非局部稀疏关注的YOLOv4优化算法
2023-11-20毛一新侯泽铭杨朝源王名茂
闵 锋,毛一新,侯泽铭,杨朝源,王名茂
武汉工程大学 智能机器人湖北省重点实验室,武汉 430205
目标检测是计算机视觉领域中的一个重要研究方向,作为图像理解和计算机视觉的基石,目标检测是解决分割、场景理解、目标跟踪、图像描述和事件检测等更高层次视觉任务的基础。近年来,随着计算机硬件资源和深度卷积算法在图像分类任务中取得的突破性进展,基于深度卷积的目标检测算法也逐渐替代了传统的目标检测算法,在精度和性能方面取得了显著成果。根据目前各算法在目标检测公共数据集MSCOCO[1]上表现,目标检测在性能上仍然存在较大提升空间。
目前被广泛使用的两个检测算法是以R-CNN[2](region-based CNN)系列为代表的基于候选框的两阶段深度学习算法和以YOLO(you only look once)系列为代表的基于回归的单阶段深度学习目标检测算法。但R-CNN的检测速度与YOLO系列算法和单点多盒检测器(single shot multibox detector,SSD)等典型的单阶段目标检测算法具有较大差距。文献[3]提出了第一个单阶段目标检测算法YOLO,采用全连接层提取检测结果。文献[4-5]在YOLOv1的基础上继续改进,又提出了YOLOv2和YOLOv3检测算法,其中YOLOv2进行了多种尝试,使用了批标准化(batch normalization,BN)技术,引入了锚框机制;YOLOv3采用darknet-53作为骨干网络,并且使用了3 种不同大小的锚框,在逻辑分类器中使用sigmoid 函数把输出约束在0~1 之间,使得YOLOv3 拥有更快的推理速度。文献[6]在传统的YOLO基础上,加入了一些实用的技巧,提出了YOLOv4算法,YOLOv4是一个高性能、通用的目标检测模型,能一次性完成目标定位与目标分类两个任务,因此选择YOLOv4 作为目标检测的基本框架是可行的。但目前YOLOv4-CSPdarknet53 算法对一些场景下目标的独特性检测在检测速度和检测精度上仍然存在不足,就需要对YOLOv4的网络结构进行相应的调整和改进。
目标检测中的经典网络如Fast R-CNN[7]、SPPNet[8]和Faster R-CNN[9]等大多只是利用了深度神经网络的末层来进行预测。然而由于特征提取过程中的空间和细节特征信息的丢失,难以在深层特征图中检测小目标。在深度神经网络中,浅层的感受野更小,语义信息弱,上下文信息缺乏,但是可以获得更多空间和细节特征信息,在提取深度语义信息的过程中,损失了较多的空间位置信息表征,致使在部分目标的效果并不好。从这一思路出发,Liu 等[10]提出一种多尺度目标检测算法SSD(single shot multibox detector),利用较浅层的特征图来检测较小的目标,利用较深层的特征图来检测较大的目标,如图1(a)所示。李成豪等[11]提出一种基于多尺度感受野融合的算法,有效提升了小目标的特征提取能力。刘建政等[12]通过浅层的特征映射信息进行融合的思想来提高对算法小目标的检测性能,提高了网络的目标检测精度。Kong等[13]提出了一种有效的多尺度融合网络,即HyperNet,通过综合浅层的高分辨率特征和深层的语义特征以及中间层特征的信息显著提高了召回率,进而提高了目标检测的性能(见图1(b))。这些方法能有效利用不同尺度的信息,是提升目标特征表达的一种有效手段。但是,不同尺度之间存在大量重复计算,对于内存和计算成本的开销较大。为节省计算资源并获得更好的特征融合效果,文献[14]结合单一特征映射、金字塔特征层次和综合特征的优点,提出了特征金字塔FPN(feature pyramid network)。FPN 是目前最流行的多尺度网络,它引入了一种自底向上、自顶向下的网络结构,通过将相邻层的特征融合以达到特征增强的目的(见图1(c))。向华桥等[15]设计了扁平的Flat-FPN特征提取网络来提高强化底层特征,有效提高目标检测精度,Li 等[16]通过引入多支路空洞卷积,减少下采样过程中的特征丢失并通过感兴趣区域的尺度融合来增强目标特征表达。赵鹏飞等[17]考虑到浅层卷积层缺乏语义信息等往往导致了对于目标检测的效果不佳,为提高小目标检测的精确性与鲁棒性,提出了分组残差结构用于改善浅层语义特征信息不足的问题。
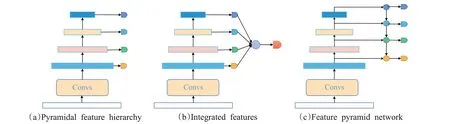
图1 三种多尺度学习方式Fig.1 Three ways of multi-scale learning
窦允冲等[18]通过增加特征金字塔到主干网络的反馈机制,提高了网络分类和定位的有效性。总体来说,上述方法在强化语义特征提取都有较好的表现,但传统目标检测网络在提取深度语义信息下采样至低分辨率过程中,已经造成了大量目标的空间位置信息缺失,即使在从低分辨率流重新恢复至高分辨流,该过程仍为不可逆过程。这使得输入特征图即使经过一系列特征增强的方案,仍会出现较小目标的检测效果差的问题。
与传统的目标检测算法从由高到低分辨率网络产生的低分辨率表示恢复高分辨率的过程不同,Sun 等[19]考虑到空间位置表征丢失对人体姿态检测的影响,提出了人体姿态估计的高分辨率表示学习网络HRnet,并刷新了MSCOCO的关键点检测、姿态估计、多人姿态估计这三项任务的记录。受HRnet启发,本文认为高分辨率空间位置表征保持对于较小目标检测同样具有重要意义,并对其进行了深度改进,本文使用CrModule模块替代了原HRnet中用于同分辨率交互的卷积核大小为3×3的2D卷积,降低深层网络的特征冗余性,减少网络计算量;提出了基于稀疏表达的特征超分重构与高分辨率表示相结合的网络结构,增强较小目标判别性特征,降低较小目标的特征学习难度,提升网络目标检测性能;并将多尺度融合后的有效特征层使用深度可分离卷积下采样得到的多分辨率的三个有效特征层取代HRnet 的单个特征层输出,加强语义表征提取。
在上述设想下,本文提出了高分辨率保持与特征超分重构网络CrHRnet。
1 CrHRnet-YOLOv4网络
CrHRnet-YOLOv4 结构框架如图2 所示,该网络架构中CrHRnet主干网可提取4个具有强语义信息不同分辨率流并对其进行多尺度特征融合,输出高分辨率特征层,并通过深度可分离卷积提取3个具有强语义信息和空间位置表征的特征层,接着输入到PANet和SPP结构中进行有效特征增强,其中SPP结构是用以提高图像的尺度不变性并减少过拟合,PANet使用自适应特征池化和全连接融合2 个模块,保证特征的完整性和多样性,并通过全连接融合得到更加准确的预测,最终目标检测结果用YOLO Head输出。

图2 CrHRnet-YOLOv4网络结构示意图Fig.2 Schematic diagram of CrHRnet-YOLOv4 network structure
1.1 CrHRnet主干特征提取网络
CrHRnet 网络结构如图3 所示。以输入图片大小416×416×3为例,在进入特征提取主干网络之前会有一个通道数匹配的阶段(Stem),将图像输入到Stem 中,Stem由两个步长为3×3的卷积组成,步长为2,在完成通道数匹配后输入到Backbone中成为网络首个阶段,图3中每一种尺度的特征流称之为一个Stage,每个特征流中只含同分辨率交互的部分称之为一个Block(仅Stage1 中的每个Block 含一个NLSA 模块)。Backbone主要由几个部分组成:(1)基于稀疏表达的非局部特征超分重构;(2)并行多分辨率Block特征提取;(3)重复多分辨率融合。

图3 CrHRnet特征提取网络结构Fig.3 CrHRnet feature extraction network structure
CrHRnet与ResNet[20]、VGGNet[21]等传统网络模型将输入图像编码由低分辨率表示恢复高分辨率表示不同,在整个过程中保持高分辨率表示。该网络具有三个关键特征:(1)并行连接高分辨率到低分辨率的卷积数据流,CrModule 和残差模块(Residual-Block)处理同分辨率模块的特征提取;(2)使用NLSA[22]非局部稀疏注意对特征图中较小目标实现特征超分辨率重构,提高小目标特征可学习性,在不同分辨率之间重复交换信息,加强网络特征提取能力,使所产生的特征表示在语义上更丰富,空间位置信息表征更准确;(3)重复多分辨率融合,多层有效特征层输出。
1.2 基于稀疏表达的非局部特征超分重构
目标检测领域中,公开数据集中较小目标由本身定义导致的RGB信息过少,因而包含的判别性特征不足,造成目标检测算法检测精度难以提升,且传统网络中高分辨率特征层在下采样至低分辨率的语义表征学习过程中,损失了大量的空间位置信息,即使将图像编码由低分辨率表示恢复至高分辨率,这种位置信息丢失过程仍为不可逆的,同样也会造成较小目标检测精度下降。为降低小目标检测对网络结构检测精度的影响,提出了NLSA与高分辨率表示相结合的网络结构CrHRnet。
NLSA 算法同时兼顾了稀疏表达和非局部操作的优点,该算法特征重构过程具有良好的健壮性、高效性和抗噪性,在Urban100等数据集上的PSNR(peak signalto-noise ratio)等指标达到了目前最先进水平。NLSA在CrHRnet 算法中主要是对高分辨率特征图中的特征块进行超分重建,提高较小物体的特征表示,使之与大物体特征类似,提高网络对小目标的检测性能。NLSA能在全局范围内确定特征关联最大的位置,而不关注不相关的区域,从而实现了强大而高效的全局建模操作。
特征层的非局部注意(non-local attention,NLA)的深层网络感受野是全局的,NLA 通常是汇总所有位置的信息来增强输入特征图,其原理表示如式(1)所示:
其中,xi、xj、xj^分别表示特征层X的第i、j、j^ 个像素级特征,f( )·,· 是高斯投影核函数,用于度量两个像素特征的相关性,g()· 是一个特征变换函数,利用得到的权重对原始图进行映射,yi为目标函数需求结果。

若需式(2)中λi中的元素应保持稀疏,且应纳入全局中最相关元素,NLSA 采用球形局部敏感哈希(Spherical-LSH)算法来实现了上述目标。LSH 函数是一类特殊的哈希函数,可有效保留原始数据之间的距离属性;即假设现有a1、a2、a3三点,其中a1、a2相邻,a1、a3相隔较远,若Hash(a1)和Hash(a2)碰撞概率要比Hash(a1) 和Hash(a3) 大得多,则此Hash() 属于LSH 函数。本文采用的Spherical-LSH算法思想是利用LSH函数将张量投影到超球体中,如图4 所示,球体中多面体每个顶点可以视为一个哈希桶,通过数量积运算选择最近顶点作为其Hash code,假设图4中x1与x2具有强相关性,与x3不具备相关性,由于LSH算法可有效保留原始特征的空间距离属性,则x1与x2会被分配在同一个哈希桶中,而与x3分配在不同的哈希桶中。

图4 Spherical-LSH算法思想示意图Fig.4 Schematic diagram of Spherical-LSH algorithm
对特征向量实现哈希桶分配,其实际应用操作原理如式(3)所示:


1.3 并行的多分辨率处理
CrHRnet 从Stem 的高分辨率输入流开始,作为Stage1,逐步将高分辨率与低分辨率的流相加,形成新的级,并将多分辨率流并行连接。考虑到特征层学习过程本质是卷积和多尺度残差与融合过程,本文提出级联残差结构(cascaded residual module)替代普通卷积提取深度语义信息。较原HRnet 网络,CrHRnet 采用CrModule结构取代原HRnet卷积核大小为3×3的2D卷积用于同分辨率的语义信息提取;降低网络特征提取的冗余性,减少模型的计算量。
以输入和输出的特征图尺寸均为104×104×128(H×W×C)为例,单层3×3普通2D卷积合计乘法运算次数为15.9×108次,单层CrModule合计乘法运算次数为0.66×108次,仅为普通卷积运算量的4.1%。大幅降低了高分辨率特征图的卷积运算量,实验结果表明,CrModule模块也具有良好的特征提取能力。CrModule(图5)共分为3个部分。

图5 CrModule结构示意图Fig.5 Structural diagram of CrModule
首先将Input 的特征图进行一个普通的1×1 卷积,这是一个少量卷积,例如正常使用m通道的卷积,这里就会得到m/4 通道数的输出层,这个1×1卷积的作用类似于特征整合,生成输入特征层的特征浓缩,接着再进行深度可分离卷积,这个深度可分离卷积是逐层卷积(如图5中ηi),最后将通道数拼接生成通道数为m/2 的单级特征层(如图5中的Part A部分),因此较普通卷积它的计算量更低。接着对Part A获取的特征层进行3×3普通2D卷积,生成通道数为m/4 的输出,并继续对其进行逐层卷积,形成新的级(如图5 中Part B 部分),将各级特征层拼接构建出具有丰富语义特征的残差块,最后将级联残差结构获得的特征浓缩与输入特征图残差连接生成新的同分辨率特征图(Part C)。实验表明,CrModule较普通卷积结构而言,计算量大幅减少,提高了算法的检测性能。
1.4 多尺度特征融合
对于不同分辨率大小的特征层融合方式如图6 所示,高分辨率特征层使用深度可分离卷积进行通道数匹配,同时低分辨率特征层通过上采样及特征融合形成新的高分辨率表征。

图6 多尺度特征融合原理图Fig.6 Multi-scale feature fusion schematic
融合模块的目标是通过多分辨率表示交换信息。它们之间的语义表征会进行多次交互,特征层在经过网络的每个Block模块后会进行多分辨率特征融合。可将该网络分为四个阶段,用Layer(s,f)来表示。用s作为不同阶段索引,f表示对应阶段的对应子流索引,其中其逻辑上结构如图7所示。

图7 CrHRnet逻辑结构图Fig.7 Logical structure diagram of CrHRnet
令首个阶段的s=1,f=1,则第s个阶段Layer(s,f)的通道数Channels(s,f) 、特征层输入分辨率大小InputSize(s,f)如公式(4)、公式(5)所示:
2 实验及结果分析
2.1 数据集
本文使用的实验数据集为PASCAL VOC[23]。VOC数据集是目标检测和分割常用数据集,其中包含4大类和20 个小类。很多优秀的计算机视觉模型比如分类、定位、检测、分割,动作识别等模型都是基于PASCAL VOC 挑战赛及其数据集上推出的。CrHRnet 性能测试选用VOC2007+VOC2012 的train+val 部分进行训练,使用VOC2007的test测试的评估方式。VOC2007 数据集的train+val 部分由5 011 张训练样本12 608 个目标数目组成,VOC2012的train+val中共有11 540张训练样本以及27 450 个目标数目,VOC2007-test 测试集中由4 952 张测试样本以及12 032 个待检测目标数目组成。训练集样本数量合计16 551张训练样本,共40 558个目标物体。
2.2 实验条件和评价指标
本实验使用的操作系统为Linux,处理器型号为Intel Core i5-10400F,显卡型号为NVIDIA GeForceRTX3060,采用NVIDIA CUDA 加速工具箱,优化器选择随机梯度下降(stochastic gradient descent,SGD)。实验参数设置最高学习率为0.01,最低学习率为0.000 1,训练Epoch 为1 000 次。为了评价网络的性能和证明目标检测网络的有效性,选取下列指标进行评价。
(1)查准率(Precision,P)和召回率(Recall,R)。查准率是指网络检测到的正样本数量占检测到的所有样本数量的比率;召回率指网络检测到的正样本数量占标记真实样本数量的比率。查准率和召回率的计算公式如式(6)所示:
其中,真样本(true positive,TP)表示检测到的目标类别与真实目标类别一致的样本;假样本(false positive,FP)为检测到的目标类别与真实目标类别不一致的样本;假负样本(false negative,FN)为真实目标存在但未被网络检测出来的样本。
(2)平均准确率(average precision,AP)和平均准确率均值(mean average precision,mAP)。一个理想的目标检测网络应该在召回率增长的同时,查准率在很高的水平,但现实情况是召回率的提高往往需要损失查准率的值,因此通常情况下采用查准率-召回率(precision recall,P-R)曲线来显示目标检测器在准确率和召回率之间的平衡。对每一个物体类别,该类别的平均准确率定义为P-R曲线下方的面积;平均准确率均值是所有类别的平均准确率的均值。AP 和mAP 的计算公式如式(7)所示:
其中,N表示所有类别的数量。
(3)帧率(frames per second,FPS)。帧率指目标检测网络每秒中能够检测的图片数量,用该指标评价目标检测网络的检测速度。
2.3 实验结果和分析
为验证CrHRnet 网络改进的有效性,本文根据2.2节的实验参数设置对2.1 节中介绍的数据集进行训练。训练集均使用VOC07+12,在测试集使用VOC-Test07的条件下对CrHRnet 以及HRnet 作为YOLOv4 主干特征提取网络测试其网络性能,共进行了7 组消融实验,实验结果如表1所示,表中“√”表示使用了对应方法,“×”表示不使用该方法;N 为HRnet 算法中的Normal-Block(2D卷积,卷积核大小为3)、R表示Residual-Block,是将N 模块输出的特征层与原始输入特征层残差相加的结构;C表示CrModule模块,表中Block1-N表示上述网络结构的同分辨率提取Block1 块使用的方法为Normal-Block,其他选项同理,实验的FPS测试均在GTX1650设备上进行。

表1 基于YOLOv4架构下的消融实验Table 1 Ablation experiment based on YOLOv4 framework
通过对比表1中1、2组,3、4组以及6、7组的实验结果,添加NLSA 模块在相同网络结构下测试mAP 分别提升了1.26、1.62、1.28 个百分点,NLSA 模块有效提升了算法目标检测精度,实验结果分析证实了NLSA算法的有效性,基于稀疏表达的特征超分重构方法有利于提升目标判别性特征的可学习性,可有效提高算法检测精度。将1、3 组,2、4 组以及4、7 组的实验所测得的mAP以及FPS结果进行对比易知,CrModule模块有利于提升网络的检测速度,且通过与浅层残差结构线性组合,在处理深层次的语义信息过程中,能够减少特征提取的冗余性,提升网络的泛化性能和目标检测精度。CrHRnet将稀疏表达的非局部注意特征超分重构算法与残差级联网络融合,有效提升了网络的检测速度和检测精度,网络测试mAP达到了90.82%,优于HRnet的检测精度。
为更加有效评估CrHRnet-YOLOv4 算法的检测效果,本文通过实验对YOLOv4架构下不同主干特征提取网络模型进行了评估(mobilenet_v1[24]、mobilenet_v2[25]、mobilenet_v3[26]、VGGNet等),在训练集均使用VOC07+12 训练的条件下,使用VOC-Test07 的测试性能对比实验结果如表2所示。表2的实验结果分析可得,CrHRnet在VOC-Test07 上的测试mAP 高于YOLOv4 其他不同Backbone下的目标检测算法多个百分点不等。此外,还使用上述不同算法进行了单张图片的FPS 测试。测试结果显示,CrHRnet在具有良好的检测精度的同时也具有较好的检测速率,相较于原YOLOv4-CSPdarknet53提升了30%,实验表明,CrHRnet 在检测速度和检测精度有了较好的提升。

表2 YOLOv4架构下不同特征提取网络性能比较Table 2 Performance comparison of different feature extraction networks under YOLOv4 architecture
图8 为CrHRnet-YOLOv4 在VOC-Test07 实验测试后,统计出的各个类别的准确AP值大小,其中横坐标代表AP 值大小,纵坐标代表类别名称。为进一步验证本文算法的效果,本文将CrHRnet-YOLOv4算法与目标检测中常用的主流目标检测算法进行了对比实验,其检测结果对比如表3 所示。其中包括SSD、ResNet、Faster R-CNN、YOLOv5 等经典算法以及最新的HSD[27]、DETReg[28]、CoupleNet[29]、Cascade Eff-B7 NAS-FPN[30]算法,根据表3 所示,对比Faster R-CNN、YOLOv5_s、YOLOv5_m 等经典网络CrHRnet-YOLOv4 在平均准确率均值分别有12 个百分点、9.5 个百分点、3.4 个百分点的提升;与最新的优秀算法DETReg、NAS-FPN 对比,mAP 分别提升了5.3 个百分点和1.5 个百分点,实验检测结果表明,CrHRnet做为特征提取网络具有更强的健壮性、更好的泛化能力,更准确的目标检测精度。

图8 CrHRnet-YOLOv4在VOC-Test07的各类别的AP值Fig.8 AP values of each category tested by CrHRnet-YOLOv4 in VOC-Test07 dataset
图9为YOLOv5_s、YOLOv5_m、YOLOv4、CrHRnet-YOLOv4算法在VOC数据集中检测相同样例的检测效果对比图。

图9 多种检测算法在VOC数据集样例检测效果对比图Fig.9 Comparison of detection effects of various detection algorithms in sample detection of VOC dataset
3 总结与展望
本文提出了CrHRnet-YOLOv4的网络模型,用于处理视觉目标检测问题,通过实验验证,取得了较高的检测精度和较快的检测速度。网络模型算法在视觉目标检测问题上,该算法与现有的算法有几点根本区别。(1)连接高分辨率和低分辨率卷积使用的是并联而不是串联的方式;(2)在整个过程中保持高分辨率,而不是从低分辨率恢复高分辨率,避免了空间位置信息的缺失;(3)使用NLSA 实现特征块超分重构,提升目标判别性特征的可学习性;(4)同分辨率特征层使用CrModule和Residual-Block 线性组合替代普通卷积,提升算法检测性能。
高分辨率保持网络在人体姿态关键点检测以及目标检测均取得了不错的效果;但在训练低分辨率的数据集时,往往得不到较好的效果;经过分析可能是因为低分辨率图片的空间位置信息本身难以抓取和保持,在同分辨率特征层自身进行多次信息交互时,空间表征不够精确,使得待检测样本的空间位置信息错乱冗余,造成检测效果不佳的结果。超分辨率重构可能是一种最直接的、可解释的提升本网络目标检测性能的方法,但这一类研究仍存在较大的研究空间,如何将超分辨率重构中先进技术与目标检测技术深度结合是提升目标检测算法精度的一个可行研究思路。
