面向知识图谱补全的归纳学习研究综述
2023-11-16梁新雨司冠南李建辛田鹏新安兆亮周风余
梁新雨,司冠南+,李建辛,田鹏新,安兆亮,周风余
1.山东交通学院 信息科学与电气工程学院,济南 250357
2.山东大学 控制科学与工程学院,济南 250000
谷歌自2012 年首次引入知识图谱(knowledge graph,KG)概念以来,在人工智能领域以极快的速度飞速发展。随着KG 深入的研究和应用,KG 被广泛用于各种与人工智能相关的任务,如智能问答[1]、推荐系统[2]和网络安全系统[3]等领域。虽然KG 被广泛使用,但是随着现实世界数据的指数级增长,现有的KG知识大多是有噪声和不完整的。例如,在开放知识图谱Freebase 中,约有71%的人缺少出生地信息,99%的没有民族信息[4]。
为了解决KG不完整的问题和提高KG在下游应用中的效用,有必要进行知识图谱补全(knowledge graph completion,KGC)。传统KGC 方法假设测试时所有的实体和关系都出现在训练过程中,由于现实世界KG的演变性质,一旦出现不可见实体或不可见关系需要从头开始重新训练KG。比如DBPedia从2015 年底至2016 年初,平均每天新增200 个实体[5],但是频繁添加实体可能会导致开销大幅增加。为了解决这一问题,一些学者旨在补全包含不可见实体或不可见关系的三元组,而无需从头训练KG。
然而不同的作者在概念上使用不同的名称来描述相同的任务,因此存在术语鸿沟。比如一些学者使用文本描述或图像等额外信息嵌入新实体称为开放世界(或零样本)KGC[5-7];一些学者关注KG的长尾关系,预测可见实体间的不可见关系称为少样本KGC[8-10];一些学者通过聚合原始KG中现有邻居信息嵌入的新实体或新关系称为OOKG(out-of-knowledgegraph)实体或OOKG 关系[11-13];现有的研究更多地将新实体或新关系称为不可见实体或不可见关系,将该任务称为面向KGC的归纳学习[14-16]。
从归纳式知识图谱补全的理论角度出发,Ali 等人[15]将归纳式KGC 分为半归纳和全归纳的KGC,半归纳式KGC不可见实体必须链接到原始KG,全归纳式KGC 预测新兴KG 的不可见实体。Sack 等人[16]在Ali等人[15]基础上考虑全归纳式不可见关系问题。但是上述都忽略了半归纳式不可见关系问题。本文提出一个统一的框架,将开放世界、零样本和少样本KGC统称为面向KGC的归纳学习,将新实体、OOKG实体统称为不可见实体,关系同理。本文正式描述归纳设置,如图1 所示,(a)图为半归纳式KGC 解决原始KG 的不可见实体或不可见关系问题,(b)图为全归纳式解决新兴KG 的不可见实体或不可见关系问题,第1章预备知识给出了详细的定义并从该角度分类了全部的模型。
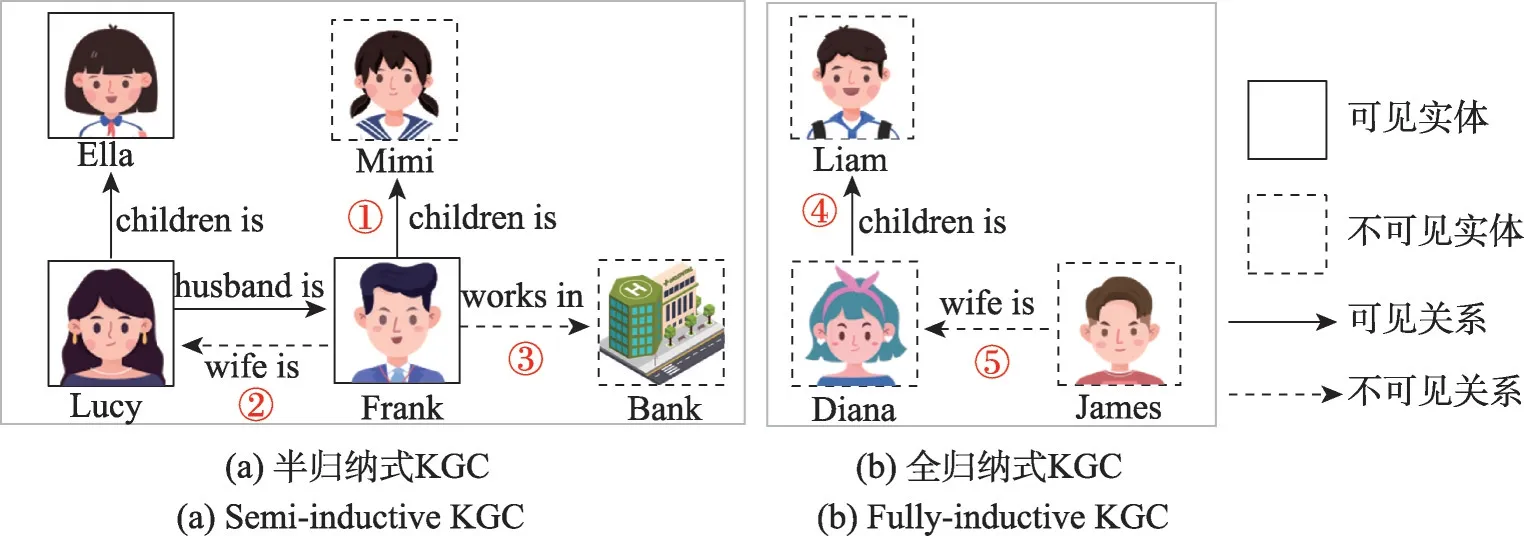
图1 归纳式知识图谱补全Fig.1 Inductive knowledge graph completion
从归纳式知识图谱补全的技术角度出发,本文对归纳式知识图谱补全的各类方法进行归纳总结。如图2所示,首先根据有无使用额外信息(文本、时序等)将归纳式知识图谱补全方法分为基于结构信息的归纳式KGC 和基于额外信息的归纳式KGC。根据汇总分类目前研究将基于结构信息的归纳KGC分为三类:基于归纳嵌入、基于逻辑规则和基于元学习的方法。它们主要区别在于如何处理不可见实体或不可见关系。其中基于归纳嵌入的方法旨在通过聚合邻居节点特征嵌入不可见实体或不可见关系;基于逻辑规则的方法通过显式和隐式地挖掘逻辑规则,因为逻辑规则独立于实体,因此对新兴KG 的不可见实体有内在的归纳性并可以推广到不可见关系,并且为模型如何以人类可理解的方式推断未知事实提供解释;元学习又称学会学习,基本思想是利用以前学习的知识和经验,只需利用少量的训练样本就快速适应具有不可见实体或不可见关系的新任务,并且可以提高不同KG 之间的泛化性和可迁移性。此外,根据汇总分类目前研究将基于额外信息的归纳KGC 分为两类:广泛研究的基于文本信息的方法、少量基于其他信息的方法。基于文本信息的方法借助文本描述或者实体描述等文本信息嵌入或预测不可见实体或不可见关系;基于其他信息的方法根据处理多模态信息或者时序嵌入或预测不可见实体或不可见关系。
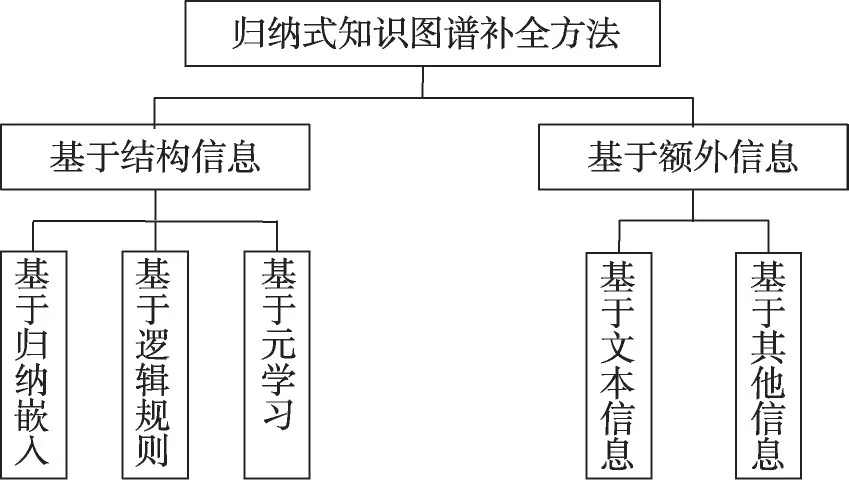
图2 归纳式知识图谱补全方法Fig.2 Inductive knowledge graph completion methods
本文深入研究了面向知识图谱补全的归纳学习的最新进展。具体来说,本文的贡献在于:
(1)从归纳式知识图谱补全的理论角度出发,以原始KG 和新兴KG 的知识图谱补全任务为分类依据,分为半归纳式和全归纳式,并从该角度总结归纳了本文的模型。
(2)从归纳式知识图谱补全的技术角度出发,以有无使用额外信息为分类依据,分为基于结构信息和额外信息,对现有各类面向知识图谱补全的归纳学习方法进行归纳总结。
(3)展望面向知识图谱补全的归纳学习的未来发展方向和前景。
1 预备知识
定义1(知识图谱和新兴知识图谱)
定义知识图谱:
其中,E 表示实体集合,R 表示关系集合,E ×R×E表示事实三元组集合,事实三元组用(h,r,t)表示,其中h表示头实体,t表示尾实体,r表示头实体和尾实体之间的关系。
定义新兴知识图谱:
其中,E′ ⋂ E=∅,E′ 表示不可见实体集。新兴KG G′(E′,R) 包含不可见实体集E′和与原始KG G(E,R)共享的可见关系集R。
事实三元组如(中国,首都,北京),其中“中国”“首都”“北京”分别是头实体、关系、尾实体,表示中国首都是北京这个事实。
如图1 所示,在原始KG 执行半归纳式KGC,在新兴KG执行全归纳式KGC。新兴KG的三元组(不可见头实体Diana,可见关系children is,不可见尾实体Liam)与原始KG 三元组(可见头实体Lucy,可见关系children is,可见尾实体Ella)共享可见的关系children is,但是原始KG 的三元组都是可见的,新兴KG的实体都是不可见的。
定义2(链接预测和三元组分类)
知识图谱补全有两大任务,三元组分类(triplet classification,TC)和链接预测(link prediction,LP),其中链接预测又分为实体预测和关系预测。
知识图谱实体预测为给定一个三元组(?,r,t)或者(h,r,?),目标是训练模型来预测缺失的头实体或者尾实体。知识图谱关系预测为给定一个三元组(h,?,t),目标是训练模型来预测缺失的关系。
知识图谱三元组分类为给定一个三元组(h,r,t),目标是训练模型来分类三元组是真还是假。
定义3(直推式链接预测和归纳式链接预测)
定义直推式链接预测为预测缺失的三元组:
定义归纳式链接预测为预测缺失的三元组:
其中,E″表示不可见实体集,R″为不可见关系集。
定义4(半归纳式链接预测和全归纳式链接预测)
定义半归纳式(semi-inductive,SI)链接预测为预测原始KG缺失的三元组(存在可见实体):
其中,α、β、γ分别为:
其中,α、β、γ分别如图1中的①、②、③,分别预测(可见头实体Frank,可见关系children is,不可见尾实体Mimi)、(可见头实体Frank,不可见关系wife is,可见尾实体Lucy)和(可见头实体Frank,不可见关系works in,不可见尾实体Bank)。
定义全归纳式(fully-inductive,FI)链接预测为预测新兴KG缺失的三元组(不存在可见实体):
其中,λ、μ分别如图1 中的④和⑤,分别预测(不可见头实体Diana,可见关系children is,不可见尾实体Liam)和(不可见头实体James,不可见关系wife is,不可见尾实体Diana)。
定义3将链接预测任务细分为直推式和归纳式,定义4进一步将归纳式细分为半归纳和全归纳,其三元组分类任务为分类预测的三元组是真是假,这里不详细阐述。
表1对图1的5种场景归纳式链接预测模型进行分类,下面具体阐述上述模型适用的归纳场景。

表1 归纳式知识图谱补全场景分类Table 1 Scene classification of inductive knowledge graph completion
2 基于结构信息的归纳式知识图谱补全
如上所述,基于结构信息的归纳式KGC 主要有嵌入表示、逻辑规则、元学习。表2 对基于结构信息的归纳式KGC 的典型模型进行了对比,后续章节将对这些模型进行详细的阐述。

表2 基于结构信息的归纳式知识图谱补全对比Table 2 Comparison of inductive knowledge graph completion based on structural information
2.1 基于归纳嵌入的方法
2.1.1 基于图神经网络的模型
一些图神经网络(graph neural network,GNN),如GraphSAGE(graph sample and aggregate)[121]、Graph-SAINT(graph sampling based inductive learning method)[122]等显示了在图中的归纳表示学习的能力。GraphSAGE如图3 所示,首先对邻居采样,其次聚合邻居节点信息,最后预测图上下文和标签。此外,GraphSAINT基于子图采样(而非GraphSAGE 基于邻域采样),克服了邻居节点数量爆炸式增长的问题,能够在大规模图上实现归纳学习。KG 是一种基于图的数据结构,它将实体抽象为顶点,将实体之间的关系抽象为边,通过结构化的形式对知识进行建模和描述,并将知识可视化。很多学者受此启发[121-122],通过GNN 对KG 中邻居节点特征进行聚合嵌入不可见实体或不可见关系。
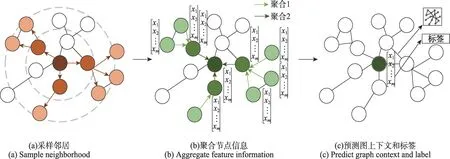
图3 GraphSAGE模型结构Fig.3 Model structure of GraphSAGE
Hamaguchi 等人提出了MEAN[11],其使用GNN嵌入不可见实体,GNN 的传播模型将信息从实体传播到其邻域,而输出模型使用基于嵌入的KGC 模型。然而,它通过简单的池化函数聚合邻居,忽略了邻居之间的差异,并且仅对包含少量关系的数据集有效。ConvLayer[12]同时受益于GNN 和卷积神经网络(convolutional neural network,CNN),使用卷积层作为GNN 中的过渡函数,以更少的参数学习表达性更强的嵌入。为了充分利用隐藏在三元组中的关系语义,CFAG[14]利用粗粒度聚合器(coarse-grained aggregator,CG-AGG)和细粒度生成对抗网络(finegrained generative adversarial network,FG-GAN)中的两个粒度级别关系语义来生成不可见实体的表示。首先,CG-AGG 通过基于超图神经网络(hyper-graph neural network,HGNN)的全局聚合器和基于GNN的局部聚合器生成具有多种语义的实体表示;其次,FG-GAN 进一步通过条件生成对抗网络(conditional generative adversarial network,CGNN)增强具有特定语义的实体表示。
上述模型可以处理半归纳式的不可见实体嵌入问题,很少有学者利用GNN 在半归纳式中学习嵌入不可见关系。目前已知Geng 等人提出DOZSL(disentangled ontology embedding for zero-shot learning)[39]学习解纠缠的本体嵌入,该模型基于生成对抗网络(generative adversarial network,GAN)的生成模型和基于图卷积网络(graph convolutional network,GCN)的传播模型集成解纠缠的嵌入,在不同方面捕捉和利用更细粒度的关系。
上述模型主要是通过聚合原始KG 中邻域信息来生成不可见实体的嵌入,不能同时对不可见实体和不可见关系进行嵌入。Zhao 等人提出FCLEntity-Att[13],使用卷积过渡和基于注意力的GNN 结构对不可见实体和不可见关系进行嵌入。Wang 等人提出SAGNN(structured attention graph neural network)[56],通过从入、出、共现频率等结构信息中挖掘潜在的关联特征,在输入节点缺乏嵌入表示的情况下为邻域内的不同节点指定不同的权重,最终对不可见实体和不可见关系生成具有高级语义特征的嵌入。
2.1.2 基于其他的模型
一些模型在基于GNN的模型嵌入不可见实体上进行改进,LAN(logic attention network)[17]基于逻辑规则和神经网络的注意机制来聚合邻居,以排列不变的方式为实体的邻居赋予不同的权重,同时考虑邻居的冗余性和查询关系。SLAN(similarity-aware aggregation network)[18]考虑挖掘可见实体与不可见实体之间的相似性,首先使用基于实体的邻居上下文和边缘上下文度量实体之间的相似性,然后设计特定于查询的注意权重来聚合相似度和邻域信息。CatE(concept aware knowledge transfer for inductive knowledge graph embedding)[19]基于本体论概念来解决不可见实体邻居稀疏性问题,首先采用Transformer 编码器对本体概念的复杂上下文结构进行建模,其次提出模板细化策略的归纳实体嵌入生成器,通过集成不可见实体的邻居和相应的概念来嵌入不可见实体。ARP(attention-based relation prediction)[20]关注实体和关系的多种类型的关联信息,通过结合一阶子图和一跳实体上下文特征增强不可见实体的嵌入,并设计联合损失函数保证同时包含子图和上下文特征的统一嵌入。
不同于以上基于GNN 的模型嵌入不可见实体,杜治娟等人提出TransNS[21],选取相关的邻居作为实体的属性来推断不可见实体,并利用实体之间的语义亲和力选择负例三元组来增强语义交互能力。Albooyeh等人提出oDisMult[22],引入简单高效的训练算法来优化精心设计的聚合函数嵌入不可见实体。Dai等人提出InvTransE[23],利用TransE假设来预训练邻接实体的表示,再对这些表示直接计算,就能快速归纳得到不可见实体的表示。
上述模型可以处理半归纳式的不可见实体嵌入问题,特别的,面对如图4 不断增长的KG,同时处理半归纳式的不可见实体和不可见关系问题。Cui等人提出LKGE(lifelong knowledge graph embedding)[57],考虑终身KG 嵌入和迁移而不必从头学习嵌入。该模型采用掩码KG 自编码器作为嵌入学习和更新的基础,并采用嵌入转移策略将学习到的知识注入到不可见实体和关系中,最后应用嵌入正则化方法防止知识更新中的灾难性遗忘。

图4 LKGE模型结构Fig.4 Model structure of LKGE
基于归纳嵌入的方法可扩展性强,适用大型数据集,但是缺乏基于逻辑规则的可解释性和准确性,并且属于半归纳式,只能直接对与原始KG有关联的不可见实体或不可见关系进行嵌入。下面将具体阐述联合嵌入和逻辑规则、联合嵌入和元学习,弥补以上缺点。
2.2 基于逻辑规则的方法
基于逻辑规则的方法主要有三种:基于规则的学习主要是明确挖掘逻辑规则;基于局部子图结构隐式学习KG中的逻辑规则;联合嵌入和逻辑规则。
2.2.1 基于规则的模型
(1)挖掘逻辑规则
传统的归纳关系预测方法主要是寻找KG 中的好的规则来预测目标三元组的存在。Galarraga等人提出知识图谱关联规则挖掘算法(association rule mining under incomplete evidence,AMIE)[58],从不完备的KG上挖掘霍恩规则(Horn rules)。具体来说,该算法通过3个挖掘算子(悬挂原子、实例化原子、闭合原子)迭代扩展规则来探索搜索空间,并融入对应的剪枝策略来缩小搜索空间。在此基础上,Galarraga等人将AMIE扩展为AMIE+[59],通过增加一系列修剪和查询重写技术来挖掘更大的KG,并利用实体类型信息和联合推理提高预测精度。但是以上模型的规则学习基于全局的KG进行搜索,成本高,效率低,预测效果差。与AMIE[58]基于整个KG计算置信度不同的是,RuleN[60]基于选择随机样本计算一个近似值,能够挖掘更长的路径规则。与AMIE、AMIE+自顶向下方法必须学习某一类型的所有规则相反,AnyBURL[61]从大型KG中自底向上学习逻辑规则,利用强化学习对两个实体间的关系进行采样,将采样路径推广为霍恩规则,运行速度快,需要更少的计算资源。
以上规则挖掘方法从KG 中挖掘出高置信度规则,然而好规则的数量可能是KG 大小的指数级,挖掘的规则覆盖率低,计算复杂度高、搜索成本较大、效率低会耗费大量的时间资源。
(2)逻辑规则和神经网络
基于逻辑规则的模型具有高准确率和强可解释性的优点,但该方法局限于噪声敏感和扩展性差,而神经网络的强鲁棒性和高效率可以缓解这一问题。
Yang等人受TensorLog和神经网络的启发,提出第一个端到端的可微模型NeuralLP[62],学习可变规则长度。该模型结合一阶规则推理和稀疏矩阵乘法,并引入具有注意机制和记忆的神经控制器系统,可以同时学习一阶逻辑规则的参数和结构。但是该模型对最大长度的规则有限制,不可避免地挖掘出高置信度的不正确规则,同时可微模型基于TensorLog框架,用矩阵表示三元组,矩阵维数为实体数,空间复杂度较高。Sadeghian 等人改进了NeuralLP 提出Drum[63],将每个规则的学习置信度分数与低秩张量近似之间建立联系,使用BiRNN 在不同关系的学习规则任务之间共享有用的信息。但是该模型仅使用正样本进行训练,未使用负采样提高模型的性能。以上模型同时学习逻辑规则及其权重优化是复杂的,Qu 等人提出RNNLogic[64],为迭代优化引入规则生成器和推理预测器并提出EM算法:首先更新推理预测器探索一些逻辑规则;其次在E步中利用规则生成器和推理预测器进行后验推理,筛选出高质量的规则;最后在M步中,选择E步中高质量规则的监督下更新规则生成器。然而上述模型不能解决KG 中缺失边问题,在处理不合理的规则候选时存在不足。Zhang等人提出RuleNet[65],利用关系参数的语义信息解决可微规则学习中的缺失边问题。具体而言,首先依赖查询的对偶图构造可以利用关系参数的信息,有效地学习关系之间的联系,其次进行缺失边感知的可微规则学习,遍历所有可能的规则路径。
(3)逻辑规则和图神经网络
最近GNN 在深度学习得到了广泛的应用,基于GNN的框架来捕获逻辑规则,可解释性强,模型容量大,可扩展性强,并建模KG 中关系之间更复杂的语义相关性。
Zhu 等人提出基于路径表示学习的GNN 框架NBFNet[66],所提出的路径公式概括了几种传统的方法并可以通过广义Bellman-Ford 算法进行有效求解。具体而言,广义Bellman-Ford算法参数化为三个神经函数:INDICATOR、MESSAGE 和AGGREGATE函数。分别学习广义Bellman-Ford算法的边界条件、乘法运算符和求和运算符。Liu等人提出INDIGO[67],采用成对编码的GNN,进一步利用了KG的结构特征捕获逻辑规则,其使用KG 中的三元组与GNN 处理的KG 中节点特征向量的元素之间的一对一对应关系来编码KG,并且预测的三元组可以直接从GNN的最后一层读出,而不需要额外的组件或评分函数。为了避免规则在指数大小空间中搜索,循环基图神经网络(cycle basis graph neural network,CBGNN)[68]首次将逻辑规则学习视为循环学习。该模型首先利用循环空间的线性结构并计算合适的循环基更好地表达规则,提高规则的搜索效率;其次搜索整个循环空间,通过GNN 的消息传递在循环空间中进行隐式代数运算,学习良好规则的表示。Zhang 等人提出RED-GNN(relational digraphs graph neural network)[69],由重叠的关系路径组成的关系有向图来捕获KG 的局部证据。该模型利用动态规划递归编码多个具有共享边的关系有向图,并通过依赖查询的注意权重选择强相关边。
基于规则的模型能显式地挖掘逻辑规则,可解释性和准确性强,有内在的归纳性,可以对新兴KG的不可见实体进行链接预测。但是存在以下问题:模型大小指数型增长会导致模型参数可伸缩性问题;很难扩展到大型数据集;很难与KG 的其他特征相结合,从而完成准确的补全。
2.2.2 基于子图的模型
子图可以被解释为两个目标实体之间有效路径的组合,它比单个规则更全面、信息更丰富。为了充分利用目标实体之间的拓扑信息和GNN 的表达能力,最近基于子图的模型被广泛提出,该方法仅从结构(即子图结构和结构节点特征)中学习和泛化,通过局部子图结构隐式学习KG中的逻辑规则,具有内在的归纳性。
最早Teru 等人提出GraIL[70],该框架对局部子图结构进行推理,以实体独立的方式预测目标节点之间的关系。如图5所示,该模型首先提取两个目标节点周围的封闭子图,然后标记所提取子图中的节点,包含图的相关结构信息,最后利用GNN 进行消息传递,对标记的子图进行评分,可以在训练后推广到不可见实体的KG。
在此之后许多学者从不同方面对GraIL进行改进,Chen等人提出TACT(topology-aware correlations)[71],对关系之间的语义关联进行建模,创新性地将所有关系对划分为7种拓扑模式,可以有效地以实体无关的方式利用关系之间的拓扑感知相关性进行归纳链接预测。CoMPILE(communicative message passing neural network)[72]扩展GraIL 的思想,引入新的节点-边缘通信消息传递机制来建模有向子图,符合KG的方向性,可以自然地处理不对称和反对称关系。RPCIR(relational path contrast for inductive reasoning)[73]关注单个子图中规则监督不足的问题,创新性地引入对比学习构建正、负关系路径获得自监督信息,其次利用GCN获得正、负关系路径的表示,最后结合对比信息和监督信息联合训练。Mai 等人关注造成基于子图方法的弱解释性的原因——存在噪声节点和边,提出GraphDrop[74],动态地修剪不相关的节点和边以生成最小充分子图,提出硬dropout和软dropout两种方法来过滤节点和边缘,并引入拓扑损失来保留修剪后的子图中的逻辑规则和拓扑结构。SGI(subgraph infomax)[75]使目标关系与其封闭子图之间的交互信息最大化,并提出预先训练的SGI相互信息估计量来选择困难负样本的新采样方法。Zheng 等人提出基于子图的元学习器Meta-iKG[76],该模型利用局部子图传递子图特定的信息,通过元梯度更快地学习可迁移的模式以快速适应小样本关系,还引入大样本关系更新过程使模型在大样本关系上也能很好地泛化。
由于仅利用子图会丢失大量的相邻关系信息,Wang 等人提出关系消息传递方法PathCon[77],考虑KG 中的两类子图结构即实体对的关系上下文和关系路径,在边缘之间迭代传递关系消息以聚合邻域信息以进行关系预测。Xu 等人提出SNRI(subgraph neighboring relations infomax)[78],从相邻关系特征和相邻关系路径两方面有效地将完整的相邻关系集成到封闭子图中,然后通过交互信息最大化以全局方式建模邻接关系。Chen等人提出基于相邻关系拓扑图(neighboring relations topology graph,NRTG)的实体表示方法[79],其中节点表示关系,边表示关系之间的拓扑模式。具体来说,首先将关系之间的连接结构划分为六种拓扑模式,关系拓扑模块通过提取头部和尾部实体的局部子图的所有三元组分别构建其相邻关系拓扑图;然后聚合相邻关系和NRTG中关系之间的拓扑模式作为实体表示。ConGLR(context graph with logical reasoning)[80]在子图的基础上引入上下文图联合计算归纳得分,采用两个部分信息交互的GCN分别处理子图和上下文图,并为子图GCN引入边感知和关系感知注意机制,为实体和关系的表示带来了丰富的KG结构语义。
虽然上述方法可以处理新兴KG 中的不可见实体,但它们不能同时考虑不可见实体和不可见关系,一些学者对此问题进行了探索。Geng 等人提出RMPI(relational message passing network for fully inductive KGC)[109],首先提取一个封闭子图将实体视图子图转换为关系视图子图,其次利用目标关系引导的图修剪策略、目标关系感知邻域注意、处理空子图、KG本体模式的关系语义注入等新技术充分进行关系消息传递对同时不可见实体和不可见关系进行归纳预测。Wu 等人提出ReCoLe(relation-dependent contrastive learning)[110],首先采用基于聚类算法的抽样方法,其次提取不同目标三元组的有向包围子图并输入到相应的基于GNN 的编码器中,最后基于GNN的编码器通过对比学习进行优化,提高对不可见关系的泛化能力。与Meta-iKG[76]不同,Huang等人提出使用自我监督预训练的连接子图推理器(connection subgraph reasoner,CSR)[111],首先使用假设建议模块以连接子图的形式找到共享假设,然后使用证据建议模块测试是否有足够接近假设的证据来预测查询的三元组,进一步考虑不可见关系并且不需要在人工策划的训练任务集上进行预训练。
基于子图的模型在处理新兴KG 的不可见实体任务显示出很强的归纳学习能力,并可以扩展到新兴KG 的不可见关系。但仍存在一些缺点。具体而言:(1)外围子图的大小可能非常大,包含干扰模型学习的噪声信息;(2)由于子图结构的复杂性,很难推断出归纳预测的结果是从子图的哪些部分得出结果的,可解释性差。
2.2.3 联合嵌入和逻辑规则的模型
受基于嵌入和逻辑规则的各自优势,一些学者提出混合模型。与仅对不可见实体嵌入不同,Bhowmik等人提出不可见实体表示学习和推理的联合框架(explainable link prediction for emerging entities,ELPE)[24],不仅通过Graph Transformer编码器的变体聚合邻域信息对不可见的实体进行表示,而且通过强化学习找到源实体和目标实体之间的推理路径对不可见实体的链接预测具有可解释性。He等人提出VN network(virtual neighbor network)[25],同时关注邻居稀疏问题和有意义的复杂模式。具体而言:首先提出基于规则的虚拟邻居预测减少邻居稀疏性,识别逻辑和对称路径规则来捕获复杂的模式并在软标签和KG嵌入上建立迭代优化方案,丰富不可见实体的邻域;其次将带有虚拟邻居的KG输入到基于GNN的编码器中;最后基于嵌入式的解码器为不可见实体嵌入的三元组分配分数。
与LKGE[57]考虑终身学习类似,Cui 等人提出不可见实体出现在多个批次中的场景。该模型[26]由四个模块组成:基于行走的智能体、自适应关系聚合的图卷积网络(adaptive relation aggregation GCN,ARGCN)、反馈注意和链接增强。具体而言:ARGCN利用实体的相邻关系对实体进行编码和更新;使用查询感知的反馈注意机制捕获实体的不同邻居重要性,链接增强策略缓解不可见实体的稀疏链接问题;从推理轨迹中提取基于行走的规则,以支持反馈注意和链接增强。
联合嵌入和逻辑规则提高了基于嵌入的方法的可解释性,但是基于嵌入和逻辑规则的方法很少对不可见关系进行研究,基于元学习的方法弥补了这个缺点。
2.3 基于元学习的方法
根据目前研究,基于元学习的方法主要有三种:第一,基于度量的模型,基于实体对的表示来度量两个可见实体之间的相似性,识别不可见关系;第二,基于优化的模型,大多数基于模型不可知性元学习(model-agnostic meta-learning,MAML)算法预测两个可见实体间的不可见关系;第三,联合归纳嵌入和元学习解决只能直接对与原始KG 有关联的不可见实体或不可见关系进行嵌入的缺点。
2.3.1 基于度量的模型
一些学者关注预测可见实体间存在不可见关系的三元组,首先基于实体编码器对实体对编码,在支持三元组中学习到含有相同可见关系的实体对间的相似性,最后进行查询三元组与支持三元组的相似性匹配来识别不可见关系。
Xiong等人提出匹配网络GMatching[40],如图6所示,邻居编码器利用KG实体的局部图结构更好地表示实体,然后从邻居编码器中获取支持三元组中任意两个实体对的向量表示,最后匹配处理器进行查询三元组与支持三元组的相似性匹配。一些学者在此基础上进行改进,FSRL(few-shot relation learning)[8]使用关系感知异构邻居编码器捕获不同的关系类型和邻居对实体嵌入的影响和循环自编码器聚合网络模拟少样本实体对的相互作用。FAAN(adaptive attentional network for few-shot KGC)[9]进一步学习邻居的动态表示,首先自适应邻居编码器学习自适应实体表示使实体表示适应不同的任务,其次使用Transformer编码器对实体对进行编码,最后适应匹配处理器匹配支持和查询三元组。此外,REFORM(error-aware few-shot graph completion)[10]关注元训练时的错误检测,该模型由邻居编码器、交叉关系聚合和错误缓解三个模块组成,分别减少错误邻居的影响、捕获关系之间的相关性和预测阶段减轻错误三元组的影响。元模式学习框架(meta pattern learning framework,MetaP)[41]解决KG依赖和负样本问题,首先基于卷积滤波器的模式学习器来直接提取三元组的模式减少KG依赖问题,其次基于有效性平衡机制的模式匹配器同时考虑了三元组之间的模式相似性和正负样本。P-INT(path-based interaction model)[42]利用从头部到尾部实体的路径来表示一个实体对,将基于表示的相似度度量转换为基于头尾实体连接路径的交互度量。FSDR(few-shot discriminative representation learning model)[43]创造性引入实例图神经网络整合负支持实例和建模支持实例之间的交互,充分捕获支持集中的可用信息。
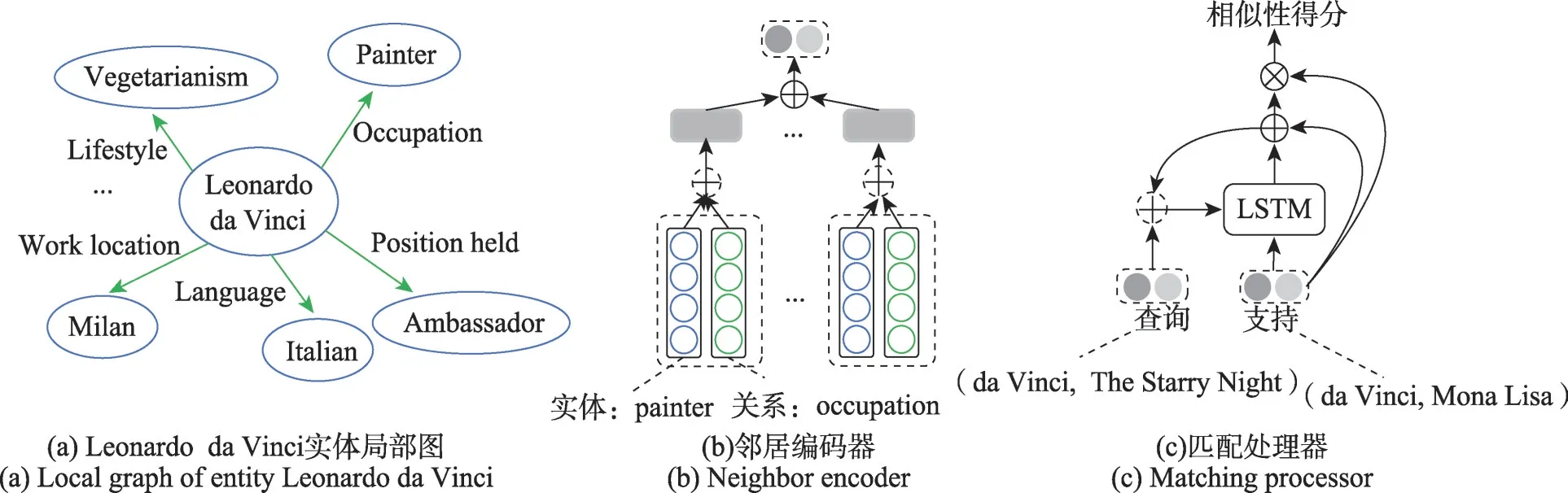
图6 GMatching模型结构Fig.6 Model structure of GMatching
2.3.2 基于优化的模型
基于优化的模型大多数基于MAML 算法,其基本思想是训练得到模型的初始参数,使模型测试时仅通过少量样本的一次或几次梯度更新就能预测两个可见实体间的不可见关系且达到很好的性能。
Chen等人最早提出元关系学习框架MetaR[44],其中关系元和梯度元共享支持集和查询集之间的元信息,试图在任务之间提取共享元信息并其观察到的三元组快速转移到不可见关系的三元组。如图7 所示,首先关系元学习器从支持集中提取关系元,并学习从支持集中的头尾实体到关系元的映射,其次嵌入学习器通过实体嵌入和关系元评估特定关系下实体对的真值和损失函数,计算梯度元并实现关系元的快速更新。为了处理一对多、多对一甚至多对多的复杂关系,Niu等人提出的GANA(gated and attentive neighbor aggregator)[45]采用全局-局部两阶段的框架进行关系学习。具体而言,全局阶段利用门控和注意力邻居聚合器自动捕获最重要的邻域信息并过滤邻域噪声信息,并引入双向长短时记忆网络(bidirectional long short-term memory,Bi-LSTM)编码器学习关系的表示;局部阶段设计MTransH,利用MAML学习关系特定的超平面参数对复杂关系进行建模。Wu等人提出HiRe(hierarchical relational learning method)[46],进一步联合捕获三个层次的关系信息(实体级、三元组级和上下文级),通过对目标三元组与其真/假上下文之间的对比相关性建模,并基于Transformer 编码器的元关系学习器捕获成对的三元组级关系信息,所学习的实体/关系嵌入通过实体级的MTransD进一步细化,最后基于MAML 的训练策略优化整个学习框架。
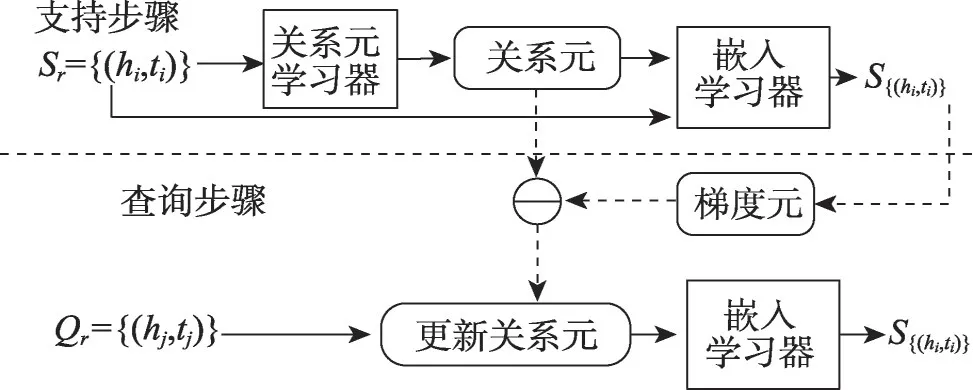
图7 MetaR模型结构Fig.7 Model structure of MetaR
此外,Lv 等人提出Meta-KGR(meta-based multihop reasoning method)[47],采用强化学习框架并使用MAML 从高频关系中学习有效的元参数,可以快速适应不可见关系。FIRE(few-shot multi-hop relation learning model)[48]通过异构结构编码和知识感知搜索空间剪枝扩展了Meta-KGR。
2.3.3 联合归纳嵌入和元学习的模型
基于归纳嵌入的方法通过聚集不可见实体的邻居来嵌入的不可见实体,虽然一定程度上解决了不可见实体问题,但仍然面临三个挑战:(1)不能直接对与原始KG 无关联的不可见实体进行聚合;(2)不能对新兴KG 上的不可见实体进行嵌入;(3)不能同时对新兴KG 上的不可见实体和不可见关系嵌入。一些学者受基于度量的模型的启发,在原始KG上采样一组任务,使用支持集作为GNN 的输入并进行元训练,然后将学习到的任务传递给查询集。
针对第一个挑战,Baek等人关注KG中的长尾关系,提出GEN(graph extrapolation networks)[27]对两个GNN 进行元训练,对可见到不可见以及不可见到不可见实体进行链接预测。具体而言,首先归纳式推理可见到不可见实体之间的节点嵌入,然后对整个KG进一步进行直推式推理,对不可见实体本身进行链接预测并建模不确定性。Zhang 等人提出两阶段模型HRFN(hyper-relation feature learning network)[28],在第一阶段从原始KG 中元学习超关联特征并使用基于GNN 的两层网络预表示不可见实体,获得其粗粒度表示;在第二阶段中基于上述不可见实体的粗粒度预表示,采用基于GNN 直推式学习网络对不可见实体的嵌入进行微调。针对第二个挑战,Chen 等人提出MorsE(meta-knowledge transfer)[81],通过建模和学习与实体无关的元知识对新兴KG 中不可见实体进行嵌入。具体而言:首先在原始KG上采样一组任务模拟此归纳式任务;其次通过实体初始化器和GNN 调制两个模块对元知识建模,分别初始化每个实体嵌入和通过实体多跳邻域的结构捕获实体的实例级信息;最后元训练后可以在新兴KG中对不可见实体生成高质量的嵌入。针对第三个挑战,MaKEr(meta-learning based knowledge extrapolation)[112]进一步关注新兴KG 的不可见实体和关系,首先在现有KG上采样一组任务模拟此归纳式任务,其次基于采样任务元训练GNN 框架,可以为不可见实体和关系的构造特征并输出嵌入。
联合嵌入和元学习的模型对GNN 进行元训练,弥补基于归纳嵌入的模型只能在半归纳式中嵌入不可见实体或不可见关系的缺陷,提高了模型性能。
3 基于额外信息的归纳式知识图谱补全
尽管基于结构信息的归纳式KGC具有显著的优势,但是仅从KG本身学习知识,忽略了KG之外与实体和关系相关的额外信息。表3 对基于额外信息的归纳式KGC 的模型进行了对比,后续章节将对这些模型进行详细的阐述。
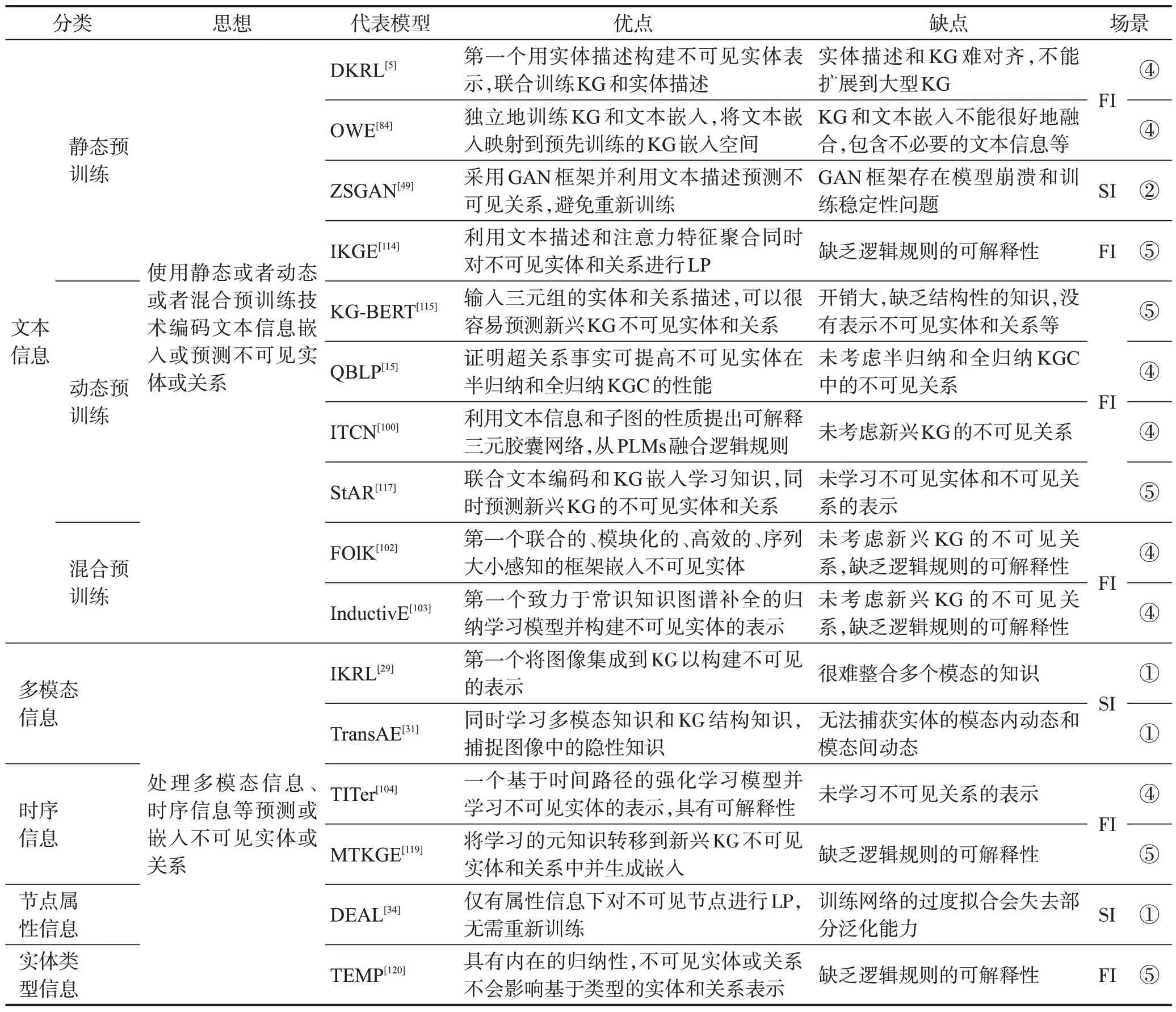
表3 基于额外信息的归纳式知识图谱补全对比Table 3 Comparison of inductive knowledge graph completion based on extra information
3.1 基于文本信息的方法
早期的自然语言处理领域使用word2vec[123]和Glove[124]等静态预训练技术对文本进行编码,但是无法解决一词多义等问题。对此BERT(bidirectional encoder representations from transformers)[125]和RoBERTa(robustly optimized BERT pretraining approach)[126]等动态预训练模型相继提出,将预训练技术推向了研究高潮。
因此,根据预训练语言模型(pretrained language models,PLMs)的不同将基于文本信息的方法分为三类,基于静态、动态和混合预训练的模型。
3.1.1 基于静态预训练的模型
根据Markowitz 等人[93]的研究,使用文本描述可以对不可见实体到不可见实体的三元组进行链接预测。早期Xie等人提出第一个用实体描述信息构建不可见实体表示的工作(description-embodied knowledge representation learning,DKRL)[5](如图8 所示),将基于图的嵌入(TransE)和基于描述的嵌入(CBOW(continuous bag of words)和CNN 编码器)联合训练。ConMask(content masking model)[6]进一步使用关系依赖的内容掩蔽、全卷积神经网络和语义平均从KG 中的实体和关系的文本特征中提取不可见实体的关系依赖嵌入。但该模型没有充分利用文本描述中丰富的特征信息,而且所提出的基于依赖关系的内容屏蔽方法容易丢失目标词,内容屏蔽窗口的大小也很难确定。MIA(multiple interaction attention)[7]改进了ConMask,提出建模头部实体描述、头部实体名称、关系名称和候选尾部实体描述之间的交互,对不可见实体形成丰富的表示,然而MIA 在很大程度上依赖于实体描述的丰富性。为了充分利用潜在的语义依赖信息,DKGC-JSTD(dynamic KGC with jointly structural and textual dependency)[82]首先利用新颖的特征提取模型、关系语义选择和语义平均从实体描述中提取关联嵌入,然后利用具有多类型单元和邻居层的深度双向GRU建立内部拓扑结构与外部文本信息之间更深层次的语义依赖关系。此外,SDT[83]将实体的结构信息、实体描述(CBOW 和CNN编码器)和分层类型信息(递归和加权层次编码器)合并到一个统一框架中以嵌入不可见实体。
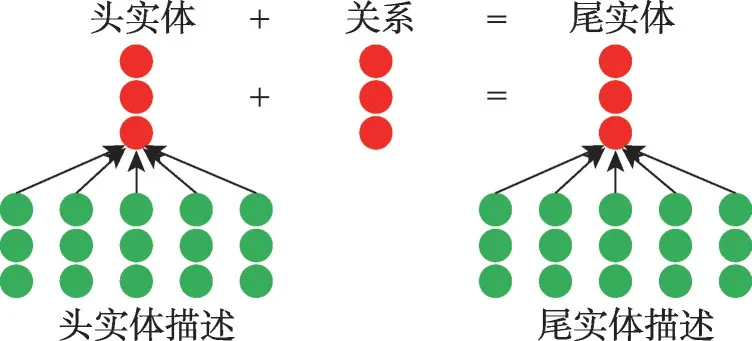
图8 DKRL模型结构Fig.8 Model structure of DKRL
与上述方法联合训练KG 和文本向量不同[5-7],Shah 等人提出OWE(open-world extension)[84],扩展基于嵌入式的KGC 模型预测不可见的实体。如图9所示,首先使用实体的名称和描述来构建基于文本的表示,独立地训练KG 和文本嵌入,然后将基于文本的嵌入映射到基于图嵌入空间,学习到的映射可以应用KGC模型预测不可见实体。许多学者改进了OWE[84]模型,WOWE(weighted aggregator for OWE)[85]使用加权聚合器,采用注意力网络的方法获取实体描述中单词的权重。OWE-RST(relation specific transformations for OWE)[86]学习从基于文本的嵌入空间到基于图的嵌入空间的特定关系的转换函数。OWE-MRC(machine reading comprehension for OWE)[87]使用机器阅读理解从长描述中提取出有意义的短描述。针对三元组的结构嵌入和描述嵌入不能很好地融合的问题,Caps-OWKG(capsule network for openworld KGC)[88]利用胶囊网络对融合嵌入后的三元组进行处理,得到最终的三元组概率得分。EmReCo(embeddings based on relation-specific constraints)[89]重视关系的影响,使用感知关系的注意力聚合器获得实体在特定关系下的文本嵌入,并在实体嵌入中设计特定于关系的门过滤机制来保持特定于关系的特征。
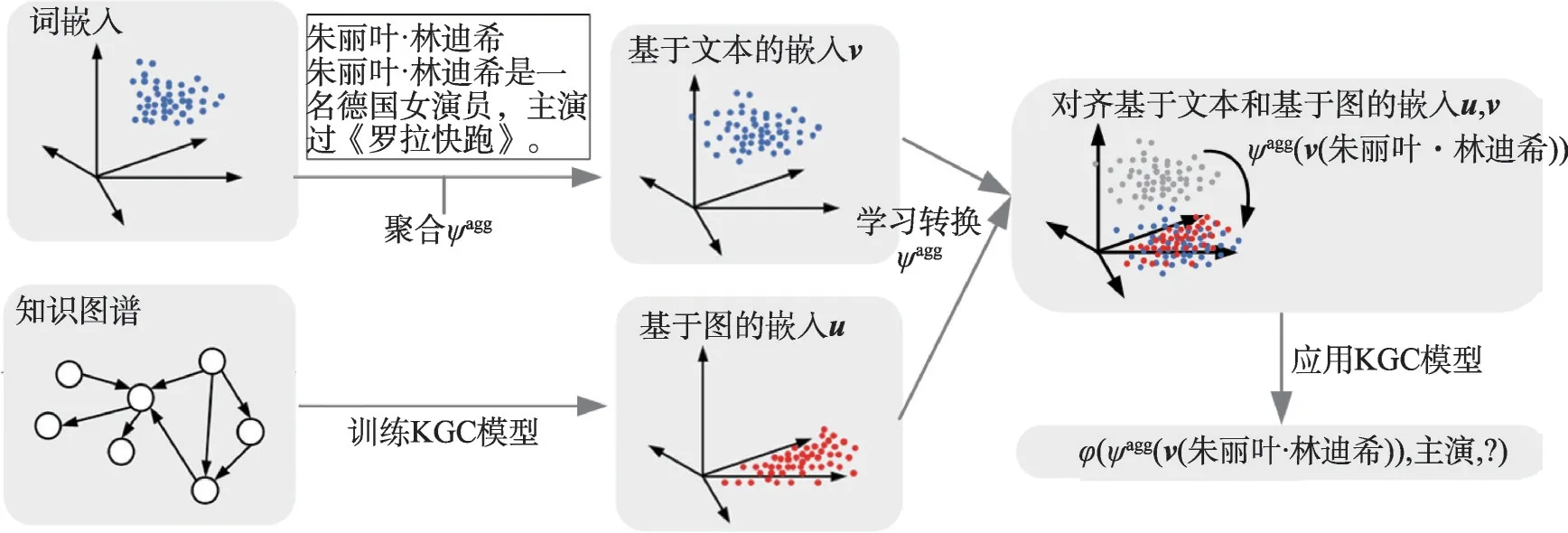
图9 OWE模型结构Fig.9 Model structure of OWE
此外,一些模型使用生成对抗网络(generative adversarial network,GAN)利用文本描述从可见实体对中嵌入不可见关系。Qin等人提出ZSGAN(GAN for zero-shot knowledge graph relational learning)[49],通过生成器和判别器之间的对抗性训练,利用生成器仅从文本描述生成不可见关系的嵌入。OntoZSL(ontologyenhanced zero-shot learning)[50]进一步从描述KG关系之间更丰富关联的本体论模式帮助生成器生成不可见的关系。然而简单GAN结构不能充分地从文本描述中提取特征,随机和双对抗GAN的框架(stochastic and dual adversarial GAN,SDA)[51]引入随机生成器和附加分类器来提高逼近能力和优化过程,更好地挖掘语义信息和提取特征之间的关联。结构增强生成对抗网络(structure-enhanced GAN,SEGAN)[52]采用结构编码器将KG 结构信息引入生成器以缓解文本描述与KG嵌入之间的差异,并设计特征编码器来解耦实体并提供更深层次的实体交互以提高实体表示的准确性。
尽管生成对抗方法的性能有所提高,但存在模型崩溃和训练稳定性问题。受原型网络的启发,HAPZSL(hybrid attention prototype network for zeroshot knowledge graph relational learning)[53]通过描述编码器和混合注意机制获得关系原型和实体对表示,然后将它们输入到一个潜在空间,迫使实体对更接近它们的关系原型。但是使用关系的文本描述的方法缺乏健壮性,因为它们只能支持来自固定词汇表的标记,无法对词汇表外单词建模,可以使用本体来学习不可见关系的语义表示。Song等人提出本体引导和文本增强的表示[54],首先本体图建立不可见关系与本体其他相关元素之间的联系,文本描述丰富不可见关系的语义表示,其次使用文本关系图卷积网络(text-relation graph convolution network,TR-GCN)基于本体结构及其文本描述获得关系的元表示。Song等人也提出解耦混合图专家算法(decoupling mixtureof-graph experts,DMoG)[55],通过融合本体图和文本图来表示事实图中的不可见关系,并对融合空间和推理空间进行解耦以缓解可见关系的过拟合。
为了使用文本描述同时对新兴KG 的不可见实体和不可见关系进行链接预测。Wang等人提出元学习框架[113],首先描述编码器从具有多个关系的实体描述中提取特定于关系的信息,其次通过生成模型TCVAE(triplet conditional variational auto-encoder)生成额外的三元组来缓解少样本学习的数据稀疏性,最后使用元学习器提高处理不可见关系和不可见实体的泛化能力。与上述方法不同的是,IKGE(inductive KG embedding)[114]保留了全局结构信息,通过注意力特征聚合同时对不可见实体和不可见关系进行链接预测,IKGE 从根本上学习嵌入生成器函数,从实体描述中归纳生成事实嵌入,将事实推广不可见实体和不可见关系。
基于静态预训练的技术处理文本信息可以对不可见实体到不可见实体的三元组进行链接预测,并扩展到不可见关系。表4 对所有的基于静态预训练的模型进行了分类总结。此外,使用文本信息还可以从可见实体对中嵌入不可见关系。除了静态预训练,动态预训练技术兴起将文本信息推向了研究高潮,下面将详细阐述。
表4 基于静态预训练的模型分类汇总Table 4 Model classification summary based on static pretraining
3.1.2 基于动态预训练的模型
早期Yao 等人以三元组的实体描述和关系描述为输入,利用KG-BERT(knowledge graph bidirectional encoder representations from transformer)[115]计算三元组的评分函数。如图10 所示,首先输入序列的第一个标记是特殊的分类标记[CLS],其次建立头实体、关系和尾实体的句子标记,实体和关系的句子由特殊的标记[SEP]分开,然后将标记序列输入到BERT进行微调,实验证明[118]可以很容易推广到不可见实体和关系。但是有几个主要的缺点限制了性能,很多学者提出一些模型对KG-BERT[115]进行改进。多任务学习方法(multi-task learning for knowledge graph completion,MTL-KGC)[116]通过将关系预测和相关性排名任务与目标链接预测结合起来,可以从KG中学习更多的关系属性,并且可以从词汇相似的候选词中选出正确答案。MLMLM(mean likelihood masked language model)[90]从屏蔽语言模型中采样不同长度的不同文本的似然,以易处理的方式对不可见实体进行链接预测,改进了KG-BERT[115]的数百万个推理步骤用于单个三元组评分的缺陷。KEPLER(knowledge embedding and pre-trained language representation)[91]统一知识嵌入和PLMs表示,并对知识嵌入和屏蔽语言建模目标联合优化,从实体的描述中为不可见实体生成嵌入。BLP(BERT for link prediction)[92]使用PLMs通过LP来学习不可见实体的表示,并研究了它与四种不同关系模型的结合性能,学习到的实体表示有很强的泛化特性,可以很好地转移到其他任务(如实体分类和信息检索)。单纯的结构目标在捕捉图结构方面存在一定的局限性[90-92],StATIK(structure and text for inductive knowledge completion)[93]的结构信息通过消息传递神经网络(message passing graph neural network,MPNN)每个实体周围的邻域信息,文本信息通过PLMs整合,提高模型的可伸缩性并能在大型KG中不可见实体的归纳式中获得更好的泛化。
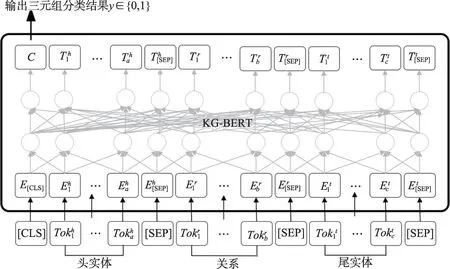
图10 KG-BERT模型结构Fig.10 Model structure of KG-BERT
KG-BERT[115]隐式地在模型参数中进行推理,受记忆增强神经网络最新进展的启发,KNN-KGE(Knearest neighbor knowledge graph embedding)[94]使用PLMs构建实体知识库来显式记忆不可见实体,通过K近邻对实体分布进行线性插值,根据实体嵌入空间中到知识库的距离来计算最近的邻居,从而通过记忆进行推理。受对比学习领域的最新进展的启发,SimKGC(simple contrastive KGC)[95]创造性引入三种类型的负采样(批次内负采样、预批次负采样、自批次内负采样)将负样本量可以增加到数千的规模。大多数基于PLMs的KGC模型只是简单地拼接实体和关系的标签作为输入,导致不连贯的句子,不能充分利用PLMs中的隐性知识,PKGC(PLM-based KGC)[96]将每个三元组及其支持信息转换为自然的提示句,并进一步输入PLMs进行预测。此外,线性化三元组会影响关系模式的学习,Bi-Link(bridging inductive link)[97]首先使用基于概率规则的提示生成自然关系表达式;并设计对称链接预测模型,在正向和反向预测之间建立双向链接适应测试时灵活的自集成策略。为了能在语义层面上学习三元组的关联信息,LP-Bert[98]在预训练阶段通过上下文学习的掩码语言模型(mask language model,MLM)、实体语义学习的掩码实体模型(mask entity model,MEM)和关系语义学习的掩码关系模型(mask relation model,MRM),来学习结构化KG的关系信息和非结构化语义知识;微调阶段受对比学习的启发分批设计了三种形式的负抽样提高了负抽样的比例,并利用三元组逆关系的增强数据,提高模型的性能和鲁棒性。此外,一些学者研究特殊领域KG,Nadkarni 等人提出KG-PubMedBERT[99],对应用于生物医学KGC 的LMs 进行研究并展示了基于LMs的模型在应用于训练期间未见的实体时的优势。Ali等人针对超关系图的归纳式KGC提出QBLP(qualifier BERT for link prediction)[15],是一种利用限定符中的语义对BLP 进行扩展的模型,证明超关系事实在不可见实体的半归纳和全归纳式中可以大大提高KGC性能。
针对逻辑规则难以融合的问题,一些学者尝试从PLMs融合逻辑规则。Wu等人利用关系的文本信息和基于子图的性质提出可解释三元胶囊网络(interpretable triplet capsule network,ITCN)[100]。具体而言:首先提取目标三元组周围的有向封闭子图;其次利用PLMs来学习关系语义中携带的先验知识,并产生上下文关系嵌入来初始化子图中的节点和边;然后使用GCN 将子图中的每个三元组构造为胶囊;最后使用排序多层路由机制对胶囊进行评分和解释。Lin 等人提出在PLMs 中融合KG 的拓扑上下文和逻辑规则的模型(fuse topology contexts and logical rules in language models,FTL-LM)[101]。具体而言:首先提出基于路径的拓扑上下文学习方法,用异构随机游走生成拓扑路径,进一步构造推理路径及正负样本,通过掩码语言建模和对比路径学习策略对这些拓扑上下文进行语义建模;其次提出变分EM算法分别对三元组模型和规则模型进行交替优化,将KG的逻辑规则纳入到LM。
以上模型可以对不可见到不可见实体的三元组进行链接预测,为了进一步扩展不可见关系,StAR(structure-augmented text representation)[117]联合文本编码和KG 嵌入来学习情境化和结构化知识,首先Siamese-style 的文本编码器编码用于两个上下文表示的三元组,并提出两种并行的评分策略(确定性表示学习、空间结构学习)来学习上下文化和结构化的知识,最后基于图嵌入的自适应集成方案进一步提高性能,但StAR[117]未学习不可见实体和不可见关系的表示。RAILD(relation aware inductive link prediction)[16]进一步通过微调PLMs 来编码实体和关系的文本描述学习未知实体和未知关系的表示,提出有向加权关系网络生成算法(weighted and directed network of relations,WeiDNeR),仅从图结构中的上下文信息对关系进行编码来嵌入不可见关系。此外,BERTRL(BERT-based relational learning)[118]首先将目标关系中实体周围的局部子图线性化为路径,其次将路径输入到BERT中进行微调,通过连接两个实体的路径显式地进行推理,能实现高解释性和高准确性。
基于动态预训练的模型同样可以对不可见实体到不可见实体的三元组进行链接预测,并扩展到不可见关系。表5 对所有的基于动态预训练的模型进行了分类总结。此外,还有一些学者联合静态和动态预训练进行混合预训练,下面将详细阐述。
3.1.3 基于混合预训练的模型
目前已知基于混合预训练的模型使用文本描述可以对不可见实体到不可见实体的三元组进行链接预测很少。Tripathi等人提出了FOlK[102],第一个联合的、模块化的、高效的、序列大小感知的框架生成不可见实体嵌入。具体来说,可视化嵌入实验解释了联合训练对不可见实体嵌入性能的显著改善,并可以执行实体分类等下游任务;模块化使FOlK可以容纳多种结构能量函数;使用简单的嵌入能量函数来评分可以提高测试中完成过滤排名所需的时间;对短描述和长描述分别使用word2vec嵌入和RoBERTa模型进行编码,无论描述长度如何都具有竞争力。Wang等人提出第一个致力于常识KG(commonsense knowledge graph)补全的归纳学习模型InductivE[103]。首先CKG 的实体属性由自由形式文本组成,因此自由文本编码器使用PLMs 和单词嵌入来嵌入文本属性,直接从原始实体属性计算实体嵌入来保证归纳学习能力;其次提出致密化过程的GNN,利用相邻结构信息进一步增强不可见实体的表示。未来进一步使用混合预训练扩展到不可见关系。表6 对所有的基于混合预训练的模型进行了分类总结。

表6 基于混合预训练的模型分类汇总Table 6 Model classification summary based on hybrid pretraining
虽然基于文本信息的归纳式KGC方法得到了广泛的研究,但是需要额外的文本知识,并非每个实体在现实中都有相应的文本知识,在实际中实现起来比较困难。
3.2 基于其他信息的方法
除了上面广泛研究的基于文本信息的方法,少数学者提出基于其他信息的方法,比如多模态信息、时序信息、节点属性和实体类型信息等。
(1)多模态信息
现实世界存在多模态的知识,如图11 所示,威廉·莎士比亚和《罗密欧与朱丽叶》存在图像特征和文本描述。Xie等人提出IKRL(image-embodied knowledge representation learning)[29],第一个考虑实体图像信息学习知识表示,通过构造每个图像的特征表示并通过注意机制将其集成到基于图像的聚合表示中,最后与TransE 共同学习知识表示。MKBE(multimodal knowledge base embeddings)[30]把多模态信息当作额外的三元组,首先组合编码组件联合学习实体和多模态嵌入,其次对抗性训练的解码组件使用实体嵌入来计算缺失的多模态属性。知识图谱很难捕捉图像中的隐性知识,比如蝴蝶和花同时出现,说明实体“蝴蝶”和“花”高度相关,Wang 等人将多模态自编码器与TransE 模型相结合提出TransAE[31],同时学习多模态知识和结构知识。然而,传统的简单拼接或注意方法无法捕获实体的模态内动态和模态间动态,Liang 等人提出HRGAT(hyper-node relational graph attention network)[32],捕获多模态信息和图结构信息,首先使用低秩多模态融合对模态内动态和模态间动态进行建模,将原始KG 转化为超节点图,其次采用RGAT(relational graph attention)获取图结构信息,最后多模态信息和图结构信息聚合生成最终嵌入。此外,Zheng 等人提出MMKGR(multi-hop multi-modal knowledge graph reasoning)[33],首先统一的门-注意网络通过充分的注意交互和降噪生成多模态互补特征,这些特征被输入到互补的特征感知强化学习框架中,缓解稀疏奖励问题。
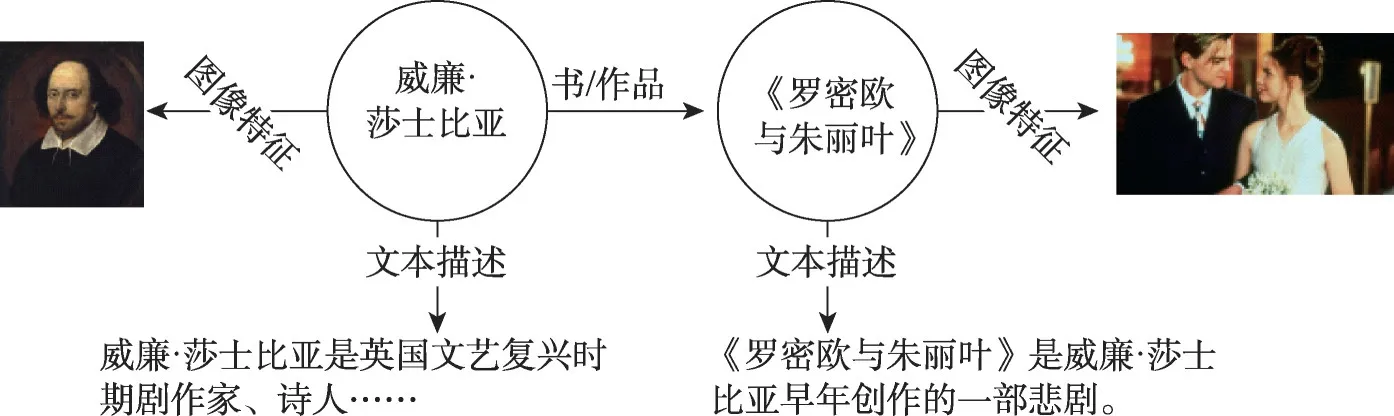
图11 多模态知识图谱Fig.11 Multi-modal knowledge graph
目前对多模态信息的研究还处于早期阶段,TransAE[31]实验证明可以对不可见实体进行链接预测,但还没有实验证明对不可见实体和不可见实体的三元组进行链接预测,因此将其分类到半归纳式中。
(2)时序信息
现实世界知识是不断变化的,许多事实存在时间有效性,一些学者将时序信息引入KG中对不可见实体进行LP。
早期Sun 等人提出基于时间路径的强化学习模型TITer(time traveler)[104],利用智能体的相对时间编码函数和时间奖励建模时间信息,并使用归纳均值(inductive mean,IM)机制来更新测试过程中不可见实体的表示。TLogic(temporal logical rules)[105]基于通过时间随机游走提取的时间逻辑规则,首先学习时间规则路径,然后应用规则来生成答案,并根据规则的置信度和时间差对候选答案进行评分。Mei等人进一步提出自适应规则嵌入归纳推理模型(adaptive logical rule embedding model for inductive reasoning,ALRE-IR)[106],基于历史关系路径自主提取和评估规则,并提出增强匹配损失优化方法,从粗粒度四重和细粒度规则视角训练模型。为了解决少样本的归纳LP,FITCARL(few-shot inductive learning on TKG using confidence-augmented reinforcement learning)[107]使 用时间感知的Transformer 学习不可见实体的表示;结合强化学习指导搜索过程,并设计置信度增强的策略网络缓解少样本设置的负面影响;提出无参数概念正则化器更好地利用时序知识图谱(temporal knowledge graph,TKG)的概念信息。受GraIL[70]的启发,xERTE(explainable reasoning for TKG)[108]基于时间关系注意机制和反向表示更新方案提取依赖于查询的子图,并通过时间邻居的迭代采样、注意传播和子图修剪进行推理。以上模型挖掘时间逻辑规则,具有内在的归纳性,可以解决新兴KG的不可见实体问题。
此外,Ding 等人提出元学习框架FILT(few-shot inductive learning on TKG)[37],从TKG 挖掘可见实体概念感知信息,将其转移到不可见的实体中,并使用基于时间差的图形编码器学习不可见实体的上下文化表示。为了最大限度地减少与人类学习少样本的差 距,MetaTKGR(meta temporal knowledge graph reasoning)[38]的时间编码器通过采样和聚集TKG 邻居信息,学习不可见实体的时间感知表示;元时间推理采用双层优化(内部优化和外部优化)学习最优采样和聚合参数,所学习的参数可以很容易地适应不可见实体并保持时间鲁棒性。MTKGE(meta-learning based temporal knowledge graph extrapolation)[119]进一步设计两个GNN 捕获与实体无关的关系特征:相对位置模式图(relative position pattern graph,RPPG)和时间序列模式图(temporal sequence pattern graph,TSPG),将学习到的元知识转移到新兴KG不可见实体和不可见关系中并生成嵌入。
(3)节点属性信息
如图12所示,展示了仅有属性信息的对不可见节点进行链接预测。DEAL(dual-encoder graph embedding with alignment)[34]通过节点属性信息对不可见节点进行链接预测,该模型由三部分组成:两个节点嵌入编码器和一个对齐机制。其中,两种编码器分别输出面向属性和面向结构的节点嵌入,对齐机制对两种类型的嵌入进行对齐,学习不可见节点的嵌入。由于对训练网络的过度拟合DEAL[34]失去部分泛化能力,Li等人引入对抗性训练和随机噪声正则化[35]。具体来说,首先,两个多层感知器也分别作为编码器来学习属性嵌入和结构嵌入并引入随机初始化线性层来提高模型的鲁棒性,两种嵌入通过对抗性训练相互作用。Zhang等人针对链路稀疏性、节点属性噪声和动态变化提出上下文化自监督学习(contextualized self-supervised learning,CSSL)[36],从随机行走中收集的上下文节点和上下文子图,通过链路预测和自监督学习任务监督模型参数的学习。
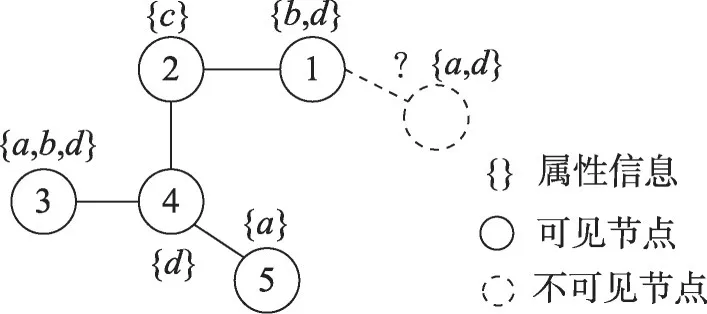
图12 带有属性信息的归纳链接预测Fig.12 Inductive link prediction with attribute information
目前根据节点属性信息对不可见节点进行链接预测研究较少,以上模型属于在半归纳式中不可见实体的问题。
(4)实体类型信息
Hu 等人提出类型感知消息传递模型(typeaware message passing,TEMP)[120],该模型由两个子模型组成:(1)类型感知实体表示(type-aware entity representations,TER),聚合实体的类型信息来丰富其向量表示;(2)类型感知关系表示(type-aware relation representations,TRR),构建全局类型图然后聚合关系类型,通过实体和关系的双向集成机制获得感知关系的实体表示和感知实体的关系表示。因为不可见实体或不可见关系的出现不会影响基于类型的实体和关系表示,所以模型具有固有的归纳性。这是目前已知唯一利用实体类型信息进行归纳KGC,并且适用于全归纳设置。
虽然基于附加信息的方法可以预测不可见实体或关系,但是基于附加信息的模型既需要高成本也需要高质量的数据资源,而这些信息在现实场景中总是不可用的,这些方法会受到限制。
4 未来研究方向展望
虽然目前面向知识图谱补全的归纳学习方法取得了一定进展,但该领域仍处于发展时期,仍然存在尚未解决的问题和挑战,本文将从以下几个方面展望未来研究方向。
(1)特殊知识图谱
现有模型的数据集大多数从DBpedia[127]、Freebase[128]等KG 构建,很少有研究对特殊KG 进行研究。常识KG[103]由于动态和高度稀疏的性质成为归纳KGC 的自然基准;Ali 等人[15]证明了超关系KG 的事实可以提高归纳KGC 的性能;Nadkarni 等人[99]对生物医学KGC 的LMs 进行研究,并应用于训练时不可见实体;在多模态KG 也可嵌入不可见实体[31];时序知识图谱也可以为新兴KG 的不可见实体和关系生成嵌入[119]。目前已有的研究还处于浅层,未来进一步研究以上特殊KG是一个重要的方向。
(2)引入额外信息
尽管基于结构信息的归纳KGC 具有显著的优势,但是仅从KG学习知识,忽略了KG之外与实体和关系相关的额外信息。但是当前的标准基准数据集缺乏充分的额外信息,未来要收集多模态信息和时间信息等来丰富基准数据集,并在基于结构信息的归纳KGC中引入更多的额外信息,提高模型的性能。
(3)不可见实体和不可见关系
目前研究主要是对单独不可见实体和关系进行归纳KGC,但是现实世界可能同时出现不可见实体和关系。典型的基于动态预训练的模型由于其独特优势可以很容易推广到不可见实体和关系[118],基于子图的模型通过注入KG的本体论模式[109]、聚类采样和关系依赖对比学习[110]等技术进一步预测不可见关系,在KG上采样一组不可见实体和关系的训练任务[112]进行元训练也可以推广到不可见实体和关系,未来将继续深入研究。
(4)混合模型
在基于结构信息的归纳KGC 中,基于归纳嵌入的方法具有高伸缩性,但是可解释性差并且只能对原始KG 有关联的不可见实体或关系进行嵌入。一些学者提出混合模型,联合嵌入和逻辑规则提高模型可解释性[24-26],联合嵌入和元学习嵌入与原始KG无关联的不可见实体[27-28]、嵌入新兴KG 的不可见实体或关系[80,112]。此外,最新的研究开辟了PLMs 与逻辑推理相结合的新方向[100-101]。目前还处于初级阶段,值得进一步探索。
(5)归纳设置研究
目前研究集中在半归纳和全归纳设置,未来将研究其他的归纳方法。全归纳比半归纳具有更强的归纳能力,基于归纳嵌入和基于元学习主要集中在半归纳设置,联合元学习和归纳嵌入的模型扩展到了全归纳设置,未来将继续深入研究。此外,继续研究基于多模态信息、节点属性的模型将其全归纳设置。在全归纳设置中,基于子图和动态预训练的模型由于其独特优势引起了广泛研究,未来将继续深入研究。
