基于Transformer 融合的遥感图像文本跨模态检索方法∗
2023-11-15吴媛媛夏沭涛孙炜玮
吴媛媛 夏沭涛 孙炜玮
(1.91001部队 北京 100036)(2.海军航空大学信息融合研究所 烟台 264001)
1 引言
跨模态检索任务是利用某一种模态信息的数据作为查询去检索其他模态信息所对应的数据,模态间关联关系的建立有助于人们从海量数据中快速准确地找到感兴趣的内容。近年来卫星与无人机等遥感探测技术飞速发展,遥感图像文本跨模态检索以其灵活高效的获取感兴趣信息的方式和实际应用价值受到了广泛关注。通过建立遥感图像信息与文本信息之间准确的关联关系,实现两种模态数据之间的关联检索,不仅能有效利用多源的情报资源,而且可以得到对同一目标的多方面信息,有利于提高描述同一目标情报信息的可靠性,有着重要的实际意义。
跨模态检索的方法在自然领域已经得到了广泛的探索[1~3],国内外学者也开始对遥感领域跨模态问题进行探索。文献[4]研究了基于哈希网络的SAR与光学图像之间的遥感跨模态检索,通过引入图像转换的策略丰富了图像信息的多样性。Gou等[5]中提出了一种视觉-语音关联学习网络,并构建了图像和语音的关联数据集,验证了遥感图像与语音数据之间关联关系构建的可能性。文献[6]基于不同模态信息间潜在的语义一致性,提出了一种通用的跨模态遥感信息关联学习方法,通过共同空间的构建实现了多种模态数据的相互检索。文献[7]提出了一种深度语义对齐网络,并设计了语义对齐模块来细化遥感图像与文本的对应关系,通过利用注意力和门机制对数据特征进行过滤以得到更具辨别力的特征表示。Yuan 等[8]提出了一种适用于多源输入的非对称多模态特征匹配网络,同时构建了一个细粒度且更具挑战性的遥感图像-文本匹配数据集。虽然现在已经有许多对遥感图像跨模态检索方法的研究,但由于模型对各模态特征表示能力不足,关联关系挖掘不够充分等问题,造成现有的方法准确率仍比较低,难以满足更高准确性的任务需求。
针对上述问题,为克服遥感图像与文本描述之间的语义鸿沟,实现两种模态数据之间的准确检索,本文提出了一种基于Transformer融合的遥感图像文本跨模态检索方法,用于开展面向遥感图像文本的跨模态检索问题研究,该模型主要由各模态特征提取部分和跨模态融合部分组成,单模态特征提取部分用于获取各模态信息准确的特征表示,跨模态信息融合部分用于进一步发掘不同模态之间潜在的关联关系,实现跨模态特征信息的交互。最后,通过对比损失和匹配损失对不同模态的特征信息进行约束,增强跨模态信息间语义的一致性,以构建准确的关联关系,并在多个公开数据集上验证了方法的有效性。
2 模型设计
为提高遥感图像跨模态检索算法的准确性,本文提出了一种基于Transformer 融合的模型(TFM)。所提模型对两种不同模态数据分别设计了相应的特征提取模块,输入的遥感图像通过视觉Transformer(Vision Transformer,ViT)[9]来学习其特征表示,图像输入后首先被切分为一个个小块,进一步再经Transformer 编码器进行处理。对于文本描述,采用BERT[10]模型进行处理,BERT 是一种基于注意力的双向语言模型,而且其有效性在多种自然语言处理任务中已得到证明。本文所提模型的基本结构如图1所示。
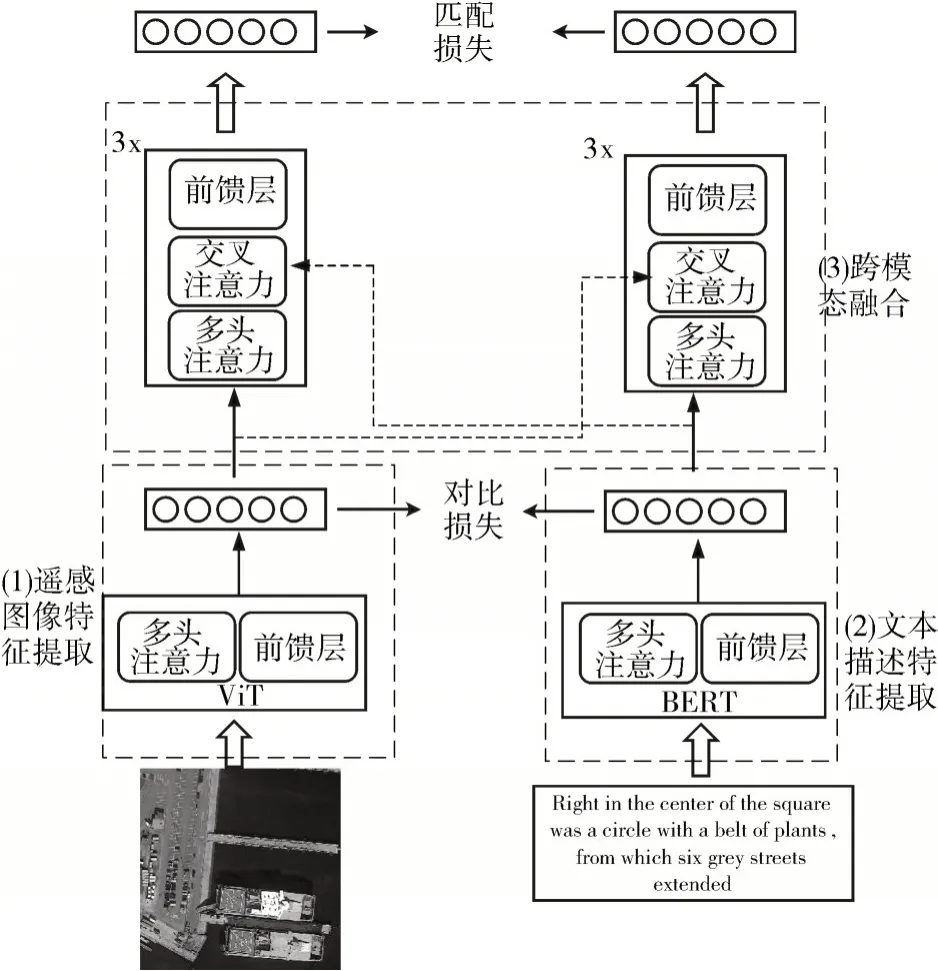
图1 本文所提方法构架
2.1 遥感图像特征表示
输入遥感图像的处理过程如图2 所示,在提取遥感图像的特征表示时,视觉特征提取模块首先会将输入图像分割为不重叠的小块:
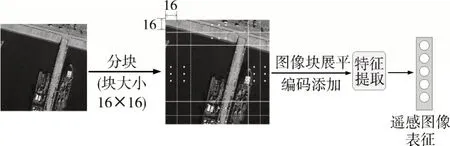
图2 遥感图像特征提取网络
在图像被分割成小块后,首先会通过一个可训练的线性投影将图像块展平并映射成维度为Dm的向量,这个投影的输出称为图像块编码,再加以表示整个图像的[CLS]编码,输入遥感图像被表示成一系列的编码向量:
在图像块编码中还加入了位置编码以使模型能够保留输入图像块的有关位置信息,有助于获得更准确的特征表示。然后将所得到的向量序列输入进行特征提取,获得最终的图像特征表示向量序列,进而将输入遥感图像的编码向量映射到模型统一特征空间中,得到遥感图像的视觉特征表示。
2.2 文本描述特征表示
对于文本描述,使用BERT 作为其特征提取模块,文本信息输入后,首先由WordPieces[11]将输入数据转化成一个标记序列,然后将序列分割成单词块的形式。
其中,ycls代表整个句子的向量表示;ysep为句子结尾标识符向量;M是分割后单词块的数量。
单词块在文本特征编码器初步处理后得到对应词块的编码向量,再与输入序列文本的位置编码向量相结合得到最终的序列文本输入的向量形式。然后进一步进行特征表示的学习,最后将学习到的特征向量映射到模型统一的特征空间中,获得输入序列文本信息的特征表示。
图3 展示了输入的序列文本信息处理过程,在文本描述输入到特征编码器后会先按单词拆分,再进一步提取输入数据所包含的丰富浅层特征和深层语义特征信息。

图3 文本特征提取网络
2.3 跨模态融合模块
为了实现遥感图像与序列文本之间的跨模态信息间的交互,本文模型中构建了跨模态信息融合模块。模块基于Transformer的基本架构,通过使用交叉注意机制进一步挖掘跨模态信息间潜在的相关关系,提高关联的准确性。这种注意力机制与多头注意力模块结构相类似,但存在一定区别,跨模态信息融合模块中的注意力机理如图4 所示,其中X和Y是来自不同模态的特征信息。设计的跨模态融合模块,通过融合单模态的特征表示来获取融合特征信息,以进一步发掘不同模态信息间的关联关系,提高特征表示的判别性。在融合之前,单模态编码器已分别学习得到了视觉特征表示和序列文本特征表示,然后该模块在单模态获得的特征信息的基础上,通过模态间信息的交互进一步挖掘有助于构建跨模态关联关系的潜在语义信息。

图4 跨模态融合模块中的注意力机制
以输入为同一模态信息时为例,该注意力机制的计算过程可表述如下:
3.学生在课堂中学习了一些有趣事实之后,通过Brainstorm的形式让学生总结可以表达情感和观点的形容词,学生给出的词汇非常丰富。
其中,Z∊Rn×d为输入向量,n为输入向量长度,d为维度;WQi=∊Rdm×D,WKi=∊Rdm×D,WVi=∊Rdm×D和WO=∊RHD×dm是参数矩阵;dm表示模型的维数,通常dm=d;H为多头注意力的头数;D通过D=dm/H计算。其输出结果会进一步输入到前馈模块,经前馈神经网络和激活函数处理后输出。
2.4 目标函数
在本文模型中,为了在共同的特征空间中对不同模态信息进行约束,构建准确的跨模态关联关系,所提模型设计的目标函数是对比损失和匹配损失的组合。对比损失通过最大化遥感图像和序列文本间的相互信息,使得不同模态的语义信息保持一致性。而匹配损失有助于提高本文所提模型对输入的图像和序列信息是否匹配的判别能力,以建立更准确的关联关系。所提模型整体的目标函数可表示为
1)对比损失
对比学习在一定程度上可以使得不同模态特征表示间的相互信息最大化,让相关的图像和文本信息在共同特征空间中更接近,而不相关的图像和文本的表征信息在共同特征空间中距离更远。采用与文献[12]MoCo 类似的方式,使用动态字典作为存储负样本的队列,其中的样本在训练过程中会依次被替换,该过程由与对应的模态特征编码器共享相参数的动量编码器实现,所提模型中使用两个队列存储来自动量单模态编码器的视觉和文本表示。不同模态信息间的相似度计算公式如下:
其中,Xcls,Ycls分别是图像和文本编码器最终输出中代表整体信息的[CLS]编码;gx,gy将[CLS]编码向量映射为归一化的低维特征表示。
通过对遥感图像和文本描述特征表示的对比学习,所提模型可以更好地挖掘跨模态信息中潜在的语义信息,对比损失能够使得相匹配的遥感图像和序列文本的语义信息保持一致性,发掘不同模态信息间的潜在相关性,使单模态特征编码器学习到的特征表示更具判别性。跨模态信息的对比损失有如下定义:
其中,h()表示交叉熵函数;Lit(I)和Lti(T)表示跨模态信息间真实的相似度标签。
2)匹配损失
为了进一步提高所提方法的关联性能,在模型中引入匹配损失来预测遥感图像与序列文本信息是否相匹配。针对部分数据信息间具有很强的相似性,容易造成混淆,因此模型通过不同模态间的相似度找出硬负对来进一步提高判别性能,硬负对是指其中的部分样本和真值具有较高相似度,但在具体细节存在差异,影响关联的精确性。在计算跨模态信息间的匹配损失时,所提模型采用了硬负对的训练策略。匹配损失的计算公式定义为
式中,ym是表示对应真值的二维独热编码向量;pm是跨模态信息相互匹配的概率,由跨模态信息融合模块输出的[CLS]编码向量进行计算。
3 实验验证分析
3.1 数据集
常用的遥感图像文本公开数据集主要包括:SYD-Captions 数据集[13],数据集包含613 张遥感图像,每幅图像对应5个描述语句。UCM-Captions数据集是在文献[13]中构造的,数据集包含2100 张遥感图像,每幅图像对应5 个描述语句。遥感图像文本匹配数据集(Remote sensing Image-Text Match dataset,RSITMD)[8]是最新公开的一个细粒度的遥感图像与文本描述匹配数据集。该数据集共包含4743幅遥感图像,且仍使用5 个句子来描述每幅图像的内容,但描述更注重细节信息,各句子之间的相似性更低。上述数据集中的部分样例如图5中所示。

图5 SYD-Captions、RSITMD和UCM-Captions数据集样例
3.2 实验设置
为了充分验证本文所提方法的有效性,本文在上述数据集上进行了大量实验。对于每个数据集,实验时将80%的数据用作训练,10%用作验证,剩下的10%作为测试。
在实验中,学习率设置为0.00003,迭代次数为20。在训练过程中使用余弦退火策略来衰减学习率,图像特征提取模块通过预先训练的权值的ViT[14]进行初始化,文本描述特征提取模块由预训练的BERT 模型进行初始化,两种模态数据输出特征向量的维度均设置为768,使用AdamW优化器[15]进行训练。
跨模态检索任务分为遥感图像检索文本(I→T)以及文本检索遥感图像(T→I)两种类型。本文实验采用召回率作为算法的性能衡量指标,R@K表示针对某一模态的查询数据,返回的其他模态数据的前K 个返回值中包含的真值的比例,K 通常设置为1,5 和10。另一个来评估模型性能的度量指标为R_mean,用R@K 所有数据的平均值表示,能够更直观地反映模型的整体性能。上述指标的值越高,模型的表现越好。
3.3 实验结果与分析
为验证本文方法的有效性,我们在上述数据集上进行了实验验证,并与部分图文跨模态检索的基准算法进行了对比实验。对比算法分别为VSE++、SCAN、CAMP、MTFN,对比实验在相同的实验条件下进行[8],方法AMFMN 的后面代表其模型不同的注意力计算方法。在遥感领域常用公开的跨模态数据集上的对比结果如表1~3 所示。
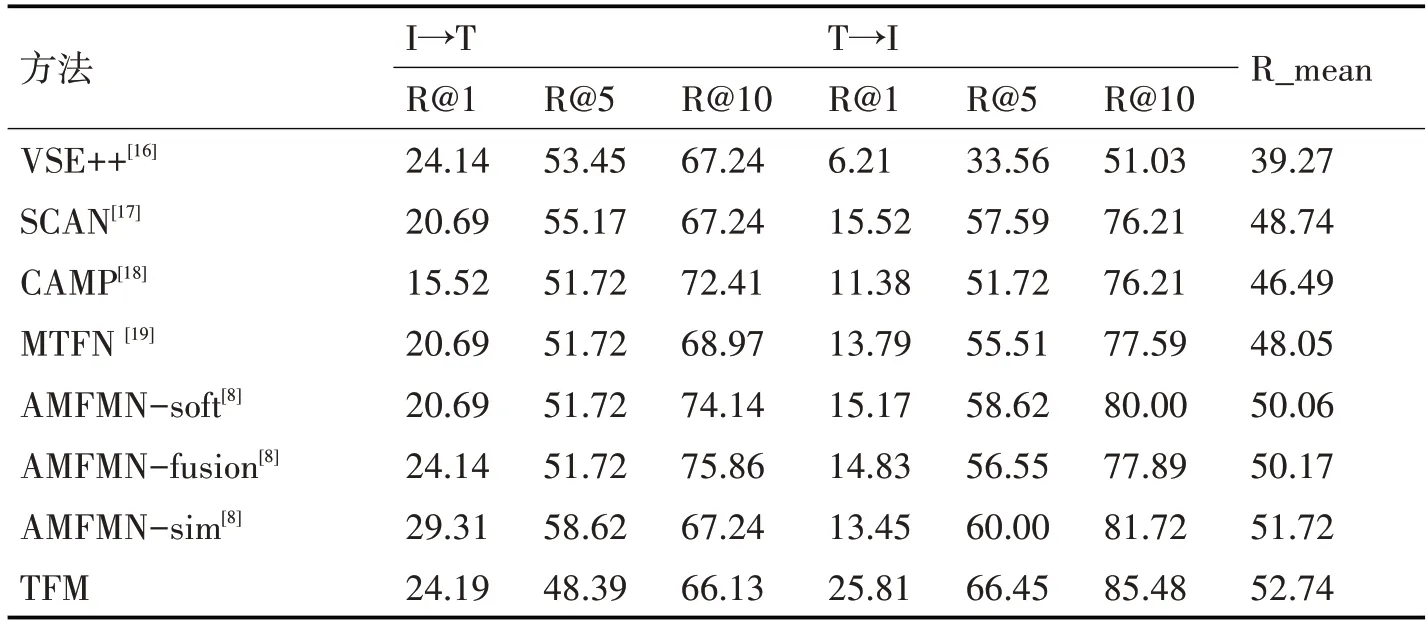
表1 不同方法在SYD-Captions数据集上的结果对比

表2 不同方法在UCM数据集上的结果对比
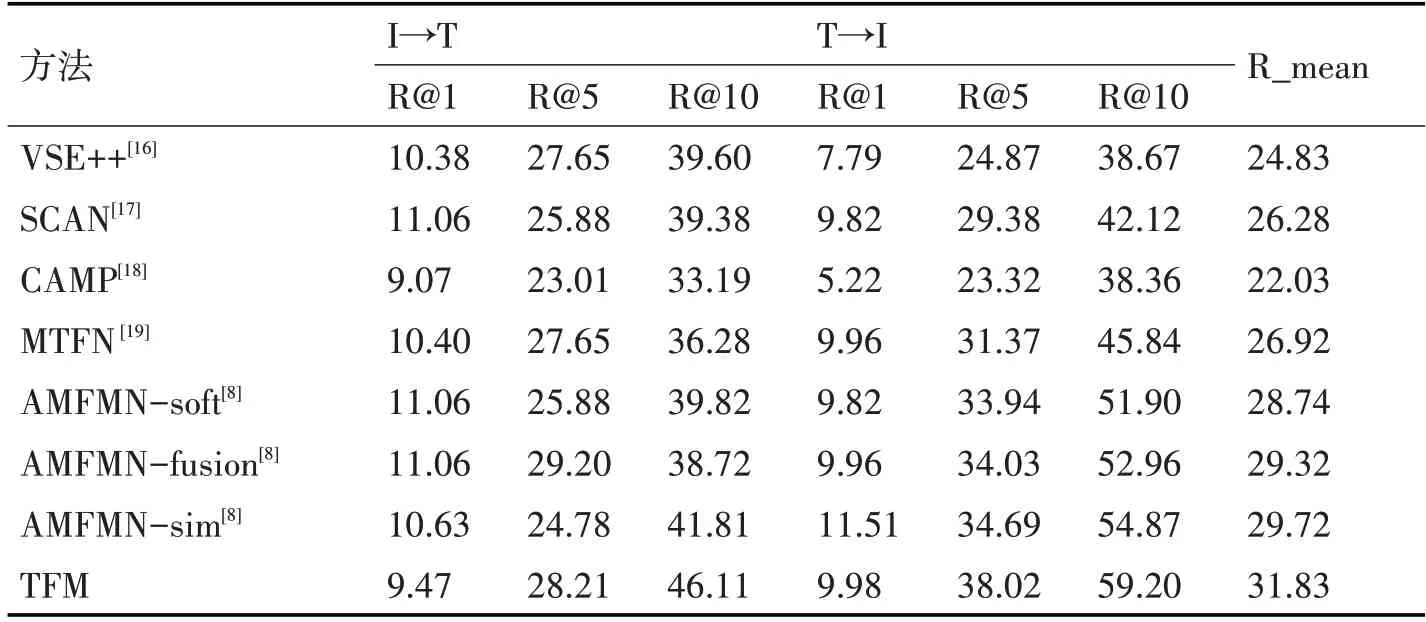
表3 不同方法在RSITMD数据集上的结果对比
对比结果如表1~3 所示,其中VSE++、SCAN、CAMP、MTFN 是计算机视觉领域用于解决自然场景图像跨模态关联检索问题的算法,从表格中可以看出,与这些方法相比,本文所提方法在几个公开数据集上的实验结果在反映模型整体性能的度量指标R_mean 以及各任务R@K 指标上大都有较大幅度的提高。这说明计算机视觉领域的部分方法在用于遥感领域时,由于遥感图像的语义信息相对更丰富,导致这些模型的检索效果并不理想,难以获得数据中的准确表征信息来构建关联关系。AMEMN 是遥感领域最近提出的用于图像文本跨模态关联的非对称多模态特征匹配网络,可用于多尺度输入并能动态过滤冗余特征,与计算机视觉领域的几种方法相比具有更好的性能。而本文所提的方法整体表现更为出色,在各个数据集的模型整体评价值指标R_mean 上均达到了最佳的表现,而且在两个子任务的评价指标上的表现也较好,实验结果优于其他基准算法。通过上述在常用公开数据集上与其他基准算法的对比,实验结果有力说明了本文所提模型在实现遥感图像跨模态关联任务上的有效性,表明本文方法能够较准确地对各模态信息的特征进行表征实现遥感图像与文本描述之间的相互检索。
4 结语
本文提出了一种基于Transformer 融合的遥感图像文本跨模态检索方法。针对不同模态的信息,分别设计了对应特征提取模块,再通过基于注意力的融合模块实现跨模态信息间的交互,有助于深入发掘不同模态信息间潜在的相关关系,增强语义相关性。进一步通过对比学习损失函数以及不同模态数据间的匹配损失函数的设计,使不同模态间的相互信息最大化,增强跨模态信息间的语义相关性及一致性,构建准确的关联关系。最后在多个公开数据集上,通过与其他基准方法的对比实验,充分验证了所提方法的有效性。不过模型规模相对较大,后续将考虑轻量化的设计进一步优化所提算法。
