆岩带,其东西长约为1 500 km。造山带北起柴达木盆地南缘,南至巴颜喀拉-松潘甘孜板块,东起秦岭-大别造山带,西至阿尔金造山带(许志琴等,2012;潘彤,2017),并大致以乌图美仁乡为界分为东西两段。东昆仑造山带经历了前寒武纪、早古生代、晚古生代—早中生代和晚中生代—新生代旋回4个造山旋回(莫宣学等,2007;董连慧等,2015;田龙等2023)。这些旋回记录了原特提斯洋、古特提斯洋以及新特提斯洋的形成、扩张与消亡过程(Zhong et al.,2017)。除了晚中生代—新生代旋回外,其他造山旋回都伴随着大量的岩浆活动,其中以晚古生代和早中生代(特别是三叠纪)的岩浆活动最为激烈(莫宣学等,2007)。
祁漫塔格成矿带主体位于东昆仑西段,东西长约为550 km,横跨青海和新疆,总体呈西宽东窄的楔形,北西向延伸展布(许长坤等,2012;Zhong et al.,2017)。祁漫塔格地区出露地层时代跨度大、分布零散,且大都经历了不同程度的后期改造(景宝盛等,2013;潘彤,2017)。已有研究证实,中元古界长城系小庙组和狼牙山组、奥陶系滩间山群以及石炭系缔敖苏组和大干沟组与区域斑岩-矽卡岩矿化关系密切,是主要的赋矿地层(丰成友等,2010,2011;高永宝,2013)。长城系小庙组主要为片岩和大理岩等,与区域钨锡矿化关系密切(高永宝等,2011;许长坤等,2012);蓟县系狼牙山组主要由变质碎屑岩和碳酸盐岩组成,夹少量火山岩(丰成友等,2011;赵一鸣等,2013);滩间山群又被称为祁漫塔格群,为一套海相火山-沉积组合(张晓飞等,2012;庄玉军等,2023);大干沟组和缔敖苏组均是一套主要由灰岩组成的碎屑岩-碳酸盐建造(丰成友等,2010,2012)。祁漫塔格成矿带区域构造活动十分剧烈,NW向、NNW向、压扭性断裂组成了区域主体构造骨架(舒晓峰等,2012),不同级别和序次的断裂构造交汇聚合位置,往往是成岩成矿的有利部位,而NE向和SN向断裂大多为成矿后构造(钟世华等,2017)。研究区岩浆岩分布十分广泛,时代上从前寒武纪到早中生代均有分布,但以志留纪—泥盆纪(435~370 Ma)和中晚三叠世—早侏罗世花岗岩(245~196 Ma)最为发育(丰成友等,2012;Zhong et al.,2021b),主要形成于早古生代旋回和晚生代-早中生代旋回的(后)碰撞阶段。
祁漫塔格成矿带是近几年查明的有较大找矿远景的斑岩-矽卡岩型铜钼铁铅锌多金属成矿带(毛景文等,2012),分布有20余处大中型金属矿床,矿化类型多样(图1),成矿元素丰富,代表性矿床有维宝、尕林格、虎头崖、野马泉、卡尔却卡、四角羊、肯德可克等(丰成友等,2011;Yu et al.,2017b;高永宝等,2018;Zhong et al., 2021b)。来自辉钼矿Re-Os和热液白云母Ar-Ar等的年龄结果证实,这些矿床的形成大都与三叠纪花岗岩类有关(李世金等,2008;丰成友等,2011;田承盛等,2013;于淼等,2015;Xia et al., 2015)。近些年,随着勘查和研究工作的深入,在祁漫塔格许多铜钼铁铅锌多金属矿区发现了含矿化的泥盆纪花岗岩体,证实在该地区存在两期斑岩-矽卡岩多金属矿化(Zhong et al.,2021a,2021b)。除这些与花岗岩类有关的矿床外,与基性-超基性岩有关的铜镍硫化物矿床是该地区另一种重要的矿床类型,以夏日哈木超大型铜镍硫化物矿床为代表(杨兴科等,2016;许骏等,2021)。
2 研究方法
2.1 数据来源
文中共收集来自东昆仑祁漫塔格地区的582条成矿岩体与非成矿岩体的主微量元素数据,包括246条成矿岩体的全岩数据和336条非成矿岩体的全岩数据(表1)。其中,246条成矿岩体数据来自以下4种类型矿床:斑岩钼矿(17条)、斑岩铜矿(23条)、矽卡岩铜铅锌矿床(87条)、矽卡岩铁矿床(119条)。虽然矽卡岩钨锡矿床和矽卡岩铅锌矿床在祁漫塔格成矿带也十分发育,但是文中没有使用来自这些矿床类型的成矿岩体数据。这是由于已有研究表明,来自这些矿床的成矿岩体特征与文中使用的4种矿床类型的成矿岩体特征具有显著差异。例如,斑岩钼矿、斑岩铜矿、矽卡岩铜铅锌矿床、矽卡岩铁矿床的成矿岩体通常具有较高的氧逸度特征,而矽卡岩钨锡矿床的成矿岩体氧逸度则较低。
对于每一条全岩数据,选择28种特征用于机器学习模型训练,其中包括7种主量元素(Si、Al、Fe、Mg、Ca、Na、K)、14种稀土元素(La、Ce、Pr、Nd、Sm、Eu、Gd、Tb、Dy、Ho、Er、Tm、Yb、Lu)、5种微量元素(Ba、Rb、Nb、Sr、Y)以及由以上微量元素派生的2个比值(Sr/Y、La/Yb)。选择以上元素特征用于机器学习模型训练是由于已有的研究表明这些元素在成矿岩体与非成矿岩体类型判别上具有重要意义(Nathwani et al.,2022)。
文中汇编了成矿岩体和非成矿岩体全岩地球化学数据库中各个特征的统计学规律(表2,图2)。尽管成矿岩体和非成矿岩体的许多特征的分布范围存在重叠,但是一些特征也表现出显著的差异,如Nb、Sm、Eu、Gd、Dy、Y等(表2,图2)。成矿岩体Nb含量为3.1×10-6~59.0×10-6,平均值为13.9×10-6;非成矿岩体Nb含量为0.5×10-6~89.7×10-6,平均值为16.6×10-6。成矿岩体Sm含量为1.5×10-6~14.8×10-6,平均值为4.9×10-6;非成矿岩体Sm含量为1.4×10-6~22.6×10-6,平均值为7.2×10-6。来自成矿岩体Eu含量为0~2.3×10-6,平均值为0.8×10-6;非成矿岩体Eu含量为0.1×10-6~6.8×10-6,平均值为1.2×10-6。成矿岩体Gd含量为1.2×10-6~14.3×10-6,平均值为4.4×10-6;非成矿岩体Gd含量为1.3×10-6~20.6×10-6,平均值为6.6×10-6。成矿岩体Dy含量为1.1×10-6~23.0×10-6,平均值为4.0×10-6;非成矿岩体Dy含量为0.7×10-6~24.5×10-6,平均值为6.1×10-6。成矿岩体Y含量为6.8×10-6~164.8×10-6,平均值为24.2×10-6;非成矿岩体Y含量为3.7×10-6~157.0×10-6,其平均值远大于成矿岩体,为32.4×10-6。

图2 文中使用的成矿岩体和非成矿岩体的28种全岩特征箱状图Fig. 2 Box illustrations of the 28 features of the mineralized and barren magmatic rocks used in this study
2.2 机器学习模型
文中采用随机森林(Random Forest,简称RF)对成矿岩体和非成矿岩体进行识别。采用随机森林的原因包括:①该算法训练过程简单,已被广泛用于解决地质学中的分类问题(李苍柏等,2020)。②预研究也证实,随机森林也是常见的机器学习算法中对识别成矿岩体和非成矿岩体全岩地球化学数据最有效的方法。随机森林算法是由Breiman提出的一种强大的集合学习方法,是一种结合了“Bagging”思想与随机特征选取技术的有监督机器学习算法(图3)。算法的基本思想是使用有放回的抽样方法(Booststrap)从原始训练样本中有放回地重复随机抽取N组训练样本,建立一个具有N棵决策树的随机森林模型(Breiman,2001)。具体来说,该算法首先利用bootstrap抽样从原始训练集抽取k个样本,每个样本的样本容量都与原始训练集一样。然后,对这k个样本分别建立k个决策树模型,从而得到k种分类的结果。最后,根据k种分类结果再对每个记录结果进行投票表决决定其最终分类。大量的理论和实证研究都表明随机森林模型具有很高的预测准确率,对异常值和噪声具有很好的容忍度,且不容易出现过拟合,被广泛应用于成矿预测(李慧,2022)、岩体类型识别(王子烨,2020)等。随机森林模型具有以下常用的超参数:分类器的个数n_estimators(即树的数量)、决策树选择的最大特征数目max_features、决策树的最大深度max_depth(温博文等,2018),不同的超参数组合对模型分类性能具有不同的影响(刘晓生等,2019;袁颖等,2019)。为获得模型最优的分类性能,笔者使用网格搜索(grid search)对模型进行进行参数优化。对于成矿岩体与非成矿岩体数据库当n_estimators值为91,max_features值为14,max_depth值为11时,模型获得最高准确率。
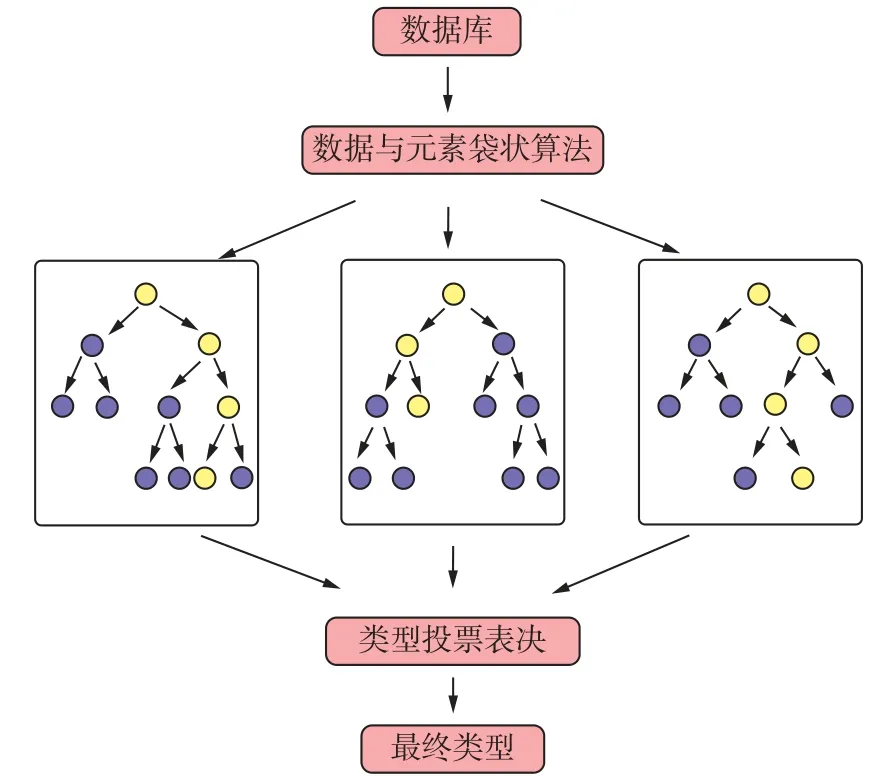
图3 随机森林模型原理图Fig. 3 Random Forest model diagram
2.3 模型训练与评价
在使用随机森林模型对数据库进行训练前,首先将数据库中582条数据以8∶2的比例随机划分为训练集与测试集。且为消除量纲和数量级的影响,同时降低模型训练时长,笔者使用Standard Scale数据标准化方法对数据库中的数据进行特征缩放,使数据库中的数据变换到均值为0、标准差为1的范围。此外,考虑到成矿岩体与非成矿岩体的数据数量具有一定的不平衡现象(比例约为3∶2),而数据不平衡会影响模型训练结果(Kotsiantis et al.,2006;Chawla,2009)。因此,文中采用过采样方法(SMOTE)使数据库达到平衡后再进行机器学习训练。此外,笔者模型训练过程中对训练集数据还进行了五倍交叉验证,目的是减少由于单一训练集可能产生的高偏差。使用参数优化后的随机森林模型对测试集中的数据进行判别,获得随机森林模型的最终分类表现得分。
在文中采用准确率与受试者特征曲线(Receiver Operating Characteristic Curve,简称ROC曲线)综合评价随机森林模型的分类性能。准确率表示预测结果中被预测是正确的比率。受试者特征曲线是对机器学习模型的分类性能进行评价的指标,是以假阳性率(False Positive Rate,简称FPR)为横坐标,真阳性率(True Positive Rate,简称TPR)为纵坐标,在[0,1]范围内画出曲线。其中,假阳性率是预测的正例中实际上为负的,在所有负例中的占比;真阳性率是预测的正例中实际上也为正的,在所有正例中的占比。假阳性率越低、真阳性率越高,模型分类性能越好。AUC值(Area Under Curve,曲线下的面积)指前文提到的ROC曲线与坐标轴围成的面积。AUC值能够量化反映分类模型的性能,取值范围为[0,1],并且越接近1时,模型分类效果越好(潘北斗等,2022)。当AUC值在0.5~0.7时,分类模型具有较低的准确性;AUC值在0.7~0.9时,分类模型有一定的准确性;AUC值在0.9以上时,分类模型有较高的准确性(Lv et al.,2011)。
式中:TP(True Positive),即实际为正例且被划分为正例的样本数;FN(False Negative),即实际为正例但被划分为负例的样本数;FP(False Positive),即实际为负例但被划分为正例的样本数;TN(True Negative),即实际为负例且被划分为负例的样本数。
3 研究结果
使用训练好的随机森林模型对测试集中成矿岩体与非成矿岩体进行预测,其结果见表3和图4。总的来说,模型的分类准确率较高,为0.90,证明文中训练得到的随机森林模型能够有效地识别祁漫塔格成矿带成矿岩体和非成矿岩体。此外,文中训练得到的模型在识别成矿岩体时的准确率为0.84,而在识别非成矿岩体时的准确率则高达0.94(表3)。这表明,该模型在预测成矿岩体时的表现略低于在预测非成矿岩体时的表现。根据ROC曲线,也可以获得类似的结果。AUC值为0.93,大于0.90,说明模型在预测成矿岩体和非成矿岩体时的准确率高。

表3 随机森林模型分类结果表Tab. 3 Classification results of Random Forest model

图4 训练的随机森林模型对测试集的评价图Fig. 4 Classification result for the test set using the trained of Random Forest model
4 讨论
4.1 机器学习模型表现
机器学习作为人工智能的一个子集,其目标是利用计算机模拟或实现人类的学习行为,以获取新的知识或技能(Jordan et al.,2015;Bergen et al.,2019)。与传统方法相比,机器学习优势显著:①机器学习更加注重从数据中提取新知识,因此机器学习模型的训练和使用对先验知识的依赖大幅降低(Lin et al.,2020;Wang et al.,2021)。②自动获得输入-输出之间的规律,几乎不需人工干预,这样即节省了大量的专家手工标定时间,同时避免了人为因素所引入的误差(Petrelli et al.,2016)。③在保证准确性的前提下,大大提高了分析效率,因此在处理、分析海量数据时更具(Zhong et al.,2023)优势。④与传统分类方法仅能关注少数几个特征不同(如根据二元图解),用于机器学习模型训练的特征数量、种类不受限,因此能够更充分的挖掘数据背后的复杂关系(Zhong et al.,2023)。近些年,针对斑岩-矽卡岩矿床成矿岩体的研究呈爆发性增长,积累了丰富的地球化学资料,这为从大数据角度开展成矿岩浆识别方法研究提供了可能。最近,一些学者也在该领域做出了一些有益尝试。Nathwani等(2022)利用汇编的全球斑岩铜矿床成矿岩体和非成矿岩体的全岩主量和微量元素数据,提出了基于全岩成分的成矿岩浆机器学习识别方法;Zhou等(2022)和Zou等(2022)则通过汇编全球斑岩铜矿床成矿岩体和非成矿岩体的锆石微量元素数据,建立了基于锆石成分数据区分岩体成矿能力的机器学习分类器;利用秘鲁Quellaveco斑岩铜矿区的锆石阴极发光(CL)图像,Nathwani等(2023)提出了基于锆石形态特征识别成矿岩体的机器学习方法。这些研究开创了基于人工智能技术开展岩体成矿潜力研究的先河,为建立斑岩铜矿床地球化学找矿勘查新方法、从更深层次窥探斑岩铜矿床成因机制提供了新的思路。文中用于机器学习训练的成矿岩体数据来自多种矿床类型:除斑岩铜矿床外,还包含斑岩钼矿、斑岩铜矿、矽卡岩铜铅锌矿床和矽卡岩铁矿床。文中获得的模型准确率与AUC值,2个模型性能评价指标均不低于0.90,表明机器学习模型不但对识别斑岩铜矿床成矿岩体有效,对识别其他斑岩-矽卡岩矿床的成矿岩体也同样表现优异。为了进一步显示机器学习方法在区分成矿岩体和非成矿岩体时的优势,图5展示了传统研究广泛使用的全岩Yb-La/Yb和Y-Sr/Y图解在祁漫塔格地区的表现情况。可以看出,来自祁漫塔格地区的成矿岩体数据和非成矿岩体数据在2个图解上高度重合,显示出至少对于祁漫塔格地区斑岩-矽卡岩多金属矿床,传统的地球化学方法难以有效区分它们的成矿岩体和非成矿岩体。

图5 祁漫塔格地区成矿岩体和非成矿岩体全岩密度图解Fig. 5 Whole-rock density diagrams for the mineralized and barren rocks from the Qimantagh metallogenic belt
由于测试集中的花岗岩数据可能与训练集中的部分数据来源于同一地区,因此基于测试集得到的模型准确率存在高估的可能,无法真实地反映分类模型的好坏。为此,笔者选取了36条新数据用于外部独立验证(图6),包括19条成矿岩体全岩数据(Guo et al.,2022;Xu et al.,2023)、17条非成矿岩体全岩数据(Ren et al.,2023)。这些全岩数据来自祁漫塔格周边地区,因此均没有出现在训练数据库中。运用文中获得的随机森林模型对这些花岗岩数据进行判别,结果显示分类准确率为0.92。其中,对成矿岩体分类准确率为0.90(图6a),对非成矿岩体分类准确率为0.94(图6b)。结果证明,文中提出的随机森林模型对识别东昆仑祁漫塔格成矿带及周边地区的成矿花岗岩体和非成矿花岗岩体十分有效。为便于研究人员使用,文中训练得到的随机森林模型代码已经上传至https://github.com/ShihuaZhong/2023-Qimantagh-RF-whole-rock-classifier。
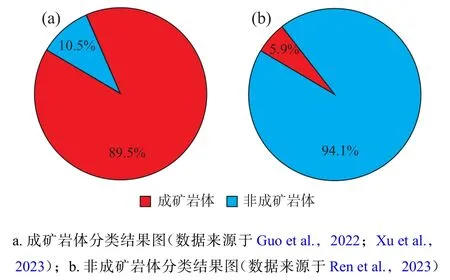
图6 外部独立验证数据集的分类结果图Fig. 6 Plot of classification results for external independent validation dataset
4.2 模型应用前提和展望
综上所述,文中训练的随机森林模型在识别祁漫塔格成矿带及周边地区的成矿岩体和非成矿岩体时,具有较高的准确率。此外,与传统方法相比,机器学习模型也可极大提高找矿效率,节省人力和物理成本。因此,将文中训练的模型用于该地区找矿勘查,将具有广阔的应用前景。不过,为获得真实可靠的预测结果,在运用文中模型评估岩体成矿潜力时需要注意其应用前提。
(1)文中是基于祁漫塔格成矿带的成矿岩体和非成矿岩体数据训练得到的机器学习模型,因此该模型主要适用于祁漫塔格成矿带及其周边地区,而将该模型应用于其他地区时需谨慎。同时,用于训练的数据库也仅包含了来自该地区斑岩铜矿、斑岩钼矿、矽卡岩铜铅锌矿床以及矽卡岩铁矿床的成矿岩体数据,因此该模型无法准确识别祁漫塔格成矿带其他矿床(如矽卡岩钨锡矿床、矽卡岩铅锌矿床)的成矿岩体。
(2)全岩地球化学成分极易受到后期热液蚀变的影响,会对预测结果产生影响。对斑岩成矿系统,热液蚀变通常发育在岩体周边甚至内部,导致许多成矿岩体的成分因受热液事件的改造,已经不能代表其原始成矿信息。这可能可以解释为何文中得到的机器学习模型在预测成矿岩体时的准确率低于非成矿岩体。因此,为提高预测准确率,用于成矿潜力评价的花岗岩体应该尽可能新鲜。
(3)考虑到全岩成分易受其他因素干扰,未来可探索利用锆石、磷灰石等岩浆副矿物成分取代全岩成分或者综合使用副矿物和全岩成分,开展机器学习模型训练。这不仅是由于锆石、磷灰石等副矿物在花岗岩类岩石中广泛存在,更重要的原因是相比于全岩成分,副矿物(特别是锆石)成分稳定,形成后几乎不受后期热液活动的影响。可以预见,综合锆石等副矿物微量元素特征得到的机器学习模型将能够进一步提高成矿岩体和非成矿岩体预测的准确性。相较于花岗岩中常见的锆石、磷灰石等副矿物,花岗岩在固结成岩之后全岩的地球化学成分易受到热液活动与变质作用的影响,地球化学成分发生较大的改变,已不能完全记录花岗岩成矿信息。因此,为建立更加准确的成矿岩体与非成矿岩体的机器学习模型,应尝试使用副矿物地球化学成分与全岩地球化学成分相结合的地球化学数据库,共同对成矿岩体与非成矿岩体进行判别。
5 结论
(1)文中汇编了来自祁漫塔格成矿带成矿岩体和非成矿岩体的28种常见全岩地球化学特征,结合随机森林算法,提出了一个用于识别该地区斑岩-矽卡岩型多金属矿床成矿岩体和非成矿岩体的机器学习分类模型。
(2)模型评价指标显示,文中训练得到的机器学习模型的准确率为0.90,表明该模型能够有效识别来自祁漫塔格(及周边)地区花岗岩的成矿潜力。与传统成矿预测方法相比,该方法能够大大降低成矿预测的人力和物力成本,提高找矿效率。
(3)该模型仅适用于预测花岗岩类能否形成斑岩铜矿、斑岩钼矿、矽卡岩铜铅锌矿床或矽卡岩铁矿床;同时,将该模型应用于祁漫塔格以外地区时也需谨慎。此外,考虑到花岗岩全岩成分易受热液蚀变等因素干扰,为提高成矿预测准确率,应尽可能选择新鲜花岗岩用于预测。
