多教师对比知识反演的无数据模型压缩方法
2023-11-16林振元林绍辉姚益武何高奇王长波马利庄
林振元,林绍辉+,姚益武,何高奇,王长波,马利庄
1.华东师范大学 计算机科学与技术学院,上海 200062
2.北京大学 信息科学技术学院,北京 100871
知识蒸馏(knowledge distillation,KD)[1-5]是一种常见的模型压缩方法,在大多数现有的KD 方法中,使用基于logits[1]或来自教师的特征信息[2]的方法可以将知识从教师网络转移到学生模型,但在这其中需要访问整个训练数据。本文将这些KD 方法称为数据驱动的KD 方法。然而在现实中,由于隐私、保密或传输限制,在蒸馏过程中原始训练样本通常不可用。例如,患者的医疗数据是保密的,不会公开共享以泄露患者的隐私。如果没有数据的帮助,这些方法在获取不到原始数据的情况下将无法使用。
许多工作[6-8]使用生成对抗网络研究无数据模型压缩。然而,这些研究都关注于提高从特定的单一模型反演数据的性能,导致生成的数据缺乏多样性和泛化性。
一方面,从某一特定模型反演知识会使合成图像有偏差。由于生成的样本是从单一的教师模型反演学习得到的,只含有教师网络所包含的结构先验知识,导致这些合成的数据不能用于蒸馏到其他的模型。如图1 所示,在相同的设定下分别将DAFL(data-free learning)[6]、DFQ(data-free quantization)[9]、DeepInversion[10]、CMI(contrastive model inversion)[7]方法合成的数据直接用于训练不同架构的网络,实验结果表明同一个方法得到的训练数据用于训练不同网络时效果差异很大,而且与CIFAR-10 原始数据相比性能上仍存在较大的差距。以Inception-V3 为例,现有的方法CMI[7]所合成的数据与原始数据得到的性能仍然相差了10 个百分点,而且使用合成的数据来训练不同的网络结构很不稳定,不同网络的准确率有较大的方差,说明先前的方法合成的数据可能包含了某一种网络结构的先验知识以至于无法很好推广适用于其他的模型的训练。因此,这种方法显然无法拓展至多种网络进行压缩。而使用不同的教师网络进行多次多个模型的压缩将显著增加多个模型的训练时间和数据内存存储。另外,Chen等[6]使用特定的教师模型(ResNet-34[11])合成数据去训练其他模型,例如ResNet-18、WRN-16-1,WRN-16-1的最终性能明显低于ResNet-18 的性能。因此本文的目的在于所合成的数据可以直接用于训练其他结构的网络。
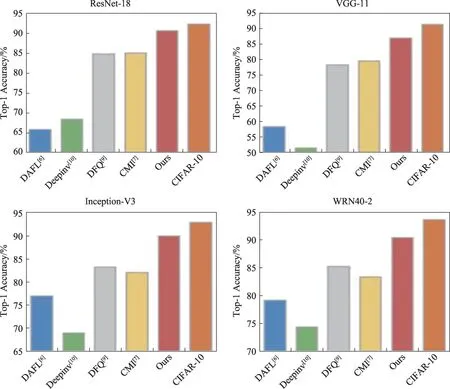
图1 跨模型无数据蒸馏的结果概述Fig.1 Overview of results of cross-model data-free distillation
另一方面,目前的工作在判别器中使用信息熵[6]或学生-教师分歧[9]来生成多样化的图像,由于缺乏与历史生成的图像的比较,生成图片的多样性仍然有所欠缺。在这种情况下,该类算法在生成的图像中会遇到重复模式,生成器极有可能生成与历史实例高度相似的实例。
为了解决这些问题,本文提出了一种多教师对比知识反演的无数据蒸馏方法(multi-teacher contrastive knowledge inversion,MTCKI),图2 描述了所提出方法的工作流程。MTCKI 算法在实际应用中,也有着巨大的需求。例如,模型的供应端(公司和企业)是会有很多不同网络架构的预训练模型,而客户端需要部署一个小模型在自己的终端设备上。本文提出了一种供应端-客户端合作的模式,供应端将已经训练好的多个教师模型提供给客户,而不提供原始的训练数据,而客户端只通过这些训练好的教师网络去得到一个学生网络用于部署。单个学生可以访问多个教师从而得到多个教师网络提供的全面指导,由此训练出的学生模型对模型偏差具有较强的鲁棒性。本文首先提出了基于多教师集成的模型反演,充分反演来自教师的更丰富的信息以生成可泛化的数据。同时,本文进一步提出了多教师和学生之间的对比交互正则化,其中包含教师内对比和师生对比,以提高合成数据的多样性。具体来说,教师内部对比用于逐步合成具有与历史样本不同模式的新样本。本文还提出了师生对比,师生对比旨在使得生成器合成的图片能让学生网络和教师网络映射到相同的表示空间中,采用对比学习的方法拉近同一物体的多视角表示,并区分开不同物体的特征。学生网络学到的不仅是学生网络所擅长提取的特征,比如鸟的嘴,还能从与教师网络的表示的拉近过程中明白鸟的嘴、翅膀、眼睛、羽毛都可以被看作同一物体的不同视角,从而学习到更好的特征表示。基于以上原理,生成器所合成的图片融合了多视角的特征信息使得合成的图片具有泛化性和多样性,一次生成的图片数据集能够用于蒸馏或从头训练多个不同的学生网络。本文方法以对抗的方式训练图像生成和知识转移的过程,最终可以获得高精度的学生模型和高质量的生成数据。
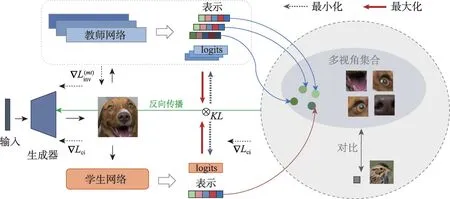
图2 多教师对比知识反演的无数据模型压缩方法整体架构Fig.2 Overall framework of multi-teacher contrastive knowledge inversion for data-free distillation
本文的主要贡献总结如下:
(1)提出了一个新的无数据知识蒸馏框架,从多个可用的教师模型中提取“多视角”知识,同时提高学生模型精度和合成高质量数据。
(2)设计了一种对比交互方式,充分利用来自多位师生的知识,生成具有高泛化性和多样性的合成数据。一次生成的图片数据集能够用于蒸馏或从头训练多个不同的学生网络。
(3)实验表明本文方法优于现有的方法。本文方法不仅合成了更接近原始数据集分布的高保真数据,而且还达到了与在原始数据集上训练的预训练模型相媲美的结果。
1 相关工作
1.1 数据驱动的知识蒸馏
知识蒸馏[1]旨在通过从大型教师网络转移知识来提高小型学生网络的性能。产生的知识可来自类后验概率[1]或中间特征[1-2,7,12-13]。目前已有利用多个教师构建更丰富和有启发性的信息来训练学生模型的研究,其中知识来自集成logits[14-15]或特征[16-18]。例如,Lan 等[14]构造了一个多分支结构,每个分支表示学生,并对每个分支进行融合得到教师网络,将最终的集成logits作为蒸馏知识。You等[17]使用多个教师网络的结合来提取不同实例中间层中的三元组排序关系,鼓励与学生保持一致。本文方法在以下两方面与之前的方法完全不同:(1)本文的框架以无数据的方式构建,这相比之前的数据驱动的知识蒸馏更加灵活;(2)本文考虑了多位教师之间的内部和相互关系,与基于多教师的知识蒸馏相比,它可以提取更丰富的知识进行蒸馏。
1.2 无数据的知识蒸馏
无数据知识蒸馏的关键是在无需真实图像的情况下进行图像合成。一般可以大致分为两类:(1)在先验知识上使用梯度下降直接学习图像,如激活统计[19]和批量正则化(batch normalization,BN)统计[10];(2)对抗性训练以在噪声输入上学习生成器。DAFL[6]和DFQ[9]在第一阶段使用生成对抗网络(generative adversarial networks,GAN)生成图像,可进一步用于学习学生模型。最近,ZAQ(zero-shot adversarial quantization)[20]提出了一个两级差异建模框架,用对抗的方式对学生和老师之间的中间特征进行差异估计,并通过知识转移来学习学生。训练后,无需重新训练即可同时获得合成图像和学生模型。ZeroQ[21]、Knowledge Within[22]以及MixMix[23]使用合成的数据集来执行无数据量化。然而,这些方法是模型定制的,生成的图像不能推广到其他模型进行蒸馏。与这些方法不同,本文方法提出了多教师和学生之间的对比交互,以生成高泛化和高多样性的图像。虽然MixMix[23]也利用多教师使用合成的数据集来执行无数据量化,但本文方法利用最终特征信息和师生交互来更好地提高合成图像的泛化性和多样性。此外,学生和图像生成的学习是以端到端的方式训练的,这与MixMix中的两步训练完全不同。
1.3 对比学习
对比学习[24-28]已广泛应用于无监督学习,能够学习有效的特征表示以提高下游任务的性能。实例级对比是一种简单而有效的策略,旨在将正样本和锚点拉近,同时将其推离表示空间中的负样本。例如,He 等[26]使用记忆库来存储来自动量编码器的负样本,并使用InfoNCE损失[27]从查询编码器和动量编码器之间的表示中构建对比。Chen等[24]用大批量数据替换记忆库,让两个网络在不同输入增强上进行对比。对比学习的思想同样也有被应用于知识蒸馏[29-31]。例如,Tian等[29]通过最大化教师和学生表示之间的互信息,将对比学习与知识蒸馏相结合。然而,这些方法中的对比知识是由真实数据和一个教师网络形成的,然而,本文方法不需要任何真实数据,只需构建多教师和学生之间的对比。
2 多教师对比知识反演方法
2.1 预备知识
为了更好地说明所提出的方法,本文首先使用一个预训练的教师网络介绍了三个广泛使用的模型反演损失。令fT(x,θt)和fS(x,θs)分别表示来自输入图像x的教师和学生编码器的输出,其中参数分别为θt和θs。由于预训练教师中给定固定参数,本文通过省略θt将fT(x,θt)表示为fT(x)。=G(z,θg)是参数为θg的生成器G从噪声输入z合成的图像。本文的目标是通过减小教师网络带来的偏差来生成具有多样性的高保真数据集,以替代原始图像X。
(1)One-hot 预测损失。它用于生成器合成与教师网络训练数据相兼容的图像,使教师能够对∈做出one-hot 的预测[5]。因此,给定一个预定义的类c,本文将one-hot预测损失表示为:
这里的CE是指交叉熵损失。
(2)BN 层中的特征正则化损失。BN 层已广泛用于CNN,它通过在训练期间用平均统计量对特征图进行归一化来缓解协变量偏移。训练后,这些统计数据存储了有关X的丰富信息(例如:运行均值μ(x)和运行方差σ2(x))。因此,Yin 等[10]通过最小化所有层的和x的统计数据之间的距离来提出特征正则化:
(3)对抗蒸馏损失。通过对抗性蒸馏损失以鼓励合成图像使学生-教师产生较大的分歧[10,32-33],可以表示为:
其中,KL是KL散度,τ是温度参数。
如上所述,本文整合了无数据蒸馏的基本框架,无数据蒸馏的整体模型反演损失可以通过组合公式(1)~(3)来表示:
其中,λi,i=1,2,3 是平衡参数。
2.2 多视图的教师网络集成
文献[34]提出了多视图假设,即“多视图”结构非常普遍存在于许多现实世界的数据集中。这些数据中存在多个特征,可用于正确分类图像。例如,通过观察翅膀、身体大小或嘴巴的形状,可以将鸟类图像分类为鸟类。模型往往只需要获取一部分的特征,由于大部分的图像可以被正确分类,模型便不再学习额外的特征。在现有的无数据蒸馏方法中,即使学生可以提取单一老师学习的所有特征,他们仍然无法“看到”该特定教师未发现的特征,从而限制了学生的表现。除此之外,由于图像的合成受限于教师网络,生成器合成的图像缺乏多视图结构,以至于学生网络难以看到物体的全部特征,这也就限制了合成数据的泛化性能。即使某些模型缺少单个学生可以学习多视图知识的视图,基于集成的方法也可以收集到大部分这些视图。受文献[14,34]的启发,本文首先考虑多个集成教师来构建一个可靠的多分支模型。整体的框架如图2所示,本文的框架包含多个教师网络、一个学生网络以及一个生成器。本文选择所有教师的平均最终输出作为模型预测,而不是按文献[14]使用门控组件。此外,本文使用不同的教师来获取各种统计知识,以提高合成图像的多视图结构,从而提升数据的泛化性能。因此,方程式中的模型反演损失式(4)可以重新表述为:
2.3 多教师和学生之间的对比策略
对比学习[23,25-26]以自监督方式在特征表示上取得了巨大成功,可以有效地转移到下游任务,例如分割和目标检测。实例级对比是一种简单而有效的策略,目的在于将锚点拉近正实例,同时将其推离表示空间中的负实例。MOCO(momentum contrast)[26]算法使用记忆库(比如存储来自历史数据的特征)通过将当前的实例与历史存储的实例的匹配来进行对比,从而学习图像特征表示。它启发了本文使用记忆库进行对比学习来生成具有高度多样性的数据。
受此启发,任意选取生成器合成的同一批图像中的一张图像为待测图像,将待测图像的表示和数据增强后的待测图像的表示作为正样本对,生成器合成的同一批图像中待测图像以外的图像的表示作为负样本,并将生成器合成的历史图像的表示作为负样本。本文首先引入一个头部投影网络h将输入投影到一个新的特征空间中。因此,本文可以获得每个带有参数的教师的输出。本文遵循MOCO的流程,并通过InfoNCE[27]为每个教师编码器独立地构造教师内对比损失(intra-teacher contrastive loss),可以表示为:
教师内对比损失可以帮助生成器逐步合成一些与历史样本不同的新样本。然而,它只独立考虑了教师的实例级对比,本文希望通过不同网络对物体不同视图下的特征关系进行对比学习,从而使得学生网络以及生成器对于数据中的多视图知识的分布学习到更好的表征。换句话说,同一个物体在不同视图下的表征应当是相似的,不同物体的表征则远离。基于上述思想,学生网络学到的不仅是学生网络所擅长提取的特征,比如鸟的嘴,还能从与教师网络的表示的拉近过程中明白鸟的嘴、翅膀、眼睛、羽毛都可以被看作同一物体的不同视角,从而学习到更好的特征表示。故本文进一步提出了师生对比,旨在使生成器合成的图片能让学生网络和教师网络映射到相同的表示空间中,采用对比学习的方法拉近同一物体的多视角表示,并将不同物体的特征区分开来。首先,从当前批次中的第i个图像构造学生的特征,表示为=h(fS(,θs),θh)。然后,本文将学生的特征和相同的第i图像中教师的特征进行拉近,并将和负实例的表示推远,包括记忆库和其他不包括当前批次中的第i个图像实例。因此,师生对比损失可以表述为:
其中,Neg是负样本的集合,可以定义为:
这里,D(s)是教师网络索引集,为学生模型输出的历史图像记忆库中的第j个负样本的特征表示。通过结合式(9)和式(10),本文可以将多教师和学生之间的对比交互损失表示为:
本文通过最小化式(11)来反演出来自多个教师的更丰富的知识。它有效地生成具有多样性和更真实的图像。需要注意的是,与MOCO不同,本文的框架是以对抗的方式进行训练,不需要动量编码器。
2.4 优化
本文方法包含两个阶段:通过生成器G生成图像以及从教师蒸馏知识到学生网络。对于图像生成,本文结合了模型反演损失和对比交互损失Lci,可以表示为:
其中,λ是和Lci之间的平衡参数。对于知识蒸馏,本文的目标是将知识从多教师集成的预测结果蒸馏到学生网络,则式(8)改为:
本文的框架在两阶段过程中进行训练,如算法1所示,其中生成器和学生交替更新。在每次迭代中,首先训练生成器使得其输出的图片通入教师网络后的统计量信息逼近存储在教师BN层中的统计数据,使得特征图处于一个合理的范围内。随后使用对比学习与历史样本进行对比,融合教师网络多视角的信息,并消除存储在图像中的模型结构所带来的偏差信息。然后训练学生网络使其输出与教师集合预测的输出之间的距离最小化。通过交替更新学生和生成器,算法收敛到最优点。
算法1多教师对比知识反演的算法
3 实验
3.1 实验设置
(1)数据集和模型。本文在不同的网络架构上评估提出的方法,包括ResNets[11]、带BN 层的VGG[35]、WRN[36]、Inception-V3[37]和MobileNet-v2[38]。在3 个广泛使用的数据集CIFAR-10、CIFAR-100 和Caltech-101[39]上进行了实验用于测试合成图像的质量,并训练教师网络和学生网络。本文选择ResNet-34、VGG-11、WRN-40-2 和Inception-V3 作为教师模型。选择WRN-16-1、ResNet-18、WRN-16-2、WRN-40-1 和VGG-8作为学生模型,并对其进行评估。本文在表1中总结了这些在原始CIFAR-10/100和Caltech-101数据集上训练的教师的准确率,其中“Ensemble”表示ResNet-34、VGG-11 和WRN-40-2 集成后的准确率。将本文方法与现有的最先进的方法DAFL[6]、DFQ[9]、Deepinv(deep inversion)[10]、CMI[7]进行了比较。
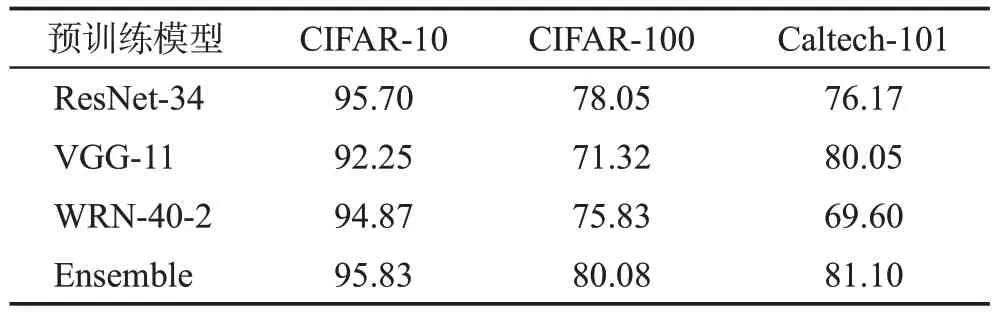
表1 在不同数据集上预训练教师网络的准确率Table 1 Accuracy of pre-trained teachers on different datasets 单位:%
(2)实验设置细节。本文使用PyTorch来实现提出的多教师对比知识反演,算法1中的优化问题在具有24 GB显存的NVIDIA GTX 3090 GPU上运行来进行实验。权重衰减设置为0.000 1,动量设置为0.9。对于数据集CIFAR-10 和CIFAR-100,本文将小批量(minibatch)大小、总训练回合(epoch)数和初始学习率分别设置为256、200和0.1。学习率在120、150、175和190 个epoch 上按0.1 的比例衰减。对于数据集Caltech-101,本文首先从原始数据集中随机抽取20%的图像作为测试集,并将所有图像的大小调整为128×128。本文使用更大的生成器来合成图像,教师数设置为3(在3.3 节中有对集成教师网络个数的影响的分析)。
对于在数据集Caltech-101 上的实验,将批量大小设定为32,合成图像大小尺寸为128×128,epoch为400,学习率在250、300、350 和375 个epoch 上按0.1衰减,同时遵循了CMI中对于超参数的设定,λ1、λ2、λ3分别设置为0.5、1.0 和0.5,其余训练参数设置为与CIFAR-10/100 相同。对于超参数λ,本文使用[0.1,1.0]范围内的交叉验证来确定多教师模型反演损失和对比交互损失之间的最佳权衡。
(3)生成器和头部映射层的结构。生成器G的内部结构由一个全连接层(fully connected layers,FC)、三个卷积层组成,其中一个卷积层是由一个卷积、批量归一化和LeakyReLU 组成。输入噪声的维度设置为256。对于头部投影架构,本文使用两个全连接层将网络的输出表示映射到同样的256维。
(4)评价指标。本文选择学生的准确率和生成的图像与原始数据之间的FID(Frechet inception distance score)作为评估标准。FID 是生成对抗网络GAN 中常见的衡量指标,用于衡量两个数据集的相似程度,分数越低两者的分布越接近。
3.2 与现有算法的比较
本文在数据集CIFAR-10、CIFAR-100 和Caltech-101 上进行实验。CIFAR-10 是一个常用的分类数据集,图像均匀分布在10个类别中。它总共有50 000张训练图像和10 000张测试图像,所有这些图像的大小都是32×32 像素。CIFAR-100中的图像与CIFAR-10相同,只是它们分为100个类别。Caltech-101是一个包含101个类别的图像分类数据集。每个类别的样本数量从40到800不等,每张图像的大小约为300×200。
本文选择ResNet-34、VGG-11和WRN-40-2作为本文的多个教师。在数据集CIFAR-10、CIFAR-100和Caltech-101中集成的预训练教师达到95.83%、80.08%和67.08%的准确率。本文以定量和定性的方式将本文方法与最优方法(state-of-the-art,SOTA)进行比较。
(1)客观指标分析。表2记录了本文方法和先前的方法在不同数据集CIFAR-10、CIFAR-100和Caltech-101上的比较结果。本文可以观察到:①本文方法在所有3 个数据集上都优于现有方法。例如,当在CIFAR-10 数据集上蒸馏到相同的WRN-16-1 时,本文方法达到了91.59%的准确率,比最佳的CMI 基线提高了2.49个百分点。对于CIFAR-100,在蒸馏到相同的WRN-16-2时,本文比CMI高出了2.08个百分点的准确率。对于更复杂的场景Caltech-101,本文方法在蒸馏到MobileNet-V2 时与Deepinv 相比增加了3.89 个百分点的准确率。②在本文所采用的多教师集成的准确率和CIFAR-10 上的一个特定ResNet-34的准确率(≈95.7%)几乎一致时,本文方法在提取同一个学生时相比其他基线实现了显著的性能提升。这也就表明模型性能的提升来自于多教师结构和提出的对比交互损失,而不是简单来自于强教师。③教师和学生之间的同构结构有助于提高学生在所有基线中的表现。例如,在CIFAR-10上,本文使用相同的WRN-16-1 作为学生,相比于ResNet-34 作为教师,WRN-40-2作为教师时显著提高了学生WRN-16-1的准确率。④值得注意的是,本文的预训练教师没有使用MobileNet-V2,然而本文的合成图像仍然可以有效地训练模型。而且本文方法已经和使用原始数据训练的MobileNet-V2的准确度非常接近。这意味着使用本文提出的多教师对比知识反演方法的合成图像对于各种模型的训练具有很高的泛化性。⑤与其他方法相比,本文用不同的学生模型生成的数据集的FID值都是最低的,并且方差较小。这意味着本文的合成图像与原始数据集最一致。本文方法在CIFAR-10 数据集上的FID 值(即≈52.20)甚至可以与一些使用原始数据的GAN方法[8]相媲美。
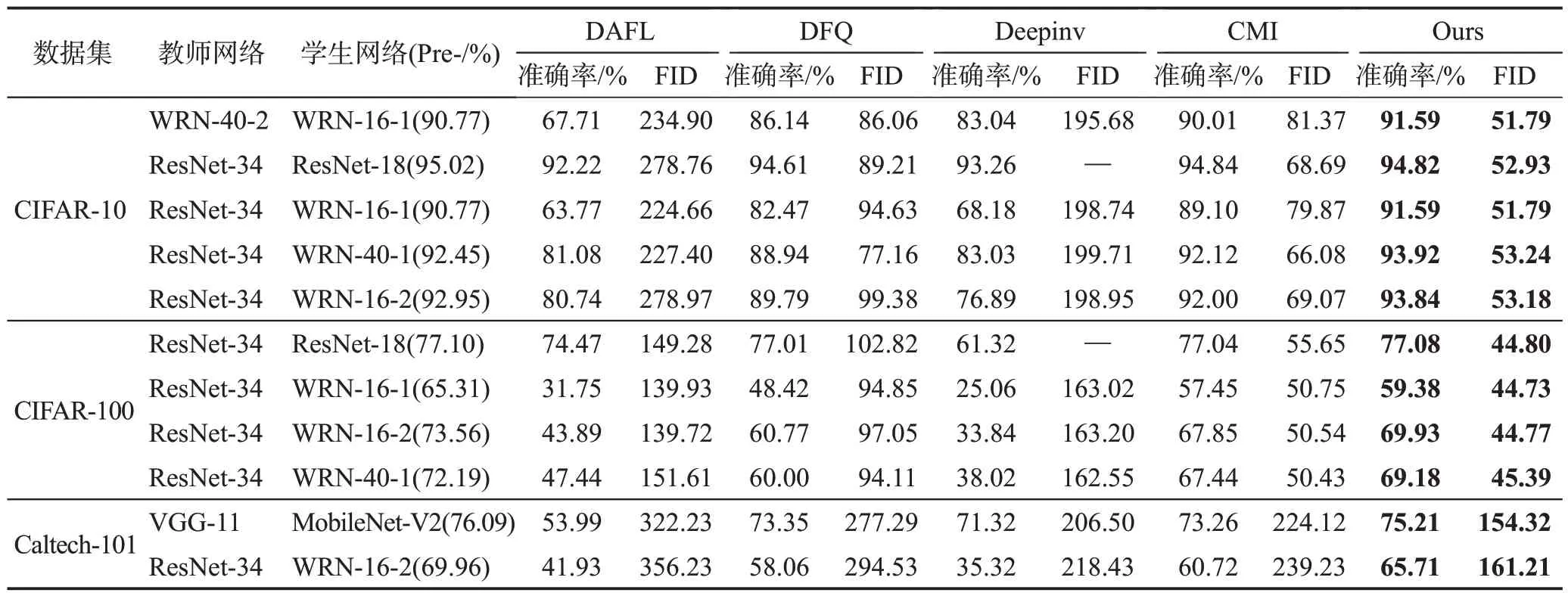
表2 在不同数据集上无数据蒸馏方法的结果Table 2 Results of data-free distillation on different datasets
(2)主观视觉分析。本文进一步将提出的方法与现有方法的合成质量进行比较,如图3 所示。与DAFL[6]、DFQ[9]、Deepinv[10]、CMI[7]相比,可以明显看出本文的多教师对比知识反演所生成的图像质量最高。例如,DAFL 使用CIFAR-10 数据集上的预训练教师生成的图像类似噪声图像。Deepinv 能够生成具有视觉特征的图像,但物体颜色与背景颜色接近,风格单一。因此,它与原始的CIFAR-10 数据集相距甚远。DFQ 和本文的合成图像之间的比较表明,本文提出的方法可以生成更多样化的图像,而DFQ 则遇到了明显的模式崩溃问题。尽管CMI合成的图像在颜色和风格上似乎有一些改进,但它们仍然过于模糊而无法区分。本文方法在对象轮廓的清晰度、颜色匹配的合理性方面提高了图像质量。对于CIFAR-10数据集,本文方法生成更多样化的语义图像,例如不同姿势的马的特写和各种类型的卡车。即使是像船后面的天际线这样的微小细节也能够清晰生成。对于CIFAR-100数据集,合成图像提供了丰富的语义信息,肉眼可以很轻松识别图3中显示的对象,如熊猫、自行车、鲜花。

图3 不同方法反演生成的图片展示Fig.3 Images inverted from pre-trained model by different methods
3.3 消融实验
为了评估本文方法的有效性,包括多教师的引入,对比交互损失、泛化性和多样性。本文选择CIFAR-10数据集中的预训练模型进行消融实验。
(1)超参数λ的敏感性。本文首先评估λ的敏感性。如表3所示,本文对不同学生网络设定下超参数敏感性做了实验,发现当λ设置为0.2 时蒸馏到不同的学生网络能够达到相对最佳的精度。为了方便讨论,本文将所有实验的λ设置为0.2。
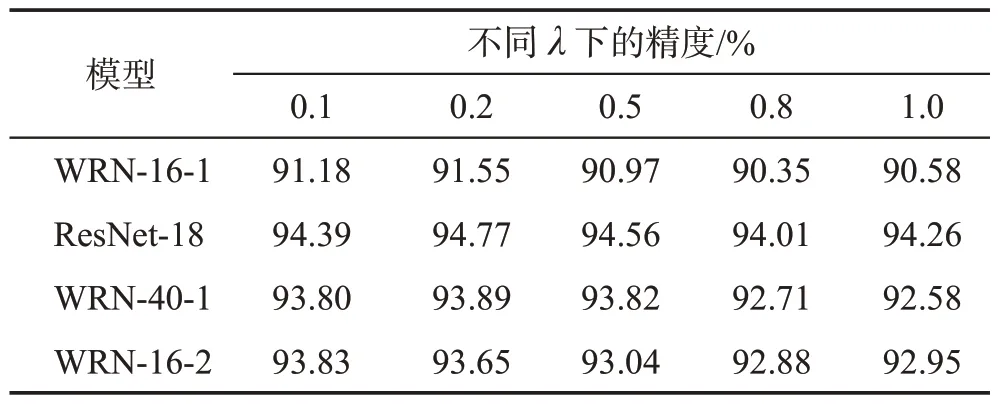
表3 蒸馏到不同网络结构时的超参数λ对结果的影响Table 3 Effect of hyper-parameter λ for distilling student networks
(2)集成教师网络个数的影响。本文进行了多教师集成的几种组合,其中教师的数量从1 到4。为了帮助学生学习更多样化的知识,本文选择了异构教师网络,即不同网络结构的模型作为教师。如表4所示,更多的教师相对来说可以达到更高的准确率。随着教师数量的增加,学生和教师集成的测试准确率的增长速度放缓,终于接近一个上限。当教师数量设置为3,达到了相对饱和的性能。考虑到计算开销,本文将实验中多教师的网络个数设定为3。
(3)对比交互损失的作用。本文研究了所提出的不同模块的贡献,包括多教师、教师内对比学习和师生对比学习。本文将每个模块单独关闭做cutoff来检测其有效性。如表5所示,本文使用mt(multi-teacher)、itcl(intra-teacher contrastive learning)、tscl(teacher-student contrastive learning)分别代表多教师、教师内对比学习和师生对比学习。实验数据表明使用多教师进行无数据蒸馏时直接将性能提高了5.7 个百分点。使用教师内对比损失函数可提升性能4.43 个百分点。当在多教师的基础上加入教师内对比损失时,WRN-16-1 的准确率相比于原始方法达到了大约8 个百分点的增益。在此基础上,本文进一步添加了学生-教师对比损失,对性能实现了进一步提升,使得本文的模型最终达到91.59%的准确率。这是由于教师模型中提取“多视角”知识并将其很好地融合到学生模型中,同时使用了对比交互方式,充分利用来自多位师生的知识,生成具有高泛化性和多样性的合成数据。

表5 不同组件在蒸馏过程中对算法的影响Table 5 Effect of different component combinations on algorithm during distillation
(4)合成数据的泛化性能分析。本文使用WRN-16-1作为学生,使用多教师对比知识反演方法得到的数据和CMI方法反演的数据从头开始训练不同结构的网络,由此来评估数据是否可以用于训练多种不同的网络。为了公平比较,在这两个方法合成数据时采用的训练参数和策略是相同的。
结果如表6 所示,与CMI 相比,本文方法实现了大幅提升(可高达8个百分点的提升)。此外,与原始CIFAR-10 数据集相比,使用本文方法的合成数据在从零开始训练教师方面达到了非常接近的准确性。注意到本文并没有使用Inception-V3 作为教师网络之一,而本文的合成图像仍可以有效地训练该模型。这意味着使用MTCKI的合成图像对于各种模型的训练具有很高的泛化性。
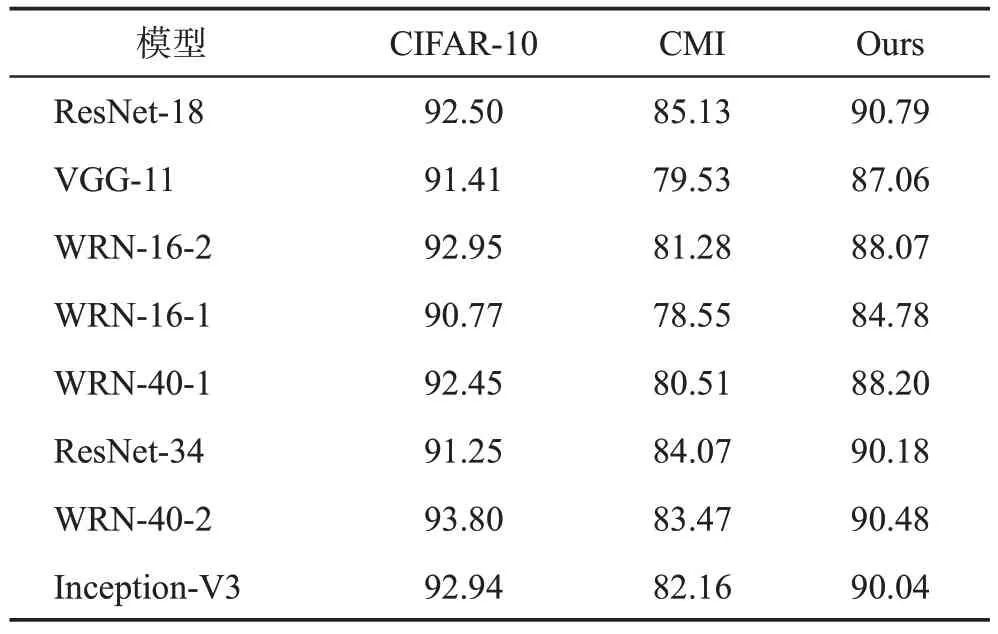
表6 将合成数据直接用于从头训练网络效果对比Table 6 Comparison of training model from scratch using inverted data 单位:%
(5)数据多样性分析。为了进一步评估本文方法在数据多样性方面的有效性,本文使用T-SNE[40]工具可视化MTCKI 和CMI 合成图像的数据分布情况。如图4 所示,对于本文方法,数据整体的分布较为分散,图片的特征分布较广,有效分开不同类别的数据分布,而具有相同类别的数据被很好地聚合。此分布与原始CIFAR-10 数据集十分接近。而CMI的数据点较为密集,图片的特征较为相似,表明不同类别的合成图像没有被解开。与CMI 相比,本文方法表现出更好的数据多样性。
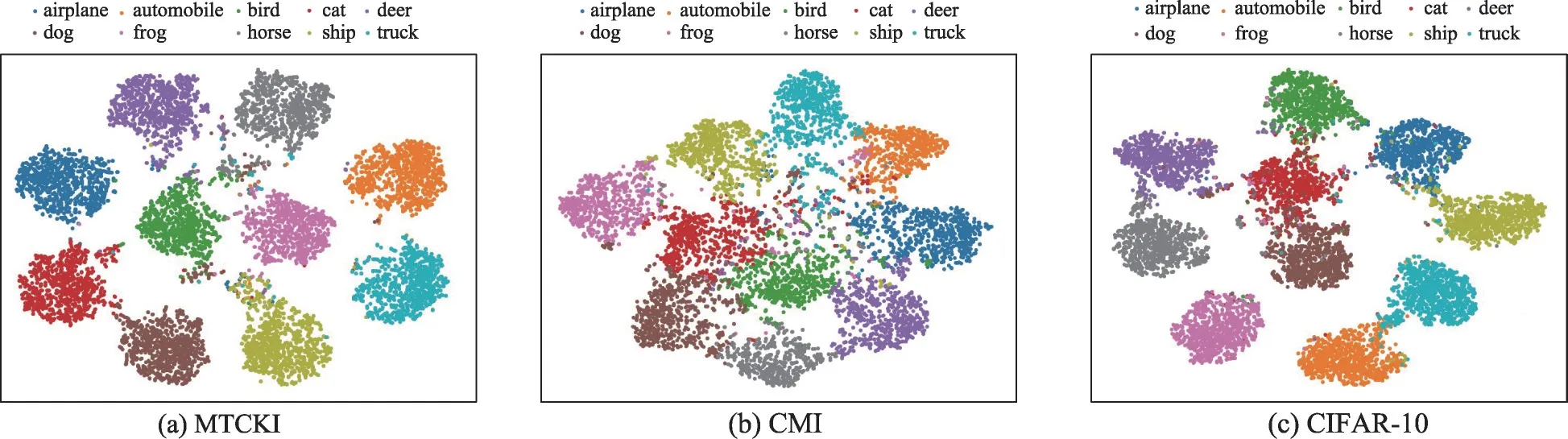
图4 CIFAR-10原始数据、CMI合成数据、MTCKI合成数据分布对比Fig.4 Distribution comparison among original CIFAR-10 data and data inverted by MTCKI and CMI
3.4 训练过程分析
由于生成对抗的方法在收敛时可能会出现不稳定的情况,本文进一步分析了本文方法的收敛性和不同epoch 下图像变化的情况。如图5 所示,本文方法可以稳定地收敛。与其他基线进行了可视化比较,本文方法需要更少的训练epoch 来收敛,且收敛到的损失最低。值得注意的是,在训练过程中,由于丰富的多教师信息和对比交互的有效性,如图6 所示,第10个epoch合成的图像已经具有多样化的语义信息和组织良好的物体轮廓。除此之外,本文还客观分析了对比交互损失对运算复杂度的影响,本文将其分成测试时间和训练时间两部分。在测试时间上,加入对比交互损失不会对最终的测试时间有影响,因为该损失相当于模型训练中的正则化项,测试过程中模型将不参与该部分计算。在训练时间上,对比交互损失确实会增加模型训练内存和时间开销。当使用对比交互损失在单卡NVIDIA 3090GPU上训练200 个epoch,需花费16.6 h,而不使用对比交互损失在单卡NVIDIA 3090GPU上训练200个epoch需要11.9 h。虽然对比交互损失在训练上会增大开销,但是在一次训练过程中合成的图片可以用于多次从头训练一个新的网络或用于有数据的知识蒸馏且准确率相比先前的方法都有较大提升,一定程度上节省了后续的开销,并提高了模型精度。
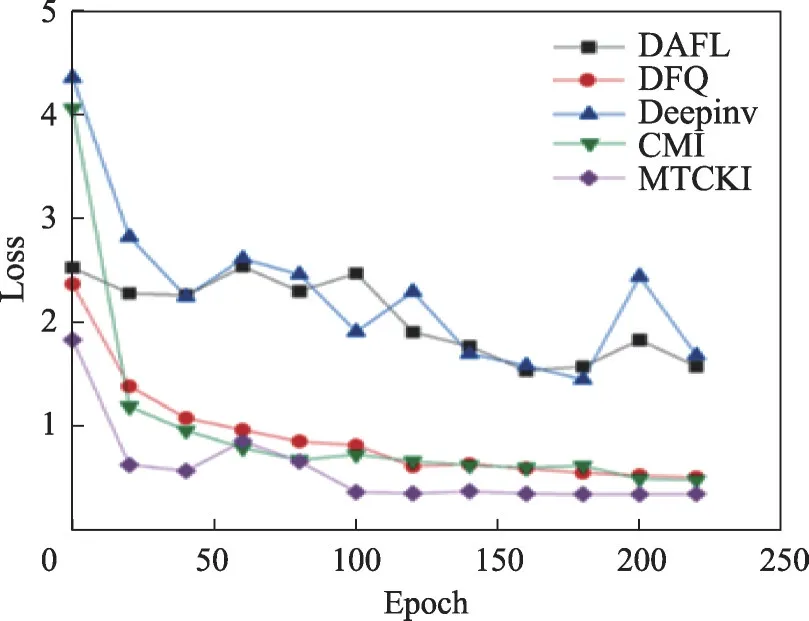
图5 不同方法在训练过程中的损失曲线对比Fig.5 Training loss curves of different methods during training

图6 不同回合阶段的合成图片的质量Fig.6 Quality of generated images in different epochs
4 结束语
本文提出了一种基于多教师对比知识反演的无数据知识蒸馏框架(MTCKI),该框架在提高学生网络表现的同时,以对抗的方式生成高保真度的训练数据。首先,本文提出了一种供应端-客户端合作的模式,用于数据保护下的模型压缩,然后构建了一个新的无数据知识蒸馏框架,从多个教师模型中提取“多视角”知识并将其很好地融合到学生模型中。此外,本文建立了多教师和学生之间的对比交互以提高合成图像的多样性。本文提出的MTCKI能将一次生成的图片数据用于蒸馏或从头训练多个不同的学生网络。本文综合评估了MTCKI 在各种CNN 架构上的性能,实验结果表明,MTCKI 不仅生成视觉上效果不错的图像,而且在性能上优于现有的无数据蒸馏方法。
