基于Autoformer AI架构的SD-OTN专线流量预测模型
2023-11-18骆益民中国联通广东分公司广东广州510627
骆益民(中国联通广东分公司,广东广州 510627)
1 概述
传统的OTN 专线在发现网络带宽越限时,技术上无法支持业务带宽快速调整,不能满足实时性突发需求,无法避免由此引起的业务丢包等。为提升大客户精品网络的竞争力,满足政企客户对时延、业务快速开通、带宽实时调整等专线业务的新需求,通过SDN化的OTN 网络[1]承载可以实现业务快速开通、业务快速发放、快速响应客户业务增减调整、时延动态监测等功能[2],从而满足客户多种需求,具有强大能力的SD-OTN为流量预测提供了很好的实际应用场景。
如何对流量进行精准预测,为用户提供更好的体验和解决方案成为运营商的研究热点之一。实际网络流量具有非线性、周期性、自相似性、突发性等特点,采用机器学习算法,对历史流量序列特征进行学习和训练,能更好适应流量历史特点,具有更高的准确性。如基于时域注意力机制Transformer[3]的专线流量预测模型,但其计算复杂度较高,难以发现更长范围的关系关联性。基于时域自相关机制的Autoformer[4]、informer[5]模型计算复杂度为线性logO(LlogL),但缺少对频域特征的关注。Fedformer[6]基于频域特征的学习捕捉时间序列的全局特性,实现了线性计算复杂度。
本文提出的流量预测模型采用多头注意力机制对时频域特征结合训练的Autoformer 架构,可同时学习时域和频域序列特征并进行两域各自相关机制融合预测,获得更高预测准确性。
2 SD-OTN流量监测分析
为了提高流量预测准确性,首先需要把握流量总体特点,才能选取适应性强的AI 预测算法。通过对413 条SD-OTN 专线电路进行流量监测,涉及通信、邮政、银行、政府单位、制造业等行业,分析得出SD-OTN专线流量的时间分布特点。图1所示为具有明显客户行为特征的电路流量样本。
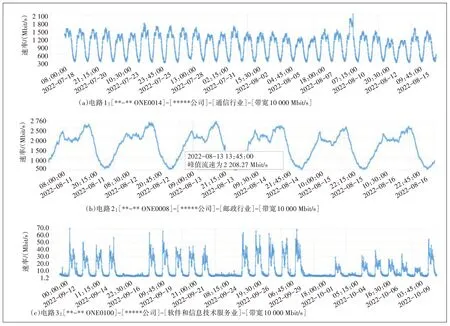
图1 3条SD-OTN专线电路流量趋势
从图1 可以看出,**-** ONE0014NP 电路流量和带宽利用率呈现以日为周期的周期性,流量区间在300~1 500 Mbit/s,带宽利用率区间在3.8%~20%,实际使用带宽为签约带宽的20%。**-** ONE0008NP 电路流量和带宽利用率呈现以日为周期的周期性,流量区间在550~2 760 Mbit/s,带宽利用率区间在5.5%~27.6%,实际使用带宽为签约带宽的27.6%。**-**ONE0100NP 电路流量和带宽利用率呈现以日为周期的周期性,流量区间在1.5~63 Mbit/s,带宽利用率区间在0.15%~6.3%,实际使用带宽为签约带宽的6.3%,周末流量基本保持在低点平稳运行。
通过对上述多条SD-OTN 专线电路流量进行监测发现,SD-OTN 专线电路流量具有总体每日趋势相似,节假日整体趋势变小或者低点平稳运行的特点。
3 基于Autoformer架构的AI流量预测模型
3.1 流量预测模型构建
本文通过对SD-OTN 电路流量特征进行分析,使用多头注意力机制与时频域特征结合训练的Autoformer[4]架构对流量长期序列进行预测(见图2),可以捕捉更长范围的关系关联性,更好地捕捉和学习时间序列的时域和频域特性。在频率域中,在计算复杂度不高的情况下,就能捕获时间序列频域特征,提高预测准确性。通过时域自相关计算和频域相关系数计算进行融合预测输出。

图2 基于时频域特征结合训练的Autoformer架构的流量预测模型架构
预测模型包括四大功能模块,分别为数据预处理、Encoder 堆叠、Decoder 堆叠、Decoder 输出数据处理。具体步骤如下。
a)长时序流量输入:将3 个月15 min 颗粒度的长时序业务流入流出数据作为模型算法的输入。
b)数据预处理:主要对客户原始数据进行处理,提取更多初始特征。
(a)数据清洗:通过pandas 或数据库方式读取客户最近几个月的流量,进行数据异常点过滤。
(b)分析周期趋势:对数据进行析构处理,解析出长周期趋势、短周期趋势、不同周期内同点数据差异值等数据。
(c)时刻标点:对流量数据进行周期时刻数据提取,如获取小时点、周天、月天、季度等时刻数据,形成时刻表点数据;对国家的节假日进行不同权重的标定。
(d)傅里叶变换:对流量数据进行傅里叶频率转换,形成数据的同期频率数据源;同时,根据准确性要求,可选进行小波变换,通过bior1.3 算法实现对低频分量、水平高频、垂直高频、对角线高频等特征的提取。
(e)滑动窗口:对输入的流量数据进行每小时滑动窗口取值,获取数据的训练值,提取与预测值对应的历史值,不停循环滑动建立数据集。
(f)Token 化:对形成的数据集,通过Tokenizer 实现数据的标准化并送入网络。
c)Encoder 堆叠:实现数据的特征提取,主要是对提供的时序数据本身、生成的傅里叶、小波变换数据以及时刻标点数据的关系使用多头注意力机制[5]和多层感知机[7]进行数据矩阵融合来实现特征提取。
(a)多头(12 头)自注意力模块,通过自注意力机制q/k/v 模块,编码器输出多个子空间的K/V 特征量,实现对数据中的关心数据激活(根据后续loss 向前的传递,选取部分对结果起更重要作用的数据,附上更高的权重),选择对预测贡献值更大的数据关系权重,送入解码器对接实现时序数据还原预测。
(b)多层前馈网络,对自注意力模块的输出数据进行降维和标准化,以便融合权重送入下一个Encoder或下一个模块。
(c)边界敏感模型[8],实现数据前后关系的边界弹性、选择性提取,针对滑动窗口形成的边界可以根据当前特征的权重值大小向前后选取更多数据,相对于传统LSTM的RNN[9],有更好的收敛效果。
d)Decoder堆叠:实现中间特征的展开关联预测。
(a)多源输入融合,通过对Encoder 模型的输入以及预测循环输入进行权重融合,实现对Decoder 模块的输入。
(b)时序维度分解,将数据从Encoder 的K/V 分量向高维度编写,以实现特征关联的能力,实现不同维度(时序、傅里叶频率、小波频率、时刻标点)数据的多个层面分解。
(c)自相关机制,对时序分析的多维度数据与源数据的自相关系数进行计算。
(d)频率相关机制,对时序分析的多维度数据与源数据的频率相关系数进行计算。
(e)数据融合预测,对经过自相关、频率关系计算的多维度数据进行融合(通过多层感知机进行维度矩阵变化),生成最终的下轮周期的流量数据。
e)对Decoder输出数据做如下处理。
(a)反Token,对Decoder 输出的数据,做反Token数据输出,形成和输入数据一致的数据量度。
(b)趋势矫正,根据传统机器学习方法计算的逻辑回归、多项式预测方法,实现对获取的趋势和模型输出的数据进行微调。
(c)数据矫正,在实现对数据预测的同时对异常点进行矫正和过滤(通过平均值、最大最小值来判断离群点,判断是否超过正常范围)。
(d)数据输出,输出指定格式、pandas 或数据库格式的数据。
(e)循环输入预测数据,经过筛选后送入Decoder进行数据的对比训练和预测。
3.2 流量预测结果分析
基于计算量的考虑,将电路3 个月15 min 颗粒度的历史流量序列作为训练样本,通过流量模型输出预测序列并与实际流量进行对比(见图3和图4)。
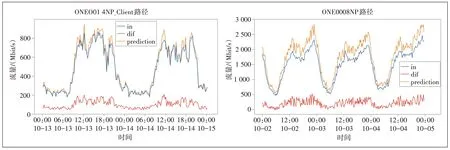
图3 流量预测对比

图4 流量预测偏差率
图3 中黄色曲线为预测曲线,蓝色曲线为实际曲线,红色曲线为残差曲线(预测曲线和实际曲线的差值)。从预测结果可以看出,流量的上升和下降趋势与实际曲线变化基本吻合,残差值在流量高峰时比低峰大,但在预测精度为15 min 实际应用中,预留偏大的网络资源更能适应实时流量突发的情况。通过图4预测偏差率曲线分析(预测偏差率=残差/实际值×100%)发现,预测偏差率在8%~26%,平均偏差率分别为17.1%和16.8%。
3.3 流量预测应用
通过预测未来的流量走势,在带宽达到越限(红线)前,对客户提前做好越限提醒,减少客户电路拥塞和丢包投诉,使SD-OTN 专线月投诉率降低了16.7%。推荐客户使用带宽提速增值业务,提升业务带宽至带宽提速预测值,并根据越限预测持续时间设置提速业务的使用时间。客户可以根据预测结果,对自身业务进行灵活调整,减少电路网络拥塞和业务丢包,提升网络利用率(见图5)。

图5 流量预测应用举例
4 结束语
本文提出的采用Autoformer 中编码器-解码器架构和相关机制算法的流量预测模型,通过多头注意力机制学习和训练流量序列的时域和频域特征模型,可以学习更多序列特征,有效提高了SD-OTN 专线流量预测准确度,并被应用到生产实践中。通过对流量趋势的精准预测,提前做好流量越限和丢包预警,并及时推送给客户,压降非实际网络故障投诉量,SD-OTN专线月投诉率降低了16.7%,有效提升了用户体验。同时,该流量预测模型可为SD-OTN 客户提供付费的临时调速和周期性调速方案等增值业务功能,计划推广到政企一线部门,赋能一线引导客户进行SD-OTN专线提速,支撑政企客户业务的发展,提升网络价值输出。
