基于Spark MLlib中决策树算法对阿尔及利亚森林火灾的预测研究
2023-11-15高丰伟田睿周浩胡洁
高丰伟, 田睿, 周浩, 胡洁
南京林业大学信息科学技术学院, 江苏 南京 210037
森林火灾是一种危害极大的自然灾害,它以突发性强、破坏性大、难以处置为特点,对人类的生产生活产生严重影响。在我国,每年森林火灾平均发生一万多次,森林被烧毁的面积达到上百万公顷。森林火灾不仅损失大量林木,并且会破坏森林生态系统平衡,对森林环境造成不可逆的伤害。因此如果能够对森林火灾的发生做出预测,及时地进行预警,能够极大地预防或避免森林火灾的发生。
在森林防火预测研究中,离不开数据挖掘。Spark十分擅长处理机器学习方面的问题。在使用Spark框架时,可以将迭代计算这种对I/O和CPU消耗巨大的计算操作放进内存运行极大地提高了计算效率。MLlib是Spark框架的一部分,是分布式机器学习库。MLlib和Spark中的Spark SQL、Spark Streaming、Graph X等其他Spark子框架可以进行无缝的数据共享和相互操作[1-2],方便构建机器学习在线训练模型,在森林防火预测研究中的数据挖掘起着至关重要的作用。决策树算法是一种经典的机器学习算法,由决策树算法衍生了数量繁多的成熟系统,这些系统已在语音识别、模式识别、医疗诊断等领域得到了广泛的应用,并且在森林防火预测分类研究中也越来越受到重视。
加拿大森林火险气候指数系统(以下简称FWI系统)指标体系以大量点火试验、天气资料以及火灾资料为基础,以时滞平衡含水率理论为理论基础,把气象条件、地理位置、日照时数与可燃物含水率有机结合了起来,是全球最常用的火灾天气危险等级指数系统之一。作为全球最常用的火灾天气等级系统,其应用和研究区域较为广泛,包括在北美、南美、欧洲、非洲、亚洲等主要国家和地区都有对应研究。FWI系统在20世纪80年代首次引入我国后,一系列研究表明,FWI系统适合在云南、黑龙江、内蒙古自治区、吉林、四川、新疆和山西应用[3]。
通过对阿尔及利亚部分地区的火灾发生情况和监测的气象数据,基于Spark MLlib使用机器学习算法,对气象数据进行数据挖掘,以实现对森林火灾的预测分类。阿尔及利亚位于非洲北部,也是FWI系统的覆盖国家之一,其北部地区为地中海气候,冬季温和多雨,夏季炎热干燥,降雨量相对较少。阿尔及利亚是受世界上森林火灾影响较大的国家之一,火灾发生时段主要集中在夏季,特别是在每日的中午到下午4时这个区间。根据相关记录显示,除人为因素外,在阿尔及利亚分布较广的阿尔法草等植被被认为是高度易燃的物种,尤其是在湿度几乎为零的旱季,它们促进了火灾的快速蔓延。2008至2017年间,超过320 409 hm2的森林被烧毁,火灾超过31 513起。2012年,阿尔及利亚记录了超过5 110起火灾和烧毁面积达到了99 061 hm2[4-5]。
基于Spark MLlib机器学习框架,对阿尔及利亚北部两地区森林气象监测数据使用决策树模型进行训练并进行火灾分类预测。通过计算气象数据之间相关性以及根据气象因子与FWI系统之间的关系,对特征变量进行筛选,从而优化了决策树模型,提高了森林火灾分类预测的准确率。基于此,可为我国的森林火灾预测分类研究提供新的思路。
1 材料与方法
1.1 数据准备
1.1.1 数据来源
数据来源使用UCI机器学习库中提供的阿尔及利亚森林火灾数据集。数据集包括11个特征变量,包括日期、温度、相对湿度(RH)、风速(WS)、降雨量以及FWI系统中6个火险天气指数。由于2012年是2007年至2018年记录的火灾发生率最高的一年,因此使用2012年6月至2012年9月监测得到的4个气象因子和6个FWI系统的火险天气指数数据作为实验数据。
FWI系统与每日14时的温度、相对湿度、空旷地10 m高的风速和地方标准时中午测量的24 h的总降水量这四种气象因子关系密切。系统由6个部分组成,前3个指标分别代表森林凋落物中不同层的湿度,包括细小可燃物湿度码(FFMC)、粗腐殖质湿度码(DMC)和干旱码(DC)。每天的湿度码通过当天测量的气象数据值以及前一天的湿度码计算得到。森林可燃物的干燥速率对于不同类型是不同的,伴随着每天天气变化,可燃物湿度也发生变化。系统的后3个指标是火灾行为码,由3个湿度码和风速生成,分别表示森林中的可燃物的蔓延速度、有效可燃物的数量和代表火灾强度的火灾天气指标,即初始蔓延速度(IISI)、累积指数(BUI)和火险天气指数(FWI)[6]。
该数据集包含244个实例,包括位于阿尔及利亚东北部的Bejaia地区和位于阿尔及利亚西北部的Sidi Bel-abbes地区,各122个实例。每个实例中又包含了日期、温度、相对湿度(RH)、风速(WS)降雨量以及FWI系统中6个火险天气指数,总共2 684个原始数据。阿勒颇松(Pinus halepensisMill.)是地中海盆地干旱地区分布最广的针叶树,也是阿尔及利亚北部分布较多的植被,其物种对气候表现出可塑性生长反应,尤其对干旱十分敏感,也是阿尔及利亚北部地区较容易发生火灾的植被类型。根据以上并结合阿尔及利亚环境气候等因素,本次主要选择温度、相对湿度(RH)、风速(WS)、降雨量为气象因子进行数据挖掘及森林火灾分类预测。人为因素同样是对森林火灾发生产生影响的一大因素,但因为本文重点在于研究对已有数据进行数据挖掘以及数据特征之间的相关性分析,人为因素受当地政策及文化等主观因素影响较强,因此本次暂不考虑人为因素对预测的影响。
1.1.2 数据清洗
对于阿尔及利亚森林火灾数据集中的数据清洗过程包括缺失值处理和异常值处理:
(1)对于缺失的处理:缺失值处理的常用方法主要有删除记录、不处理和数据插补等,综合本次森林火灾数据集数据样本规模分析,删除记录和不处理显然会对最终分析结果的准确性和客观性产生影响[9]。因此,本次采用数据插补法对缺失值进行处理。本实验中的数据插补方法选为拉格朗日插值法:
已知n-1次多项式过n个点:
从数据样本中n个点(x1,y1),(x2,y2)···(xn,yn)代入多项式:
求出拉格朗日多项式为:
将缺失值对应的x代入公式(2),就能得到缺失值的插补值L(x)。
(2)对于异常值的处理:在FWI系统指数中,出现指数值小于零的情况,视为异常情况,本文将该值视为缺失值。利用现有的FWI数据,采用拉格朗日插值法对其填补。
1.2 研究方法
1.2.1 不同特征参数的相关性分析
在相关性分析中,使用皮尔森相关系数(Pearson Correlation Coefficient)是当前主流的一种分析方法[10-11]。皮尔森相关系数是一种线性相关系数,描述了两个变量之间线性相关的程度,在19世纪80年代由卡尔·皮尔逊总结前人的方法演变而来[12]。样本相关系数(样本皮尔逊系数),可通过估算样本中的协方差和标准差得到,常用r代表,其定义的公式如下:
使用Spark MLlib库中的Statistics.corr()函数对数据集的11个属性两两进行相关性分析,得到相关性系数热图,如图1所示。相关性系数是区间分布在0.2269-0.994之间。其中DMC指数和DC指数的相关性系数为0.9610,DMC指数和BUI指数的相关性系数为0.9946,DMC指数和FWI指数相关性系数为0.9006,DC指数和BUI指数相关性系数为0.9826,DC指数和FWI指数相关性系数为0.8675,ISI指数和FWI指数相关性系数为0.9382,BUI指数和FWI指数相关性系数为0.8992。将以上相关性系数大于0.8的两个特征筛选出来。需要说明的是FFMC、DMC 、DC、ISI、BUI和 FWI是根据地方标准时中午测量的24小时的总降水量、空气相对湿度、风速和24小时降水量计算得出,FWI系统中的火险指数与温度、湿度等气象因子密切相关。因此在筛选出相关性系数大于0.8的特征后,根据FWI系统中火险天气指数的特点,我们剔除了BUI、DMC及FWI三个特征参数,它们之间有较强的相关性。

图1 不同特征参数相关性分析Fig. 1 Correlation analysis of different characteristic parameters
1.2.2 决策树模型
决策树(Decision Tree)是机器学习中分类和回归的常用方法。由于易于解释,处理分类特征,扩展到多类分类设置,不需要特征缩放,并且能够捕获非线性和特征相互作用,因此决策树得到了广泛的使用[13-15]。
对于本文使用数据集来说,分类结果是由发生火灾以及不发生火灾两种组成,因此选择二叉决策树。决策树的学习主要包括3个步骤:一是特征选择,二是决策树的生成,最后是剪枝。
(1)特征选择。为了提高决策树学习的效率,往往选取的训练数据都是具有分类能力的特征。特征选择的准则一般为信息增益(或信息增益比、基尼指数等),衡量信息增益的熵越大,代表着随机变量的不确定性就越大,信息增益的描述可归纳为公式如下:
g(D,A)为特征A对训练数据集D的信息增益,H(D)与H(D|A)分别为集合D的经验熵和特征A给定条件下D的经验条件熵之差。
(a)真实火灾发生情况 (b) 预测火灾发生情况
信息增益比的描述可归纳为公式如下:
gR(D,A)为特征A对训练数据集D的信息增益比,HA(D)分别为集合D的经验熵和特征A给定条件下D的经验条件熵之比。
基尼指数可描述为:在分类问题中,假设有K个类,样本点属于第K类的概率为pk,如下公式:
在本实验中特征选择标准为基尼指数,由于只存在两类,因此K=2。
(2)决策树的生成。主要流程为:从根节点开始,对节点计算所有可能的特征的信息增益,选择信息最大的特征作为几点特征,由该特征的不同取值建立子节点,再对子节点递归地调用以上方法,构建决策树。直至所有特征信息增益均很小或无特征可选时终止。
(3)决策树的剪枝。对决策树进行剪枝,以防止对未知测试数据的分类出现过拟合的现象。剪枝往往由极小化决策树整体的损失函数进行实现。损失函数定义为:
T为任意子树,C(T)为对训练数据的预测误差,在训练,|T|为子树的叶子节点个数,Ca(T)为参数是a时的子树T的整体损失,参数a权衡训练数据的拟合程度与模型的复杂度。
1.2.3 建立训练模型
基于Spark MLlib的决策树分类模型首先对原始火山数据集进行数据清洗,对原始数据集中的缺失值及异常值进行数据处理,处理方法主要为拉格朗日插值和填补。使用case class类定义一个森林数据类forest,读取火灾数据集并创建一个forest模式的RDD并转换为DataFrame。创建决策树模型DecisionTreeClassifier,通过setter的方法来设置决策树的参数,下面简要介绍一下DecisionTreeClassifier模型对象中部分常用的参数含义。
(1)featurescol:用来设置特征列名的参数,默认值为“features”。
(2)impurity:用来设置信息增益标准的参数,支持信息增益“entropy”和基尼指数“gini”,默认值为“gini”。
(3)labelcol:用来设置标签列名的参数,默认值为“label”。
(4)maxdepth:设置树的最大深度,默认值为5。例如,将maxdepth值设置为0,表示只有一个叶子节点;将maxdepth值设置为1,表示有一个根节点和两个叶子节点。
(5)predictioncol:用来设置预测列名的参数,默认值为“prediction”。
(6)rawpredictioncol:用来设置原始预测值(置信度)的列名参数。
本次实验需要设置特征列(featurescol)和待预测列(labelcol),同时设置信息增益标准为Gini。
构建机器学习流水线,使用训练集调用fit方法对模型进行训练,得到训练模型后使用测试集调用transform方法对其进行预测。结合原始数据分类情况分析预测结果,并得到错误率。Spark MLlib的决策树分类模型流程图如图2所示。
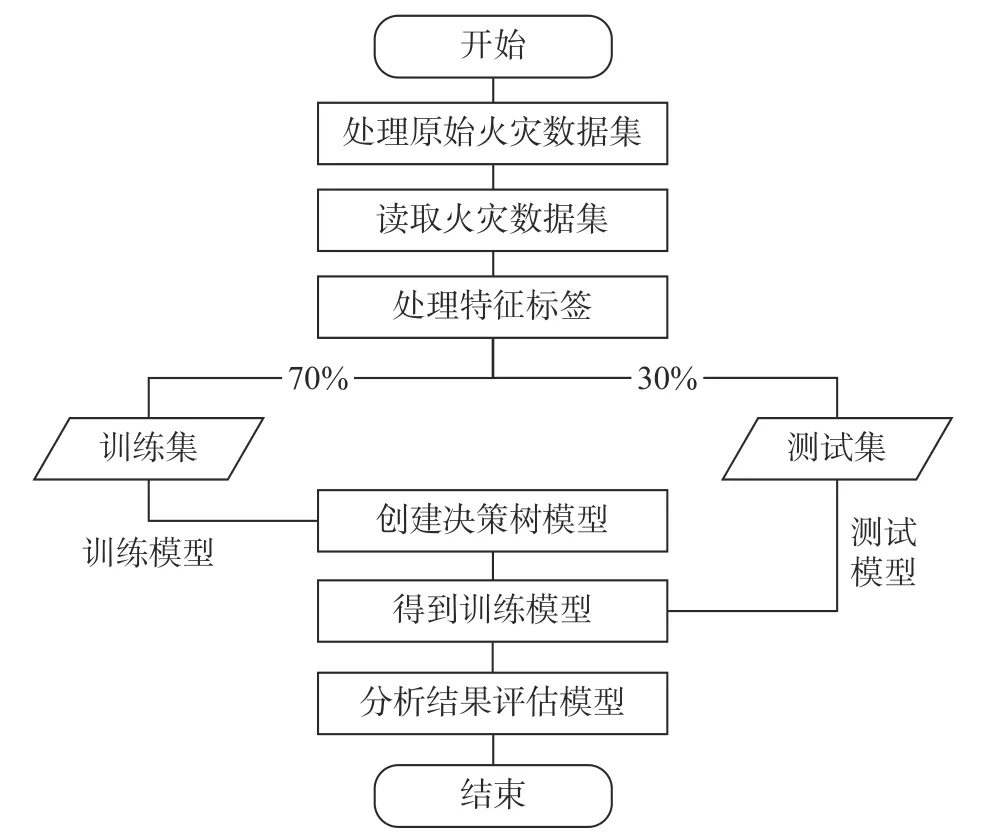
图2 构建决策树模型流程Fig. 2 Process of constructing decision tree model
2 结果与分析
2.1 使用决策树模型对森林火灾预测结果
将数据集随机分成训练集和测试集,其中训练集占70%,测试集占30%,使用训练集对模型进行训练,得到决策树模型。使用测试集对模型进行测试,结果如图3所示。左侧甘特图显示了6月—9月之间阿尔及利亚火灾发生天数情况,右侧甘特图为预测6月—9月之间的火灾发生天数。总体上看,预测结果基本一致,个别天数出现了预测错误。如6月的第21天和7月的第13天都与真实数据的分类情况产生了差异。调用函数Evaluator(),计算测试数据预测准确率,并通过程序控制台打印输出,预测准确率为94.94%(精确小数点后两位)。其中测试样本数量为40,预测分类正确数量为38,有2天的预测分类结果与实际出现了不相符的情况。为了提高预测准确率,对数据集中不同特征参数的进行研究分析,去除相关性较高的特征参数,优化模型后,再进行预测。
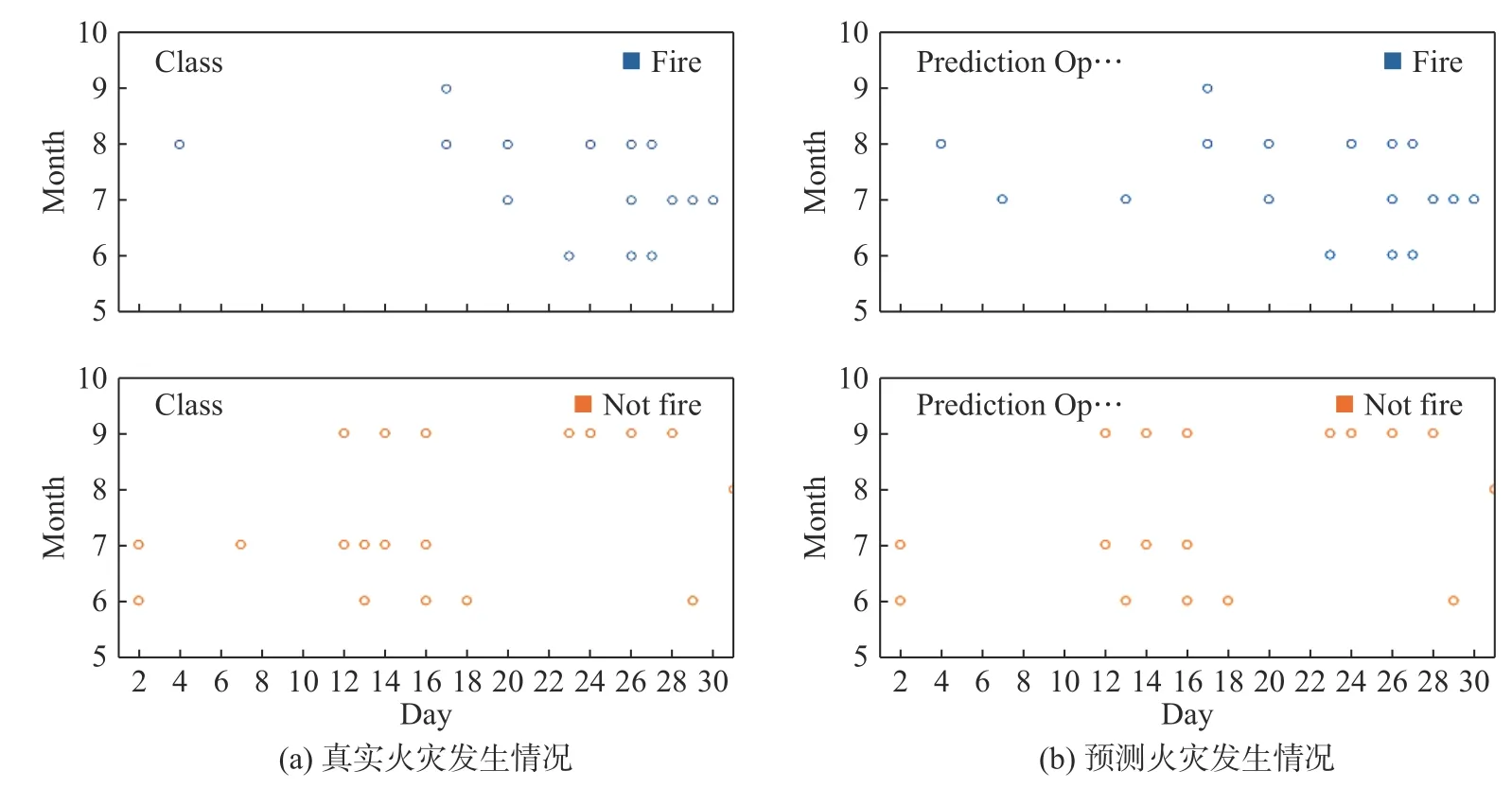
图3 原始数据分类与预测分类情况对比Fig. 3 Comparison between original data classification and forecast classification
2.2 优化模型后森林火灾预测结果比较
在原有模型的基础上,对处理数据集阶段做出优化。即对样本数据中相关性高的特征进行剔除。通过1.2.1节分析,本试验将累积指数(BUI)指数、FWI系统中的Duff湿度代码(DMC)指数及火灾天气指数(FWI)指数三个特征参数进行剔除。使用训练集对模型进行训练,得到决策树模型。使用测试集对模型进行测试,结果如图4所示。

图4 改进后预测分类与真实分类情况对比Fig. 4 Comparison between improved prediction classification and real classification
左侧甘特图显示了6月—9月之间阿尔及利亚火灾发生天数情况,右侧甘特图为预测6月—9月之间的火灾发生天数。总体上看,预测结果基本一致,也出现极个别的预测错误。例如7月的第7天与真实数据的分类情况产生了差异。同样调用函数Evaluator(),计算测试数据预测准确率,并通过程序控制台打印输出,预测准确率为97.17%(精确小数点后两位)。其中测试样本数量为34,正确预测分类数量为33,出现了1天的预测结果与实际不符的情况。相比较剔除相关性高的特征数据前的预测,准确率提高了约3%。模型改进前后预测情况对比见表1。

表1 改进前后预测准确率对比Tab. 1 Comparison of prediction accuracy before and after improvement
通过以上结果可以得出,利用Spark MLlib计算特征参数相关性并过滤,对决策树分类预测模型起到了优化的作用。因此在使用Spark MLlib计算框架时,将多种数据挖掘算法进行组合,从而对森林火灾预测的准确性进行了提升。
3 讨 论
本文选取阿尔及利亚森林火灾数据作为分析对象,经过数据清洗将数据处理成适合本文研究模型需要的数据。利用Spark大数据框架,结合原有数据集和森林火灾分类情况,提出基于Spark的决策树预测分类模型,并对森林火灾数据样本中的特征参数进行相关性分析,通过对比不同特征参数的相关性系数,以及考虑FWI系统中火险天气指数与气象因子之间的密切关系,剔除了相关性较高的一些特征参数,从而优化模型。模型优化前预测准确率达到94.94%,优化后,模型预测准确率达到97.17%,提高了近3%。
本文创新点在于利用大数据运算框架Spark MLlib对阿尔及利亚森林火灾数据进行数据挖掘以及分类预测。将大数据技术与森林火灾预测相结合,为森林火灾预测方向提供一个新的思路。本次实验也存在一些局限性,例如影响森林火灾发生的因素除温湿度等气象因素外,人为因素也是一重要影响因素。不同地区的人文文化差异、生产经营活动,都会对森林火灾的发生产生影响,需要具体问题具体分析。此外,季节也是影响森林火灾又一大因素,夏季森林火灾的发生次数明显高于冬季。在接下来的研究中,需要进一步研究分析特征参数相关性方法,进行降维,例如主成分分析(PCA)等,并考虑融合多种数据挖掘算法,将季节性因素的影响也融入研究,使预测结果更准确更全面。
