基于多源异构信息融合的配电工程数据分析及应用研究
2023-11-21董君马云飞张婷婷左琪刚
董君,马云飞,张婷婷,左琪刚
(国网天水供电公司,甘肃天水 741000)
随着近年来配电网投资的增加与配电工程数据的快速增长,数据的分析及应用也面临着严峻挑战[1-2]。而数据挖掘(Data Mining,DM)、数据融合(Data Fusion)与大数据分析(Big Data Analysis,BDA)等新一代人工智能技术(Artificial Intelligence,AI)的更新,给大规模数据的处理及应用带来了新的解决方案。但配电工程数据在生产、运营与管理方面仍存在多源异构问题,这也导致数据的分析与推广存在瓶颈[3-4]。针对上述问题,国内学者开展了多方面的研究,通过结合数据提取规则解决多源异构数据的融合问题,以实现不同数据库间的访问及共享。文献[5]通过对比结构化与非结构化数据的差异,提出适用于海量数据的存储模式,进而解决配电数据孤岛问题。文献[6]对不同维度的数据均进行了分析,且采用深度学习(Deep Learning,DL)进行特征提取,从而提高了数据分类的精度。国外学者的研究则较为超前,初期便提出将数据融合框架应用于矿山、铁路等工程场景,但该框架无法适用于不同维度的数据处理与分析之中[7-8]。由于配电工程数据呈现多维度、数据量广等特征,故需采用精度更高的算法进行分析与处理。因此,该文采用多源异构数据融合技术对配电工程数据的分析展开研究。
1 算法设计
1.1 正交基前向神经网络
数据融合算法基于反向传播(Back Propagation,BP)网络进行样本数据的训练操作。但由于极值点的确定存在偶然性,因此其易产生数据过拟合问题[9-10]。而多源异构数据融合算法采用正交基前向神经网络来确定隐含层的数目,故可提高配电工程数据分析的精度与效率。
传统神经网络算法的激励函数(Activation Function)为多项式函数,其可通过巧妙设定权阈值的方式缩短运行时间。但该种处理方式占据了较多内存,因此对硬件设备的处理效率也会有更高要求。而正交基前向神经网络处理算法将单个任务分解为多个子任务,且其节点与所对应的模块执行同一步骤,并确保了多个数据块可同时发送至Reduce节点,进而提高了CPU 的处理效率。
在计算过程中,正交基前向神经网络加入了多源异构数据融合算法。通过将配电工程数据进行分布式处理,以提高处理器的运行效率。该算法的并行处理流程,如图1 所示。

图1 多源异构数据融合并行处理流程图
1.2 多源异构数据融合
配电工程数据种类繁多,常见的有配电网工程造价数据、架空线路工程数据、电缆线路工程数据等。通过收集样本数据来对上述信息进行横向与纵向地对比与分析,便可得到分析结果。多源异构数据融合即是对数据进行分类,并从多个角度完成融合分析,从而得到相应的结果[11]。收集到的配电工程数据储存于Hadoop 平台,该平台可以储存海量数据[12],再以整定值为目标实现数据的融合处理。数据融合处理步骤如图2 所示。

图2 数据融合处理
数据融合处理的具体步骤如下:
1)将采集到的配电工程数据作离散化处理,包括配电网工程造价数据、架空线路工程数据与电缆线路工程数据等。其中,配电设备的状态用0-1 变量表示。
2)将上述离散化的数据进行矩阵化处理,用Ni表示时刻i采集到的配电工程数据集合的数据矩阵为:
其中,t为与时间相关的数据参数。因此,P个配电工程数据矩阵M可表示为:
3)采用正交基前向神经网络对配电工程数据进行训练、预测及分析。
2 配电工程数据分析及应用
2.1 配电工程数据预处理
常见的配电工程数据源有:配电网工程造价数据、架空线路工程数据、电缆线路工程数据等。这些数据都存在着多来源、多维度、冗余等特征,因此需要对所收集到的样本数据做预处理,才能进行数据分析及应用。对于收集到的配电工程异构数据,分析其数据间的关联性,且输入预处理后的结果,即可作为数据训练与迭代的信号源。当采集到配电网工程的各类数据时,需对上述数据进行降噪处理,同时剔除异常数据,从而提高数据的准确率。假设数据总样本数为N,其中子样本数据集A、B、C与关联数据集Y分别可表示为:
则样本数据i可表示为:
2.2 稀疏自编码器数据融合
由于配电工程数据分类不明确,因此为有效识别工程数据的种类,采用了无监督学习、聚类分析特征的稀疏自编码数据融合算法。该算法除了可以还原数据本质、体现无监督特征之外,还能主动提取样本数据信息,并根据数据特征将其分为不同的种类,且最终得到数据融合结果。此外与传统数据融合算法不同,该算法的编码器在损失函数中增加了稀疏约束(Sparsity Constraint)[13],以限制数据的范围,并增加配网工程数据的特征提取能力。稀疏自编码器数据融合算法的流程,如图3 所示[14-15]。

图3 稀疏自编码器数据融合算法流程
从图中可看出,该算法的数据分析有三个关键点:1)在对配电工程数据重构的过程中采用稀疏自编码器(Sparse AutoEncoder,SAE);2)采用均方损失函数以及Adam 数据优化器优化处理配电工程数据,并初始化网络参数;3)通过K-medoid 算法设置数据中心点,再进行反复迭代以找到数据分类的基数。
2.3 边缘数据自适应增强
当采集到配电工程数据之后,为确保整体与局部数据的一致性及协调性,仍需对边缘数据进行自适应增强处理[16]。首先,定义数据一致性为:
式中,gout(x,y)、gave(x,y)表示配电工程数据在直角坐标系中的输出值与数据局部平均值。
为提高数据的真实性,进一步定义数据的边缘值为:
随后再进行数据还原操作,所采用的还原公式为:
其中,Pin、Pout分别表示配电工程数据的输入与输出分量;而β(x,y)则表示还原系数,其可通过下式计算得到:
式中,δ为偏置量。综上,经过数据还原及数据一致性计算,通过处理局部与整体数据的协调性,可对边缘数据进行自适应增强处理。
3 算例分析
该算例分析的基础数据主要采集于某地区2020年1 月1 日—2020 年12 月31 日竣工投产的电力公司,新建或整体改造10 kV 及以下配电网工程(包括配电站房、配电变压器、架空线路、电缆工程)概算和决算的数据。其中,配电站房类工程完全覆盖;架空线路工程10 kV 路径长度不小于2 km,0.4 kV 路径长度不小于1 km;而电缆线路工程的路径长度则为0.5 km 以上。该地区2020 年共收集配电工程、架空线路工程及电缆线路工程样本1 147 项,总计静态投资32 650.40 万元。其中配电工程样本分类统计情况如表1 所示。
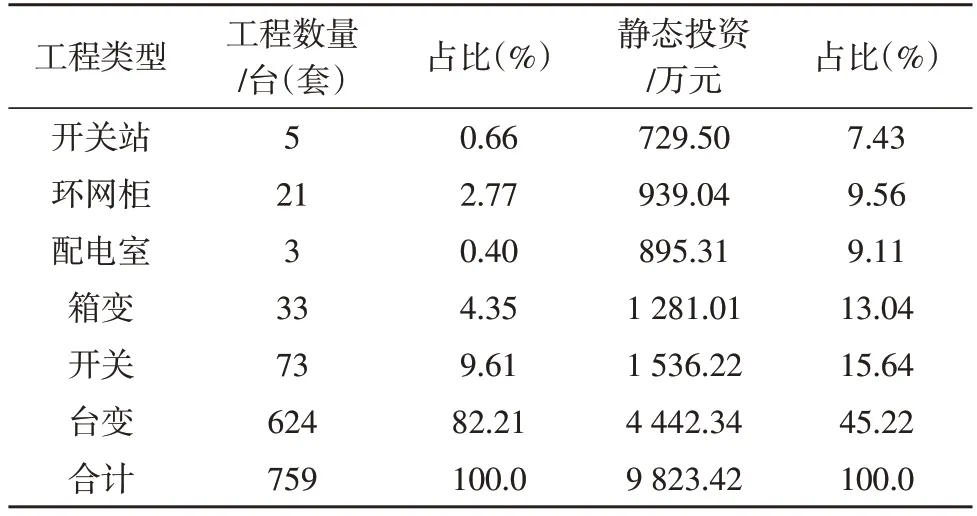
表1 配电工程样本分类统计情况
配网工程数据分析分别从工程样本情况、造价水平、分项费用、不同项目管理单位造价水平等多源异构数据融合开展分析研究。收集该地区2020 年农网改造升级工程及高损台区治理工程中完成财务决算的项目,并开展投资结余率研究,以进一步掌握配电网工程造价的规律。
2020 年配电变台工程样本总计624 项,共667 台(套),静态投资4 442.34 万元。技术方案分为100、200、400 kVA 及100 kVA 以下小成套共四种类型。配电变台工程典型技术方案的分布具体如表2所示。
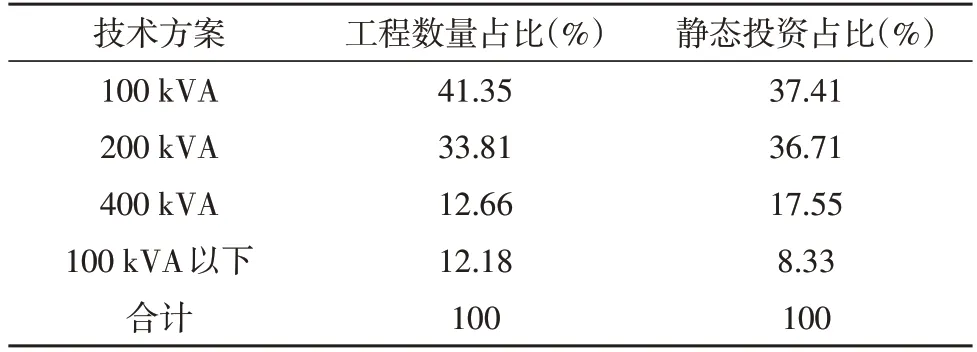
表2 配电变台工程典型技术方案
根据图4 所示的配电网工程总体结余率散点分布情况,将结余率划分为四个区间,并统计配电工程、架空线路工程与电缆线路工程结余情况。由图可知,配电网工程结余率主要分布在0%~10%的范围内,总体占比达到69.35%,其次是10%~20%范围内,占比达到23.26%,而20%以上的结余率工程占比为7.08%。

图4 配电网工程总体结余率散点分布
进一步地,使用四种方法对该地区的配电网工程数据进行分析。计算不同方法的标准误差与绝对误差,统计结果如表3 所示。从表中可看出,当采用本方法对配网数据进行分析时,标准误差与绝对误差均有所降低,且更能反映真实值。原因在于,该方法采用了正交多项式作为激励函数来实现不同类型数据的融合。因此,其更能反映原始数据的特征。

表3 四种方法误差对比
为进一步分析该文方法在不同数据量时的计算效率,分别设置了四组实验,分析当配网数据集在5、10、15、20 GB 情形下的处理器运行时间。两种方法的运行时间,如表4 所示。从表中可看出,随着配网工程数据量的增大,两种方法所用时长均在增加。但在数据量相同时,所述方法用时更短。由此证明了该文方法具有高效的运行速度,故能适用于大容量配网工程数据的场景。

表4 两种方法消耗时间对比
4 结束语
针对配电工程数据量较大、维度多、分析与处理困难等问题,该文开展了基于多源异构数据融合的配电工程数据分析方法研究。在数据特征提取时,首先利用正交基前向神经网络算法有效提高了特征提取精度;然后,采用稀疏自编码数据融合算法来识别数据种类;最终再使用均方损失函数及Adam 数据优化器优化处理配电工程数据,并对边缘数据进行自适应增强处理。算例分析表明,该方法可从不同的维度体现配电工程数据所反映的问题,能更优地体现数据的真实值,且运行速度也较快。未来将继续推进智能算法在数据提取过程中应用的研究,以进一步提升数据分析的精度。
