融合注意力机制和上下文信息的实时交通标志检测算法
2023-11-16冯爱棋吴小俊徐天阳
冯爱棋,吴小俊,徐天阳
江南大学 人工智能与计算机学院 江苏省模式识别与计算智能工程实验室,江苏 无锡 214122
交通标志检测任务是自动驾驶系统的重要组成部分。提前检测出前方的交通标志可以给驾驶系统和驾驶者提供极其关键的道路交通信息,如限速80 km/h、注意人行横道、禁止鸣笛等信息。由于交通标志尺寸小、遮挡变形、褪色老化和外界光线变化等因素,该任务充满了挑战。
在早期工作中,许多研究人员通常利用交通标志独特的颜色和形状特征来定位和识别交通标志[1-3]。他们通过方向梯度直方图(histogram of oriented gradients,HOG)[4]和尺度不变特征变换(scale-invariant feature transform,SIFT)[5]等方法,使用手工设计的局部特征来搜索可能包含交通标志的区域,再用分类器预测类别。尽管上述方法获得广泛的关注,但是人工设计的特征常独立于训练过程,因此这些方法在实际应用中常获得次优的性能,并且在上述提及的具有挑战性的场景中很难保持良好的泛化能力。
为了解决基于人工设计特征方法存在的问题,出现了许多基于卷积神经网络(convolutional neural network,CNN)的目标检测算法,该类方法可以在训练过程中学习更深层次的语义特征,相较于手工设计的特征具有更好的鲁棒性和泛化性。基于CNN的目标检测算法根据检测阶段划分可以归纳为两类:两阶段目标检测算法和一阶段目标检测算法。两阶段目标检测算法主要是基于R-CNN(region with convolutional neural network features)[6]的一系列算法,代表算法如Faster R-CNN[7]、Cascade R-CNN[8]和Mask R-CNN[9]等。该类方法首先利用区域提议网络(region proposal network,RPN)选择可能包含物体的感兴趣的区域(region of interests,RoI),然后对RoI进行分类和定位。而一阶段检测器则将目标检测视为回归任务,直接在图像上预测边界框和类别,包括SSD(single shot multibox detector)系列算法[10-11]和YOLO(you only look once)系列算法[12-15]等。这些通用的检测算法对于分辨率高、外观清晰的中大型物体检测效果很好,但对于像交通标志这类小目标表现不佳。MS COCO 数据集中将分辨率小于32×32 像素的目标定义为小目标。由于小目标在图像中占据很少的像素区域,CNN 在没有足够表观信息支撑的情况下很难学习到丰富的、有判别性的特征表示。为了提高小尺度交通标志的检测精度,可对RoI进行超分以保留更多的特征,例如Li等人[16]提出感知生成对抗网络(generative adversarial network,GAN),通过对RoI 的特征图进行超分操作以保留更多的小目标的特征,但是由于缺乏直接的高分辨率的特征图作为监督信号,经超分得到的高分辨率特征图的质量受到限制。
近年来,注意力机制在神经网络中得到广泛研究和应用[17-22],通过模拟人类感知系统中的信息处理方式,神经网络有选择地更加关注某些区域,聚焦更有价值的信息。SENet(squeeze-and-excitation networks)通过探索特征图中不同通道的重要程度,加强有用的特征并抑制不相关的特征,优化了通道结构,提高了网络的表征能力。Zhang 等人[20]通过将Faster R-CNN与通道注意力机制相结合来优化RoI 的特征来改善小尺度交通标志的检测精度。Wang等人[21]在特征金字塔网络(feature pyramid network,FPN)[23]的基础上利用自适应注意力模块和特征增强模块来减少特征图生成过程中的信息丢失,进而增强特征金字塔的表示能力,提高模型对小中大尺度交通标志的检测性能。郭璠等人[22]在YOLOv3 的基础上引入通道注意力和基于语义分割引导的空间注意力机制,使网络聚焦并增强有效特征,但该算法引入大量参数,不能满足检测实时性要求。
除了突出目标本身的表观信息,利用与待检测物体相关的物体或环境等上下文信息也有助于检测小目标[24]。以此概念为基础,为了能检测出小尺度人脸,Hu 等人[25]同时提取RoI 及其周围区域信息,利用周围区域中的人体信息提高对小尺度人脸的检测精度。为了充分利用上下文信息帮助检测小尺度交通标志,马宇等人[26]通过级联多个扩张卷积扩大感受野,从而补充物体周围的上下文信息。Chen 等人[27]提出交叉感受野模块增加模型的感受野,构建重要的上下文特征。区别于扩大感受野,Yuan 等人[28]提出的垂直空间序列注意力模块从垂直方向补充小尺度交通标志的上下文信息,改善算法对小尺度交通标志的感知能力。
尽管以上方法有效提高了交通标志的检测精度,但由于交通标志在图像中占比小以及背景干扰,在实际场景中仍存在较多漏检情况,并且已有方法不能很好地满足实时性要求。针对上述问题,本文基于YOLOv5 提出融合注意力机制和上下文信息的实时交通标志检测算法。由于交通标志通常出现在图像的固定区域,首先在主干网络中嵌入空间注意力模块,强化重要的空间位置特征,抑制干扰信息,提高主干网络的特征提取能力;另外在主干网络末端引入窗口自注意力机制,捕获全局上下文信息,挖掘与交通标志相关的周围信息来提高小尺度交通标志的检测精度。其次,利用Ghost 模块构建轻量的特征融合网络,对不同尺度的特征图进行融合,减少计算量的同时确保有效的特征融合;在后处理阶段,提出高斯加权融合方法对预测框进行修正,进一步提高检测框的定位精度。在TT100K 和DFG 交通标志检测数据集上的实验表明,本文算法具有较高的准确性,有效地改善了小尺度交通标志的漏检情况,同时检测速度可达80 FPS,可以满足实际场景中交通标志检测任务的高准确性和高实时性需求。
1 理论基础
1.1 YOLOv5目标检测算法
YOLOv5 检测算法广泛使用在学术研究和工业应用,根据网络深度和网络宽度的不同可分为YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x,模型计算复杂度逐渐增多,检测精度逐渐提升。YOLOv5主要由特征提取主干网BackBone、特征融合Neck和检测头Head三部分构成,如图1所示。
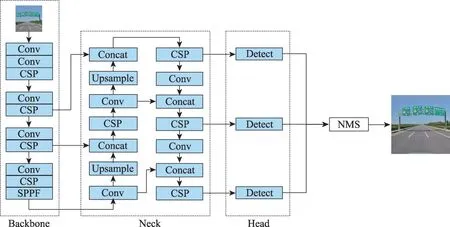
图1 YOLOv5模型结构图Fig.1 Model structure of YOLOv5
BackBone 作为主干网络用于提取特征,主要由Conv、CSP(cross stage partial)和SPPF(spatial pyramid pooling fast)等模块组成,如图2 所示。Conv 模块是由卷积、批标准化(batch normalization,BN)和Sigmoid 线性单元(Sigmoid linear unit,SiLU)组成的基本卷积单元。SPPF 模块首先通过1×1 卷积压缩通道,然后相继经过3个不同尺寸(5、9和13)的最大池化,最后用1×1 卷积调制通道数与输入通道数相同。多尺度的池化操作丰富了感受野,同时有助于解决anchor和特征图的对齐问题。相较于SPP,SPPF在保持精度的同时减少参数量和计算量,加快推断速度。CSP模块是YOLOv5中最重要的特征提取模块,左右分支分别采用1×1 卷积将通道数缩减一半,然后左分支输进一个残差块,最后将两个分支的特征进行拼接并用1×1 卷积优化拼接后的特征。CSP模块通过将部分特征进行更深的特征提取,减少冗余特征且补充原始的特征,获得语义丰富的特征图。
Neck部分是路径聚合网络(path aggregation network,PANet)[29],PANet 在FPN 的基础上增加了自下而上的分支,将FPN中浅层的位置信息,通过该分支逐步传递到深层中,增强深层中的位置信息。通过自上而下、自下而上两个分支和单边连接,增强了各个输出层级的位置信息和语义信息,优化了各个输出层级的特征表示。
Head部分的核心是预测,对于Neck中输出的三种不同尺度的特征图,Detect模块采用1个1×1 卷积将通道调制为B×(5+C)维的预测向量,其中,B为每个网格点的预测框数,5+C对应目标的4 个回归参数、置信度和C个类别概率,最后通过非极大值抑制(non-maximum suppression,NMS)剔除冗余的检测框保留剩余的预测框。
1.2 多头自注意力
在过去的两年中,Transformer 在许多计算机视觉任务中展现了出色的性能[30-31]。Transformer 将图像划分为一系列图像块,通过多头自注意力(multihead self-attention,MHSA)从全局学习图像序列之间的复杂依赖关系,捕获全局信息和丰富的上下文信息。多头自注意力有助于学习物体之间及物体与周围环境的关系,对小物体和被遮挡物体表现良好。给定一个图像输入序列X∈RN×d,多头自注意力包含h个头,对于自注意力头i,SAi执行如下运算:
2 融合注意力机制和上下文信息的实时交通标志检测算法
针对现有的交通标志检测算法常无法满足检测实时性要求且在小尺度交通标志检测时存在较多漏检的问题,本文以YOLOv5 中最小的检测模型YOLOv5s作为基准模型,提出融合注意力机制和上下文信息的实时交通标志检测算法。首先,在主干网络中嵌入设计的跨阶段局部空间注意力(cross stage partial spatial attention,CSP-SA)模块以强化关键位置特征,提高主干网络的特征提取能力;其次,在主干网络末端引入窗口自注意力机制,设计跨阶段局部窗口Transformer(cross stage partial window transformer,CSP-WT)模块用于学习不同位置信息的关联性,捕获物体周围的上下文信息;再次,利用Ghost 模块构建Ghost 路径聚合网络(ghost path aggregation network,Ghost PAN)对不同尺度的特征图进行高效融合;最后,采用高斯加权融合方法修正预测框,进一步提高预测框的定位精度。本文算法的总体结构图如图3所示。

图3 本文算法的总体结构图Fig.3 Overall framework of proposed method
2.1 跨阶段局部空间注意力模块
首先,针对交通标志检测这一特定目标检测任务,图4 统计了交通标志在TT100K 数据集上的位置分布情况,可以发现,交通标志一般处在图像的中部区域,聚焦于该区域的特征提取可以提高交通标志的定位精度。
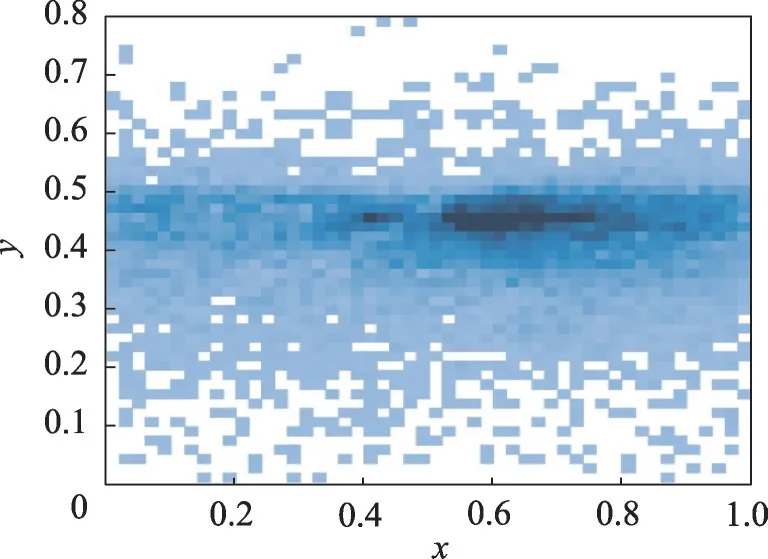
图4 TT100K数据集上交通标志位置分布图Fig.4 Location distribution of traffic signs on TT100K dataset
同时,交通标志一般都设置在警示牌或交通杆上,聚焦这些关键区域有助于提高检测精度。基于该发现,本文在主干网络的CSP模块中嵌入空间注意力机制,设计CSP-SA(cross stage partial spatial attention)模块,如图5 所示。CSP-SA 模块加强了感兴趣的空间区域,抑制不相关的区域,进一步强化主干网络的特征学习能力。对于输入特征图F∈RC×H×W,H、W、C分别表示特征图的高、宽和通道数,首先输入上下两个分支并分别采用1×1 卷积将通道数缩减一半,上分支得到特征图,将下分支得到的特征图从通道维度上分别选择最大值和平均值,并将得到特征图拼接得到特征图,F′的具体实现公式为:
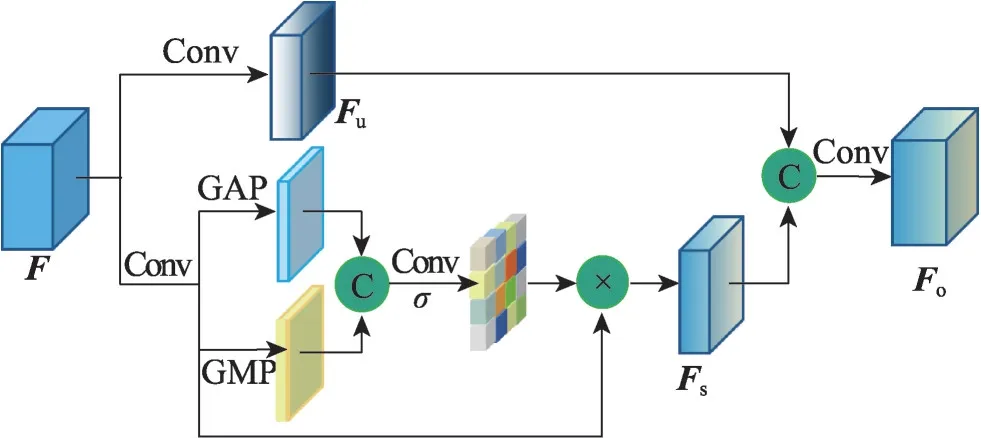
图5 CSP-SA模块Fig.5 CSP-SA module
式中,GAP(∙)表示全局平均池化,GMP(∙)表示全局最大池化,Concat(∙)表示通道拼接。F′包含了每个位置点的平均值和最大值信息,然后通过1×1 卷积从F′中学习每个位置点的权重,接着采用Sigmoid激活函数获得0到1之间归一化的空间权重图,最后将空间权重图与Fd进行逐位相乘操作,即将注意力权重图逐像素点加权到Fd的每个特征点上,得到经过空间注意力增强的特征图,Fs的具体实现公式为:
CSP-SA 模块通过在CSP 模块中引入空间注意力机制,学习空间注意力权重图实现对原始特征图的空间位置进行不同程度的加强和抑制,使得最终的特征图更关注含有交通标志的空间位置。相较于直接使用空间注意力模块,CSP-SA模块减少了冗余特征,具有较少的计算量,同时补充了原始特征,获得了语义更加丰富的特征图。
2.2 跨阶段局部窗口Transformer模块
已有的交通标志方法通过扩张、叠加感受野获得上下文信息,缺少对全局上下文信息的利用,而本文利用Transformer 学习不同像素点之间的关系,与CSP 相结合设计了轻量有效的跨阶段窗口Transformer模块,从全局和局部捕捉交通标志周围有价值的信息,改善交通标志的漏检情况。多头自注意力可以学习图像像素点之间的依赖关系,捕获图像中目标与场景或目标与目标之间的关联信息,利用小目标周围的上下文信息,进而帮助检测小目标。但是,在高分辨率特征图上做全局自注意力的计算复杂度和内存消耗是巨大的。为了提高计算效率并且减少内存消耗,本文结合窗口Transformer 和CSP 设计CSP-WT(cross stage partial window Transformer)模块,有效地减少了计算量和内存消耗,同时可以捕获物体周围的上下文信息,改善物体的漏检情况。如图6 所示,窗口Transformer 包含两层:第一层是窗口多头自注意力(window multi-head self-attention,W-MHSA),通过将特征图平均划分为多个子窗口,然后在局部窗口中计算自注意力;第二层是一个多层感知机(multilayer perceptron,MLP)。其中,每一层都包含层归一化(layer norm,LN)和残差连接。对于特征图F∈RC×H×W,局部窗口大小为K×K,全局的MHSA和基于窗口的W-MHSA的计算复杂度如下:
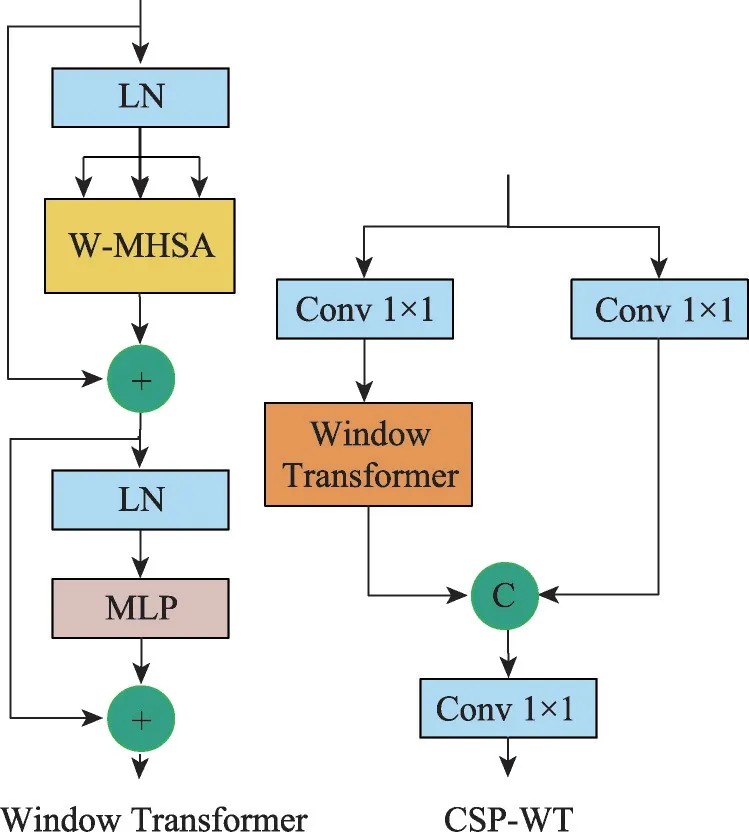
图6 Window Transformer和CSP-WT模块结构图Fig.6 Structures of Window Transformer and CSP-WT modules
对于高分辨率特征图,基于窗口的自注意力计算复杂度大大降低。为了进一步减少计算量同时保留CNN 和Transformer 的特征,设计CSP-WT 模块,将窗口Transformer 嵌入到CSP 模块中,如图6 右图所示,左侧分支利用1×1 卷积减少通道数进而减少Transformer 的计算量和内存消耗,右侧分支的1×1卷积保留CNN 提取的特征,最后进行通道拼接获得丰富且有判别性的特征表示。
2.3 轻量的特征融合网络
Han 等人[32]指出卷积神经网络中的特征图存在大量相似的特征图,这些相似的特征图可以通过廉价的操作获得并提出Ghost 模块,如图7 所示。对于输入特征图F,首先通过1×1 卷积将通道数减半获得本征特征图FI,再采用线性操作如分组卷积对其进行变换获得Ghost 特征图FG,最后拼接本征特征图和Ghost特征图。
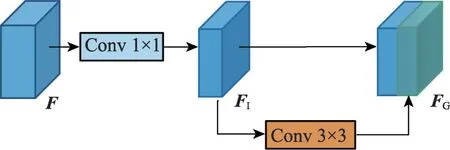
图7 Ghost模块Fig.7 Ghost module
对于输入的特征图F∈RC×H×W,第一层1×1卷积的参数量为1×1×C×C′,第二层k×k分组卷积的参数量为,其中,k和g分别表示分组卷积的卷积核大小和分组数。在本文中,C′和g都为C的一半,Ghost模块的参数量为。常规的k×k卷积的参数量为k×k×C×C,记作P2。参数量压缩比rc计算如下:
常规卷积的参数量约为Ghost 模块的2k2倍,表明Ghost 模块可以极大地减少参数量。本文利用Ghost 模块构建轻量的特征融合网络Ghost PAN,如图3所示,可以在节省参数量和计算量的同时保持特征融合效果。
2.4 高斯加权融合方法
对于检测头产生的大量的预测框,YOLOv5中采用NMS筛选预测框。首先选择置信度得分最高的预测框,然后剔除与其交并比(intersection over union,IoU)值大于等于阈值的框,保留小于阈值的框。由于NMS 直接将与其IoU 值大于等于阈值的框去除,如果得分最高的框的定位不一定精准,而被剔除的框中包含有定位更精准的框,则会导致定位精确的框被剔除,如图8(b)所示,经NMS 处理后保留的预测框的定位精度并不高。为了进一步提高定位精度,本文提出高斯加权融合(Gaussian weighted fusion,GWF)方法。首先,将得分最高的预测框作为基准框,将与其IoU 值大于等于阈值的框视作候选框,将这些候选框按置信度得分从大到小排序选择N个框,计算N+1 个框的均值框bmean。区别于Li等人[33]直接采用IoU作为权重系数的边界框加权融合策略,为了更好地保留高IoU的预测框,本文对于保留的预测框采用高斯权重系数加权融合,得到最终的预测框bmerge。在消融实验中,验证了高斯加权相较于线性加权具有更好的定位精度。
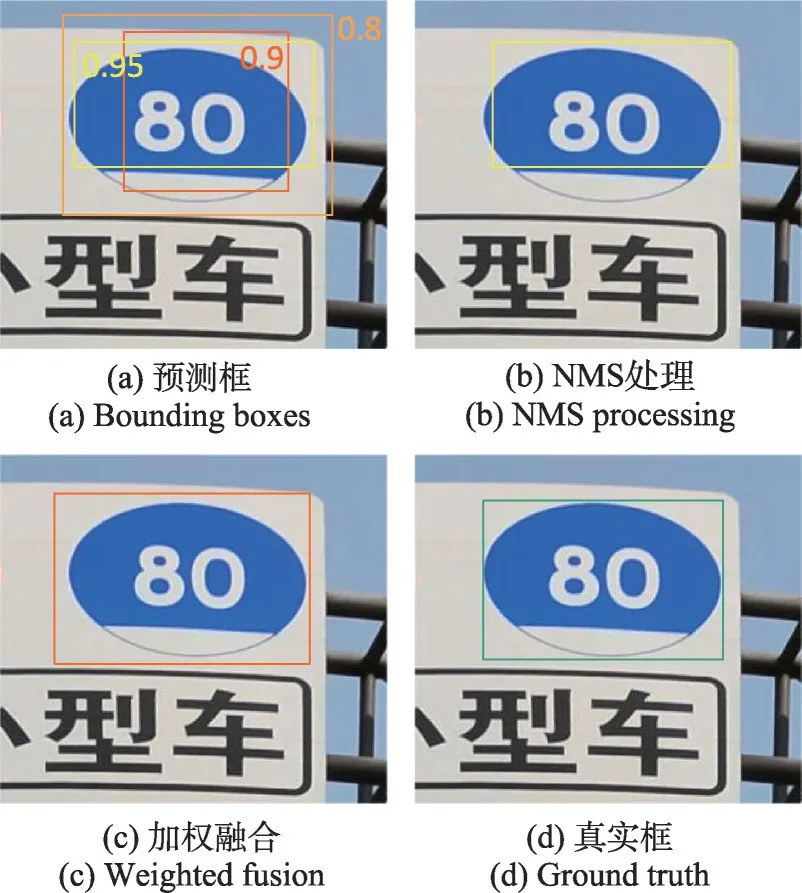
图8 NMS和高斯加权融合方法对比Fig.8 Comparison of NMS and Gaussian weighted fusion method
如图8(c)所示,该方法有效地修正了预测框,更贴近真实框。具体公式如下:
其中,bi表示第i个候选框,bmean表示均值框,IoUi表示bi和bmean的交并比,wi表示经过高斯函数处理后的权重系数,bmerge表示最终融合的预测框。
2.5 损失函数
总损失函数由置信度损失、分类损失和定位损失三部分组成。
2.5.1 置信度损失
采用二元交叉熵损失计算目标置信度损失。每个预测层有S2个网格点,每个网格点负责预测B个预测框。表示第i个网格点的第j个预测框是否包含物体,如果有物体,=1,否则为0。表示第i个网格点的第j个预测框对应的预测值。置信度损失函数定义为:
2.5.2 分类损失
分类损失是根据类别预测向量计算预测类别与真实标签的交叉熵损失。表示第i个网格点的第j个基准框是否负责这个目标,如果负责,,此时需要对这个基准框回归的预测框计算分类误差,否则不计入分类损失。和分别表示第i个网格点的第j个预测框对应的某个类别的真实值和预测概率值。分类损失函数定义为:
2.5.3 定位损失
IoU是衡量预测框和真实框的重合程度,直接使用IoU作为损失函数会存在一个问题,如果两个框不相交则IoU 为0,无法反映两个框的位置关系。本文的定位损失采用CIoU(complete IoU)损失函数,CIoU进一步考虑了预测框与真实框的中心点距离和宽高比一致性,可以解决IoU 损失存在的问题,并能加快网络收敛,定义为:
其中,B表示预测框(x,y,w,h),Bgt表示真实框(xgt,ygt,wgt,hgt),bgt、wgt和hgt分别表示真实框的中心点、宽和高,b、w和h分别表示预测框的中心点、宽和高。ρ(∙)用于计算两点的欧几里德距离,c表示包围真实框和预测框的最小矩形框的对角线长度。αv用于控制预测框的宽高尽可能与真实框的宽高接近,其中,,α为权衡参数,v用来衡量长宽比的一致性。总损失函数定义为:
其中,λobj、λcls和λbox分别表示置信度损失、类别损失和定位损失的权衡因子。
3 实验及结果分析
3.1 TT100K交通标志检测数据集
TT100K[34]交通标志检测数据集包含9 176 张标注图像,其中,6 105 张训练图像,3 071 张测试图像。所有图像采集于现实生活场景,分辨率为2 048×2 048像素。和Zhu 等人一样[16,34-36],选择交通标志数超过100的45个类别进行实验评估,如图9所示。对于一些很少见的交通标志,原数据集将其标注为大类别,如“io”表示与指示相关的交通标志,“po”代表与禁止相关的交通标志,“wo”表示与警示相关的交通标志。
图9 TT100K数据集上参与评估的45个类别Fig.9 45 categories for evaluation on TT100K dataset
3.2 DFG交通标志检测数据集
DFG[37]交通标志检测数据集采集现实场景中遮挡、阴影和阳光直射等环境下的图像,交通标志具有不同的大小、长宽比,且包含文本和符号。该数据集由200 个类别共6 957 张图片组成,大多数的图像分辨率为1 920×1 280 像素,包含大量外观相似的交通标志。训练集有5 254 张图片包含14 208个标注,测试集有1 703 张图片包含4 393 个标注。DFG 数据集上包含许多方向相反的交通标志,如图10 所示,因此训练时不适合使用水平翻转数据增强策略。
3.3 评估指标
在检测准确性评价指标方面,采用目标检测任务中常用的平均精度均值(mean average precision,mAP)。真正例(true positive,TP)表示检测到的交通标志是正确的,假正例(false positive,FP)表示检测到的交通标志是错误的,假负例(false negative,FN)表示漏检的交通标志。当IoU大于或等于阈值时,预测框被视为真正例,否则为假正例。精确率(precision,P)主要衡量模型的错检程度,召回率(recall,R)主要衡量模型的漏检程度,F1得分综合考虑了精确率和召回率,计算方式如下:
平均精度(average precision,AP)表示精确率-召回率(precision-recall,P-R)曲线与坐标轴包围的面积,是结合了精确率和召回率的综合指标,可全面评估目标检测模型。mAP 是所有类别的AP 的均值,mAP 值越大表明检测效果越好。AP 和mAP 的计算方式如下:
其中,N表示类别数量,APi表示第i个类别的平均精度。
此外,还比较了不同IoU下和不同尺度下的mAP,AP50和AP75用于评估IoU 阈值为0.50 和0.75 下mAP,APS、APM和APL分别用于评估检测小、中、大尺度目标的mAP。为了进一步衡量模型大小和速度,还评估了模型参数量(Params)、每秒浮点运算次数(FLOPs)和每秒处理图片数(FPS)。
3.4 实验设置
本文实验的主要环境为:Ubuntu 16.04 操作系统,Intel Core i9-10980XE CPU 和两块NVIDIA GeForce RTX 2080Ti GPU,Pytorch1.7.1框架,训练和测试图像大小为1 024×1 024 像素。Faster R-CNN[7]、Cascade R-CNN[8]和Sparse R-CNN[38]都是基于MMDetection[39]目标检测框架实现,Backbone 为ResNet-50,Swin-T+Cascade R-CNN 的Backbone 为Swin-T[31],采 用FPN多尺度检测结构,训练12 个周期,用两块GPU 进行训练,每块GPU 训练两张图片。YOLOv3-tiny[13]、YOLOv5s[14]、YOLOX-s[40]、YOLOv6s[15]和本文算法采用一块GPU训练,批训练大小为16,训练周期为300。所有模型都采用COCO预训练权重作为初始化权重。本文基于YOLOv5的实验皆为6.0版本[14]。
3.5 TT100K数据集实验结果分析
将本文方法在TT100K 测试集上的检测结果与其他方法进行综合比较,如表1所示,可以看出,与两阶段目标检测算法Faster R-CNN、Cascade R-CNN相比,本文方法在mAP上都有较大提升。与基准模型YOLOv5s 相比,mAP和AP50分别提高1.4 个百分点和1.3 个百分点。和YOLOX-s 相比,本文方法在mAP上提高2.7个百分点,在小尺度交通标志上mAP提高1.0 个百分点。与最新的YOLO 系列算法YOLOv6s 相比,mAP和AP50分别高出0.4 个百分点、0.3 个百分点,同时本文方法的参数量只有5.7×106,相较于YOLOv6s的1.72×107的参数量,模型更小,速度更快,更适合车载设备。本文方法FPS达到80,可以满足真实驾驶场景中的实时性要求。
表2 对比了其他先进的交通标志检测算法[15,34-36]在IoU 阈值为0.5 下小、中和大尺度的P、R和F1 结果。和Zhu等人[34]的方法相比,在小尺度、中尺度和大尺度上,本文方法在精确率上分别提高3.4个百分点、4.6个百分点和1.7 个百分点,召回率分别提高4.1 个百分点、2.4个百分点和5.3个百分点。在所有对比方法中,本文方法在小尺度上取得了最高的F1 得分88.2%,与Deng 等人[36]提出的方法相比,在小尺度上召回率提高1.5个百分点,F1提升1.1个百分点,这也表明了该方法在精确定位和分类小尺度目标上具有更好的性能。
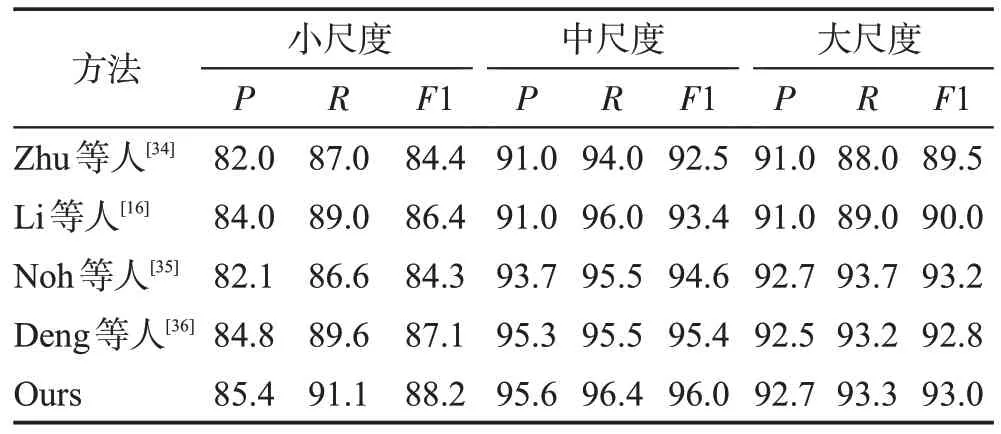
表2 不同交通标志尺寸下TT100K数据集上检测结果对比Table 2 Comparison of detection results on TT100K dataset with different sizes of traffic signs 单位:%
图11 展示了本文方法和YOLOv5s 在TT100K数据集上的可视化检测结果。上栏是YOLOv5s,下栏是本文方法,为了便于观察,放大包含交通标志的区域并置于图像下方。从第一列图像可以看出,YOLOv5s 和本文方法都能准确地检测交通标志,但本文方法检测出的交通标志得分更高、定位更准,表明本文提出的高斯加权融合方法对交通标志检测框定位更准确。在第二列图像中,原YOLOv5s 漏检了位于杆上的小尺度交通标志,而本文方法成功检测出较小的pl30 和w55 两个交通标志。在第三列图像中,对于远处的限高杆上的p26 和ph4.5 两个小尺度交通标志,本文方法仍然可以准确检测到,这得益于本文引入的注意力机制和上下文信息,通过利用交通标志周边的相关信息改善小尺度交通标志的漏检情况,提高检测精度。可视化结果表明本文方法有效地改善小尺度交通标志的漏检情况,可以更准确地检测出小尺度交通标志。

图11 YOLOv5s和本文方法在TT100K数据集上可视化对比Fig.11 Visual comparison of YOLOv5s and proposed method on TT100K dataset
3.6 DFG数据集实验结果分析
为了进一步验证本文方法的泛化性,在DFG 数据集上进行实验,DFG数据集包含200个类别且存在大量的小尺度交通标志。表3 显示了本文方法和其他先进的检测算法在DFG 数据集的性能对比。和Faster R-CNN、Cascade R-CNN 和Sparse R-CNN 相比,本文方法在mAP上分别提高5.0个百分点、2.6个百分点、7.3 个百分点。相较于基准模型YOLOv5s,本文方法mAP提高1.5个百分点,AP50提高2.5个百分点。和最新的YOLO 系列算法YOLOv6s 相比,AP50提高1.1个百分点,YOLOv6s的参数量为1.73×107,计算量为113.7 GFLOPs,而本文方法的参数量只有6.1×106,同时计算量更少,FPS 提高27。在所有方法中,本文方法取得了最高的AP75,达到83.4%,这表明本文方法的检测框更精确。在DFG数据集上的可视化检测结果如图12所示:在第一列图像中,本文方法准确检测出位于远处的III-6交通标志;在第三列图像中,原YOLOv5s漏检了位于道路上的II-47.1标志,本文方法则成功地检测到该小尺度交通标志,YOLOv5s将II-22标志误检为II-33,将I-14标志误检为II-30-40标志,而本文方法对图像中3个标志均正确定位与识别。从DFG 数据集上的可视化可以看出,本文方法相较于YOLOv5s 检测得分更高,且能检测出小尺度交通标志,有效地缓解了小尺度交通标志的漏检情况,同时也证明了本文方法具有良好的泛化性。
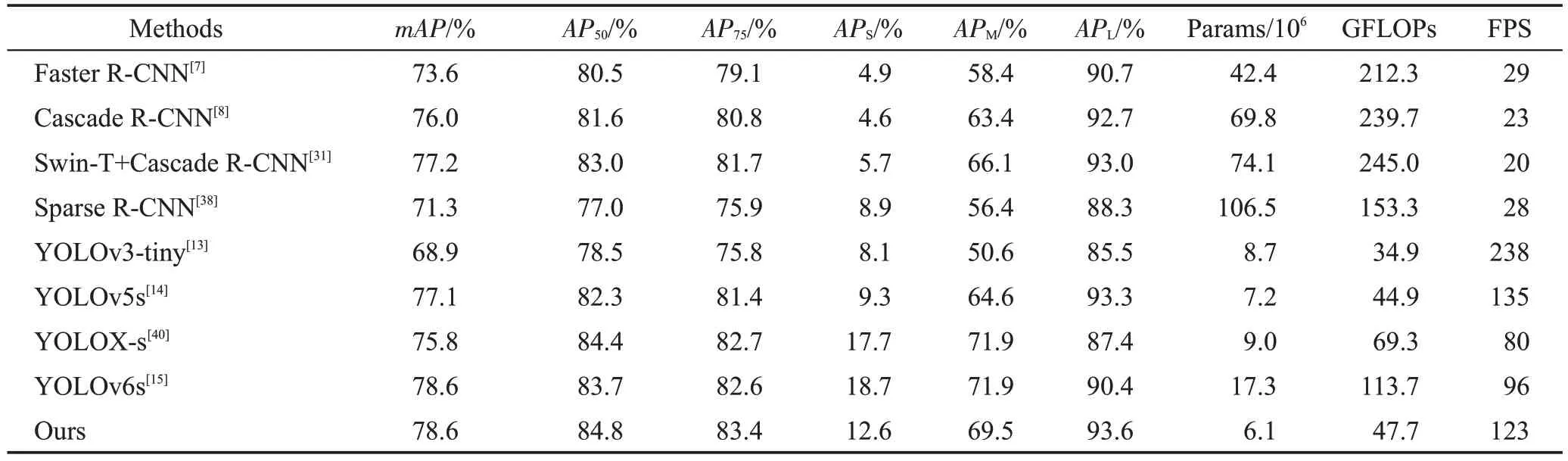
表3 不同方法在DFG数据集上检测结果对比Table 3 Comparison of detection results of different methods on DFG dataset

图12 YOLOv5s和本文方法在DFG数据集上可视化对比Fig.12 Visual comparison of YOLOv5s and proposed method on DFG dataset
参照Tabernik 等人[37]的实验条件,表4 对比不同交通标志尺寸下DFG数据集上的结果,表中“min 30 px”表示交通标志的最小尺度为30 像素进行训练和测试。从表中可以看出,本文方法在不同交通标志尺寸都取得最高的mAP50,且在“min 30 px”条件下相较于Tabernik 等人方法提升0.8 个百分点,进一步表明本文方法在检测小尺度交通标志上的优越性。
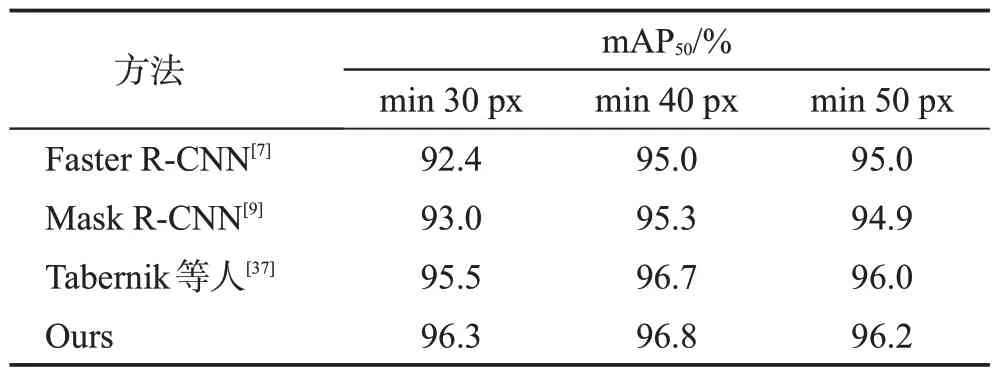
表4 不同交通标志尺寸下DFG数据集上检测结果对比Table 4 Comparison of detection results on DFG dataset with different sizes of traffic signs
3.7 消融实验
为了验证本文方法的有效性,在TT100K交通标志检测数据集上进行消融实验,如表5所示。本文方法的基线为YOLOv5s。CSP-SA 表示在主干网络中嵌入的跨阶段局部空间注意力模块,引入CSP-SA后,mAP和AP50分别提高0.3 个百分点和0.5 个百分点。CSP-WT 表示本文设计的跨阶段局部窗口Transformer模块,引入该模块后mAP提高0.8个百分点,AP50提高0.7个百分点,AP75提高0.5 个百分点,表明该模块可以通过捕获交通标志周围的上下文信息改善检测精度。本文提出的CSP-SA 模块和CSPWT 模块对于检测精度的提升较高,表明本文融合注意力机制和上下文信息的合理性。本文利用Ghost 模块构建的轻量的特征融合网络Ghost PAN有效地减少了模型的参数量和计算复杂度,同时还能保持检测精度。GWF 表示在后处理阶段采用高斯加权融合方法对预测框进行修正,GWF 进一步提高了预测框的定位精度。消融实验验证了本文方法的有效性。
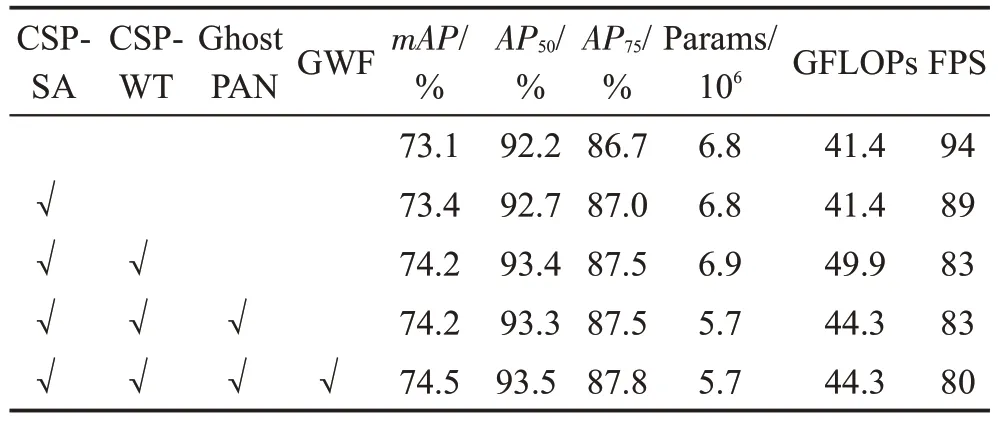
表5 本文方法在TT100K数据集上的消融实验Table 5 Ablation experiments of proposed algorithm on TT100K dataset
为了验证本文提出的高斯加权融合方法中采用高斯系数的有效性,对比了线性系数和高斯系数,线性系数是直接采用IoU作为权重系数,高斯系数是经过高斯函数处理后的,为,结果如表6 所示。从表中可以看出,采用高斯系数作为权重系数相较于线性系数具有更高的mAP 和AP50。当IoU 较高时,采用高斯系数作为权重相较于线性系数具有较高的值,可以给高IoU分配高的权重;同时,随着IoU降低,高斯系数下降平缓,有利于给高IoU 的预测框分配高的权重。

表6 不同权重系数在TT100K数据集上的消融实验Table 6 Ablation experiments with different weighted coefficients on TT100K 单位:%
4 结束语
本文提出融合注意力机制和上下文信息的实时交通标志检测算法,在主干网络中嵌入空间注意力机制用于强化包含交通标志的空间位置特征,另外采用窗口Transformer 学习不同位置信息的关联性,捕获物体周围的上下文信息。在特征融合阶段,构建轻量的特征融合网络,在减少参数量的同时确保有效的特征融合。最后,在预测框后处理阶段提出高斯加权边界框融合方法,进一步提高检测框的定位精度。实验表明,本文算法有效地提高了小尺度交通标志的检测精度,且满足检测实时性要求。在后续研究中,计划结合去雨去雾算法和检测算法改善雨雾环境下的交通标志检测效果。
