联合注意力与卷积网络的知识超图链接预测
2023-11-16秦宏超林晓丽刘小琪王国仁
庞 俊,徐 浩,秦宏超,林晓丽,刘小琪,王国仁
1.武汉科技大学 计算机科学与技术学院,武汉 430070
2.智能信息处理与实时工业系统湖北省重点实验室,武汉 430070
3.北京理工大学 计算机学院,北京 100081
知识超图是一种超图结构[1]的知识图谱。它使用超边(即多元关系)描述现实世界中多个实体之间的关系[2]。知识超图链接预测旨在通过已知的实体和关系预测出未知的关系,在推荐系统[3]和问答系统[4]等领域有广泛的应用。
目前,学界对知识超图的链接预测方法开展了一些研究。根据推理方式的不同,现有知识超图链接预测方法可分为三类:基于软规则的方法[5]、基于神经网络的方法[6-8]与基于嵌入表示模型的方法[2,9-11]。与前两种方法相比,基于嵌入表示模型的方法可以将复杂的数据结构映射到欧式空间,更容易发现关联关系。
目前,最优的知识超图嵌入模型是文献[2]提出的HypE 模型。HypE 根据实体在元组中的不同位置,采用不同的卷积核来提取实体的特征,具有较好的链接预测效果。但是HypE 直接采用初始化的关系嵌入参与最终评分,未考虑不同实体对关系嵌入的贡献程度不同,从而制约了算法性能。
注意力机制是一种常用的表达不同贡献的有效机制,因此本文提出了一种改进的注意力机制,提取实体不同贡献度的有效信息,融入关系嵌入向量。此外,为提取实体特征的卷积核添加相邻实体数量,使实体嵌入包含更多信息。基于上述工作,本文提出了一种联合注意力与卷积网络的知识超图嵌入模型(link prediction based on attention and convolution network,LPACN)。
虽然LPACN 方法的链接预测性能比HypE 等baseline方法更高,但训练时存在梯度消失的问题,使得继续增加迭代次数,其训练效果也不会更好。因此本文引入改进的ResidualNet 来缓解LPACN 的梯度消失,增强知识超图链接预测的效果。此外,为增强模型的非线性学习能力,本文还在改进的Residual-Net之后添加了一个多层感知器。基于上述工作,本文提出了LPACN的改进模型LPACN+。
本文的主要贡献如下:
(1)提出了一种基于注意力和卷积网络的嵌入模型LPACN,解决知识超图链接预测问题。采用改进的注意力机制,将实体的不同贡献度融入关系嵌入,并且采用相邻实体数量补足实体嵌入信息含量。
(2)提出改进模型LPACN+。引入改进的Residual-Net 与多层感知器,缓解了LPACN 的梯度消失,增强了模型的非线性学习能力。
(3)真实数据集上的大量实验结果验证了本文提出的LPACN 和LPACN+的链接预测能力优于Baseline方法。
1 相关工作
本章主要介绍了与本文相关的研究工作,现有知识超图链接预测方法可大致分为三类:(1)基于软规则的方法[5];(2)基于神经网络的方法[6-8];(3)基于嵌入表示模型的方法[2,9-11]。
第一类基于软规则的方法将关系作为谓词,节点作为变量,通过设置关系推理的逻辑和约束条件进行简单推理,典型方法包括RLR(relational logistic regression)[5]等。这类模型学习能力非常有限,不适合预测大规模数据。
第二类基于神经网络的方法采用CNN等神经网络对非线性关系进行建模,能深入学习超图的语义特征。例如,NaLP(link prediction on N-ary relational data)[6]将n元事实表示为一组“角色-值”对,通过卷积神经网络提取相关特征,并使用全连接神经网络来评估它们的相关性,最后得到整个n元关系事实的有效性得分。NaLP 对建模关系的类别有严格的要求,限制了该模型的应用场景。NeuInfer(knowledge inference on N-ary facts)[7]以主三元组与辅助“角色-实体”对的形式来描述n元事实,通过多层全连接网络学习事实中的语义特征,然后使用打分函数得到元组的得分。HINGE(hyper-relational knowledge graph embedding)[8]表示n元事实的方式与NeuInfer相同,并使用卷积网络提取事实中的语义特征,通过全连接网络对事实进行打分,HINGE相较于NeuInfer在性能上有较大提升。这类方法往往只关注局部的语义特征而忽略了事实之间的关联。
第三类基于嵌入学习模型的方法通过欧式空间映射的方式将元组转化为向量,然后学习它们之间隐含的关联关系,通过不同的处理方式来使用打分函数对正负样本进行打分,完成链接预测的任务。其首先在知识图谱链接预测中得到应用,如TransE[12]将知识图谱中每个关系看作头实体到尾实体的一个平移变换,将知识图谱中的实体和关系映射到低维空间进行打分。由于TransE 模型不具有鲁棒性,TransH[13]将翻译操作放在特定的超平面上进行,将实体嵌入映射到关系超平面之后再进行打分运算。文献[9]将TransH扩展到知识超图中,提出了m-TransH方法,将多元关系事实定义为角色序列到其值的映射,每个映射都对应一个关系的实例。m-TransH 不具有完全表达性,且对建模的关系类别有严格的要求。文献[10]将TuckER[14]扩展到知识超图中,提出了GETD(generalizing tensor decomposition)方法,并使用张量环来降低模型的复杂度。GETD 只能处理所有元组元数均相同的数据集。HyperGAN(hyper generative adversarial network)[11]通过对抗训练生成高质量负样本,来解决现有模型训练负样本质量低下、复杂度过高的问题。该方法专注于提高负样本质量,而本文重点研究整个知识超图链接预测算法。此外,HSimplE[2]改进了SimplE[15],使实体嵌入向量根据其在元组中的位置而改变。HypE[2]同样受益于SimplE的启发,根据实体在元组中不同位置包含信息不同的特性,学习不同的卷积核以提取实体特征,使得模型因能提取更加丰富的特征,而取得了当前最好的链接预测效果。且HypE具有完全表达性,对于包含不同元数元组的数据集能给出准确的链接预测结果。但由于参与最终评分的关系嵌入是通过初始化方法获取的,而未考虑实体对关系的贡献;并且其卷积可提取的信息不够丰富,从而限制了算法的链接预测能力。
综上所述,基于嵌入模型的方法能够发现元组隐含的关联信息,从而取得更好预测效果,是目前最优的知识超图链接预测模型。因此本文对该类方法展开研究。但现有的最优嵌入模型HypE 在链接预测时忽略了实体对关系的贡献,从而制约了模型的性能。因此,本文提出了LPACN方法,考虑实体对关系的贡献度,将实体的有效信息融入到关系嵌入中,并向处理实体的卷积网络添加更多信息,增强方法的链接预测能力。
2 问题形式化定义与符号
定义1(知识超图)知识超图是由顶点和超边组成的图,记作KHG={V,E}。其中V={v1,v2,…,v|V|}表示KHG 中实体(顶点)的集合;E={e1,e2,…,e|E|}表示节点之间关系(超边)的集合。|V|指KHG 所含顶点的个数,|E|指KHG 所含超边的数目。任意一条超边e都对应着一个元组T=e(v1,v2,…,v|e|),T∈τ。|e|指超边e所含顶点的个数,即e的元数。τ表示理想完整目标知识超图KHG所有元组组成的集合。知识超图也可看作多元组的集合。每个多元组由一条超边和该超边包含的所有实体组成。
定义2(知识超图链接预测)已知根据实际应用构建的知识超图所有元组的集合τ′,同场景下理想完整的知识超图所有元组的集合τ,τ′⊆τ。知识超图链接预测旨在根据已知元组T∈τ′预测出新的元组Ti∈τ-τ′,并更新τ′=τ′∪Ti,使得min(|τ-τ′|) 。|τ-τ′|表示集合τ与τ′的差集的基数。
本文剩余部分常用符号及含义如表1所示。

表1 符号及含义Table 1 Notation and description
3 LPACN方法
本章详细介绍本文提出的LPACN模型。首先简要描述LPACN 框架与其执行大致流程,然后重点展开介绍其中的关系的嵌入表示和实体投影向量生成,最后描述LPACN模型的训练过程。
3.1 LPACN框架
LPACN 模型的基本思想是:基于注意力机制生成关系注意力向量,该向量考虑了不同实体对所在关系嵌入的不同贡献程度;将关系内实体的邻居实体数目融入提取实体特征的卷积核,以补足实体投影向量包含的信息。考虑实体贡献度和补足实体嵌入信息,有利于增大正例元组的得分,从而提高知识超图链接预测的性能。
LPACN 总体框架如图1(a)所示,包括三步:(1)关系注意力向量生成;(2)实体投影向量集生成;(3)元组打分。由于元组打分较简单,下文将主要介绍第一步和第二步。

图1 LPACN模型示意图Fig.1 Illustration diagram of LPACN model
3.2 关系注意力向量生成
本节提出一种关系的注意力嵌入表示方法。注意力机制为元组内的每个实体分配不同的重要程度。其通过实体和对应关系之间的权重来表示,使关系注意力嵌入向量按比例包含实体信息,从而丰富关系所含语义信息,提高算法预测性能。
为了得到关系ei的注意力嵌入表示,首先对关系初始嵌入向量ei∈Rde(de表示向量ei的维度)与实体初始嵌入向量集合(1 ≤i≤|e|,dv表示实体向量v的维度)进行串联操作,然后对串联结果向量进行线性映射,并遵循文献[16]中的方法,在线性映射后使用LeakyReLU 非线性函数进行处理,得出同时包含实体集合Vi与关系ei信息的投影向量。该计算过程如式(1)所示:
为了得到关系ei与实体集合Vei之间的权重α,将融合了实体与关系的投影向量pi使用softmax 进行处理。关系注意力嵌入向量ef通过αij与pij的乘积的累加得到,其计算公式如式(2)所示:
αij表示权重向量,代表了实体vij对关系ei的重要程度,pij表示投影向量pi的第j行。
关系注意力嵌入向量ef包含了关系ei与实体集合Vei的信息,能更好地适应知识超图的链接预测任务。
3.3 实体投影向量集生成
知识超图的实体可出现在多个关系的不同位置,同一元组中相邻实体数量与特征会因出现位置不同而异。为了能根据实体vij在元组中的位置来提取特征,首先使用包含了元组位置信息的卷积核wi∈Rn×Rl提取实体嵌入vij中的特征(n代表该位置的卷积核个数,l代表卷积核长度,可预先定义。wi表示元组中第i个位置的卷积核,wij∈Rl指代第i个位置的卷积核中的第j行);然后采用参数nebj向卷积核wi中添加相邻实体数目信息,使得wi能根据不同的相邻实体数量提取到不同的有效特征。卷积处理如式(3)所示:
为了得出完整的映射向量,需要对获得的卷积嵌入向量βij进行串联操作与线性映射,如式(4)所示:
W2∈Rnq×Rdv表示线性映射矩阵。q代表特征映射的大小,q=(d-l/s)+1。
此外,嵌入学习过程中,使用多层神经网络处理实体,很容易丢失实体初始嵌入信息。为了解决该问题,将初始实体向量vij加上转换后的映射向量,计算得到的在保留原始向量特征基础上,有更强的表达能力。其计算过程如式(5)所示:
最后,使用关系注意力向量与所有实体投影向量之间的内积对元组T进行打分,如式(6)所示:
LPACN 模型中每个实体只学习单个向量,能有效降低模型的复杂程度,还具有完全表达性(能够为每一个元组打分,从而分辨它们是否为真)。
3.4 模型训练
3.4.1 损失函数
训练神经网络旨在使损失函数尽可能达到最小。不同的损失函数可能适合不同的任务。根据本文任务选择了交叉熵损失作为损失函数(文献[17]已验证有效性),其计算公式如式(7)所示:
其中,Gtrain表示训练集,Gneg(T)表示通过替换元组T中的实体构建的负样集。
3.4.2 训练过程
算法1LPACN的训练过程
算法1 描述了LPACN 的训练过程。首先,根据实体v所需的卷积核数量nf对卷积核w进行初始化(第1行)。然后,进行迭代训练,直至预设Ite次为止(第2~20 行,为了使模型得到充分训练,根据文献[2]的方法,实验中Ite设置为1 000)。每次迭代过程如下所示:根据Mini-Batch 方法将Gtrain划分为多个子集{Si}(第3 行),并将全局损失loss初始化为0(第4行);然后分别对每个子集Si分批次进行处理(第5~19行)。其处理过程如下:首先分别对Si中的每个元组T进行打分(第6~15 行),然后计算出该子集训练时的损失L(Si),并更新实体与关系的嵌入(第16、17行),最后更新全局损失(第18行)。其中,Si中的每个元组T的处理过程如下:首先为T构造负样集Gneg(T)(第7行),并将Gneg(T)与T合并组成元组集合T*(第8行);然后遍历T*中的元组T′,对其中的v、e进行初始化,并使用注意力机制与卷积网络对关系与实体进行处理,最后对该元组进行打分(第9 至14 行)。
4 LPACN+方法
虽然LPACN方法通过丰富关系和实体嵌入向量包含的信息,能提高知识超图链接预测的性能,但实验发现它仍存在梯度消失问题。针对该问题,本文使用改进的ResidualNet,对LPACN 进行优化处理。此外,采用多层感知器进一步提升LPACN 的非线性学习能力,最终得到LPACN的改进算法LPACN+。
LPACN+在LPACN 模型中的卷积网络之后引入了改进的ResidualNet,接着使用一种多层感知器得到实体感知向量。由于其余部分均与LPACN相同,图2 只简要展示了LPACN+模型引入改进的ResidualNet与多层感知器这部分流程。在图2中,代表经过残差网络处理得到的残差向量,improved residual processing 表示使用改进的残差网络进行处理。下文将主要介绍改进的ResidualNet。
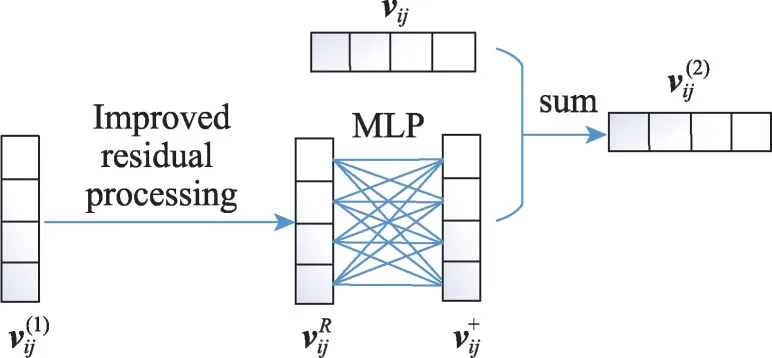
图2 LPACN+主要改进工作示意图Fig.2 Illustration diagram of main improvement work for LPACN+
为了缓解梯度消失问题,本文在实体投影操作(详情见3.3 节)之后添加ResidualNet[18],并对其进行改进。ResidualNet中的残差函数F(x)通常使用全连接层或卷积层作为残差网络,但考虑到卷积层相较于全连接层更灵活且高效,因此本文实验中的F(x)使用了卷积神经网络。
通常残差函数F(x)中使用的卷积核是随机初始化而来,无法有效提取知识超图中的映射向量的结构信息。为此,本文使用3.3节中包含位置信息与邻接信息的卷积核wi来作为代替权重层的卷积核,使ResidualNet 最大程度地保留元组中的结构信息。整个残差网络的过程如式(8)所示:
F(x)选择两层以上的网络层数是因为当F(x)选用单层网络时,式(8)变成线性层,相较其他网络没有优势。
改进后的ResidualNet通过一段跳连接为模型恢复了学习梯度。多层网络学习后,为模型重新赋值一个实体向量,使残差向量在很大程度上保留了原超图中节点的特征与结构信息,这样模型在不断学习中始终含有知识超图的原始信息,从而恢复了原本的梯度,能有效缓解梯度消失。
最后,本文使用文献[19]中提出的多层感知器,如图2所示。限于篇幅,不赘述。
5 实验
本章在真实数据集上比较了本文提出的LPACN算法、LPACN+算法以及Baseline 算法的链接预测能力,分析了LPACN+的梯度消失缓减程度,通过消融实验测试了不同元数的数据对链接预测结果的影响。
5.1 数据集
本文实验采用了文献[2]使用的数据集,即从FreeBase 数据集抽取的两个常用知识超图链接预测数据集JF-17K[8]、FB-AUTO[2]。
JF-17K 数据集通过删除FreeBase 中出现频率不高的实体和三元组,并随机抽取关系中的事实构造而成,没有划分验证集。FB-AUTO 数据集中只包含与“Automative”相关的事实,并随机划分为训练集、测试集、验证集。上述数据集的数据情况如表2 所示。其中,|E|与|R|分别表示实体与关系的数量。#train、#test、#valid分别描述训练集、测试集与验证集中包含元组的数量。
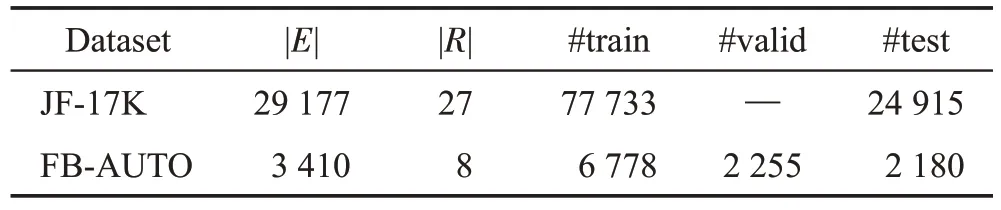
表2 数据集统计Table 2 Statistics of datasets
5.2 Baseline方法与评价标准
本文Baseline 算法包括目前流行的知识超图链接预测算法m-TransH[9]、HSimplE[2]与HypE[2]。
本文采用了知识超图链接预测常用的评价标准:平均倒数排名(mean reciprocal rank,MRR)[2]和Hit@n[2]。由于平均排名(mean rank,MR)对异常值不敏感[20],本文未采用。MRR和Hit@n值越大,链接预测性能越好。本文实验取Hit@1、Hit@3、Hit@10。
5.3 链接预测性能比较
本节分别在JF-17K 和FB-AUTO 数据集上对比本文提出的LPACN、LPACN+与Baseline方法的MRR、Hit@1、Hit@3和Hit@10,实验结果如表3所示。
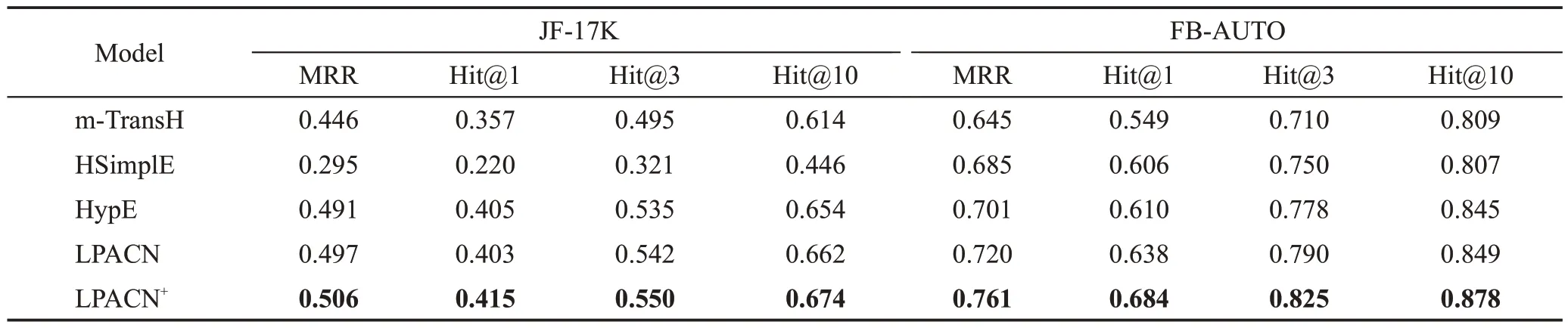
表3 LPACN与Baseline方法的链接预测性能对比Table 3 Comparison of link prediction performance of LPACN and Baseline methods
实验结果表明,LPACN 在上述数据集的绝大部分结果都优于HypE。因为一方面,本文改进的注意力机制相较于HypE,不但考虑了目标关系所含实体对该关系的嵌入表示的贡献度不同,还融入相邻实体数量以增加对应实体嵌入表示包含的信息;能为链接预测提供更多的推理依据,从而提升了知识超图链接预测的效果。另一方面,添加的邻接实体数目信息让卷积网络可学习的特征更多。此外,为实体向量添加丢失的初始信息,使模型能够更好地进行预测。LPACN 在JF-17K 数据集上的Hit@1 比HypE低0.002。因为JF-17K存在数据泄露的问题[21],会干扰模型预测的准确性。
从表3 还可以看出,LPACN+在所有数据集上的指标都远高于LPACN。这是LPACN+在LPACN的基础上依次添加了改进的残差网络和多层感知器的缘故。这样不但缓解了梯度消失,还增强了非线性学习能力,使模型能够不断地学习,并减少学习过程中信息的损失,因此LPACN+的链接预测结果更加准确。
5.4 梯度消失减缓分析
为了进一步分析梯度消失缓解程度,本节在FBAUTO数据集上比较了LPACN、R-LPACN(ResidualNet+LPACN)和LPACN+的loss曲线,结果如图3所示。
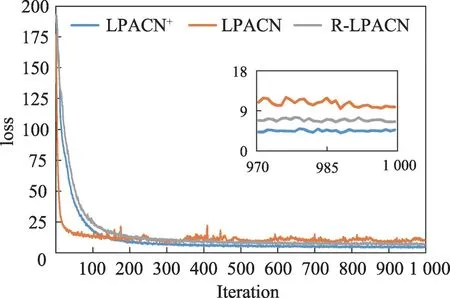
图3 loss对比图Fig.3 Comparison chart of loss
从图3可见,虽然3个模型的曲线下降趋势大致相同,但是最终的loss 有较大差别。LPACN 模型在经过1 000 次迭代学习之后的loss 定格在了9 左右;在LPACN 的基础上添加了ResidualNet 之后,RLPACN的loss降到了6左右,降低约30%;最后,同时添加了ResidualNet 与多层感知器的LPACN+,其loss降到3左右,较上一模型降低了约50%,较LPACN降低约60%。从对比的结果可直观地看出:与LPACN相比,LPACN+最终损失有很大幅度的下降,达到了60%。这验证了ResidualNet 与多层感知器对降低loss都发挥了较大的作用,能有效缓解梯度消失。
ResidualNet 与多层感知器从不同的角度对模型进行提升。一方面,改进的ResidualNet 恢复了学习的梯度,从而缓解梯度消失的问题;另一方面,多层感知器又通过多层的神经元与非线性函数增强模型的非线性学习能力使其能学到更多的特征,损失的信息也就越少,loss值更低。
5.5 消融实验
为了验证LPACN+对于不同关系元数的链接预测能力,本节在JF-17K不同元数的数据子集上,使用Hit@10 对比了LPACN+与Baseline方法的性能,其实验结果如表4所示。
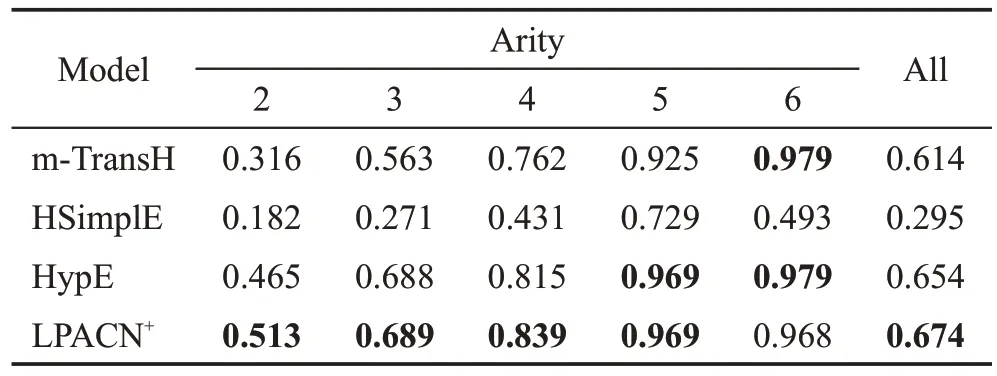
表4 JF-17K不同元数的子集上链接预测结果对比Table 4 Comparison of link prediction results on subsets of JF-17K in different arities
从表4可知LPACN+虽然在不同元数数据集上的链接预测能力总体略强于HypE,但相较于其他Baseline 优势非常明显。对于二元、四元的数据集,LPACN+的预测能力都优于HypE;在三元、五元的数据集上,LPACN+与HypE 的链接预测能力基本相同。对六元组进行预测时,HypE 相对于LPACN+略有优势。分析发现,JF-17K 中六元组的数量只有37个,模型在该稀疏子集中可学习的样例较少,且HypE对于稀疏数据具有更强的推理能力,因此LPACN+在该子集上的链接预测效果略逊色于HypE。
6 结束语
本文提出了一种联合注意力与卷积网络的方法LPACN,解决知识超图链接预测问题。与目前最优的模型相比,LPACN 不但采用一种改进的注意力机制,考虑了实体对所在关系的嵌入表示的贡献度,而且将相邻实体个数信息融入卷积核,以丰富实体嵌入向量中包含的信息。为缓减LPACN 的梯度消失,LPACN+对LPACN进行了优化:在实体向量投影操作后,融合了改进的ResidualNet继续进行残差处理,并在残差处理后使用了多层感知器,进一步提升了模型的非线性学习能力。真实数据集上的大量实验结果验证了本文方法的预测性能比所有Baseline 方法更高。后续工作将尝试加入一些辅助文本或其他元组内的信息来进一步丰富嵌入,从而继续提升算法预测性能。
